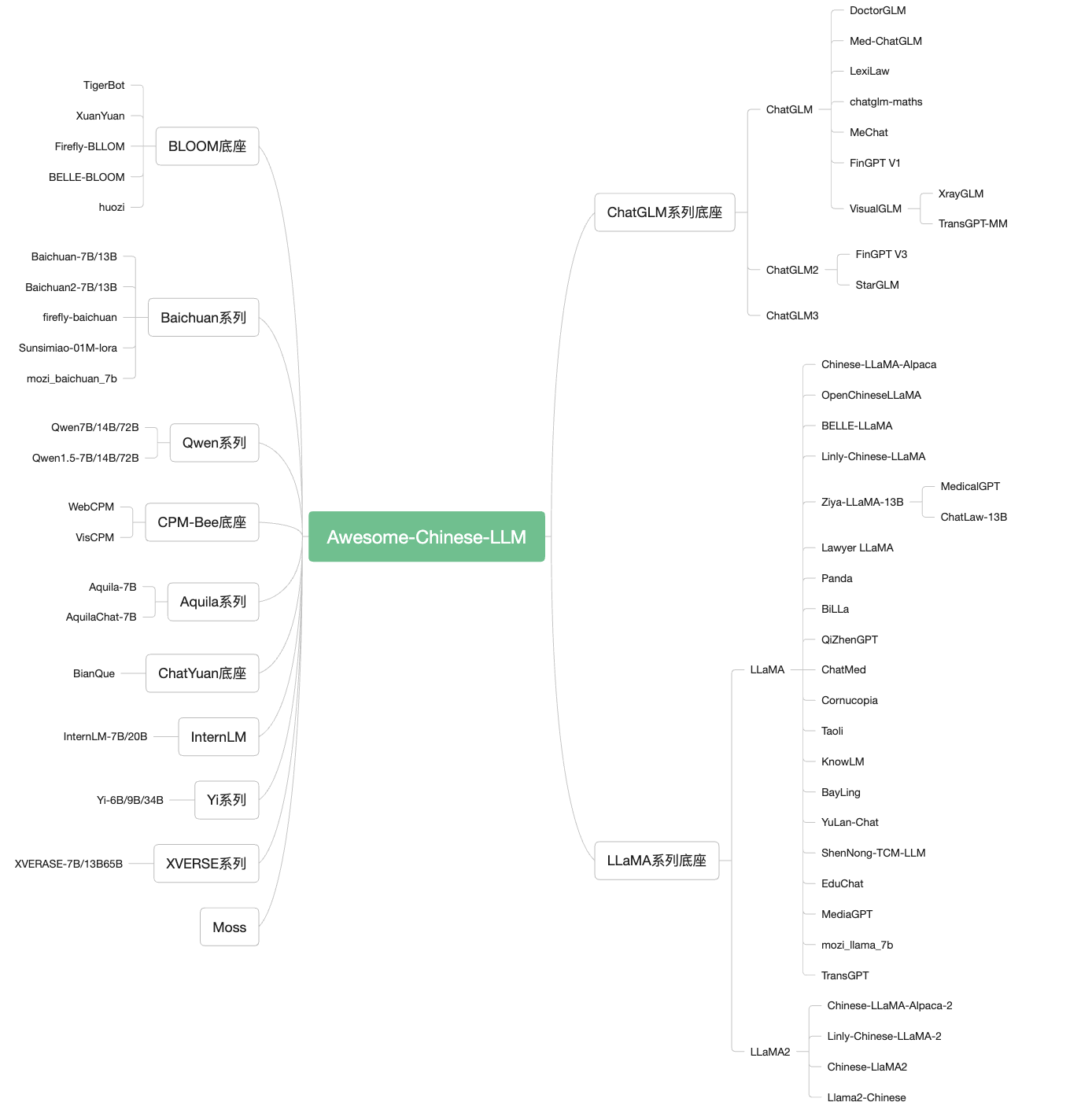
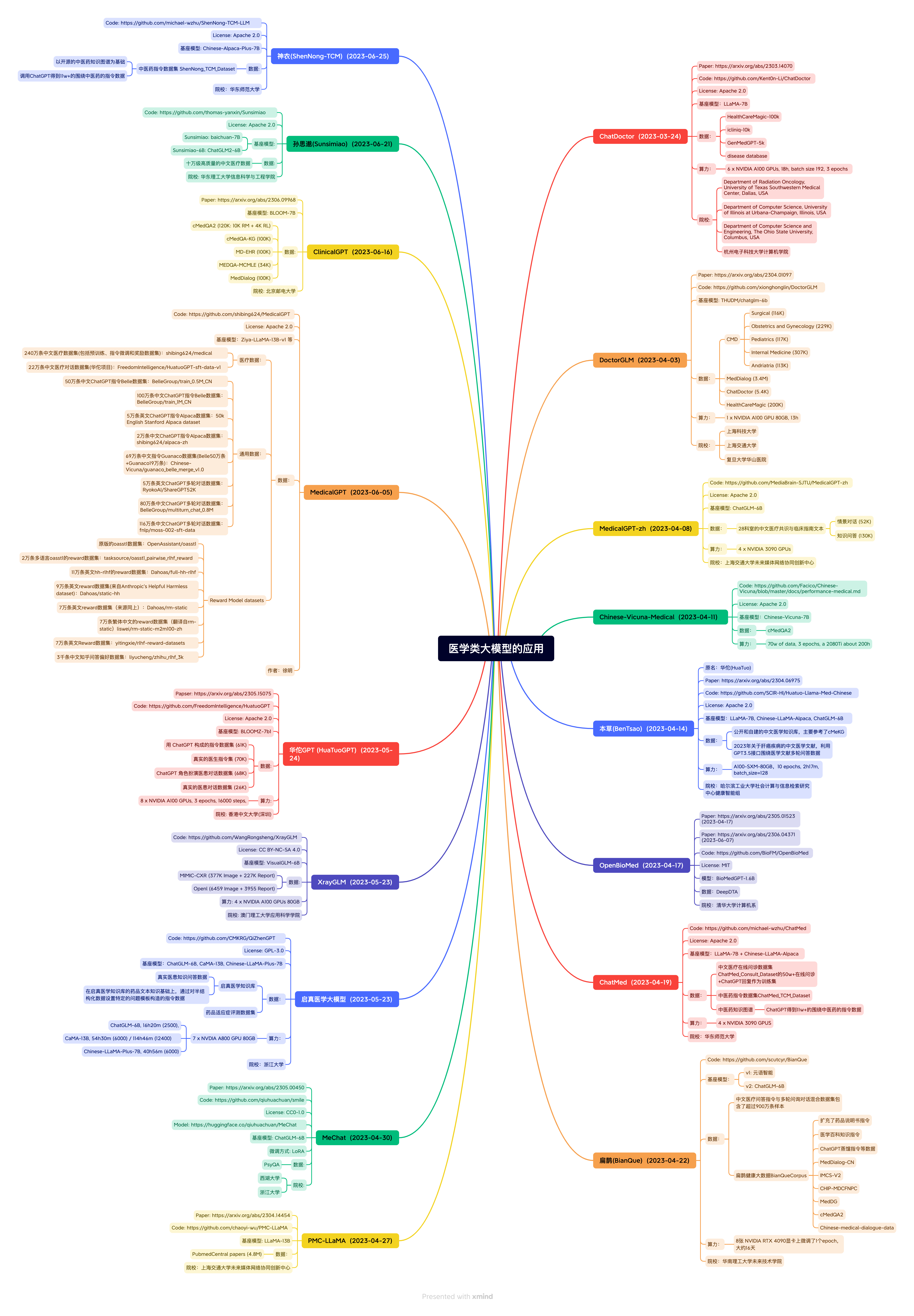
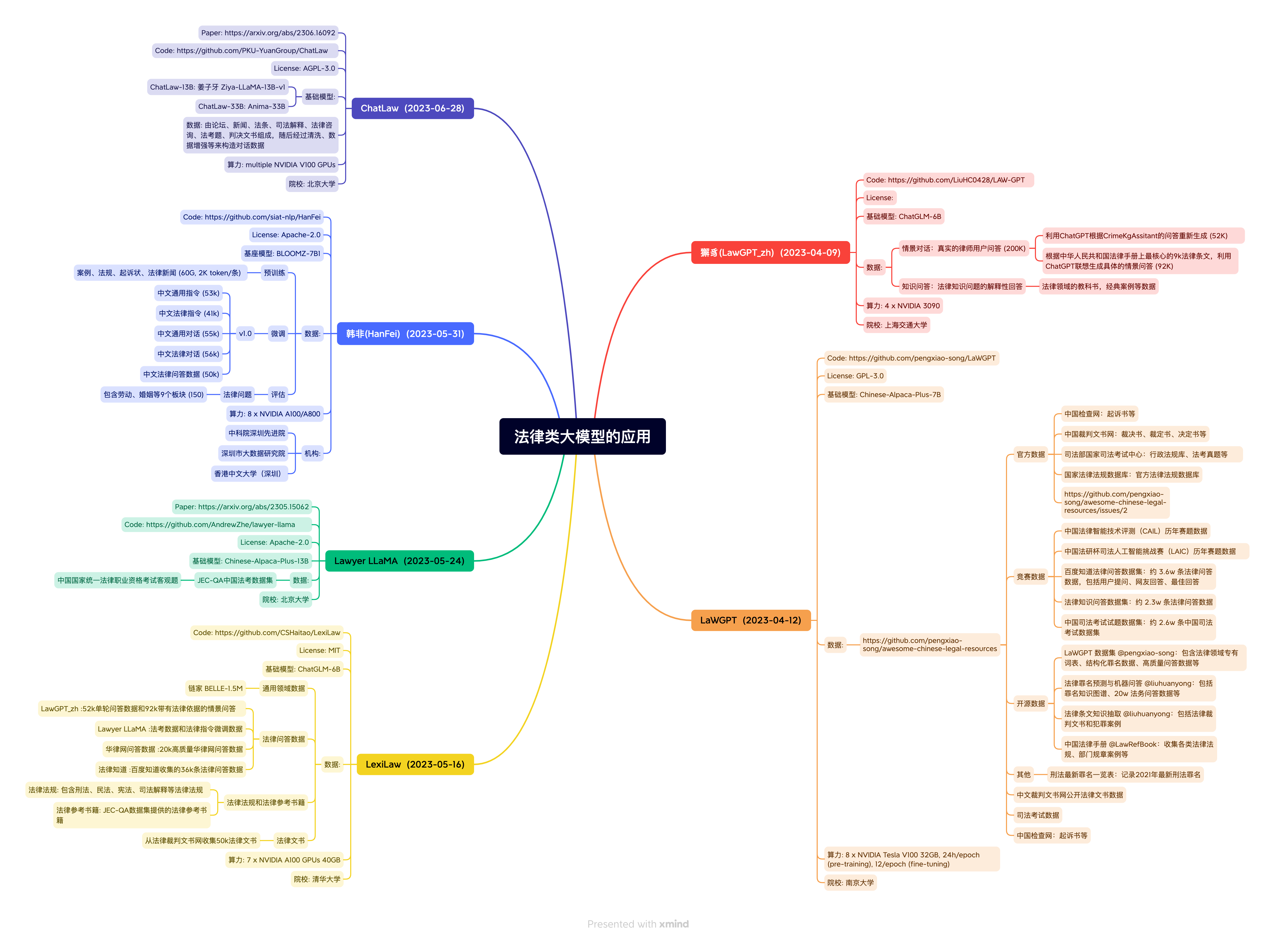
An Awesome Collection for LLM in Chinese
收集和梳理中文LLM相关
自ChatGPT为代表的大语言模型(Large Language Model, LLM)出现以后,由于其惊人的类通用人工智能(AGI)的能力,掀起了新一轮自然语言处理领域的研究和应用的浪潮。尤其是以ChatGLM、LLaMA等平民玩家都能跑起来的较小规模的LLM开源之后,业界涌现了非常多基于LLM的二次微调或应用的案例。本项目旨在收集和梳理中文LLM相关的开源模型、应用、数据集及教程等资料,目前收录的资源已达100+个!
如果本项目能给您带来一点点帮助,麻烦点个️吧~
同时也欢迎大家贡献本项目未收录的开源模型、应用、数据集等。提供新的仓库信息请发起PR,并按照本项目的格式提供仓库链接、star数,简介等相关信息,感谢~
常见底座模型细节概览:
底座
包含模型
模型参数大小
训练token数
训练最大长度
是否可商用
ChatGLM
ChatGLM/2/3/4 Base&Chat
6B
1T/1.4
2K/32K
可商用
LLaMA
LLaMA/2/3 Base&Chat
7B/8B/13B/33B/70B
1T/2T
2k/4k
部分可商用
Baichuan
Baichuan/2 Base&Chat
7B/13B
1.2T/1.4T
4k
可商用
Qwen
Qwen/1.5/2/2.5 Base&Chat&VL
7B/14B/32B/72B/110B
2.2T/3T/18T
8k/32k
可商用
BLOOM
BLOOM
1B/7B/176B-MT
1.5T
2k
可商用
Aquila
Aquila/2 Base/Chat
7B/34B
-
2k
可商用
InternLM
InternLM/2/2.5 Base/Chat/VL
7B/20B
-
200k
可商用
Mixtral
Base&Chat
8x7B
-
32k
可商用
Yi
Base&Chat
6B/9B/34B
3T
200k
可商用
DeepSeek
Base&Chat
1.3B/7B/33B/67B
-
4k
可商用
XVERSE
Base&Chat
7B/13B/65B/A4.2B
2.6T/3.2T
8k/16k/256k
可商用
目录
目录
1. 模型
2. 应用
2.1 垂直领域微调
医疗
法律
金融
教育
科技
电商
网络安全
农业
2.2 LangChain应用
2.3 其他应用
3. 数据集
4. LLM训练微调框架
5. LLM推理部署框架
6. LLM评测
7. LLM教程
LLM基础知识
提示工程教程
LLM应用教程
LLM实战教程
8. 相关仓库
Star History
1. 模型
1.1 文本LLM模型
ChatGLM:
地址:https://github.com/THUDM/ChatGLM-6B
简介:中文领域效果最好的开源底座模型之一,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持
ChatGLM2-6B
地址:https://github.com/THUDM/ChatGLM2-6B
简介:基于开源中英双语对话模型 ChatGLM-6B 的第二代版本,在保留了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之上,引入了GLM 的混合目标函数,经过了 1.4T 中英标识符的预训练与人类偏好对齐训练;基座模型的上下文长度扩展到了 32K,并在对话阶段使用 8K 的上下文长度训练;基于 Multi-Query Attention 技术实现更高效的推理速度和更低的显存占用;允许商业使用。
ChatGLM3-6B
地址:https://github.com/THUDM/ChatGLM3
简介:ChatGLM3-6B 是 ChatGLM3 系列中的开源模型,在保留了前两代模型对话流畅、部署门槛低等众多优秀特性的基础上,ChatGLM3-6B 引入了如下特性:更强大的基础模型: ChatGLM3-6B 的基础模型 ChatGLM3-6B-Base 采用了更多样的训练数据、更充分的训练步数和更合理的训练策略;更完整的功能支持: ChatGLM3-6B 采用了全新设计的 Prompt 格式,除正常的多轮对话外。同时原生支持工具调用(Function Call)、代码执行(Code Interpreter)和 Agent 任务等复杂场景;更全面的开源序列: 除了对话模型 ChatGLM3-6B 外,还开源了基础模型 ChatGLM3-6B-Base、长文本对话模型 ChatGLM3-6B-32K。以上所有权重对学术研究完全开放,在填写问卷进行登记后亦允许免费商业使用。
GLM-4
地址:https://github.com/THUDM/GLM-4
简介:GLM-4-9B 是智谱 AI 推出的最新一代预训练模型 GLM-4 系列中的开源版本。 在语义、数学、推理、代码和知识等多方面的数据集测评中, GLM-4-9B 及其人类偏好对齐的版本 GLM-4-9B-Chat 均表现出超越 Llama-3-8B 的卓越性能。除了能进行多轮对话,GLM-4-9B-Chat 还具备网页浏览、代码执行、自定义工具调用(Function Call)和长文本推理(支持最大 128K 上下文)等高级功能。本代模型增加了多语言支持,支持包括日语,韩语,德语在内的 26 种语言。我们还推出了支持 1M 上下文长度(约 200 万中文字符)的 GLM-4-9B-Chat-1M 模型和基于 GLM-4-9B 的多模态模型 GLM-4V-9B。GLM-4V-9B 具备 1120 * 1120 高分辨率下的中英双语多轮对话能力,在中英文综合能力、感知推理、文字识别、图表理解等多方面多模态评测中,GLM-4V-9B 表现出超越 GPT-4-turbo-2024-04-09、Gemini 1.0 Pro、Qwen-VL-Max 和 Claude 3 Opus 的卓越性能。
Qwen/Qwen1.5/Qwen2/Qwen2.5
地址:https://github.com/QwenLM
简介:通义千问 是阿里云研发的通义千问大模型系列模型,包括参数规模为18亿(1.8B)、70亿(7B)、140亿(14B)、720亿(72B)和1100亿(110B)。各个规模的模型包括基础模型Qwen,以及对话模型。数据集包括文本和代码等多种数据类型,覆盖通用领域和专业领域,能支持8~32K的上下文长度,针对插件调用相关的对齐数据做了特定优化,当前模型能有效调用插件以及升级为Agent。
InternLM
地址:https://github.com/InternLM/InternLM-techreport
简介:商汤科技、上海AI实验室联合香港中文大学、复旦大学和上海交通大学发布千亿级参数大语言模型“书生·浦语”(InternLM)。据悉,“书生·浦语”具有1040亿参数,基于“包含1.6万亿token的多语种高质量数据集”训练而成。
InternLM2
地址:https://github.com/InternLM/InternLM
简介:商汤科技、上海AI实验室联合香港中文大学、复旦大学和上海交通大学发布千亿级参数大语言模型“书生·浦语”(InternLM2)。InternLM2 在数理、代码、对话、创作等各方面能力都获得了长足进步,综合性能达到开源模型的领先水平。InternLM2 包含两种模型规格:7B 和 20B。7B 为轻量级的研究和应用提供了一个轻便但性能不俗的模型,20B 模型的综合性能更为强劲,可以有效支持更加复杂的实用场景。
DeepSeek-V2
地址:https://github.com/deepseek-ai/DeepSeek-V2
简介:DeepSeek-V2:强大、经济、高效的专家混合语言模型
Baichuan-7B
地址:https://github.com/baichuan-inc/Baichuan-7B
简介:由百川智能开发的一个开源可商用的大规模预训练语言模型。基于Transformer结构,在大约1.2万亿tokens上训练的70亿参数模型,支持中英双语,上下文窗口长度为4096。在标准的中文和英文权威benchmark(C-EVAL/MMLU)上均取得同尺寸最好的效果。
Baichuan-13B
地址:https://github.com/baichuan-inc/baichuan-13B
简介:Baichuan-13B 是由百川智能继 Baichuan-7B 之后开发的包含 130 亿参数的开源可商用的大规模语言模型,在权威的中文和英文 benchmark 上均取得同尺寸最好的效果。该项目发布包含有预训练 (Baichuan-13B-Base) 和对齐 (Baichuan-13B-Chat) 两个版本。
Baichuan2
地址:https://github.com/baichuan-inc/Baichuan2
简介:由百川智能推出的新一代开源大语言模型,采用 2.6 万亿 Tokens 的高质量语料训练,在多个权威的中文、英文和多语言的通用、领域 benchmark上取得同尺寸最佳的效果,发布包含有7B、13B的Base和经过PPO训练的Chat版本,并提供了Chat版本的4bits量化。
XVERSE-7B
地址:https://github.com/xverse-ai/XVERSE-7B
简介:由深圳元象科技自主研发的支持多语言的大语言模型,支持 8K 的上下文长度(Context Length),使用 2.6 万亿 token 的高质量、多样化的数据对模型进行充分训练,支持中、英、俄、西等 40 多种语言。并包含GGUF、GPTQ量化版本的模型,支持在llama.cpp、vLLM在MacOS/Linux/Windows系统上推理。
XVERSE-13B
地址:https://github.com/xverse-ai/XVERSE-13B
简介:由深圳元象科技自主研发的支持多语言的大语言模型,支持 8K 的上下文长度(Context Length),使用 3.2 万亿 token 的高质量、多样化的数据对模型进行充分训练,支持中、英、俄、西等 40 多种语言。包含长序列对话模型 XVERSE-13B-256K ,该版本模型最大支持 256K 的上下文窗口长度,约 25w 字的输入内容,可以协助进行文献总结、报告分析等任务。并包含GGUF、GPTQ量化版本的模型,支持在llama.cpp、vLLM在MacOS/Linux/Windows系统上推理。
XVERSE-65B
地址:https://github.com/xverse-ai/XVERSE-65B
简介:由深圳元象科技自主研发的支持多语言的大语言模型,支持 16K 的上下文长度(Context Length),使用 2.6 万亿 token 的高质量、多样化的数据对模型进行充分训练,支持中、英、俄、西等 40 多种语言。包含增量预训练到 3.2 万亿 token 的 XVERSE-65B-2 模型。并包含GGUF、GPTQ量化版本的模型,支持在llama.cpp、vLLM在MacOS/Linux/Windows系统上推理。
XVERSE-MoE-A4.2B
地址:https://github.com/xverse-ai/XVERSE-MoE-A4.2B
简介:由深圳元象科技自主研发的支持多语言的大语言模型(Large Language Model),使用混合专家模型(MoE,Mixture-of-experts)架构,模型的总参数规模为 258 亿,实际激活的参数量为 42 亿,支持 8K 的上下文长度(Context Length),使用 3.2 万亿 token 的高质量、多样化的数据对模型进行充分训练,支持中、英、俄、西等 40 多种语言。
Skywork
地址:https://github.com/SkyworkAI/Skywork
简介:该项目开源了天工系列模型,该系列模型在3.2TB高质量多语言和代码数据上进行预训练,开源了包括模型参数,训练数据,评估数据,评估方法。具体包括Skywork-13B-Base模型、Skywork-13B-Chat模型、Skywork-13B-Math模型和Skywork-13B-MM模型,以及每个模型的量化版模型,以支持用户在消费级显卡进行部署和推理。
Yi
地址:https://github.com/01-ai/Yi
简介:该项目开源了Yi-6B和Yi-34B等模型,该系列模型最长可支持200K的超长上下文窗口版本,可以处理约40万汉字超长文本输入,理解超过1000页的PDF文档。
Chinese-LLaMA-Alpaca:
地址:https://github.com/ymcui/Chinese-LLaMA-Alpaca
简介:中文LLaMA&Alpaca大语言模型+本地CPU/GPU部署,在原版LLaMA的基础上扩充了中文词表并使用了中文数据进行二次预训练
Chinese-LLaMA-Alpaca-2:
地址:https://github.com/ymcui/Chinese-LLaMA-Alpaca-2
简介:该项目将发布中文LLaMA-2 & Alpaca-2大语言模型,基于可商用的LLaMA-2进行二次开发。
Chinese-LlaMA2:
地址:https://github.com/michael-wzhu/Chinese-LlaMA2
简介:该项目基于可商用的LLaMA-2进行二次开发决定在次开展Llama 2的中文汉化工作,包括Chinese-LlaMA2: 对Llama 2进行中文预训练;第一步:先在42G中文预料上进行训练;后续将会加大训练规模;Chinese-LlaMA2-chat: 对Chinese-LlaMA2进行指令微调和多轮对话微调,以适应各种应用场景和多轮对话交互。同时我们也考虑更为快速的中文适配方案:Chinese-LlaMA2-sft-v0: 采用现有的开源中文指令微调或者是对话数据,对LlaMA-2进行直接微调 (将于近期开源)。
Llama2-Chinese:
地址:https://github.com/FlagAlpha/Llama2-Chinese
简介:该项目专注于Llama2模型在中文方面的优化和上层建设,基于大规模中文数据,从预训练开始对Llama2模型进行中文能力的持续迭代升级。
OpenChineseLLaMA:
地址:https://github.com/OpenLMLab/OpenChineseLLaMA
简介:基于 LLaMA-7B 经过中文数据集增量预训练产生的中文大语言模型基座,对比原版 LLaMA,该模型在中文理解能力和生成能力方面均获得较大提升,在众多下游任务中均取得了突出的成绩。
BELLE:
地址:https://github.com/LianjiaTech/BELLE
简介:开源了基于BLOOMZ和LLaMA优化后的一系列模型,同时包括训练数据、相关模型、训练代码、应用场景等,也会持续评估不同训练数据、训练算法等对模型表现的影响。
Panda:
地址:https://github.com/dandelionsllm/pandallm
简介:开源了基于LLaMA-7B, -13B, -33B, -65B 进行中文领域上的持续预训练的语言模型, 使用了接近 15M 条数据进行二次预训练。
Robin (罗宾):
地址:https://github.com/OptimalScale/LMFlow
简介:Robin (罗宾)是香港科技大学LMFlow团队开发的中英双语大语言模型。仅使用180K条数据微调得到的Robin第二代模型,在Huggingface榜单上达到了第一名的成绩。LMFlow支持用户快速训练个性化模型,仅需单张3090和5个小时即可微调70亿参数定制化模型。
Fengshenbang-LM:
地址:https://github.com/IDEA-CCNL/Fengshenbang-LM
简介:Fengshenbang-LM(封神榜大模型)是IDEA研究院认知计算与自然语言研究中心主导的大模型开源体系,该项目开源了姜子牙通用大模型V1,是基于LLaMa的130亿参数的大规模预训练模型,具备翻译,编程,文本分类,信息抽取,摘要,文案生成,常识问答和数学计算等能力。除姜子牙系列模型之外,该项目还开源了太乙、二郎神系列等模型。
BiLLa:
地址:https://github.com/Neutralzz/BiLLa
简介:该项目开源了推理能力增强的中英双语LLaMA模型。模型的主要特性有:较大提升LLaMA的中文理解能力,并尽可能减少对原始LLaMA英文能力的损伤;训练过程增加较多的任务型数据,利用ChatGPT生成解析,强化模型理解任务求解逻辑;全量参数更新,追求更好的生成效果。
Moss:
地址:https://github.com/OpenLMLab/MOSS
简介:支持中英双语和多种插件的开源对话语言模型,MOSS基座语言模型在约七千亿中英文以及代码单词上预训练得到,后续经过对话指令微调、插件增强学习和人类偏好训练具备多轮对话能力及使用多种插件的能力。
Luotuo-Chinese-LLM:
地址:https://github.com/LC1332/Luotuo-Chinese-LLM
简介:囊括了一系列中文大语言模型开源项目,包含了一系列基于已有开源模型(ChatGLM, MOSS, LLaMA)进行二次微调的语言模型,指令微调数据集等。
Linly:
地址:https://github.com/CVI-SZU/Linly
简介:提供中文对话模型 Linly-ChatFlow 、中文基础模型 Linly-Chinese-LLaMA 及其训练数据。 中文基础模型以 LLaMA 为底座,利用中文和中英平行增量预训练。项目汇总了目前公开的多语言指令数据,对中文模型进行了大规模指令跟随训练,实现了 Linly-ChatFlow 对话模型。
Firefly:
地址:https://github.com/yangjianxin1/Firefly
简介:Firefly(流萤) 是一个开源的中文大语言模型项目,开源包括数据、微调代码、多个基于Bloom、baichuan等微调好的模型等;支持全量参数指令微调、QLoRA低成本高效指令微调、LoRA指令微调;支持绝大部分主流的开源大模型,如百川baichuan、Ziya、Bloom、LLaMA等。持lora与base model进行权重合并,推理更便捷。
ChatYuan
地址:https://github.com/clue-ai/ChatYuan
简介:元语智能发布的一系列支持中英双语的功能型对话语言大模型,在微调数据、人类反馈强化学习、思维链等方面进行了优化。
ChatRWKV:
地址:https://github.com/BlinkDL/ChatRWKV
简介:开源了一系列基于RWKV架构的Chat模型(包括英文和中文),发布了包括Raven,Novel-ChnEng,Novel-Ch与Novel-ChnEng-ChnPro等模型,可以直接闲聊及进行诗歌,小说等创作,包括7B和14B等规模的模型。
CPM-Bee
地址:https://github.com/OpenBMB/CPM-Bee
简介:一个完全开源、允许商用的百亿参数中英文基座模型。它采用Transformer自回归架构(auto-regressive),在超万亿(trillion)高质量语料上进行预训练,拥有强大的基础能力。开发者和研究者可以在CPM-Bee基座模型的基础上在各类场景进行适配来以创建特定领域的应用模型。
TigerBot
地址:https://github.com/TigerResearch/TigerBot
简介:一个多语言多任务的大规模语言模型(LLM),开源了包括模型:TigerBot-7B, TigerBot-7B-base,TigerBot-180B,基本训练和推理代码,100G预训练数据,涵盖金融、法律、百科的领域数据以及API等。
Aquila
地址:https://github.com/FlagAI-Open/FlagAI/tree/master/examples/Aquila
简介:由智源研究院发布,Aquila语言大模型在技术上继承了GPT-3、LLaMA等的架构设计优点,替换了一批更高效的底层算子实现、重新设计实现了中英双语的tokenizer,升级了BMTrain并行训练方法,是在中英文高质量语料基础上从0开始训练的,通过数据质量的控制、多种训练的优化方法,实现在更小的数据集、更短的训练时间,获得比其它开源模型更优的性能。也是首个支持中英双语知识、支持商用许可协议、符合国内数据合规需要的大规模开源语言模型。
Aquila2
地址:https://github.com/FlagAI-Open/Aquila2
简介:由智源研究院发布,Aquila2 系列,包括基础语言模型 Aquila2-7B,Aquila2-34B 和 Aquila2-70B-Expr ,对话模型 AquilaChat2-7B ,AquilaChat2-34B 和 AquilaChat2-70B-Expr,长文本对话模型AquilaChat2-7B-16k 和 AquilaChat2-34B-16。
Anima
地址:https://github.com/lyogavin/Anima
简介:由艾写科技开发的一个开源的基于QLoRA的33B中文大语言模型,该模型基于QLoRA的Guanaco 33B模型使用Chinese-Vicuna项目开放的训练数据集guanaco_belle_merge_v1.0进行finetune训练了10000个step,基于Elo rating tournament评估效果较好。
KnowLM
地址:https://github.com/zjunlp/KnowLM
简介:KnowLM项目旨在发布开源大模型框架及相应模型权重以助力减轻知识谬误问题,包括大模型的知识难更新及存在潜在的错误和偏见等。该项目一期发布了基于Llama的抽取大模型智析,使用中英文语料对LLaMA(13B)进行进一步全量预训练,并基于知识图谱转换指令技术对知识抽取任务进行优化。
BayLing
地址:https://github.com/ictnlp/BayLing
简介:一个具有增强的跨语言对齐的通用大模型,由中国科学院计算技术研究所自然语言处理团队开发。百聆(BayLing)以LLaMA为基座模型,探索了以交互式翻译任务为核心进行指令微调的方法,旨在同时完成语言间对齐以及与人类意图对齐,将LLaMA的生成能力和指令跟随能力从英语迁移到其他语言(中文)。在多语言翻译、交互翻译、通用任务、标准化考试的测评中,百聆在中文/英语中均展现出更好的表现。百聆提供了在线的内测版demo,以供大家体验。
YuLan-Chat
地址:https://github.com/RUC-GSAI/YuLan-Chat
简介:YuLan-Chat是中国人民大学GSAI研究人员开发的基于聊天的大语言模型。它是在LLaMA的基础上微调开发的,具有高质量的英文和中文指令。 YuLan-Chat可以与用户聊天,很好地遵循英文或中文指令,并且可以在量化后部署在GPU(A800-80G或RTX3090)上。
PolyLM
地址:https://github.com/DAMO-NLP-MT/PolyLM
简介:一个在6400亿个词的数据上从头训练的多语言语言模型,包括两种模型大小(1.7B和13B)。PolyLM覆盖中、英、俄、西、法、葡、德、意、荷、波、阿、土、希伯来、日、韩、泰、越、印尼等语种,特别是对亚洲语种更友好。
huozi
地址:https://github.com/HIT-SCIR/huozi
简介:由哈工大自然语言处理研究所多位老师和学生参与开发的一个开源可商用的大规模预训练语言模型。 该模型基于 Bloom 结构的70 亿参数模型,支持中英双语,上下文窗口长度为 2048,同时还开源了基于RLHF训练的模型以及全人工标注的16.9K中文偏好数据集。
YaYi
地址:https://github.com/wenge-research/YaYi
简介:雅意大模型在百万级人工构造的高质量领域数据上进行指令微调得到,训练数据覆盖媒体宣传、舆情分析、公共安全、金融风控、城市治理等五大领域,上百种自然语言指令任务。雅意大模型从预训练初始化权重到领域模型的迭代过程中,我们逐步增强了它的中文基础能力和领域分析能力,并增加了多轮对话和部分插件能力。同时,经过数百名用户内测过程中持续不断的人工反馈优化,进一步提升了模型性能和安全性。已开源基于 LLaMA 2 的中文优化模型版本,探索适用于中文多领域任务的最新实践。
YAYI2
地址:https://github.com/wenge-research/YAYI2
简介:YAYI 2 是中科闻歌研发的新一代开源大语言模型,包括 Base 和 Chat 版本,参数规模为 30B。YAYI2-30B 是基于 Transformer 的大语言模型,采用了超过 2 万亿 Tokens 的高质量、多语言语料进行预训练。针对通用和特定领域的应用场景,我们采用了百万级指令进行微调,同时借助人类反馈强化学习方法,以更好地使模型与人类价值观对齐。本次开源的模型为 YAYI2-30B Base 模型。
Yuan-2.0
地址:https://github.com/IEIT-Yuan/Yuan-2.0
简介:该项目开源了由浪潮信息发布的新一代基础语言大模型,具体开源了全部的3个模型源2.0-102B,源2.0-51B和源2.0-2B。并且提供了预训练,微调,推理服务的相关脚本。源2.0是在源1.0的基础上,利用更多样的高质量预训练数据和指令微调数据集,令模型在语义、数学、推理、代码、知识等不同方面具备更强的理解能力。
Chinese-Mixtral-8x7B
地址:https://github.com/HIT-SCIR/Chinese-Mixtral-8x7B
简介:该项目基于Mixtral-8x7B稀疏混合专家模型进行了中文扩词表增量预训练,开源了Chinese-Mixtral-8x7B扩词表模型以及训练代码。该模型的的中文编解码效率较原模型显著提高。同时通过在大规模开源语料上进行的增量预训练,该模型具备了强大的中文生成和理解能力。
BlueLM
地址:https://github.com/vivo-ai-lab/BlueLM
簡介:BlueLM 是由 vivo AI 全球研究院自主研发的大规模预训练语言模型,本次发布包含 7B 基础 (base) 模型和 7B 对话 (chat) 模型,同时我们开源了支持 32K 的长文本基础 (base) 模型和对话 (chat) 模型。
TuringMM
地址:https://github.com/lightyear-turing/TuringMM-34B-Chat
簡介:TuringMM-34B-Chat是一款开源的中英文Chat模型,由北京光年无限科技有限公司基于Yi-34B开源模型、基于14w的精标教育数据进行sft微调以及15W对齐数据进行DPO偏好学习得到的一个微调模型。
Orion
地址:https://github.com/OrionStarAI/Orion
簡介:Orion-14B-Base是一个具有140亿参数的多语种大模型,该模型在一个包含2.5万亿token的多样化数据集上进行了训练,涵盖了中文、英语、日语、韩语等多种语言。
OrionStar-Yi-34B-Chat
地址:https://github.com/OrionStarAI/OrionStar-Yi-34B-Chat
簡介:OrionStar-Yi-34B-Chat 是猎户星空基于零一万物开源的Yi-34B模型,使用 15W+ 的高质量语料训练而来微调大模型,旨在为大模型社区用户提供卓越的交互体验。
MiniCPM
地址:https://github.com/OpenBMB/MiniCPM
简介:MiniCPM 是面壁智能与清华大学自然语言处理实验室共同开源的系列端侧大模型,主体语言模型 MiniCPM-2B 仅有 24亿(2.4B)的非词嵌入参数量, 总计2.7B参数量。
Mengzi3
地址:https://github.com/Langboat/Mengzi3
简介:Mengzi3 8B/13B模型基于Llama架构,语料精选自网页、百科、社交、媒体、新闻,以及高质量的开源数据集。通过在万亿tokens上进行多语言语料的继续训练,模型的中文能力突出并且兼顾多语言能力。
1.2 多模态LLM模型
2. 应用
2.1 垂直领域微调
医疗
法律
金融
教育
桃李(Taoli):
地址:https://github.com/blcuicall/taoli
简介:一个在国际中文教育领域数据上进行了额外训练的模型。项目基于目前国际中文教育领域流通的500余册国际中文教育教材与教辅书、汉语水平考试试题以及汉语学习者词典等,构建了国际中文教育资源库,构造了共计 88000 条的高质量国际中文教育问答数据集,并利用收集到的数据对模型进行指令微调,让模型习得将知识应用到具体场景中的能力。
EduChat:
地址:https://github.com/icalk-nlp/EduChat
简介:该项目华东师范大学计算机科学与技术学院的EduNLP团队研发,主要研究以预训练大模型为基底的教育对话大模型相关技术,融合多样化的教育垂直领域数据,辅以指令微调、价值观对齐等方法,提供教育场景下自动出题、作业批改、情感支持、课程辅导、高考咨询等丰富功能,服务于广大老师、学生和家长群体,助力实现因材施教、公平公正、富有温度的智能教育。
chatglm-maths:
地址:https://github.com/yongzhuo/chatglm-maths
简介:基于chatglm-6b微调/LORA/PPO/推理的数学题解题大模型, 样本为自动生成的整数/小数加减乘除运算, 可gpu/cpu部署,开源了训练数据集等。
MathGLM:
地址:https://github.com/THUDM/MathGLM
简介:该项目由THUDM研发,开源了多个能进行20亿参数可以进行准确多位算术运算的语言模型,同时开源了可用于算术运算微调的数据集。
QiaoBan:
地址:https://github.com/HIT-SCIR-SC/QiaoBan
简介:该项目旨在构建一个面向儿童情感陪伴的大模型,这个仓库包含:用于指令微调的对话数据/data,巧板的训练代码,训练配置文件,使用巧板进行对话的示例代码(TODO,checkpoint将发布至huggingface)。
科技
天文大语言模型StarGLM:
地址:https://github.com/Yu-Yang-Li/StarGLM
简介:基于ChatGLM训练了天文大语言模型,以期缓解大语言模型在部分天文通用知识和前沿变星领域的幻觉现象,为接下来可处理天文多模态任务、部署于望远镜阵列的观测Agent——司天大脑(数据智能处理)打下基础。
TransGPT·致远:
地址:https://github.com/DUOMO/TransGPT
简介:开源交通大模型,主要致力于在真实交通行业中发挥实际价值。它能够实现交通情况预测、智能咨询助手、公共交通服务、交通规划设计、交通安全教育、协助管理、交通事故报告和分析、自动驾驶辅助系统等功能。
Mozi:
地址:https://github.com/gmftbyGMFTBY/science-llm
简介:该项目开源了基于LLaMA和Baichuan的科技论文大模型,可以用于科技文献的问答和情感支持。
电商
EcomGPT
地址:https://github.com/Alibaba-NLP/EcomGPT
简介:一个由阿里发布的面向电商领域的语言模型,该模型基于BLOOMZ在电商指令微调数据集上微调得到,人工评估在12个电商评测数据集上超过ChatGPT。
网络安全
SecGPT
地址:https://github.com/Clouditera/secgpt
简介:开项目开源了网络安全大模型,该模型基于Baichuan-13B采用Lora做预训练和SFT训练,此外该项目还开源了相关预训练和指令微调数据集等资源。
农业
后稷(AgriMa):
地址:https://github.com/zhiweihu1103/AgriMa
简介:首个中文开源农业大模型是由山西大学、山西农业大学与The Fin AI联合研发,以Baichuan为底座,基于海量有监督农业领域相关数据微调,具备广泛的农业知识和智能分析能力,该模型旨在为农业领域提供全面而高效的信息处理和决策支持。
稷丰(AgriAgent):
地址:https://github.com/zhiweihu1103/AgriAgent
简介:首个开源中文农业多模态大模型是由山西农业大学研发,以MiniCPM-Llama3-V 2.5为底座,能够从图像、文本、气象数据等多源信息中提取有用信息,为农业生产提供全面、精准的智能化解决方案。我们致力于将稷丰应用于作物健康监测、病虫害识别、土壤肥力分析、农田管理优化等多个方面,帮助农民提升生产效率,减少资源浪费,促进农业的可持续发展。
2.2 LangChain应用
2.3 其他应用
wenda:
地址:https://github.com/wenda-LLM/wenda
简介:一个LLM调用平台。为小模型外挂知识库查找和设计自动执行动作,实现不亚于于大模型的生成能力。
JittorLLMs:
地址:https://github.com/Jittor/JittorLLMs
简介:计图大模型推理库:笔记本没有显卡也能跑大模型,具有成本低,支持广,可移植,速度快等优势。
LMFlow:
地址:https://github.com/OptimalScale/LMFlow
简介:LMFlow是香港科技大学LMFlow团队开发的大模型微调工具箱。LMFlow工具箱具有可扩展性强、高效、方便的特性。LMFlow仅使用180K条数据微调,即可得到在Huggingface榜单第一名的Robin模型。LMFlow支持用户快速训练个性化模型,仅需单张3090和5个小时即可微调70亿参数定制化模型。
fastllm:
地址:https://github.com/ztxz16/fastllm
简介:纯c++的全平台llm加速库,chatglm-6B级模型单卡可达10000+token / s,支持moss, chatglm, baichuan模型,手机端流畅运行。
WebCPM
地址:https://github.com/thunlp/WebCPM
简介:一个支持可交互网页搜索的中文大模型。
GPT Academic:
地址:https://github.com/binary-husky/gpt_academic
简介:为GPT/GLM提供图形交互界面,特别优化论文阅读润色体验,支持并行问询多种LLM模型,支持清华chatglm等本地模型。兼容复旦MOSS, llama, rwkv, 盘古等。
ChatALL:
地址:https://github.com/sunner/ChatALL
简介:ChatALL(中文名:齐叨)可以把一条指令同时发给多个 AI,可以帮助用户发现最好的回答。
CreativeChatGLM:
地址:https://github.com/ypwhs/CreativeChatGLM
简介:可以使用修订和续写的功能来生成创意内容,可以使用“续写”按钮帮 ChatGLM 想一个开头,并让它继续生成更多的内容,你可以使用“修订”按钮修改最后一句 ChatGLM 的回复。
docker-llama2-chat:
地址:https://github.com/soulteary/docker-llama2-chat
简介:开源了一个只需要三步就可以上手LLaMA2的快速部署方案。
ChatGLM2-Voice-Cloning:
地址:https://github.com/KevinWang676/ChatGLM2-Voice-Cloning
简介:实现了一个可以和喜欢的角色沉浸式对话的应用,主要采用ChatGLM2+声音克隆+视频对话的技术。
Flappy
地址:https://github.com/pleisto/flappy
简介:一个产品级面向所有程序员的LLM SDK,
LazyLLM
地址:https://github.com/LazyAGI/LazyLLM
简介:LazyLLM是一款低代码构建多Agent大模型应用的开发工具,协助开发者用极低的成本构建复杂的AI应用,并可以持续的迭代优化效果。LazyLLM提供了更为灵活的应用功能定制方式,并实现了一套轻量级网管机制来支持一键部署多Agent应用,支持流式输出,兼容多个Iaas平台,且支持对应用中的模型进行持续微调。
MemFree
地址:https://github.com/memfreeme/memfree
简介:MemFree 是一个开源的 Hybrid AI 搜索引擎,可以同时对您的个人知识库(如书签、笔记、文档等)和互联网进行搜索, 为你提供最佳答案。MemFree 支持自托管的极速无服务器向量数据库,支持自托管的极速Local Embedding and Rerank Service,支持一键部署。
3. 数据集
预训练数据集
MNBVC
地址:https://github.com/esbatmop/MNBVC
数据集说明:超大规模中文语料集,不但包括主流文化,也包括各个小众文化甚至火星文的数据。MNBVC数据集包括新闻、作文、小说、书籍、杂志、论文、台词、帖子、wiki、古诗、歌词、商品介绍、笑话、糗事、聊天记录等一切形式的纯文本中文数据。数据均来源于互联网收集,且在持续更新中。
WuDaoCorporaText
地址:https://data.baai.ac.cn/details/WuDaoCorporaText
数据集说明:WuDaoCorpora是北京智源人工智能研究院(智源研究院)构建的大规模、高质量数据集,用于支撑大模型训练研究。目前由文本、对话、图文对、视频文本对四部分组成,分别致力于构建微型语言世界、提炼对话核心规律、打破图文模态壁垒、建立视频文字关联,为大模型训练提供坚实的数据支撑。
CLUECorpus2020
地址:https://github.com/CLUEbenchmark/CLUECorpus2020
数据集说明:通过对Common Crawl的中文部分进行语料清洗,最终得到100GB的高质量中文预训练语料,可直接用于预训练、语言模型或语言生成任务以及专用于简体中文NLP任务的小词表。
WanJuan-1.0
地址:https://opendatalab.org.cn/WanJuan1.0
数据集说明:书生·万卷1.0为书生·万卷多模态语料库的首个开源版本,包含文本数据集、图文数据集、视频数据集三部分,数据总量超过2TB。 目前,书生·万卷1.0已被应用于书生·多模态、书生·浦语的训练。通过对高质量语料的“消化”,书生系列模型在语义理解、知识问答、视觉理解、视觉问答等各类生成式任务表现出的优异性能。
seq-monkey-data
SFT数据集
RefGPT:基于RefGPT生成大量真实和定制的对话数据集
地址:https://github.com/DA-southampton/RedGPT
数据集说明:包括RefGPT-Fact和RefGPT-Code两部分,其中RefGPT-Fact给出了5万中文的关于事实性知识的多轮对话,RefGPT-Code给出了3.9万中文编程相关的多轮对话数据。
COIG
地址:https://huggingface.co/datasets/BAAI/COIG
数据集说明:维护了一套无害、有用且多样化的中文指令语料库,包括一个人工验证翻译的通用指令语料库、一个人工标注的考试指令语料库、一个人类价值对齐指令语料库、一个多轮反事实修正聊天语料库和一个 leetcode 指令语料库。
generated_chat_0.4M:
地址:https://huggingface.co/datasets/BelleGroup/generated_chat_0.4M
数据集说明:包含约40万条由BELLE项目生成的个性化角色对话数据,包含角色介绍。但此数据集是由ChatGPT产生的,未经过严格校验,题目或解题过程可能包含错误。
alpaca_chinese_dataset:
地址:https://github.com/hikariming/alpaca_chinese_dataset
数据集说明:根据斯坦福开源的alpaca数据集进行中文翻译,并再制造一些对话数据
Alpaca-CoT:
地址:https://github.com/PhoebusSi/Alpaca-CoT
数据集说明:统一了丰富的IFT数据(如CoT数据,目前仍不断扩充)、多种训练效率方法(如lora,p-tuning)以及多种LLMs,三个层面上的接口,打造方便研究人员上手的LLM-IFT研究平台。
pCLUE:
地址:https://github.com/CLUEbenchmark/pCLUE
数据集说明:基于提示的大规模预训练数据集,用于多任务学习和零样本学习。包括120万训练数据,73个Prompt,9个任务。
firefly-train-1.1M:
地址:https://huggingface.co/datasets/YeungNLP/firefly-train-1.1M
数据集说明:23个常见的中文数据集,对于每个任务,由人工书写若干种指令模板,保证数据的高质量与丰富度,数据量为115万
BELLE-data-1.5M:
地址:https://github.com/LianjiaTech/BELLE/tree/main/data/1.5M
数据集说明:通过self-instruct生成,使用了中文种子任务,以及openai的text-davinci-003接口,涉及175个种子任务
Chinese Scientific Literature Dataset:
地址:https://github.com/ydli-ai/csl
数据集说明:中文科学文献数据集(CSL),包含 396,209 篇中文核心期刊论文元信息 (标题、摘要、关键词、学科、门类)以及简单的prompt
Chinese medical dialogue data:
地址:https://github.com/Toyhom/Chinese-medical-dialogue-data
数据集说明:中文医疗对话数据集,包括:<Andriatria_男科> 94596个问答对 <IM_内科> 220606个问答对 <OAGD_妇产科> 183751个问答对 <Oncology_肿瘤科> 75553个问答对 <Pediatric_儿科> 101602个问答对 <Surgical_外科> 115991个问答对 总计 792099个问答对。
Huatuo-26M:
地址:https://github.com/FreedomIntelligence/Huatuo-26M
数据集说明:Huatuo-26M 是一个中文医疗问答数据集,此数据集包含了超过2600万个高质量的医疗问答对,涵盖了各种疾病、症状、治疗方式、药品信息等多个方面。Huatuo-26M 是研究人员、开发者和企业为了提高医疗领域的人工智能应用,如聊天机器人、智能诊断系统等需要的重要资源。
Alpaca-GPT-4:
地址:https://github.com/Instruction-Tuning-with-GPT-4/GPT-4-LLM
数据集说明:Alpaca-GPT-4 是一个使用 self-instruct 技术,基于 175 条中文种子任务和 GPT-4 接口生成的 50K 的指令微调数据集。
InstructionWild
地址:https://github.com/XueFuzhao/InstructionWild
数据集说明:InstructionWild 是一个从网络上收集自然指令并过滤之后使用自然指令结合 ChatGPT 接口生成指令微调数据集的项目。主要的指令来源:Twitter、CookUp.AI、Github 和 Discard。
ShareChat
地址:https://paratranz.cn/projects/6725
数据集说明:一个倡议大家一起翻译高质量 ShareGPT 数据的项目。
项目介绍:清洗/构造/翻译中文的ChatGPT数据,推进国内AI的发展,人人可炼优质中文 Chat 模型。本数据集为ChatGPT约九万个对话数据,由ShareGPT API获得(英文68000,中文11000条,其他各国语言)。项目所有数据最终将以 CC0 协议并入 Multilingual Share GPT 语料库。
Guanaco
地址:https://huggingface.co/datasets/JosephusCheung/GuanacoDataset
数据集说明:一个使用 Self-Instruct 的主要包含中日英德的多语言指令微调数据集。
chatgpt-corpus
地址:https://github.com/PlexPt/chatgpt-corpus
数据集说明:开源了由 ChatGPT3.5 生成的300万自问自答数据,包括多个领域,可用于用于训练大模型。
SmileConv
地址:https://github.com/qiuhuachuan/smile
数据集说明:数据集通过ChatGPT改写真实的心理互助 QA为多轮的心理健康支持多轮对话(single-turn to multi-turn inclusive language expansion via ChatGPT),该数据集含有56k个多轮对话,其对话主题、词汇和篇章语义更加丰富多样,更加符合在长程多轮对话的应用场景。
偏好数据集
4. LLM训练微调框架
5. LLM推理部署框架
6. LLM评测
FlagEval (天秤)大模型评测体系及开放平台
地址:https://github.com/FlagOpen/FlagEval
简介:旨在建立科学、公正、开放的评测基准、方法、工具集,协助研究人员全方位评估基础模型及训练算法的性能,同时探索利用AI方法实现对主观评测的辅助,大幅提升评测的效率和客观性。FlagEval (天秤)创新构建了“能力-任务-指标”三维评测框架,细粒度刻画基础模型的认知能力边界,可视化呈现评测结果。
C-Eval: 构造中文大模型的知识评估基准:
地址:https://github.com/SJTU-LIT/ceval
简介:构造了一个覆盖人文,社科,理工,其他专业四个大方向,52 个学科(微积分,线代 …),从中学到大学研究生以及职业考试,一共 13948 道题目的中文知识和推理型测试集。此外还给出了当前主流中文LLM的评测结果。
OpenCompass:
地址:https://github.com/InternLM/opencompass
简介:由上海AI实验室发布的面向大模型评测的一站式平台。主要特点包括:开源可复现;全面的能力维度:五大维度设计,提供 50+ 个数据集约 30 万题的的模型评测方案;丰富的模型支持:已支持 20+ HuggingFace 及 API 模型;分布式高效评测:一行命令实现任务分割和分布式评测,数小时即可完成千亿模型全量评测;多样化评测范式:支持零样本、小样本及思维链评测,结合标准型或对话型提示词模板;灵活化拓展。
SuperCLUElyb: SuperCLUE琅琊榜
地址:https://github.com/CLUEbenchmark/SuperCLUElyb
简介:中文通用大模型匿名对战评价基准,这是一个中文通用大模型对战评价基准,它以众包的方式提供匿名、随机的对战。他们发布了初步的结果和基于Elo评级系统的排行榜。
GAOKAO-Bench:
地址:https://github.com/OpenLMLab/GAOKAO-Bench
简介:GAOKAO-bench是一个以中国高考题目为数据集,测评大模型语言理解能力、逻辑推理能力的测评框架,收集了2010-2022年全国高考卷的题目,其中包括1781道客观题和1030道主观题,构建起GAOKAO-bench的数据部分。
AGIEval:
地址:https://github.com/ruixiangcui/AGIEval
简介:由微软发布的一项新型基准测试,这项基准选取20种面向普通人类考生的官方、公开、高标准往常和资格考试,包括普通大学入学考试(中国高考和美国 SAT 考试)、法学入学考试、数学竞赛、律师资格考试、国家公务员考试等等。
Xiezhi:
地址:https://github.com/mikegu721/xiezhibenchmark
简介:由复旦大学发布的一个综合的、多学科的、能够自动更新的领域知识评估Benchmark,包含了哲学、经济学、法学、教育学、文学、历史学、自然科学、工学、农学、医学、军事学、管理学、艺术学这13个学科门类,24万道学科题目,516个具体学科,249587道题目。
Open LLM Leaderboard:
地址:https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
简介:由HuggingFace组织的一个LLM评测榜单,目前已评估了较多主流的开源LLM模型。评估主要包括AI2 Reasoning Challenge, HellaSwag, MMLU, TruthfulQA四个数据集上的表现,主要以英文为主。
CMMLU:
地址:https://github.com/haonan-li/CMMLU
简介:CMMLU是一个综合性的中文评估基准,专门用于评估语言模型在中文语境下的知识和推理能力。CMMLU涵盖了从基础学科到高级专业水平的67个主题。它包括:需要计算和推理的自然科学,需要知识的人文科学和社会科学,以及需要生活常识的中国驾驶规则等。此外,CMMLU中的许多任务具有中国特定的答案,可能在其他地区或语言中并不普遍适用。因此是一个完全中国化的中文测试基准。
MMCU:
地址:https://github.com/Felixgithub2017/MMCU
简介:该项目提供对中文大模型语义理解能力的测试,评测方式、评测数据集、评测记录都公开,确保可以复现。该项目旨在帮助各位研究者们评测自己的模型性能,并验证训练策略是否有效。
chinese-llm-benchmark:
地址:https://github.com/jeinlee1991/chinese-llm-benchmark
简介:中文大模型能力评测榜单:覆盖百度文心一言、chatgpt、阿里通义千问、讯飞星火、belle / chatglm6b 等开源大模型,多维度能力评测。不仅提供能力评分排行榜,也提供所有模型的原始输出结果!
Safety-Prompts:
地址:https://github.com/thu-coai/Safety-Prompts
简介:由清华大学提出的一个关于LLM安全评测benchmark,包括安全评测平台等,用于评测和提升大模型的安全性,囊括了多种典型的安全场景和指令攻击的prompt。
PromptCBLUE: 中文医疗场景的LLM评测基准
地址:https://github.com/michael-wzhu/PromptCBLUE
简介:为推动LLM在医疗领域的发展和落地,由华东师范大学联合阿里巴巴天池平台,复旦大学附属华山医院,东北大学,哈尔滨工业大学(深圳),鹏城实验室与同济大学推出PromptCBLUE评测基准, 将16种不同的医疗场景NLP任务全部转化为基于提示的语言生成任务,形成首个中文医疗场景的LLM评测基准。
HalluQA: 中文幻觉评估基准
地址:https://github.com/xiami2019/HalluQA
简介:该项目提出了一个名为HalluQA的基准测试,用于衡量中文大型语言模型中的幻觉现象。HalluQA包含450个精心设计的对抗性问题,涵盖多个领域,并考虑了中国历史文化、风俗和社会现象。在构建HalluQA时,考虑了两种类型的幻觉:模仿性虚假和事实错误,并基于GLM-130B和ChatGPT构建对抗性样本。为了评估,设计了一种使用GPT-4进行自动评估的方法,判断模型输出是否是幻觉。
7. LLM教程
LLM基础知识
HuggingLLM:
地址:https://github.com/datawhalechina/hugging-llm
简介:介绍 ChatGPT 原理、使用和应用,降低使用门槛,让更多感兴趣的非NLP或算法专业人士能够无障碍使用LLM创造价值。
LLMsPracticalGuide:
地址:https://github.com/Mooler0410/LLMsPracticalGuide
简介:该项目提供了关于LLM的一系列指南与资源精选列表,包括LLM发展历程、原理、示例、论文等。
提示工程教程
LLM应用教程
LLM实战教程
LLMs九层妖塔:
地址:https://github.com/km1994/LLMsNineStoryDemonTower
简介:ChatGLM、Chinese-LLaMA-Alpaca、MiniGPT-4、FastChat、LLaMA、gpt4all等实战与经验。
llm-action:
地址:https://github.com/liguodongiot/llm-action
简介:该项目提供了一系列LLM实战的教程和代码,包括LLM的训练、推理、微调以及LLM生态相关的一些技术文章等。
llm大模型训练专栏:
地址:https://www.zhihu.com/column/c_1252604770952642560
简介:该项目提供了一系列LLM前言理论和实战实验,包括论文解读与洞察分析。
书生·浦语大模型实战营
地址:https://github.com/InternLM/tutorial
简介:该课程由上海人工智能实验室重磅推出。课程包括大模型微调、部署与评测全链路,目的是为广大开发者搭建大模型学习和实践开发的平台。
8. 相关仓库
FindTheChatGPTer:
地址:https://github.com/chenking2020/FindTheChatGPTer
简介:ChatGPT爆火,开启了通往AGI的关键一步,本项目旨在汇总那些ChatGPT的开源平替们,包括文本大模型、多模态大模型等,为大家提供一些便利。
LLM_reviewer:
地址:https://github.com/SpartanBin/LLM_reviewer
简介:总结归纳近期井喷式发展的大语言模型,以开源、规模较小、可私有化部署、训练成本较低的‘小羊驼类’模型为主。
Awesome-AITools:
地址:https://github.com/ikaijua/Awesome-AITools
简介:收藏整理了AI相关的实用工具、评测和相关文章。
open source ChatGPT and beyond:
地址:https://github.com/SunLemuria/open_source_chatgpt_list
简介:This repo aims at recording open source ChatGPT, and providing an overview of how to get involved, including: base models, technologies, data, domain models, training pipelines, speed up techniques, multi-language, multi-modal, and more to go.
Awesome Totally Open Chatgpt:
地址:https://github.com/nichtdax/awesome-totally-open-chatgpt
简介:This repo record a list of totally open alternatives to ChatGPT.
Awesome-LLM:
地址:https://github.com/Hannibal046/Awesome-LLM
简介:This repo is a curated list of papers about large language models, especially relating to ChatGPT. It also contains frameworks for LLM training, tools to deploy LLM, courses and tutorials about LLM and all publicly available LLM checkpoints and APIs.
DecryptPrompt:
地址:https://github.com/DSXiangLi/DecryptPrompt
简介:总结了Prompt&LLM论文,开源数据&模型,AIGC应用。
Awesome Pretrained Chinese NLP Models:
地址:https://github.com/lonePatient/awesome-pretrained-chinese-nlp-models
简介:收集了目前网上公开的一些高质量中文预训练模型。
ChatPiXiu:
地址:https://github.com/catqaq/ChatPiXiu
简介:该项目旨在打造全面且实用的ChatGPT模型库和文档库。当前V1版本梳理了包括:相关资料调研+通用最小实现+领域/任务适配等。
LLM-Zoo:
地址:https://github.com/DAMO-NLP-SG/LLM-Zoo
简介:该项目收集了包括开源和闭源的LLM模型,具体包括了发布时间,模型大小,支持的语种,领域,训练数据及相应论文/仓库等。
LLMs-In-China:
地址:https://github.com/wgwang/LLMs-In-China
简介:该项目旨在记录中国大模型发展情况,同时持续深度分析开源开放的大模型以及数据集的情况。
BMList:
地址:https://github.com/OpenBMB/BMList
简介:该项目收集了参数量超过10亿的大模型,并梳理了各个大模型的适用模态、发布的机构、适合的语种,参数量和开源地址、API等信息。
awesome-free-chatgpt:
地址:https://github.com/LiLittleCat/awesome-free-chatgpt
简介:该项目收集了免费的 ChatGPT 镜像网站列表,ChatGPT的替代方案,以及构建自己的ChatGPT的教程工具等。
Awesome-Domain-LLM:
地址:https://github.com/luban-agi/Awesome-Domain-LLM
简介:该项目收集和梳理垂直领域的开源模型、数据集及评测基准。
Star History