LLaMA LoRA Tuner
v0.0.20230421
通过低秩适应 (LoRA) 轻松评估和微调 LLaMA 模型。
更新:
在
dev分支上,有一个新的聊天 UI 和一个新的演示模式配置,作为演示新模型的简单方法。然而,新版本还没有微调功能,并且不向后兼容,因为它使用了新的方式来定义模型的加载方式,并且还使用了新的提示模板格式(来自LangChain)。
有关更多信息,请参阅:#28。
LLM.Tuner.Chat.UI.in.Demo.Mode.mp4
请参阅 Hugging Face 上的演示*仅提供 UI 演示。要尝试训练或文本生成,请在 Colab 上运行。
一键启动并在 Google Colab 中使用标准 GPU 运行时运行。
在 Google Drive 中加载和存储数据。
评估存储在文件夹中或 Hugging Face 中的各种 LLaMA LoRA 模型。 
在基本模型之间切换,例如decapoda-research/llama-7b-hf 、 nomic-ai/gpt4all-j 、 databricks/dolly-v2-7b 、 EleutherAI/gpt-j-6b或EleutherAI/pythia-6.9b 。
使用不同的提示模板和训练数据集格式微调 LLaMA 模型。 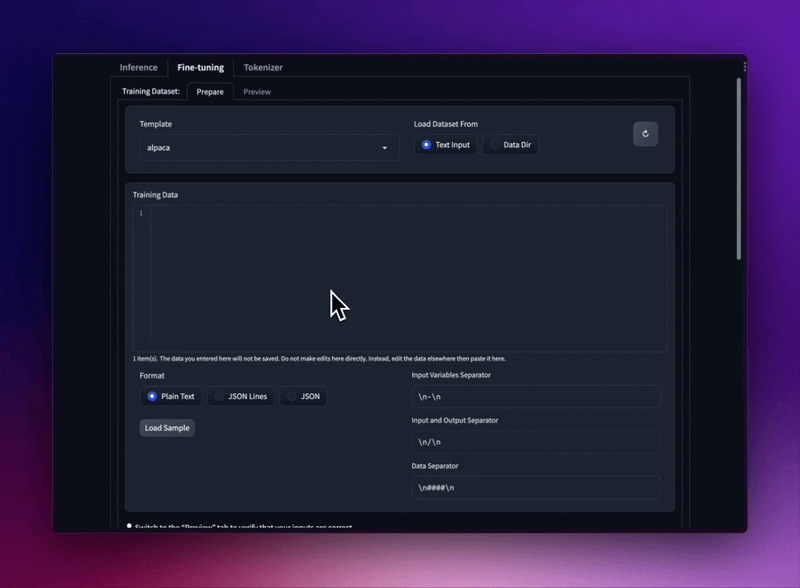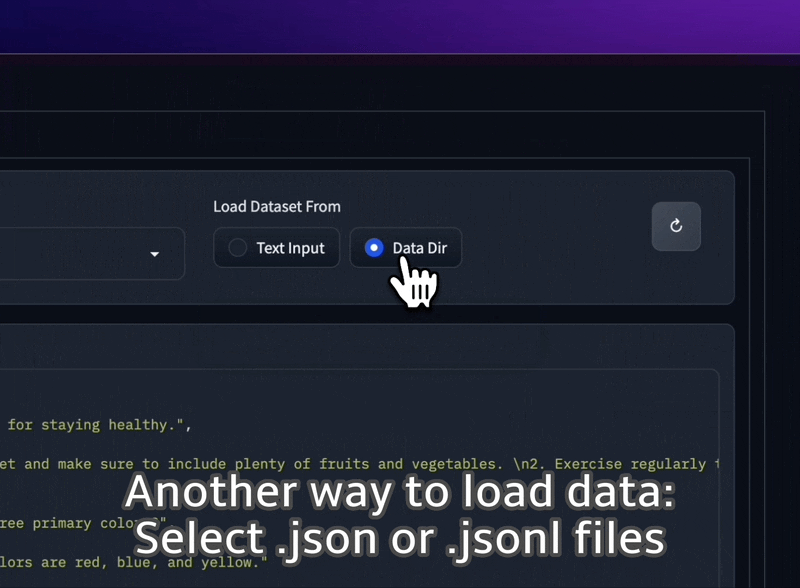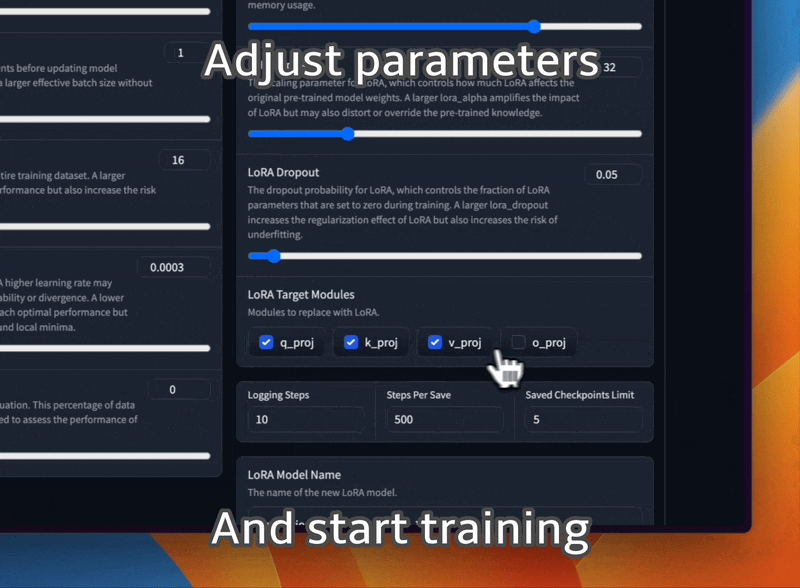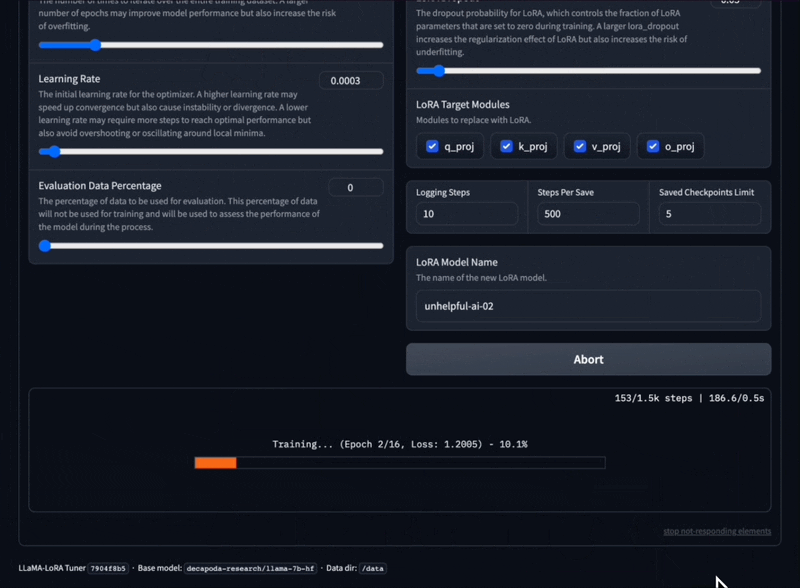
从文件夹加载 JSON 和 JSONL 数据集,甚至将纯文本直接粘贴到 UI 中。
支持斯坦福羊驼种子任务、阿尔帕卡数据和OpenAI“提示”-“完成”格式。
使用提示模板保持数据集干燥。
有多种方法可以运行此应用程序:
在 Google Colab 上运行:最简单的入门方法,您只需要一个 Google 帐户即可。标准(免费)GPU 运行时足以运行微批量大小为 8 的生成和训练。但是,文本生成和训练比其他云服务慢得多,并且 Colab 在运行长任务时可能会在不活动状态下终止执行。
通过 SkyPilot 在云服务上运行:如果您有云服务(Lambda Labs、GCP、AWS 或 Azure)帐户,则可以使用 SkyPilot 在云服务上运行应用程序。可以安装云存储桶来保存您的数据。
本地运行:取决于您拥有的硬件。
请参阅视频以获取分步说明。
打开此 Colab Notebook 并选择运行时 > 全部运行( ⌘/Ctrl+F9 )。
系统将提示您授权 Google 云端硬盘访问权限,因为 Google 云端硬盘将用于存储您的数据。有关设置和更多信息,请参阅“配置”/“Google 云端硬盘”部分。
运行大约 5 分钟后,您将在“Launch”/“Start Gradio UI”部分的输出中看到公共 URL(例如Running on public URL: https://xxxx.gradio.live )。在浏览器中打开 URL 以使用该应用程序。
按照 SkyPilot 安装指南后,创建.yaml来定义运行应用程序的任务:
# llm-tuner.yamlresources: 加速器: A10:1 # 1x NVIDIA A10 GPU,在 Lambda Cloud 上约为 0.6 美元/小时。运行“sky show-gpus”以获取支持的 GPU 类型,并运行“sky show-gpus [GPU_NAME]”以获取 GPU 类型的详细信息。
云: lambda # 可选;如果省略,SkyPilot 将自动选择最便宜的 cloud.file_mounts: # 挂载将用作数据目录的现有云存储。
#(存储训练数据集训练模型)
# 有关详细信息,请参阅 https://skypilot.readthedocs.io/en/latest/reference/storage.html。
/data:name: llm-tuner-data # 确保此名称是唯一的或者您拥有此存储桶。如果不存在,SkyPilot 将尝试使用此名称创建一个存储桶。store: s3 # 可以是 [s3, gcs] 模式之一:MOUNT# 克隆 LLaMA-LoRA Tuner 存储库并安装其依赖项。 conda create -q python=3.8 -n llm-tuner -y conda activate llm-tuner # 克隆 LLaMA-LoRA Tuner 存储库并安装其依赖项 [ ! -d llm_tuner ] && git clone https://github.com/zetavg/LLaMA-LoRA-Tuner.git llm_tuner echo '安装依赖项...' pip install -r llm_tuner/requirements.lock.txt # 可选:安装 wandb 到启用权重和偏差日志记录 pip install wandb # 可选:修补bitsandbytes 以解决错误“libbitsandbytes_cpu.so:未定义符号:cget_col_row_stats" BITSANDBYTES_LOCATION="$(pip show bitsandbytes | grep 'Location' | awk '{print $2}')/bitsandbytes" [ -f "$BITSANDBYTES_LOCATION/libbitsandbytes_cpu.so" ] && [ ! -f "$BITSANDBYTES_LOCATION/libbitsandbytes_cpu.so.bak" ] && [ -f "$BITSANDBYTES_LOCATION/libbitsandbytes_cuda121.so" ] && echo '修补bitsandbytes以支持GPU...' && mv "$BITSANDBYTES_LOCATION/libbitsandbytes_cpu.so" “$BITSANDBYTES_LOCATION/libbitsandbytes_cpu.so.bak” && cp “$BITSANDBYTES_LOCATION/libbitsandbytes_cuda121.so” “$BITSANDBYTES_LOCATION/libbitsandbytes_cpu.so” conda install -q cudatoolkit -y echo '已安装依赖项。' # 可选:安装并设置 Cloudflare Tunnel,以使用自定义域名将应用程序公开到互联网 [ -f /data/secrets/cloudflared_tunnel_token.txt ] && echo "Installing Cloudflare" && curl -L --output cloudflared.deb https: //github.com/cloudflare/cloudflared/releases/latest/download/cloudflared-linux-amd64.deb && sudo dpkg -i cloudflared.deb && sudo cloudflared 服务卸载 || : && sudo cloudflared service install "$(cat /data/secrets/cloudflared_tunnel_token.txt | tr -d 'n')" # 可选:预下载模型 echo "预下载基础模型,这样你就不必等待一旦应用程序准备就绪......” python llm_tuner/download_base_model.py --base_model_names='decapoda-research/llama-7b-hf,nomic-ai/gpt4all-j'# 启动应用程序。 `hf_access_token`、`wandb_api_key` 和 `wandb_project` 是可选的。 conda 激活 llm-tuner python llm_tuner/app.py --data_dir='/data' --hf_access_token="$([ -f /data/secrets/hf_access_token.txt ] && cat /data/secrets/hf_access_token.txt | tr -d 'n')" --wandb_api_key="$([ -f /data/secrets/wandb_api_key.txt ] && cat /data/secrets/wandb_api_key.txt | tr -d 'n')" --wandb_project='llm-tuner' --timezone='大西洋/雷克雅未克' --base_model= '十足动物研究/llama-7b-hf' --base_model_choices='decapoda-research/llama-7b-hf,nomic-ai/gpt4all-j,databricks/dolly-v2-7b' --share然后启动集群来运行任务:
sky launch -c llm-tuner llm-tuner.yaml
-c ...是一个可选标志,用于指定集群名称。如果未指定,SkyPilot 将自动生成一个。
您将在终端中看到应用程序的公共 URL。在浏览器中打开 URL 以使用该应用程序。
请注意,退出sky launch只会退出日志流,不会停止任务。您可以使用sky queue --skip-finished查看正在运行或挂起的任务的状态,使用sky logs <cluster_name> <job_id>连接回日志流,使用sky cancel <cluster_name> <job_id>停止任务。
完成后,运行sky stop <cluster_name>以停止集群。要终止集群,请运行sky down <cluster_name> 。
完成后请记住停止或关闭集群,以避免产生意外费用。运行sky cost-report以查看集群的成本。
要登录云计算机,请运行ssh <cluster_name> ,例如ssh llm-tuner 。
如果您本地机器上安装了sshfs ,您可以通过运行如下命令将云机器的文件系统挂载到本地计算机上:
mkdir -p /tmp/llm_tuner_server && umount /tmp/llm_tuner_server || : && sshfs llm-tuner:/ /tmp/llm_tuner_server
conda create -y python=3.8 -n llm-tuner conda 激活 llm-tuner
pip install -r requests.lock.txt python app.py --data_dir='./data' --base_model='decapoda-research/llama-7b-hf' --timezone='大西洋/雷克雅未克' --share
您将在终端中看到应用程序的本地和公共 URL。在浏览器中打开 URL 以使用该应用程序。
有关更多选项,请参阅python app.py --help 。
要在不加载语言模型的情况下测试 UI,请使用--ui_dev_mode标志:
python app.py --data_dir='./data' --base_model='decapoda-research/llama-7b-hf' --share --ui_dev_mode
要使用 Gradio 自动重新加载,需要
config.yaml文件,因为不支持命令行参数。有一个示例文件可以开始:cp config.yaml.sample config.yaml。然后,只需运行gradio app.py。
请参阅 YouTube 上的视频。
https://github.com/tloen/alpaca-lora
https://github.com/lxe/simple-llama-finetuner
...
待定


