offensive ai compilation
1.0.0
涵盖进攻性人工智能的有用资源的精选列表。
利用人工智能模型的漏洞。
对抗性机器学习负责评估其弱点并提供对策。
它分为四种类型的攻击:提取、反转、中毒和逃避。
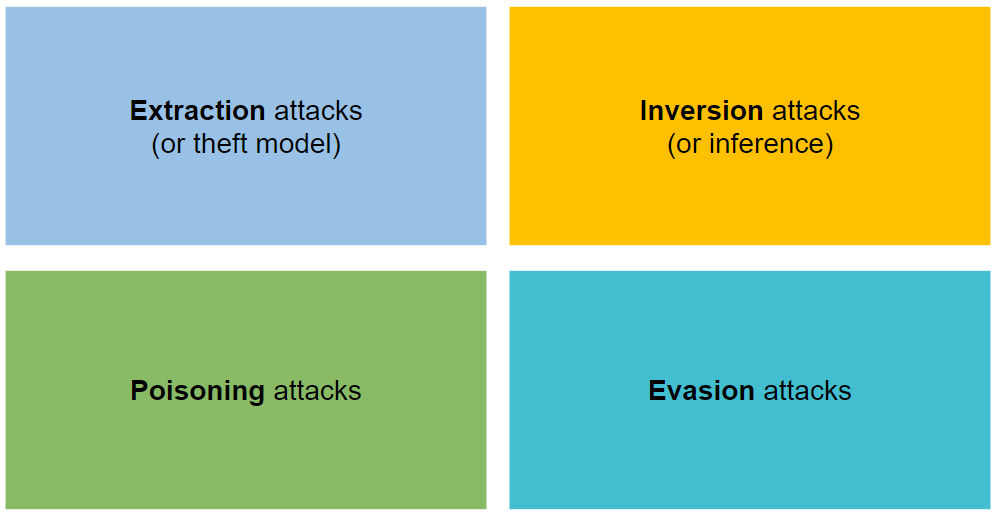
它试图通过发出最大化信息提取的请求来窃取模型的参数和超参数。
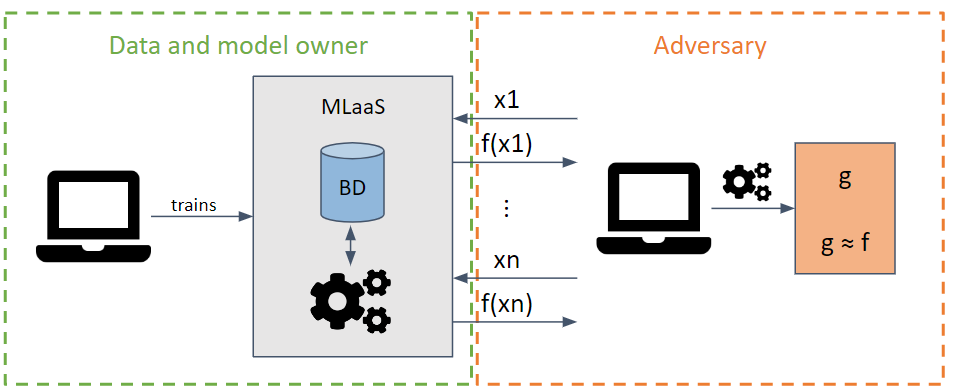
根据对手模型的了解,可以执行白盒和黑盒攻击。
在最简单的白盒情况下(当对手完全了解模型,例如 sigmoid 函数时),人们可以创建一个易于求解的线性方程组。
在一般情况下,如果对模型的了解不足,则使用替代模型。该模型根据对原始模型的请求进行训练,以模仿与原始模型相同的功能。
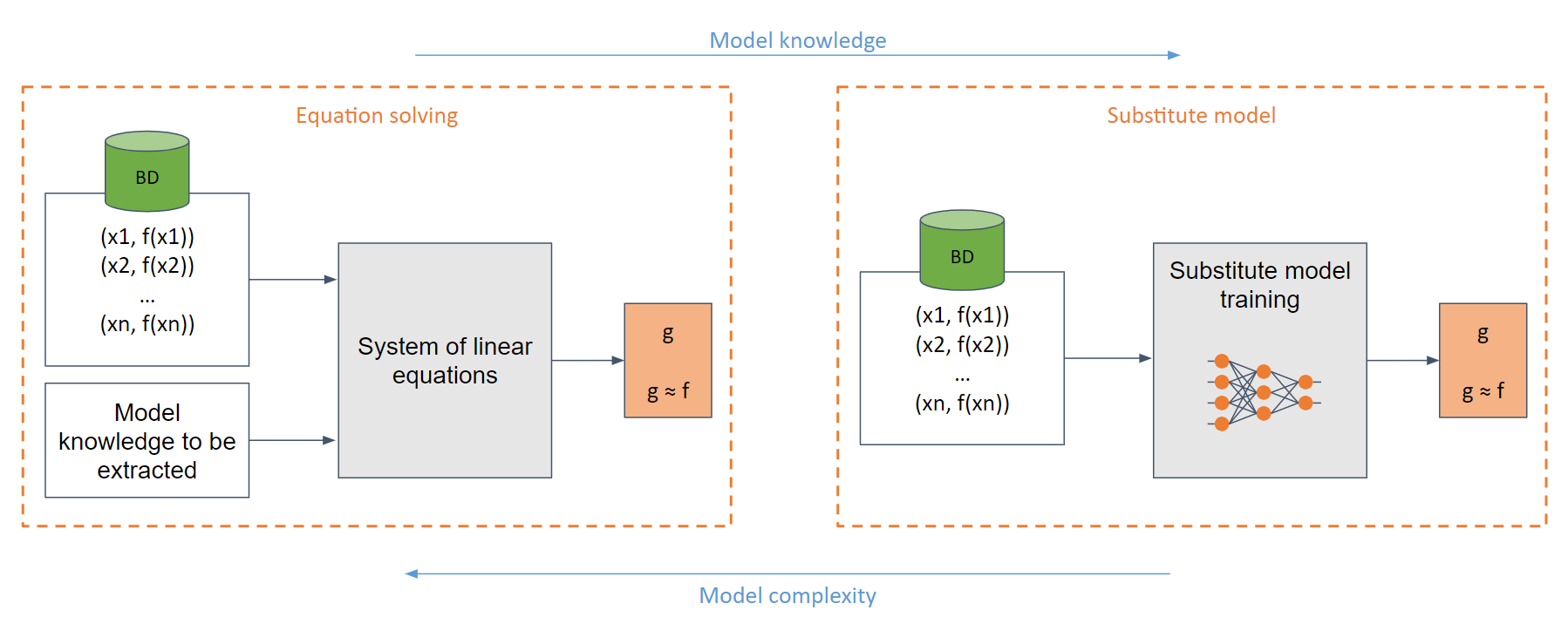
训练替代模型(在许多情况下)相当于从头开始训练模型。
计算量非常大。
攻击者在被发现之前对请求数量有限制。
输出值的舍入。
使用差异隐私。
使用合奏。
使用特定的防御措施
它们的目的是扭转机器学习模型的信息流。
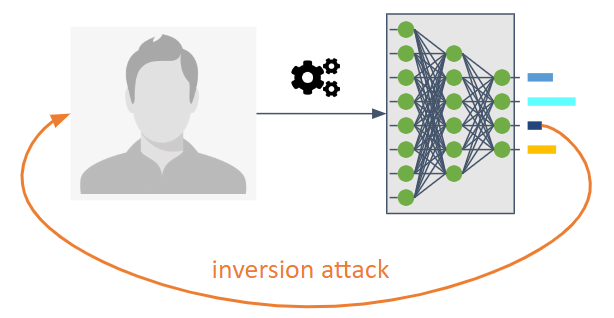
它们使对手能够知道未明确打算共享的模型。
它们使我们能够了解训练数据或信息作为模型的统计属性。
可能有三种类型:
成员推理攻击 (MIA) :攻击者试图确定样本是否被用作训练的一部分。
属性推断攻击(PIA) :攻击者旨在提取在训练阶段未明确编码为特征的统计属性。
重建:对手试图从训练集中和/或其相应的标签重建一个或多个样本。也称为倒转。
使用先进的密码学。对策包括差分隐私、同态密码学和安全多方计算。
由于过度训练和隐私的关系,使用了Dropout等正则化技术。
模型压缩已被提议作为对重建攻击的防御。
他们的目的是通过导致机器学习模型降低其准确性来破坏训练集。
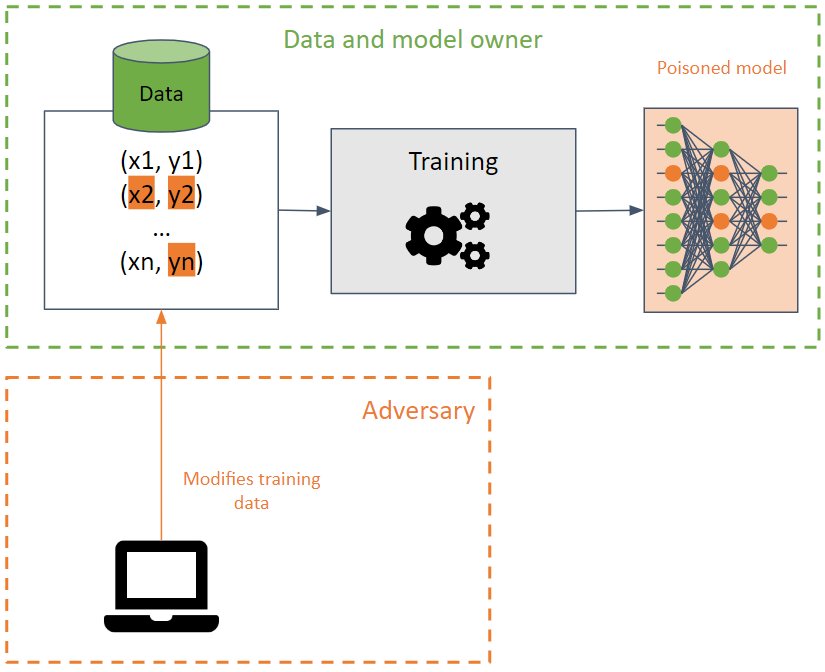
在训练数据上执行这种攻击时很难检测到,因为攻击可以使用相同的训练数据在不同模型之间传播。
攻击者试图通过修改决策边界来破坏模型的可用性,从而产生错误的预测或在模型中创建后门。在后者中,模型在大多数情况下表现正确(返回所需的预测),但对手专门创建的某些输入会产生不良结果。对手可以操纵预测结果并发起未来的攻击。
BadNet 是机器学习模型中最简单的后门类型。此外,BadNet 能够保留在模型中,即使它们针对与原始模型不同的任务(迁移学习)再次进行重新训练。
需要注意的是,公共预训练模型可能包含后门。
检测中毒数据并使用数据清理。
健全的培训方法。
具体防御。
对手向机器学习模型的输入添加一个小的扰动(以噪声的形式),使其分类错误(示例对手)。
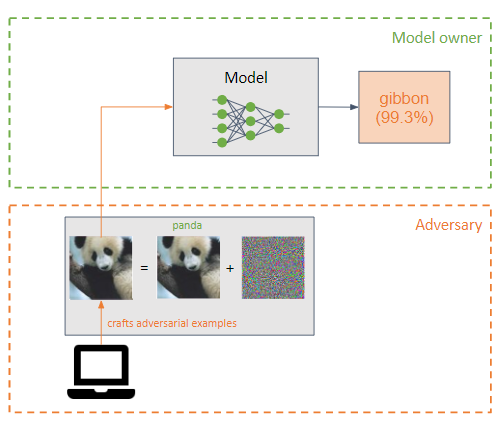
它们与投毒攻击类似,但主要区别在于逃避攻击试图利用模型在推理阶段的弱点。
对手的目标是让对手的例子无法被人类察觉。
根据对手所需的输出,可以执行两种类型的攻击:
有针对性:对手的目的是获得对其选择的预测。
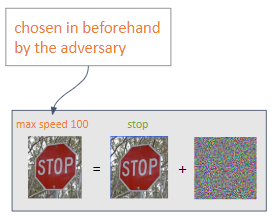
无目标:对手意图实现错误分类。

最常见的攻击是白盒攻击:
对抗性训练,包括在训练期间制作对抗性示例,使模型能够学习对抗性示例的特征,从而使模型对此类攻击更加鲁棒。
输入的转换。
梯度掩蔽/正则化。不太有效。
防御薄弱。
即时注射防御:针对即时注射的每一种实际和建议的防御措施。
Lakera PINT 基准:即时注入测试 (PINT) 基准提供了一种中立的方法来评估即时注入检测系统(如 Lakera Guard)的性能,而无需依赖这些工具可用于优化评估性能的已知公共数据集。
Devil's Inference:一种通过观察特定输入时头部注意力分布来对抗性评估 Phi-3 Instruct 模型的方法。这种方法促使模型采用“魔鬼心态”,使其能够产生暴力性质的输出。
| 姓名 | 类型 | 支持的算法 | 支持的攻击类型 | 攻击/防御 | 支持的框架 | 人气 |
|---|---|---|---|---|---|---|
| 克莱弗汉斯 | 图像 | 深度学习 | 闪避 | 攻击 | 张量流、Keras、JAX | |
| 傻瓜箱 | 图像 | 深度学习 | 闪避 | 攻击 | 张量流、PyTorch、JAX | |
| 艺术 | 任何类型(图像、表格数据、音频……) | 深度学习、SVM、LR等 | 任意(提取、推理、中毒、逃避) | 两个都 | Tensorflow、Keras、Pytorch、Scikit Learn | |
| 文本攻击 | 文本 | 深度学习 | 闪避 | 攻击 | Keras,拥抱脸 | |
| 广告灯 | 图像 | 深度学习 | 闪避 | 两个都 | --- | |
| 广告框 | 图像 | 深度学习 | 闪避 | 两个都 | PyTorch、张量流、MxNet | |
| 深鲁棒 | 图像、图表 | 深度学习 | 闪避 | 两个都 | 火炬 | |
| 仿制品 | 任何 | 任何 | 闪避 | 攻击 | --- | |
| 对抗性音频示例 | 声音的 | 深度语音 | 闪避 | 攻击 | --- |
Adversarial Robustness Toolbox 缩写为 ART,是一个开源的 Adversarial Machine Learning 库,用于测试机器学习模型的稳健性。

它采用Python开发,实现提取、反转、投毒和规避攻击与防御。
ART 支持最流行的框架:Tensorflow、Keras、PyTorch、MxNet 和 ScikitLearn 等。
它不仅限于使用使用图像作为输入的模型,还支持其他类型的数据,例如音频、视频、表格数据等。
使用 ART 学习对抗性机器学习的研讨会?
Cleverhans 是一个用于执行逃避攻击并测试图像模型上的深度学习模型的鲁棒性的库。

它是用 Python 开发的,并与 Tensorflow、Torch 和 JAX 框架集成。
它实施多种攻击,例如 L-BFGS、FGSM、JSMA、C&W 等。
人工智能用于完成恶意任务并增强经典攻击。
MiguelHernández | JoséIgnacioEscribano |


