awesome RLHF
1.0.0
这是通过人类反馈(RLHF)进行增强学习的研究论文的集合。并将不断更新存储库,以跟踪RLHF的前沿。
欢迎跟随和明星!
很棒的RLHF(带有人类反馈的RL)
2024
2023
2022
2021
2020年及以前
详细的解释
目录
RLHF的概述
文件
代码库
数据集
博客
其他语言支持
贡献
执照
RLHF的想法是使用增强学习中的方法直接优化人类反馈的语言模型。 RLHF使语言模型能够开始使对文本数据的一般语料库进行训练的模型与复杂的人类价值观的模型。
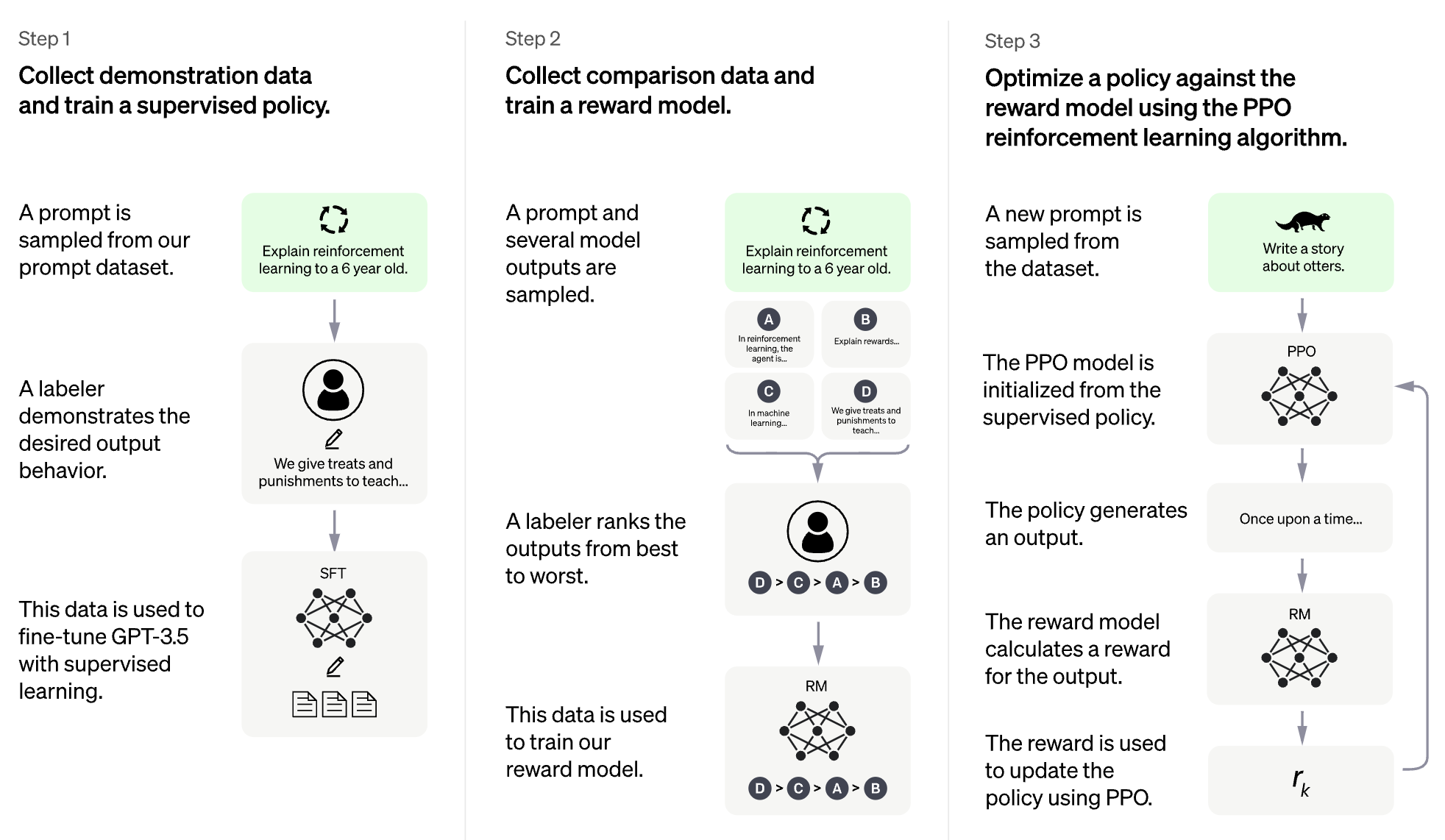
大型语言模型(LLM)的RLHF
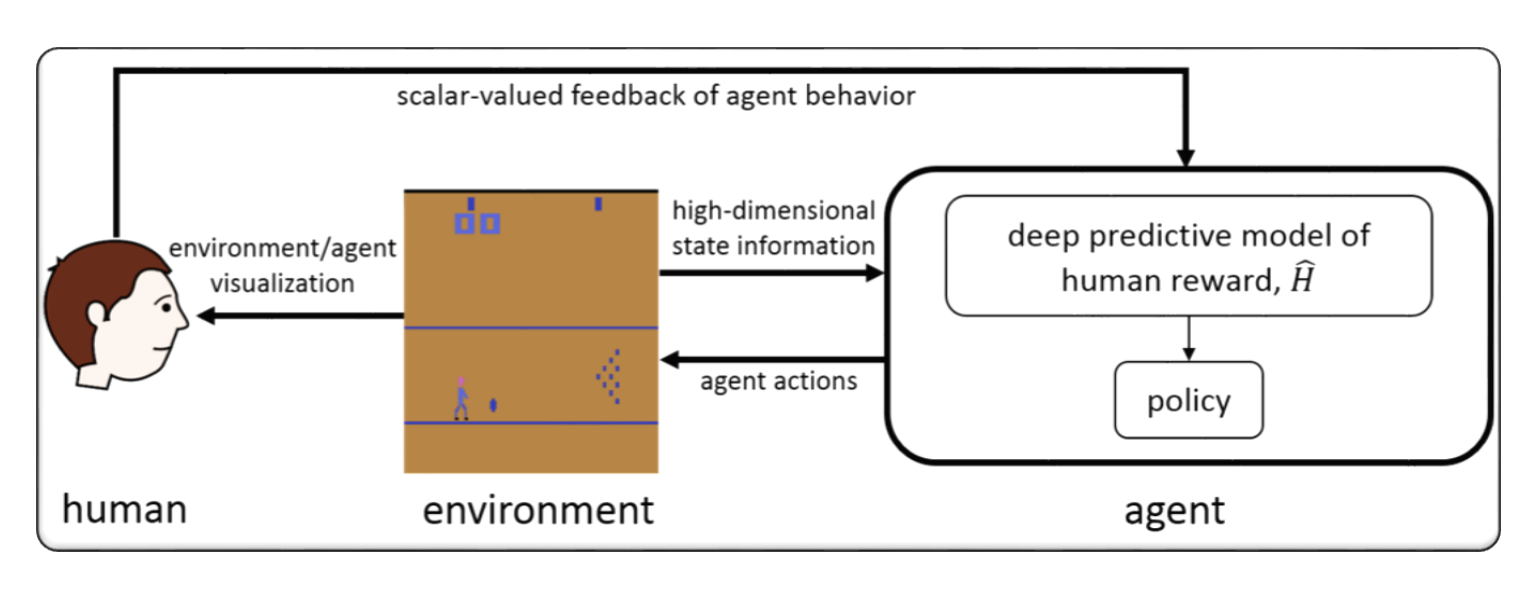
视频游戏的RLHF(例如Atari)
(以下部分是由Chatgpt自动生成的)
RLHF通常是指“通过人类反馈进行加强学习”。增强学习(RL)是一种机器学习,涉及培训代理商根据环境的反馈做出决策。在RLHF中,代理商还以评级或评估其行动的形式从人类那里收到反馈,这可以帮助其更快,准确地学习。
RLHF是人工智能中的一个活跃研究领域,在机器人技术,游戏和个性化推荐系统等领域中进行了应用。它试图解决RL在代理商中从环境中获得反馈的有限访问,并要求人类投入以提高其绩效的情况。
通过人类反馈(RLHF)的增强学习是人工智能研究的快速发展领域,并且已经开发了几种先进的技术来提高RLHF系统的性能。这里有一些例子:
Inverse Reinforcement Learning (IRL) :IRL是一种使代理商从人类反馈中学习奖励功能的技术,而不是依靠预定义的奖励功能。这使得代理可以从更复杂的反馈信号中学习,例如所需行为的演示。
Apprenticeship Learning :学徒学习是一种将IRL与监督学习相结合的技术,使代理商能够从人类的反馈和专家演示中学习。这可以帮助代理商更快,有效地学习,因为它能够从正面和负面反馈中学习。
Interactive Machine Learning (IML) :IML是一种涉及代理商与人类专家之间积极互动的技术,使专家可以实时就代理商的行动提供反馈。这可以帮助代理商更快,更有效地学习,因为它可以在学习过程的每个步骤中都会收到有关其行动的反馈。
Human-in-the-Loop Reinforcement Learning (HITLRL) :HITLRL是一种技术,涉及将人类的反馈在多个级别的RL过程中,例如奖励成型,行动选择和政策优化。这可以通过利用人类和机器的优势来帮助提高RLHF系统的效率和有效性。
以下是人类反馈(RLHF)的加强学习的例子:
Game Playing :在游戏中,人类反馈可以帮助代理商学习在不同游戏方案中有效的策略和策略。例如,在流行的GO游戏中,人类专家可以为代理商提供反馈,以帮助其改善其游戏玩法和决策。
Personalized Recommendation Systems :在推荐系统中,人类反馈可以帮助代理商学习单个用户的偏好,从而可以提供个性化的建议。例如,代理可以使用用户对推荐产品的反馈来了解哪些功能对他们最重要。
Robotics :在机器人技术中,人类反馈可以帮助代理商学习如何以安全有效的方式与物理环境互动。例如,机器人可以通过人类操作员的反馈在最佳采取途径或避免哪些对象的情况下从人类操作员那里进行反馈,从而更快地浏览新环境。
Education :在教育方面,人类反馈可以帮助代理商学习如何更有效地教学学生。例如,基于人工智能的导师可以使用教师的反馈,其中教学策略与不同的学生最有效,从而帮助个性化学习经验。
format: - [title](paper link) [links] - author1, author2, and author3... - publisher - keyword - code - experiment environments and datasets
混合流:灵活有效的RLHF框架
广明尚恩,奇张,Zilingfeng Ye,Xibin Wu,Wang Zhang,Ru Zhang,Yanghua Peng,Haibin Lin,Chuan Wu
关键字:灵活,高效,RLHF框架
代码:官方
警报:通过分层奖励建模对齐语言模型
Yuhang Lai,Siyuan Wang,Shujun Liu,Xuanjing Huang,Zhongyu Wei
关键字:分层奖励,开放文本生成任务
代码:官方
TLCR:代币级别的连续奖励,以从人类反馈中学习细粒度的增强
Eunseop Yoon,Hee Suk Yoon,Soohwan Eom,Gunsoo Han,Daniel Wontae Nam,Daejin Jo,Kyoung-woon,Mark A. A. Hasegawa-Johnson,Sungwoong Kim,Chang D. Yoo
关键字:令牌级的连续奖励,RLHF
代码:官方
将大型多模型与实际增强的RLHF对齐
Zhiqing Sun,Sheng Shen,Shengcao Cao,Haotian Liu,Chunyuan Li,Yikang Shen,Chuang Gan,Liang-Yan Gui,Yu-Xiong Wang,Yiming Yang,Kurt Keutzer,Trevor Darrell,Trevor Darrell,Trevor Darrell
关键字:实际增强RLHF,视觉和语言,人类偏好数据集
代码:官方
通过自我奖励对比迅速蒸馏来指导大型语言模型对齐
aiwei liu,haoping bai,Zhiyun Lu,Xiang Kong,Simon Wang,Jiulong Shan,Meng Cao,Lijie Wen
关键字:没有人类偏好数据,自我奖励,DPO
代码:官方
对不同用户偏好的LLM的算术控制:多目标奖励的定向偏好对齐
Haoxiang Wang,Yong Lin,Wei Xiong,Rui Yang,Shizhe Diao,Shuang Qiu,Han Zhao,Tong Zhang
关键字:用户偏好,多目标奖励模型,拒绝采样填充
代码:官方
返回基础知识:重新审核风格优化,以从LLMS中的人类反馈中学习
Arash Ahmadian,Chris Cremer,MatthiasGallé,Marzieh Fadaee,Julia Kreutzer,Olivier Pietquin,Ahmetüstün,Sara Hooker
关键字:在线RL优化,低计算成本
代码:官方
通过细粒度的增强学习来改善大型语言模型,并使用最小的编辑约束
Zhipeng Chen,Kun Zhou,Wayne Xin Zhao,Junchen Wan,Fuzheng Zhang,Di Zhang,Ji-Rong Wen
关键字:令牌级奖励,法学硕士
代码:官方
RLAIF与RLHF:通过AI反馈从人类反馈中缩放增强加固
Harrison Lee,Samrat Phatale,Hassan Mansoor,Thomas Mesnard,Johan Ferret,Kellie Ren Lu,Colton Bishop,Ethan Hall,Victor Carbune,Abhinav Rastogi,Sushant Prakash,Sushant Prakash
关键字:来自AI反馈的RL
代码:官方
用于双杆钢筋学习和RLHF的原则基于罚款的方法
汉山,杨杨,蒂亚尼·陈
关键字:二元优化
代码:官方
从人类反馈中获得强化学习的免费奖励
Alex James Chan,Hao Sun,Samuel Holt,Mihaela van der Schaar
关键字:奖励成型,RLHF
代码:官方
一种最小化的方法来加强人类反馈学习
Gokul Swamy,Christoph Dann,Rahul Kidambi,Steven Wu,Alekh Agarwal
关键字:Minimax获胜者,自我播放优先优化
代码:官方
RLHF-V:通过细粒度惩教的行为对齐人的行为对准人类反馈,向值得信赖的MLLM
Tianyu Yu,Yuan Yao,Haoye Zhang,Taiwen HE,Yifeng Han,Ganqu Cui,Jinyi Hu,Jhiyuan Liu,Hai-Tao Zheng,Maosong Sun,Tat-Seng Chua
关键字:多模式大语模型,幻觉问题,从人类反馈中学习的增强
代码:官方
RLHF工作流程:从奖励建模到在线RLHF
Hanze Dong,Wei Xiong,Bo Pang,Haoxiang Wang,Han Zhao,Yingbo Zhou,Nan Jiang,Doyen Sahoo,Caiming Ximing Xiong,Tong Zhang
关键字:在线迭代RLHF,偏好建模,大语言模型
代码:官方
MAXMIN-RLHF:朝着具有多种人类偏好的大型语言模型的公平对准
Souradip Chakraborty,Jiahao Qiu,Hui Yuan,Alec Koppel,Furong Huang,Dinesh Manocha,Amrit Singh Bedi,Mengdi Wang
关键字:偏好分布的混合物,maxmin对齐目标
代码:官方
RLHF的数据集重置策略优化
Jonathan D. Chang,Wenhao Zhan,Owen Oertell,KiantéBrantley,Dipendra Misra,Jason D. Lee,Wen Sun
关键字:数据集重置策略优化
代码:官方
关于将文本到图像扩散与偏好结合的密集奖励观点
Shentao Yang,Tianqi Chen,Mingyuan Zhou
关键字:用于文本到图像生成的RLHF,DPO的密集奖励改进,有效的一致性
代码:官方
自我播放微调将弱语言模型转换为强语模型
Zixiang Chen,Yihe Deng,Huizhuo Yuan,Kaixuan JI,Quanquan Gu
关键字:自我播放微调
代码:官方
RLHF解密:对LLMS人类反馈的强化学习的批判性分析
Shreyas Chaudhari,Pranjal Aggarwal,Vishvak Murahari,Tanmay Rajpurohit,Ashwin Kalyan,Karthik Narasimhan,Ameet Deshpande,Bruno Castro da Silva
关键字:RLHF,Oracular奖励,奖励模型分析,调查
面对扩散模型的奖励过度转化:归纳和首要偏见的观点
Ziyi Zhang,Sen Zhang,Yibing Zhan,Yong Luo,Yonggang Wen,Dacheng Tao
关键字:扩散模型,一致性,增强学习,RLHF,奖励过度转移,首要偏见
代码:官方
关于大型语言模型一致性的多元化偏好
Dun Zeng,Yong Dai,Pengyu Cheng,Tianhao Hu,Wanshun Chen,Nan Du,Zenglin Xu
关键字:对齐共享偏好,奖励建模指标,LLM
代码:官方
通过分配偏好奖励建模对齐人群反馈
Dexun Li,Cong Zhang,Kuicai Dong,Derrick Goh Xin Deik,Ruiming Tang,Yong Liu
关键字:RLHF,偏好分布,对齐,LLM
超越一位偏好 - 所有对齐方式:多目标直接偏好优化
Zhanhui Zhou,Jie Liu,Chao Yang,Jing Shao,Yu Liu,Xiangyu Yue,Wanli Ouyang,Yu Qiao
关键字:无奖励建模的多目标RLHF,DPO
代码:官方
模拟的不对准:大语言模型的安全一致性可能适得其反!
Zhanhui Zhou,Jie Liu,Zhichen Dong,Jiaheng Liu,Chao Yang,Wanli Ouyang,Yu Qiao
关键字:LLM推理时间攻击,DPO,在没有培训的情况下产生有害的LLM
代码:官方
在一般KL规范化的偏好下,对人类反馈的NASH学习的理论分析
Chenlu Ye,Wei Xiong,Yuheng Zhang,Nan Jiang,Tong Zhang
关键字:基于游戏的RLHF,NASH学习,无奖励模式下的对齐方式
减轻RLHF的对齐税
Yong Lin,Hangyu Lin,Wei Xiong,Shizhe Diao,Jianmeng Liu,Jipeng Zhang,Rui Pan,Haoxiang Wang,Wenbin Hu,Wenbin Hu,Hanning Zhang,Hanze Dong,Hanze Dong,Renjie Pi,Renjie Pi,Han Zhao,Han Zhao,Nan Jiang,Heng Jiang,Heng Ji,Yuan Yao,Tong Yao,Tonn Yao,Tonn Yao,Tonn Yao,Tonn Yao,Tonn Yao,Tonn Yao,Tonn Yao,Tonn Yao,Tonn Yao,Tonn Yao,Tonn Yao
关键字:RLHF,对准税,灾难性遗忘
通过增强学习的培训扩散模型
凯文·布莱克(Kevin Black),迈克尔·詹纳(Michael Janner),伊隆·杜(Yilun du),伊利亚·科斯特里科夫(Ilya Kostrikov),谢尔盖·莱文
关键字:增强学习,RLHF,扩散模型
代码:官方
ALIGNDIFF:通过行为可定制的扩散模型对齐人类的偏好
Zibin Dong,Yifu Yuan,Jianye Hao,Fei Ni,Yao Mu,Yan Zheng,Yujing Hu,Tangjie LV,Changjie Fan,Zhipeng Hu
关键字:增强学习;扩散模型; rlhf;偏好对齐
代码:官方
从人类反馈中获得强化学习的免费奖励
Alex J. Chan,Hao Sun,Samuel Holt,Mihaela van der Schaar
关键字:RLHF
代码:官方
转换和结合奖励,以使大语模型对齐
Zihao Wang,Chirag Nagpal,Jonathan Berant,Jacob Eisenstein,Alex D'Amour,Sanmi Koyejo,Victor Veitch
关键字:RLHF,Aligning,LLM
参数有效的强化从人类反馈中学习
Hakim Sidahmed, Samrat Phatale, Alex Hutcheson, Zhuonan Lin, Zhang Chen, Zac Yu, Jarvis Jin, Simral Chaudhary, Roman Komarytsia, Christiane Ahlheim, Yonghao Zhu, Bowen Li, Saravanan Ganesh, Bill Byrne, Jessica Hoffmann, Hassan Mansoor, Wei Li ,Abhinav Rastogi,Lucas Dixon
关键字:RLHF,参数有效方法,低计算成本,LLM,VLM
通过有效的奖励模型合奏改善从人类反馈中的强化学习
Shun Zhang,Zhenfang Chen,Sunli Chen,Yikang Shen,Zhiqing Sun,Chuang Gan
关键字:RLHF,奖励合奏,高效的合奏方法
一般理论范式了解人类偏好的学习
Mohammad Gheshlaghi Azar,Mark Rowland,Bilal Piot,Daniel Guo,Daniele Calandriello,Michal Valko,RémiMunos
关键字:RLHF,成对偏好
细粒度的人类反馈为语言模型培训提供了更好的奖励
Zeqiu Wu,Yushi Hu,Weijia Shi,Nouha Dziri,Alane Suhr,Prithviraj Ammanabrolu,Noah A. Smith,Mari Ostendorf,Hannaneh Hajishirzi
关键字:RLHF,句子级奖励,LLM
代码:官方
偏好的令牌级别的语言模型指南微调
Shentao Yang,Shujian Zhang,Tengying Xia,Yihao Feng,Caiming Xiong,Mingyuan Zhou
关键字:RLHF,令牌级培训指南,替代/在线培训框架,简约培训目标
代码:官方
奇妙的奖励以及如何驯服它们:关于以任务为导向的对话系统奖励学习的案例研究
Yihao Feng*,Shentao Yang*,Shujian Zhang,Jianguo Zhang,Caiming Xiong,Mingyuan Zhou,Huan Wang
关键字:RLHF,Genalized奖励功能学习,奖励功能利用,面向任务的对话系统,学习到级别
代码:官方
反向偏好学习:基于偏好的RL没有奖励功能
Joey Hejna,Dorsa Sadigh
关键字:反向偏好学习,没有奖励模型
代码:官方
Alpacafarm:从人类反馈中学习的方法的模拟框架
Yann Dubois,Chen Xuechen Li,Rohan Taori,Tianyi Zhang,Ishaan Gulrajani,Jimmy BA,Carlos Guestrin,Percy S. Liang,Tatsunori B. Hashimoto
关键字:RLHF,仿真框架
代码:官方
对人类对齐的优先排名优化
Feifan Song,Bowen Yu,Minghao Li,Haiyang Yu,Fei Huang,Yongbin Li,Houfeng Wang
关键字:偏好排名优化
代码:官方
对抗偏好优化
Pengyu Cheng,Yifan Yang,Jian Li,Yong Dai,Nan Du
关键字:RLHF,GAN,对抗游戏
代码:官方
从人类反馈中学习的迭代偏好:rlhf的桥接理论和实践
Wei Xiong,Hanze Dong,Chenlu Ye,Ziqi Wang,Han Zhong,Heng JI,Nan Jiang,Tong Zhang
关键字:RLHF,迭代DPO,数学基础
通过主动探索从人类反馈中采样有效的加强学习
Viraj Mehta,Vikramjeet Das,Ojash Neopane,Yijia Dai,Ilija Bogunovic,Jeff Schneider,Willie Neiswanger
关键字:RLHF,样本功效,探索
从统计反馈中学习的强化学习:从AB测试到蚂蚁测试的旅程
Feiyang Han,Yimin Wei,Zhaofeng Liu,Yanxing Qi
关键字:RLHF,AB测试,RLSF
奖励模型能够准确分析分配转移基础模型的能力的基线分析
Ben Pikus,Will Levine,Tony Chen,Sean Hendryx
关键字:RLHF,OOD,分销班次
通过自然语言的大型语言模型与人类反馈的数据有效对齐
DI Jin,Shikib Mehri,Devamanyu Hazarika,Aishwarya Padmakumar,Sungjin Lee,Yang Liu,Mahdi Namazifar
关键字:RLHF,数据效率,对齐方式
让我们逐步加强
莎拉·潘(Sarah Pan),弗拉迪斯拉夫·莱林(Vladislav Lialin),谢林·马卡蒂拉(Sherin Muckatira)
关键字:RLHF,推理
直接基于偏好的政策优化而无需奖励建模
Gaon An,Junhyeok Lee,Xingdong Zuo,Norio Kosaka,Kyung-Min Kim,Hyun Oh Song
关键字:无奖励建模,对比度学习,离线再培养费学习的RLHF
ALIGNDIFF:通过行为可定制的扩散模型对齐人类的偏好
Zibin Dong,Yifu Yuan,Jianye Hao,Fei Ni,Yao Mu,Yan Zheng,Yujing Hu,Tangjie LV,Changjie Fan,Zhipeng Hu
关键字:RLHF,对齐,扩散模型
尤里卡:通过编码大语言模型的人级奖励设计
Yecheng Jason MA,William Liang,Guanzhi Wang,De-An Huang,Osbert Bastani,Dinesh Jayaraman,Yuke Zhu,Linxi粉丝,Anima Anandkumar
关键字:基于LLM,奖励功能设计
安全的RLHF:从人类反馈中学习的安全加固
Josef Dai,Xuehai Pan,Ruiyang Sun,Jiaming JI,Xinbo Xu,Mickel Liu,Yizhou Wang,Yaodong Yang
关键字:销售RL,LLM微型
通过人类反馈的质量多样性
Li Ding,Jenny Zhang,Jeff Clune,Lee Spector,Joel Lehman
关键字:质量多样性,扩散模型
remax:一种简单,有效,有效的加强学习方法,用于对齐大语言模型
Ziniu Li,Tian Xu,Yushun Zhang,Yang Yu,Ruoyu Sun,Zhi-Quan Luo
关键字:计算效率,差异技术
使用任务奖励调整计算机视觉模型
AndréSusanoPinto,Alexander Kolesnikov,Yuge Shi,Lucas Beyer,Xiaohua Zhai
关键字:计算机视觉中的奖励调整
事后观察的智慧使语言模型更好
Tianjun Zhang,Fangchen Liu,Justin Wong,Pieter Abbeel,Joseph E. Gonzalez
关键字:事后观点指令重新标签,RLHF系统,无需价值网络
代码:官方
语言指示人类协调的强化学习
Hengyuan Hu,Dorsa Sadigh
关键字:人类协调,人类偏好对准,指示条件的RL
将语言模型与离线强化从人类反馈中学习
Jian Hu,Li Tao,June Yang,Chandler Zhou
关键字:基于决策者的对准,离线增强学习,RLHF系统
对人类对齐的优先排名优化
Feifan Song,Bowen Yu,Minghao Li,Haiyang Yu,Fei Huang,Yongbin Li和Houfeng Wang
关键字:受监督的人类偏好一致性,偏好排名扩展
代码:官方
弥合差距:一项关于自然语言产生(人)反馈的调查
帕特里克·费尔南德斯(Patrick Fernandes),阿曼·麦达安(Aman Madaan),艾美·刘(Emmy Liu),安东尼奥·法林纳斯(AntónioFarinhas),佩德罗·亨里克·马丁斯(Pedro Henrique Martins),阿曼达·伯茨(Amanda Bertsch),何塞·乔西(JoséBertsch)
关键字:自然语言产生,人类反馈整合,反馈形式和分类法,AI反馈和基于原则的判断
GPT-4技术报告
Openai
关键字:大规模,多模型,基于变压器的模型,微调使用的RLHF
代码:官方
数据集:Drop,Winogrande,Hellaswag,Arc,Humaneval,GSM8K,MMLU,真实
筏:生成基础模型对齐的奖励排名
Hanze Dong,Wei Xiong,Deepanshu Goyal,Rui Pan,Shizhe Diao,Jipeng Zhang,Kashun Shum,Tong Zhang
关键字:拒绝采样登录,替代PPO,扩散模型
代码:官方
RRHF:对对齐语言模型的排名响应没有人为反馈
Zheng Yuan,Hongyi Yuan,Chuanqi Tan,Wei Wang,Songfang Huang,Fei Huang
关键字:RLHF的新范式
代码:官方
对人类在RL的人类偏好学习
Joey Hejna,Dorsa Sadigh
关键字:偏好学习,互动学习,多任务学习,通过查看人类in-in-in-in-in-in-in-in-in-in-in-in-in-in-in-in-in-in-in-in-in-in-in-in-in-in-in-in-in-in-In数据数据库
代码:官方
更好地对齐文本对图像模型与人类偏好
小吴,孔齐安·孙,冯
关键字:扩散模型,文本到图像,美学
代码:官方
想象力:学习和评估文本到图像生成的人类偏好
Jiazheng Xu,小刘,Yuchen Wu,Yuxuan Tong,Qinkai Li,Ming ding,Jie Tang,Yuxiao Dong
关键字:通用文本到图像人类偏好RM,评估文本对图像生成模型
代码:官方
数据集:Coco,diffusionDB
使用人类反馈对齐文本对象模型
Kimin Lee,Hao Liu,Moonkyung Ryu,Olivia Watkins,Yuqing Du,Craig Boutilier,Pieter Abbeel,Mohammad Ghavamzadeh,Shixiang Shane Gu
关键字:文本对图像,稳定的扩散模型,预测人类反馈的奖励功能
Visual Chatgpt:使用视觉基础模型说话,绘画和编辑
Chenfei Wu,Shengming Yin,Weizhen Qi,Xiaodong Wang,Zecheng Tang,Nan Duan
关键字:视觉粉底模型,视觉chatgpt
代码:官方
具有人类偏好(PHF)的训练语言模型
Tomasz Korbak,Kejian Shi,Angelica Chen,Rasika Bhalerao,Christopher L. Buckley,Jason Phang,Samuel R. Bowman,Ethan Perez
关键字:预处理,离线RL,决策变压器
代码:官方
通过F-Divergence最小化(F-DPG)对齐语言模型与偏好
Dongyoung Go,Tomasz Korbak,GermánKruszewski,Jos Rozen,Nahyeon Ryu,Marc Dymetman
关键字:f-Divergence,rl带有kl罚款
从成对或K-Wise比较的人类反馈中有原则的增强学习
Banghua Zhu,Jiantao Jiao,Michael I. Jordan
关键字:悲观的MLE,最大凝集IRL
大语模型中道德自我纠正的能力
人类
关键字:通过增加RLHF培训来提高道德自我纠正能力
数据集;烧烤
自然语言处理的强化学习(不是)是否?
Rajkumar Ramamurthy,Prithviraj Ammanabrolu,Kianté,Brantley,Jack Hessel,Rafet Sifa,Christian Bauckhage,Hannaneh Hajishirzi,Yejin Choi
关键字:使用RL,基准,表现RL算法优化语言生成器
代码:官方
数据集:IMDB,Commongen,CNN每日邮报,Totto,WMT-16(EN-DE),NordativeQa,DailyDialog
奖励模型的缩放定律过度优化
Leo Gao,John Schulman,Jacob Hilton
关键字:金奖励模型火车代理奖励模型,数据集大小,策略参数大小,bon,ppo
通过有针对性的人类判断(Sparrow)改善对话代理的一致性
Amelia Glaese,Nat McAleese,MajaTrębacz等。
关键字:寻求信息对话代理,将良好的对话分解为自然语言规则,DPC,与模型互动以引起违反特定规则的行为(对抗性探测)
数据集:自然问题,ELI5,质量,Triviaqa,Winobias,烧烤
红色小组语言模型以减少危害:方法,缩放行为和经验教训
Deep Ganguli,Liane Lovitt,Jackson Kernion等。
关键字:红色团队语言模型,调查缩放行为,阅读组合数据集
代码:官方
使用强化学习进行开放式对话中的动态计划
Deborah Cohen,Moonkyung Ryu,Yinlam Chow,Orgad Keller,Ido Greenberg,Avinatan Hassidim,Michael Fink,Yossi Matias,Idan Szpektor,Craig Boutilier,Gal Elidan
关键字:实时,开放式对话系统,通过语言模型,CAQL,CQL,BERT对话状态的简洁嵌入对话状态
夸克:可控的文本生成,并用加固的学习
Ximing Lu,Sean Welleck,Jack Hessel,Liweh Jiang,Lianhui Qin,Peter West,Prithviraj Ammanabrolu,Yejin Choi
关键字:在信号上微调语言模型,决策变压器,LLM使用PPO调整
代码:官方
数据集:写作推广,SST-2,Wikitext-103
通过从人类反馈中学习的强化学习培训有用且无害的助手
Yuntao Bai,Andy Jones,Kamal Ndousse等。
关键字:无害的助手,在线模式,RLHF培训的鲁棒性,OOD检测。
代码:官方
数据集:Triviaqa,Hellaswag,Arc,OpenBookQa,Lambada,Humaneval,MMLU,真实
教授语言模型以验证的引号(Gophercite)支持答案
Jacob Menick,Maja Trebacz,Vladimir Mikulik,John Aslanides,Francis Song,Martin Chadwick,Mia Glaese,Susannah Young,Lucy Campbell-Gillingham,Geoffrey Irving,NatMcaleese
关键字:引用特定证据的答案,不确定何时弃权
数据集:自然问题,ELI5,质量,真实性
培训语言模型遵循人为反馈的指示(指示)
Long Ouyang,Jeff Wu,Xu Jiang等。
关键字:大语言模型,与人类意图的对齐语言模型
代码:官方
数据集:真实情况,realtoxicityPrompts
宪法AI:无害反馈的无害
Yuntao Bai,Saurav Kadavath,Sandipan Kundu,Amanda Askell,Jackson Kernion等。
关键字:来自AI反馈(RLAIF)的RL,通过自我改进,经过思考链风格训练无害的AI助手,更精确地控制AI行为
代码:官方
通过模型编写的评估发现语言模型行为
Ethan Perez,Sam Ringer,KamilėLukošiūtė,Karina Nguyen,Edwin Chen等。
关键字:自动通过LMS生成评估,更多的RLHF使LMS恶化,LM写评估是高素质
代码:官方
数据集:烧烤,Winogender模式
通过可解释的多个实例学习,从轨迹标签中从轨迹标签中进行非马克维亚奖励建模
约瑟夫·劳(Joseph Early),汤姆·贝利(Tom Bewley),克里斯汀·埃弗斯(Christine Evers)
关键字:奖励建模(RLHF),非马克维亚语,多个实例学习,可解释性
代码:官方
WebGPT:通过人类反馈(WebGPT)浏览器协助提问的问题
Reiichiro Nakano,Jacob Hilton,Suchir Balaji等。
关键字:模型搜索网络并提供参考,模仿学习,卑诗省,长形式问题
数据集:Eli5,Triviaqa,真实
递归用人类反馈总结书籍
Jeff Wu,Long Ouyang,Daniel M. Ziegler,Nisan Stiennon,Ryan Lowe,Jan Leike,Paul Christiano
关键字:经过小型任务培训的模型,以协助人类评估更广泛的任务,卑诗省
数据集:书籍,叙事Qa
重新审查神经机器翻译的增强学习的弱点
塞缪尔·基格兰(Samuel Kiegeland),朱莉娅·克鲁特策(Julia Kreutzer)
关键字:策略梯度的成功是由于奖励,而不是输出分布的形状,机器翻译,NMT,域适应
代码:官方
数据集:WMT15,IWSLT14
学会从人类反馈中总结
Nisan Stiennon,Long Ouyang,Jeff Wu,Daniel M. Ziegler,Ryan Lowe,Chelsea Voss,Alec Radford,Dario Amodei,Paul Christiano
关键字:关心摘要质量,培训损失会影响模型行为,奖励模型推广到新数据集
代码:官方
数据集:TL; DR,CNN/DM
来自人类偏好的微调语言模型
丹尼尔·齐格勒(Daniel M.
关键字:对语言的奖励学习,以积极的情绪,摘要任务和身体描述性继续文本
代码:官方
数据集:TL; DR,CNN/DM
通过奖励建模的可扩展代理对齐:研究方向
Jan Leike,David Krueger,Tom Everitt,Miljan Martic,Vishal Maini,Shane Legg
关键字:代理对准问题,从互动中学习奖励,优化与RL的奖励,递归奖励建模
代码:官方
env:atari
奖励从人类的偏好和示威中学习的奖励
Borja Ibarz,Jan Leike,Tobias Pohlen,Geoffrey Irving,Shane Legg,Dario Amodei
关键字:专家演示轨迹偏好奖励黑客问题,人类标签中的噪音
代码:官方
env:atari
深驯服:在高维状态空间中形成互动剂
Garrett Warnell,Nicholas Waytowich,Vernon Lawhern,Peter Stone
关键字:高维状态,利用人类教练的输入
代码:第三方
env:atari
从人类的偏好中学习深度强化
Paul Christiano,Jan Leike,Tom B. Brown,Miljan Martic,Shane Legg,Dario Amodei
关键字:探索在成对轨迹分割之间的人类偏好中定义的目标,学习比人类反馈更复杂的东西
代码:官方
Env:Mujoco Atari
依赖政策的人类反馈的互动学习
詹姆斯·麦格拉珊(James MacGlashan),马克·K·霍(Mark K Ho),罗伯特·洛夫汀(Robert Loftin
关键字:决策受到当前政策而不是人类反馈的影响,从依赖政策的反馈中学习,这些反馈收敛到本地最佳
format: - [title](codebase link) [links] - author1, author2, and author3... - keyword - experiment environments, datasets or tasks
VERL:LLM的火山发动机增强学习
BYTEDANCE SEED MLSYS团队和HKU:Guangming Sheng,Chi Zhang,Zilingfeng Ye,Xibin Wu,Wang Zhang,Ru Zhang,Yangua Peng,Haibin Lin,Chuan Wu
关键字:灵活,高效,RLHF框架
任务:RLHF,包括数学和代码在内的推理任务。
OpenRLHF
OpenRLHF
关键字:70B,RLHF,DeepSpeed,Ray,VLLM
任务:易于使用,可扩展且高性能的RLHF框架(支持70B+完整调整和Lora&Mixtral&KTO)。
棕榈 + RLHF- pytorch
Phil Wang,Yachine Zahidi,Ikko Eltociear Ashimine,Eric Alcaide
关键字:变形金刚,棕榈体系结构
数据集:ENWIK8
LM-Human-Preference
丹尼尔·齐格勒(Daniel M.
关键字:对语言的奖励学习,以积极的情绪,摘要任务和身体描述性继续文本
数据集:TL; DR,CNN/DM
以下建筑 - 人类反馈
Long Ouyang,Jeff Wu,Xu Jiang等。
关键字:大语言模型,与人类意图的对齐语言模型
数据集:真实的realtoxicityPrompts
变压器增强学习(TRL)
Leandro von Werra,Younes Belkada,Lewis Tunstall等。
关键字:使用RL,PPO,变压器的LLM训练LLM
任务:IMDB情绪
变压器增强学习X(TRLX)
Jonathan Tow,Leandro von Werra等。
关键字:分布式培训框架,基于T5的语言模型,使用RL,PPO,ILQL培训LLM
任务:使用RL使用提供的奖励功能或奖励标记的数据集进行微调LLM
RL4LMS(一个模块化的RL库,以对人类偏好进行微调语言模型)
Rajkumar Ramamurthy,Prithviraj Ammanabrolu,Kianté,Brantley,Jack Hessel,Rafet Sifa,Christian Bauckhage,Hannaneh Hajishirzi,Yejin Choi
关键字:使用RL,基准,表现RL算法优化语言生成器
数据集:IMDB,Commongen,CNN每日邮报,Totto,WMT-16(EN-DE),NordativeQa,DailyDialog
lamda-rlhf-pytorch
菲尔·王
关键字:LAMDA,注意力机构
任务:Pytorch中Google LAMDA研究论文的开源预培训实施
Textrl
埃里克·林(Eric Lam)
关键字:HuggingFace的变压器
任务:文字生成
env:PFRL,健身房
minrlhf
汤姆弗斯特
关键字:PPO,最小库
任务:教育目的
深速chat
微软
关键字:负担得起的RLHF培训
Dromedary
IBM
关键字:最少的人类监督,自我对准
任务:自我对准语言模型,受到最少的人类监督训练
FG-RLHF
Zeqiu Wu,Yushi Hu,Weijia Shi等。
关键字:细粒度RLHF,在每个细分市场之后提供奖励,并结合了与不同反馈类型相关的多个RMS
任务:一个框架,可以从密度和多个RMS的奖励功能中进行培训和学习 - SAFE-RLHF
Xuehai Pan,Ruiyang Sun,Jiaming JI等。
关键字:支持流行的预训练模型,大型人体标记的数据集,用于安全约束验证的多尺度指标,自定义参数
任务:通过安全的RLHF受约束的价值一致的LLM
format: - [title](dataset link) [links] - author1, author2, and author3... - keyword - experiment environments or tasks
HH-RLHF
本·曼恩(Ben Mann),深ganguli
关键字:人类偏好数据集,红色小组数据,机器编写
任务:有关人类偏好数据的开源数据集有关有帮助和无害性的数据
斯坦福人类偏好数据集(SHP)
Ethayarajh,Kawin和Zhang,Heidi和Wang,Yizhong和Jurafsky,Dan
关键字:自然发生和人工编写的数据集,18个不同的主题领域
任务:旨在用于培训RLHF奖励模型
提示
Stephen H. Bach,Victor Sanh,Zheng-Xin Yong等。
关键字:提示英语数据集,将数据示例映射到自然语言中
任务:用于创建,共享和使用自然语言提示的工具包
结构化知识接地(SKG)资源收集
Tianbao Xie,Chen Henry Wu,Peng Shi等。
关键字:结构化知识接地
任务:数据集的收集与结构化知识接地有关
弗兰收藏
Longpre Shayne,Hou Le,Vu Tu等。
任务:收集收集Flan 2021,P3,超自然说明的数据集
RLHF-Reward-Datasets
Yiting Xie
关键字:机器编写的数据集
WebGPT_COMPARISON
Openai
关键字:人工编写的数据集,长形式问题回答
任务:训练一个长期的问题回答模型,以与人类的偏好保持一致
总结_from_feedback
Openai
关键字:人工编写的数据集,摘要
任务:训练摘要模型以与人类的偏好保持一致
dahoas/nimthetic-Instruct-gptj-pairwise
达霍斯
关键字:人工编写的数据集,合成数据集
稳定的一致性 - 社交游戏中的一致性学习
Ruibo Liu,Ruixin(Ray)Yang,Qiang Peng
关键字:用于对齐训练的交互数据,在沙箱中运行
任务:在模拟社交游戏中训练记录的交互数据
利马
meta ai
关键字:没有任何RLHF,很少经过精心策划的提示和响应
任务:用于培训利马模型的数据集
[Openai] chatgpt:优化对话的语言模型
[拥抱脸]说明从人类反馈(RLHF)学习的强化学习
[Zhihu]通向agi:大型语言模型(llm)技术精要
[Zhihu]大语言模型的涌现能力:现象与解释
[zhihu]中文hh-rlHf数据集上的ppo实践
[W&B完全连接]从人类反馈中了解强化学习(RLHF)
[DeepMind]通过人类反馈学习
[概念]深入理解语言模型的突现能力
[概念]拆解追溯gpt-3.5各项能力的起源
[要点]语言模型的加强学习
[YouTube]约翰·舒尔曼(John Schulman) - 从人类反馈中学习的强化:进步和挑战
[OpenAi / Arize] Openai对人类反馈进行加固学习
[ENCORD]从人类反馈(RLHF)进行计算机视觉的强化指南
[Weixun Wang] RL(HF)+LLM的概述
土耳其
我们的目的是使此回购变得更好。如果您有兴趣贡献,请参考此处以获取贡献的说明。
Awesome RLHF在Apache 2.0许可下发布。


