automata
v0.0.4
automata的灵感来自于这样的理论:代码本质上是一种记忆形式,当配备正确的工具时,人工智能可以进化出实时能力,这有可能导致通用人工智能的诞生。 automata一词源自希腊语αὐτόματος,表示“自我行动、自我意志、自我移动”, automata理论是对抽象机器和automata以及可以使用它们解决的计算问题的研究。
更多信息如下。
按照以下步骤设置automata环境
# Clone the repository
git clone [email protected]:emrgnt-cmplxty/ automata .git && cd automata /
# Initialize git submodules
git submodule update --init
# Install poetry and the project
pip3 install poetry && poetry install
# Configure the environment and setup files
poetry run automata configure拉取 Docker 镜像:
$ docker pull ghcr.io/emrgnt-cmplxty/ automata :latest运行 Docker 镜像:
$ docker run --name automata _container -it --rm -e OPENAI_API_KEY= < your_openai_key > -e GITHUB_API_KEY= < your_github_key > ghcr.io/emrgnt-cmplxty/ automata :latest这将启动一个安装了automata Docker 容器,并打开一个交互式 shell 供您使用。
Windows 用户可能需要通过 Visual Studio 的“使用 C++ 进行桌面开发”来安装 C++ 支持以获取某些依赖项。
此外,可能需要更新到 gcc-11 和 g++-11。这可以通过运行以下命令来完成:
# Adds the test toolchain repository, which contains newer versions of software
sudo add-apt-repository ppa:ubuntu-toolchain-r/test
# Updates the list of packages on your system
sudo apt update
# Installs gcc-11 and g++-11 packages
sudo apt install gcc-11 g++-11
# Sets gcc-11 and g++-11 as the default gcc and g++ versions for your system
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-11 60 --slave /usr/bin/g++ g++ /usr/bin/g++-11运行automata搜索需要 SCIP 索引。这些索引用于创建代码图,该代码图通过代码库中的依赖关系来关联符号。 automata代码库会定期生成和上传新索引,但如果本地开发需要,程序员必须手动生成它们。如果您遇到问题,我们建议您参考此处的说明。
# Install dependencies and run indexing on the local codebase
poetry run automata install-indexing # Refresh the code embeddings (after making local changes)
poetry run automata run-code-embedding
# Refresh the documentation + embeddings
poetry run automata run-doc-embedding --embedding-level=2
以下命令说明了如何使用简单的指令来运行系统。建议您进行此类初始运行,以确保系统按预期工作。
# Run a single agent w/ trivial instruction
poetry run automata run-agent --instructions= " Return true " --model=gpt-3.5-turbo-0613
# Run a single agent w/ a non-trivial instruction
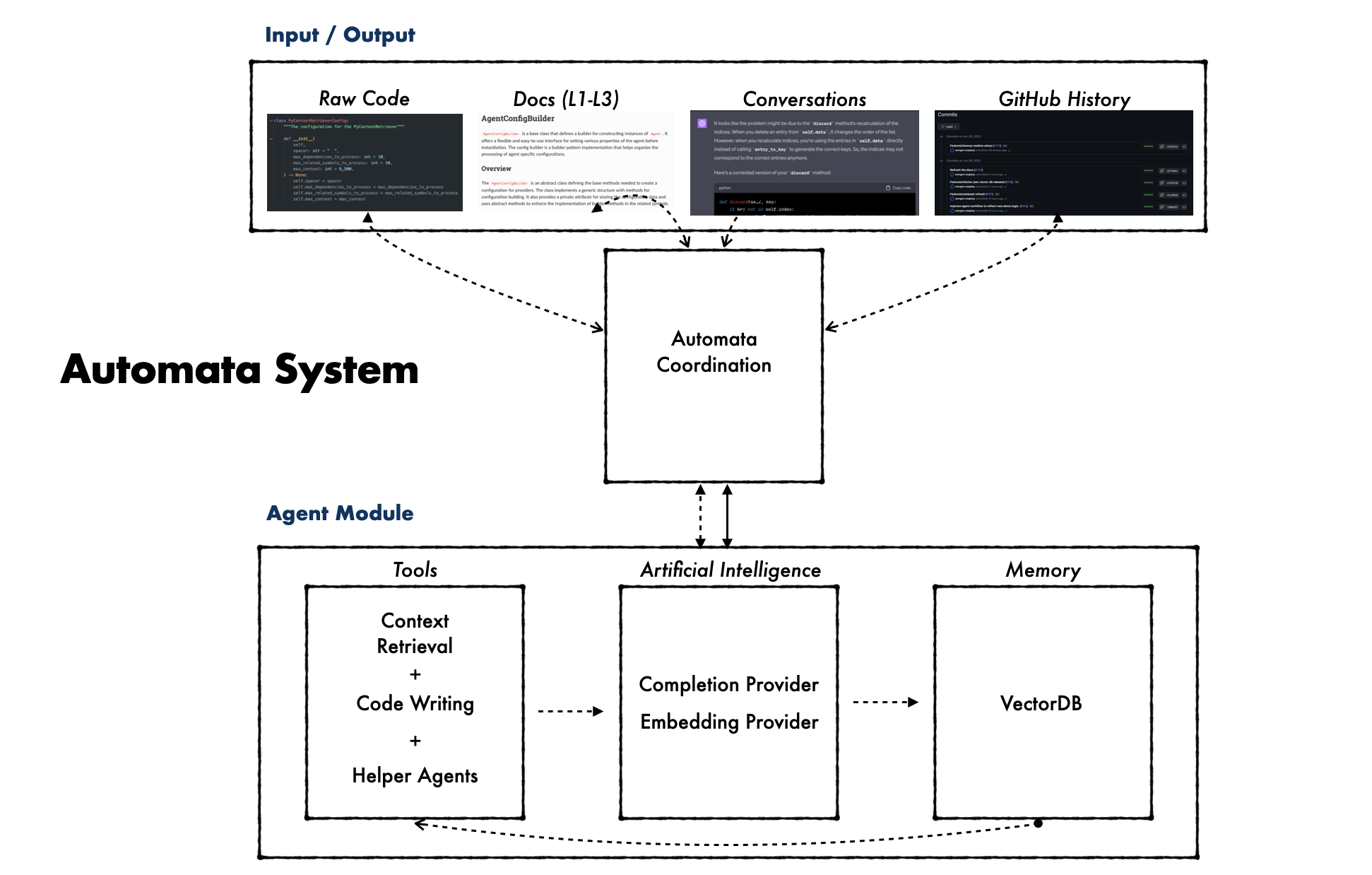
poetry run automata run-agent --instructions= " Explain what automata Agent is and how it works, include an example to initialize an instance of automata Agent. " automata工作原理是将大型语言模型(例如 GPT-4)与向量数据库相结合,形成一个能够记录、搜索和编写代码的集成系统。该过程从生成全面的文档和代码实例开始。这与搜索功能相结合,构成了automata自编码潜力的基础。
automata采用下游工具来执行高级编码任务,不断构建其专业知识和自主性。这种自编码方法反映了自主工匠的工作,其中工具和技术根据反馈和积累的经验不断完善。
有时,理解复杂系统的最佳方法是从理解基本示例开始。以下示例说明了如何运行您自己的automata代理。代理将使用一条简单的指令进行初始化,然后尝试编写代码来完成该指令。然后代理将返回其尝试的结果。
from automata . config . base import AgentConfigName , OpenAI automata AgentConfigBuilder
from automata . agent import OpenAI automata Agent
from automata . singletons . dependency_factory import dependency_factory
from automata . singletons . py_module_loader import py_module_loader
from automata . tools . factory import AgentToolFactory
# Initialize the module loader to the local directory
py_module_loader . initialize ()
# Construct the set of all dependencies that will be used to build the tools
toolkit_list = [ "context-oracle" ]
tool_dependencies = dependency_factory . build_dependencies_for_tools ( toolkit_list )
# Build the tools
tools = AgentToolFactory . build_tools ( toolkit_list , ** tool_dependencies )
# Build the agent config
agent_config = (
OpenAI automata AgentConfigBuilder . from_name ( " automata -main" )
. with_tools ( tools )
. with_model ( "gpt-4" )
. build ()
)
# Initialize and run the agent
instructions = "Explain how embeddings are used by the codebase"
agent = OpenAI automata Agent ( instructions , config = agent_config )
result = agent . run ()此代码库中的嵌入由SymbolCodeEmbedding和SymbolDocEmbedding等类表示。这些类存储有关符号及其各自嵌入的信息,嵌入是表示高维空间中符号的向量。
这些类的示例有: SymbolCodeEmbedding用于存储与符号代码相关的嵌入的类。 SymbolDocEmbedding一个用于存储与符号文档相关的嵌入的类。
创建“SymbolCodeEmbedding”实例的代码示例:
import numpy as np
from automata . symbol_embedding . base import SymbolCodeEmbedding
from automata . symbol . parser import parse_symbol
symbol_str = 'scip-python python automata 75482692a6fe30c72db516201a6f47d9fb4af065 ` automata .agent.agent_enums`/ActionIndicator#'
symbol = parse_symbol ( symbol_str )
source_code = 'symbol_source'
vector = np . array ([ 1 , 0 , 0 , 0 ])
embedding = SymbolCodeEmbedding ( symbol = symbol , source_code = source_code , vector = vector )创建“SymbolDocEmbedding”实例的代码示例:
from automata . symbol_embedding . base import SymbolDocEmbedding
from automata . symbol . parser import parse_symbol
import numpy as np
symbol = parse_symbol ( 'your_symbol_here' )
document = 'A document string containing information about the symbol.'
vector = np . random . rand ( 10 )
symbol_doc_embedding = SymbolDocEmbedding ( symbol , document , vector )如果您想为automata做出贡献,请务必查看贡献指南。该项目遵守automata的行为准则。通过参与,您应该遵守此准则。
我们使用 GitHub issues 来跟踪请求和错误,请参阅automata讨论以了解一般问题和讨论,并请直接提出具体问题。
automata项目致力于遵守开源软件开发中普遍接受的最佳实践。
automata项目的最终目标是达到能够独立设计、编写、测试和完善复杂软件系统的熟练程度。这包括理解和导航大型代码库、推理软件架构、优化性能,甚至在必要时发明新算法或数据结构的能力。
虽然完全实现这一目标可能是一项复杂且长期的努力,但朝着这一目标迈出的每一步不仅有可能显着提高人类程序员的生产力,而且有可能揭示人工智能和计算机的基本问题科学。
automata根据 Apache License 2.0 获得许可。
该项目是 emrgnt-cmplxty 和 maks-ivanov 之间从该存储库开始的初始工作的扩展。


