很棒的审计算法
用于审核黑盒算法的精选算法列表。如今,许多算法(推荐、评分、分类)都是由第三方提供商运行的,用户或机构对如何操作数据没有任何了解。因此,此列表中的审核算法适用于此设置,创造了“黑匣子”设置,其中一名审核员希望深入了解这些远程算法。
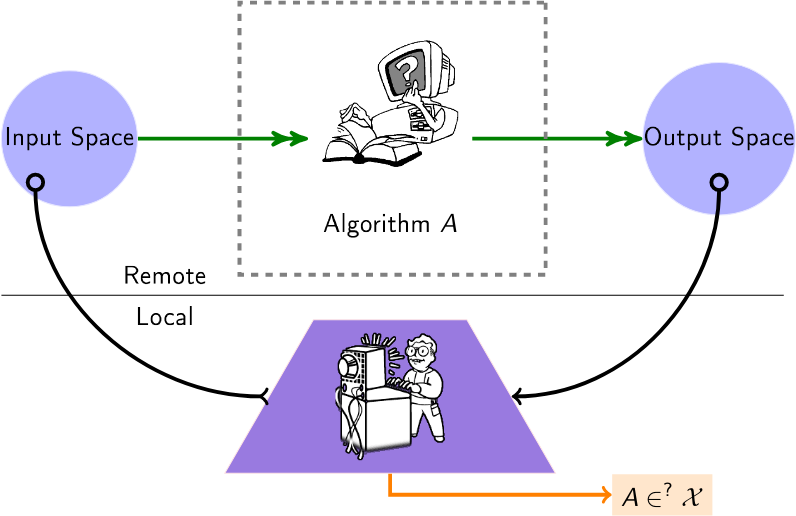
用户查询远程算法(例如,通过可用的API),以推断有关该算法的信息。
内容
文件
2024年
- 审计本地解释很困难 - (NeurIPS)给出审计解释的(禁止的)查询复杂性。
- 法学硕士也对图产生幻觉:结构视角 -(复杂网络)查询法学硕士的已知图并研究拓扑幻觉。提出结构性幻觉等级。
- 多代理协作的公平审核 - (ECAI)考虑多个代理一起工作,每个代理针对不同的任务审核同一平台。
- 绘制算法审计领域:识别研究趋势、语言和地理差异的系统文献综述 - (Arxiv)对算法审计研究的系统回顾以及其方法论趋势的识别。
- FairProof:神经网络的机密性和可认证的公平性 - (Arxiv)提出了使用零知识证明等加密工具的传统审计的替代范例;给出了一个名为 FairProof 的系统,用于验证小型神经网络的公平性。
- 在操纵下,某些人工智能模型是否更难审计? - (SATML)使用 Rademacher 复杂度将黑盒审计的难度与目标模型的容量联系起来。
- 针对语言分类模型的改进成员推理攻击 - (ICLR)提出了一个在审核模式下针对分类器运行成员推理攻击的框架。
- 通过投注审计公平性 - (Neurips) [代码]允许连续监控来自黑盒分类器或回归器的传入数据的顺序方法。
2023年
- 通过一 (1) 次训练运行进行隐私审计 -(NeurIPS - 最佳论文)一种通过单次训练运行来审计差分隐私机器学习系统的方案。
- 通过反事实推理在不知情的情况下审计公平性 -(信息处理与管理)展示如何揭示符合法规的黑盒模型是否仍然存在偏见。
- XAudit:从理论上看带有解释的审计 - (Arxiv)形式化解释在审计中的作用,并研究模型解释是否以及如何帮助审计。
- 跟上语言模型:NLI 数据和模型中的鲁棒性与偏差的相互作用 - (Arxiv)提出了一种通过使用语言模型本身来延长审计数据集保质期的方法;还发现当前偏差审计指标的问题并提出替代方案——这些替代方案强调模型的脆弱性表面上增加了之前的偏差分数。
- 通过迭代细化进行在线公平审计 - (KDD)提供自适应流程,自动推断与估计公平性指标相关的概率保证。
- 窃取语言模型的解码算法 - (CCS)窃取 LLM 解码算法的类型和超参数。
- 对 YouTube 上的兔子洞进行建模 - (SNAM)对 YouTube 上的兔子洞中用户的陷阱动态进行建模,并提供对该封闭空间的测量。
- 审核 YouTube 的推荐算法是否存在错误信息过滤气泡 -(推荐系统上的交易)如何“戳破气泡”,即从推荐中恢复气泡外壳。
- 通过公平性的视角审核 Yelp 的业务排名和评论推荐 - (Arxiv)通过人口统计平等、曝光率和统计测试(例如分位数线性和逻辑回归)审核 Yelp 的业务排名和评论推荐系统的公平性。
- Confidential-PROFITT:树公平训练的机密证明 - (ICLR)提出公平决策树学习算法以及零知识证明协议,以获得审核服务器上的公平性证明。
- SCALE-UP:通过分析扩展预测一致性进行有效的黑盒输入级后门检测 - (ICLR)考虑机器学习即服务 (MLaaS) 应用程序中黑盒设置下的后门检测。
2022年
- 双面:商业人脸识别系统的对抗性审计 - (ICWSM)对多个系统 API 和数据集进行对抗性审计,提出一些令人担忧的观察结果。
- 扩大搜索引擎审计:算法审计的实用见解 - (信息科学杂志)(代码)使用虚拟代理的模拟浏览行为审计多个搜索引擎。
- 石灰热情:实现与架构无关的模型距离 - (ICLR)使用 LIME 测量两个远程模型之间的距离。
- 主动公平审计 - (ICML)研究基于查询的审计算法,可以以查询高效的方式估计 ML 模型的人口统计奇偶性。
- 看看方差!基于 Sobol 的灵敏度分析的高效黑盒解释 - (NeurIPS) Sobol 指数提供了一种有效的方法来捕获图像区域之间的高阶交互及其通过方差镜头对(黑盒)神经网络预测的贡献。
- 你的回声被听到:亚马逊智能扬声器生态系统中的跟踪、分析和广告定位 - (arxiv)推断 Amazon Echo 系统和广告定位算法之间的联系。
2021年
- 当裁判同时也是玩家时:电子商务市场上自有品牌产品推荐的偏见 - (FAccT)亚马逊自有品牌产品是否获得了不公平的推荐份额,因此与第三方产品相比具有优势?
- 日常算法审核:了解日常用户在暴露有害算法行为方面的力量 - (CHI)为用户进行“日常算法审核”提供了理由。
- 审核黑盒预测模型的数据最小化合规性 - (NeurIPS)使用有限数量的查询来衡量预测模型满足的数据最小化水平。
- 澄清影子禁令的记录 - (INFOCOM)(代码)考虑 Twitter 中影子禁令的可能性(即调节黑盒算法),并测量几个假设的概率。
- 从大型语言模型中提取训练数据 -(USENIX 安全性)从 GPT-2 模型的训练数据中提取逐字文本序列。
- FairLens:审核黑盒临床决策支持系统 -(信息处理和管理)通过比较不同的多标签分类差异度量,提供检测和解释临床 DSS 中潜在公平性问题的管道。
- Twitter 上的审计算法偏差 - (WebSci)。
- 贝叶斯算法执行:使用互信息估计黑盒函数的可计算属性 - (ICML)一种预算约束和贝叶斯优化过程,用于从黑盒算法中提取属性。
2020年
- Black-Box Ripper:使用生成进化算法复制黑盒模型 - (NeurIPS)复制黑盒神经模型的功能,但查询量没有限制(通过教师/学生方案和进化搜索) 。
- 审计激进化路径 - (FAT*)使用静态渠道推荐上的随机游走来研究激进渠道彼此之间的可达性。
- 图神经网络上的对抗模型提取 -(AAAI 图深度学习研讨会:方法论和应用)介绍了 GNN 模型提取并提出了初步方法。
- 远程解释性面临保镖问题 -(《自然机器智能》第 2 卷,第 529-539 页)(代码)显示了远程人工智能决策的解释是不可能的(通过一个请求)或难以发现。
- GeoDA:黑盒对抗性攻击的几何框架 -(CVPR)(代码)在纯黑盒设置中制作对抗性示例来愚弄模型(无梯度,仅推断类)。
- 模仿游戏:利用黑盒推荐器进行算法选择 -(Netys)(代码)通过模仿远程且训练有素的算法的决策来参数化本地推荐算法。
- 审核新闻策展系统:检查 Apple News 中的算法和编辑逻辑的案例研究 - (ICWSM)将 Apple News 作为社会技术新闻策展系统的审核研究(热门故事部分)。
- 审计算法:关于经验教训和数据最小化的风险 - (AIES)对 Telefónica 开发的健康推荐应用程序的实际审计(主要是关于偏见)。
- 从大型语言模型中提取训练数据 - (arxiv)执行训练数据提取攻击,通过查询语言模型来恢复单个训练示例。
2019年
- 用于远程神经网络水印的对抗性前沿缝合 -(神经计算和应用)(替代实现)检查远程机器学习模型是否是“泄漏”模型:通过对远程模型的标准 API 请求,提取(或不提取)零-位水印,被插入到水印有价值的模型(例如,大型深度神经网络)。
- 仿冒网络:窃取黑盒模型的功能 - (CVPR)询问对手能够在多大程度上窃取此类仅基于黑盒交互的“受害者”模型的功能:输入图像,输出预测。
- 打开黑匣子:审核 Google 的热门故事算法 - (Flairs-32)对 Google 的热门故事面板的审核,提供对其用于选择和排名新闻发布商的算法选择的见解
- 使有针对性的黑盒规避攻击有效且高效 - (arXiv)研究对手如何最佳地利用其查询预算对深度神经网络进行有针对性的规避攻击。
- 用于衡量广告拍卖中激励兼容性的在线学习 - (WWW)衡量黑盒拍卖平台的激励兼容性 (IC) 机制(遗憾)。
- TamperNN:部署神经网络的高效篡改检测 - (ISSRE)精心设计输入的算法,可通过远程执行的分类器模型检测篡改。
- 通过听取架构提示来进行边缘设备中的神经网络模型提取攻击 - (arxiv)通过从总线监听中获取内存访问事件,通过 LSTM-CTC 模型识别层序列,根据内存访问模式进行层拓扑连接,以及根据内存访问模式进行层维度估计数据量限制,证明可以准确恢复类似的网络架构作为攻击起点
- 使用复合未标记数据从受保护的深度神经网络窃取知识 - (ICNN)复合方法,可用于攻击和提取黑盒模型的知识,即使它完全隐藏其 softmax 输出。
- 通过背景知识对齐在对抗性环境中进行神经网络反演 - (CCS)对抗性环境中的模型反演方法,基于训练充当原始模型的反演的反演模型。在不完全了解原始训练数据的情况下,通过从更通用的数据分布中提取的辅助样本训练反演模型,仍然可以实现准确的反演。
2018年
- 无需打开黑匣子的反事实解释:自动决策和 GDPR -(《哈佛法律与技术杂志》)要解释关于 x 的决策,请找到一个反事实:最接近 x 且改变决策的点。
- 蒸馏和比较:使用透明模型蒸馏审核黑盒模型 - (AIES)将黑盒模型视为教师,训练透明的学生模型来模仿黑盒模型分配的风险评分。
- 走向逆向工程黑盒神经网络 -(ICLR)(代码)通过分析远程神经网络模型对某些输入的响应模式来推断其内部超参数(例如层数、非线性激活类型)。
- 数据驱动的对对抗域中黑盒分类器的探索性攻击 -(神经计算)逆向工程远程分类器模型(例如,用于逃避验证码测试)。
- xGEM:生成解释黑盒模型的示例 - (arXiv)通过训练无监督的隐式生成模型来搜索黑盒模型中的偏差。然后通过沿着数据流形扰动数据样本来定量总结黑盒模型的行为。
- 基于随机游走的节点相似性的学习网络 - (NIPS)通过观察一些随机游走通勤时间来反转图。
- 从黑盒模型中识别机器学习系列 - (CAEPIA)确定返回的预测背后是哪种机器学习模型。
- 通过定时侧通道窃取神经网络 - (arXiv)使用查询通过定时攻击窃取/近似模型。
- Copycat CNN:通过使用随机非标记数据说服坦白来窃取知识 -(IJCNN)(代码)通过使用随机自然图像(ImageNet 和 Microsoft-COCO)查询黑盒模型 (CNN) 来窃取知识。
- 审核政治相关搜索引擎结果页面的个性化和构成 - (WWW) Chrome 扩展,用于调查参与者并收集搜索引擎结果页面 (SERP) 和自动完成建议,用于研究个性化和构成。
2017年
- 揭示影响力食谱:对同行排名服务中的拓扑影响进行逆向工程 - (CSCW)旨在确定同行排名服务中使用哪些中心性指标。
- 推荐的拓扑面:偏差检测的模型和应用 -(复杂网络)为向用户推荐的项目提出了偏差检测框架。
- 针对机器学习模型的成员推理攻击 -(安全与隐私研讨会)给定一个机器学习模型和一条记录,确定该记录是否用作模型训练数据集的一部分。
- 针对机器学习的实用黑盒攻击 -(亚洲 CCS)了解远程服务如何容易受到对抗性分类攻击的影响。
2016年
- 通过定量输入影响实现算法透明度:学习系统的理论和实验 - (IEEE S&P)使用 shapley 值评估特征对模型的个体、联合和边际影响。
- 审核黑盒模型的间接影响 - (ICDM)通过“巧妙地”将变量从数据集中删除并查看准确性差距来评估变量对黑盒模型的影响
- 用于诊断黑盒模型偏差的迭代正交特征投影 -(FATML 研讨会)执行特征排序以分析黑盒模型
- 在线自由职业市场中的偏差:来自 TaskRabbit 的证据 -(dat 研讨会)衡量 TaskRabbit 的搜索算法排名。
- 通过预测 API 窃取机器学习模型 -(Usenix Security)(代码)旨在提取远程服务使用的机器学习模型。
- “为什么我应该相信你?”解释任何分类器的预测 - (arXiv)(代码)通过围绕数据实例进行采样来解释黑盒分类器模型。
- 回归黑色:对消毒剂和过滤器进行正式的黑盒分析 -(安全和隐私)消毒剂和过滤器的黑盒分析。
- 通过定量输入影响实现算法透明度:学习系统的理论和实验 -(安全和隐私)引入了捕获输入对观察系统输出的影响程度的措施。
- 亚马逊商城算法定价的实证分析 - (WWW)(代码)开发一种检测算法定价的方法,并根据经验使用它来分析其在亚马逊商城上的流行程度和行为。
2015年
- 证明和消除不同的影响 - (SIGKDD)提出基于 SVM 的方法来证明不存在偏差,以及从数据集中消除偏差的方法。
- Peeking Under the Hood of Uber - (IMC)推断 Uber 激增价格算法的实现细节。
2014年
- 窥视黑匣子:通过随机化探索分类器 -(数据挖掘和知识发现期刊)(代码)查找可以在不更改预测样本的输出标签的情况下进行排列的特征组
- XRay:通过差分关联增强网络透明度 -(USENIX 安全)审核哪些用户配置文件数据用于定位特定广告、推荐或价格。
2013年
- 衡量 Web 搜索的个性化 - (WWW)开发一种衡量 Web 搜索结果个性化的方法。
- 审核:具有结果相关查询成本的主动学习 - (NIPS)从仅支付负标签费用的二元分类器中学习。
2012年
- 规避凸分类器的查询策略 - (JMLR)凸分类器的规避方法。考虑规避复杂性。
2008年
- Privacy Oracle:一种通过黑盒差异测试查找应用程序泄漏的系统 - (CCS) Privacy Oracle:一种发现应用程序在向远程服务器传输过程中泄露个人信息的系统。
2005年
- 对抗性学习 - (KDD)使用成员资格查询对远程线性分类器进行逆向工程。
相关活动
2024年
- 第一届审计与人工智能国际会议
- 可调节机器学习研讨会 (RegML'24)
2023年
- 支持用户参与测试、审核和竞争 AI(CSCW 用户 AI 审核)
- 算法的算法审计研讨会(WAAA)
- 可调节机器学习研讨会 (RegML'23)


