elastic_transformers
1.0.0
带有句子转换器的语义弹性搜索。我们将利用 Elastic 的强大功能和 BERT 的魔力来索引一百万篇文章,并对它们进行词汇和语义搜索。
目的是提供一种易于使用的方式来设置您自己的 Elasticsearch,并使用 NLP 转换器实现上下文嵌入/语义搜索的近乎最先进的功能。
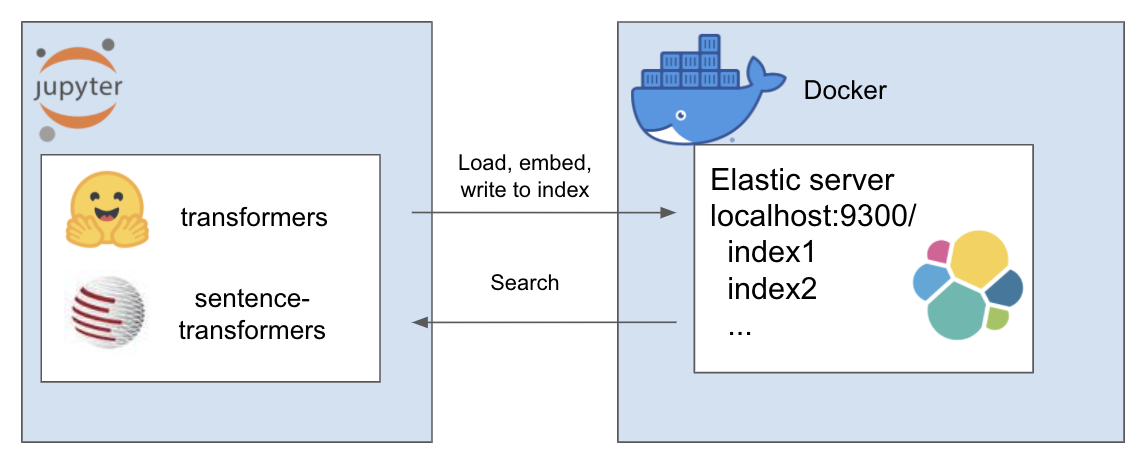
上述设置的工作原理如下
我的环境称为et ,我为此使用 conda。在项目目录内导航
conda create - - name et python = 3.7
conda install - n et nb_conda_kernels
conda activate et
pip install - r requirements . txt在本教程中,我使用 Rohk 的 A Million News Headlines 并将其放置在项目目录内的数据文件夹中。
elastic_transformers/
├── data/
您会发现这些步骤非常抽象,因此您也可以使用您选择的数据集来执行此操作
按照此处 Elastic 页面上有关使用 Docker 设置 Elastic 的说明进行操作。对于本教程,您只需运行以下两个步骤:
该存储库引入了 ElasiticTransformers 类。帮助创建、索引和查询包含嵌入的 Elasticsearch 索引的实用程序
启动连接链接以及(可选)要使用的索引的名称
et = ElasticTransformers ( url = 'http://localhost:9300' , index_name = 'et-tiny' )create_index_spec定义索引的映射。可以提供相关字段的列表以用于关键字搜索或语义(密集向量)搜索。它还具有密集向量大小的参数,因为这些参数可能会有所不同create_index - 使用之前创建的规范来创建可供搜索的索引
et . create_index_spec (
text_fields = [ 'publish_date' , 'headline_text' ],
dense_fields = [ 'headline_text_embedding' ],
dense_fields_dim = 768
)
et . create_index ()write_large_csv - 将大型 csv 文件分解为块,并迭代地使用预定义的嵌入实用程序为每个块创建嵌入列表,然后将结果提供给索引
et . write_large_csv ( 'data/tiny_sample.csv' ,
chunksize = 1000 ,
embedder = embed_wrapper ,
field_to_embed = 'headline_text' )搜索- 允许选择关键字(Elastic 中的“匹配”)或语义(Elastic 中的密集)搜索。值得注意的是,它需要与 write_large_csv 中使用的相同嵌入函数
et . search ( query = 'search these terms' ,
field = 'headline_text' ,
type = 'match' ,
embedder = embed_wrapper ,
size = 1000 )成功设置后,使用以下笔记本使这一切正常工作
这个 repo 结合了以下杰出人士的精彩作品。如果您还没有这样做,请检查他们的工作......


