Extendible Hashing for DBMS
1.0.0
数据库系统可扩展散列的低级实现。
该方法使用目录和存储桶来散列数据,并因其计算时间的灵活性和高效性而广为人知。
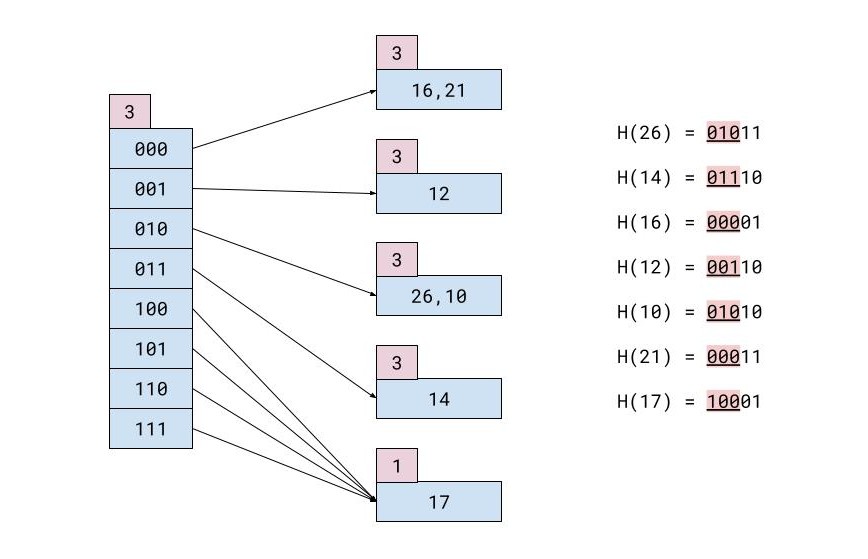
例如,您有这样的记录表:
| ID | 姓名 | 姓 | 城市 |
|---|---|---|---|
| 26 | 玛丽亚 | 科罗尼斯 | 香港 |
| 14 | 克里斯托福罗斯 | 盖塔尼斯 | 东京 |
| 16 | 玛丽安娜 | 卡沃纳里 | 迈阿密 |
| 12 | 泰奥菲洛斯 | 尼科洛普洛斯 | 伦敦 |
| 10 | 约瑟夫 | 斯温戈斯 | 东京 |
| 21 | 泰奥菲洛斯 | 米哈斯 | 雅典 |
| 17 号 | 乔戈斯 | 哈拉特西斯 | 慕尼黑 |
如果每个内存块只能有 2 条记录,则所有插入后的哈希文件将如下所示:
该程序可以由两个不同的主函数运行。第一个在文件中插入大量记录,第二个则同时创建记录并将其插入到三个不同的文件中。
测试_main1:
make main1
./build/runner
测试_主2:
make main2
./build/runner