whisper.cpp
v1.7.2
稳定:v1.7.2 /路线图|常问问题
Openai的耳语自动语音识别(ASR)模型的高性能推断:
支持的平台:
该模型的整个高级实现都包含在hisper.h和hisper.cpp中。该代码的其余部分是ggml机器学习库的一部分。
具有如此轻巧的模型实现,可以轻松地将其集成到不同的平台和应用程序中。例如,这是在iPhone 13设备上运行该模型的视频 - 完全离线,on Dempice:whinper.objc
您也可以轻松地制作自己的离线语音助手应用程序:命令
在苹果硅上,推理通过金属在GPU上完全运行:
或者您甚至可以在浏览器中直接运行:Talk.WASM
张量操作员对Apple Silicon CPU进行了大量优化。根据计算大小,使用了ARM NEON SIMD INTINSICS或CBLAS ACGELETARE框架例程。后者对于更大尺寸特别有效,因为加速框架利用现代苹果产品中可用的特殊用途AMX协处理器。
首先克隆存储库:
git clone https://github.com/ggerganov/whisper.cpp.git导航到目录:
cd whisper.cpp
然后,下载以ggml格式转换的低语模型之一。例如:
sh ./models/download-ggml-model.sh base.en现在构建主要示例并转录这样的音频文件:
# build the main example
make -j
# transcribe an audio file
./main -f samples/jfk.wav对于快速演示,只需运行make base.en :
$ make -j base.en
cc -I. -O3 -std=c11 -pthread -DGGML_USE_ACCELERATE -c ggml.c -o ggml.o
c++ -I. -I./examples -O3 -std=c++11 -pthread -c whisper.cpp -o whisper.o
c++ -I. -I./examples -O3 -std=c++11 -pthread examples/main/main.cpp whisper.o ggml.o -o main -framework Accelerate
./main -h
usage: ./main [options] file0.wav file1.wav ...
options:
-h, --help [default] show this help message and exit
-t N, --threads N [4 ] number of threads to use during computation
-p N, --processors N [1 ] number of processors to use during computation
-ot N, --offset-t N [0 ] time offset in milliseconds
-on N, --offset-n N [0 ] segment index offset
-d N, --duration N [0 ] duration of audio to process in milliseconds
-mc N, --max-context N [-1 ] maximum number of text context tokens to store
-ml N, --max-len N [0 ] maximum segment length in characters
-sow, --split-on-word [false ] split on word rather than on token
-bo N, --best-of N [5 ] number of best candidates to keep
-bs N, --beam-size N [5 ] beam size for beam search
-wt N, --word-thold N [0.01 ] word timestamp probability threshold
-et N, --entropy-thold N [2.40 ] entropy threshold for decoder fail
-lpt N, --logprob-thold N [-1.00 ] log probability threshold for decoder fail
-debug, --debug-mode [false ] enable debug mode (eg. dump log_mel)
-tr, --translate [false ] translate from source language to english
-di, --diarize [false ] stereo audio diarization
-tdrz, --tinydiarize [false ] enable tinydiarize (requires a tdrz model)
-nf, --no-fallback [false ] do not use temperature fallback while decoding
-otxt, --output-txt [false ] output result in a text file
-ovtt, --output-vtt [false ] output result in a vtt file
-osrt, --output-srt [false ] output result in a srt file
-olrc, --output-lrc [false ] output result in a lrc file
-owts, --output-words [false ] output script for generating karaoke video
-fp, --font-path [/System/Library/Fonts/Supplemental/Courier New Bold.ttf] path to a monospace font for karaoke video
-ocsv, --output-csv [false ] output result in a CSV file
-oj, --output-json [false ] output result in a JSON file
-ojf, --output-json-full [false ] include more information in the JSON file
-of FNAME, --output-file FNAME [ ] output file path (without file extension)
-ps, --print-special [false ] print special tokens
-pc, --print-colors [false ] print colors
-pp, --print-progress [false ] print progress
-nt, --no-timestamps [false ] do not print timestamps
-l LANG, --language LANG [en ] spoken language ('auto' for auto-detect)
-dl, --detect-language [false ] exit after automatically detecting language
--prompt PROMPT [ ] initial prompt
-m FNAME, --model FNAME [models/ggml-base.en.bin] model path
-f FNAME, --file FNAME [ ] input WAV file path
-oved D, --ov-e-device DNAME [CPU ] the OpenVINO device used for encode inference
-ls, --log-score [false ] log best decoder scores of tokens
-ng, --no-gpu [false ] disable GPU
sh ./models/download-ggml-model.sh base.en
Downloading ggml model base.en ...
ggml-base.en.bin 100%[========================>] 141.11M 6.34MB/s in 24s
Done! Model 'base.en' saved in 'models/ggml-base.en.bin'
You can now use it like this:
$ ./main -m models/ggml-base.en.bin -f samples/jfk.wav
===============================================
Running base.en on all samples in ./samples ...
===============================================
----------------------------------------------
[+] Running base.en on samples/jfk.wav ... (run 'ffplay samples/jfk.wav' to listen)
----------------------------------------------
whisper_init_from_file: loading model from 'models/ggml-base.en.bin'
whisper_model_load: loading model
whisper_model_load: n_vocab = 51864
whisper_model_load: n_audio_ctx = 1500
whisper_model_load: n_audio_state = 512
whisper_model_load: n_audio_head = 8
whisper_model_load: n_audio_layer = 6
whisper_model_load: n_text_ctx = 448
whisper_model_load: n_text_state = 512
whisper_model_load: n_text_head = 8
whisper_model_load: n_text_layer = 6
whisper_model_load: n_mels = 80
whisper_model_load: f16 = 1
whisper_model_load: type = 2
whisper_model_load: mem required = 215.00 MB (+ 6.00 MB per decoder)
whisper_model_load: kv self size = 5.25 MB
whisper_model_load: kv cross size = 17.58 MB
whisper_model_load: adding 1607 extra tokens
whisper_model_load: model ctx = 140.60 MB
whisper_model_load: model size = 140.54 MB
system_info: n_threads = 4 / 10 | AVX = 0 | AVX2 = 0 | AVX512 = 0 | FMA = 0 | NEON = 1 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | VSX = 0 |
main: processing 'samples/jfk.wav' (176000 samples, 11.0 sec), 4 threads, 1 processors, lang = en, task = transcribe, timestamps = 1 ...
[00:00:00.000 --> 00:00:11.000] And so my fellow Americans, ask not what your country can do for you, ask what you can do for your country.
whisper_print_timings: fallbacks = 0 p / 0 h
whisper_print_timings: load time = 113.81 ms
whisper_print_timings: mel time = 15.40 ms
whisper_print_timings: sample time = 11.58 ms / 27 runs ( 0.43 ms per run)
whisper_print_timings: encode time = 266.60 ms / 1 runs ( 266.60 ms per run)
whisper_print_timings: decode time = 66.11 ms / 27 runs ( 2.45 ms per run)
whisper_print_timings: total time = 476.31 ms
该命令下载了base.en模型转换为自定义ggml格式,并在文件夹samples中对所有.wav样本进行了推断。
对于详细的用法说明,运行: ./main -h
请注意,主要示例当前仅使用16位WAV文件运行,因此请确保在运行工具之前转换输入。例如,您可以使用这样的ffmpeg :
ffmpeg -i input.mp3 -ar 16000 -ac 1 -c:a pcm_s16le output.wav如果您想使用一些额外的音频样本,只需运行:
make -j samples
这将从Wikipedia下载更多音频文件,并通过ffmpeg将其转换为16位WAV格式。
您可以按以下方式下载并运行其他模型:
make -j tiny.en
make -j tiny
make -j base.en
make -j base
make -j small.en
make -j small
make -j medium.en
make -j medium
make -j large-v1
make -j large-v2
make -j large-v3
make -j large-v3-turbo
| 模型 | 磁盘 | mem |
|---|---|---|
| 微小的 | 75 MIB | 〜273 MB |
| 根据 | 142 MIB | 〜388 MB |
| 小的 | 466 MIB | 〜852 MB |
| 中等的 | 1.5吉布 | 〜2.1 GB |
| 大的 | 2.9吉布 | 〜3.9 GB |
whisper.cpp支持Whisper ggml模型的整数量化。量化的模型需要更少的内存和磁盘空间,并且可以更有效地处理硬件。
以下是创建和使用量化模型的步骤:
# quantize a model with Q5_0 method
make -j quantize
./quantize models/ggml-base.en.bin models/ggml-base.en-q5_0.bin q5_0
# run the examples as usual, specifying the quantized model file
./main -m models/ggml-base.en-q5_0.bin ./samples/gb0.wav在Apple硅设备上,可以通过Core ML在Apple神经发动机(ANE)上执行编码器推断。这可能会导致显着的加速 - 与仅CPU执行相比,X3的速度更快。以下是生成核心ML模型并将其与whisper.cpp一起使用的说明:
安装创建核心ML模型所需的Python依赖性:
pip install ane_transformers
pip install openai-whisper
pip install coremltoolscoremltools正确运行,请确认已安装Xcode并执行xcode-select --install以安装命令行工具。conda create -n py310-whisper python=3.10 -yconda activate py310-whisper生成核心ML模型。例如,要生成一个base.en模型,请使用:
./models/generate-coreml-model.sh base.en这将生成文件夹models/ggml-base.en-encoder.mlmodelc
构建whisper.cpp并提供核心ML支持:
# using Makefile
make clean
WHISPER_COREML=1 make -j
# using CMake
cmake -B build -DWHISPER_COREML=1
cmake --build build -j --config Release像往常一样运行示例。例如:
$ ./main -m models/ggml-base.en.bin -f samples/jfk.wav
...
whisper_init_state: loading Core ML model from 'models/ggml-base.en-encoder.mlmodelc'
whisper_init_state: first run on a device may take a while ...
whisper_init_state: Core ML model loaded
system_info: n_threads = 4 / 10 | AVX = 0 | AVX2 = 0 | AVX512 = 0 | FMA = 0 | NEON = 1 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | VSX = 0 | COREML = 1 |
...
在设备上的第一个运行速度很慢,因为ANE服务将Core ML模型编译为某些设备特定格式。接下来的运行速度更快。
有关核心ML实施的更多信息,请参阅PR#566。
在支持OpenVino的平台上,可以在OpenVino支持的设备上执行编码器推理,包括X86 CPU和Intel GPU(Integrated&Invete)。
这可能会导致编码器性能的大幅加速。以下是生成OpenVino模型并将其与whisper.cpp一起使用的说明:
首先,设置Python Virtual Env。并安装python依赖性。建议使用Python 3.10。
视窗:
cd models
python - m venv openvino_conv_env
openvino_conv_envScriptsactivate
python - m pip install -- upgrade pip
pip install - r requirements - openvino.txtLinux和MacOS:
cd models
python3 -m venv openvino_conv_env
source openvino_conv_env/bin/activate
python -m pip install --upgrade pip
pip install -r requirements-openvino.txt生成OpenVino编码器模型。例如,要生成一个base.en模型,请使用:
python convert-whisper-to-openvino.py --model base.en
这将产生ggml-base.en-coder-openvino.xml/.bin IR模型文件。建议将它们重新定位到与ggml型号相同的文件夹中,因为这是OpenVino扩展程序将在运行时搜索的默认位置。
在OpenVino支持下构建whisper.cpp :
从发行页下载OpenVino软件包。建议使用的版本为2023.0.0。
在将软件包下载和提取软件包之后,通过采购设置脚本来设置所需的环境。例如:
Linux:
source /path/to/l_openvino_toolkit_ubuntu22_2023.0.0.10926.b4452d56304_x86_64/setupvars.shWindows(CMD):
C:PathTow_openvino_toolkit_windows_2023. 0.0 . 10926. b4452d56304_x86_64 setupvars.bat然后使用CMAKE构建项目:
cmake -B build -DWHISPER_OPENVINO=1
cmake --build build -j --config Release像往常一样运行示例。例如:
$ ./main -m models/ggml-base.en.bin -f samples/jfk.wav
...
whisper_ctx_init_openvino_encoder: loading OpenVINO model from 'models/ggml-base.en-encoder-openvino.xml'
whisper_ctx_init_openvino_encoder: first run on a device may take a while ...
whisper_openvino_init: path_model = models/ggml-base.en-encoder-openvino.xml, device = GPU, cache_dir = models/ggml-base.en-encoder-openvino-cache
whisper_ctx_init_openvino_encoder: OpenVINO model loaded
system_info: n_threads = 4 / 8 | AVX = 1 | AVX2 = 1 | AVX512 = 0 | FMA = 1 | NEON = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 0 | SSE3 = 1 | VSX = 0 | COREML = 0 | OPENVINO = 1 |
...
第一次在OpenVino设备上运行的时间很慢,因为OpenVino框架将将IR(中间表示)模型汇编为特定于设备的“ Blob”。此特定于设备的斑点将在下一次运行中缓存。
有关核心ML实施的更多信息,请参阅PR#1037。
使用NVIDIA卡,模型的处理可以通过Cublas和Custom Cuda内核有效地进行。首先,请确保您已经安装了cuda :https://developer.nvidia.com/cuda-downloads
现在,在CUDA支持的情况下构建whisper.cpp :
make clean
GGML_CUDA=1 make -j
跨供应商解决方案,该解决方案允许您加速GPU上的工作量。首先,确保您的图形卡驱动程序提供了对Vulkan API的支持。
现在,在Vulkan的支持下构建whisper.cpp :
make clean
make GGML_VULKAN=1 -j
可以通过OpenBlas在CPU上加速编码器处理。首先,请确保您已经安装了openblas :https://www.openblas.net/
现在,在开放性的支持下构建whisper.cpp :
make clean
GGML_OPENBLAS=1 make -j
可以通过英特尔的数学内核库的BLA兼容接口在CPU上加速编码器处理。首先,请确保您已经安装了Intel的MKL运行时和开发软件包:https://www.intel.com/content/www/en/en/developer/tools/tools/oneapi/onemkl-download.html
现在,用英特尔MKL Blas支持构建whisper.cpp :
source /opt/intel/oneapi/setvars.sh
mkdir build
cd build
cmake -DWHISPER_MKL=ON ..
WHISPER_MKL=1 make -j
Ascend NPU通过CANN和AI核提供推理加速度。
首先,检查是否支持您的Ascend NPU设备:
经过验证的设备
| 上升NPU | 地位 |
|---|---|
| Atlas 300T A2 | 支持 |
然后,确保您已经安装了CANN toolkit 。推荐了Cann的持久版本。
现在,在CANN支持下构建whisper.cpp :
mkdir build
cd build
cmake .. -D GGML_CANN=on
make -j
例如,像往常一样运行推理示例:
./build/bin/main -f samples/jfk.wav -m models/ggml-base.en.bin -t 8
笔记:
Verified devices 。 我们有两个可用于此项目的Docker图像:
ghcr.io/ggerganov/whisper.cpp:main :此图像包含主要可执行文件以及curl和ffmpeg 。 (平台: linux/amd64 , linux/arm64 )ghcr.io/ggerganov/whisper.cpp:main-cuda :与main相同,但在CUDA支持的情况下进行了编译。 (平台: linux/amd64 ) # download model and persist it in a local folder
docker run -it --rm
-v path/to/models:/models
whisper.cpp:main " ./models/download-ggml-model.sh base /models "
# transcribe an audio file
docker run -it --rm
-v path/to/models:/models
-v path/to/audios:/audios
whisper.cpp:main " ./main -m /models/ggml-base.bin -f /audios/jfk.wav "
# transcribe an audio file in samples folder
docker run -it --rm
-v path/to/models:/models
whisper.cpp:main " ./main -m /models/ggml-base.bin -f ./samples/jfk.wav " 您可以为Whisper.cpp安装预构建的二进制文件,也可以使用柯南从源构建它。使用以下命令:
conan install --requires="whisper-cpp/[*]" --build=missing
有关如何使用柯南的详细说明,请参考柯南文档。
这是在MacBook M1 Pro上大约半分钟的3:24分钟演讲的另一个示例medium.en
$ ./main -m models/ggml-medium.en.bin -f samples/gb1.wav -t 8
whisper_init_from_file: loading model from 'models/ggml-medium.en.bin'
whisper_model_load: loading model
whisper_model_load: n_vocab = 51864
whisper_model_load: n_audio_ctx = 1500
whisper_model_load: n_audio_state = 1024
whisper_model_load: n_audio_head = 16
whisper_model_load: n_audio_layer = 24
whisper_model_load: n_text_ctx = 448
whisper_model_load: n_text_state = 1024
whisper_model_load: n_text_head = 16
whisper_model_load: n_text_layer = 24
whisper_model_load: n_mels = 80
whisper_model_load: f16 = 1
whisper_model_load: type = 4
whisper_model_load: mem required = 1720.00 MB (+ 43.00 MB per decoder)
whisper_model_load: kv self size = 42.00 MB
whisper_model_load: kv cross size = 140.62 MB
whisper_model_load: adding 1607 extra tokens
whisper_model_load: model ctx = 1462.35 MB
whisper_model_load: model size = 1462.12 MB
system_info: n_threads = 8 / 10 | AVX = 0 | AVX2 = 0 | AVX512 = 0 | FMA = 0 | NEON = 1 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | VSX = 0 |
main: processing 'samples/gb1.wav' (3179750 samples, 198.7 sec), 8 threads, 1 processors, lang = en, task = transcribe, timestamps = 1 ...
[00:00:00.000 --> 00:00:08.000] My fellow Americans, this day has brought terrible news and great sadness to our country.
[00:00:08.000 --> 00:00:17.000] At nine o'clock this morning, Mission Control in Houston lost contact with our Space Shuttle Columbia.
[00:00:17.000 --> 00:00:23.000] A short time later, debris was seen falling from the skies above Texas.
[00:00:23.000 --> 00:00:29.000] The Columbia's lost. There are no survivors.
[00:00:29.000 --> 00:00:32.000] On board was a crew of seven.
[00:00:32.000 --> 00:00:39.000] Colonel Rick Husband, Lieutenant Colonel Michael Anderson, Commander Laurel Clark,
[00:00:39.000 --> 00:00:48.000] Captain David Brown, Commander William McCool, Dr. Kultna Shavla, and Ilan Ramon,
[00:00:48.000 --> 00:00:52.000] a colonel in the Israeli Air Force.
[00:00:52.000 --> 00:00:58.000] These men and women assumed great risk in the service to all humanity.
[00:00:58.000 --> 00:01:03.000] In an age when space flight has come to seem almost routine,
[00:01:03.000 --> 00:01:07.000] it is easy to overlook the dangers of travel by rocket
[00:01:07.000 --> 00:01:12.000] and the difficulties of navigating the fierce outer atmosphere of the Earth.
[00:01:12.000 --> 00:01:18.000] These astronauts knew the dangers, and they faced them willingly,
[00:01:18.000 --> 00:01:23.000] knowing they had a high and noble purpose in life.
[00:01:23.000 --> 00:01:31.000] Because of their courage and daring and idealism, we will miss them all the more.
[00:01:31.000 --> 00:01:36.000] All Americans today are thinking as well of the families of these men and women
[00:01:36.000 --> 00:01:40.000] who have been given this sudden shock and grief.
[00:01:40.000 --> 00:01:45.000] You're not alone. Our entire nation grieves with you,
[00:01:45.000 --> 00:01:52.000] and those you love will always have the respect and gratitude of this country.
[00:01:52.000 --> 00:01:56.000] The cause in which they died will continue.
[00:01:56.000 --> 00:02:04.000] Mankind is led into the darkness beyond our world by the inspiration of discovery
[00:02:04.000 --> 00:02:11.000] and the longing to understand. Our journey into space will go on.
[00:02:11.000 --> 00:02:16.000] In the skies today, we saw destruction and tragedy.
[00:02:16.000 --> 00:02:22.000] Yet farther than we can see, there is comfort and hope.
[00:02:22.000 --> 00:02:29.000] In the words of the prophet Isaiah, "Lift your eyes and look to the heavens
[00:02:29.000 --> 00:02:35.000] who created all these. He who brings out the starry hosts one by one
[00:02:35.000 --> 00:02:39.000] and calls them each by name."
[00:02:39.000 --> 00:02:46.000] Because of His great power and mighty strength, not one of them is missing.
[00:02:46.000 --> 00:02:55.000] The same Creator who names the stars also knows the names of the seven souls we mourn today.
[00:02:55.000 --> 00:03:01.000] The crew of the shuttle Columbia did not return safely to earth,
[00:03:01.000 --> 00:03:05.000] yet we can pray that all are safely home.
[00:03:05.000 --> 00:03:13.000] May God bless the grieving families, and may God continue to bless America.
[00:03:13.000 --> 00:03:19.000] [Silence]
whisper_print_timings: fallbacks = 1 p / 0 h
whisper_print_timings: load time = 569.03 ms
whisper_print_timings: mel time = 146.85 ms
whisper_print_timings: sample time = 238.66 ms / 553 runs ( 0.43 ms per run)
whisper_print_timings: encode time = 18665.10 ms / 9 runs ( 2073.90 ms per run)
whisper_print_timings: decode time = 13090.93 ms / 549 runs ( 23.85 ms per run)
whisper_print_timings: total time = 32733.52 ms
这是对麦克风对音频实时推断进行实时推断的幼稚例子。流工具每半秒钟采样音频,并连续运行转录。问题10中提供了更多信息。
make stream -j
./stream -m ./models/ggml-base.en.bin -t 8 --step 500 --length 5000添加--print-colors参数将使用实验性颜色编码策略打印抄录文本,以高度或低信心突出单词:
./main -m models/ggml-base.en.bin -f samples/gb0.wav --print-colors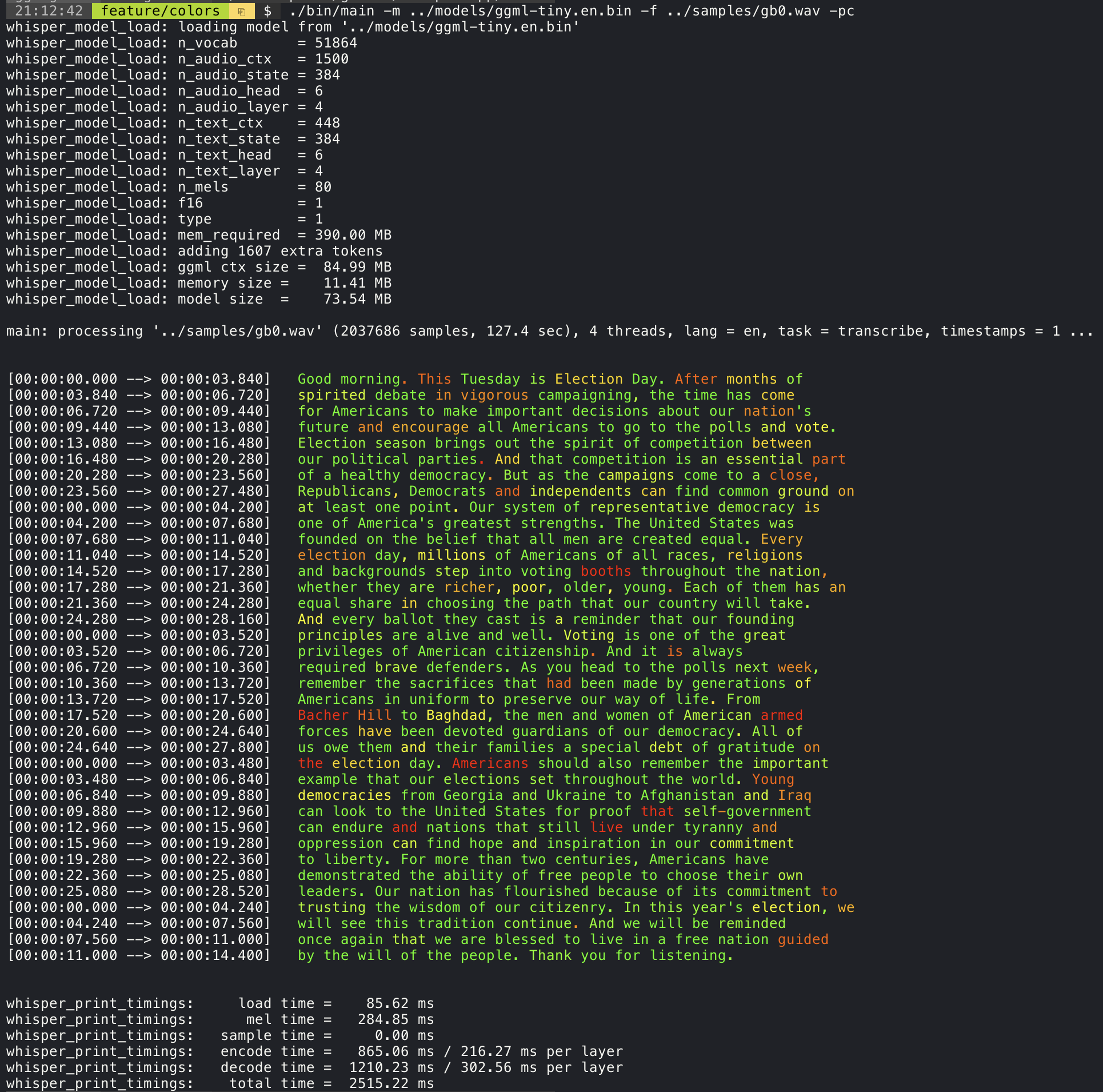
例如,要将线长度限制在最多16个字符中,只需添加-ml 16 :
$ ./main -m ./models/ggml-base.en.bin -f ./samples/jfk.wav -ml 16
whisper_model_load: loading model from './models/ggml-base.en.bin'
...
system_info: n_threads = 4 / 10 | AVX2 = 0 | AVX512 = 0 | NEON = 1 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 |
main: processing './samples/jfk.wav' (176000 samples, 11.0 sec), 4 threads, 1 processors, lang = en, task = transcribe, timestamps = 1 ...
[00:00:00.000 --> 00:00:00.850] And so my
[00:00:00.850 --> 00:00:01.590] fellow
[00:00:01.590 --> 00:00:04.140] Americans, ask
[00:00:04.140 --> 00:00:05.660] not what your
[00:00:05.660 --> 00:00:06.840] country can do
[00:00:06.840 --> 00:00:08.430] for you, ask
[00:00:08.430 --> 00:00:09.440] what you can do
[00:00:09.440 --> 00:00:10.020] for your
[00:00:10.020 --> 00:00:11.000] country.
--max-len参数可用于获得单词级的时间戳。只需使用-ml 1 :
$ ./main -m ./models/ggml-base.en.bin -f ./samples/jfk.wav -ml 1
whisper_model_load: loading model from './models/ggml-base.en.bin'
...
system_info: n_threads = 4 / 10 | AVX2 = 0 | AVX512 = 0 | NEON = 1 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 |
main: processing './samples/jfk.wav' (176000 samples, 11.0 sec), 4 threads, 1 processors, lang = en, task = transcribe, timestamps = 1 ...
[00:00:00.000 --> 00:00:00.320]
[00:00:00.320 --> 00:00:00.370] And
[00:00:00.370 --> 00:00:00.690] so
[00:00:00.690 --> 00:00:00.850] my
[00:00:00.850 --> 00:00:01.590] fellow
[00:00:01.590 --> 00:00:02.850] Americans
[00:00:02.850 --> 00:00:03.300] ,
[00:00:03.300 --> 00:00:04.140] ask
[00:00:04.140 --> 00:00:04.990] not
[00:00:04.990 --> 00:00:05.410] what
[00:00:05.410 --> 00:00:05.660] your
[00:00:05.660 --> 00:00:06.260] country
[00:00:06.260 --> 00:00:06.600] can
[00:00:06.600 --> 00:00:06.840] do
[00:00:06.840 --> 00:00:07.010] for
[00:00:07.010 --> 00:00:08.170] you
[00:00:08.170 --> 00:00:08.190] ,
[00:00:08.190 --> 00:00:08.430] ask
[00:00:08.430 --> 00:00:08.910] what
[00:00:08.910 --> 00:00:09.040] you
[00:00:09.040 --> 00:00:09.320] can
[00:00:09.320 --> 00:00:09.440] do
[00:00:09.440 --> 00:00:09.760] for
[00:00:09.760 --> 00:00:10.020] your
[00:00:10.020 --> 00:00:10.510] country
[00:00:10.510 --> 00:00:11.000] .
有关此方法的更多信息,请参见此处:#1058
示例用法:
# download a tinydiarize compatible model
. / models / download - ggml - model . sh small . en - tdrz
# run as usual, adding the "-tdrz" command-line argument
. / main - f . / samples / a13 . wav - m . / models / ggml - small . en - tdrz . bin - tdrz
...
main : processing './samples/a13.wav' ( 480000 samples , 30.0 sec ), 4 threads , 1 processors , lang = en , task = transcribe , tdrz = 1 , timestamps = 1 ...
...
[ 00 : 00 : 00.000 - - > 00 : 00 : 03.800 ] Okay Houston , we ' ve had a problem here . [ SPEAKER_TURN ]
[ 00 : 00 : 03.800 - - > 00 : 00 : 06.200 ] This is Houston . Say again please . [ SPEAKER_TURN ]
[ 00 : 00 : 06.200 - - > 00 : 00 : 08.260 ] Uh Houston we ' ve had a problem .
[ 00 : 00 : 08.260 - - > 00 : 00 : 11.320 ] We ' ve had a main beam up on a volt . [ SPEAKER_TURN ]
[ 00 : 00 : 11.320 - - > 00 : 00 : 13.820 ] Roger main beam interval . [ SPEAKER_TURN ]
[ 00 : 00 : 13.820 - - > 00 : 00 : 15.100 ] Uh uh [ SPEAKER_TURN ]
[ 00 : 00 : 15.100 - - > 00 : 00 : 18.020 ] So okay stand , by thirteen we ' re looking at it . [ SPEAKER_TURN ]
[ 00 : 00 : 18.020 - - > 00 : 00 : 25.740 ] Okay uh right now uh Houston the uh voltage is uh is looking good um .
[ 00 : 00 : 27.620 - - > 00 : 00 : 29.940 ] And we had a a pretty large bank or so .主要示例为卡拉OK型电影的输出提供了支持,该电影当前的单词被突出显示。使用-wts参数并运行生成的bash脚本。这需要安装ffmpeg 。
这里有一些“典型”示例:
./main -m ./models/ggml-base.en.bin -f ./samples/jfk.wav -owts
source ./samples/jfk.wav.wts
ffplay ./samples/jfk.wav.mp4./main -m ./models/ggml-base.en.bin -f ./samples/mm0.wav -owts
source ./samples/mm0.wav.wts
ffplay ./samples/mm0.wav.mp4./main -m ./models/ggml-base.en.bin -f ./samples/gb0.wav -owts
source ./samples/gb0.wav.wts
ffplay ./samples/gb0.wav.mp4使用脚本/bench-wts.sh脚本以以下格式生成视频:
./scripts/bench-wts.sh samples/jfk.wav
ffplay ./samples/jfk.wav.all.mp4为了对跨不同系统配置的推理的性能进行客观比较,请使用基准工具。该工具只需运行模型的编码部分,并打印执行它花费了多少时间。结果总结在以下GitHub问题中:
基准结果
此外,还提供了带有不同型号和音频文件的whisper.cpp的脚本。
您可以使用以下命令运行它,默认情况下它将与模型文件夹中的任何标准模型运行。
python3 scripts/bench.py -f samples/jfk.wav -t 2,4,8 -p 1,2它用python编写,目的是易于修改并扩展为您的基准用例。
它以基准测试的结果输出一个CSV文件。
ggml格式原始型号被转换为自定义二进制格式。这允许将所需的所有内容包装到一个文件中:
您可以使用型号/下载 - ggml-model.sh脚本或手动从此处下载转换的模型:
有关更多详细信息,请参见转换脚本模型/convert-pt-to-ggml.py或型号/readme.md。
示例文件夹中的不同项目有各种示例。一些示例甚至可以使用WebAssembly在浏览器中运行。检查一下!
| 例子 | 网络 | 描述 |
|---|---|---|
| 主要的 | 窃窃私语 | 使用耳语翻译和转录音频的工具 |
| 长椅 | 板凳 | 基准在机器上的耳语表现 |
| 溪流 | 流 | 原始麦克风捕获的实时转录 |
| 命令 | 命令 | 从麦克风接收语音命令的基本语音助手示例 |
| wchess | wchess.wasm | 语音控制的国际象棋 |
| 讲话 | 说话 | 与GPT-2机器人交谈 |
| 谈话训练 | 与美洲驼交谈 | |
| hisper.objc | 使用hisper.cpp的iOS移动应用程序 | |
| 窃窃私语 | Swiftui iOS / macOS应用使用hisper.cpp | |
| hisper.android | 使用hisper.cpp的android移动应用程序 | |
| 窃窃私语 | Neovim的语音到文本插件 | |
| 生成-karaoke.sh | 辅助脚本可以轻松生成原始音频捕获的卡拉OK视频 | |
| livestream.sh | 直播音频转录 | |
| yt-wsp.sh | 下载 +转录和/或翻译任何VOD(原始) | |
| 服务器 | http转录服务器,带有oai like api |
如果您对该项目有任何反馈,请随时使用讨论部分并打开一个新主题。您可以使用该节目并告诉类别分享使用whisper.cpp的项目。如果您有问题,请确保检查常见问题(#126)讨论。


