很棒的llms-datasets
- 总结跨五个维度的现有代表性LLMS文本数据集:预培训语料库,微调指令数据集,偏好数据集,评估数据集和传统的NLP数据集。 (常规更新)
- 已经添加了新的数据集部分:多模式大语言模型(MLLMS)数据集,检索增强生成(RAG)数据集。 (逐渐更新)
纸
该论文“大语模型的数据集:全面调查” 。(2024/2)
抽象的:
本文着手探索大型语言模型(LLM)数据集,这些模型在LLMS的显着进步中起着至关重要的作用。这些数据集用作类似于维持和培育LLM开发的根系的基础基础设施。因此,对这些数据集的检查是研究中的关键主题。为了解决当前缺乏对LLM数据集的全面概述和彻底分析,并了解其当前状态和未来趋势的见解,该调查从五个角度合并并分类了LLM数据集的基本方面:(1)培训语料库; (2)指令微调数据集; (3)偏好数据集; (4)评估数据集; (5)传统的自然语言处理(NLP)数据集。该调查阐明了普遍的挑战,并指出了未来调查的潜在途径。此外,还提供了对现有可用数据集资源的全面审查,包括来自444个数据集的统计数据,涵盖8个语言类别和跨越32个域。来自20个维度的信息已纳入数据集统计信息。调查的总数据大小超过774.5 TB,用于培训前语料库和其他数据集的700m实例。我们的目标是介绍LLM文本数据集的整个景观,并为该领域的研究人员提供了全面的参考,并为未来的研究做出了贡献。
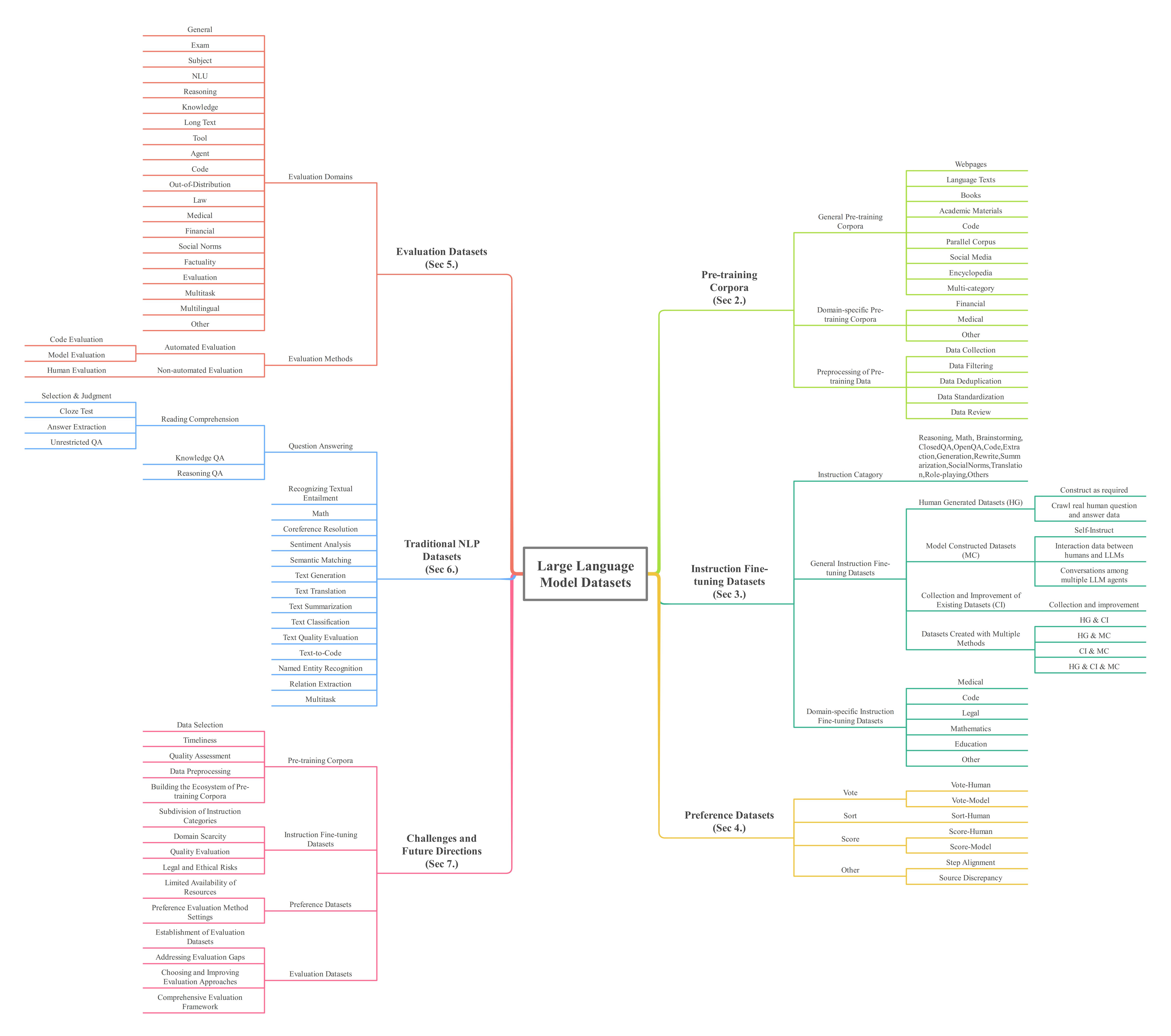
图1。调查的整体体系结构。放大以获得更好的视图
数据集信息模块
以下是数据集信息模块的摘要。
- 语料库/数据集名称
- 出版商
- 发布时间
- 尺寸
- 公共与否
- “全部”表示完整的开源;
- “部分”表示部分开源;
- “不”表示不开源。
- 执照
- 语言
- “ en”表示英语;
- “ ZH”表示中文;
- “ AR”表示阿拉伯语;
- “ ES”表示西班牙语;
- “ ru”表示俄罗斯人;
- “ de”表示德语;
- “ KO”表示韩语;
- “ LT”表示立陶宛语;
- “ FA”表示波斯语/波西;
- “ PL”表示编程语言;
- “多”表示多语言,括号中的数字表示所包括的语言数量。
- 施工方法
- “ HG”表示人类生成的语料库/数据集;
- “ MC”表示模型构建的语料库/数据集;
- “ CI”表示现有语料库/数据集的收集和改进。
- 类别
- 来源
- 领域
- 指令类别
- 偏好评估方法
- “ VO”表示投票;
- “所以”表示排序;
- “ SC”表示得分;
- “ -h”表示人类进行的;
- “ -m”表示模型进行的。
- 问题类型
- “ SQ”表示主观问题;
- “ OQ”表示客观问题;
- “多”表示多种问题类型。
- 评估方法
- “ CE”表示代码评估;
- “他”表示人类评估;
- “我”表示模型评估。
- 重点
- 评估类别/子类别的数量
- 评估类别
- 实体类别数(NER任务)
- 关系类别的数量(重新任务)
ChangElog
- (2024/01/17)创建Awesome-Lls-Datasets数据集存储库。
- (2024/02/02)修订了某些数据集的信息;添加dolma (培训前语料库|一般培训Corpora |多类)。
- (2024/02/15)添加AYA集合(指令微调数据集|常规指令微调数据集| HG&CI&MC); AYA数据集(指令微调数据集|常规指令微调数据集| HG)。
- (2024/02/22)添加OpenMathInstruct-1 (指令微调数据集|域特定指令微调数据集|数学); FinBen (评估数据集|财务)。
- (2024/04/05)
- 添加新的数据集部分: (1)多模式大语言模型(MLLMS)数据集; (2)检索增强生成(RAG)数据集。
- 添加MMRS-1M (MLLMS数据集|指令微调数据集); VideoChat2-it (MLLMS数据集|指令微调数据集);指令DOC (MLLMS数据集|指令微调数据集); Allava-4V数据(MLLMS数据集|指令微调数据集); MVBENCH (MLLMS数据集|评估数据集);奥林匹克式培训(MLLMS数据集|评估数据集); MMMU (MLLMS数据集|评估数据集)。
- 添加线索基准系列(评估数据集|评估平台); OpenLLM排行榜(评估数据集|评估平台); OpenCompass (评估数据集|评估平台); MTEB排行榜(评估数据集|评估平台); C-MTEB排行榜(评估数据集|评估平台)。
- 添加nah(in-a-a-haystack)(评估数据集|长文本); Tooleyes (评估数据集|工具); UHGEVAL (评估数据集|事实); clongeval (评估数据集|长文本)。
- 添加MathPile (培训前语料库|特定于域特异性的预培训语料库|数学); wanjuan-cc (培训前语料库|一般培训前语料库|网页)。
- 添加IEPILE (指令微调数据集|常规指令微调数据集| CI);指令(指令微调数据集|常规指令微调数据集| HG)。
- 添加crud-rag (抹布数据集); Wikieval (抹布数据集); RGB (RAG数据集);抹布 - 建筑基准 - 塔斯特(RAG数据集); ARES (RAG数据集)。
- ((2024/04/06)
- 添加GPQA (评估数据集|主题); MGSM (评估数据集|多语言); halueval-wild (评估数据集|事实); cmath (评估数据集|主题); finemath (评估数据集|主题);实时QA (评估数据集|事实); WYWEB (评估数据集|主题);中文法(评估数据集|事实);计数明星(评估数据集|长文本)。
- 添加slimpajama (培训前语料库|一般培训Corpora |多类); massiveText (培训前语料库|一般培训前语料库|多类); MADLAD-400 (培训前COLPORA |一般培训前COLPORA |网页);密涅瓦(培训前语料库|一般培训前语料库|多类); ccaligned (培训前语料库|一般培训前语料库|平行语料库); wikimatrix (培训前语料库|一般培训前语料库|平行语料库); OpenWebmath (培训前语料库|域特定的培训前Corpora |数学)。
- 添加WebQuestions (传统的NLP数据集|问题回答|知识质量质量质量质量质量图)。
- 添加alce (抹布数据集)。
- 添加alphafin (指令微调数据集|特定于域的指令微调数据集|其他); COIG-CQIA (指令微调数据集|常规指令微调数据集| HG&CI)。
- ((2024/06/15)
- 添加线索(评估数据集|医疗); CHC基础(评估数据集|常规); CIF基础(评估数据集|常规); Aclue (评估数据集|主题); LESC (评估数据集| NLU); AlignBench (评估数据集|多任务); Sciknoweval (评估数据集|主题)。
- 添加MAP-CC (培训前语料库|一般培训Corpora |多类); FineWeb (培训前COLPORA |一般培训前语料库|网页); CCI 2.0 (培训前语料库|一般培训Corpora |网页)。
- 添加Wildchat (指令微调数据集| MC)。
- 添加OpenHermespReferences (偏好数据集| sort); huozi_rlhf_data (偏好数据集|投票); helpsteer (偏好数据集|分数); helpsteer2 (偏好数据集|得分)。
- 添加MMT基础(MLLMS数据集|评估数据集);莫斯卡(MLLMS数据集|培训前CORPORA); MM-NIAH (MLLMS数据集|评估数据集)。
- 添加crag (抹布数据集)。
- ((2024/08/29)
- 添加GameBench (评估数据集|推理); Halludial (评估数据集|事实); Wildbench (评估数据集|常规); DomainEval (评估数据集|代码); sysbench (评估数据集|常规); Kobest (评估数据集| NLU); Sarcasmbench (评估数据集| NLU); C 3台(评估数据集|主题); TableBench (评估数据集|推理); ArableGaleval (评估数据集|法律)。
- 添加Multicrust (MLLMS数据集|评估数据集); obelisc (MLLMS数据集|培训前语料库);多媒体(MLLMS数据集|评估数据集)。
- 添加DCLM (培训前语料库|一般培训Corpora |网页)。
- 添加Lithuanian-QA-V1 (指令微调数据集| CI&MC);重新教导(指令微调数据集| HG&CI&MC); kollm converations (指令微调数据集| CI)。
- ((2024/09/04)
- 添加longwriter-6K (指令微调数据集| CI&MC)。
- 添加Medtrinity-25M (MLLMS数据集|评估数据集); MMIU (MLLMS数据集|评估数据集)。
- 添加Expository-Prose-V1 (培训前语料库|一般培训Corpora |多类)。
- 添加DebateQA (评估数据集|知识);针板架(评估数据集|长文本); Arabicmmlu (评估数据集|主题); Persianmmlu (评估数据集|主题); TMMLU+ (评估数据集|主题)。
- 添加rageval (抹布数据集); LFRQA (抹布数据集); Multihop-rag (抹布数据集)。
- 我们将以CSV格式发布数据集信息。
目录
- 培训前语料库
- 一般培训前语料库
- 网页
- 语言文字
- 图书
- 学术材料
- 代码
- 平行语料库
- 社交媒体
- 百科全书
- 多类
- 特定领域的预培训语料库
- 指令微调数据集
- 一般说明微调数据集
- 人类生成的数据集(HG)
- 模型构建数据集(MC)
- 现有数据集的收集和改进(CI)
- HG&CI
- HG&MC
- CI和MC
- HG&CI和MC
- 特定领域的指令微调数据集
- 偏好数据集
- 评估数据集
- 一般的
- 考试
- 主题
- nlu
- 推理
- 知识
- 长文字
- 工具
- 代理人
- 代码
- ood
- 法律
- 医疗的
- 金融的
- 社会规范
- 事实
- 评估
- 多任务
- 多种语言
- 其他
- 评估平台
- 传统的NLP数据集
- 问题回答
- 认识文本需要
- 数学
- 核心分辨率
- 情感分析
- 语义匹配
- 文字生成
- 文字翻译
- 文本摘要
- 文本分类
- 文本质量评估
- 文本对代码
- 命名实体识别
- 关系提取
- 多任务
- 多模式大语言模型(MLLM)数据集
- 检索增强发电(RAG)数据集
培训前语料库
培训前的语料库是在LLMS的培训过程中使用的大量文本数据收集。
一般培训前语料库
一般培训前语料库是由来自不同领域和来源的广泛文本组成的大型数据集。它们的主要特征是文本内容不仅限于单个领域,因此更适合培训一般基础模型。语料库是根据数据类别进行分类的。
数据集信息格式:
- Dataset name Release Time | Public or Not | Language | Construction Method | Paper | Github | Dataset | Website
- Publisher:
- Size:
- License:
- Source:
网页
CC-Stories 2018-6 |不是| en | CI |纸| github |数据集
- 出版商:Google Brain
- 尺寸:31 GB
- 执照: -
- 来源:普通爬网
CC100 2020-7 |全部|多(100)| CI |纸|数据集
- 出版商:Facebook AI
- 尺寸:2.5 TB
- 许可证:常见的使用条款
- 来源:普通爬网
Cluecorpus2020 2020-3 |全部| ZH | CI |纸|数据集
- 出版商:线索组织
- 尺寸:100 GB
- 许可证:麻省理工学院
- 来源:普通爬网
Common Crawl 2007-X |全部|多| HG |网站
- 出版商:普通爬网
- 尺寸: -
- 许可证:常见的使用条款
- 资料来源:网络爬网数据
Culturax 2023-9 |全部|多(167)| CI |纸|数据集
- 出版商:俄勒冈大学等。
- 尺寸:27 TB
- 许可证:MC4和奥斯卡许可证
- 资料来源:MC4,奥斯卡
C4 2019-10 |全部| en | CI |纸|数据集
- 出版商:Google Research
- 尺寸:12.68 TB
- 许可证:ODC-by&Common Crawl使用条款
- 来源:普通爬网
MC4 2021-6 |全部|多(108)| CI |纸|数据集
- 出版商:Google Research
- 尺寸:251 GB
- 许可证:ODC-by&Common Crawl使用条款
- 来源:普通爬网
奥斯卡22.01 2022-1 |全部|多(151)| CI |纸|数据集|网站
- 出版商:Inria
- 尺寸:8.41 TB
- 许可证:CC0
- 来源:普通爬网
Realnews 2019-5 |全部| en | CI |纸| github
- 出版商:华盛顿大学等。
- 尺寸:120 GB
- 许可证:Apache-2.0
- 来源:普通爬网
Redpajama-V2 2023-10 |全部|多(5)| CI | github |数据集|网站
- 发布者:一起计算机
- 尺寸:30.4 t令牌
- 许可证:常见的使用条款
- 资料来源:普通爬网,C4,等。
精制Web 2023-6 |部分| en | CI |纸|数据集
- 出版商:Falcon LLM团队
- 尺寸:5000 GB
- 许可证:ODC-BY-1.0
- 来源:普通爬网
wudaocorpora-Text 2021-6 |部分| ZH | HG |纸|数据集
- 出版商:Baai等。
- 尺寸:200 GB
- 许可证:麻省理工学院
- 资料来源:中文网页
Wanjuan-CC 2024-2 |部分| en | HG |纸|数据集
- 出版商:上海人工智能实验室
- 尺寸:1 T令牌
- 许可证:cc-by-4.0
- 来源:普通爬网
Madlad-400 2023-9 |全部|多(419)| HG |纸| github |数据集
- 出版商:Google Deepmind等。
- 尺寸:2.8 T令牌
- 许可证:odl-by
- 来源:普通爬网
FineWeb 2024-4 |全部| en | CI |数据集
- 发布者:HuggingFaceFW
- 尺寸:15 TB令牌
- 许可证:ODC-BY-1.0
- 来源:普通爬网
CCI 2.0 2024-4 |全部| ZH | HG | DataSet1 | DataSet2
- 出版商:Baai
- 尺寸:501 GB
- 许可证:CCI使用量
- 资料来源:中文网页
DCLM 2024-6 |全部| en | CI |纸| github |数据集|网站
- 出版商:华盛顿大学等。
- 尺寸:279.6 TB
- 许可证:常见的使用条款
- 来源:普通爬网
语言文字
ANC 2003-X |全部| en | HG |网站
- 出版商:美国国家科学基金会等。
- 尺寸: -
- 执照: -
- 资料来源:美国英语文本
BNC 1994-X |全部| en | HG |网站
- 出版商:牛津大学出版社等。
- 尺寸:4124个文本
- 执照: -
- 资料来源:英语英文文字
News-Crawl 2019-1 |全部|多(59)| HG |数据集
- 出版商:乌克里(Ukri)等。
- 尺寸:110 GB
- 许可证:CC0
- 资料来源:报纸
图书
安娜的档案2023-x |全部|多| HG |网站
- 出版商:安娜
- 尺寸:586.3 TB
- 执照: -
- 资料来源:科学枢纽,图书馆创世纪,Z-Library等。
BookCorpusopen 2021-5 |全部| en | CI |纸| github |数据集
- 出版商:Jack Bandy等。
- 大小:17,868本书
- 许可证:SmashWords服务条款
- 资料来源:多伦多书籍语料库
PG-19 2019-11 |全部| en | HG |纸| github |数据集
- 出版商:DeepMind
- 尺寸:11.74 GB
- 许可证:Apache-2.0
- 资料来源:Gutenberg项目
Gutenberg项目1971-X |全部|多| HG |网站
- 出版商:Ibiblio等。
- 尺寸: -
- 许可证:Gutenberg项目
- 资料来源:电子书数据
SmashWords 2008-X |全部|多| HG |网站
- 出版商:Draft2Digital等。
- 尺寸: -
- 许可证:SmashWords服务条款
- 资料来源:电子书数据
多伦多书籍语料库2015-6 |不是| en | HG |纸|网站
- 出版商:多伦多大学等。
- 大小:11,038本书
- 许可证:麻省理工学院和Smashwords服务条款
- 资料来源:SmashWords
学术材料
代码
BigQuery 2022-3 |不是| PL | CI |纸| github
- 出版商:Salesforce Research
- 尺寸:341.1 GB
- 许可证:Apache-2.0
- 资料来源:BigQuery
Github 2008-4 |全部| PL | HG |网站
- 发布者:Microsoft
- 尺寸: -
- 执照: -
- 资料来源:各种代码项目
PHI-1 2023-6 |不是| en&pl | HG&MC |纸|数据集
- 出版商:微软研究
- 尺寸:7 B代币
- 许可证:CC-BY-NC-SA-3.0
- 资料来源:堆栈,Stackoverflow,GPT-3.5代
堆栈2022-11 |全部| PL(358)| HG |纸|数据集
- 出版商:ServiceNow Research等。
- 尺寸:6 TB
- 许可证:原始许可证的条款
- 来源:允许许可的源代码文件
平行语料库
MTP 2023-9 |全部| en&zh | HG&CI |数据集
- 出版商:Baai
- 尺寸:1.3 TB
- 许可证:BAAI数据使用协议
- 资料来源:中文英语平行文字对
Multiun 2010-5 |全部|多(7)| HG |纸|网站
- 出版商:德国人工智能研究中心(DFKI)GMBH
- 尺寸:4353 MB
- 执照: -
- 资料来源:联合国文件
围塔2020-7 |全部|多(42)| HG |纸|网站
- 出版商:Prompsit等。
- 尺寸:59996文件
- 许可证:CC0
- 资料来源:网络爬网数据
Uncorpus v1.0 2016-5 |全部|多(6)| HG |纸|网站
- 出版商:联合国等人。
- 尺寸:799276文件
- 执照: -
- 资料来源:联合国文件
CCALIGNED 2020-11 |全部|多(138)| HG |纸|数据集
- 出版商:Facebook AI等。
- 尺寸:392 M URL对
- 执照: -
- 来源:普通爬网
Wikimatrix 2021-4 |全部|多(85)| HG |纸| github |数据集
- 出版商:Facebook AI等。
- 尺寸:134 M平行句子
- 许可证:cc-by-sa
- 资料来源:维基百科
社交媒体
OpenWebText 2019-4 |全部| en | HG |网站
- 出版商:布朗大学
- 尺寸:38 GB
- 许可证:CC0
- 来源:reddit
PushShift Reddit 2020-1 |全部| en | CI |纸|网站
- 出版商:PushShift.io等。
- 尺寸:2 TB
- 执照: -
- 来源:reddit
Reddit 2005-6 |全部| en | HG |网站
- 出版商:CondéNastDigital等。
- 尺寸: -
- 执照: -
- 资料来源:社交媒体帖子
Stackexchange 2008-9 |全部| en | HG |数据集|网站
- 出版商:Stack Exchange
- 尺寸: -
- 许可证:CC-BY-SA-4.0
- 资料来源:社区问答数据
WebText 2019-2 |部分| en | HG |纸| github |数据集
- 出版商:Openai
- 尺寸:40 GB
- 许可证:麻省理工学院
- 来源:reddit
Zhihu 2011-1 |全部| ZH | HG |网站
- 出版商:北京·吉兹·蒂安克西亚技术有限公司
- 尺寸: -
- 许可证:Zhihu用户协议
- 资料来源:社交媒体帖子
百科全书
Baidu Baike 2008-4 |全部| ZH | HG |网站
- 出版商:百度
- 尺寸: -
- 许可证:Baidu Baike用户协议
- 资料来源:百科全书内容数据
Tigerbot Wiki 2023-5 |全部| ZH | HG |纸| github |数据集
- 出版商:Tigerbot
- 尺寸:205 MB
- 许可证:Apache-2.0
- 资料来源:百度贝克
Wikipedia 2001-1 |全部|多| HG |数据集|网站
- 出版商:Wikimedia基金会
- 尺寸: -
- 许可证:cc-by-sa-3.0&gfdl
- 资料来源:百科全书内容数据
多类
Arabictext 2022 2022-12 |全部| ar | HG&CI |数据集
- 出版商:Baai等。
- 尺寸:201.9 GB
- 许可证:CC-BY-SA-4.0
- 资料来源:Arabicweb,Oscar,CC100等。
MNBVC 2023-1 |全部| ZH | HG&CI | github |数据集
- 出版商:Liwu社区
- 尺寸:20811 GB
- 许可证:麻省理工学院
- 资料来源:中文书籍,网页,论文等。
Redpajama-V1 2023-4 |全部|多| HG&CI | github |数据集
- 发布者:一起计算机
- 尺寸:1.2 t令牌
- 执照: -
- 资料来源:普通爬网,github,书籍等。
根2023-3 |部分|多(59)| HG&CI |纸|数据集
- 出版商:Hugging Face等。
- 尺寸:1.61 TB
- 许可证:Bloom Open-Rail-M
- 资料来源:Oscar,Github,等。
桩2021-1 |全部| en | HG&CI |纸| github |数据集
- 出版商:Eleutherai
- 尺寸:825.18 GB
- 许可证:麻省理工学院
- 资料来源:书籍,arxiv,github等。
Tigerbot_pretrain_en 2023-5 |部分| en | CI |纸| github |数据集
- 出版商:Tigerbot
- 尺寸:51 GB
- 许可证:Apache-2.0
- 资料来源:英语书籍,网页,恩维基等
Tigerbot_pretrain_zh 2023-5 |部分| ZH | HG |纸| github |数据集
- 出版商:Tigerbot
- 尺寸:55 GB
- 许可证:Apache-2.0
- 资料来源:中文书籍,网页,ZH-Wiki等。
Wanjuantext-1.0 2023-8 |全部| ZH | HG |纸| github |数据集
- 出版商:上海AI实验室
- 尺寸:1094 GB
- 许可证:cc-by-4.0
- 资料来源:网页,百科全书,书籍等
Dolma 2024-1 |全部| en | HG&CI |纸| github |数据集
- 出版商:AI2等。
- 尺寸:11519 GB
- 许可证:协议先生
- 资料来源:Gutenberg项目,C4,Reddit等。
Slimpajama 2023-6 |全部| en | HG&CI | github |数据集|网站
- 出版商:Cerebras等。
- 尺寸:627 B代币
- 执照: -
- 资料来源:Common Crawl,C4,Github,等。
massivetext 2021-12 |不是|多| HG&CI |纸
- 出版商:Google DeepMind
- 尺寸:10.5 TB
- 执照: -
- 资料来源:MassiveWeb,C4,书籍等。
密涅瓦2022-6 |不是| en | HG |纸
- 出版商:Google Research
- 尺寸:38.5 B代币
- 执照: -
- 资料来源:arxiv,网页等。
MAP-CC 2024-4 |全部| ZH | HG |纸| github |数据集|网站
- 出版商:多模式艺术投影研究社区等。
- 尺寸:840.48 b令牌
- 许可证:CC-BY-NC-ND-4.0
- 资料来源:中国普通爬行,中国百科全书,中文书等。
Expository-Prose-V1 2024-8 |全部| en | HG&CI |纸| github |数据集
- 出版商:pints.ai实验室
- 尺寸:56 B代币
- 许可证:麻省理工学院
- 资料来源:Arxiv,Wikipedia,Gutenberg等。
特定领域的预培训语料库
针对特定领域的预培训情况是针对特定字段或主题定制的LLM数据集。 LLMS的增量预训练阶段通常使用该语料库的类型。语料库是根据数据域进行分类的。
数据集信息格式:
- Dataset name Release Time | Public or Not | Language | Construction Method | Paper | Github | Dataset | Website
- Publisher:
- Size:
- License:
- Source:
- Category:
- Domain:
金融的
BBT-Fincorpus 2023-2 |部分| ZH | HG |纸| github |网站
- 出版商:Fudan University等。
- 尺寸:256 GB
- 执照: -
- 资料来源:公司公告,研究报告,财务
- 类别:多
- 领域:财务
Fincorpus 2023-9 |全部| ZH | HG |纸| github |数据集
- 出版商:Du Xiaoman
- 尺寸:60.36 GB
- 许可证:Apache-2.0
- 资料来源:公司公告,金融新闻,金融考试问题
- 类别:多
- 领域:财务
Finglm 2023-7 |全部| ZH | HG | github
- 出版商:知识Atlas等。
- 尺寸:69 GB
- 许可证:Apache-2.0
- 资料来源:上市公司的年度报告
- 类别:语言文本
- 领域:财务
Tigerbot-rowning 2023-5 |全部| ZH | HG |纸| github |数据集
- 出版商:Tigerbot
- 尺寸:488 MB
- 许可证:Apache-2.0
- 资料来源:财务报告
- 类别:语言文本
- 领域:财务
Tigerbot-Research 2023-5 |全部| ZH | HG |纸| github |数据集
- 出版商:Tigerbot
- 尺寸:696 MB
- 许可证:Apache-2.0
- 资料来源:研究报告
- 类别:语言文本
- 领域:财务
医疗的
数学
PIROCT-PILE-2 2023-10 |全部| en | HG&CI |纸| github |数据集|网站
- 出版商:普林斯顿大学等。
- 尺寸:55 B代币
- 执照: -
- 资料来源:Arxiv,OpenWebmath,代数
- 类别:多
- 域:数学
数学2023-12 |全部| en | HG |纸| github |数据集
- 出版商:上海若o汤大学等。
- 尺寸:9.5 B代币
- 许可证:CC-BY-NC-SA-4.0
- 资料来源:教科书,Wikipedia,Procectwiki,Common Crawl,Stackexchange,Arxiv
- 类别:多
- 域:数学
OpenWebmath 2023-10 |全部| en | HG |纸| github |数据集
- 出版商:多伦多大学等。
- 尺寸:14.7 B代币
- 许可证:ODC-BY-1.0
- 来源:普通爬网
- 类别:网页
- 域:数学
其他
指令微调数据集
指令微调数据集由一系列文本对组成,其中包括“指令输入”和“答案输出”。 “指令输入”表示人类对模型的要求。有多种类型的说明,例如分类,摘要,释义等。“答案输出”是按照指令所产生的响应,并与人类的期望保持一致。
一般说明微调数据集
一般指令微调数据集包含一个或多个没有域限制的指令类别,主要旨在增强一般任务中LLM的指令遵循能力。根据施工方法对数据集进行分类。
数据集信息格式:
- Dataset name Release Time | Public or Not | Language | Construction Method | Paper | Github | Dataset | Website
- Publisher:
- Size:
- License:
- Source:
- Instruction Category:
人类生成的数据集(HG)
databricks-dolly-15k 2023-4 |全部| en | HG |数据集|网站
- 发布者:Databricks
- 尺寸:15011实例
- 许可证:CC-BY-SA-3.0
- 资料来源:根据不同的指令类别手动生成
- 指令类别:多
指令wild_v2 2023-6 |全部| en&zh | HG | github
- 出版商:新加坡国立大学
- 尺寸:110k实例
- 执照: -
- 资料来源:在网上收集
- 指令类别:多
LCCC 2020-8 |全部| ZH | HG |纸| github
- 出版商:Tsinghua University等。
- 尺寸:12m实例
- 许可证:麻省理工学院
- 资料来源:社交媒体上的爬网用户互动
- 指令类别:多
OASST1 2023-4 |全部|多(35)| HG |纸| github |数据集
- 出版商:开放态
- 尺寸:161443实例
- 许可证:Apache-2.0
- 资料来源:人类产生和注释
- 指令类别:多
OL-CC 2023-6 |全部| ZH | HG |数据集
- 出版商:Baai
- 尺寸:11655实例
- 许可证:Apache-2.0
- 资料来源:人类产生和注释
- 指令类别:多
Zhihu-Kol 2023-3 |全部| ZH | HG | github |数据集
- 出版商:Wangrui6
- 尺寸:1006218实例
- 许可证:麻省理工学院
- 资料来源:从Zhihu爬行
- 指令类别:多
AYA数据集2024-2 |全部|多(65)| HG |纸|数据集|网站
- 出版商:AI Community等人的Cohere。
- 尺寸:204K实例
- 许可证:Apache-2.0
- 资料来源:通过AYA注释平台手动收集和注释
- 指令类别:多
指示2023-5 |全部| en&zh | HG |纸| github |数据集
- 出版商:Zhejiang University等。
- 尺寸:371700实例
- 许可证:麻省理工学院
- 资料来源:Baidu Baike,Wikipedia
- 指令类别:提取
模型构建数据集(MC)
羊Alpaca_data 2023-3 |全部| en | MC | github
- 出版商:斯坦福羊驼
- 尺寸:52K实例
- 许可证:Apache-2.0
- 资料来源:由aplaca_data提示由text-davinci-003生成
- 指令类别:多
belle_generated_chat 2023-5 |全部| ZH | MC | github |数据集
- 出版商:Belle
- 尺寸:396004实例
- 许可证:GPL-3.0
- 资料来源:Chatgpt生成
- 指令类别:生成
belle_multiturn_chat 2023-5 |全部| ZH | MC | github |数据集
- 出版商:Belle
- 尺寸:831036实例
- 许可证:GPL-3.0
- 资料来源:Chatgpt生成
- 指令类别:多
belle_train_0.5m_cn 2023-4 |全部| ZH | MC | github |数据集
- 出版商:Belle
- 尺寸:519255实例
- 许可证:GPL-3.0
- 资料来源:由text-davinci-003生成
- 指令类别:多
Belle_train_1M_CN 2023-4 |全部| ZH | MC | github |数据集
- 出版商:Belle
- 尺寸:917424实例
- 许可证:GPL-3.0
- 资料来源:由text-davinci-003生成
- 指令类别:多
belle_train_2m_cn 2023-5 |全部| ZH | MC | github |数据集
- 出版商:Belle
- 尺寸:2M实例
- 许可证:GPL-3.0
- 资料来源:Chatgpt生成
- 指令类别:多
belle_train_3.5m_cn 2023-5 |全部| ZH | MC | github |数据集
- 出版商:Belle
- 尺寸:3606402实例
- 许可证:GPL-3.0
- 资料来源:Chatgpt生成
- 指令类别:多
骆驼2023-3 |全部|多与PL | MC |纸| github |数据集|网站
- 出版商:Kaust
- 尺寸:1659328实例
- 许可证:CC-BY-NC-4.0
- 资料来源:由两个GPT-3.5-Turbo代理产生的对话
- 指令类别:多
chatgpt_corpus 2023-6 |全部| ZH | MC | github
- 出版商:Plexpt
- 尺寸:3270k实例
- 许可证:GPL-3.0
- 资料来源:由GPT-3.5-Turbo生成
- 指令类别:多
指令wild_v1 2023-3 |全部| en&zh | MC | github
- 出版商:新加坡国立大学
- 尺寸:104K实例
- 执照: -
- 资料来源:由OpenAI API生成
- 指令类别:多
LMSYS-CHAT-1M 2023-9 |全部|多| MC |纸|数据集
- 出版商:UC Berkeley等。
- 尺寸:1M实例
- 许可证:LMSYS-CHAT-1M许可证
- 资料来源:由多个LLM生成
- 指令类别:多
MOSS_002_SFT_DATA 2023-4 |全部| en&zh | MC | github |数据集
- 出版商:福丹大学
- 尺寸:1161137实例
- 许可证:CC-BY-NC-4.0
- 资料来源:由text-davinci-003生成
- 指令类别:多
MOSS_003_SFT_DATA 2023-4 |全部| en&zh | MC | github |数据集
- 出版商:福丹大学
- 尺寸:1074551实例
- 许可证:CC-BY-NC-4.0
- 资料来源:MOSS-002的对话数据,由GPT-3.5-Turbo生成
- 指令类别:多
moss_003_sft_plugin_data 2023-4 |部分| en&zh | MC | github |数据集
- 出版商:福丹大学
- 尺寸:300K实例
- 许可证:CC-BY-NC-4.0
- 资料来源:插件和LLMS生成
- 指令类别:多
OpenChat 2023-7 |全部| en | MC |纸| github |数据集
- 出版商:Tsinghua University等。
- 尺寸:70k实例
- 许可证:麻省理工学院
- 资料来源:sharegpt
- 指令类别:多
REDGPT-DATASET-V1-CN 2023-4 |部分| ZH | MC | github
- 出版商:Da-Southampton
- 尺寸:50k实例
- 许可证:Apache-2.0
- 资料来源:LLMS生成
- 指令类别:多
自我指导2022-12 |全部| en | MC |纸| github
- 出版商:华盛顿大学等。
- 尺寸:52445实例
- 许可证:Apache-2.0
- 资料来源:由GPT-3生成
- 指令类别:多
Sharechat 2023-4 |全部|多| MC |网站
- 出版商:Sharechat
- 尺寸:90k实例
- 许可证:CC0
- 资料来源:sharegpt
- 指令类别:多
sharegpt-chinese-english-90k 2023-7 |全部| en&zh | MC | github |数据集
- 出版商:ShareAi
- 尺寸:90k实例
- 许可证:Apache-2.0
- 资料来源:sharegpt
- 指令类别:多
sharegpt90k 2023-4 |全部| en | MC |数据集
- 出版商:Ryokoai
- 尺寸:90k实例
- 许可证:CC0
- 资料来源:sharegpt
- 指令类别:多
Ultrachat 2023-5 |全部| en | MC |纸| github
- 出版商:Tsinghua大学
- 尺寸:1468352实例
- 许可证:CC-BY-NC-4.0
- 资料来源:由两个Chatgpt代理产生的对话
- 指令类别:多
不自然的说明2022-12 |全部| en | MC |纸| github
- 出版商:特拉维夫大学等。
- 尺寸:240670实例
- 许可证:麻省理工学院
- 资料来源:LLMS生成
- 指令类别:多
WebGLM-QA 2023-6 |全部| en | MC |纸| github |数据集
- 出版商:Tsinghua University等。
- 尺寸:44979实例
- 许可证:Apache-2.0
- 资料来源:通过LLM构造WebGLM-QA
- 说明类别:打开质量检查
wizard_evol_instruct_196k 2023-6 |全部| en | MC |纸| github |数据集
- 出版商:Microsoft等。
- 大小:196K实例
- 执照: -
- 资料来源:通过Evol-Instruct方法进化说明
- 指令类别:多
wizard_evol_instruct_70k 2023-5 |全部| en | MC |纸| github |数据集
- 出版商:Microsoft等。
- 尺寸:70k实例
- 执照: -
- 资料来源:通过Evol-Instruct方法进化说明
- 指令类别:多
Wildchat 2024-5 |部分|多| MC |纸|数据集
- 出版商:康奈尔大学等。
- 尺寸:1039785实例
- 许可证:AI2 Impact许可证
- 资料来源:用户与chatgpt之间的对话,GPT-4
- 指令类别:多
现有数据集的收集和改进(CI)
CrossFit 2021-4 |全部| en | CI |纸| github
- 出版商:南加州大学
- 尺寸:269个数据集
- 执照: -
- 资料来源:各种NLP数据集的收集和改进
- 指令类别:多
DialogStudio 2023-7 |全部| en | CI |纸| github |数据集
- 出版商:Salesforce AI等人。
- 尺寸:87个数据集
- 许可证:Apache-2.0
- 资料来源:各种NLP数据集的收集和改进
- 指令类别:多
Dynosaur 2023-5 |全部| en | CI |纸| github |数据集|网站
- 出版商:UCLA等。
- 尺寸:801900实例
- 许可证:Apache-2.0
- 资料来源:各种NLP数据集的收集和改进
- 指令类别:多
Flan-Mini 2023-7 |全部| en | CI |纸| github |数据集
- 出版商:新加坡技术大学
- 尺寸:134万个实例
- 许可证:CC
- 资料来源:收集和改进各种指令微调数据集
- 指令类别:多
Flan 2021 2021-9 |全部|多| CI |纸| github
- 出版商:Google Research
- 大小:62个数据集
- 许可证:Apache-2.0
- 资料来源:各种NLP数据集的收集和改进
- 指令类别:多
Flan 2022 2023-1 |部分|多| CI |纸| github |数据集
- 出版商:Google Research
- 尺寸:1836数据集
- 许可证:Apache-2.0
- 资料来源:收集和改进各种指令微调数据集
- 指令类别:多
指令2022-5 |全部| en | CI |纸| github
- 出版商:卡内基·梅隆大学
- 尺寸:59个数据集
- 许可证:Apache-2.0
- 资料来源:各种NLP数据集的收集和改进
- 指令类别:多
自然说明2021-4 |全部| en | CI |纸| github |数据集
- 出版商:艾伦Ai等人研究所。
- 大小:61个数据集
- 许可证:Apache-2.0
- 资料来源:各种NLP数据集的收集和改进
- 指令类别:多
OIG 2023-3 |全部| en | CI |数据集
- 出版商:Laion
- 大小:3878622实例
- 许可证:Apache-2.0
- 资料来源:收集和改进各种数据集
- 指令类别:多
Open-Platypus 2023-8 |全部| en | CI |纸| github |数据集|网站
- 出版商:波士顿大学
- 尺寸:24926实例
- 执照: -
- 资料来源:收集和改进各种数据集
- 指令类别:多
OPT-IML台2022-12 |不是|多| CI |纸| github
- 出版商:元AI
- 尺寸:2000个数据集
- 许可证:麻省理工学院
- 资料来源:各种NLP数据集的收集和改进
- 指令类别:多
提示Source 2022-2 |全部| en | CI |纸| github
- 出版商:布朗大学等。
- 尺寸:176个数据集
- 许可证:Apache-2.0
- 资料来源:各种NLP数据集的收集和改进
- 指令类别:多
超自然说明2022-4 |全部|多| CI |纸| github
- 出版商:大学。华盛顿等。
- 大小:1616个数据集
- 许可证:Apache-2.0
- 资料来源:各种NLP数据集的收集和改进
- 指令类别:多
T0 2021-10 |全部| en | CI |纸| DataSet1 | DataSet2
- 出版商:Hugging Face等。
- 大小:62个数据集
- 许可证:Apache-2.0
- 资料来源:各种NLP数据集的收集和改进
- 指令类别:多
Unifiedskg 2022-3 |全部| en | CI |纸| github
- 出版商:香港大学等。
- 大小:21个数据集
- 许可证:Apache-2.0
- 资料来源:各种NLP数据集的收集和改进
- 指令类别:多
XP3 2022-11 |全部|多(46)| CI |纸| github
- 出版商:Hugging Face等。
- 大小:82个数据集
- 许可证:Apache-2.0
- 资料来源:各种NLP数据集的收集和改进
- 指令类别:多
iepile 2024-2 |全部| en&zh | CI |纸| github |数据集
- 出版商:Zhejiang University等。
- 大小:33个数据集
- 许可证:CC-BY-NC-SA-4.0
- 资料来源:收集和改进各种IE数据集
- 指令类别:提取
Kollm-conversations 2024-3 |全部| ko | CI |数据集
- 出版商:Davidkim205
- 大小:1122566实例
- 许可证:Apache-2.0
- 资料来源:韩国数据集的收集和改进
- 指令类别:多
HG&CI
萤火虫2023-4 |全部| ZH | HG&CI | github |数据集
- 出版商:yeungnlp
- 大小:1649399实例
- 执照: -
- 资料来源:收集中文NLP数据集并手动生成与中国文化有关的数据
- 指令类别:多
Lima-SFT 2023-5 |全部| en | HG&CI |纸|数据集
- 出版商:Meta Ai等。
- 尺寸:1330实例
- 许可证:CC-BY-NC-SA
- 资料来源:手动从各种类型的数据中进行选择
- 指令类别:多
COIG-CQIA 2024-3 |全部| ZH | HG&CI |纸|数据集
- 出版商:深圳高级技术学院等。
- 尺寸:48375实例
- 执照: -
- 资料来源:问答社区,维基百科,考试,现有的NLP数据集
- 指令类别:多
HG&MC
- 指示示意-SFT 2022-3 |不是| en | HG&MC |纸
- 出版商:Openai
- 尺寸:14378实例
- 执照: -
- 资料来源:平台问答数据和手册标签
- 指令类别:多
CI和MC
羊Alpaca_gpt4_data 2023-4 |全部| en | CI&MC |纸| github
- 出版商:微软研究
- 尺寸:52K实例
- 许可证:Apache-2.0
- 资料来源:由GPT-4与Aplaca_data提示生成
- 指令类别:多
羊Alpaca_gpt4_data_zh 2023-4 |全部| ZH | CI&MC | github |数据集
- 出版商:微软研究
- 尺寸:52K实例
- 许可证:Apache-2.0
- 资料来源:由GPT-4与羊Alpaca_data提示生成
- 指令类别:多
Bactrain-X 2023-5 |全部|多(52)| CI&MC |纸| github |数据集
- 出版商:Mbzuai
- 尺寸:3484884实例
- 许可证:CC-BY-NC-4.0
- 资料来源:由aplaca_data和databricks-dolly-15k提示由GPT-3.5-Turbo生成
- 指令类别:多
Baize 2023-3 |部分| en | CI&MC |纸| github |数据集
- 出版商:加利福尼亚大学等。
- 尺寸:210311实例
- 许可证:GPL-3.0
- 资料来源:从特定数据集中采样种子,以创建使用CHATGPT的多转话对话
- 指令类别:多
GPT4ALL 2023-3 |全部| en | CI&MC |纸| github |数据集
- 出版商:提名-AI
- 尺寸:739259实例
- 许可证:麻省理工学院
- 资料来源:由GPT-3.5-Turbo生成其他数据集的提示
- 指令类别:多
Guanacodataset 2023-3 |全部|多| CI&MC |数据集|网站
- 出版商:约瑟夫琴
- 尺寸:534530实例
- 许可证:GPL-3.0
- 资料来源:从羊驼模型上扩展最初的52K数据集
- 指令类别:多
Lamini-LM 2023-4 |全部| en | CI&MC |纸| github |数据集
- 出版商:莫纳什大学等。
- 尺寸:2585615实例
- 许可证:CC-BY-NC-4.0
- 资料来源:由Chatgpt与合成和现有提示生成
- 指令类别:多
Logicot 2023-5 |全部| en&zh | CI&MC |纸| github |数据集
- 出版商:Westlake University等。
- 尺寸:604840实例
- 许可证:CC-BY-NC-ND-4.0
- 资料来源:使用GPT-4扩展数据集
- 说明类别:推理
Longform 2023-4 |全部| en | CI & MC |纸| github |数据集
- Publisher: LMU Munich et al.
- Size: 27739 instances
- 许可证:麻省理工学院
- Source: Select documents from existing corpora and generating prompts for the documents using LLMs
- Instruction Category: Multi
Luotuo-QA-B 2023-5 |全部| EN & ZH | CI & MC | github |数据集
- Publisher: Luotuo
- Size: 157320 instances
- License: Apache-2.0 & CC0
- Source: Use LLMs to generate Q&A pairs on CSL, arXiv, and CNN-DM datasets
- Instruction Category: Multi
OpenOrca 2023-6 |全部|多| CI & MC |纸|数据集
- Publisher: Microsoft Researc
- Size: 4233923 instances
- 许可证:麻省理工学院
- Source: Expand upon the Flan 2022 dataset using GPT-3.5-Turbo and GPT-4
- Instruction Category: Multi
Wizard_evol_instruct_zh 2023-5 |全部| ZH | CI & MC | github |数据集
- Publisher: Central China Normal University et al.
- Size: 70K instances
- License: CC-BY-4.0
- Source: Generated by GPT with Wizard_evol_instruct prompts translated into Chinese
- Instruction Category: Multi
Lithuanian-QA-v1 2024-8 |全部| LT | CI & MC |纸|数据集
- Publisher: Neurotechnology
- Size: 13848 instances
- License: CC-BY-4.0
- Source: Use ChatGPT to generate Q&A pairs on Wikipedia corpus
- Instruction Category: Multi
LongWriter-6K 2024-8 |全部| EN & ZH | CI & MC |纸| github |数据集
- Publisher: Tsinghua University et al.
- Size: 6000 instances
- 许可证:Apache-2.0
- Source: Generated by GPT-4o with open-source datasets' prompts
- Instruction Category: Multi
HG & CI & MC
COIG 2023-4 |全部| ZH | HG & CI & MC |纸| github |数据集
- Publisher: BAAI
- Size: 191191 instances
- 许可证:Apache-2.0
- Source: Translated instructions, Leetcode, Chinese exams, etc.
- Instruction Category: Multi
HC3 2023-1 |全部| EN & ZH | HG & CI & MC |纸| github | Dataset1 | Dataset2
- Publisher: SimpleAI
- Size: 37175 instances
- License: CC-BY-SA-4.0
- Source: Human-Q&A pairs and ChatGPT-Q&A pairs from Q&A platforms, encyclopedias, etc.
- Instruction Category: Multi
Phoenix-sft-data-v1 2023-5 |全部|多| HG & CI & MC |纸| github |数据集
- Publisher: The Chinese University of Hong Kong et al.
- Size: 464510 instances
- License: CC-BY-4.0
- Source: Collected multi-lingual instructions, post-translated multi-lingual instructions, self-generated user-centered multi-lingual instructions
- Instruction Category: Multi
TigerBot_sft_en 2023-5 |部分| en | HG & CI & MC |纸| github |数据集
- Publisher: TigerBot
- Size: 677117 instances
- 许可证:Apache-2.0
- Source: Self-instruct, human-labeling, open-source data cleaning
- Instruction Category: Multi
TigerBot_sft_zh 2023-5 |部分| ZH | HG & CI & MC |纸| github |数据集
- Publisher: TigerBot
- Size: 530705 instances
- 许可证:Apache-2.0
- Source: Self-instruct, human-labeling, open-source data cleaning
- Instruction Category: Multi
Aya Collection 2024-2 |全部| Multi (114) | HG & CI & MC |纸|数据集|网站
- Publisher: Cohere For AI Community et al.
- Size: 513M instances
- 许可证:Apache-2.0
- Source: Templated data, Translated data and Aya Dataset
- Instruction Category: Multi
REInstruct 2024-8 |不是| en | HG & CI & MC |纸| github
- Publisher: Chinese Information Processing Laboratory et al.
- Size: 35K instances
- 执照: -
- Source: Automatically constructing instruction data from the C4 corpus using a small amount of manually annotated seed instruction data
- Instruction Category: Multi
Domain-specific Instruction Fine-tuning Datasets
The domain-specific instruction fine-tuning datasets are constructed for a particular domain by formulating instructions that encapsulate knowledge and task types closely related to that domain.
Dataset information format:
- Dataset name Release Time | Public or Not | Language | Construction Method | Paper | Github | Dataset | Website
- Publisher:
- Size:
- License:
- Source:
- Instruction Category:
- Domain:
医疗的
ChatDoctor 2023-3 |全部| en | HG & MC |纸| github |数据集
- Publisher: University of Texas Southwestern Medical Center et al.
- Size: 115K instances
- 许可证:Apache-2.0
- Source: Real conversations between doctors and patients & Generated by ChatGPT
- Instruction Category: Multi
- Domain: Medical
ChatMed_Consult_Dataset 2023-5 |全部| ZH | MC | github |数据集
- Publisher: michael-wzhu
- Size: 549326 instances
- License: CC-BY-NC-4.0
- Source: Generated by GPT-3.5-Turbo
- Instruction Category: Multi
- Domain: Medical
CMtMedQA 2023-8 |全部| ZH | HG |纸| github |数据集
- Publisher: Zhengzhou University
- Size: 68023 instances
- 许可证:麻省理工学院
- Source: Real conversations between doctors and patients
- Instruction Category: Multi
- Domain: Medical
DISC-Med-SFT 2023-8 |全部| ZH | HG & CI |纸| github |数据集|网站
- Publisher: Fudan University et al.
- Size: 464898 instances
- 许可证:Apache-2.0
- Source: Open source datasets & Manually selected data
- Instruction Category: Multi
- Domain: Medical
HuatuoGPT-sft-data-v1 2023-5 |全部| ZH | HG & MC |纸| github |数据集
- Publisher: The Chinese University of Hong Kong et al.
- Size: 226042 instances
- 许可证:Apache-2.0
- Source: Real conversations between doctors and patients & Generated by ChatGPT
- Instruction Category: Multi
- Domain: Medical
Huatuo-26M 2023-5 |部分| ZH | CI |纸| github
- Publisher: The Chinese University of Hong Kong et al.
- Size: 26504088 instances
- 许可证:Apache-2.0
- Source: Collection and improvement of various datasets
- Instruction Category: Multi
- Domain: Medical
MedDialog 2020-4 |全部| EN & ZH | HG |纸| github
- Publisher: UC San Diego
- Size: 3.66M instances
- 执照: -
- Source: Real conversations between doctors and patients
- Instruction Category: Multi
- Domain: Medical
Medical Meadow 2023-4 |全部| en | HG & CI |纸| github |数据集
- Publisher: University Hospital Aachen et al.
- Size: 160076 instances
- 许可证:GPL-3.0
- Source: Crawl data from the Internet & Collection and improvement of various NLP datasets
- Instruction Category: Multi
- Domain: Medical
Medical-sft 2023-5 |全部| EN & ZH | CI | github |数据集
- Publisher: Ming Xu
- Size: 2.07M instances
- 许可证:Apache-2.0
- Source: Collection and improvement of various NLP datasets
- Instruction Category: Multi
- Domain: Medical
QiZhenGPT-sft-20k 2023-5 |部分| ZH | CI | github |数据集
- Publisher: Zhejiang University
- Size: 20K instances
- 许可证:GPL-3.0
- Source: Collection and improvement of various datasets
- Instruction Category: Multi
- Domain: Medical
ShenNong_TCM_Dataset 2023-6 |全部| ZH | MC | github |数据集
- Publisher: michael-wzhu
- Size: 112565 instances
- 许可证:Apache-2.0
- Source: Generated by ChatGPT
- Instruction Category: Multi
- Domain: Medical
代码
Code_Alpaca_20K 2023-3 |全部| EN & PL | MC | github |数据集
- Publisher: Sahil Chaudhary
- Size: 20K instances
- 许可证:Apache-2.0
- Source: Generated by Text-Davinci-003
- Instruction Category: Code
- Domain: Code
CodeContest 2022-3 |全部| EN & PL | CI |纸| github
- Publisher: DeepMind
- Size: 13610 instances
- 许可证:Apache-2.0
- Source: Collection and improvement of various datasets
- Instruction Category: Code
- Domain: Code
CommitPackFT 2023-8 |全部| EN & PL (277) | HG |纸| github |数据集
- Publisher: Bigcode
- Size: 702062 instances
- 许可证:麻省理工学院
- Source: GitHub Action dump
- Instruction Category: Code
- Domain: Code
ToolAlpaca 2023-6 |全部| EN & PL | HG & MC |纸| github
- Publisher: Chinese Information Processing Laboratory et al.
- Size: 3928 instances
- 许可证:Apache-2.0
- Source: Manually filter APIs & Generated by ChatGPT
- Instruction Category: Code
- Domain: Code
ToolBench 2023-7 |全部| EN & PL | HG & MC |纸| github
- Publisher: Tsinghua University et al.
- Size: 126486 instances
- 许可证:Apache-2.0
- Source: Manually filter APIs & Generated by ChatGPT
- Instruction Category: Code
- Domain: Code
合法的
DISC-Law-SFT 2023-9 |部分| ZH | HG & CI & MC |纸| github |网站
- Publisher: Fudan University et al.
- Size: 403K instances
- 许可证:Apache-2.0
- Source: Open source datasets & Legal-related Text Content & Generated by GPT-3.5-Turbo
- Instruction Category: Multi
- Domain: Law
HanFei 1.0 2023-5 |全部| ZH | - | github |数据集
- Publisher: Chinese Academy of Sciences et al.
- Size: 255K instances
- 许可证:Apache-2.0
- Source: Filter legal-related data according to rules
- Instruction Category: Multi
- Domain: Law
LawGPT_zh 2023-5 |部分| ZH | CI & MC | github |数据集
- Publisher: Shanghai Jiao Tong University
- Size: 200K instances
- 执照: -
- Source: Real conversations & Generated by ChatGPT
- Instruction Category: Multi
- Domain: Law
Lawyer LLaMA_sft 2023-5 |部分| ZH | CI & MC |纸| github |数据集
- Publisher: Peking Universit
- Size: 21476 instances
- 许可证:Apache-2.0
- Source: Generated by ChatGPT with other datasets' prompts
- Instruction Category: Multi
- Domain: Law
数学
BELLE_School_Math 2023-5 | All | ZH | MC | github |数据集
- Publisher: BELLE
- Size: 248481 instances
- 许可证:GPL-3.0
- Source: Generated by ChatGPT
- Instruction Category: Math
- Domain: Math
Goat 2023-5 |全部| en | HG |纸| github |数据集
- Publisher: National University of Singapore
- Size: 1746300 instances
- 许可证:Apache-2.0
- Source: Artificially synthesized data
- Instruction Category: Math
- Domain: Math
MWP 2021-9 |全部| EN & ZH | CI |纸| github |数据集
- Publisher: Xihua University et al.
- Size: 251598 instances
- 许可证:麻省理工学院
- Source: Collection and improvement of various datasets
- Instruction Category: Math
- Domain: Math
OpenMathInstruct-1 2024-2 | All | en | CI & MC |纸| github |数据集
- 出版商:NVIDIA
- Size: 1.8M instances
- License: NVIDIA License
- Source: GSM8K and MATH datasets (original questions); Generated using Mixtral-8×7B model
- Instruction Category: Math
- Domain: Math
教育
Child_chat_data 2023-8 | All | ZH | HG & MC | github
- Publisher: Harbin Institute of Technology et al.
- Size: 5000 instances
- 执照: -
- Source: Real conversations & Generated by GPT-3.5-Turbo
- Instruction Category: Multi
- Domain: Education
Educhat-sft-002-data-osm 2023-7 |全部| EN & ZH | CI |纸| github |数据集
- Publisher: East China Normal University et al.
- Size: 4279419 instances
- License: CC-BY-NC-4.0
- Source: Collection and improvement of various datasets
- Instruction Category: Multi
- Domain: Education
TaoLi_data 2023-X | All | ZH | HG & CI | github |数据集
- Publisher: Beijing Language and Culture University et al.
- Size: 88080 instances
- 许可证:Apache-2.0
- Source: Collection and improvement of various datasets & Manually extract dictionary data
- Instruction Category: Multi
- Domain: Education
其他
DISC-Fin-SFT 2023-10 |部分| ZH | HG & CI & MC |纸| github |网站
- Publisher: Fudan University et al.
- Size: 246K instances
- 许可证:Apache-2.0
- Source: Open source datasets & Manually collect financial data & ChatGPT assistance
- Instruction Category: Multi
- Domain: Financial
AlphaFin 2024-3 | All | EN & ZH | HG & CI & MC |纸| github |数据集
- Publisher: South China University of Technology et al.
- Size: 167362 instances
- 许可证:Apache-2.0
- Source: Traditional research datasets, real-time financial data, handwritten CoT data
- Instruction Category: Multi
- Domain: Financial
GeoSignal 2023-6 |部分| en | HG & CI & MC |纸| github |数据集
- Publisher: Shanghai Jiao Tong University et al.
- Size: 22627272 instances
- 许可证:Apache-2.0
- Source: Open source datasets & Geoscience-related Text Content & Generated by GPT-4
- Instruction Category: Multi
- Domain: Geoscience
MeChat 2023-4 | All | ZH | CI & MC |纸| github |数据集
- Publisher: Zhejiang University et al.
- Size: 56K instances
- License: CC0-1.0
- Source: Based on PsyQA dataset with the proposed SMILE method
- Instruction Category: Multi
- Domain: Mental Health
Mol-Instructions 2023-6 | All | en | HG & CI & MC |纸| github |数据集
- Publisher: Zhejiang University et al.
- Size: 2043586 instances
- License: CC-BY-4.0
- Source: Molecule-oriented, Protein-oriented, Biomolecular text instructions
- Instruction Category: Multi
- Domain: Biology
Owl-Instruction 2023-9 | All | EN & ZH | HG & MC |纸| github
- Publisher: Beihang University et al.
- Size: 17858 instances
- 执照: -
- Source: Generated by GPT-4 & Manual verification
- Instruction Category: Multi
- Domain: IT
PROSOCIALDIALOG 2022-5 | All | en | HG & MC |纸|数据集
- Publisher: Allenai
- Size: 165681 instances
- License: CC-BY-4.0
- Source: Generated by humans with GPT-3 created prompts
- Instruction Category: Social Norms
- Domain: Social Norms
TransGPT-sft 2023-7 | All | ZH | HG | github |数据集
- Publisher: Beijing Jiaotong University
- Size: 58057 instances
- 许可证:Apache-2.0
- Source: Manually collect traffic-related data
- Instruction Category: Multi
- Domain: Transportation
Preference Datasets
Preference datasets are collections of instructions that provide preference evaluations for multiple responses to the same instruction input.
Preference Evaluation Methods
The preference evaluation methods for preference datasets can be categorized into voting, sorting, scoring, and other methods. Datasets are classified based on preference evaluation methods.
Dataset information format:
- Dataset name Release Time | Public or Not | Language | Construction Method | Paper | Github | Dataset | Website
- Publisher:
- Size:
- License:
- Domain:
- Instruction Category:
- Preference Evaluation Method:
- Source:
投票
Chatbot_arena_conversations 2023-6 | All |多| HG & MC |纸|数据集
- Publisher: UC Berkeley et al.
- Size: 33000 instances
- License: CC-BY-4.0 & CC-BY-NC-4.0
- Domain: General
- Instruction Category: Multi
- Preference Evaluation Method: VO-H
- Source: Generated by twenty LLMs & Manual judgment
hh-rlhf 2022-4 | All | en | HG & MC | Paper1 | Paper2 | github |数据集
- Publisher: Anthropic
- Size: 169352 instances
- 许可证:麻省理工学院
- Domain: General
- Instruction Category: Multi
- Preference Evaluation Method: VO-H
- Source: Generated by LLMs & Manual judgment
MT-Bench_human_judgments 2023-6 |全部| en | HG & MC |纸| github |数据集|网站
- Publisher: UC Berkeley et al.
- Size: 3.3K instances
- License: CC-BY-4.0
- Domain: General
- Instruction Category: Multi
- Preference Evaluation Method: VO-H
- Source: Generated by LLMs & Manual judgment
PKU-SafeRLHF 2023-7 |部分| en | HG & CI & MC |纸| github |数据集
- Publisher: Peking University
- Size: 361903 instances
- License: CC-BY-NC-4.0
- Domain: Social Norms
- Instruction Category: Social Norms
- Preference Evaluation Method: VO-H
- Source: Generated by LLMs & Manual judgment
SHP 2021-10 | All | en | HG |纸| github | Dataset
- Publisher: Stanford
- Size: 385563 instances
- 执照: -
- Domain: General
- Instruction Category: Multi
- Preference Evaluation Method: VO-H
- Source: Reddit data & Manual judgment
Zhihu_rlhf_3k 2023-4 | All | ZH | HG | Dataset
- Publisher: Liyucheng
- Size: 3460 instances
- License: CC-BY-2.0
- Domain: General
- Instruction Category: Multi
- Preference Evaluation Method: VO-H
- Source: Zhihu data & Manual judgment
Summarize_from_Feedback 2020-9 | All | en | HG & CI |纸| Dataset
- Publisher: OpenAI
- Size: 193841 instances
- 执照: -
- Domain: News
- Instruction Category: Multi
- Preference Evaluation Method: VO-H & SC-H
- Source: Open source datasets & Manual judgment and scoring
CValues 2023-7 | All | ZH | MC |纸| github | Dataset
- Publisher: Alibaba Group
- Size: 145K instances
- 许可证:Apache-2.0
- Domain: Social Norms
- Instruction Category: Social Norms
- Preference Evaluation Method: VO-M
- Source: Generated by LLMs & Evaluation by the reward model
huozi_rlhf_data 2024-2 | All | ZH | HG & MC | github | Dataset
- Publisher: Huozi-Team
- Size: 16918 instances
- 许可证:Apache-2.0
- Domain: General
- Instruction Category: Multi
- Preference Evaluation Method: VO-H
- Source: Generated by Huozi model & Manual judgment
种类
- OASST1_pairwise_rlhf_reward 2023-5 | All |多| CI | Dataset
- Publisher: Tasksource
- Size: 18918 instances
- 许可证:Apache-2.0
- Domain: General
- Instruction Category: Multi
- Preference Evaluation Method: SO-H
- Source: OASST1 datasets & Manual sorting
分数
Stack-Exchange-Preferences 2021-12 | All | en | HG |纸| Dataset
- Publisher: Anthropic
- Size: 10807695 instances
- License: CC-BY-SA-4.0
- Domain: General
- Instruction Category: Multi
- Preference Evaluation Method: SC-H
- Source: Stackexchange data & Manual scoring
WebGPT 2021-12 | All | en | HG & CI |纸| Dataset
- Publisher: OpenAI
- Size: 19578 instances
- 执照: -
- Domain: General
- Instruction Category: Multi
- Preference Evaluation Method: SC-H
- Source: Open source datasets & Manual scoring
Alpaca_comparison_data 2023-3 | All | en | MC | github
- Publisher: Stanford Alpaca
- Size: 51K instances
- 许可证:Apache-2.0
- Domain: General
- Instruction Category: Multi
- Preference Evaluation Method: SC-M
- Source: Generated by three LLMs & GPT-4 scoring
Stable_Alignment 2023-5 |全部| en | MC |纸| github
- Publisher: Dartmouth College et al.
- Size: 169K instances
- 许可证:Apache-2.0
- Domain: General
- Instruction Category: Multi
- Preference Evaluation Method: SC-M
- Source: Generated by LLMs & Model scoring
UltraFeedback 2023-10 | All | en | CI & MC |纸| github | Dataset
- Publisher: Tsinghua University et al.
- Size: 63967 instances
- 许可证:麻省理工学院
- Domain: General
- Instruction Category: Multi
- Preference Evaluation Method: SC-M
- Source: Generated by seventeen LLMs & Model scoring
OpenHermesPreferences 2024-2 | All | en | CI & MC | Dataset
- Publisher: Argilla et al.
- Size: 989490 instances
- 执照: -
- Domain: General
- Instruction Category: Multi
- Preference Evaluation Method: SO-M
- Source: OpenHermes-2.5 dataset & Model sorting
HelpSteer 2023-11 | All | en | HG & CI & MC |纸| Dataset
- 出版商:NVIDIA
- Size: 37120 instances
- License: CC-BY-4.0
- Domain: General
- Instruction Category: Multi
- Preference Evaluation Method: SC-H
- Source: Generated by LLMs & Manual judgment
HelpSteer2 2024-6 | All | en | HG & CI & MC |纸| github | Dataset
- 出版商:NVIDIA
- Size: 21362 instances
- License: CC-BY-4.0
- Domain: General
- Instruction Category: Multi
- Preference Evaluation Method: SC-H
- Source: Generated by LLMs & Manual judgment
其他
Evaluation Datasets
Evaluation datasets are a carefully curated and annotated set of data samples used to assess the performance of LLMs across various tasks. Datasets are classified based on evaluation domains.
Dataset information format:
- Dataset name Release Time | Public or Not | Language | Construction Method | Paper | Github | Dataset | Website
- Publisher:
- Size:
- License:
- Question Type:
- Evaluation Method:
- Focus:
- Numbers of Evaluation Categories/Subcategories:
- Evaluation Category:
一般的
AlpacaEval 2023-5 | All | en | CI & MC |纸| github |数据集|网站
- Publisher: Stanford et al.
- Size: 805 instances
- 许可证:Apache-2.0
- Question Type: SQ
- Evaluation Method: ME
- Focus: The performance on open-ended question answering
- Numbers of Evaluation Categories/Subcategories: 1/-
- Evaluation Category: Open-ended question answering
BayLing-80 2023-6 | All | EN & ZH | HG & CI |纸| github | Dataset
- Publisher: Chinese Academy of Sciences
- Size: 320 instances
- 许可证:GPL-3.0
- Question Type: SQ
- Evaluation Method: ME
- Focus: Chinese-English language proficiency and multimodal interaction skills
- Numbers of Evaluation Categories/Subcategories: 9/-
- Evaluation Category: Writing, Roleplay, Common-sense, Fermi, Counterfactual, Coding, Math, Generic, Knowledge
BELLE_eval 2023-4 |全部| ZH | HG & MC |纸| github
- Publisher: BELLE
- Size: 1000 instances
- 许可证:Apache-2.0
- Question Type: SQ
- Evaluation Method: ME
- Focus: The performance of Chinese language models in following instructions
- Numbers of Evaluation Categories/Subcategories: 9/-
- Evaluation Category: Extract, Closed qa, Rewrite, Summarization, Generation, Classification, Brainstorming, Open qa, Others
CELLO 2023-9 | All | en | HG |纸| github
- Publisher: Fudan University et al.
- Size: 523 instances
- 执照: -
- Question Type: SQ
- Evaluation Method: CE
- Focus: The ability of LLMs to understand complex instructions
- Numbers of Evaluation Categories/Subcategories: 2/10
- Evaluation Category: Complex task description, Complex input
MT-Bench 2023-6 | All | en | HG |纸| github |网站
- Publisher: UC Berkeley et al.
- Size: 80 instances
- 许可证:Apache-2.0
- Question Type: SQ
- Evaluation Method: ME
- Focus: The performance on open-ended question answering
- Numbers of Evaluation Categories/Subcategories: 8/-
- Evaluation Category: Writing, Roleplay, Reasoning, Math, Coding, Extraction, STEM, Humanities
SuperCLUE 2023-7 |不是| ZH | HG & MC |纸| github | Website1 | Website2
- Publisher: CLUE et al.
- Size: 3754 instances
- 执照: -
- Question Type: Multi
- Evaluation Method: HE & CE
- Focus: The performance in a Chinese context
- Numbers of Evaluation Categories/Subcategories: 2/-
- Evaluation Category: Open multi-turn open questions, OPT objective questions
Vicuna Evaluation 2023-3 | All | en | HG | github |数据集|网站
- Publisher: LMSYS ORG
- Size: 80 instances
- 许可证:Apache-2.0
- Question Type: SQ
- Evaluation Method: ME
- Focus: The performance on open-ended question answering
- Numbers of Evaluation Categories/Subcategories: 9/-
- Evaluation Category: Generic, Knowledge, Roleplay, Common-sense, Fermi, Counterfactual, Coding, Math, Writing
CHC-Bench 2024-4 |全部| ZH | HG & CI |纸| github |数据集|网站
- Publisher: Multimodal Art Projection Research Community et al.
- Size: 214 instances
- 许可证:Apache-2.0
- Question Type: Multi
- Evaluation Method: ME
- Focus: Hard-case Chinese instructions understanding and following
- Numbers of Evaluation Categories/Subcategories: 8/-
- Evaluation Category: Writing, Humanity, Science, Role-playing, Reading Comprehension, Math, Hard Cases, Coding
CIF-Bench 2024-2 | Partial | ZH | HG & CI |纸| github |网站
- Publisher: University of Manchester et al.
- Size: 15K instances
- 执照: -
- Question Type: SQ
- Evaluation Method: CE & ME
- Focus: Evaluate the zero-shot generalizability of LLMs to the Chinese language
- Numbers of Evaluation Categories/Subcategories: 10/150
- Evaluation Category: Chinese culture, Classification, Code, Commonsense, Creative NLG, Evaluation, Grammar, Linguistic, Motion detection, NER
WildBench 2024-6 | All | en | HG & CI |纸| github |数据集|网站
- Publisher: Allen Institute for AI et al.
- Size: 1024 instances
- License: AI2 ImpACT License
- Question Type: SQ
- Evaluation Method: ME
- Focus: An automated evaluation framework designed to benchmark LLMs using challenging, real-world user queries.
- Numbers of Evaluation Categories/Subcategories: 11/-
- Evaluation Category: Information seeking, Coding & Debugging, Creative writing, Reasoning, Planning, Math, Editing, Data analysis, Role playing, Brainstorming, Advice seeking
SysBench 2024-8 | All | en | HG |纸| github | Dataset
- Publisher: Peking University et al.
- Size: 500 instances
- 执照: -
- Question Type: SQ
- Evaluation Method: ME
- Focus: Systematically analyze system message following ability
- Numbers of Evaluation Categories/Subcategories: 3/-
- Evaluation Category: Constraint complexity, Instruction misalignment, Multi-turn stability
考试
AGIEval 2023-4 | All | EN & ZH | HG & CI |纸| github | Dataset
- Publisher: Microsoft
- Size: 8062 instances
- 许可证:麻省理工学院
- Question Type: OQ
- Evaluation Method: CE
- Focus: Human-centric standardized exams
- Numbers of Evaluation Categories/Subcategories: 7/20
- Evaluation Category: Gaokao, SAT, JEC, LSAT, LogiQA, AQuA-RAT, Math
GAOKAO-Bench 2023-5 | All | ZH | HG |纸| github
- Publisher: Fudan University et al.
- Size: 2811 instances
- 许可证:Apache-2.0
- Question Type: Multi
- Evaluation Method: HE & CE
- Focus: Chinese Gaokao examination
- Numbers of Evaluation Categories/Subcategories: 10/-
- Evaluation Category: Chinese, Mathematics (2 categories), English, Physics, Chemistry, Biology, Politics, History, Geography
M3Exam 2023-6 | All | Multi (9) | HG |纸| github
- Publisher: Alibaba Group et al.
- Size: 12317 instances
- 执照: -
- Question Type: OQ
- Evaluation Method: CE
- Focus: The comprehensive abilities in a multilingual and multilevel context using real human exam questions
- Numbers of Evaluation Categories/Subcategories: 3/-
- Evaluation Category: Low, Mid, High
主题
ARB 2023-7 | All | en | CI |纸| github
- Publisher: DuckAI et al.
- Size: 1207 instances
- 许可证:麻省理工学院
- Question Type: Multi
- Evaluation Method: HE & ME
- Focus: Advanced reasoning problems in multiple fields
- Numbers of Evaluation Categories/Subcategories: 5/-
- Evaluation Category: Mathematics, Physics, Law, MCAT(Reading), MCAT(Science)
C-CLUE 2021-8 | All | ZH | HG | github |网站
- Publisher: Tianjin University
- 尺寸: -
- License: CC-BY-SA-4.0
- Question Type: SQ
- Evaluation Method: CE
- Focus: Classical Chinese language understanding
- Numbers of Evaluation Categories/Subcategories: 2/-
- Evaluation Category: Named entity recognition, Relation extraction
C-Eval 2023-5 | All | ZH | HG & MC |纸| github |数据集|网站
- Publisher: Shanghai Jiao Tong University
- Size: 13948 instances
- License: CC-BY-NC-SA-4.0
- Question Type: OQ
- Evaluation Method: CE
- Focus: The advanced knowledge and reasoning abilities in a Chinese context
- Numbers of Evaluation Categories/Subcategories: 4/52
- Evaluation Category: STEM, Social Science, Humanity, Other
CG-Eval 2023-8 | All | ZH | HG |纸| github |数据集|网站
- Publisher: LanguageX AI Lab et al.
- Size: 11000 instances
- License: CC-BY-SA-4.0
- Question Type: SQ
- Evaluation Method: CE
- Focus: The generation capabilities of LLMs across various academic disciplines
- Numbers of Evaluation Categories/Subcategories: 6/55
- Evaluation Category: Science and engineering, Humanities and social sciences, Mathematical calculations, Medical practitioner qualification Examination, Judicial Examination, Certfied public accountant examination
LLMEVAL-3 2023-9 |不是| ZH | HG | github |网站
- Publisher: Fudan University et al.
- Size: 200K instances
- 执照: -
- Question Type: SQ
- Evaluation Method: ME
- Focus: Subject-specific knowledge capability
- Numbers of Evaluation Categories/Subcategories: 13/-
- Evaluation Category: Philosophy, Economics, Law, Education, Literature, History, Science, Engineering, Agriculture, Medicine, Military science, Management, Fine arts
MMCU 2023-4 |全部| ZH | HG |纸| github
- Publisher: LanguageX AI Lab
- Size: 11845 instances
- 执照: -
- Question Type: OQ
- Evaluation Method: CE
- Focus: Multidisciplinary abilities
- Numbers of Evaluation Categories/Subcategories: 4/25
- Evaluation Category: Medicine, Law, Psychology, Education
MMLU 2020-9 | All | en | HG |纸| github
- Publisher: UC Berkeley et al.
- Size: 15908 instances
- 许可证:麻省理工学院
- Question Type: OQ
- Evaluation Method: CE
- Focus: Knowledge in academic and professional domains
- Numbers of Evaluation Categories/Subcategories: 4/57
- Evaluation Category: Humanities, Social science, STEM, Other
M3KE 2023-5 | All | ZH | HG |纸| github | Dataset
- Publisher: Tianjin University et al.
- Size: 20477 instances
- 许可证:Apache-2.0
- Question Type: OQ
- Evaluation Method: CE
- Focus: Multidisciplinary abilities
- Numbers of Evaluation Categories/Subcategories: 4/71
- Evaluation Category: Arts & Humanities, Social sciences, Natural sciences, Other
SCIBENCH 2023-7 | All | en | HG |纸| github
- Publisher: University of California et al.
- Size: 695 instances
- 许可证:麻省理工学院
- Question Type: SQ
- Evaluation Method: CE
- Focus: The performance in university-level science and engineering domains
- Numbers of Evaluation Categories/Subcategories: 3/10
- Evaluation Category: Physics, Chemistry, Math
ScienceQA 2022-9 | All | en | HG |纸| github |网站
- Publisher: University of California et al.
- Size: 21208 instances
- License: CC-BY-NC-SA-4.0
- Question Type: OQ
- Evaluation Method: CE
- Focus: Science question-answering ability
- Numbers of Evaluation Categories/Subcategories: 3/26
- Evaluation Category: Natural science, Social science, Language science
TheoremQA 2023-5 | All | en | HG |纸| github |数据集
- Publisher: University of Waterloo et al.
- Size: 800 instances
- 许可证:麻省理工学院
- Question Type: SQ
- Evaluation Method: CE
- Focus: Science subject question-answering ability
- Numbers of Evaluation Categories/Subcategories: 4/39
- Evaluation Category: Mathematics, Physics, Finance, CS & EE
XiezhiBenchmark 2023-6 | All | EN & ZH | HG & MC |纸| github
- Publisher: Fudan University et al.
- Size: 249587 instances
- License: CC-BY-NC-SA-4.0
- Question Type: OQ
- Evaluation Method: CE
- Focus: Multidisciplinary abilities
- Numbers of Evaluation Categories/Subcategories: 13/516
- Evaluation Category: Medicine, Literature, Economics, Agronomy, Science, Jurisprudence, History, Art studies, Philosophy, Pedagogy, Military science, Management, Engineering
CMMLU 2023-6 | All | ZH | HG |纸| github | Dataset
- Publisher: MBZUAI
- Size: 11528 instances
- License: CC-BY-NC-4.0
- Question Type: OQ
- Evaluation Method: CE
- Focus: The knowledge and reasoning capabilities within the Chinese context
- Numbers of Evaluation Categories/Subcategories: 5/67
- Evaluation Category: Social science, STEM, Humanities, China specific, Other
GPQA 2023-11 | All | en | HG |纸| github | Dataset
- Publisher: New York University et al.
- Size: 448 instances
- License: CC-BY-4.0
- Question Type: OQ
- Evaluation Method: CE
- Focus: The disciplinary knowledge in the fields of biology, physics, and chemistry
- Numbers of Evaluation Categories/Subcategories: 3/16
- Evaluation Category: Biology, Physics, Chemistry
CMATH 2023-6 | All | ZH | HG |纸| github | Dataset
- Publisher: Xiaomi AI Lab
- Size: 1698 instances
- License: CC-BY-4.0
- Question Type: SQ
- Evaluation Method: CE
- Focus: Elementary school math word problems
- Numbers of Evaluation Categories/Subcategories: 6/-
- Evaluation Category: Grades 1 to 6 in elementary school
FineMath 2024-3 |不是| ZH | HG |纸
- Publisher: Tianjin University et al.
- Size: 1584 instances
- 执照: -
- Question Type: Multi
- Evaluation Method: -
- Focus: Elementary school math word problems
- Numbers of Evaluation Categories/Subcategories: 6/17
- Evaluation Category: Number & Operations, Measurement, Data analysis & Probability, Algebra, Geometry, Others
WYWEB 2023-7 | All | ZH | HG & CI |纸| github |数据集|网站
- Publisher: Zhejiang University et al.
- Size: 467200 instances
- 执照: -
- Question Type: Multi
- Evaluation Method: CE
- Focus: Classical Chinese
- Numbers of Evaluation Categories/Subcategories: 5/9
- Evaluation Category: Sequence labeling, Sentence classification, Token similarity, Reading comprehension, Translation
ACLUE 2023-10 | All | ZH | HG & CI |纸| github | Dataset
- Publisher: Mohamed bin Zayed University of Artificial Intelligence
- Size: 4967 instances
- License: CC-BY-NC-SA-4.0
- Question Type: OQ
- Evaluation Method: CE
- Focus: Classical Chinese language understanding
- Numbers of Evaluation Categories/Subcategories: 5/15
- Evaluation Category: Lexical, Syntactic, Semantic, Inference, Knowledge
SciKnowEval 2024-6 | All | en | HG & CI & MC |纸| github | Dataset
- Publisher: Zhejiang University et al.
- Size: 50048 instances
- 执照: -
- Question Type: Multi
- Evaluation Method: CE & ME
- Focus: Evaluate the capabilities of LLMs in handling scientific knowledge
- Numbers of Evaluation Categories/Subcategories: 2/49
- Evaluation Category: Biology, Chemistry
C 3 Bench 2024-5 | All | ZH | HG & CI |纸
- Publisher: South China University of Technology
- Size: 50000 instances
- 执照: -
- Question Type: SQ
- Evaluation Method: CE
- Focus: Classical Chinese
- Numbers of Evaluation Categories/Subcategories: 5/-
- Evaluation Category: Classification, Retrieval, NER, Punctuation, Translation
ArabicMMLU 2024-8 | All | ar | HG |纸| github | Dataset
- Publisher: MBZUAI et al.
- Size: 14575 instances
- License: CC-BY-NC-SA-4.0
- Question Type: OQ
- Evaluation Method: CE
- Focus: Multi-task language understanding benchmark for the Arabic language
- Numbers of Evaluation Categories/Subcategories: 5/40
- Evaluation Category: STEM, Social science, Humanities, Language, Other
PersianMMLU 2024-4 | All | fa | HG |纸| Dataset
- Publisher: Raia Center for Artificial Intelligence Research et al.
- Size: 20192 instances
- License: CC-ND
- Question Type: OQ
- Evaluation Method: CE
- Focus: Facilitate the rigorous evaluation of LLMs that support the Persian language
- Numbers of Evaluation Categories/Subcategories: 5/38
- Evaluation Category: Social science, Humanities, Natural science, Mathematics, Other
TMMLU+ 2024-3 |全部| ZH | HG & CI |纸| Dataset
- Publisher: iKala AI Lab et al.
- Size: 22690 instances
- 许可证:麻省理工学院
- Question Type: OQ
- Evaluation Method: CE
- Focus: Evaluate the language understanding capabilities in Traditional Chinese
- Numbers of Evaluation Categories/Subcategories: 4/66
- Evaluation Category: STEM, Social sciences, Humanities, Other
NLU
CLUE 2020-12 | All | ZH | CI |纸| github
- Publisher: CLUE team
- Size: 9 datasets
- 执照: -
- Question Type: SQ
- Evaluation Method: CE
- Focus: Natural language understanding capability
- Numbers of Evaluation Categories/Subcategories: 3/9
- Evaluation Category: Single-sentence tasks, Sentence pair tasks, Machine reading comprehension tasks
CUGE 2021-12 | All | EN & ZH | CI |纸|网站
- Publisher: Tsinghua University et al.
- Size: 33.4M instances
- 执照: -
- Question Type: SQ
- Evaluation Method: CE
- Focus: Natural language understanding capability
- Numbers of Evaluation Categories/Subcategories: 7/18
- Evaluation Category: Language understanding (word-sentence or discourse level), Information acquisition and question answering, Language generation, Conversational interaction, Multilingual, Mathematical reasoning
GLUE 2018-11 | All | en | CI |纸| github |网站
- Publisher: New York University et al.
- Size: 9 datasets
- 执照: -
- Question Type: SQ
- Evaluation Method: CE
- Focus: Natural language understanding capability
- Numbers of Evaluation Categories/Subcategories: 3/9
- Evaluation Category: Single-sentence tasks, Similarity and paraphrase tasks, Inference tasks
SuperGLUE 2019-5 | All | en | CI |纸|网站
- Publisher: New York University et al.
- Size: 8 datasets
- 执照: -
- Question Type: SQ
- Evaluation Method: CE
- Focus: Natural language understanding capability
- Numbers of Evaluation Categories/Subcategories: 4/8
- Evaluation Category: Word sense disambiguation, Natural language inference, Coreference resolution, Question answering
MCTS 2023-6 | All | ZH | HG |纸| github
- Publisher: Beijing Language and Culture University
- Size: 723 instances
- 执照: -
- Question Type: SQ
- Evaluation Method: CE
- Focus: Text simplification ability
- Numbers of Evaluation Categories/Subcategories: 1/-
- Evaluation Category: Text simplification
RAFT 2021-9 | All | en | HG & CI |纸|数据集|网站
- Publisher: Ought et al.
- Size: 28712 instances
- 执照: -
- Question Type: SQ
- Evaluation Method: CE
- Focus: Text classification ability
- Numbers of Evaluation Categories/Subcategories: 1/11
- Evaluation Category: Text classification
SentEval 2018-5 | All | en | CI |纸| github
- Publisher: Facebook Artificial Intelligence Research
- Size: 28 datasets
- License: BSD
- Question Type: SQ
- Evaluation Method: CE
- Focus: The quality of universal sentence representations
- Numbers of Evaluation Categories/Subcategories: 1/21
- Evaluation Category: Universal sentence representations
LeSC 2024-5 | All | EN & ZH | HG |纸| Github |数据集
- Publisher: Tsinghua University et al.
- Size: 600 instances
- 许可证:麻省理工学院
- Question Type: OQ
- Evaluation Method: CE
- Focus: The genuine linguistic-cognitive skills of LLMs
- Numbers of Evaluation Categories/Subcategories: 1/-
- Evaluation Category: Polysemy
KoBEST 2022-10 | All | KO | CI |纸| Dataset
- Publisher: University of Oxford et al.
- Size: 5 datasets
- License: CC-BY-SA-4.0
- Question Type: OQ
- Evaluation Method: CE
- Focus: Korean balanced evaluation of significant tasks
- Numbers of Evaluation Categories/Subcategories: 5/-
- Evaluation Category: KB-BoolQ, KB-COPA, KB-WiC, KB-HellaSwag, KB-SentiNeg
SarcasmBench 2024-8 | All | en | CI |纸
- Publisher: Tianjin University et al.
- Size: 58347 instances
- 执照: -
- Question Type: SQ
- Evaluation Method: CE
- Focus: Evaluate LLMs on sarcasm understanding
- Numbers of Evaluation Categories/Subcategories: 1/-
- Evaluation Category: Sarcasm understanding
推理
Chain-of-Thought Hub 2023-5 | All | en | CI |纸| github
- Publisher: University of Edinburgh et al.
- 尺寸: -
- 许可证:麻省理工学院
- Question Type: SQ
- Evaluation Method: CE
- Focus: The multi-step reasoning capabilities
- Numbers of Evaluation Categories/Subcategories: 6/8
- Evaluation Category: Math, Science, Symbolic, Knowledge, Coding, Factual
Choice-75 2023-9 | All | en | HG & CI & MC |纸| github
- Publisher: University of Pittsburgh et al.
- Size: 650 instances
- 执照: -
- Question Type: OQ
- Evaluation Method: CE
- Focus: Predict decisions based on descriptive scenarios
- Numbers of Evaluation Categories/Subcategories: 4/-
- Evaluation Category: Easy, Medium, Hard, N/A
NeuLR 2023-6 |全部| en | CI |纸| Github | Dataset
- Publisher: Xi'an Jiaotong University et al.
- Size: 3000 instances
- 执照: -
- Question Type: SQ
- Evaluation Method: CE
- Focus: Logical reasoning capabilities
- Numbers of Evaluation Categories/Subcategories: 3/-
- Evaluation Category: Deductive, Inductive, Abductive
TabMWP 2022-9 | All | en | HG |纸| Github |网站
- Publisher: University of California et al.
- Size: 38431 instances
- License: CC-BY-NC-SA-4.0
- Question Type: Multi
- Evaluation Method: CE
- Focus: Mathematical reasoning ability involving both textual and tabular information
- Numbers of Evaluation Categories/Subcategories: 1/-
- Evaluation Category: Mathematical reasoning and table QA
LILA 2022-10 | All | en | CI |纸| Github | Dataset
- Publisher: Arizona State Univeristy et al.
- Size: 317262 instances
- License: CC-BY-4.0
- Question Type: Multi
- Evaluation Method: CE
- Focus: Mathematical reasoning across diverse tasks
- Numbers of Evaluation Categories/Subcategories: 4/23
- Evaluation Category: Math ability, Language, Knowledge, Format
MiniF2F_v1 2021-9 | All | en | HG & CI |纸| github
- Publisher: Ecole Polytechnique et al.
- Size: 488 instances
- 执照: -
- Question Type: SQ
- Evaluation Method: CE
- Focus: The performance on formal Olympiad-level mathematics problem statements
- Numbers of Evaluation Categories/Subcategories: 1/-
- Evaluation Category: Math
GameBench 2024-6 | All | en | HG |纸| Github | Dataset
- Publisher: Olin College of Engineering et al.
- Size: 9 Games
- License: CC-BY
- Question Type: SQ
- Evaluation Method: CE
- Focus: Evaluate strategic reasoning abilities of LLM agents
- Numbers of Evaluation Categories/Subcategories: 6/9
- Evaluation Category: Abstract Strategy, Non-Deterministic, Hidden Information, Language Communication, Social Deduction, Cooperation
TableBench 2024-8 | All | en | HG & CI & MC |纸| Github |数据集|网站
- Publisher: Beihang University et al.
- Size: 886 instances
- 许可证:Apache-2.0
- Question Type: SQ
- Evaluation Method: CE
- Focus: Table question answering (TableQA) capabilities
- Numbers of Evaluation Categories/Subcategories: 4/18
- Evaluation Category: Fact checking, Numerical reasoning, Data analysis, Visualization
知识
ALCUNA 2023-10 | All | en | HG |纸| Github | Dataset
- Publisher: Peking University
- Size: 84351 instances
- 许可证:麻省理工学院
- Question Type: Multi
- Evaluation Method: CE
- Focus: Assess the ability of LLMs to respond to new knowledge
- Numbers of Evaluation Categories/Subcategories: 3/-
- Evaluation Category: Knowledge understanding, Knowledge differentiation, Knowledge association
KoLA 2023-6 | Partial | en | HG & CI |纸| Github |网站
- Publisher: Tsinghua University
- Size: 2138 instances
- 许可证:GPL-3.0
- Question Type: SQ
- Evaluation Method: CE
- Focus: The ability to grasp and utilize world knowledge
- Numbers of Evaluation Categories/Subcategories: 4/19
- Evaluation Category: Knowledge memorization, Knowledge understanding, Knowledge applying, Knowledge creating
LLMEVAL-2 2023-7 | All | ZH | HG | github
- Publisher: Fudan University et al.
- Size: 480 instances
- 执照: -
- Question Type: Multi
- Evaluation Method: HE & ME
- Focus: Knowledge capability
- Numbers of Evaluation Categories/Subcategories: 12/-
- Evaluation Category: Computer science, Economics, Foreign languages, Law, Mathematics, Medicine, Optics, Physics, Social sciences, Chinese language and literature, Chemistry, Life sciences
SocKET 2023-5 | All | en | CI |纸| github
- Publisher: University of Michigan et al.
- Size: 2616342 instances
- License: CC-BY-4.0
- Question Type: SQ
- Evaluation Method: CE
- Focus: Mastery of social knowledge
- Numbers of Evaluation Categories/Subcategories: 4/58
- Evaluation Category: Classification, Regression, Pair-wise comparison, Span identification
LMExamQA 2023-6 |全部| en | MC |纸|网站
- Publisher: Tsinghua University et al.
- Size: 10090 instances
- 执照: -
- Question Type: SQ
- Evaluation Method: ME
- Focus: The performance on open-ended question answering
- Numbers of Evaluation Categories/Subcategories: 3/25
- Evaluation Category: Knowledge memorization, Knowledge comprehension, Knowledge analysis
DebateQA 2024-8 | All | en | HG & CI & MC |纸| Github | Dataset
- Publisher: Tsinghua Universty et al.
- Size: 2941 instances
- 执照: -
- Question Type: SQ
- Evaluation Method: ME
- Focus: Evaluate the comprehensiveness of perspectives and assess whether the LLM acknowledges the question's debatable nature
- Numbers of Evaluation Categories/Subcategories: 2/-
- Evaluation Category: Perspective diversity, Dispute awareness
Long Text
L-Eval 2023-7 | All | en | HG & CI |纸| Github | Dataset
- Publisher: Fudan University et al.
- Size: 2043 instances
- 许可证:GPL-3.0
- Question Type: SQ
- Evaluation Method: HE & CE & ME
- Focus: Long text task capability
- Numbers of Evaluation Categories/Subcategories: 1/18
- Evaluation Category: Long text task
LongBench 2023-8 | All | EN & ZH | CI |纸| Github | Dataset
- Publisher: Tsinghua University et al.
- Size: 4750 instances
- 许可证:麻省理工学院
- Question Type: SQ
- Evaluation Method: CE
- Focus: Long text task capability
- Numbers of Evaluation Categories/Subcategories: 6/21
- Evaluation Category: Single-doc QA, Multi-doc QA, Summarization, Few-shot learning, Synthetic tasks, Code completion
LongEval 2023-6 | All | en | HG | Github |网站
- Publisher: LMSYS
- 尺寸: -
- 许可证:Apache-2.0
- Question Type: SQ
- Evaluation Method: CE
- Focus: Long text task capability
- Numbers of Evaluation Categories/Subcategories: 2/-
- Evaluation Category: Coarse-grained topic retrieval, Fine-grained line retrieval
InfiniteBench 2023-11 | All | EN & ZH | HG & CI & MC | Github | Dataset
- Publisher: Tsinghua University et al.
- Size: 3932 instances
- 许可证:Apache-2.0
- Question Type: Multi
- Evaluation Method: -
- Focus: Long text task capability
- Numbers of Evaluation Categories/Subcategories: 5/12
- Evaluation Category: Mathematics, Code, Dialogue, Books, Retrieval
ZeroSCROLLS 2023-5 | All | en | HG & CI |纸| Github |数据集|网站
- Publisher: Tel Aviv University et al.
- Size: 4378 instances
- 许可证:麻省理工学院
- Question Type: Multi
- Evaluation Method: CE
- Focus: Long text task capability
- Numbers of Evaluation Categories/Subcategories: 3/10
- Evaluation Category: Summarization, Question Answering, Aggregation
LooGLE 2023-11 | All | en | HG & CI & MC |纸| Github | Dataset
- Publisher: BIGAI et al.
- Size: 6448 instances
- License: CC-BY-SA-4.0
- Question Type: SQ
- Evaluation Method: HE & CE & ME
- Focus: Long text task capability
- Numbers of Evaluation Categories/Subcategories: 2/4
- Evaluation Category: Long dependency tasks, Short dependency tasks
NAH (Needle-in-a-Haystack) 2023-11 | All | en | - | github
- Publisher: gkamradt et al.
- 尺寸: -
- 许可证:麻省理工学院
- Question Type: SQ
- Evaluation Method: ME
- Focus: Long text task capability
- Numbers of Evaluation Categories/Subcategories: 1/-
- Evaluation Category: Long text task
CLongEval 2024-3 | All | ZH | HG & CI & MC |纸| Github | Dataset
- Publisher: The Chinese University of Hong Kong et al.
- Size: 7267 instances
- 许可证:麻省理工学院
- Question Type: SQ
- Evaluation Method: CE
- Focus: Long text task capability
- Numbers of Evaluation Categories/Subcategories: 7/-
- Evaluation Category: Long story QA, Long conversation memory, Long story summarization, Stacked news labeling, Stacked typo detection, Key-passage retrieval, Table querying
Counting-Stars 2024-3 | All | ZH | HG |纸| Github | Dataset
- Publisher: Tencent MLPD
- 尺寸: -
- 执照: -
- Question Type: SQ
- Evaluation Method: CE
- Focus: Long text task capability
- Numbers of Evaluation Categories/Subcategories: 1/-
- Evaluation Category: Long text task
NeedleBench 2024-7 | All | EN & ZH | HG & CI |纸| github
- Publisher: Shanghai AI Laboratory et al.
- 尺寸: -
- 执照: -
- Question Type: Multi
- Evaluation Method: CE
- Focus: Assess bilingual long-context capabilities
- Numbers of Evaluation Categories/Subcategories: 3/-
- Evaluation Category: Single-retrieval, Multi-retrieval, Multi-reasoning
工具
API-Bank 2023-4 | All | EN & PL | HG & MC |纸| github
- Publisher: Alibaba DAMO Academy et al.
- Size: 264 dialogues
- 许可证:麻省理工学院
- Question Type: SQ
- Evaluation Method: HE & CE
- Focus: Plan step-by-step API calls, retrieve relevant APIs, and correctly execute API calls to meet human needs
- Numbers of Evaluation Categories/Subcategories: 3/-
- Evaluation Category: Call, Retrieval+Call, Plan+Retrieval+Call
APIBench 2023-5 | All | EN & PL | HG & MC |纸| Github |数据集|网站
- Publisher: UC Berkeley et al.
- Size: 16450 instances
- 许可证:Apache-2.0
- Question Type: SQ
- Evaluation Method: CE
- Focus: The reasoning ability for calling APIs
- Numbers of Evaluation Categories/Subcategories: 1/-
- Evaluation Category: API call
ToolBench 2023-5 | All | en | HG & CI |纸| github
- Publisher: SambaNova Systems et al.
- Size: 795 instances
- 许可证:Apache-2.0
- Question Type: SQ
- Evaluation Method: CE
- Focus: The enhancement in tool manipulation for real-world software tasks
- Numbers of Evaluation Categories/Subcategories: 8/-
- Evaluation Category: Open weather, The cat API, Home search, Trip booking, Google sheets, Virtual home, Web shop, Tabletop
ToolEyes 2024-1 | All | en | HG |纸| Github |数据集
- Publisher: Fudan University
- Size: 382 instances
- 许可证:Apache-2.0
- Question Type: SQ
- Evaluation Method: CE & ME
- Focus: The LLMs' tool learning capabilities in authentic scenarios
- Numbers of Evaluation Categories/Subcategories: 7/41
- Evaluation Category: Text generation, Data understanding, Real-time search, Application manipulation, Personal life, Information retrieval, Financial transactions
代理人
代码
BIRD 2023-5 | All | EN & PL | HG & CI & MC |纸| Github |数据集|网站
- Publisher: The University of Hong Kong et al.
- Size: 12751 instances
- License: CC-BY-NC-4.0
- Question Type: SQ
- Evaluation Method: CE
- Focus: Text-to-SQL parsing
- Numbers of Evaluation Categories/Subcategories: 1/-
- Evaluation Category: Text-SQL
CodeXGLUE 2021-2 | All | EN & PL | CI |纸| Github | Dataset
- Publisher: Peking University et al.
- Size: 4.12M instances
- License: C-UDA
- Question Type: SQ
- Evaluation Method: CE
- Focus: Program understanding and generation tasks
- Numbers of Evaluation Categories/Subcategories: 4/10
- Evaluation Category: Code-Code, Text-Code, Code-Text, Text-to-Text
DS-1000 2022-11 | All | EN & PL | HG |纸| Github |数据集|网站
- Publisher: The University of Hong Kong et al.
- Size: 1000 instances
- License: CC-BY-SA-4.0
- Question Type: SQ
- Evaluation Method: CE
- Focus: Code generation
- Numbers of Evaluation Categories/Subcategories: 1/-
- Evaluation Category: Code generation
HumanEval 2021-7 | All | EN & PL | HG |纸| github
- Publisher: OpenAI et al.
- Size: 164 instances
- 许可证:麻省理工学院
- Question Type: SQ
- Evaluation Method: CE
- Focus: The correctness of problem-solving abilities in the context of program synthesis
- Numbers of Evaluation Categories/Subcategories: 1/-
- Evaluation Category: Code generation
HumanEvalPack 2023-8 | All | EN & PL | HG & CI |纸| Github | Dataset
- Publisher: Bigcode
- Size: 984 instances
- 许可证:麻省理工学院
- Question Type: SQ
- Evaluation Method: CE
- Focus: The correctness of problem-solving abilities in the context of program synthesis
- Numbers of Evaluation Categories/Subcategories: 3/-
- Evaluation Category: HumanEvalFix, HumanEvalExplain, HumanEvalSynthesize
MTPB 2022-3 | All | EN & PL | HG |纸| Github | Dataset
- Publisher: Salesforce Research
- Size: 115 instances
- 许可证:Apache-2.0
- Question Type: SQ
- Evaluation Method: CE
- Focus: Multi-turn Programming
- Numbers of Evaluation Categories/Subcategories: 1/-
- Evaluation Category: Code generation
ODEX 2022-12 | All | Multi & PL | HG & CI |纸| github
- Publisher: Carnegie Mellon University et al.
- Size: 945 instances
- License: CC-BY-SA-4.0
- Question Type: SQ
- Evaluation Method: CE
- Focus: Natural language to Python code generation
- Numbers of Evaluation Categories/Subcategories: 1/-
- Evaluation Category: Code generation
APPS 2021-5 | All | EN & PL | HG |纸| Github | Dataset
- Publisher: UC Berkeley et al.
- Size: 10000 instances
- 许可证:麻省理工学院
- Question Type: SQ
- Evaluation Method: CE
- Focus: The ability to take an arbitrary natural language specification and generate satisfactory Python code
- Numbers of Evaluation Categories/Subcategories: 1/-
- Evaluation Category: Code generation
DomainEval 2024-8 | All | EN & PL | HG & CI & MC |纸| Github |数据集|网站
- Publisher: Chinese Academy of Sciences et al.
- Size: 5892 instances
- 执照: -
- Question Type: SQ
- Evaluation Method: CE
- Focus: Evaluate LLMs' coding capabilities thoroughly
- Numbers of Evaluation Categories/Subcategories: 6/-
- Evaluation Category: Computation, Network, Basic operation, System, Visualization, Cryptography
ood
法律
LAiW 2023-10 | Partial | ZH | CI |纸| github
- Publisher: Sichuan University et al.
- 尺寸: -
- 执照: -
- Question Type: SQ
- Evaluation Method: CE
- Focus: Legal capabilities
- Numbers of Evaluation Categories/Subcategories: 3/13
- Evaluation Category: Basic legal NLP, Basic legal application, Complex legal application
LawBench 2023-9 | All | ZH | HG & CI |纸| Github | Dataset
- Publisher: Nanjing University et al.
- 尺寸: -
- 许可证:Apache-2.0
- Question Type: Multi
- Evaluation Method: CE
- Focus: Legal capabilities
- Numbers of Evaluation Categories/Subcategories: 3/20
- Evaluation Category: Legal knowledge memorization, Legal knowledge understanding, Legal knowledge applying
LegalBench 2023-8 | All | en | HG & CI |纸| Github |数据集|网站
- Publisher: Stanford University et al.
- Size: 90417 instances
- 执照: -
- Question Type: SQ
- Evaluation Method: HE & CE
- Focus: Legal reasoning
- Numbers of Evaluation Categories/Subcategories: 6/162
- Evaluation Category: Issue-spotting, Rule-recall, Rule-application, Rule-conclusion, Interpretation, Rhetorical-understanding
LexGLUE 2021-10 | All | en | CI |纸| github
- Publisher: University of Copenhagen et al.
- Size: 237014 instances
- 执照: -
- Question Type: SQ
- Evaluation Method: CE
- Focus: Legal capabilities
- Numbers of Evaluation Categories/Subcategories: 3/-
- Evaluation Category: Multi-label classification, Multi-class classification, Multiple choice QA
LEXTREME 2023-1 | All | Multi (24) | CI |纸| github
- Publisher: University of Bern et al.
- Size: 3508603 instances
- 执照: -
- Question Type: SQ
- Evaluation Method: CE
- Focus: Legal capabilities
- Numbers of Evaluation Categories/Subcategories: 18/-
- Evaluation Category: Brazilian court decisions, German argument mining, Greek legal code, Swiss judgment prediction, etc.
SCALE 2023-6 | All | Multi (5) | HG & CI |纸| Dataset
- Publisher: University of Bern et al.
- Size: 1.86M instances
- License: CC-BY-SA
- Question Type: SQ
- Evaluation Method: CE
- Focus: Legal multidimensional abilities
- Numbers of Evaluation Categories/Subcategories: 4/-
- Evaluation Category: Processing long documents, Utilizing domain specific knowledge, Multilingual understanding, Multitasking
ArabLegalEval 2024-8 | All | ar | HG & CI & MC |纸| Github | Dataset
- Publisher: THIQAH et al.
- Size: 37853 instances
- 执照: -
- Question Type: Multi
- Evaluation Method: ME
- Focus: Assess the Arabic legal knowledge of LLMs
- Numbers of Evaluation Categories/Subcategories: 3/-
医疗的
CBLUE 2022-5 | All | ZH | HG & CI |纸| github
- Publisher: Zhejiang University et al.
- Size: 195820 instances
- 许可证:Apache-2.0
- Question Type: SQ
- Evaluation Method: CE
- Focus: Chinese biomedical language understanding
- Numbers of Evaluation Categories/Subcategories: 5/8
- Evaluation Category: Information extraction from the medical text, normalization of the medical term, medical text classification, medical sentence similarity estimation, medical QA
CMB 2023-8 | All | ZH | HG |纸| Github |数据集|网站
- Publisher: The Chinese University of Hong Kong et al.
- Size: 281047 instances
- 许可证:Apache-2.0
- Question Type: Multi
- Evaluation Method: HE & CE & ME
- Focus: The performance of LLMs in the field of medicine
- Numbers of Evaluation Categories/Subcategories: 2/7
- Evaluation Category: CMB-Exam, CMB-Clin
HuaTuo26M-test 2023-5 | All | ZH | CI |纸| Github | Dataset
- Publisher: The Chinese University of Hong Kong et al.
- Size: 6000 instances
- 许可证:Apache-2.0
- Question Type: SQ
- Evaluation Method: CE
- Focus: Understand and generate complex medical language
- Numbers of Evaluation Categories/Subcategories: 3/-
- Evaluation Category: Medical consultant records, Encyclopedias, Knowledge bases
MultiMedQA 2022-12 | All | en | HG & CI |纸| Dataset
- Publisher: Google Research et al.
- Size: 212822 instances
- 执照: -
- Question Type: Multi
- Evaluation Method: HE & CE
- Focus: The performance in medical and clinical applications
- Numbers of Evaluation Categories/Subcategories: 1/-
- Evaluation Category: Medical question answering
PromptCBLUE 2023-4 | All | ZH | CI | github
- Publisher: East China Normal University et al.
- Size: 20640 instances
- 执照: -
- Question Type: SQ
- Evaluation Method: CE
- Focus: The performance in Chinese medical scenarios
- Numbers of Evaluation Categories/Subcategories: 16/-
- Evaluation Category: Medical named entity recognition, Medical entity relation extraction, Medical event extraction, etc.
QiZhenGPT_eval 2023-5 | All | ZH | HG | Github | Dataset
- Publisher: Zhejiang University et al.
- Size: 94 instances
- 许可证:GPL-3.0
- Question Type: SQ
- Evaluation Method: HE
- Focus: Indications for use of drugs
- Numbers of Evaluation Categories/Subcategories: 1/-
- Evaluation Category: Drug indication question answering
CLUE 2024-4 | Partical | en | HG & CI & MC |纸| github
- Publisher: University Hospital Essen et al.
- 尺寸: -
- 执照: -
- Question Type: SQ
- Evaluation Method: CE
- Focus: Real-world clinical tasks
- Numbers of Evaluation Categories/Subcategories: 6/-
- Evaluation Category: MeDiSumQA, MeDiSumCode, MedNLI, MeQSum, Problem Summary, LongHealth
金融的
BBF-CFLEB 2023-2 | All | ZH | HG & CI |纸| Github |网站
- Publisher: Fudan University et al.
- Size: 11327 instances
- 执照: -
- Question Type: SQ
- Evaluation Method: CE
- Focus: Language understanding and generation tasks in Chinese financial natural language processing
- Numbers of Evaluation Categories/Subcategories: 6/-
- Evaluation Category: FinNL, FinNA, FinRE, FinFE, FinQA, FinNSP
FinancelQ 2023-9 | All | ZH | HG & MC | github
- Publisher: Du Xiaoman
- Size: 7173 instances
- License: CC-BY-NC-SA-4.0
- Question Type: OQ
- Evaluation Method: CE
- Focus: The knowledge and reasoning abilities in financial contexts
- Numbers of Evaluation Categories/Subcategories: 10/36
- Evaluation Category: Bank, Fund, Securities, Futures and derivatives, CICE, Actuarial science, Financial planning, CPA, Taxation, Economics
FinEval 2023-8 | All | ZH | HG |纸| Github |数据集|网站
- Publisher: Shanghai University of Finance and Economics
- Size: 4661 instances
- License: CC-BY-NC-SA-4.0
- Question Type: OQ
- Evaluation Method: CE
- Focus: The performance in the financial domain knowledge
- Numbers of Evaluation Categories/Subcategories: 4/34
- Evaluation Category: Finance, Economy, Accounting, Certificate
FLUE 2022-10 | All | en | CI |纸|网站
- Publisher: Georgia Institute of Technology et al.
- Size: 26292 instances
- 执照: -
- Question Type: SQ
- Evaluation Method: CE
- Focus: NLP tasks in the financial domain
- Numbers of Evaluation Categories/Subcategories: 5/6
- Evaluation Category: Financial sentiment analysis, News headline classification, Named entity recognition, Structure boundary detection, Question answering
FinBen 2024-2 | All | en | CI |纸| github
- Publisher: The Fin AI et al.
- Size: 69805 instances
- 执照: -
- Question Type: SQ
- Evaluation Method: CE
- Focus: NLP tasks in the financial domain
- Numbers of Evaluation Categories/Subcategories: 3/6
- Evaluation Category: Foundamental tasks, Advanced cognitive engagement, General intelligence
Social Norms
CrowS-Pairs 2020-11 | All | en | HG & CI |纸| github
- Publisher: New York University
- Size: 1508 instances
- License: CC-SA-4.0
- Question Type: SQ
- Evaluation Method: CE
- Focus: The presence of cultural biases and stereotypes in pretrained language models
- Numbers of Evaluation Categories/Subcategories: 9/-
- Evaluation Category: Race, Gender, Sexual orientation, Religion, Age, Nationality, Disability, Physical appearance, Occupation
SafetyBench 2023-9 | All | EN & ZH | HG & CI & MC |纸| Github |数据集|网站
- Publisher: Tsinghua University et al.
- Size: 11435 instances
- 许可证:麻省理工学院
- Question Type: OQ
- Evaluation Method: CE
- Focus: The safety of LLMs
- Numbers of Evaluation Categories/Subcategories: 7/-
- Evaluation Category: Offensiveness, Unfairness and bias, Physical health, Mental Health, Illegal activities, Ethics and morality, Privacy and Property
Safety-Prompts 2023-4 | Partial | ZH | MC |纸| Github |数据集|网站
- Publisher: Tsinghua University et al.
- Size: 100K instances
- 许可证:Apache-2.0
- Question Type: SQ
- Evaluation Method: HE & ME
- Focus: The safety of LLMs
- Numbers of Evaluation Categories/Subcategories: 2/13
- Evaluation Category: Typical security scenarios, Instruction attack
SuperCLUE-Safety 2023-9 |不是| ZH | - | Github |网站
- Publisher: CLUEbenchmark
- Size: 4912 instances
- 执照: -
- Question Type: SQ
- Evaluation Method: ME
- Focus: The safety of LLMs
- Numbers of Evaluation Categories/Subcategories: 3/20+
- Evaluation Category: Traditional security category, Responsible artificial intelligence, Instruction attacks
TRUSTGPT 2023-6 | All | en | CI |纸| github
- Publisher: Sichuan University et al.
- Size: 2000 instances
- 许可证:麻省理工学院
- Question Type: SQ
- Evaluation Method: CE
- Focus: The performance in toxicity, bias, and value alignment
- Numbers of Evaluation Categories/Subcategories: 3/-
- Evaluation Category: Toxicity, Bias, Value-alignment
事实
FACTOR 2023-7 | Partial | en | HG & CI & MC |纸| github
- Publisher: AI21 Labs
- Size: 4030 instances
- 许可证:麻省理工学院
- Question Type: OQ
- Evaluation Method: CE
- Focus: The factuality of LLMs
- Numbers of Evaluation Categories/Subcategories: 2/-
- Evaluation Category: Wiki, News
FActScore 2023-5 | All | en | HG & MC |纸| github
- Publisher: University of Washington et al.
- Size: 500 instances
- 许可证:麻省理工学院
- Question Type: SQ
- Evaluation Method: HE & ME
- Focus: The factuality of LLMs
- Numbers of Evaluation Categories/Subcategories: 7/-
- Evaluation Category: Single-sentence contradiction (words or beyond words), Page-level contradiction, Subjective, Fact is irrelevant, Wiki is inconsistent & wrong, Annotation error
FactualityPrompt 2022-6 | All | en | CI |纸| github
- Publisher: Hong Kong University of Science and Technology et al.
- Size: 16000 instances
- 许可证:Apache-2.0
- Question Type: SQ
- Evaluation Method: CE
- Focus: The factuality of LLMs
- Numbers of Evaluation Categories/Subcategories: 2/-
- Evaluation Category: Factual prompts, Nonfactual prompts
FreshQA 2023-10 | All | en | HG |纸| github
- Publisher: Google et al.
- Size: 600 instances
- 执照: -
- Question Type: SQ
- Evaluation Method: HE
- Focus: The factuality of LLMs
- Numbers of Evaluation Categories/Subcategories: 4/-
- Evaluation Category: Never-changing, Slow-changing, Fast-changing, False-premise
HalluQA 2023-10 | All | ZH | HG & MC |纸| github
- Publisher: Fudan University et al.
- Size: 450 instances
- 执照: -
- Question Type: SQ
- Evaluation Method: ME
- Focus: The factuality of LLMs
- Numbers of Evaluation Categories/Subcategories: 3/-
- Evaluation Category: Misleading, Misleading-hard, Knowledge
HaluEval 2023-5 | All | en | HG & CI & MC |纸| Github | Dataset
- Publisher: Renmin University of China et al.
- Size: 35000 instances
- 许可证:麻省理工学院
- Question Type: SQ
- Evaluation Method: CE
- Focus: The factuality of LLMs
- Numbers of Evaluation Categories/Subcategories: 3/-
- Evaluation Category: QA, Dialogue, Summarization
TruthfulQA 2022-5 | All | en | HG |纸| github
- Publisher: University of Oxford et al.
- Size: 817 instances
- 许可证:Apache-2.0
- Question Type: SQ
- Evaluation Method: CE & ME
- Focus: The factuality of LLMs
- Numbers of Evaluation Categories/Subcategories: 38/-
- Evaluation Category: Health, Law, Conspiracies, Fiction, Misconceptions, Paranormal, Economics, Biology, Language, Indexical etc.
UHGEval 2023-11 | All | ZH | HG & MC |纸| Github | Dataset
- Publisher: Renmin University of China et al.
- Size: 5141 instances
- 许可证:Apache-2.0
- Question Type: Multi
- Evaluation Method: CE
- Focus: The factuality of LLMs
- Numbers of Evaluation Categories/Subcategories: 3/4
- Evaluation Category: Discriminative, Selective, Generative
HaluEval-Wild 2024-3 |不是| en | HG & CI & MC |纸
- Publisher: Carnegie Mellon University
- Size: 500 instances
- 执照: -
- Question Type: SQ
- Evaluation Method: -
- Focus: The factuality of LLMs
- Numbers of Evaluation Categories/Subcategories: 5/-
- Evaluation Category: Out-of-scope information, Complex reasoning, Inappropriate content, Beyond-modality interaction, Confused / Erroneous queries
RealTime QA 2022-7 | All | en | HG |纸| Github |数据集|网站
- Publisher: Toyota Technological Institute et al.
- 尺寸: -
- 执照: -
- Question Type: Multi
- Evaluation Method: CE
- Focus: The factuality of LLMs
- Numbers of Evaluation Categories/Subcategories: 1/-
- Evaluation Category: Latest knowledge Q&A
ChineseFactEval 2023-9 | All | ZH | HG & MC | Github |数据集|网站
- Publisher: Shanghai Jiao Tong University et al.
- Size: 125 instances
- 许可证:Apache-2.0
- Question Type: SQ
- Evaluation Method: -
- Focus: The factuality of LLMs
- Numbers of Evaluation Categories/Subcategories: 7/-
- Evaluation Category: General domain, Scientific research, Medical, Law, Finance, Math, Chinese modern history
HalluDial 2024-6 | All | EN | CI & MC |纸| Github | Dataset
- Publisher: BAAI et al.
- Size: 146856 instances
- 执照: -
- Question Type: SQ
- Evaluation Method: HE & CE & ME
- Focus: Automatic dialogue-level hallucination evaluation
- Numbers of Evaluation Categories/Subcategories: 2/-
- Evaluation Category: Hallucination detection, Hallucination localization and explanation
评估
FairEval 2023-5 | All | en | CI |纸| Github | Dataset
- Publisher: Peking University et al.
- Size: 80 instances
- 执照: -
- Question Type: SQ
- Evaluation Method: CE
- Focus: The performance in determining the quality of output content from different models
- Numbers of Evaluation Categories/Subcategories: 1/-
- Evaluation Category: Evaluate the quality of answers
LLMEval2 2023-8 | All |多| CI |纸| Github | Dataset
- Publisher: Chinese Academy of Sciences et al.
- Size: 2533 instances
- 许可证:麻省理工学院
- Question Type: SQ
- Evaluation Method: CE
- Focus: The performance in determining the quality of output content from different models
- Numbers of Evaluation Categories/Subcategories: 1/-
- Evaluation Category: Evaluate the quality of answers
PandaLM_testset 2023-4 | All | EN | HG & MC |纸| github
- Publisher: Peking University et al.
- Size: 999 instances
- 许可证:Apache-2.0
- Question Type: SQ
- Evaluation Method: CE
- Focus: The performance in determining the quality of output content from different models
- Numbers of Evaluation Categories/Subcategories: 1/-
- Evaluation Category: Evaluate the quality of answers
多任务
BBH 2022-10 | All | EN | CI |纸| github
- Publisher: Google Research et al.
- Size: 6511 instances
- 许可证:麻省理工学院
- Question Type: Multi
- Evaluation Method: CE
- Focus: Challenging tasks that have proven difficult for prior language model evaluations
- Numbers of Evaluation Categories/Subcategories: 23/27
- Evaluation Category: Boolean expressions, Causal judgement, Date understanding, Disambiguation QA, etc.
BIG-Bench 2022-6 | All |多| HG & CI |纸| github
- Publisher: Google et al.
- 尺寸: -
- 许可证:Apache-2.0
- Question Type: Multi
- Evaluation Method: CE
- Focus: The capabilities and limitations of language models
- Numbers of Evaluation Categories/Subcategories: 95/204
- Evaluation Category: Linguistics, Child development, Mathematics, Common sense reasoning, Biology, etc.
CLEVA 2023-8 | All | ZH | HG & CI |纸| Github |网站
- Publisher: The Chinese University of Hong Kong et al.
- Size: 370K instances
- License: CC-BY-NC-ND-4.0
- Question Type: SQ
- Evaluation Method: CE
- Focus: The performance of LLMs across various dimensions
- Numbers of Evaluation Categories/Subcategories: 2/31
- Evaluation Category: Ability, Application
CLiB 2023-6 | All | ZH | - | github
- Publisher: jeinlee1991
- Size: 90 instances
- 执照: -
- Question Type: SQ
- Evaluation Method: HE
- Focus: Multidimensional capabilities
- Numbers of Evaluation Categories/Subcategories: 4/-
- Evaluation Category: Classification, Information extraction, Reading comprehension, Tabular question answering
decaNLP 2018-6 | All | EN | CI |纸| github
- Publisher: Salesforce Research
- Size: 2010693 instances
- License: BSD-3-Clause
- Question Type: SQ
- Evaluation Method: CE
- Focus: Multitask natural language processing capabilities
- Numbers of Evaluation Categories/Subcategories: 10/-
- Evaluation Category: Question answering, Machine translaion, Summarization, Natural language inference, Sentiment analysis, Semantic role labeling, Zero-shot relation extraction, Goal-oriented dialogue, Semantic parsing, Pronoun resolution
FlagEval 2023-6 | Partial | EN & ZH | HG & CI | Github |网站
- Publisher: BAAI et al.
- Size: 84433 instances
- 执照: -
- Question Type: Multi
- Evaluation Method: HE & CE
- Focus: Multi-domain, multi-dimensional capabilities
- Numbers of Evaluation Categories/Subcategories: 3/21
- Evaluation Category: Choice qa, Classification, Generation qa
HELM 2022-11 | All | en | CI |纸| Github |网站
- Publisher: Stanford University et al.
- 尺寸: -
- 许可证:Apache-2.0
- Question Type: SQ
- Evaluation Method: HE & CE
- Focus: Evaluate LLMs on a wide range of scenarios and metrics
- Numbers of Evaluation Categories/Subcategories: 73/-
- Evaluation Category: Question answering, Information retrieval, Sentiment analysis, Toxicity detection, Aspirational scenarios, etc.
LLMEVAL-1 2023-5 | All | ZH | HG | github
- Publisher: Fudan University et al.
- Size: 453 instances
- 执照: -
- Question Type: SQ
- Evaluation Method: HE & ME
- Focus: Multidimensional capabilities
- Numbers of Evaluation Categories/Subcategories: 17/-
- Evaluation Category: Fact-based question answering, Reading comprehension, Framework generation, Paragraph rewriting, etc.
LMentry 2023-7 | All | EN | HG |纸| github
- Publisher: Tel Aviv University et al.
- Size: 110703 instances
- 执照: -
- Question Type: SQ
- Evaluation Method: CE
- Focus: The performance on challenging tasks
- Numbers of Evaluation Categories/Subcategories: 25/-
- Evaluation Category: Sentence containing word, Sentence not containing word, Word containing letter, Word not containing letter, etc.
AlignBench 2023-11 | All | ZH | HG & MC |纸| Github | Dataset
- Publisher: Tsinghua University et al.
- Size: 683 instances
- 执照: -
- Question Type: Multi
- Evaluation Method: ME
- Focus: Evaluate the alignment of LLMs on Chinese multitasks.
- Numbers of Evaluation Categories/Subcategories: 8/-
- Evaluation Category: Fundamental language ability, Advanced Chinese understanding, Open-ended questions, Writing ability, Logical reasoning, Mathematics, Task-oriented role play,
- Professional knowledge
多种语言
XNLI 2018-10 | All | Multi (15) | HG |纸| github
- Publisher: Facebook AI et al.
- Size: 112500 instances
- License: CC-BY-NC-4.0
- Question Type: SQ
- Evaluation Method: CE
- Focus: Multilingual NLI
- Numbers of Evaluation Categories/Subcategories: 1/-
- Evaluation Category: Multilingual natural language inference
XTREME 2020-3 | All | Multi (40) | CI |纸| Github |网站
- Publisher: Carnegie Mellon University et al.
- 尺寸: -
- 许可证:Apache-2.0
- Question Type: SQ
- Evaluation Method: CE
- Focus: The cross-lingual generalization capabilities
- Numbers of Evaluation Categories/Subcategories: 4/9
- Evaluation Category: Classification, Structured prediction, QA, Retrieval
MGSM 2022-10 | All | Multi (10) | CI |纸| Github | Dataset
- Publisher: Google Research et al.
- Size: 2580 instances
- License: CC-BY-SA-4.0
- Question Type: SQ
- Evaluation Method: CE
- Focus: Multilingual mathematical reasoning abilities
- Numbers of Evaluation Categories/Subcategories: 1/-
- Evaluation Category: Math
其他
EcomGPT_eval 2023-8 | All | EN & ZH | CI |纸| github
- Publisher: Alibaba
- Size: 6000 instances
- 执照: -
- Question Type: SQ
- Evaluation Method: CE
- Focus: E-commerce-related tasks
- Numbers of Evaluation Categories/Subcategories: 4/12
- Evaluation Category: Classification, Generation, Extraction, Others
- Domain: E-commerce
FewCLUE 2021-7 | Partial | ZH | CI |纸| Github |网站
- Publisher: CLUE team
- Size: 9 datasets
- 执照: -
- Question Type: SQ
- Evaluation Method: CE
- Focus: Compare different few-shot learning methods
- Numbers of Evaluation Categories/Subcategories: 3/9
- Evaluation Category: Single sentence tasks, Sentence pair tasks, Reading comprehension
- Domain: Few-shot learning
GeoBench 2023-6 | All | EN | HG |纸| github
- Publisher: Shanghai Jiao Tong University et al.
- Size: 2517 instances
- 许可证:Apache-2.0
- Question Type: Multi
- Evaluation Method: HE & CE & ME
- Focus: LLMs' performance in understanding and utilizing geoscience knowledge
- Numbers of Evaluation Categories/Subcategories: 2/-
- Evaluation Category: NPEE, APTest
- Domain: Geoscience
Owl-Bench 2023-9 | All | EN & ZH | HG |纸| github
- Publisher: Beihang University et al.
- Size: 1317 instances
- 执照: -
- Question Type: Multi
- Evaluation Method: ME
- Focus: The performance in IT-related tasks
- Numbers of Evaluation Categories/Subcategories: 9/-
- Evaluation Category: Information security, Application, System architecture, Software architecture, Middleware, Network, Operating system, Infrastructure, Database
- Domain: IT
MINT 2023-9 | All | EN | CI |纸| Github |数据集|网站
- Publisher: University of Illinois Urbana-Champaign et al.
- Size: 586 instances
- 许可证:Apache-2.0
- Question Type: SQ
- Evaluation Method: CE
- Focus: Solve complex tasks through multi-turn interactions using tools and leveraging natural language feedback
- Numbers of Evaluation Categories/Subcategories: 3/-
- Evaluation Category: Code generation, Decision making, Reasoning
- Domain: Multi-turn interactions
PromptBench 2023-6 | All | EN | CI |纸| github
- Publisher: Microsoft Research et al.
- Size: 583884 instances
- 许可证:麻省理工学院
- Question Type: SQ
- Evaluation Method: CE
- Focus: The models' robustness
- Numbers of Evaluation Categories/Subcategories: 10/15
- Evaluation Category: Sentiment analysis, Grammar correctness, Duplicate sentence detection, Natural language inference, etc.
- Domain: Robustness
EmotionBench 2023-8 | All | en | HG & MC |纸| github
- Publisher: The Chinese University of Hong Kong et al.
- 尺寸: -
- 许可证:GPL-3.0
- Question Type: SQ
- Evaluation Method: CE
- Focus: The empathy ability
- Numbers of Evaluation Categories/Subcategories: 8/36
- Evaluation Category: Anger, Anxiety, Depression, Frustration, Jealous, Guilt, Fear, Embarrassment
- Domain: Sentiment
Evaluation Platform
CLUE Benchmark Series
- SuperCLUE-Agent
- SuperCLUE-Auto
- SuperCLUE-Math6
- SuperCLUE-Safety
- SuperCLUE-Code3
- SuperCLUE-Video
- SuperCLUE-RAG
- SuperCLUE-Industry
- SuperCLUE-Role
OpenLLM Leaderboard
Opencompass
MTEB排行榜
C-MTEB Leaderboard
Traditional NLP Datasets
Diverging from instruction fine-tuning datasets, we categorize text datasets dedicated to natural language tasks before the widespread adoption of LLMs as traditional NLP datasets.
Dataset information format:
- Dataset name Release Time | Language | Paper | Github | Dataset | Website
- Publisher:
- Train/Dev/Test/All Size:
- License:
- Number of Entity Categories: (NER Task)
- Number of Relationship Categories: (RE Task)
问题回答
The task of question-answering requires the model to utilize its knowledge and reasoning capabilities to respond to queries based on provided text (which may be optional) and questions.
阅读理解
The task of reading comprehension entails presenting a model with a designated text passage and associated questions, prompting the model to understand the text for the purpose of answering the questions.
Selection & Judgment
BoolQ 2019-5 | EN |纸| github
- Publisher: University of Washington et al.
- Train/Dev/Test/All Size: 9427/3270/3245/15942
- License: CC-SA-3.0
CosmosQA 2019-9 | EN |纸| Github |数据集|网站
- Publisher: University of Illinois Urbana-Champaign et al.
- Train/Dev/Test/All Size: 25588/3000/7000/35588
- License: CC-BY-4.0
CondaQA 2022-11 | EN |纸| Github | Dataset
- Publisher: Carnegie Mellon University et al.
- Train/Dev/Test/All Size: 5832/1110/7240/14182
- 许可证:Apache-2.0
PubMedQA 2019-9 | EN |纸| Github |数据集|网站
- Publisher: University of Pittsburgh et al.
- Train/Dev/Test/All Size: -/-/-/273.5K
- 许可证:麻省理工学院
MultiRC 2018-6 | EN |纸| Github | Dataset
- Publisher: University of Pennsylvania et al.
- Train/Dev/Test/All Size: -/-/-/9872
- License: MultiRC License
RACE 2017-4 | EN |纸|数据集|网站
- Publisher: Carnegie Mellon University
- Train/Dev/Test/All Size: 87866/4887/4934/97687
- 执照: -
C3 2019-4 | ZH |纸| Github |网站
- Publisher: Cornell University et al.
- Train/Dev/Test/All Size: 11869/3816/3892/19577
- 执照: -
ReClor 2020-2 | EN |纸|网站
- Publisher: National University of Singapore
- Train/Dev/Test/All Size: 4638/500/1000/6138
- 执照: -
DREAM 2020-2 | EN |纸| Github |网站
- Publisher: National University of Singapore
- Train/Dev/Test/All Size: 4638/500/1000/6138
- 执照: -
QuAIL 2020-4 | EN |纸|网站
- Publisher: University of Massachusetts Lowell
- Train/Dev/Test/All Size: 10346/-/2164/12510
- License: CC-NC-SA-4.0
DuReader Yes/No 2019-12 | ZH | Github1 | Github2
- Publisher: Baidu Inc. et al.
- Train/Dev/Test/All Size: 75K/5.5K/11K/91.5K
- 许可证:Apache-2.0
MCTest 2013-10 | EN |纸| Dataset
- Publisher: Microsoft Research
- Train/Dev/Test/All Size: 1200/200/600/2000
- 执照: -
Cloze Test
ChID 2019-6 | ZH |纸| Github | Dataset
- Publisher: Tsinghua University et al.
- Train/Dev/Test/All Size: 605k/23.2K/83.3K/711.5K
- 许可证:Apache-2.0
LAMBADA 2016-6 | EN |纸|数据集|网站
- Publisher: University of Trento et al.
- Train/Dev/Test/All Size: 2662/4869/5153/12684
- License: CC-BY-4.0
CLOTH 2018-10 | EN |纸| Dataset
- Publisher: Carnegie Melon University
- Train/Dev/Test/All Size: 76850/11067/11516/99433
- 许可证:麻省理工学院
CMRC2019 2020-12 | ZH |纸| Github |网站
- Publisher: Harbin Institute of Technology et al.
- Train/Dev/Test/All Size: 100009/3053/5118/108180
- License: CC-BY-SA-4.0
Answer Extraction
SQuAD 2016-11 | en |纸| Dataset
- Publisher: Stanford University
- Train/Dev/Test/All Size: 87599/10570/9533/107702
- License: CC-BY-4.0
SQuAD 2.0 2018-6 | EN |纸| Dataset
- Publisher: Stanford University
- Train/Dev/Test/All Size: 130319/11873/8862/151054
- License: CC-BY-SA-4.0
HOTPOTQA 2018-9 | EN |纸|数据集|网站
- Publisher: Carnegie Mellon University et al.
- Train/Dev/Test/All Size: 90447/7405/7405/105257
- License: CC-BY-SA-4.0
TriviaQA 2017-7 | EN |纸| Github | Dataset
- Publisher: Univ. of Washington et al.
- Train/Dev/Test/All Size: -/-/-/95000
- 许可证:Apache-2.0
Natural Questions 2019-X | EN |纸| Github |数据集
- Publisher: Google Research
- Train/Dev/Test/All Size: 307372/7830/7842/323044
- License: CC-BY-4.0
ReCoRD 2018-10 | EN |纸|网站
- Publisher: Johns Hopkins University et al.
- Train/Dev/Test/All Size: 100730/10000/10000/120730
- 执照: -
QuAC 2018-8 | EN |纸|数据集|网站
- Publisher: AI2 et al.
- Train/Dev/Test/All Size: 83568/7354/7353/98407
- License: CC-BY-SA-4.0
TyDiQA 2020-3 | Multi (11) |纸| Github | Dataset
- Publisher: Google Research
- Train/Dev/Test/All Size: 116916/18670/18751/154337
- 许可证:Apache-2.0
CMRC2018 2019-11 | ZH |纸| github
- Publisher: Harbin Institute of Technology et al.
- Train/Dev/Test/All Size: 10321/3351/4895/18567
- License: CC-BY-SA-4.0
Adversarial QA 2020-2 | EN |纸| Github | Dataset
- Publisher: University College London
- Train/Dev/Test/All Size: 30000/3000/3000/36000
- 许可证:麻省理工学院
Quoref 2019-8 | EN |纸|网站
- Publisher: AI2 et al.
- Train/Dev/Test/All Size: 19399/2418/2537/24354
- License: CC-BY-4.0
MLQA 2020-7 | Multi (7) |纸| Github | Dataset
- Publisher: Facebook AI Research et al.
- Train/Dev/Test/All Size: -/4199/42246/46445
- License: CC-BY-SA-3.0
DuReader Robust 2020-3 | ZH |纸| Github1 | Github2
- Publisher: Baidu Inc. et al.
- Train/Dev/Test/All Size: 15K/1.4K/4.8K/21.2K
- 许可证:Apache-2.0
DuReader Checklist 2021-3 | ZH | Github1 | Github2
- Publisher: Baidu Inc. et al.
- Train/Dev/Test/All Size: 3K/1.1K/4.5K/8.6K
- 许可证:Apache-2.0
CUAD 2021-3 | EN |纸| Dataset
- Publisher: UC Berkeley et al.
- Train/Dev/Test/All Size: 22450/-/4182/26632
- License: CC-BY-4.0
MS MARCO 2016-11 | EN |纸| Github | Dataset
- Publisher: Microsoft AI & Research
- Train/Dev/Test/All Size: 808731/101093/101092/1010916
- 许可证:麻省理工学院
Unrestricted QA
Knowledge QA
In the knowledge QA task, models respond to questions by leveraging world knowledge, common sense, scientific insights, domain-specific information, and more.
ARC 2018-3 | EN |纸|网站
- Publisher: AI2
- Train/Dev/Test/All Size: 3370/869/3548/7787
- License: CC-BY-SA
CommonsenseQA 2018-11 | EN |纸| Github |数据集|网站
- Publisher: Tel-Aviv University et al.
- Train/Dev/Test/All Size: 9797/1225/1225/12247
- 许可证:麻省理工学院
OpenBookQA 2018-10 | EN |纸| Github | Dataset
- Publisher: AI2 et al.
- Train/Dev/Test/All Size: 4957/500/500/5957
- 许可证:Apache-2.0
PIQA 2019-11 | EN |纸| Github | Dataset
- Publisher: AI2 et al.
- Train/Dev/Test/All Size: 16.1K/1.84K/3.08K/21.02K
- 许可证:麻省理工学院
JEC-QA 2019-11 | EN |纸| Github |数据集|网站
- Publisher: Tsinghua University et al.
- Train/Dev/Test/All Size: -/-/26365/26365
- License: CC-NC-ND-4.0
CMD 2019-X | ZH | Github | Dataset
- Publisher: Toyhom
- Train/Dev/Test/All Size: -/-/-/792099
- 许可证:麻省理工学院
cMedQA2 2018-11 | ZH |纸| Dataset
- Publisher: National University of Defense Technology
- Train/Dev/Test/All Size: 100000/4000/4000/108000
- 许可证:GPL-3.0
HEAD-QA 2019-7 | EN & ES |纸| Github |数据集|网站
- Publisher: Universidade da Coruna
- Train/Dev/Test/All Size: 2657/1366/2742/13530
- 许可证:麻省理工学院
SciQ 2017-9 | EN |纸|数据集|网站
- Publisher: University College London et al.
- Train/Dev/Test/All Size: 11679/1000/1000/13679
- License: CC-BY-NC-3.0
WikiQA 2015-9 | EN |纸|数据集|网站
- Publisher: Georgia Institute of Technology et al.
- Train/Dev/Test/All Size: 2118/296/633/3047
- License: Microsoft Research Data License
ECQA 2021-8 | EN |纸| github
- Publisher: IIT Delhi et al.
- Train/Dev/Test/All Size: 7598/1090/2194/10882
- License: CDLA-Sharing-1.0
PsyQA 2021-6 | ZH |纸| github
- Publisher: The CoAI group et al.
- Train/Dev/Test/All Size: -/-/-/22346
- License: PsyQA User Agreement
WebMedQA 2018-12 | ZH |纸| github
- Publisher: Chinese Academy of Sciences et al.
- Train/Dev/Test/All Size: 50610/6337/6337/63284
- 许可证:Apache-2.0
WebQuestions 2013-10 | EN |纸| Dataset
- Publisher: Stanford University
- Train/Dev/Test/All Size: 3778/-/2032/5810
- 执照: -
Reasoning QA
The focal point of reasoning QA tasks is the requirement for models to apply abilities such as logical reasoning, multi-step inference, and causal reasoning in answering questions.
STRATEGYQA 2021-1 | EN |纸|网站
- Publisher: Tel Aviv University et al.
- Train/Dev/Test/All Size: 2290/-/490/2780
- 许可证:麻省理工学院
COPA 2011-6 | EN |纸|网站
- Publisher: Indiana University et al.
- Train/Dev/Test/All Size: -/500/500/1000
- License: BSD 2-Clause
HellaSwag 2019-7 | EN |纸| github
- Publisher: University of Washington et al.
- Train/Dev/Test/All Size: 39905/10042/10003/59950
- 许可证:麻省理工学院
StoryCloze 2016-6 | EN |纸| Dataset
- Publisher: University of Rochester et al.
- Train/Dev/Test/All Size: -/1871/1871/3742
- 执照: -
Social IQa 2019-4 | EN |纸| Dataset
- Publisher: AI2
- Train/Dev/Test/All Size: 33410/1954/-/35364
- 执照: -
LogiQA 2020-7 | EN & ZH |纸| github
- Publisher: Fudan University et al.
- Train/Dev/Test/All Size: 7376/651/651/8678
- 执照: -
PROST 2021-8 | EN |纸| Github | Dataset
- Publisher: University of Colorado Boulder
- Train/Dev/Test/All Size: -/-/18736/18736
- 许可证:Apache-2.0
QuaRTz 2019-11 | EN |纸|数据集|网站
- Publisher: AI2
- Train/Dev/Test/All Size: 2696/384/784/3864
- License: CC-BY-4.0
WIQA 2019-9 | EN |纸|数据集|网站
- Publisher: AI2
- Train/Dev/Test/All Size: 29808/6894/3993/40695
- 执照: -
QASC 2019-10 | EN |纸|数据集|网站
- Publisher: AI2 et al.
- Train/Dev/Test/All Size: 8134/926/920/9980
- License: CC-BY-4.0
QuaRel 2018-11 | EN |纸|网站
- Publisher: AI2
- Train/Dev/Test/All Size: 1941/278/552/2771
- License: CC-BY-4.0
ROPES 2019-8 | EN |纸|数据集|网站
- Publisher: AI2
- Train/Dev/Test/All Size: 10K/1.6K/1.7K/13.3K
- License: CC-BY-4.0
CREAK 2021-9 | EN |纸| github
- Publisher: The University of Texas at Austin
- Train/Dev/Test/All Size: 10176/1371/1371/13418
- 许可证:麻省理工学院
认识文本需要
The primary objective of tasks related to Recognizing Textual Entailment (RTE) is to assess whether information in one textual segment can be logically inferred from another.
ANLI 2019-10 | EN |纸| Github | Dataset
- Publisher: UNC Chapel Hill et al.
- Train/Dev/Test/All Size: 162865/3200/3200/169265
- License: CC-NC-4.0
RTE - | EN | Paper1 | Paper2 | Paper3 | Paper4 | Dataset
- Publisher: The PASCAL Recognising Textual Entailment Challenge
- Train/Dev/Test/All Size: 2.49K/277/3K/5.77K
- License: CC-BY-4.0
WANLI 2022-1 | EN |纸| Dataset
- Publisher: University of Washington et al.
- Train/Dev/Test/All Size: 102885/-/5000/107885
- License: CC-BY-4.0
MedNLI 2018-8 | EN |纸| Github |数据集|网站
- Publisher: University of Massachusetts Lowell et al.
- Train/Dev/Test/All Size: 11232/1395/1422/14049
- 执照: -
CommitmentBank 2019-X | EN |纸| Github | Dataset
- Publisher: The Ohio State University et al.
- Train/Dev/Test/All Size: -/-/-/1200
- 执照: -
MultiNLI 2018-6 | EN |纸| Dataset
- Publisher: New York University
- Train/Dev/Test/All Size: 392702/19647/-/412349
- 执照: -
SNLI 2015-8 | EN |纸| Dataset
- Publisher: Stanford Linguistics et al.
- Train/Dev/Test/All Size: 550152/10000/10000/570152
- License: CC-BY-SA-4.0
OCNLI 2020-10 | ZH |纸| github
- Publisher: Indiana University et al.
- Train/Dev/Test/All Size: 50K/3K/3K/56K
- License: CC-BY-NC-2.0
CMNLI 2020-12 | ZH | Github | Dataset
- Publisher: CLUE team
- Train/Dev/Test/All Size: 391783/12426/13880/418089
- 执照: -
CINLID 2021-4 | ZH | Dataset
- Publisher: Gao et al.
- Train/Dev/Test/All Size: 80124/-/26708/106832
- 执照: -
数学
Mathematical assignments commonly involve standard mathematical calculations, theorem validations, and mathematical reasoning tasks, among others.
GSM8K 2021-10 | EN |纸| Github | Dataset
- Publisher: OpenAI
- Train/Dev/Test/All Size: 7.5K/-/1K/8.5K
- 许可证:麻省理工学院
SVAMP 2021-3 | EN |纸| github
- Publisher: Microsoft Research India
- Train/Dev/Test/All Size: -/-/-/1000
- 许可证:麻省理工学院
ASDiv 2021-6 | EN |纸| Github | Dataset
- Publisher: Institute of Information Science
- Train/Dev/Test/All Size: -/-/-/2305
- License: CC-BY-NC-4.0
MATH 2021-3 | EN |纸| Github | Dataset
- Publisher: UC Berkeley et al.
- Train/Dev/Test/All Size: 7500/-/5000/12500
- 许可证:麻省理工学院
Ape210K 2020-9 | ZH |纸| github
- Publisher: Yuanfudao AI Lab et al.
- Train/Dev/Test/All Size: 200488/5000/5000/210488
- 执照: -
Math23K 2017-9 | ZH |纸| github
- Publisher: Tencent AI Lab
- Train/Dev/Test/All Size: -/-/-/23161
- 许可证:麻省理工学院
MathQA 2019-5 | EN |纸|数据集|网站
- Publisher: University of Washington et al.
- Train/Dev/Test/All Size: 29837/4475/2985/37297
- 许可证:Apache-2.0
AQUA-RAT 2017-7 | EN |纸| Github | Dataset
- Publisher: DeepMind
- Train/Dev/Test/All Size: 100949/250/250/101499
- 许可证:Apache-2.0
NaturalProofs 2021-4 | EN |纸| github
- Publisher: University of Washington et al.
- Train/Dev/Test/All Size: -/-/-/80795
- 许可证:麻省理工学院
Coreference Resolution
The core objective of tasks related to coreference resolution is the identification of referential relationships within texts.
WSC 2012-X | EN |纸| Dataset
- Publisher: University of Toronto et al.
- Train/Dev/Test/All Size: -/-/285/285
- License: CC-BY-4.0
DPR 2012-7 | EN |纸| Dataset
- Publisher: University of Texas at Dallas
- Train/Dev/Test/All Size: 1322/-/564/1886
- 执照: -
WinoGrande 2019-7 | EN |纸| Github | Dataset
- Publisher: AI2 et al.
- Train/Dev/Test/All Size: 63238/1267/1767/66272
- License: CC-BY
WiC 2018-8 | EN |纸|网站
- Publisher: University of Cambridge
- Train/Dev/Test/All Size: 5428/638/1400/7466
- License: CC-NC-4.0
WinoWhy 2020-7 | EN |纸| github
- Publisher: HKUST
- Train/Dev/Test/All Size: -/-/-/43972
- 许可证:麻省理工学院
CLUEWSC2020 2020-12 | ZH |纸| Github1 | Github2
- Publisher: CLUE team
- Train/Dev/Test/All Size: 1244/304/290/1838
- 执照: -
Sentiment Analysis
The sentiment analysis task, commonly known as emotion classification, seeks to analyze and deduce the emotional inclination of provided texts, commonly categorized as positive, negative, or neutral sentiments.
IMDB 2011-6 | EN |纸| Dataset
- Publisher: Stanford University
- Train/Dev/Test/All Size: 25000/-/25000/50000
- 执照: -
Sentiment140 2009-X | EN |纸| Dataset
- Publisher: Stanford University
- Train/Dev/Test/All Size: 1600000/-/359/1600359
- 执照: -
SST-2 2013-10 | EN |纸| Dataset
- Publisher: Stanford University
- Train/Dev/Test/All Size: 67349/872/1821/70042
- 执照: -
EPRSTMT 2021-7 | ZH |纸| github
- Publisher: CLUE team
- Train/Dev/Test/All Size: 32/32/1363/20992
- 执照: -
Semantic Matching
The task of semantic matching entails evaluating the semantic similarity or degree of correspondence between two sequences of text.
MRPC 2005-X | EN |纸
- Publisher: Microsoft Research
- Train/Dev/Test/All Size: 4076/-/1725/5801
- 执照: -
QQP 2018-11 | EN |纸| Dataset
- Publisher: New York University et al.
- Train/Dev/Test/All Size: 364K/-/-/364K
- 执照: -
PAWS 2019-6 | EN |纸| Github | Dataset
- Publisher: Google AI Language
- Train/Dev/Test/All Size: 49401/8000/8000/65401
- 执照: -
STSB 2017-8 | Multi (10) |纸| github |数据集|网站
- Publisher: Google Research et al.
- Train/Dev/Test/All Size: 5749/1500/1379/8628
- 执照: -
AFQMC 2020-12 | ZH |纸
- Publisher: CLUE team
- Train/Dev/Test/All Size: 34.3K/4.3K/3.9K/42.5K
- 执照: -
BQ 2018-10 | ZH |纸| Dataset
- Publisher: Harbin Institute of Technology et al.
- Train/Dev/Test/All Size: 100000/10000/10000/120000
- 执照: -
LCQMC 2018-8 | ZH |纸
- Publisher: Harbin Institute of Technology et al.
- Train/Dev/Test/All Size: 238766/8802/12500/260068
- License: CC-BY-4.0
PAWS-X 2019-8 | Multi (6) |纸| github
- Publisher: Google Research
- Train/Dev/Test/All Size: 296406/11815/11844/320065
- 执照: -
BUSTM 2021-7 | ZH |纸| github
- Publisher: CLUE team
- Train/Dev/Test/All Size: 32/32/3772/8087
- 执照: -
DuQM 2021-9 | ZH |纸| Github1 | Github2
- Publisher: Baidu Inc. et al.
- Train/Dev/Test/All Size: -/-/-/10121
- 许可证:Apache-2.0
文字生成
The narrow definition of text generation tasks is bound by provided content and specific requirements. It involves utilizing benchmark data, such as descriptive terms and triplets, to generate corresponding textual descriptions.
CommonGen 2019-11 | EN |纸| Github | Dataset
- Publisher: University of Southern California et al.
- Train/Dev/Test/All Size: 67389/4018/1497/72904
- 许可证:麻省理工学院
DART 2020-7 | EN |纸| Github | Dataset
- Publisher: Yale University et al.
- Train/Dev/Test/All Size: 30526/2768/6959/40253
- 许可证:麻省理工学院
E2E 2017-6 | EN |纸| Github | Dataset
- Publisher: Heriot-Watt University
- Train/Dev/Test/All Size: 42061/4672/4693/51426
- License: CC-BY-SA-3.0
WebNLG 2017-7 | EN & RU |纸| Github | Dataset
- Publisher: LORIA et al.
- Train/Dev/Test/All Size: 49665/6490/7930/64085
- License: CC-BY-NC-SA-4.0
文字翻译
Text translation involves transforming text from one language to another.
Text Summarization
The task of text summarization pertains to the extraction or generation of a brief summary or headline from an extended text to encapsulate its primary content.
AESLC 2019-7 | EN |纸| Github | Dataset
- Publisher: Yale University et al.
- Train/Dev/Test/All Size: 14436/1960/1906/18302
- License: CC-BY-NC-SA-4.0
CNN-DM 2017-4 | EN |纸| Dataset
- Publisher: Stanford University et al.
- Train/Dev/Test/All Size: 287113/13368/11490/311971
- 许可证:Apache-2.0
MultiNews 2019-7 | EN |纸| Github | Dataset
- Publisher: Yale University
- Train/Dev/Test/All Size: 44972/5622/5622/56216
- 执照: -
Newsroom 2018-6 | EN |纸| Dataset
- Publisher: Cornell University
- Train/Dev/Test/All Size: 995041/108837/108862/1212740
- 执照: -
SAMSum 2019-11 | EN |纸| Dataset
- Publisher: Cornell University
- Train/Dev/Test/All Size: 14732/818/819/16369
- License: CC-BY-NC-ND-4.0
XSum 2018-10 | EN |纸| Github | Dataset
- Publisher: University of Edinburgh
- Train/Dev/Test/All Size: 204045/11332/11334/226711
- 许可证:麻省理工学院
Opinion Abstracts 2016-6 | EN |纸| Dataset
- Publisher: Northeastern University et al.
- Train/Dev/Test/All Size: 5990/-/-/5990
- 执照: -
WikiLingua 2020-10 | Multi (18) |纸| Github | Dataset
- Publisher: Columbia University et al.
- Train/Dev/Test/All Size: -/-/-/770087
- License: CC-BY-3.0
LCSTS 2015-6 | ZH |纸| Dataset
- Publisher: Harbin Institute of Technology
- Train/Dev/Test/All Size: 2400000/10000/1000/2411000
- License: CC-BY-4.0
CNewSum 2021-10 | ZH |纸| Github |数据集|网站
- Publisher: ByteDance
- Train/Dev/Test/All Size: 275596/14356/14355/304307
- 许可证:Apache-2.0
XL-Sum 2021-8 | Multi (45) |纸| Dataset
- Publisher: BUET et al.
- Train/Dev/Test/All Size: 1122857/114198/114198/1351253
- License: CC-BY-NC-SA-4.0
WikiHow 2018-10 | EN |纸| github
- Publisher: University of California
- Train/Dev/Test/All Size: -/-/-/230K
- 许可证:CC-BY-NC-SA
MediaSum 2021-3 | EN |纸| github | Dataset
- Publisher: Microsoft Cognitive Services Research Group
- Train/Dev/Test/All Size: 443596/10000/10000/463596
- 执照: -
文本分类
Text classification tasks aim to assign various text instances to predefined categories, comprising text data and category labels as pivotal components.
AGNEWS 2015-9 | EN |纸|数据集|网站
- Publisher: New York University
- Train/Dev/Test/All Size: 120000/-/7600/127600
- 执照: -
TNEWS 2020-11 | ZH |纸| Github | Dataset
- Publisher: CLUE team
- Train/Dev/Test/All Size: 53.3K/10K/10K/73.3K
- 执照: -
IFLYTEK 2020-12 | ZH |纸
- Publisher: CLUE team
- Train/Dev/Test/All Size: 12.1K/2.6K/2.6K/17.3K
- 执照: -
MARC 2020-11 | Multi (6) |纸| Dataset
- Publisher: Amazon et al.
- Train/Dev/Test/All Size: 1200000/30000/30000/1260000
- 执照: -
THUCNews 2016-X | ZH | Github |网站
- Publisher: Tsinghua University
- Train/Dev/Test/All Size: -/-/-/1672165
- 许可证:麻省理工学院
CSLDCP 2021-7 | ZH |纸| Github |网站
- Publisher: CLUE team
- Train/Dev/Test/All Size: 536/536/4783/23966
- 执照: -
Text Quality Evaluation
The task of text quality evaluation, also referred to as text correction, involves the identification and correction of grammatical, spelling, or language usage errors in text.
CoLA 2018-5 | EN |纸|网站
- Publisher: New York University
- Train/Dev/Test/All Size: 8511/1043/-/9554
- License: CC-BY-4.0
SIGHAN - | ZH | Paper1 | Paper2 | Paper3 | Dataset1 | Dataset2 | Dataset3
- Publisher: Chaoyang Univ. of Technology et al.
- Train/Dev/Test/All Size: 6476/-/3162/9638
- 执照: -
YACLC 2021-12 | ZH |纸| github
- Publisher: Beijing Language and Culture University et al.
- Train/Dev/Test/All Size: 8000/1000/1000/10000
- 执照: -
CSCD-IME 2022-11 | ZH |纸| github
- Publisher: Tencent Inc
- Train/Dev/Test/All Size: 30000/5000/5000/40000
- 许可证:麻省理工学院
Text-to-Code
The Text-to-Code task involves models converting user-provided natural language descriptions into computer-executable code, thereby achieving the desired functionality or operation.
MBPP 2021-8 | EN & PL |纸| github
- Publisher: Google Research
- Train/Dev/Test/All Size: -/-/974/974
- 执照: -
DuSQL 2020-11 | ZH & PL |纸| Dataset
- Publisher: Baidu Inc. et al.
- Train/Dev/Test/All Size: 18602/2039/3156/23797
- 执照: -
CSpider 2019-11 | ZH & PL |纸| Github |网站
- Publisher: Westlake University
- Train/Dev/Test/All Size: -/-/-/10181
- License: CC-BY-SA-4.0
Spider 2018-9 | EN & PL |纸| Github |网站
- Publisher: Yale University
- Train/Dev/Test/All Size: -/-/-/10181
- License: CC-BY-SA-4.0
命名实体识别
The Named Entity Recognition (NER) task aims to discern and categorize named entities within a given text.
WUNT2017 2017-9 | EN |纸| Dataset
- Publisher: Johns Hopkins University et al.
- Train/Dev/Test/All Size: 3394/1009/1287/5690
- License: CC-BY-4.0
- Number of Entity Categories: 6
Few-NERD 2021-5 | EN |纸| Github |数据集|网站
- Publisher: Tsinghua University et al.
- Train/Dev/Test/All Size: -/-/-/188200
- License: CC-BY-SA-4.0
- Number of Entity Categories: 66
CoNLL2003 2003-6 | EN & DE |纸| Dataset
- Publisher: University of Antwerp
- Train/Dev/Test/All Size: 14041/3250/3453/20744
- 执照: -
- Number of Entity Categories: 4
OntoNotes 5.0 2013-10 | Multi (3) |纸|数据集|网站
- Publisher: Boston Childrens Hospital and Harvard Medical School et al.
- Train/Dev/Test/All Size: 59924/8528/8262/76714
- 执照: -
- Number of Entity Categories: 18
MSRA 2006-7 | ZH |纸| Dataset
- Publisher: University of Chicago
- Train/Dev/Test/All Size: 46364/-/4365/50729
- License: CC-BY-4.0
- Number of Entity Categories: 3
Youku NER 2019-6 | ZH |纸| Github | Dataset
- Publisher: Singapore University of Technology and Design et al.
- Train/Dev/Test/All Size: 8001/1000/1001/10002
- 执照: -
- Number of Entity Categories: 9
Taobao NER 2019-6 | ZH |纸| Github | Dataset
- Publisher: Singapore University of Technology and Design et al.
- Train/Dev/Test/All Size: 6000/998/1000/7998
- 执照: -
- Number of Entity Categories: 9
Weibo NER 2015-9 | ZH |纸| Github | Dataset
- Publisher: Johns Hopkins University
- Train/Dev/Test/All Size: 1350/269/270/1889
- License: CC-BY-SA-3.0
- Number of Entity Categories: 4
CLUENER 2020-1 | ZH |纸| Github | Dataset
- Publisher: CLUE Organization
- Train/Dev/Test/All Size: 10748/1343/1345/13436
- 执照: -
- Number of Entity Categories: 10
Resume 2018-7 | ZH |纸| github
- Publisher: Singapore University of Technology and Design
- Train/Dev/Test/All Size: 3821/463/477/4761
- 执照: -
- Number of Entity Categories: 8
关系提取
The endeavor of Relation Extraction (RE) necessitates the identification of connections between entities within textual content. This process typically includes recognizing and labeling pertinent entities, followed by the determination of the specific types of relationships that exist among them.
Dialogue RE 2020-7 | EN & ZH |纸| github |网站
- Publisher: Tencent AI Lab et al.
- Train/Dev/Test/All Size: 6100/2034/2034/10168
- 执照: -
- Number of Relationship Categories: 36
TACRED 2017-9 | EN |纸|数据集|网站
- Publisher: Stanford University
- Train/Dev/Test/All Size: 68124/22631/15509/106264
- License: LDC
- Number of Relationship Categories: 42
DocRED 2019-7 | EN |纸| github
- Publisher: Tsinghua University et al.
- Train/Dev/Test/All Size: 1546589/12332/12842/1571763
- 许可证:麻省理工学院
- Number of Relationship Categories: 96
FewRel 2018-10 | EN | Paper1 | Paper2 | Github |网站
- Publisher: Tsinghua University
- Train/Dev/Test/All Size: -/-/-/70000
- License: CC-BY-SA-4.0
- Number of Relationship Categories: 100
多任务
Multitask datasets hold significance as they can be concurrently utilized for different categories of NLP tasks.
CSL 2022-9 | ZH |纸| github
- Publisher: School of Information Engineering et al.
- Train/Dev/Test/All Size: -/-/-/396209
- 许可证:Apache-2.0
QED 2021-3 | EN |纸| github
- Publisher: Stanford University et al.
- Train/Dev/Test/All Size: 7638/1355/-/8993
- License: CC-BY-SA-3.0 & GFDL
METS-CoV 2022-9 | EN |纸| github
- Publisher: Zhejiang University et al.
- Train/Dev/Test/All Size: -/-/-/-
- 许可证:Apache-2.0
Multi-modal Large Language Models (MLLMs) Datasets
Pre-training Corpora
文件
Instruction Fine-tuning Datasets
遥感
- MMRS-1M : Multi-sensor remote sensing instruction dataset
- Paper: EarthGPT: A Universal Multi-modal Large Language Model for Multi-sensor Image Comprehension in Remote Sensing Domain
- Github: https://github.com/wivizhang/EarthGPT
Images + Videos
- VideoChat2-IT : Instruction fine-tuning dataset for images/videos
- Paper: MVBench: A Comprehensive Multi-modal Video Understanding Benchmark
- Dataset: https://huggingface.co/datasets/OpenGVLab/VideoChat2-IT
Visual Document Understanding
- InstructDoc : A dataset for zero-shot generalization of visual document understanding
- Paper: InstructDoc: A Dataset for Zero-Shot Generalization of Visual Document Understanding with Instructions
- Github: https://github.com/nttmdlab-nlp/InstructDoc
- Dataset: https://github.com/nttmdlab-nlp/InstructDoc
一般的
- ALLaVA-4V Data : The multimodal instruction fine-tuning dataset for the ALLaVA model
- Paper: ALLaVA: Harnessing GPT4V-synthesized Data for A Lite Vision-Language Model
- Github: https://github.com/FreedomIntelligence/ALLaVA
- Dataset: https://huggingface.co/datasets/FreedomIntelligence/ALLaVA-4V
Evaluation Datasets
Video Understanding
- MVBench : A comprehensive multi-modal video understanding benchmark
- Paper: MVBench: A Comprehensive Multi-modal Video Understanding Benchmark
- Github: https://github.com/OpenGVLab/Ask-Anything/tree/main/video_chat2
- Dataset: https://huggingface.co/datasets/OpenGVLab/MVBench
主题
多任务
- MMT-Bench : A comprehensive multimodal benchmark for evaluating large vision-language models towards multitask AGI
- Paper: MMT-Bench: A Comprehensive Multimodal Benchmark for Evaluating Large Vision-Language Models Towards Multitask AGI
- Github: https://github.com/OpenGVLab/MMT-Bench
- Dataset: https://huggingface.co/datasets/Kaining/MMT-Bench
Long Input
- MM-NIAH : The first benchmark specifically designed to systematically evaluate the capability of existing MLLMs to comprehend long multimodal documents
- Paper: Needle In A Multimodal Haystack
- Github: https://github.com/OpenGVLab/MM-NIAH
- Dataset: https://github.com/OpenGVLab/MM-NIAH
事实
- MultiTrust : The first comprehensive and unified benchmark on the trustworthiness of MLLMs across five primary aspects: truthfulness, safety, robustness, fairness, and privacy
- Paper: Benchmarking Trustworthiness of Multimodal Large Language Models: A Comprehensive Study
- Github: https://github.com/thu-ml/MMTrustEval
- Website: https://multi-trust.github.io/#leaderboard
医疗的
MultiMed : A benchmark designed to evaluate and enable large-scale learning across a wide spectrum of medical modalities and tasks
- Paper: MultiMed: Massively Multimodal and Multitask Medical Understanding
MedTrinity-25M : A large-scale multimodal dataset with multigranular annotations for medicine
- Paper: MedTrinity-25M: A Large-scale Multimodal Dataset with Multigranular Annotations for Medicine
- Github: https://github.com/UCSC-VLAA/MedTrinity-25M
- Dataset: https://huggingface.co/datasets/UCSC-VLAA/MedTrinity-25M
- Website: https://yunfeixie233.github.io/MedTrinity-25M/
图像理解
- MMIU : A comprehensive evaluation suite designed to assess LVLMs across a wide range of multi-image tasks
- Paper: MMIU: Multimodal Multi-image Understanding for Evaluating Large Vision-Language Models
- Github: https://github.com/OpenGVLab/MMIU
- Dataset: https://huggingface.co/datasets/FanqingM/MMIU-Benchmark
- Website: https://mmiu-bench.github.io/
Retrieval Augmented Generation (RAG) Datasets
CRUD-RAG : A comprehensive Chinese benchmark for RAG
- Paper: CRUD-RAG: A Comprehensive Chinese Benchmark for Retrieval-Augmented Generation of Large Language Models
- Github: https://github.com/IAAR-Shanghai/CRUD_RAG
- Dataset: https://github.com/IAAR-Shanghai/CRUD_RAG
WikiEval : To do correlation analysis of difference metrics proposed in RAGAS
- Paper: RAGAS: Automated Evaluation of Retrieval Augmented Generation
- Github: https://github.com/explodinggradients/ragas
- Dataset: https://huggingface.co/datasets/explodinggradients/WikiEval
RGB : A benchmark for RAG
- Paper: Benchmarking Large Language Models in Retrieval-Augmented Generation
- Github: https://github.com/chen700564/RGB
- Dataset: https://github.com/chen700564/RGB
RAG-Instruct-Benchmark-Tester : An updated benchmarking test dataset for RAG use cases in the enterprise
- Dataset: https://huggingface.co/datasets/llmware/rag_instruct_benchmark_tester
- Website: https://medium.com/@darrenoberst/how-accurate-is-rag-8f0706281fd9
ARES : An automated evaluation framework for RAG
- Paper: ARES: An Automated Evaluation Framework for Retrieval-Augmented Generation Systems
- Github: https://github.com/stanford-futuredata/ARES
- Dataset: https://github.com/stanford-futuredata/ARES
ALCE : The quality assessment benchmark for context and responses
- Paper: Enabling Large Language Models to Generate Text with Citations
- Github: https://github.com/princeton-nlp/ALCE
- Dataset: https://huggingface.co/datasets/princeton-nlp/ALCE-data
CRAG : A comprehensive RAG benchmark
- Paper: CRAG -- Comprehensive RAG Benchmark
- Website: https://www.aicrowd.com/challenges/meta-comprehensive-rag-benchmark-kdd-cup-2024
RAGEval :A framework for automatically generating evaluation datasets to evaluate the knowledge usage ability of different LLMs in different scenarios
- Paper: RAGEval: Scenario Specific RAG Evaluation Dataset Generation Framework
- Github: https://github.com/OpenBMB/RAGEval
- Dataset: https://github.com/OpenBMB/RAGEval
LFRQA :A dataset of human-written long-form answers for cross-domain evaluation in RAG-QA systems
- Paper: RAG-QA Arena: Evaluating Domain Robustness for Long-form Retrieval Augmented Question Answering
- Github: https://github.com/awslabs/rag-qa-arena
MultiHop-RAG : Benchmarking retrieval-augmented generation for multi-hop queries
- Paper: MultiHop-RAG: Benchmarking Retrieval-Augmented Generation for Multi-Hop Queries
- Github: https://github.com/yixuantt/MultiHop-RAG/
- Dataset: https://huggingface.co/datasets/yixuantt/MultiHopRAG
接触
联系信息:
Lianwen Jin:[email protected]
Yang Liu:[email protected]
Due to our current limited human resources to manage such a vast amount of data resources, we regret that we are unable to include all data resources at this moment. If you find any important data resources that have not yet been included, we warmly invite you to submit relevant papers, data links, and other information to us. We will evaluate them, and if appropriate, we will include the data in the Awesome-LLMs-Datasets and the survey paper . Your assistance and support are greatly appreciated!
引用
If you wish to cite this project, please use the following citation format:
@article{liu2024survey,
title={Datasets for Large Language Models: A Comprehensive Survey},
author={Liu, Yang and Cao, Jiahuan and Liu, Chongyu and Ding, Kai and Jin, Lianwen},
journal={arXiv preprint arXiv:2402.18041},
year={2024}
}


