Scraping Dynamic JavaScript Ajax Websites With BeautifulSoup
1.0.0

JavaScript吗?Browser大多数网站的网页抓取可能相对容易。本教程已详细介绍了该主题。然而,有许多网站无法使用相同的方法进行抓取。原因是这些网站使用 JavaScript 动态加载内容。
该技术也称为 AJAX(异步 JavaScript 和 XML)。从历史上看,该标准包括创建XMLHttpRequest对象以从 Web 服务器检索 XML,而无需重新加载整个页面。如今,这个对象很少被直接使用。通常,像 jQuery 这样的包装器用于检索 JSON、部分 HTML 甚至图像等内容。
要抓取常规网页,至少需要两个库。 requests库下载页面。一旦该页面作为 HTML 字符串可用,下一步就是将其解析为 BeautifulSoup 对象。然后可以使用此 BeautifulSoup 对象查找特定数据。
下面是一个简单的示例脚本,它打印id设置为firstHeading h1元素内的文本。
import requests
from bs4 import BeautifulSoup
response = requests . get ( "https://quotes.toscrape.com/" )
bs = BeautifulSoup ( response . text , "lxml" )
author = bs . find ( "small" , class_ = "author" )
if author :
print ( author . text )
## OUTPUT
# Albert Einstein请注意,我们正在使用 Beautiful Soup 库的版本 4。早期版本已停产。您可能会看到 beautiful soup 4 被写成 Beautiful Soup、BeautifulSoup 甚至 bs4。它们都引用同一个美丽的汤4库。
如果站点是动态的,相同的代码将不起作用。例如,同一站点在https://quotes.toscrape.com/js/上有一个动态版本(请注意此 URL 末尾的js )。
response = requests . get ( "https://quotes.toscrape.com/js" ) # dynamic web page
bs = BeautifulSoup ( response . text , "lxml" )
author = bs . find ( "small" , class_ = "author" )
if author :
print ( author . text )
## No output原因是第二个站点是动态的,其中的数据是使用JavaScript生成的。
有两种方法可以处理此类网站。
本教程详细介绍了这两种方法。
然而,首先,我们需要了解如何确定站点是否是动态的。
这是使用 Chrome 或 Edge 确定网站是否动态的最简单方法。 (这两个浏览器都在底层使用 Chromium)。
按F12键打开开发人员工具。确保焦点位于开发人员工具上,然后按CTRL+SHIFT+P组合键打开命令菜单。
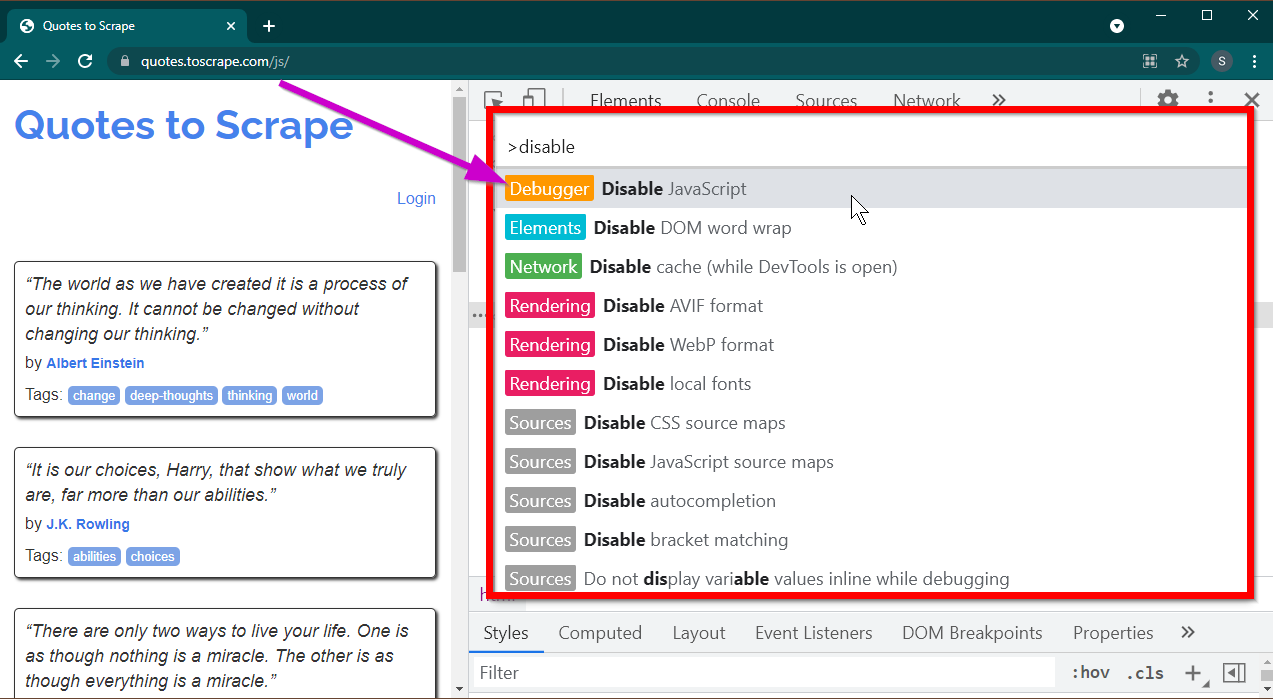
它将显示很多命令。开始输入disable ,命令将被过滤以显示Disable JavaScript 。选择此选项可禁用JavaScript 。
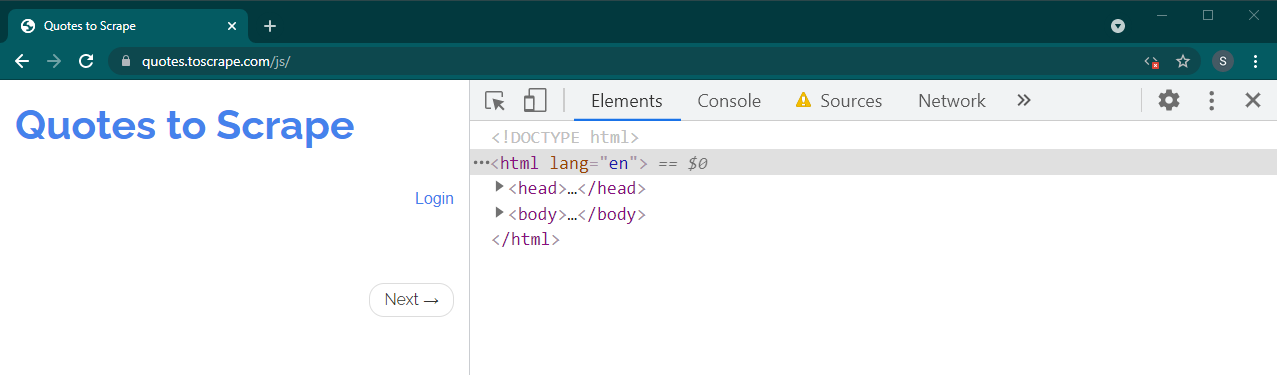
现在按Ctrl+R或F5重新加载此页面。页面将重新加载。
如果这是一个动态站点,很多内容将会消失:
在某些情况下,网站仍会显示数据,但会回退到基本功能。例如,这个网站有一个无限滚动。如果 JavaScript 被禁用,它会显示常规分页。
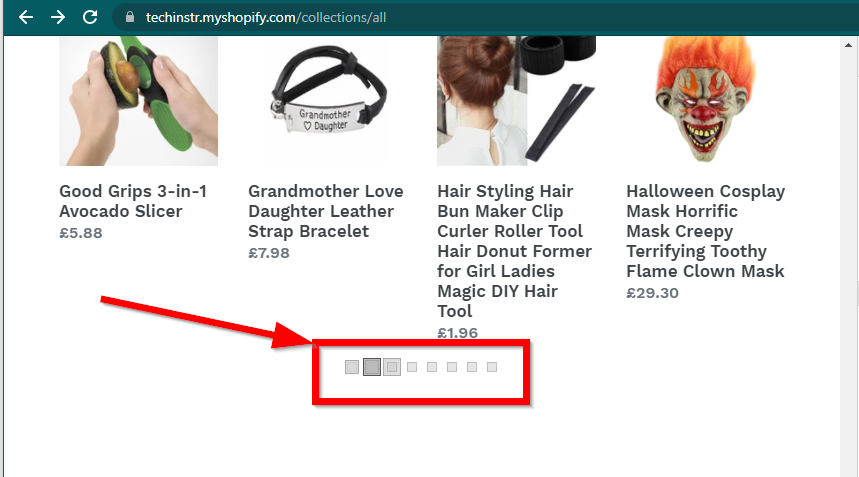 | 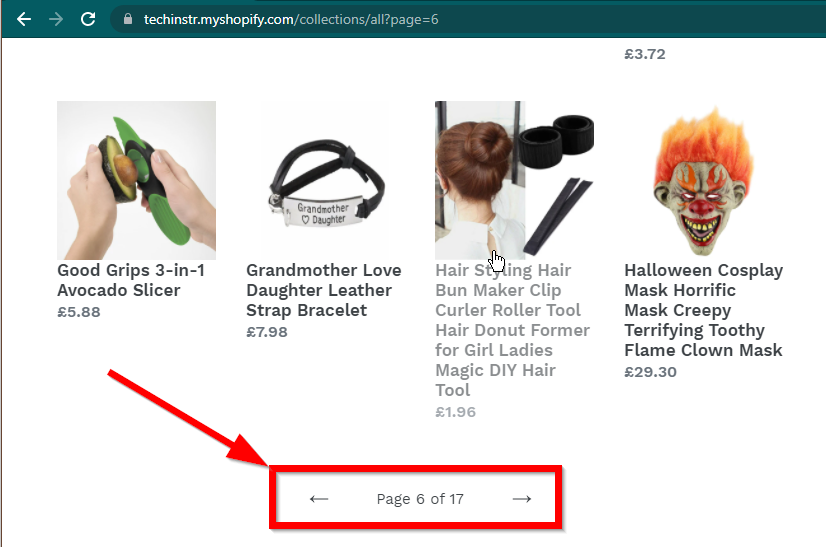 |
|---|---|
| 启用 JavaScript | JavaScript 已禁用 |
下一个需要回答的问题是BeautifulSoup的能力。
JavaScript吗?简短的回答是否定的。
理解解析和渲染等词很重要。解析只是将 Python 对象的字符串表示形式转换为实际对象。
那么什么是渲染呢?渲染本质上是将 HTML、JavaScript、CSS 和图像解释为我们在浏览器中看到的内容。
Beautiful Soup 是一个用于从 HTML 文件中提取数据的 Python 库。这涉及将 HTML 字符串解析为 BeautifulSoup 对象。为了进行解析,首先我们需要 HTML 作为字符串。动态网站不直接拥有 HTML 中的数据。这意味着 BeautifulSoup 无法与动态网站一起使用。
Selenium 库可以在 Chrome 或 Firefox 等浏览器中自动加载和渲染网站。尽管 Selenium 支持从 HTML 中提取数据,但也可以提取完整的 HTML 并使用 Beautiful Soup 来提取数据。
让我们首先使用 Selenium 开始使用 Python 进行动态网页抓取。
安装 Selenium 涉及安装三件事:
您选择的浏览器(您已经拥有):
您的浏览器的驱动程序:
Python 硒包:
pip install seleniumconda-forge频道安装。 conda install -c conda-forge selenium 启动浏览器、加载页面然后关闭浏览器的 Python 脚本的基本框架很简单:
from selenium . webdriver import Chrome
from webdriver_manager . chrome import ChromeDriverManager
driver = Chrome ( ChromeDriverManager (). install ())
driver . get ( 'https://quotes.toscrape.com/js/' )
#
# Code to read data from HTML here
#
driver . quit ()现在我们可以在浏览器中加载页面,让我们看看提取特定元素。提取元素的方法有两种——硒和美丽汤。
本例中我们的目标是找到作者元素。
在 Chrome 中加载网站https://quotes.toscrape.com/js/ ,右键单击作者姓名,然后单击“检查”。这应该加载开发者工具,并突出显示作者元素,如下所示:
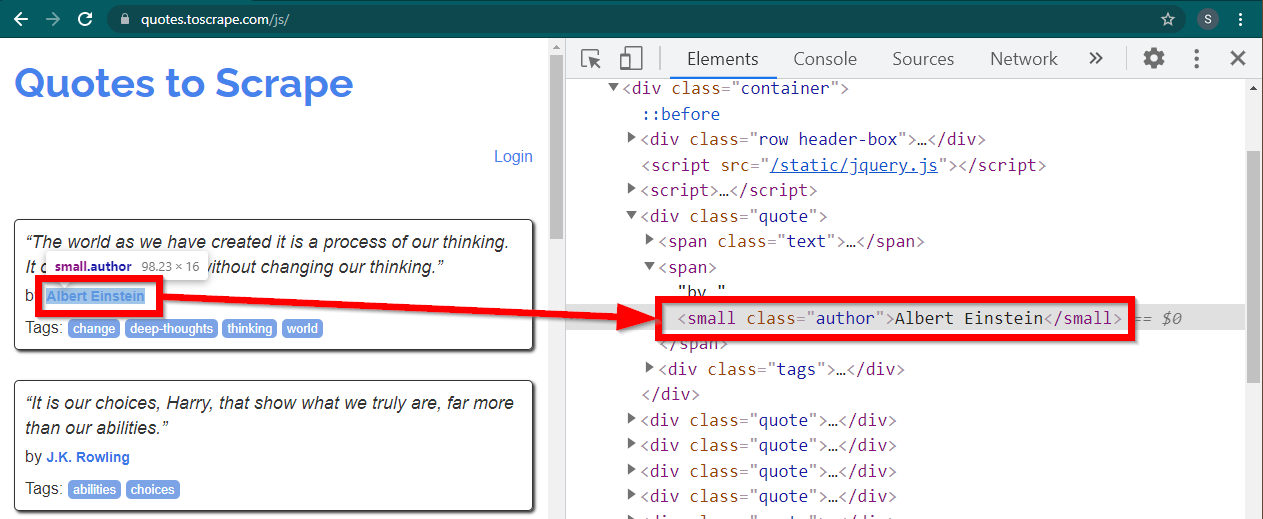
这是一个small元素,其class属性设置为author 。
< small class =" author " > Albert Einstein </ small >Selenium 允许使用各种方法来定位 HTML 元素。这些方法是驱动程序对象的一部分。此处有用的一些方法如下:
element = driver . find_element ( By . CLASS_NAME , "author" )
element = driver . find_element ( By . TAG_NAME , "small" )还有一些其他方法,可能对其他场景有用。这些方法如下:
element = driver . find_element ( By . ID , "abc" )
element = driver . find_element ( By . LINK_TEXT , "abc" )
element = driver . find_element ( By . XPATH , "//abc" )
element = driver . find_element ( By . CSS_SELECTOR , ".abc" )也许最有用的方法是find_element(By.CSS_SELECTOR)和find_element(By.XPATH) 。这两种方法中的任何一种都应该能够选择大部分场景。
我们修改一下代码,以便可以打印第一作者。
from selenium . webdriver import Chrome
from selenium . webdriver . common . by import By
from webdriver_manager . chrome import ChromeDriverManager
driver = Chrome ( ChromeDriverManager (). install ())
driver . get ( 'https://quotes.toscrape.com/js/' )
element = driver . find_element ( By . CLASS_NAME , "author" )
print ( element . text )
driver . quit ()如果你想打印所有作者怎么办?
所有find_element方法都有一个对应的方法 - find_elements 。注意复数形式。要查找所有作者,只需更改一行:
elements = driver . find_elements ( By . CLASS_NAME , "author" )这将返回一个元素列表。我们可以简单地运行一个循环来打印所有作者:
for element in elements :
print ( element . text )注意:完整的代码位于 selenium_example.py 代码文件中。
但是,如果您已经熟悉 BeautifulSoup,则可以创建 Beautiful Soup 对象。
正如我们在第一个示例中看到的,Beautiful Soup 对象需要 HTML。对于网页抓取静态站点,可以使用requests库检索 HTML。下一步是将此 HTML 字符串解析为 BeautifulSoup 对象。
response = requests . get ( "https://quotes.toscrape.com/" )
bs = BeautifulSoup ( response . text , "lxml" )让我们了解如何使用 BeautifulSoup 抓取动态网站。
以下部分与前面的示例保持不变。
from selenium . webdriver import Chrome
from webdriver_manager . chrome import ChromeDriverManager
from bs4 import BeautifulSoup
driver = Chrome ( ChromeDriverManager (). install ())
driver . get ( 'https://quotes.toscrape.com/js/' )页面的渲染 HTML 可在属性page_source中找到。
soup = BeautifulSoup ( driver . page_source , "lxml" )一旦 soup 对象可用,所有 Beautiful Soup 方法都可以照常使用。
author_element = soup . find ( "small" , class_ = "author" )
print ( author_element . text )注:完整的源代码在selenium_bs4.py中
Browser一旦脚本准备就绪,脚本运行时浏览器就不需要可见。浏览器可以隐藏,脚本仍然可以正常运行。浏览器的这种行为也称为无头浏览器。
要使浏览器无头,请导入ChromeOptions 。对于其他浏览器,可以使用它们自己的选项类。
from selenium . webdriver import ChromeOptions现在,创建该类的一个对象,并将headless属性设置为 True。
options = ChromeOptions ()
options . headless = True最后,在创建 Chrome 实例时发送该对象。
driver = Chrome ( ChromeDriverManager (). install (), options = options )现在,当您运行脚本时,浏览器将不可见。有关完整的实现,请参阅 selenium_bs4_headless.py 文件。
加载浏览器的成本很高——它会占用并不真正需要的 CPU、RAM 和带宽。当网站被抓取时,数据很重要。所有这些 CSS、图像和渲染并不是真正需要的。
使用Python抓取动态网页最快、最有效的方法是定位数据的实际位置。
该数据可以位于两个地方:
<script>标记中让我们看几个例子。
在 Chrome 中打开 https://quotes.toscrape.com/js。页面加载后,按 Ctrl+U 查看源代码。按Ctrl+F调出搜索框,搜索Albert。
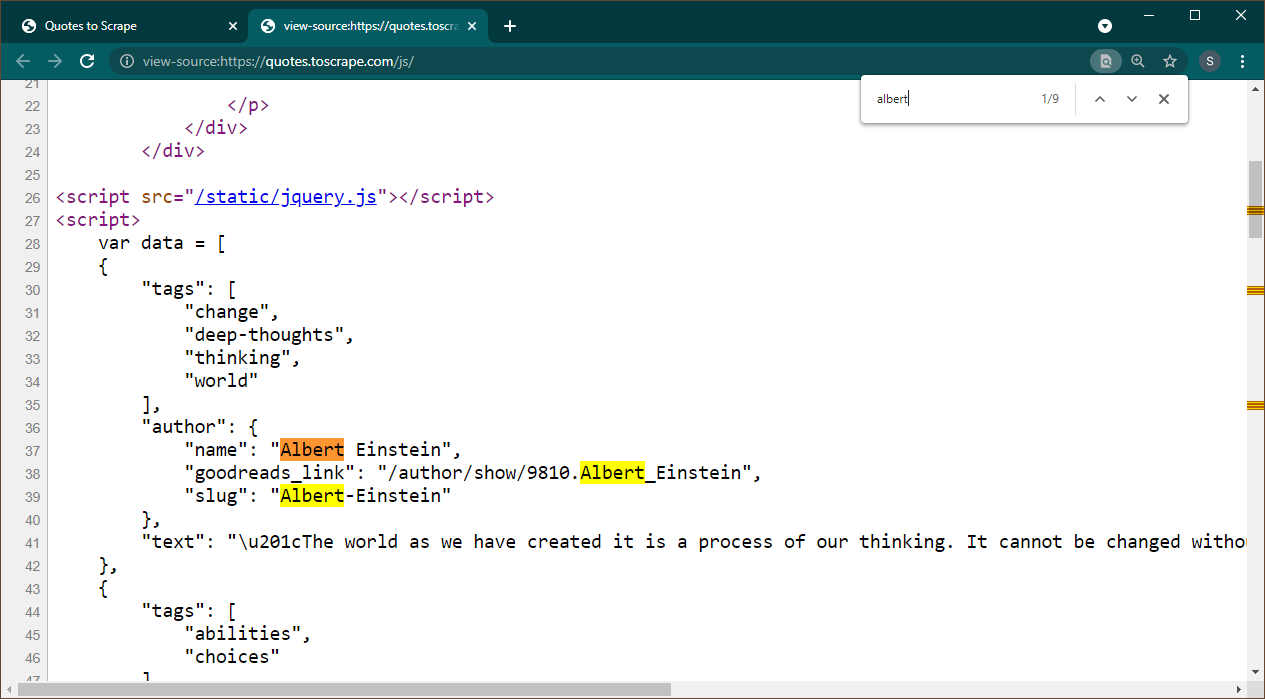
我们可以立即看到数据作为 JSON 对象嵌入到页面上。另请注意,这是脚本的一部分,其中该数据被分配给变量data 。
在这种情况下,我们可以使用Requests库来获取页面,并使用Beautiful Soup来解析页面并获取脚本元素。
response = requests . get ( 'https://quotes.toscrape.com/js/' )
soup = BeautifulSoup ( response . text , "lxml" )请注意,有多个<script>元素。包含我们需要的数据的数据没有src属性。让我们用它来提取脚本元素。
script_tag = soup . find ( "script" , src = None )请记住,除了我们感兴趣的数据之外,该脚本还包含其他 JavaScript 代码。因此,我们将使用正则表达式来提取该数据。
import re
pattern = "var data =(.+?); n "
raw_data = re . findall ( pattern , script_tag . string , re . S )数据变量是一个包含一项的列表。现在我们可以使用 JSON 库将此字符串数据转换为 python 对象。
if raw_data :
data = json . loads ( raw_data [ 0 ])
print ( data )输出将是 python 对象:
[{ 'tags' : [ 'change' , 'deep-thoughts' , 'thinking' , 'world' ], 'author' : { 'name' : 'Albert Einstein' , 'goodreads_link' : '/author/show/9810.Albert_Einstein' , 'slug' : 'Albert-Einstein' }, 'text' : '“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”' }, { 'tags' : [ 'abilities' , 'choices' ], 'author' : { 'name' : 'J.K. Rowling' , .....................该列表无法根据需要转换为任何格式。另请注意,每个项目都包含指向作者页面的链接。这意味着您可以阅读这些链接并创建一个蜘蛛来从所有这些页面获取数据。
完整的代码包含在 data_in_same_page.py 中。
网页抓取动态网站可以遵循完全不同的路径。有时数据会完全加载到单独的页面上。 Librivox 就是这样的一个例子。
打开开发人员工具,转到网络选项卡并按 XHR 进行过滤。现在打开此链接或搜索任何书籍。您将看到数据是嵌入在 JSON 中的 HTML。
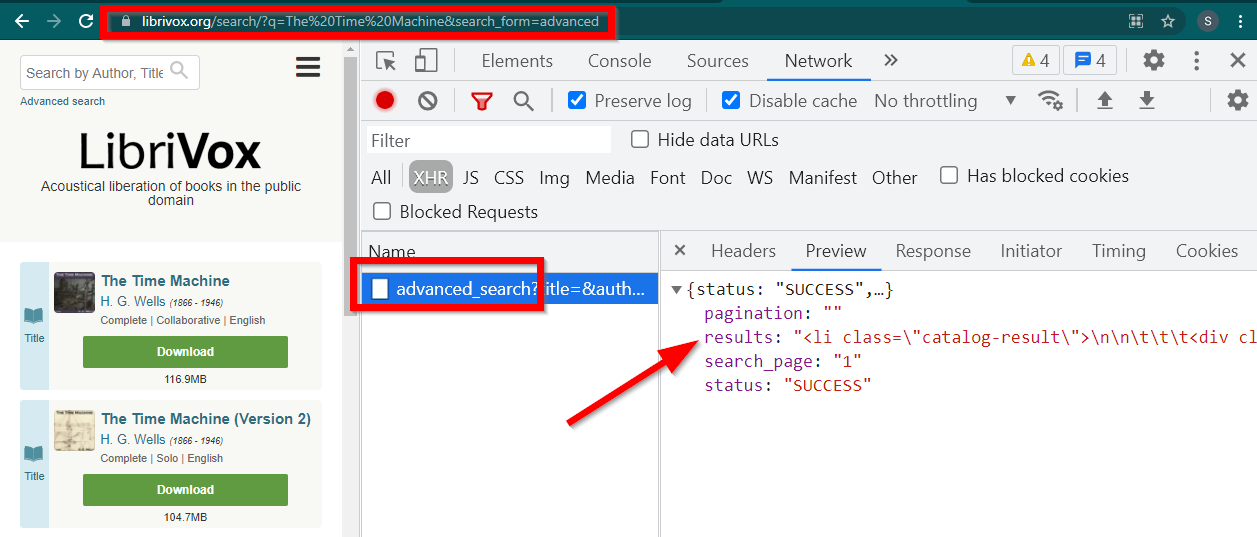
注意几点:
浏览器显示的 URL 为https://librivox.org/search/?q=...
数据位于https://librivox.org/advanced_search?....
如果你查看 headers,你会发现 advance_search 页面发送了一个特殊的 header X-Requested-With: XMLHttpRequest
这是提取此数据的片段:
headers = {
'X-Requested-With' : 'XMLHttpRequest'
}
url = 'https://librivox.org/advanced_search?title=&author=&reader=&keywords=&genre_id=0&status=all&project_type=either&recorded_language=&sort_order=alpha&search_page=1&search_form=advanced&q=The%20Time%20Machine'
response = requests . get ( url , headers = headers )
data = response . json ()
soup = BeautifulSoup ( data [ 'results' ], 'lxml' )
book_titles = soup . select ( 'h3 > a' )
for item in book_titles :
print ( item . text )完整的代码包含在 librivox.py 文件中。


