video diffusion pytorch
0.7.0
这些烟花不存在
文字转视频,它正在发生!官方项目页面
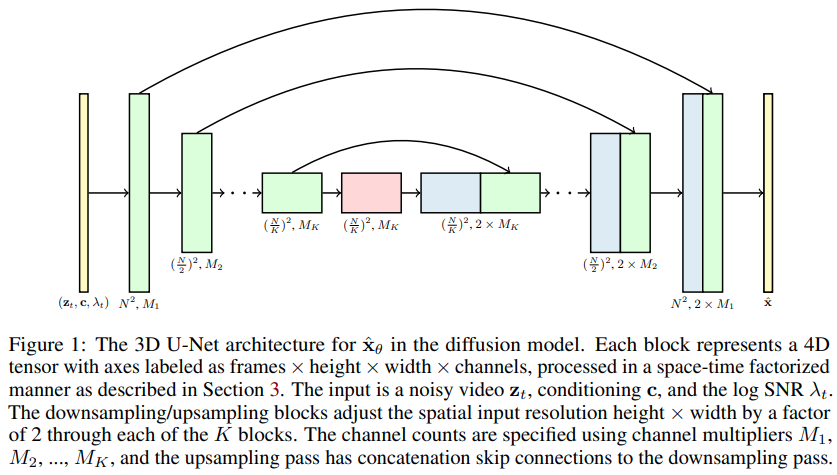
视频扩散模型的实现,Jonathan Ho 的新论文,将 DDPM 扩展到视频生成 - 在 Pytorch 中。它使用特殊的时空因子 U 网,将生成从 2D 图像扩展到 3D 视频
14k 用于困难移动 mnist(比 NUWA 收敛得更快更好)- wip

上述实验之所以成为可能,全归功于 Stability.ai 提供的资源
文本到视频合成的任何新开发都将集中在 Imagen-pytorch
$ pip install video-diffusion-pytorch import torch
from video_diffusion_pytorch import Unet3D , GaussianDiffusion
model = Unet3D (
dim = 64 ,
dim_mults = ( 1 , 2 , 4 , 8 )
)
diffusion = GaussianDiffusion (
model ,
image_size = 32 ,
num_frames = 5 ,
timesteps = 1000 , # number of steps
loss_type = 'l1' # L1 or L2
)
videos = torch . randn ( 1 , 3 , 5 , 32 , 32 ) # video (batch, channels, frames, height, width) - normalized from -1 to +1
loss = diffusion ( videos )
loss . backward ()
# after a lot of training
sampled_videos = diffusion . sample ( batch_size = 4 )
sampled_videos . shape # (4, 3, 5, 32, 32)为了对文本进行调节,他们首先通过 BERT-large 传递标记化文本来导出文本嵌入。然后你只需要像这样训练它
import torch
from video_diffusion_pytorch import Unet3D , GaussianDiffusion
model = Unet3D (
dim = 64 ,
cond_dim = 64 ,
dim_mults = ( 1 , 2 , 4 , 8 )
)
diffusion = GaussianDiffusion (
model ,
image_size = 32 ,
num_frames = 5 ,
timesteps = 1000 , # number of steps
loss_type = 'l1' # L1 or L2
)
videos = torch . randn ( 2 , 3 , 5 , 32 , 32 ) # video (batch, channels, frames, height, width)
text = torch . randn ( 2 , 64 ) # assume output of BERT-large has dimension of 64
loss = diffusion ( videos , cond = text )
loss . backward ()
# after a lot of training
sampled_videos = diffusion . sample ( cond = text )
sampled_videos . shape # (2, 3, 5, 32, 32)如果您打算使用 BERT-base 进行文本调节,您还可以直接将视频描述作为字符串传递
import torch
from video_diffusion_pytorch import Unet3D , GaussianDiffusion
model = Unet3D (
dim = 64 ,
use_bert_text_cond = True , # this must be set to True to auto-use the bert model dimensions
dim_mults = ( 1 , 2 , 4 , 8 ),
)
diffusion = GaussianDiffusion (
model ,
image_size = 32 , # height and width of frames
num_frames = 5 , # number of video frames
timesteps = 1000 , # number of steps
loss_type = 'l1' # L1 or L2
)
videos = torch . randn ( 3 , 3 , 5 , 32 , 32 ) # video (batch, channels, frames, height, width)
text = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles'
]
loss = diffusion ( videos , cond = text )
loss . backward ()
# after a lot of training
sampled_videos = diffusion . sample ( cond = text , cond_scale = 2 )
sampled_videos . shape # (3, 3, 5, 32, 32) 该存储库还包含一个方便的Trainer类,用于在gifs文件夹上进行训练。每个gif必须具有正确的尺寸image_size和num_frames 。
import torch
from video_diffusion_pytorch import Unet3D , GaussianDiffusion , Trainer
model = Unet3D (
dim = 64 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
)
diffusion = GaussianDiffusion (
model ,
image_size = 64 ,
num_frames = 10 ,
timesteps = 1000 , # number of steps
loss_type = 'l1' # L1 or L2
). cuda ()
trainer = Trainer (
diffusion ,
'./data' , # this folder path needs to contain all your training data, as .gif files, of correct image size and number of frames
train_batch_size = 32 ,
train_lr = 1e-4 ,
save_and_sample_every = 1000 ,
train_num_steps = 700000 , # total training steps
gradient_accumulate_every = 2 , # gradient accumulation steps
ema_decay = 0.995 , # exponential moving average decay
amp = True # turn on mixed precision
)
trainer . train ()样本视频(如gif文件)将定期保存到./results中,扩散模型参数也是如此。
论文中的主张之一是,通过进行因子时空注意力,可以迫使网络同时关注当前的图像和视频,从而获得更好的结果。
目前尚不清楚他们是如何实现这一目标的,但我进一步猜测。
为了将一定比例的批量视频样本的注意力吸引到当前时刻,只需在扩散前向方法上传递prob_focus_present = <prob>
loss = diffusion ( videos , cond = text , prob_focus_present = 0.5 ) # for 50% of videos, focus on the present during training
loss . backward ()如果您对如何完成此操作有更好的了解,只需打开一个 github 问题即可。
@misc { ho2022video ,
title = { Video Diffusion Models } ,
author = { Jonathan Ho and Tim Salimans and Alexey Gritsenko and William Chan and Mohammad Norouzi and David J. Fleet } ,
year = { 2022 } ,
eprint = { 2204.03458 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { Saharia2022 ,
title = { Imagen: unprecedented photorealism × deep level of language understanding } ,
author = { Chitwan Saharia*, William Chan*, Saurabh Saxena†, Lala Li†, Jay Whang†, Emily Denton, Seyed Kamyar Seyed Ghasemipour, Burcu Karagol Ayan, S. Sara Mahdavi, Rapha Gontijo Lopes, Tim Salimans, Jonathan Ho†, David Fleet†, Mohammad Norouzi* } ,
year = { 2022 }
}

