transitions
Release 0.9.2
Python 中的轻量级、面向对象的状态机实现,具有许多扩展。与 Python 2.7+ 和 3.0+ 兼容。
pip install transitions
...或者从 GitHub 克隆存储库,然后:
python setup.py install
他们说一个好的例子胜过 100 页 API 文档、一百万条指令或一千个单词。
好吧,“他们”可能在撒谎……但无论如何,这里有一个例子:
from transitions import Machine
import random
class NarcolepticSuperhero ( object ):
# Define some states. Most of the time, narcoleptic superheroes are just like
# everyone else. Except for...
states = [ 'asleep' , 'hanging out' , 'hungry' , 'sweaty' , 'saving the world' ]
def __init__ ( self , name ):
# No anonymous superheroes on my watch! Every narcoleptic superhero gets
# a name. Any name at all. SleepyMan. SlumberGirl. You get the idea.
self . name = name
# What have we accomplished today?
self . kittens_rescued = 0
# Initialize the state machine
self . machine = Machine ( model = self , states = NarcolepticSuperhero . states , initial = 'asleep' )
# Add some transitions. We could also define these using a static list of
# dictionaries, as we did with states above, and then pass the list to
# the Machine initializer as the transitions= argument.
# At some point, every superhero must rise and shine.
self . machine . add_transition ( trigger = 'wake_up' , source = 'asleep' , dest = 'hanging out' )
# Superheroes need to keep in shape.
self . machine . add_transition ( 'work_out' , 'hanging out' , 'hungry' )
# Those calories won't replenish themselves!
self . machine . add_transition ( 'eat' , 'hungry' , 'hanging out' )
# Superheroes are always on call. ALWAYS. But they're not always
# dressed in work-appropriate clothing.
self . machine . add_transition ( 'distress_call' , '*' , 'saving the world' ,
before = 'change_into_super_secret_costume' )
# When they get off work, they're all sweaty and disgusting. But before
# they do anything else, they have to meticulously log their latest
# escapades. Because the legal department says so.
self . machine . add_transition ( 'complete_mission' , 'saving the world' , 'sweaty' ,
after = 'update_journal' )
# Sweat is a disorder that can be remedied with water.
# Unless you've had a particularly long day, in which case... bed time!
self . machine . add_transition ( 'clean_up' , 'sweaty' , 'asleep' , conditions = [ 'is_exhausted' ])
self . machine . add_transition ( 'clean_up' , 'sweaty' , 'hanging out' )
# Our NarcolepticSuperhero can fall asleep at pretty much any time.
self . machine . add_transition ( 'nap' , '*' , 'asleep' )
def update_journal ( self ):
""" Dear Diary, today I saved Mr. Whiskers. Again. """
self . kittens_rescued += 1
@ property
def is_exhausted ( self ):
""" Basically a coin toss. """
return random . random () < 0.5
def change_into_super_secret_costume ( self ):
print ( "Beauty, eh?" )现在,您已将状态机烘焙到NarcolepticSuperhero中。让我们带他/她/出去兜风吧……
> >> batman = NarcolepticSuperhero ( "Batman" )
> >> batman . state
'asleep'
> >> batman . wake_up ()
> >> batman . state
'hanging out'
> >> batman . nap ()
> >> batman . state
'asleep'
> >> batman . clean_up ()
MachineError : "Can't trigger event clean_up from state asleep!"
> >> batman . wake_up ()
> >> batman . work_out ()
> >> batman . state
'hungry'
# Batman still hasn't done anything useful...
> >> batman . kittens_rescued
0
# We now take you live to the scene of a horrific kitten entreement...
> >> batman . distress_call ()
'Beauty, eh?'
> >> batman . state
'saving the world'
# Back to the crib.
> >> batman . complete_mission ()
> >> batman . state
'sweaty'
> >> batman . clean_up ()
> >> batman . state
'asleep' # Too tired to shower!
# Another productive day, Alfred.
> >> batman . kittens_rescued
1虽然我们无法读懂真正的蝙蝠侠的想法,但我们肯定可以想象我们NarcolepticSuperhero的当前状态。
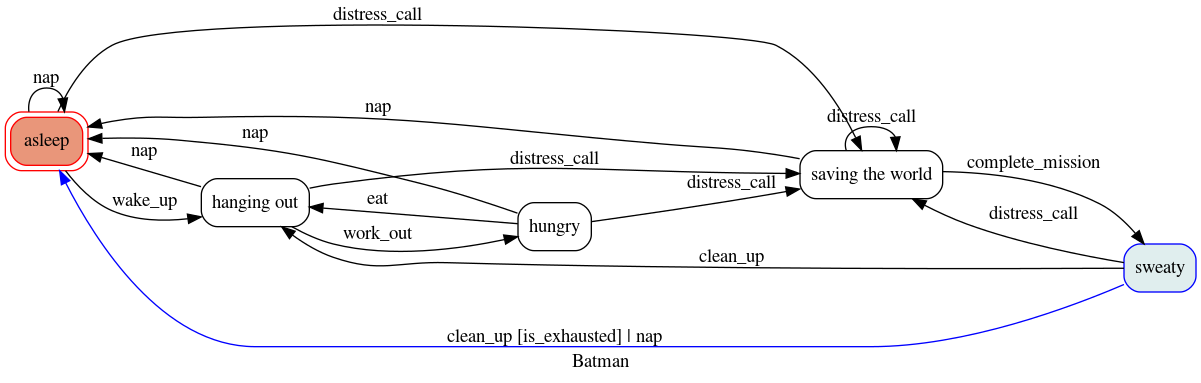
如果您想知道如何操作,请查看图表扩展。
状态机是由有限数量的状态和这些状态之间的转换组成的行为模型。在每个状态和转换中可以执行一些操作。状态机需要在某个初始状态下启动。当使用transitions时,状态机可能由多个对象组成,其中一些(机器)包含用于操作其他(模型)的定义。下面,我们将了解一些核心概念以及如何使用它们。
状态。状态表示状态机中的特定条件或阶段。这是一种独特的行为模式或过程的阶段。
过渡。这是导致状态机从一种状态变为另一种状态的过程或事件。
模型。实际的有状态结构。它是在转换期间更新的实体。它还可以定义将在转换期间执行的操作。例如,在转换之前或进入或退出状态时。
机器。这是管理和控制模型、状态、转换和操作的实体。它是协调状态机整个过程的指挥者。
扳机。这是启动转换的事件,发送信号以启动转换的方法。
行动。当进入、退出某个状态或在转换期间执行的特定操作或任务。该操作是通过回调实现的,回调是在某些事件发生时执行的函数。
启动并运行状态机非常简单。假设您有对象lump ( Matter类的实例),并且您想要管理其状态:
class Matter ( object ):
pass
lump = Matter ()您可以初始化绑定到模型lump (最小)工作状态机,如下所示:
from transitions import Machine
machine = Machine ( model = lump , states = [ 'solid' , 'liquid' , 'gas' , 'plasma' ], initial = 'solid' )
# Lump now has a new state attribute!
lump . state
> >> 'solid'另一种方法是不显式地将模型传递给Machine初始值设定项:
machine = Machine ( states = [ 'solid' , 'liquid' , 'gas' , 'plasma' ], initial = 'solid' )
# The machine instance itself now acts as a model
machine . state
> >> 'solid'请注意,这次我没有将lump模型作为参数传递。传递给Machine第一个参数充当模型。因此,当我在那里传递一些东西时,所有便利功能都将添加到该对象中。如果未提供模型,则machine实例本身充当模型。
当我一开始说“最小”时,这是因为虽然这个状态机在技术上是可操作的,但它实际上并没有做任何事情。它从'solid'状态开始,但永远不会进入另一个状态,因为还没有定义任何转换!
让我们再试一次。
# The states
states = [ 'solid' , 'liquid' , 'gas' , 'plasma' ]
# And some transitions between states. We're lazy, so we'll leave out
# the inverse phase transitions (freezing, condensation, etc.).
transitions = [
{ 'trigger' : 'melt' , 'source' : 'solid' , 'dest' : 'liquid' },
{ 'trigger' : 'evaporate' , 'source' : 'liquid' , 'dest' : 'gas' },
{ 'trigger' : 'sublimate' , 'source' : 'solid' , 'dest' : 'gas' },
{ 'trigger' : 'ionize' , 'source' : 'gas' , 'dest' : 'plasma' }
]
# Initialize
machine = Machine ( lump , states = states , transitions = transitions , initial = 'liquid' )
# Now lump maintains state...
lump . state
> >> 'liquid'
# And that state can change...
# Either calling the shiny new trigger methods
lump . evaporate ()
lump . state
> >> 'gas'
# Or by calling the trigger method directly
lump . trigger ( 'ionize' )
lump . state
> >> 'plasma'请注意附加到Matter实例的闪亮新方法( evaporate() 、 ionize()等)。每个方法都会触发相应的转换。还可以通过调用带有转换名称的trigger()方法来动态触发转换,如上所示。有关此内容的更多信息,请参阅触发转换部分。
任何好的状态机(毫无疑问,还有许多坏的状态机)的灵魂都是一组状态。上面,我们通过将字符串列表传递给Machine初始值设定项来定义有效的模型状态。但在内部,状态实际上表示为State对象。
您可以通过多种方式初始化和修改状态。具体来说,您可以:
Machine初始值设定项,给出状态的名称,或者State对象,或者以下片段说明了实现同一目标的几种方法:
# import Machine and State class
from transitions import Machine , State
# Create a list of 3 states to pass to the Machine
# initializer. We can mix types; in this case, we
# pass one State, one string, and one dict.
states = [
State ( name = 'solid' ),
'liquid' ,
{ 'name' : 'gas' }
]
machine = Machine ( lump , states )
# This alternative example illustrates more explicit
# addition of states and state callbacks, but the net
# result is identical to the above.
machine = Machine ( lump )
solid = State ( 'solid' )
liquid = State ( 'liquid' )
gas = State ( 'gas' )
machine . add_states ([ solid , liquid , gas ])状态在添加到机器时初始化一次,并将持续存在,直到它们从机器中删除。换句话说:如果您更改状态对象的属性,则下次进入该状态时不会重置此更改。如果您需要其他行为,请查看如何扩展状态功能。
但是仅仅拥有状态并能够在它们之间移动(转换)本身并不是很有用。如果您想要做某事,在进入或退出某种状态时执行某些操作怎么办?这就是回调发挥作用的地方。
State还可以与enter和exit回调列表相关联,每当状态机进入或离开该状态时都会调用这些回调。您可以在初始化期间通过将回调传递给State属性字典中的状态对象构造函数来指定回调,或者稍后添加它们。
为了方便起见,每当将新State添加到Machine时,方法on_enter_«state name»和on_exit_«state name»都会在 Machine 上动态创建(而不是在模型上!),这允许您动态添加新的进入和退出如果您需要的话稍后回调。
# Our old Matter class, now with a couple of new methods we
# can trigger when entering or exit states.
class Matter ( object ):
def say_hello ( self ): print ( "hello, new state!" )
def say_goodbye ( self ): print ( "goodbye, old state!" )
lump = Matter ()
# Same states as above, but now we give StateA an exit callback
states = [
State ( name = 'solid' , on_exit = [ 'say_goodbye' ]),
'liquid' ,
{ 'name' : 'gas' , 'on_exit' : [ 'say_goodbye' ]}
]
machine = Machine ( lump , states = states )
machine . add_transition ( 'sublimate' , 'solid' , 'gas' )
# Callbacks can also be added after initialization using
# the dynamically added on_enter_ and on_exit_ methods.
# Note that the initial call to add the callback is made
# on the Machine and not on the model.
machine . on_enter_gas ( 'say_hello' )
# Test out the callbacks...
machine . set_state ( 'solid' )
lump . sublimate ()
> >> 'goodbye, old state!'
> >> 'hello, new state!'请注意,当机器首次初始化时, on_enter_«state name»回调不会触发。例如,如果您定义了on_enter_A()回调,并使用initial='A'初始化Machine ,则on_enter_A()直到您下次进入状态A时才会被触发。 (如果您需要确保on_enter_A()在初始化时触发,您可以简单地创建一个虚拟初始状态,然后在__init__方法内显式调用to_A() 。)
除了在初始化State时传入回调或动态添加回调之外,还可以在模型类本身中定义回调,这可能会提高代码清晰度。例如:
class Matter ( object ):
def say_hello ( self ): print ( "hello, new state!" )
def say_goodbye ( self ): print ( "goodbye, old state!" )
def on_enter_A ( self ): print ( "We've just entered state A!" )
lump = Matter ()
machine = Machine ( lump , states = [ 'A' , 'B' , 'C' ])现在,任何时候lump转换到状态A时, Matter类中定义的on_enter_A()方法都会触发。
您可以使用on_final回调,当进入final=True状态时将触发该回调。
from transitions import Machine , State
states = [ State ( name = 'idling' ),
State ( name = 'rescuing_kitten' ),
State ( name = 'offender_gone' , final = True ),
State ( name = 'offender_caught' , final = True )]
transitions = [[ "called" , "idling" , "rescuing_kitten" ], # we will come when called
{ "trigger" : "intervene" ,
"source" : "rescuing_kitten" ,
"dest" : "offender_gone" , # we
"conditions" : "offender_is_faster" }, # unless they are faster
[ "intervene" , "rescuing_kitten" , "offender_caught" ]]
class FinalSuperhero ( object ):
def __init__ ( self , speed ):
self . machine = Machine ( self , states = states , transitions = transitions , initial = "idling" , on_final = "claim_success" )
self . speed = speed
def offender_is_faster ( self , offender_speed ):
return self . speed < offender_speed
def claim_success ( self , ** kwargs ):
print ( "The kitten is safe." )
hero = FinalSuperhero ( speed = 10 ) # we are not in shape today
hero . called ()
assert hero . is_rescuing_kitten ()
hero . intervene ( offender_speed = 15 )
# >>> 'The kitten is safe'
assert hero . machine . get_state ( hero . state ). final # it's over
assert hero . is_offender_gone () # maybe next time ... 您始终可以通过以下任一方式检查模型的当前状态:
.state属性,或者is_«state name»()如果您想检索当前状态的实际State对象,可以通过Machine实例的get_state()方法来实现。
lump . state
> >> 'solid'
lump . is_gas ()
> >> False
lump . is_solid ()
> >> True
machine . get_state ( lump . state ). name
> >> 'solid'如果您愿意,可以在初始化Machine时通过传递model_attribute参数来选择自己的状态属性名称。这也会将is_«state name»()的名称更改为is_«model_attribute»_«state name»() 。类似地,自动转换将被命名to_«model_attribute»_«state name»()而不是to_«state name»() 。这样做是为了允许多台机器在具有单独状态属性名称的同一模型上工作。
lump = Matter ()
machine = Machine ( lump , states = [ 'solid' , 'liquid' , 'gas' ], model_attribute = 'matter_state' , initial = 'solid' )
lump . matter_state
> >> 'solid'
# with a custom 'model_attribute', states can also be checked like this:
lump . is_matter_state_solid ()
> >> True
lump . to_matter_state_gas ()
> >> True 到目前为止,我们已经了解了如何给出状态名称并使用这些名称来使用我们的状态机。如果您喜欢更严格的输入和更多的 IDE 代码完成(或者您只是不能再输入“sesquipedalophobia”,因为这个词让您感到害怕),那么使用枚举可能就是您正在寻找的:
import enum # Python 2.7 users need to have 'enum34' installed
from transitions import Machine
class States ( enum . Enum ):
ERROR = 0
RED = 1
YELLOW = 2
GREEN = 3
transitions = [[ 'proceed' , States . RED , States . YELLOW ],
[ 'proceed' , States . YELLOW , States . GREEN ],
[ 'error' , '*' , States . ERROR ]]
m = Machine ( states = States , transitions = transitions , initial = States . RED )
assert m . is_RED ()
assert m . state is States . RED
state = m . get_state ( States . RED ) # get transitions.State object
print ( state . name ) # >>> RED
m . proceed ()
m . proceed ()
assert m . is_GREEN ()
m . error ()
assert m . state is States . ERROR如果您愿意,您可以混合枚举和字符串(例如[States.RED, 'ORANGE', States.YELLOW, States.GREEN] ),但请注意,在内部, transitions仍会按名称处理状态( enum.Enum.name )。因此,不可能同时具有状态'GREEN'和States.GREEN 。
上面的一些示例已经说明了传递中过渡的使用,但在这里我们将更详细地探讨它们。
与状态一样,每个转换在内部都表示为其自己的对象 - 类Transition的实例。初始化一组转换的最快方法是将字典或字典列表传递给Machine初始化程序。我们已经在上面看到了这一点:
transitions = [
{ 'trigger' : 'melt' , 'source' : 'solid' , 'dest' : 'liquid' },
{ 'trigger' : 'evaporate' , 'source' : 'liquid' , 'dest' : 'gas' },
{ 'trigger' : 'sublimate' , 'source' : 'solid' , 'dest' : 'gas' },
{ 'trigger' : 'ionize' , 'source' : 'gas' , 'dest' : 'plasma' }
]
machine = Machine ( model = Matter (), states = states , transitions = transitions )在字典中定义转换的优点是清晰,但可能很麻烦。如果您追求简洁,您可以选择使用列表来定义转换。只需确保每个列表中的元素与Transition初始化中的位置参数的顺序相同(即, trigger 、 source 、 destination等)。
下面的列表列表在功能上等同于上面的字典列表:
transitions = [
[ 'melt' , 'solid' , 'liquid' ],
[ 'evaporate' , 'liquid' , 'gas' ],
[ 'sublimate' , 'solid' , 'gas' ],
[ 'ionize' , 'gas' , 'plasma' ]
]或者,您可以在初始化后向Machine添加转换:
machine = Machine ( model = lump , states = states , initial = 'solid' )
machine . add_transition ( 'melt' , source = 'solid' , dest = 'liquid' )要执行转换,需要某些事件来触发它。有两种方法可以做到这一点:
在基础模型中使用自动附加的方法:
> >> lump . melt ()
> >> lump . state
'liquid'
> >> lump . evaporate ()
> >> lump . state
'gas'请注意,您不必在任何地方显式定义这些方法;每个转换的名称都绑定到传递给Machine初始值设定项的模型(在本例中为lump )。这也意味着您的模型不应包含与事件触发器同名的方法,因为如果尚未占用该位置, transitions只会将便捷方法附加到您的模型。如果您想修改该行为,请查看常见问题解答。
使用trigger方法,现在附加到您的模型(如果之前没有)。如果需要动态触发,此方法允许您按名称执行转换:
> >> lump . trigger ( 'melt' )
> >> lump . state
'liquid'
> >> lump . trigger ( 'evaporate' )
> >> lump . state
'gas' 默认情况下,触发无效转换将引发异常:
> >> lump . to_gas ()
> >> # This won't work because only objects in a solid state can melt
>> > lump . melt ()
transitions . core . MachineError : "Can't trigger event melt from state gas!"这种行为通常是可取的,因为它有助于提醒您代码中的问题。但在某些情况下,您可能希望默默地忽略无效触发器。您可以通过设置ignore_invalid_triggers=True (逐个州或全局所有州)来执行此操作:
> >> # Globally suppress invalid trigger exceptions
>> > m = Machine ( lump , states , initial = 'solid' , ignore_invalid_triggers = True )
> >> # ...or suppress for only one group of states
>> > states = [ 'new_state1' , 'new_state2' ]
> >> m . add_states ( states , ignore_invalid_triggers = True )
> >> # ...or even just for a single state. Here, exceptions will only be suppressed when the current state is A.
>> > states = [ State ( 'A' , ignore_invalid_triggers = True ), 'B' , 'C' ]
> >> m = Machine ( lump , states )
> >> # ...this can be inverted as well if just one state should raise an exception
>> > # since the machine's global value is not applied to a previously initialized state.
>> > states = [ 'A' , 'B' , State ( 'C' )] # the default value for 'ignore_invalid_triggers' is False
> >> m = Machine ( lump , states , ignore_invalid_triggers = True )如果您需要知道某个状态下哪些转换是有效的,您可以使用get_triggers :
m . get_triggers ( 'solid' )
> >> [ 'melt' , 'sublimate' ]
m . get_triggers ( 'liquid' )
> >> [ 'evaporate' ]
m . get_triggers ( 'plasma' )
> >> []
# you can also query several states at once
m . get_triggers ( 'solid' , 'liquid' , 'gas' , 'plasma' )
> >> [ 'melt' , 'evaporate' , 'sublimate' , 'ionize' ]如果您从一开始就遵循本文档,您会注意到get_triggers实际上返回的触发器比上面显示的显式定义的触发器要多,例如to_liquid等。这些称为auto-transitions ,将在下一节中介绍。
除了显式添加的任何转换之外,每当将状态添加到Machine实例时,都会自动创建to_«state»()方法。无论机器当前处于哪种状态,此方法都会转换到目标状态:
lump . to_liquid ()
lump . state
> >> 'liquid'
lump . to_solid ()
lump . state
> >> 'solid'如果您愿意,可以通过在Machine初始值设定项中设置auto_transitions=False来禁用此行为。
给定的触发器可以附加到多个转换,其中一些转换可能以相同的状态开始或结束。例如:
machine . add_transition ( 'transmogrify' , [ 'solid' , 'liquid' , 'gas' ], 'plasma' )
machine . add_transition ( 'transmogrify' , 'plasma' , 'solid' )
# This next transition will never execute
machine . add_transition ( 'transmogrify' , 'plasma' , 'gas' )在这种情况下,如果模型当前为'plasma'则调用transmogrify()会将模型的状态设置为'solid' ,否则将其设置为'plasma' 。 (请注意,只有第一个匹配的转换才会执行;因此,上面最后一行中定义的转换不会执行任何操作。)
您还可以使用'*'通配符使触发器从所有状态转换到特定目的地:
machine . add_transition ( 'to_liquid' , '*' , 'liquid' )请注意,通配符转换仅适用于调用 add_transition() 时存在的状态。当模型处于定义转换后添加的状态时调用基于通配符的转换将引发无效转换消息,并且不会转换到目标状态。
可以轻松添加反射触发器(与源和目标具有相同状态的触发器),并将=指定为目标。如果应将相同的反射触发器添加到多个状态,这会很方便。例如:
machine . add_transition ( 'touch' , [ 'liquid' , 'gas' , 'plasma' ], '=' , after = 'change_shape' )这将为所有三种状态添加自反转换,以touch()作为触发器,并在每个触发器后执行change_shape 。
与自反转换相反,内部转换永远不会真正离开状态。这意味着将处理与转换相关的回调(例如before或after ,而与状态相关的回调exit或enter则不会。要将转换定义为内部,请将目标设置为None 。
machine . add_transition ( 'internal' , [ 'liquid' , 'gas' ], None , after = 'change_shape' )人们普遍希望状态转换遵循严格的线性顺序。例如,给定状态['A', 'B', 'C'] ,您可能需要A → B 、 B → C和C → A的有效转换(但没有其他对)。
为了促进这种行为,Transitions 在Machine类中提供了add_ordered_transitions()方法:
states = [ 'A' , 'B' , 'C' ]
# See the "alternative initialization" section for an explanation of the 1st argument to init
machine = Machine ( states = states , initial = 'A' )
machine . add_ordered_transitions ()
machine . next_state ()
print ( machine . state )
> >> 'B'
# We can also define a different order of transitions
machine = Machine ( states = states , initial = 'A' )
machine . add_ordered_transitions ([ 'A' , 'C' , 'B' ])
machine . next_state ()
print ( machine . state )
> >> 'C'
# Conditions can be passed to 'add_ordered_transitions' as well
# If one condition is passed, it will be used for all transitions
machine = Machine ( states = states , initial = 'A' )
machine . add_ordered_transitions ( conditions = 'check' )
# If a list is passed, it must contain exactly as many elements as the
# machine contains states (A->B, ..., X->A)
machine = Machine ( states = states , initial = 'A' )
machine . add_ordered_transitions ( conditions = [ 'check_A2B' , ..., 'check_X2A' ])
# Conditions are always applied starting from the initial state
machine = Machine ( states = states , initial = 'B' )
machine . add_ordered_transitions ( conditions = [ 'check_B2C' , ..., 'check_A2B' ])
# With `loop=False`, the transition from the last state to the first state will be omitted (e.g. C->A)
# When you also pass conditions, you need to pass one condition less (len(states)-1)
machine = Machine ( states = states , initial = 'A' )
machine . add_ordered_transitions ( loop = False )
machine . next_state ()
machine . next_state ()
machine . next_state () # transitions.core.MachineError: "Can't trigger event next_state from state C!" 转换中的默认行为是立即处理事件。这意味着on_enter方法中的事件将在调用绑定到after回调之前处理。
def go_to_C ():
global machine
machine . to_C ()
def after_advance ():
print ( "I am in state B now!" )
def entering_C ():
print ( "I am in state C now!" )
states = [ 'A' , 'B' , 'C' ]
machine = Machine ( states = states , initial = 'A' )
# we want a message when state transition to B has been completed
machine . add_transition ( 'advance' , 'A' , 'B' , after = after_advance )
# call transition from state B to state C
machine . on_enter_B ( go_to_C )
# we also want a message when entering state C
machine . on_enter_C ( entering_C )
machine . advance ()
> >> 'I am in state C now!'
> >> 'I am in state B now!' # what?本例的执行顺序为
prepare -> before -> on_enter_B -> on_enter_C -> after.
如果启用排队处理,则转换将在触发下一个转换之前完成:
machine = Machine ( states = states , queued = True , initial = 'A' )
...
machine . advance ()
> >> 'I am in state B now!'
> >> 'I am in state C now!' # That's better!这导致
prepare -> before -> on_enter_B -> queue(to_C) -> after -> on_enter_C.
重要提示:在处理队列中的事件时,触发器调用将始终返回True ,因为无法在排队时确定涉及排队调用的转换最终是否会成功完成。即使仅处理单个事件也是如此。
machine . add_transition ( 'jump' , 'A' , 'C' , conditions = 'will_fail' )
...
# queued=False
machine . jump ()
> >> False
# queued=True
machine . jump ()
> >> True当模型从机器中删除时, transitions也会从队列中删除所有相关事件。
class Model :
def on_enter_B ( self ):
self . to_C () # add event to queue ...
self . machine . remove_model ( self ) # aaaand it's gone 有时,您只希望在发生特定条件时执行特定转换。您可以通过在conditions参数中传递一个方法或方法列表来完成此操作:
# Our Matter class, now with a bunch of methods that return booleans.
class Matter ( object ):
def is_flammable ( self ): return False
def is_really_hot ( self ): return True
machine . add_transition ( 'heat' , 'solid' , 'gas' , conditions = 'is_flammable' )
machine . add_transition ( 'heat' , 'solid' , 'liquid' , conditions = [ 'is_really_hot' ])在上面的示例中,如果is_flammable返回True ,当模型处于'solid'状态时调用heat()将转换为'gas'状态。否则,如果is_really_hot返回True它将转换为状态'liquid' 。
为了方便起见,还有一个'unless'参数,其行为与条件完全相同,但相反:
machine . add_transition ( 'heat' , 'solid' , 'gas' , unless = [ 'is_flammable' , 'is_really_hot' ])在这种情况下,只要is_flammable()和is_really_hot()返回False ,只要heat()触发,模型就会从固体转变为气体。
请注意,条件检查方法将被动接收传递给触发方法的可选参数和/或数据对象。例如,以下调用:
lump . heat ( temp = 74 )
# equivalent to lump.trigger('heat', temp=74) ...会将temp=74可选 kwarg 传递给is_flammable()检查(可能包装在EventData实例中)。有关这方面的更多信息,请参阅下面的传递数据部分。
如果您想在继续之前确保转换是可能的,您可以使用已添加到模型中的may_<trigger_name>函数。您的模型还包含may_trigger函数来按名称检查触发器:
# check if the current temperature is hot enough to trigger a transition
if lump . may_heat ():
# if lump.may_trigger("heat"):
lump . heat ()这将执行所有prepare回调并评估分配给潜在转换的条件。当转换的目的地尚不可用时,也可以使用转换检查:
machine . add_transition ( 'elevate' , 'solid' , 'spiritual' )
assert not lump . may_elevate () # not ready yet :(
assert not lump . may_trigger ( "elevate" ) # same result for checks via trigger name 您可以将回调附加到转换和状态。每个转换都有'before'和'after'属性,其中包含在转换执行之前和之后调用的方法列表:
class Matter ( object ):
def make_hissing_noises ( self ): print ( "HISSSSSSSSSSSSSSSS" )
def disappear ( self ): print ( "where'd all the liquid go?" )
transitions = [
{ 'trigger' : 'melt' , 'source' : 'solid' , 'dest' : 'liquid' , 'before' : 'make_hissing_noises' },
{ 'trigger' : 'evaporate' , 'source' : 'liquid' , 'dest' : 'gas' , 'after' : 'disappear' }
]
lump = Matter ()
machine = Machine ( lump , states , transitions = transitions , initial = 'solid' )
lump . melt ()
> >> "HISSSSSSSSSSSSSSSS"
lump . evaporate ()
> >> "where'd all the liquid go?"还有一个'prepare'回调,在检查任何'conditions'或执行其他回调之前,转换开始后立即执行。
class Matter ( object ):
heat = False
attempts = 0
def count_attempts ( self ): self . attempts += 1
def heat_up ( self ): self . heat = random . random () < 0.25
def stats ( self ): print ( 'It took you %i attempts to melt the lump!' % self . attempts )
@ property
def is_really_hot ( self ):
return self . heat
states = [ 'solid' , 'liquid' , 'gas' , 'plasma' ]
transitions = [
{ 'trigger' : 'melt' , 'source' : 'solid' , 'dest' : 'liquid' , 'prepare' : [ 'heat_up' , 'count_attempts' ], 'conditions' : 'is_really_hot' , 'after' : 'stats' },
]
lump = Matter ()
machine = Machine ( lump , states , transitions = transitions , initial = 'solid' )
lump . melt ()
lump . melt ()
lump . melt ()
lump . melt ()
> >> "It took you 4 attempts to melt the lump!"请注意,除非当前状态是指定转换的有效源,否则不会调用prepare 。
在初始化期间,可以分别使用before_state_change和after_state_change将要在每次转换之前或之后执行的默认操作传递给Machine :
class Matter ( object ):
def make_hissing_noises ( self ): print ( "HISSSSSSSSSSSSSSSS" )
def disappear ( self ): print ( "where'd all the liquid go?" )
states = [ 'solid' , 'liquid' , 'gas' , 'plasma' ]
lump = Matter ()
m = Machine ( lump , states , before_state_change = 'make_hissing_noises' , after_state_change = 'disappear' )
lump . to_gas ()
> >> "HISSSSSSSSSSSSSSSS"
> >> "where'd all the liquid go?"回调还有两个关键字,它们应该独立执行:a) 可能有多少个转换,b) 是否有任何转换成功,c) 即使在执行其他回调期间引发错误。使用prepare_event传递给Machine回调将在处理可能的转换(及其各自的prepare回调)发生之前执行一次。无论处理的转换是否成功,都会执行finalize_event的回调。请注意,如果发生错误,它将作为error附加到event_data并可以使用send_event=True进行检索。
from transitions import Machine
class Matter ( object ):
def raise_error ( self , event ): raise ValueError ( "Oh no" )
def prepare ( self , event ): print ( "I am ready!" )
def finalize ( self , event ): print ( "Result: " , type ( event . error ), event . error )
states = [ 'solid' , 'liquid' , 'gas' , 'plasma' ]
lump = Matter ()
m = Machine ( lump , states , prepare_event = 'prepare' , before_state_change = 'raise_error' ,
finalize_event = 'finalize' , send_event = True )
try :
lump . to_gas ()
except ValueError :
pass
print ( lump . state )
# >>> I am ready!
# >>> Result: <class 'ValueError'> Oh no
# >>> initial有时事情并没有按预期进行,我们需要处理异常并清理混乱以使事情继续进行。我们可以将回调传递给on_exception来执行此操作:
from transitions import Machine
class Matter ( object ):
def raise_error ( self , event ): raise ValueError ( "Oh no" )
def handle_error ( self , event ):
print ( "Fixing things ..." )
del event . error # it did not happen if we cannot see it ...
states = [ 'solid' , 'liquid' , 'gas' , 'plasma' ]
lump = Matter ()
m = Machine ( lump , states , before_state_change = 'raise_error' , on_exception = 'handle_error' , send_event = True )
try :
lump . to_gas ()
except ValueError :
pass
print ( lump . state )
# >>> Fixing things ...
# >>> initial您可能已经意识到,将可调用对象传递给状态、条件和转换的标准方法是通过名称。当处理回调和条件时, transitions将使用它们的名称从模型中检索相关的可调用对象。如果无法检索该方法并且它包含点, transitions将将该名称视为模块函数的路径并尝试导入它。或者,您可以传递属性或属性的名称。它们将被包装到函数中,但由于明显的原因而无法接收事件数据。您还可以直接传递可调用对象,例如(绑定)函数。如前所述,您还可以将可调用名称的列表/元组传递给回调参数。回调将按照添加的顺序执行。
from transitions import Machine
from mod import imported_func
import random
class Model ( object ):
def a_callback ( self ):
imported_func ()
@ property
def a_property ( self ):
""" Basically a coin toss. """
return random . random () < 0.5
an_attribute = False
model = Model ()
machine = Machine ( model = model , states = [ 'A' ], initial = 'A' )
machine . add_transition ( 'by_name' , 'A' , 'A' , conditions = 'a_property' , after = 'a_callback' )
machine . add_transition ( 'by_reference' , 'A' , 'A' , unless = [ 'a_property' , 'an_attribute' ], after = model . a_callback )
machine . add_transition ( 'imported' , 'A' , 'A' , after = 'mod.imported_func' )
model . by_name ()
model . by_reference ()
model . imported ()可调用解析在Machine.resolve_callable中完成。如果需要更复杂的可调用解析策略,可以重写此方法。
例子
class CustomMachine ( Machine ):
@ staticmethod
def resolve_callable ( func , event_data ):
# manipulate arguments here and return func, or super() if no manipulation is done.
super ( CustomMachine , CustomMachine ). resolve_callable ( func , event_data )总结一下,目前触发事件的方式有3种。您可以调用模型的便捷函数,例如lump.melt() ,按名称执行触发器,例如lump.trigger("melt")或者使用machine.dispatch("melt")在多个模型上调度事件(请参阅中有关多个模型的部分)替代初始化模式)。然后按以下顺序执行转换回调:
| 打回来 | 当前状态 | 评论 |
|---|---|---|
'machine.prepare_event' | source | 在处理各个转换之前执行一次 |
'transition.prepare' | source | 转换开始后立即执行 |
'transition.conditions' | source | 条件可能会失败并停止转换 |
'transition.unless' | source | 条件可能会失败并停止转换 |
'machine.before_state_change' | source | 在模型上声明的默认回调 |
'transition.before' | source | |
'state.on_exit' | source | 在源状态上声明的回调 |
<STATE CHANGE> | ||
'state.on_enter' | destination | 在目标状态上声明的回调 |
'transition.after' | destination | |
'machine.on_final' | destination | 将首先调用子级的回调 |
'machine.after_state_change' | destination | 在模型上声明的默认回调;内部转换后也会被调用 |
'machine.on_exception' | source/destination | 引发异常时将执行回调 |
'machine.finalize_event' | source/destination | 即使没有发生转换或引发异常,回调也会被执行 |
如果任何回调引发异常,则不会继续处理回调。这意味着当在转换之前(在state.on_exit或更早)发生错误时,它会停止。如果在进行转换后(在state.on_enter或更高版本中)出现提升,则状态更改将持续存在并且不会发生回滚。在machine.finalize_event中指定的回调将始终被执行,除非异常是由终结回调本身引发的。请注意,每个回调序列必须在执行下一阶段之前完成。阻止回调将停止执行顺序,从而阻止trigger或dispatch调用本身。如果您希望并行执行回调,您可以查看用于异步处理的扩展AsyncMachine或用于线程的LockedMachine 。
有时您需要向机器初始化时注册的回调函数传递一些反映模型当前状态的数据。过渡允许您以两种不同的方式执行此操作。
首先(默认),您可以将任何位置或关键字参数直接传递给触发器方法(在调用add_transition()时创建):
class Matter ( object ):
def __init__ ( self ): self . set_environment ()
def set_environment ( self , temp = 0 , pressure = 101.325 ):
self . temp = temp
self . pressure = pressure
def print_temperature ( self ): print ( "Current temperature is %d degrees celsius." % self . temp )
def print_pressure ( self ): print ( "Current pressure is %.2f kPa." % self . pressure )
lump = Matter ()
machine = Machine ( lump , [ 'solid' , 'liquid' ], initial = 'solid' )
machine . add_transition ( 'melt' , 'solid' , 'liquid' , before = 'set_environment' )
lump . melt ( 45 ) # positional arg;
# equivalent to lump.trigger('melt', 45)
lump . print_temperature ()
> >> 'Current temperature is 45 degrees celsius.'
machine . set_state ( 'solid' ) # reset state so we can melt again
lump . melt ( pressure = 300.23 ) # keyword args also work
lump . print_pressure ()
> >> 'Current pressure is 300.23 kPa.'您可以将任意数量的参数传递给触发器。
这种方法有一个重要的限制:状态转换触发的每个回调函数都必须能够处理所有参数。如果每个回调期望的数据有所不同,这可能会导致问题。
为了解决这个问题,Transitions 支持另一种发送数据的方法。如果您在Machine初始化时设置send_event=True ,则触发器的所有参数都将包装在EventData实例中并传递给每个回调。 ( EventData对象还维护对与事件关联的源状态、模型、转换、机器和触发器的内部引用,以防您需要访问这些内容。)
class Matter ( object ):
def __init__ ( self ):
self . temp = 0
self . pressure = 101.325
# Note that the sole argument is now the EventData instance.
# This object stores positional arguments passed to the trigger method in the
# .args property, and stores keywords arguments in the .kwargs dictionary.
def set_environment ( self , event ):
self . temp = event . kwargs . get ( 'temp' , 0 )
self . pressure = event . kwargs . get ( 'pressure' , 101.325 )
def print_pressure ( self ): print ( "Current pressure is %.2f kPa." % self . pressure )
lump = Matter ()
machine = Machine ( lump , [ 'solid' , 'liquid' ], send_event = True , initial = 'solid' )
machine . add_transition ( 'melt' , 'solid' , 'liquid' , before = 'set_environment' )
lump . melt ( temp = 45 , pressure = 1853.68 ) # keyword args
lump . print_pressure ()
> >> 'Current pressure is 1853.68 kPa.'在到目前为止的所有示例中,我们已将一个新的Machine实例附加到一个单独的模型( lump , Matter类的实例)。虽然这种分离使事情保持整洁(因为您不必将一大堆新方法修补到Matter类中),但它也可能会变得烦人,因为它需要您跟踪在状态机上调用了哪些方法,以及在状态机绑定到的模型上调用哪些函数(例如, lump.on_enter_StateA()与machine.add_transition() )。
幸运的是,Transitions 很灵活,并且支持另外两种初始化模式。
首先,您可以创建一个根本不需要其他模型的独立状态机。只需在初始化期间省略模型参数即可:
machine = Machine ( states = states , transitions = transitions , initial = 'solid' )
machine . melt ()
machine . state
> >> 'liquid'如果您以这种方式初始化机器,则可以将所有触发事件(如evaporate() , sublimate()等)和所有回调函数直接附加到Machine实例。
这种方法的优点是可以将所有状态机功能整合到一个地方,但如果您认为状态逻辑应该包含在模型本身而不是单独的控制器中,可能会感觉有点不自然。
另一种(可能更好)的方法是让模型继承Machine类。 Transitions 旨在支持无缝继承。 (只要确保覆盖类Machine的__init__方法!):
class Matter ( Machine ):
def say_hello ( self ): print ( "hello, new state!" )
def say_goodbye ( self ): print ( "goodbye, old state!" )
def __init__ ( self ):
states = [ 'solid' , 'liquid' , 'gas' ]
Machine . __init__ ( self , states = states , initial = 'solid' )
self . add_transition ( 'melt' , 'solid' , 'liquid' )
lump = Matter ()
lump . state
> >> 'solid'
lump . melt ()
lump . state
> >> 'liquid'在这里,您可以将所有状态机功能整合到现有模型中,这通常比将我们想要的所有功能都放在单独的独立Machine实例中更自然。
一台机器可以处理多个模型,这些模型可以作为列表传递,如Machine(model=[model1, model2, ...]) 。如果您想要添加模型以及机器实例本身,您可以在初始化期间传递类变量占位符(字符串) Machine.self_literal例如Machine(model=[Machine.self_literal, model1, ...]) 。您还可以创建一个独立的机器,并通过machine.add_model通过将model=None传递给构造函数来动态注册模型。此外,您可以使用machine.dispatch来触发所有当前添加的模型上的事件。如果机器是持久的并且您的模型是临时的并且应该被垃圾收集,请记住调用machine.remove_model :
class Matter ():
pass
lump1 = Matter ()
lump2 = Matter ()
# setting 'model' to None or passing an empty list will initialize the machine without a model
machine = Machine ( model = None , states = states , transitions = transitions , initial = 'solid' )
machine . add_model ( lump1 )
machine . add_model ( lump2 , initial = 'liquid' )
lump1 . state
> >> 'solid'
lump2 . state
> >> 'liquid'
# custom events as well as auto transitions can be dispatched to all models
machine . dispatch ( "to_plasma" )
lump1 . state
> >> 'plasma'
assert lump1 . state == lump2 . state
machine . remove_model ([ lump1 , lump2 ])
del lump1 # lump1 is garbage collected
del lump2 # lump2 is garbage collected如果您没有在状态机构造函数中提供初始状态, transitions将创建并添加一个名为'initial'默认状态。如果您不想要默认的初始状态,可以传递initial=None 。但是,在这种情况下,每次添加模型时都需要传递初始状态。
machine = Machine ( model = None , states = states , transitions = transitions , initial = None )
machine . add_model ( Matter ())
> >> "MachineError: No initial state configured for machine, must specify when adding model."
machine . add_model ( Matter (), initial = 'liquid' )具有多个状态的模型可以使用不同的model_attribute值连接多台机器。如检查状态中所述,这将添加自定义is/to_<model_attribute>_<state_name>函数:
lump = Matter ()
matter_machine = Machine ( lump , states = [ 'solid' , 'liquid' , 'gas' ], initial = 'solid' )
# add a second machine to the same model but assign a different state attribute
shipment_machine = Machine ( lump , states = [ 'delivered' , 'shipping' ], initial = 'delivered' , model_attribute = 'shipping_state' )
lump . state
> >> 'solid'
lump . is_solid () # check the default field
> >> True
lump . shipping_state
> >> 'delivered'
lump . is_shipping_state_delivered () # check the custom field.
> >> True
lump . to_shipping_state_shipping ()
> >> True
lump . is_shipping_state_delivered ()
> >> False转换包括非常基本的日志记录功能。许多事件(即状态更改、转换触发器和条件检查)均使用标准 Python logging模块记录为 INFO 级事件。这意味着您可以轻松地将日志记录配置为脚本中的标准输出:
# Set up logging; The basic log level will be DEBUG
import logging
logging . basicConfig ( level = logging . DEBUG )
# Set transitions' log level to INFO; DEBUG messages will be omitted
logging . getLogger ( 'transitions' ). setLevel ( logging . INFO )
# Business as usual
machine = Machine ( states = states , transitions = transitions , initial = 'solid' )
...机器是可腌制的,可以储存和装载pickle 。对于 Python 3.3 及更早版本,需要dill 。
import dill as pickle # only required for Python 3.3 and earlier
m = Machine ( states = [ 'A' , 'B' , 'C' ], initial = 'A' )
m . to_B ()
m . state
> >> B
# store the machine
dump = pickle . dumps ( m )
# load the Machine instance again
m2 = pickle . loads ( dump )
m2 . state
> >> B
m2 . states . keys ()
> >> [ 'A' , 'B' , 'C' ]您可能已经注意到, transitions使用 Python 的一些动态功能为您提供处理模型的便捷方法。然而,静态类型检查器不喜欢在运行时之前不知道模型属性和方法。从历史上看, transitions也没有分配模型上已定义的便捷方法以防止意外覆盖。
但别担心!您可以使用机器构造函数参数model_override来更改模型的装饰方式。如果设置model_override=True , transitions将仅覆盖已定义的方法。这可以防止新方法在运行时出现,并且还允许您定义要使用的辅助方法。
from transitions import Machine
# Dynamic assignment
class Model :
pass
model = Model ()
default_machine = Machine ( model , states = [ "A" , "B" ], transitions = [[ "go" , "A" , "B" ]], initial = "A" )
print ( model . __dict__ . keys ()) # all convenience functions have been assigned
# >> dict_keys(['trigger', 'to_A', 'may_to_A', 'to_B', 'may_to_B', 'go', 'may_go', 'is_A', 'is_B', 'state'])
assert model . is_A () # Unresolved attribute reference 'is_A' for class 'Model'
# Predefined assigment: We are just interested in calling our 'go' event and will trigger the other events by name
class PredefinedModel :
# state (or another parameter if you set 'model_attribute') will be assigned anyway
# because we need to keep track of the model's state
state : str
def go ( self ) -> bool :
raise RuntimeError ( "Should be overridden!" )
def trigger ( self , trigger_name : str ) -> bool :
raise RuntimeError ( "Should be overridden!" )
model = PredefinedModel ()
override_machine = Machine ( model , states = [ "A" , "B" ], transitions = [[ "go" , "A" , "B" ]], initial = "A" , model_override = True )
print ( model . __dict__ . keys ())
# >> dict_keys(['trigger', 'go', 'state'])
model . trigger ( "to_B" )
assert model . state == "B"如果您想使用所有便利函数并添加一些回调,那么当您定义了很多状态和转换时,定义模型可能会变得非常复杂。 transitions中的generate_base_model方法可以从机器配置生成基本模型来帮助您解决这个问题。
from transitions . experimental . utils import generate_base_model
simple_config = {
"states" : [ "A" , "B" ],
"transitions" : [
[ "go" , "A" , "B" ],
],
"initial" : "A" ,
"before_state_change" : "call_this" ,
"model_override" : True ,
}
class_definition = generate_base_model ( simple_config )
with open ( "base_model.py" , "w" ) as f :
f . write ( class_definition )
# ... in another file
from transitions import Machine
from base_model import BaseModel
class Model ( BaseModel ): # call_this will be an abstract method in BaseModel
def call_this ( self ) -> None :
# do something
model = Model ()
machine = Machine ( model , ** simple_config )定义将被覆盖的模型方法会增加一些额外的工作。来回切换以确保事件名称拼写正确可能很麻烦,特别是如果状态和转换是在模型之前或之后的列表中定义的。您可以通过将状态定义为枚举来减少样板文件和使用字符串的不确定性。您还可以借助add_transitions和event直接在模型类中定义转换。您可以选择使用函数装饰器add_transitions还是事件来为属性赋值,具体取决于您喜欢的代码风格。它们的工作方式相同,具有相同的签名,并且应该产生(几乎)相同的 IDE 类型提示。由于这仍在进行中,您需要创建一个自定义 Machine 类并使用 with_model_definitions 进行转换来检查以这种方式定义的转换。
from enum import Enum
from transitions . experimental . utils import with_model_definitions , event , add_transitions , transition
from transitions import Machine
class State ( Enum ):
A = "A"
B = "B"
C = "C"
class Model :
state : State = State . A
@ add_transitions ( transition ( source = State . A , dest = State . B ), [ State . C , State . A ])
@ add_transitions ({ "source" : State . B , "dest" : State . A })
def foo ( self ): ...
bar = event (
{ "source" : State . B , "dest" : State . A , "conditions" : lambda : False },
transition ( source = State . B , dest = State . C )
)
@ with_model_definitions # don't forget to define your model with this decorator!
class MyMachine ( Machine ):
pass
model = Model ()
machine = MyMachine ( model , states = State , initial = model . state )
model . foo ()
model . bar ()
assert model . state == State . C
model . foo ()
assert model . state == State . A尽管过渡的核心保持轻量级,但仍有各种 MixIn 来扩展其功能。目前支持的有:
有两种机制可以检索启用了所需功能的状态机实例。第一种方法利用便利factory如果需要该功能,则将四个参数graph 、 nested 、 locked或asyncio设置为True :
from transitions . extensions import MachineFactory
# create a machine with mixins
diagram_cls = MachineFactory . get_predefined ( graph = True )
nested_locked_cls = MachineFactory . get_predefined ( nested = True , locked = True )
async_machine_cls = MachineFactory . get_predefined ( asyncio = True )
# create instances from these classes
# instances can be used like simple machines
machine1 = diagram_cls ( model , state , transitions )
machine2 = nested_locked_cls ( model , state , transitions )这种方法的目标是实验性使用,因为在这种情况下,底层类不必知道。然而,类也可以直接从transitions.extensions导入。命名方案如下:
| 图表 | 嵌套 | 锁定 | 异步 | |
|---|---|---|---|---|
| 机器 | ✘ | ✘ | ✘ | ✘ |
| 图机 | ✓ | ✘ | ✘ | ✘ |
| 层次机 | ✘ | ✓ | ✘ | ✘ |
| 锁机 | ✘ | ✘ | ✓ | ✘ |
| 层次图机 | ✓ | ✓ | ✘ | ✘ |
| 锁定图机 | ✓ | ✘ | ✓ | ✘ |
| 锁定分层机 | ✘ | ✓ | ✓ | ✘ |
| 锁定层次图机 | ✓ | ✓ | ✓ | ✘ |
| 异步机 | ✘ | ✘ | ✘ | ✓ |
| 异步图机 | ✓ | ✘ | ✘ | ✓ |
| 分层异步机 | ✘ | ✓ | ✘ | ✓ |
| 分层异步图机 | ✓ | ✓ | ✘ | ✓ |
要使用功能丰富的状态机,可以编写:
from transitions . extensions import LockedHierarchicalGraphMachine as LHGMachine
machine = LHGMachine ( model , states , transitions )转换包括一个允许嵌套状态的扩展模块。这使我们能够创建上下文并对状态与状态机中的某些子任务相关的情况进行建模。要创建嵌套状态,请从转换导入NestedState或使用带有初始化参数name和children字典。或者, initial可以用于定义进入嵌套状态时要转换到的子状态。
from transitions . extensions import HierarchicalMachine
states = [ 'standing' , 'walking' , { 'name' : 'caffeinated' , 'children' :[ 'dithering' , 'running' ]}]
transitions = [
[ 'walk' , 'standing' , 'walking' ],
[ 'stop' , 'walking' , 'standing' ],
[ 'drink' , '*' , 'caffeinated' ],
[ 'walk' , [ 'caffeinated' , 'caffeinated_dithering' ], 'caffeinated_running' ],
[ 'relax' , 'caffeinated' , 'standing' ]
]
machine = HierarchicalMachine ( states = states , transitions = transitions , initial = 'standing' , ignore_invalid_triggers = True )
machine . walk () # Walking now
machine . stop () # let's stop for a moment
machine . drink () # coffee time
machine . state
> >> 'caffeinated'
machine . walk () # we have to go faster
machine . state
> >> 'caffeinated_running'
machine . stop () # can't stop moving!
machine . state
> >> 'caffeinated_running'
machine . relax () # leave nested state
machine . state # phew, what a ride
> >> 'standing'
# machine.on_enter_caffeinated_running('callback_method')使用initial的配置可能如下所示:
# ...
states = [ 'standing' , 'walking' , { 'name' : 'caffeinated' , 'initial' : 'dithering' , 'children' : [ 'dithering' , 'running' ]}]
transitions = [
[ 'walk' , 'standing' , 'walking' ],
[ 'stop' , 'walking' , 'standing' ],
# this transition will end in 'caffeinated_dithering'...
[ 'drink' , '*' , 'caffeinated' ],
# ... that is why we do not need do specify 'caffeinated' here anymore
[ 'walk' , 'caffeinated_dithering' , 'caffeinated_running' ],
[ 'relax' , 'caffeinated' , 'standing' ]
]
# ... HierarchicalMachine构造函数的initial关键字接受嵌套状态(例如initial='caffeinated_running' )和被视为并行状态的状态列表(例如initial=['A', 'B'] )或当前状态另一个模型( initial=model.state )实际上应该是前面提到的选项之一。请注意,传递字符串时, transition将检查initial子状态的目标状态并将其用作入口状态。这将递归地完成,直到子状态不提及初始状态。并行状态或作为列表传递的状态将“按原样”使用,并且不会进行进一步的初始评估。
请注意,您之前创建的状态对象必须是NestedState或其派生类。简单Machine实例中使用的标准State类缺乏嵌套所需的功能。
from transitions . extensions . nesting import HierarchicalMachine , NestedState
from transitions import State
m = HierarchicalMachine ( states = [ 'A' ], initial = 'initial' )
m . add_state ( 'B' ) # fine
m . add_state ({ 'name' : 'C' }) # also fine
m . add_state ( NestedState ( 'D' )) # fine as well
m . add_state ( State ( 'E' )) # does not work!使用嵌套状态时必须考虑的一些事项: 状态名称与NestedState.separator连接。当前分隔符设置为下划线('_'),因此其行为与基本机器类似。这意味着foo_bar将知道状态foo的子状态bar 。 bar的子状态baz将被称为foo_bar_baz等等。当进入子状态时,所有父状态都会调用enter 。对于退出子状态也是如此。第三,嵌套状态可以覆盖其父级的转换行为。如果当前状态未知转换,则会将其委托给其父级。
这意味着在标准配置中,HSM 中的状态名称不得包含下划线。对于transitions ,无法判断machine.add_state('state_name')是否应该添加名为state_name的状态或向状态state添加子状态name 。然而,在某些情况下,这还不够。例如,如果状态名称由多个单词组成,并且您希望/需要使用下划线而不是CamelCase来分隔它们。为了解决这个问题,您可以很容易地更改用于分隔的字符。如果您使用 Python 3,您甚至可以使用奇特的 unicode 字符。将分隔符设置为下划线以外的其他字符会改变一些行为(自动转换和设置回调):
from transitions . extensions import HierarchicalMachine
from transitions . extensions . nesting import NestedState
NestedState . separator = '↦'
states = [ 'A' , 'B' ,
{ 'name' : 'C' , 'children' :[ '1' , '2' ,
{ 'name' : '3' , 'children' : [ 'a' , 'b' , 'c' ]}
]}
]
transitions = [
[ 'reset' , 'C' , 'A' ],
[ 'reset' , 'C↦2' , 'C' ] # overwriting parent reset
]
# we rely on auto transitions
machine = HierarchicalMachine ( states = states , transitions = transitions , initial = 'A' )
machine . to_B () # exit state A, enter state B
machine . to_C () # exit B, enter C
machine . to_C . s3 . a () # enter C↦a; enter C↦3↦a;
machine . state
> >> 'C↦3↦a'
assert machine . is_C . s3 . a ()
machine . to ( 'C↦2' ) # not interactive; exit C↦3↦a, exit C↦3, enter C↦2
machine . reset () # exit C↦2; reset C has been overwritten by C↦3
machine . state
> >> 'C'
machine . reset () # exit C, enter A
machine . state
> >> 'A'
# s.on_enter('C↦3↦a', 'callback_method')自动转换称为to_C_3_a()而不是 to_C_3_a to_C.s3.a() 。如果您的子状态以数字开头,则转换会向自动转换FunctionWrapper添加前缀“s”(“3”变为“s3”),以符合 Python 的属性命名方案。如果不需要交互式补全,可以直接调用to('C↦3↦a') 。此外, on_enter/exit_<<state name>>替换为on_enter/exit(state_name, callback) 。状态检查可以以类似的方式进行。可以使用FunctionWrapper变体is_C.s3.a()代替is_C_3_a() 。
要检查当前状态是否是特定状态的子状态, is_state支持关键字allow_substates :
machine . state
> >> 'C.2.a'
machine . is_C () # checks for specific states
> >> False
machine . is_C ( allow_substates = True )
> >> True
assert machine . is_C . s2 () is False
assert machine . is_C . s2 ( allow_substates = True ) # FunctionWrapper support allow_substate as well您也可以在 HSM 中使用枚举,但请记住, Enum是按值进行比较的。如果状态树中的值多次出现,则无法区分这些状态。
states = [ States . RED , States . YELLOW , { 'name' : States . GREEN , 'children' : [ 'tick' , 'tock' ]}]
states = [ 'A' , { 'name' : 'B' , 'children' : states , 'initial' : States . GREEN }, States . GREEN ]
machine = HierarchicalMachine ( states = states )
machine . to_B ()
machine . is_GREEN () # returns True even though the actual state is B_GREEN HierarchicalMachine已从头开始重写,以支持并行状态和更好的嵌套状态隔离。这涉及根据社区反馈进行一些调整。要了解处理顺序和配置,请查看以下示例:
from transitions . extensions . nesting import HierarchicalMachine
import logging
states = [ 'A' , 'B' , { 'name' : 'C' , 'parallel' : [{ 'name' : '1' , 'children' : [ 'a' , 'b' , 'c' ], 'initial' : 'a' ,
'transitions' : [[ 'go' , 'a' , 'b' ]]},
{ 'name' : '2' , 'children' : [ 'x' , 'y' , 'z' ], 'initial' : 'z' }],
'transitions' : [[ 'go' , '2_z' , '2_x' ]]}]
transitions = [[ 'reset' , 'C_1_b' , 'B' ]]
logging . basicConfig ( level = logging . INFO )
machine = HierarchicalMachine ( states = states , transitions = transitions , initial = 'A' )
machine . to_C ()
# INFO:transitions.extensions.nesting:Exited state A
# INFO:transitions.extensions.nesting:Entered state C
# INFO:transitions.extensions.nesting:Entered state C_1
# INFO:transitions.extensions.nesting:Entered state C_2
# INFO:transitions.extensions.nesting:Entered state C_1_a
# INFO:transitions.extensions.nesting:Entered state C_2_z
machine . go ()
# INFO:transitions.extensions.nesting:Exited state C_1_a
# INFO:transitions.extensions.nesting:Entered state C_1_b
# INFO:transitions.extensions.nesting:Exited state C_2_z
# INFO:transitions.extensions.nesting:Entered state C_2_x
machine . reset ()
# INFO:transitions.extensions.nesting:Exited state C_1_b
# INFO:transitions.extensions.nesting:Exited state C_2_x
# INFO:transitions.extensions.nesting:Exited state C_1
# INFO:transitions.extensions.nesting:Exited state C_2
# INFO:transitions.extensions.nesting:Exited state C
# INFO:transitions.extensions.nesting:Entered state B当使用parallel而不是children时, transitions将同时进入传递列表的所有状态。要进入哪个子状态由initial定义,该初始值应始终指向直接子状态。一个新颖的功能是通过在状态定义中传递transitions关键字来定义局部转换。上面定义的转换['go', 'a', 'b']仅在C_1中有效。虽然您可以像['go', '2_z', '2_x']中那样引用子状态,但您不能在本地定义的转换中直接引用父状态。当父状态退出时,其子状态也将退出。除了Machine已知的转换处理顺序(其中转换按添加顺序考虑)之外, HierarchicalMachine还考虑层次结构。将首先评估子状态中定义的转换(例如, C_1_a位于C_2_z之前),并且使用通配符*定义的转换(目前)将仅将转换添加到根状态(在此示例中为A 、 B 、 C )从0.8.0嵌套状态开始可以直接添加,并将即时创建父状态:
m = HierarchicalMachine ( states = [ 'A' ], initial = 'A' )
m . add_state ( 'B_1_a' )
m . to_B_1 ()
assert m . is_B ( allow_substates = True ) 0.9.1 中的实验:您可以在状态中或 HSM 本身上使用on_final回调。如果 a) 状态本身被标记为final并且刚刚进入,或者 b) 所有子状态都被视为最终状态并且至少一个子状态刚刚进入最终状态,则将触发回调。在 b) 的情况下,如果条件 b) 成立,所有父母也将被视为最终决定。当处理并行发生并且当所有子状态都达到最终状态时应通知您的 HSM 或任何父状态时,这可能很有用:
from transitions . extensions import HierarchicalMachine
from functools import partial
# We initialize this parallel HSM in state A:
# / X
# / / yI
# A -> B - Y - yII [final]
# Z - zI
# zII [final]
def final_event_raised ( name ):
print ( "{} is final!" . format ( name ))
states = [ 'A' , { 'name' : 'B' , 'parallel' : [{ 'name' : 'X' , 'final' : True , 'on_final' : partial ( final_event_raised , 'X' )},
{ 'name' : 'Y' , 'transitions' : [[ 'final_Y' , 'yI' , 'yII' ]],
'initial' : 'yI' ,
'on_final' : partial ( final_event_raised , 'Y' ),
'states' :
[ 'yI' , { 'name' : 'yII' , 'final' : True }]
},
{ 'name' : 'Z' , 'transitions' : [[ 'final_Z' , 'zI' , 'zII' ]],
'initial' : 'zI' ,
'on_final' : partial ( final_event_raised , 'Z' ),
'states' :
[ 'zI' , { 'name' : 'zII' , 'final' : True }]
},
],
"on_final" : partial ( final_event_raised , 'B' )}]
machine = HierarchicalMachine ( states = states , on_final = partial ( final_event_raised , 'Machine' ), initial = 'A' )
# X will emit a final event right away
machine . to_B ()
# >>> X is final!
print ( machine . state )
# >>> ['B_X', 'B_Y_yI', 'B_Z_zI']
# Y's substate is final now and will trigger 'on_final' on Y
machine . final_Y ()
# >>> Y is final!
print ( machine . state )
# >>> ['B_X', 'B_Y_yII', 'B_Z_zI']
# Z's substate becomes final which also makes all children of B final and thus machine itself
machine . final_Z ()
# >>> Z is final!
# >>> B is final!
# >>> Machine is final! 除了语义顺序之外,如果您想为特定任务指定状态机并计划重用它们,嵌套状态也非常方便。在0.8.0之前, HierarchicalMachine不会集成机器实例本身,而是通过创建状态和转换的副本来集成它们。然而,由于0.8.0 (Nested)State实例只是被引用,这意味着一台机器的状态和事件集合的变化将影响另一台机器实例。但模型及其状态不会被共享。请注意,如果不使用remap关键字,事件和转换也会通过引用复制,并且将由两个实例共享。进行此更改是为了更符合Machine它也通过引用使用传递的State实例。
count_states = [ '1' , '2' , '3' , 'done' ]
count_trans = [
[ 'increase' , '1' , '2' ],
[ 'increase' , '2' , '3' ],
[ 'decrease' , '3' , '2' ],
[ 'decrease' , '2' , '1' ],
[ 'done' , '3' , 'done' ],
[ 'reset' , '*' , '1' ]
]
counter = HierarchicalMachine ( states = count_states , transitions = count_trans , initial = '1' )
counter . increase () # love my counter
states = [ 'waiting' , 'collecting' , { 'name' : 'counting' , 'children' : counter }]
transitions = [
[ 'collect' , '*' , 'collecting' ],
[ 'wait' , '*' , 'waiting' ],
[ 'count' , 'collecting' , 'counting' ]
]
collector = HierarchicalMachine ( states = states , transitions = transitions , initial = 'waiting' )
collector . collect () # collecting
collector . count () # let's see what we got; counting_1
collector . increase () # counting_2
collector . increase () # counting_3
collector . done () # collector.state == counting_done
collector . wait () # collector.state == waiting如果使用children关键字传递HierarchicalMachine ,则该机器的初始状态将分配给新的父状态。在上面的示例中,我们看到输入counting也会输入counting_1 。如果这是不期望的行为,并且机器应该在父状态下停止,则用户可以将initial传递为False例如{'name': 'counting', 'children': counter, 'initial': False} 。
有时您希望这样的嵌入状态集合“返回”,这意味着完成后它应该退出并转移到您的超级状态之一。要实现此行为,您可以重新映射状态转换。在上面的示例中,我们希望计数器在达到done状态时返回。这是按如下方式完成的:
states = [ 'waiting' , 'collecting' , { 'name' : 'counting' , 'children' : counter , 'remap' : { 'done' : 'waiting' }}]
... # same as above
collector . increase () # counting_3
collector . done ()
collector . state
> >> 'waiting' # be aware that 'counting_done' will be removed from the state machine如上所述,使用remap将复制事件和转换,因为它们在原始状态机中无效。如果重用的状态机没有最终状态,您当然可以手动添加转换。如果 'counter' 没有 'done' 状态,我们只需添加['done', 'counter_3', 'waiting']即可实现相同的行为。
如果您希望通过值而不是引用复制状态和转换(例如,如果您想保留 0.8 之前的行为),您可以通过创建NestedState并将机器事件和状态的深层副本分配给它。
from transitions . extensions . nesting import NestedState
from copy import deepcopy
# ... configuring and creating counter
counting_state = NestedState ( name = "counting" , initial = '1' )
counting_state . states = deepcopy ( counter . states )
counting_state . events = deepcopy ( counter . events )
states = [ 'waiting' , 'collecting' , counting_state ]对于复杂的状态机,共享配置而不是实例化机器可能更可行。特别是因为实例化的机器必须源自HierarchicalMachine 。此类配置可以通过 JSON 或 YAML 轻松存储和加载(请参阅常见问题解答)。 HierarchicalMachine允许使用关键字children或states定义子状态。如果两者都在场,则仅考虑children 。
counter_conf = {
'name' : 'counting' ,
'states' : [ '1' , '2' , '3' , 'done' ],
'transitions' : [
[ 'increase' , '1' , '2' ],
[ 'increase' , '2' , '3' ],
[ 'decrease' , '3' , '2' ],
[ 'decrease' , '2' , '1' ],
[ 'done' , '3' , 'done' ],
[ 'reset' , '*' , '1' ]
],
'initial' : '1'
}
collector_conf = {
'name' : 'collector' ,
'states' : [ 'waiting' , 'collecting' , counter_conf ],
'transitions' : [
[ 'collect' , '*' , 'collecting' ],
[ 'wait' , '*' , 'waiting' ],
[ 'count' , 'collecting' , 'counting' ]
],
'initial' : 'waiting'
}
collector = HierarchicalMachine ( ** collector_conf )
collector . collect ()
collector . count ()
collector . increase ()
assert collector . is_counting_2 ()其他关键词:
title (可选):设置生成图像的标题。show_conditions (默认 False):显示过渡边缘的条件show_auto_transitions (默认 False):在图中显示自动转换show_state_attributes (默认 False):在图表中显示回调(进入、退出)、标签和超时转换可以生成基本状态图,显示状态之间的所有有效转换。基本图表支持生成 mermaid 状态机定义,可与 mermaid 的实时编辑器、GitLab 或 GitHub 和其他 Web 服务中的 markdown 文件一起使用。例如,这段代码:
from transitions . extensions . diagrams import HierarchicalGraphMachine
import pyperclip
states = [ 'A' , 'B' , { 'name' : 'C' ,
'final' : True ,
'parallel' : [{ 'name' : '1' , 'children' : [ 'a' , { "name" : "b" , "final" : True }],
'initial' : 'a' ,
'transitions' : [[ 'go' , 'a' , 'b' ]]},
{ 'name' : '2' , 'children' : [ 'a' , { "name" : "b" , "final" : True }],
'initial' : 'a' ,
'transitions' : [[ 'go' , 'a' , 'b' ]]}]}]
transitions = [[ 'reset' , 'C' , 'A' ], [ "init" , "A" , "B" ], [ "do" , "B" , "C" ]]
m = HierarchicalGraphMachine ( states = states , transitions = transitions , initial = "A" , show_conditions = True ,
title = "Mermaid" , graph_engine = "mermaid" , auto_transitions = False )
m . init ()
pyperclip . copy ( m . get_graph (). draw ( None )) # using pyperclip for convenience
print ( "Graph copied to clipboard!" )生成此图(检查文档源以查看降价符号):
---
美人鱼图
---
状态图-v2
方向LR
classDef s_default 填充:白色,颜色:黑色
classDef s_inactive 填充:白色,颜色:黑色
classDef s_parallel 颜色:黑色,填充:白色
classDef s_active 颜色:红色,填充:深鲑鱼色
classDef s_previous 颜色:蓝色,填充:天蓝色
将“A”表述为 A
A 类 s_previous
将“B”表述为 B
B 类 s_active
将“C”表述为 C
C --> [*]
C 类 s_default
状态C{
将“1”声明为 C_1
状态 C_1 {
[*] --> C_1_a
将“a”表示为 C_1_a
将“b”状态为 C_1_b
C_1_b --> [*]
}
--
将“2”声明为 C_2
状态 C_2 {
[*] --> C_2_a
将“a”声明为 C_2_a
将“b”状态为 C_2_b
C_2_b --> [*]
}
}
C --> A:重置
A --> B: 初始化
B --> C: 做
C_1_a --> C_1_b: 去
C_2_a --> C_2_b: 去
[*] --> A
要使用更复杂的绘图功能,您需要安装graphviz和/或pygraphviz 。要使用包graphviz生成图形,您需要手动或通过软件包管理器安装GraphViz。
sudo apt-get install graphviz graphviz-dev # Ubuntu and Debian
brew install graphviz # MacOS
conda install graphviz python-graphviz # (Ana)conda
现在您可以安装实际的Python软件包
pip install graphviz pygraphviz # install graphviz and/or pygraphviz manually...
pip install transitions[diagrams] # ... or install transitions with 'diagrams' extras which currently depends on pygraphviz
当前, GraphMachine将在可用时使用pygraphviz ,并在找不到pygraphviz时落到graphviz 。如果graphviz也不可用,则将使用mermaid 。可以通过将graph_engine="graphviz" (或"mermaid" )传递给构造函数来覆盖这一点。请注意,此默认值可能会在将来发生变化,而pygraphviz支持可能会被删除。使用Model.get_graph()您可以获取当前图或感兴趣的区域(ROI)并以此为单位:
# import transitions
from transitions . extensions import GraphMachine
m = Model ()
# without further arguments pygraphviz will be used
machine = GraphMachine ( model = m , ...)
# when you want to use graphviz explicitly
machine = GraphMachine ( model = m , graph_engine = "graphviz" , ...)
# in cases where auto transitions should be visible
machine = GraphMachine ( model = m , show_auto_transitions = True , ...)
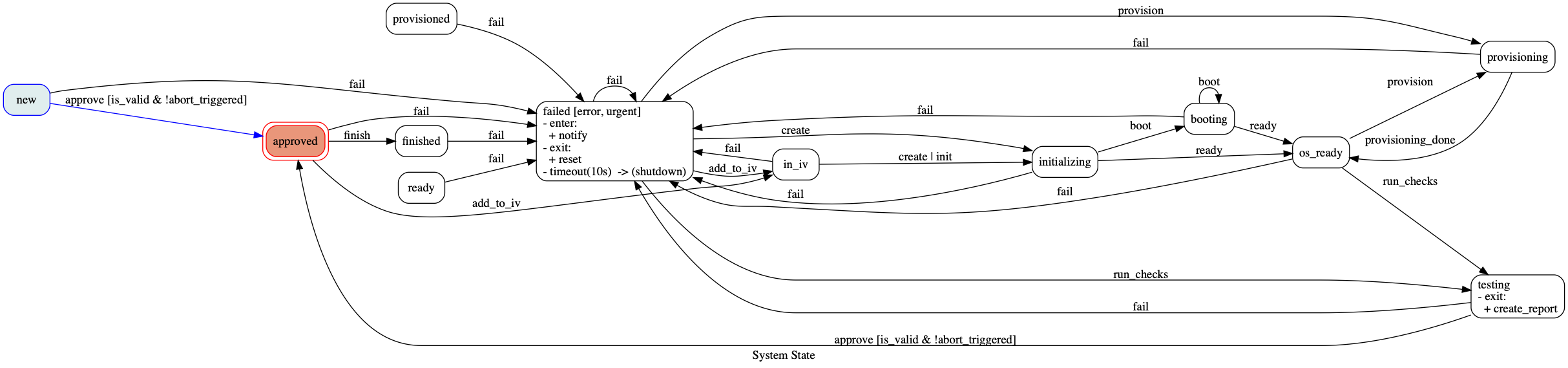
# draw the whole graph ...
m . get_graph (). draw ( 'my_state_diagram.png' , prog = 'dot' )
# ... or just the region of interest
# (previous state, active state and all reachable states)
roi = m . get_graph ( show_roi = True ). draw ( 'my_state_diagram.png' , prog = 'dot' )这会产生这样的东西:
独立于您使用的后端,绘制功能还接受文件描述符或二进制流作为第一个参数。如果将此参数设置为None ,则将返回字节流:
import io
with open ( 'a_graph.png' , 'bw' ) as f :
# you need to pass the format when you pass objects instead of filenames.
m . get_graph (). draw ( f , format = "png" , prog = 'dot' )
# you can pass a (binary) stream too
b = io . BytesIO ()
m . get_graph (). draw ( b , format = "png" , prog = 'dot' )
# or just handle the binary string yourself
result = m . get_graph (). draw ( None , format = "png" , prog = 'dot' )
assert result == b . getvalue ()通过以回调为单位的参考文献和部分将尽可能地解决:
from transitions . extensions import GraphMachine
from functools import partial
class Model :
def clear_state ( self , deep = False , force = False ):
print ( "Clearing state ..." )
return True
model = Model ()
machine = GraphMachine ( model = model , states = [ 'A' , 'B' , 'C' ],
transitions = [
{ 'trigger' : 'clear' , 'source' : 'B' , 'dest' : 'A' , 'conditions' : model . clear_state },
{ 'trigger' : 'clear' , 'source' : 'C' , 'dest' : 'A' ,
'conditions' : partial ( model . clear_state , False , force = True )},
],
initial = 'A' , show_conditions = True )
model . get_graph (). draw ( 'my_state_diagram.png' , prog = 'dot' )这应该产生与此类似的东西:

如果参考格式不适合您的需求,则可以覆盖静态方法GraphMachine.format_references 。如果要完全跳过参考,只需让GraphMachine.format_references返回None 。另外,请查看我们的示例ipython/jupyter笔记本电脑,以获取有关如何使用和编辑图形的更详细的示例。
如果在线程中进行事件进行调度,则可以使用LockedMachine或LockedHierarchicalMachine ,其中功能访问(!sic)可以用重入锁固定。这并不能通过修补模型或状态机的成员变量来损坏您的计算机。
from transitions . extensions import LockedMachine
from threading import Thread
import time
states = [ 'A' , 'B' , 'C' ]
machine = LockedMachine ( states = states , initial = 'A' )
# let us assume that entering B will take some time
thread = Thread ( target = machine . to_B )
thread . start ()
time . sleep ( 0.01 ) # thread requires some time to start
machine . to_C () # synchronized access; won't execute before thread is done
# accessing attributes directly
thread = Thread ( target = machine . to_B )
thread . start ()
machine . new_attrib = 42 # not synchronized! will mess with execution order任何Python上下文管理器都可以通过machine_context关键字参数传递:
from transitions . extensions import LockedMachine
from threading import RLock
states = [ 'A' , 'B' , 'C' ]
lock1 = RLock ()
lock2 = RLock ()
machine = LockedMachine ( states = states , initial = 'A' , machine_context = [ lock1 , lock2 ])通过machine_model的任何上下文都将在Machine注册的所有模型之间共享。也可以添加人均上下文:
lock3 = RLock ()
machine . add_model ( model , model_context = lock3 )重要的是,所有用户提供的上下文经理都重新进入,因为即使在单个触发调用的背景下,状态机将多次调用它们。
如果您使用的是Python 3.7或更高版本,则可以使用AsyncMachine与异步回调一起使用。如果愿意,您可以混合同步和异步回调,但这可能具有不期望的副作用。请注意,事件需要等待,活动循环也必须由您处理。
from transitions . extensions . asyncio import AsyncMachine
import asyncio
import time
class AsyncModel :
def prepare_model ( self ):
print ( "I am synchronous." )
self . start_time = time . time ()
async def before_change ( self ):
print ( "I am asynchronous and will block now for 100 milliseconds." )
await asyncio . sleep ( 0.1 )
print ( "I am done waiting." )
def sync_before_change ( self ):
print ( "I am synchronous and will block the event loop (what I probably shouldn't)" )
time . sleep ( 0.1 )
print ( "I am done waiting synchronously." )
def after_change ( self ):
print ( f"I am synchronous again. Execution took { int (( time . time () - self . start_time ) * 1000 ) } ms." )
transition = dict ( trigger = "start" , source = "Start" , dest = "Done" , prepare = "prepare_model" ,
before = [ "before_change" ] * 5 + [ "sync_before_change" ],
after = "after_change" ) # execute before function in asynchronously 5 times
model = AsyncModel ()
machine = AsyncMachine ( model , states = [ "Start" , "Done" ], transitions = [ transition ], initial = 'Start' )
asyncio . get_event_loop (). run_until_complete ( model . start ())
# >>> I am synchronous.
# I am asynchronous and will block now for 100 milliseconds.
# I am asynchronous and will block now for 100 milliseconds.
# I am asynchronous and will block now for 100 milliseconds.
# I am asynchronous and will block now for 100 milliseconds.
# I am asynchronous and will block now for 100 milliseconds.
# I am synchronous and will block the event loop (what I probably shouldn't)
# I am done waiting synchronously.
# I am done waiting.
# I am done waiting.
# I am done waiting.
# I am done waiting.
# I am done waiting.
# I am synchronous again. Execution took 101 ms.
assert model . is_Done ()因此,为什么您需要使用Python 3.7或更高版本。异步支持已引入早些时候。 AsyncMachine利用contextvars在新事件到达之前到达时处理运行回调:
async def await_never_return ():
await asyncio . sleep ( 100 )
raise ValueError ( "That took too long!" )
async def fix ():
await m2 . fix ()
m1 = AsyncMachine ( states = [ 'A' , 'B' , 'C' ], initial = 'A' , name = "m1" )
m2 = AsyncMachine ( states = [ 'A' , 'B' , 'C' ], initial = 'A' , name = "m2" )
m2 . add_transition ( trigger = 'go' , source = 'A' , dest = 'B' , before = await_never_return )
m2 . add_transition ( trigger = 'fix' , source = 'A' , dest = 'C' )
m1 . add_transition ( trigger = 'go' , source = 'A' , dest = 'B' , after = 'go' )
m1 . add_transition ( trigger = 'go' , source = 'B' , dest = 'C' , after = fix )
asyncio . get_event_loop (). run_until_complete ( asyncio . gather ( m2 . go (), m1 . go ()))
assert m1 . state == m2 . state这个示例实际上说明了两件事:首先,在M1从A为B的过渡中调用的“ go”未被取消,其次,命名m2.fix()将通过执行“ fix fix'来停止m2的过渡尝试从A到B的过渡尝试。从A到C没有contextvars这种分离将是不可能的。请注意, prepare和conditions不被视为正在进行的过渡。这意味着在评估了conditions后,即使已经发生了另一个事件,也会执行过渡。仅当在回调before或更高版本以上时,任务才会被取消。
AsyncMachine具有模型特殊的队列模式,当queued='model'将其传递给构造函数时,可以使用。使用特定于模型的队列,只有在属于同一模型的情况下,事件才会排队。此外,提出的例外只能清除提出该例外的模型的事件队列。为了简单起见,让我们假设在asyncio.gather中的每个事件。以下不是同时触发,而是稍微延迟:
asyncio . gather ( model1 . event1 (), model1 . event2 (), model2 . event1 ())
# execution order with AsyncMachine(queued=True)
# model1.event1 -> model1.event2 -> model2.event1
# execution order with AsyncMachine(queued='model')
# (model1.event1, model2.event1) -> model1.event2
asyncio . gather ( model1 . event1 (), model1 . error (), model1 . event3 (), model2 . event1 (), model2 . event2 (), model2 . event3 ())
# execution order with AsyncMachine(queued=True)
# model1.event1 -> model1.error
# execution order with AsyncMachine(queued='model')
# (model1.event1, model2.event1) -> (model1.error, model2.event2) -> model2.event3请注意,机器构建后不得更改队列模式。
如果您的超级英雄需要一些自定义行为,则可以通过装饰机器的状态进行一些额外的功能:
from time import sleep
from transitions import Machine
from transitions . extensions . states import add_state_features , Tags , Timeout
@ add_state_features ( Tags , Timeout )
class CustomStateMachine ( Machine ):
pass
class SocialSuperhero ( object ):
def __init__ ( self ):
self . entourage = 0
def on_enter_waiting ( self ):
self . entourage += 1
states = [{ 'name' : 'preparing' , 'tags' : [ 'home' , 'busy' ]},
{ 'name' : 'waiting' , 'timeout' : 1 , 'on_timeout' : 'go' },
{ 'name' : 'away' }] # The city needs us!
transitions = [[ 'done' , 'preparing' , 'waiting' ],
[ 'join' , 'waiting' , 'waiting' ], # Entering Waiting again will increase our entourage
[ 'go' , 'waiting' , 'away' ]] # Okay, let' move
hero = SocialSuperhero ()
machine = CustomStateMachine ( model = hero , states = states , transitions = transitions , initial = 'preparing' )
assert hero . state == 'preparing' # Preparing for the night shift
assert machine . get_state ( hero . state ). is_busy # We are at home and busy
hero . done ()
assert hero . state == 'waiting' # Waiting for fellow superheroes to join us
assert hero . entourage == 1 # It's just us so far
sleep ( 0.7 ) # Waiting...
hero . join () # Weeh, we got company
sleep ( 0.5 ) # Waiting...
hero . join () # Even more company o/
sleep ( 2 ) # Waiting...
assert hero . state == 'away' # Impatient superhero already left the building
assert machine . get_state ( hero . state ). is_home is False # Yupp, not at home anymore
assert hero . entourage == 3 # At least he is not alone当前,过渡配有以下状态功能:
超时- 一段时间后触发活动
timeout timeout (int,可选) - 如果通过on_timeout (string/callable,可选) - 到达超时时间时将调用timeout时会引起一个AttributeError ,但on_timeout标签- 将标签添加到状态
tags (列表,可选) - 将标签分配给状态State.is_<tag_name>在状态已标记为tag_name时将返回True ,else False错误- 在无法剩下状态时提高MachineError
Tags继承(如果使用Error请勿使用Tags )accepted (布尔,可选) - 标记为接受的状态tags ,其中包含“接受”auto_transitions设置为False时,才会提出错误。否则,每个状态都可以使用to_<state>方法退出。挥发性- 每次输入状态时初始化对象
volatile (类,可选) - 每次输入状态时,类型类的对象都会分配给模型。属性名称由hook定义。如果省略,将创建一个空的volatileObjecthook (字符串,默认值='scope') - 模型的时间对象的属性名称。您可以编写自己的State扩展,并以相同的方式添加它们。请注意, add_state_features期望混合素。这意味着您的扩展名应始终调用被覆盖的方法__init__ , enter并exit 。您的扩展可能会从状态继承,但也可以在没有该状态的情况下工作。使用@add_state_features的缺点是,装饰的机器不能腌制(更确切地说,动态生成的CustomState无法腌制)。这可能是编写专用自定义状态类的原因。根据所选状态机,您的自定义状态类可能需要提供某些状态功能。例如, HierarchicalMachine要求您的自定义状态为NestedState的实例( State不够)。要注入您的状态,您可以将它们分配到Machine的类属性state_cls或Override Machine.create_state以防万一创建状态时需要执行一些特定过程:
from transitions import Machine , State
class MyState ( State ):
pass
class CustomMachine ( Machine ):
# Use MyState as state class
state_cls = MyState
class VerboseMachine ( Machine ):
# `Machine._create_state` is a class method but we can
# override it to be an instance method
def _create_state ( self , * args , ** kwargs ):
print ( "Creating a new state with machine '{0}'" . format ( self . name ))
return MyState ( * args , ** kwargs )如果要完全避免使用AsyncMachine中的线程,则可以用asyncio扩展名的AsyncTimeout替换Timeout状态功能:
import asyncio
from transitions . extensions . states import add_state_features
from transitions . extensions . asyncio import AsyncTimeout , AsyncMachine
@ add_state_features ( AsyncTimeout )
class TimeoutMachine ( AsyncMachine ):
pass
states = [ 'A' , { 'name' : 'B' , 'timeout' : 0.2 , 'on_timeout' : 'to_C' }, 'C' ]
m = TimeoutMachine ( states = states , initial = 'A' , queued = True ) # see remark below
asyncio . run ( asyncio . wait ([ m . to_B (), asyncio . sleep ( 0.1 )]))
assert m . is_B () # timeout shouldn't be triggered
asyncio . run ( asyncio . wait ([ m . to_B (), asyncio . sleep ( 0.3 )]))
assert m . is_C () # now timeout should have been processed您应该考虑将queued=True tum TimeoutMachine构造函数。这将确保对事件进行顺序处理,并避免在邻近度和事件发生时可能出现的异步赛车条件。
您可以查看常见问题解答,以获取一些灵感或结帐django-transitions 。它是由克里斯蒂安·莱德曼(Christian Ledermann)开发的,也由Github主持。该文档包含一些用法示例。
首先,恭喜!您到达了文档的结尾!如果您想在安装过渡之前尝试transitions ,则可以在mybinder.org的交互式jupyter笔记本中执行此操作。只需单击此按钮。
对于错误报告和其他问题,请在GitHub上打开一个问题。
对于使用问题,请在堆栈溢出上发布,并确保使用pytransitions标签标记您的问题。不要忘记看看扩展的示例!
对于任何其他问题,招标或大型不受限制的货币礼物,请给Tal Yarkoni(初始作者)和/或Alexander Neumann(现有维护者)发送电子邮件。


