Reading_groups
1.0.0
计算的力量: 很多证据表明,机器学习的进步很大程度上是由计算驱动的,而不是研究,请参考:"The Bitter Lesson",而且往往会出现Emergence和Homogenization现象。
有研究表明,人工智能计算使用量大约每3.4个月翻一番,而效率提升每16个月才翻一番。其中计算使用量主要由计算力驱动,而效率则由研究驱动。
这意味着计算增长在历史上主导了机器学习和其子领域的进步。 GPT-4的出现更加证明了这一点。 尽管如此,未来是否有更颠覆Transformer的架构仍需要我们重视,比如说S4。
目前的NLP研究热点大部分基于更先进的LLM (~100B,
关于LLM更多topics的论文请参考这里和这里。
论文 (粗糙类别)
资源
【对GPT-4的测试,limitation】Sparks of Artificial General Intelligence: Early experiments with GPT-4
【InstructGPT论文,包括sft,ppo等,最重要的文章之一】Training language models to follow instructions with human feedback
【scalable oversight: 人类在模型超过自己的任务后怎么持续的提升模型?】Measuring Progress on Scalable Oversight for Large Language Models
【Alignment的定义,deepmind出品】Alignment of Language Agents
A General Language Assistant as a Laboratory for Alignment
【RETRO论文,利用CCA+检索的模型】Improving language models by retrieving from trillions of tokens
Fine-Tuning Language Models from Human Preferences
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
【中英文的大模型,超过GPT-3】GLM-130B: An Open Bilingual Pre-trained Model
【预训练目标优化】UL2: Unifying Language Learning Paradigms
【Alignment新的基准,模型库和新方法】Is Reinforcement Learning (Not) for Natural Language Processing?: Benchmarks, Baselines, and Building Blocks for Natural Language Policy Optimization
【通过技术不使用[MASK]标记进行MLM】Representation Deficiency in Masked Language Modeling
【文字转为图像训练,缓解了Vocabulary的需要并抗某些攻击】Language Modelling with Pixels
LexMAE: Lexicon-Bottlenecked Pretraining for Large-Scale Retrieval
InCoder: A Generative Model for Code Infilling and Synthesis
【检索Text相关图像进行语言模型预训练】Visually-Augmented Language Modeling
A Non-monotonic Self-terminating Language Model
【通过prompt设计进行负面反馈比较微调】Chain of Hindsight Aligns Language Models with Feedback
【Sparrow模型】Improving alignment of dialogue agents via targeted human judgements
【用小模型参数加速大模型训练过程(不从头)】Learning to Grow Pretrained Models for Efficient Transformer Training
【多种知识源MoE半参数知识融合模型】Knowledge-in-Context: Towards Knowledgeable Semi-Parametric Language Models
【不同数据集上的多个已训练模型合并方法】Dataless Knowledge Fusion by Merging Weights of Language Models
【很有启发,检索机制代替 Transformer 中的 FFN 的通用架构(×2.54 time),以便解耦存储在模型参数中的知识】Language model with Plug-in Knowldge Memory
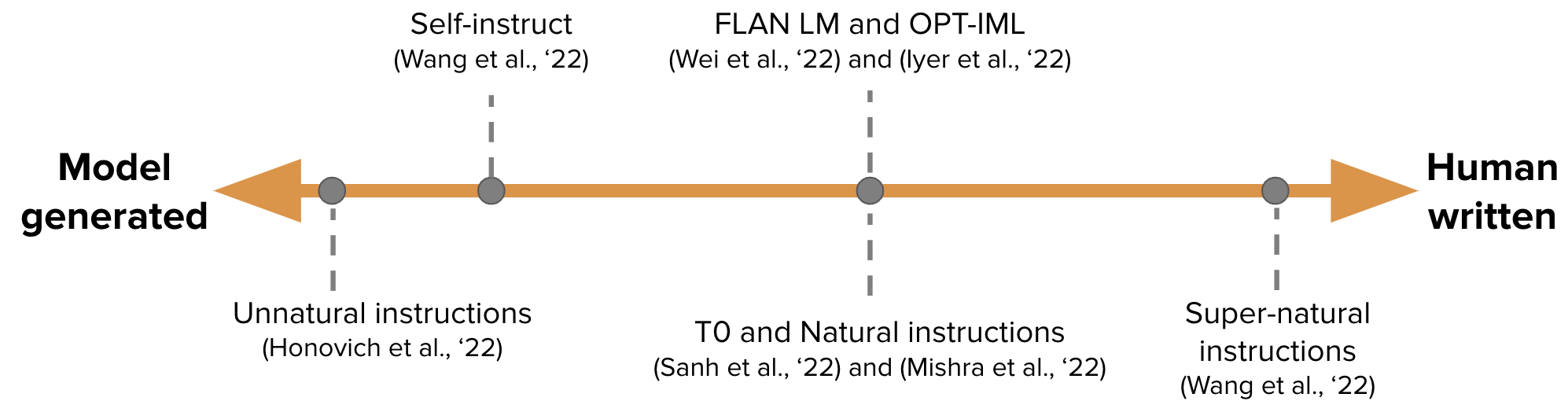
【自动生成Instruction tuning的数据用于GPT-3的训练】Self-Instruct: Aligning Language Model with Self Generated Instructions
-
Towards Conditionally Dependent Masked Language Models
【迭代地校准不完美生成的独立校正器,Sean Welleck的后续文章】Generating Sequences by Learning to Self-Correct
【持续学习:新任务增加一个prompt,且上一个任务的prompt和大模型不变】Progressive Prompts: Continual Learning for Language Models without Forgetting
【EMNLP 2022,模型的持续更新】MemPrompt: Memory-assisted Prompt Editing with User Feedback
【新的神经架构 (FOLNet),其中包含一阶逻辑归纳偏差】Learning Language Representations with Logical Inductive Bias
GanLM: Encoder-Decoder Pre-training with an Auxiliary Discriminator
【基于state-space models的预训练语言模型,超过BERT】Pretraining Without Attention
【预训练的时候就考虑人类反馈】Pretraining Language Models with Human Preferences
【Meta的开源LLaMA模型,7B-65B,训练比通常使用的更多的标记的小模型,在各种推理预算下实现最佳性能】LLaMA: Open and Efficient Foundation Language Models
【通过少量示例教大型语言模型自我调试并解释生成代码,但目前已经经常这样用过】Teaching Large Language Models to Self-Debug
How Far Can Camels Go? Exploring the State of Instruction Tuning on Open Resources
LIMA: Less Is More for Alignment
【Tree-of-thought, 越来越像alphago了】Deliberate Problem Solving with Large Language Models
【应用ICL的多步推理方法,很有启发】ReAct: Synergizing Reasoning and Acting in Language Models
【CoT直接生成program code,然后让python interpreter执行】Program of Thoughts Prompting: Disentangling Computation from Reasoning for Numerical Reasoning Tasks
【大模型直接产生证据上下文】Generate rather than Retrieve: Large Language Models are Strong Context Generators
【具有4个特定操作的写作模型】PEER: A Collaborative Language Model
【将Python、SQL执行器和大模型结合】Binding Language Models in Symbolic Languages
【检索文档生成代码】DocPrompting: Generating Code by Retrieving the Docs
【Grounding+LLM的系列文章接下来会有很多】LLM-Planner: Few-Shot Grounded Planning for Embodied Agents with Large Language Models
【自我迭代生成(利用python验证过)训练数据】Language Models Can Teach Themselves to Program Better
相关文章:Specializing Smaller Language Models towards Multi-Step Reasoning
STaR: Bootstrapping Reasoning With Reasoning, 来自Neurips 22 (生成CoT数据用于模型微调), 引起后续一系列教小模型的CoT的文章
类似想法 【知识蒸馏】 Teaching Small Language Models to Reason 与 Learning by Distilling Context
类似想法 KAIST和Xiang Ren组(【CoT的rationale微调(教授)时进行扰动】PINTO: Faithful Language Reasoning Using Prompt-Generated Rationales等) 与 Large Language Models Are Reasoning Teachers
ETH的【CoT的数据分别训练问题分解和问题解答模型】Distilling Multi-Step Reasoning Capabilites of Large Language Models into Smaller Models via Semantic Decompositions
【让小模型学会CoT能力】In-context Learning Distillation: Transferring Few-shot Learning Ability of Pre-trained Language Models
【大模型教小模型CoT】Large Language Models Are Reasoning Teachers
【大模型生成证据(背诵)然后进行小样本闭卷问答】Recitation-Augmented Language Models
【归纳推理的自然语言方式】Language Models as Inductive Reasoners
【GPT-3用于数据标注(如情感分类)】Is GPT-3 a Good Data Annotator?
【基于多任务训练用于少样本数据增强的模型】KnowDA: All-in-One Knowledge Mixture Model for Data Augmentation in Low-Resource NLP
【procedural planning的工作,暂时不感兴趣】Neuro-Symbolic Procedural Planning with Commonsense Prompting
【目标:为维基百科中某些参考文献支持的Query生成一篇事实正确的文章】WebBrain: Learning to Generate Factually Correct Articles for Queries by Grounding on Large Web Corpus
【将外部物理模拟器的结果结合在context中】Mind's Eye: Grounded Language Model Reasoning through Simulation
【检索增强的CoT做知识Intensive的任务】Interleaving Retrieval with Chain-of-Thought Reasoning for Knowledge-Intensive Multi-Step Questions
【对比一致搜索 (CCS)无监督识别语言模型中的潜在(二元)知识】Discovering Latent Knowledge in Language Models Without Supervision
【Percy Liang组,可信搜索引擎,只有51.5%的生成句子得到引用的完全支持】Evaluating Verifiability in Generative Search Engines
Progressive-Hint Prompting Improves Reasoning in Large Language Models
Principle-Driven Self-Alignment of Language Models from Scratch with Minimal Human Supervision
Judging LLM-as-a-judge with MT-Bench and Chatbot Arena
【在我看来是最重要的文章之一,语言模型在交叉熵损失下的比例定律,损失与模型大小,数据集大小,用于训练的计算量成幂律关系,而宽度深度等架构细节影响较小】Scaling Laws for Neural Language Models
【另一篇最重要的文章之一,Chinchilla,限定计算下,最优的模型并不是最大的模型,而是更多数据训练的较小模型(60-70B)】Training Compute-Optimal Large Language Models
【哪种架构和优化目标有助于零样本泛化】What Language Model Architecture and Pretraining Objective Work Best for Zero-Shot Generalization?
【Grokking “顿悟”学习过程 Memorization->Circuit formation->Cleanup】Progress measures for grokking via mechanistic interpretability
【调查检索式模型的特点,发现两者均对reasoning有限】Can Retriever-Augmented Language Models Reason? The Blame Game Between the Retriever and the Language Model
【人类-AI语言交互评价框架】Evaluating Human-Language Model Interaction
What learning algorithm is in-context learning? Investigations with linear models
【模型编辑,这块是Hot topic】Mass-Editing Memory in a Transformer
【模型对无关上下文的敏感性,向提示中示例添加不相关的信息和添加忽略不相关上下文的指令部分解决】Large Language Models Can Be Easily Distracted by Irrelevant Context
【zero-shot CoT在敏感问题下会表现出bias和toxicity】 On Second Thought, Let’s Not Think Step by Step! Bias and Toxicity in Zero-Shot Reasoning
【大模型的CoT具有跨语言能力】Language models are multilingual chain-of-thought reasoners
【不同Prompt序列困惑度越低性能越好】 Demystifying Prompts in Language Models via Perplexity Estimation
【大模型的binary implicature resolution任务,这种暗示难并没有缩放现象】Large language models are not zero-shot communicators (https://github.com/google/BIG-bench/tree/main/bigbench/benchmark_tasks/implicatures)
【复杂的提示提升了CoT】Complexity-Based Prompting for Multi-step Reasoning
What Matters In The Structured Pruning of Generative Language Models?
【AmbiBench数据集,任务歧义:缩放 RLHF 模型在消除歧义任务方面表现最佳。微调比few-shot prompting更有帮助】Task Ambiguity in Humans and Language Models
【GPT-3的测试,包括记忆,校准,偏见等】Prompting GPT-3 To Be Reliable
【OSU研究CoT哪个部分对性能有效】Towards Understanding Chain-of-Thought Prompting: An Empirical Study of What Matters
【离散提示的跨语言模型研究】Can discrete information extraction prompts generalize across language models?
【记忆率与训练中的模型大小、前缀长度和重复率呈对数线性关系】Quantifying Memorization Across Neural Language Models
【很有启发,将问题通过GPT迭代分解为子问题并回答】Measuring and Narrowing the Compositionality Gap in Language Models
【对GPT-3类似公务员那种智力题类比测试】Emergent Analogical Reasoning in Large Language Models
【短文本训练,长文本测试,评估模型的变长适应能力】A Length-Extrapolatable Transformer
【什么时候检索,什么时候用大模型足够】When Not to Trust Language Models: Investigating Effectiveness and Limitations of Parametric and Non-Parametric Memories
【ICL是另一种形式的gradient更新】Why Can GPT Learn In-Context? Language Models Secretly Perform Gradient Descent as Meta Optimizers
Is GPT-3 a Psychopath? Evaluating Large Language Models from a Psychological Perspective
【对OPT模型进行不同大小训练的过程研究,发现困惑度是ICL的指标】Training Trajectories of Language Models Across Scales
【EMNLP 2022, 预训练纯英语语料包含着其他语言,模型跨语言能力可能来自于数据泄露】Language Contamination Helps Explains the Cross-lingual Capabilities of English Pretrained Models
【Overriding语义先验而使用prompt中的信息是一项涌向能力】Larger language models do in-context learning differently
【EMNLP 2022 findings】What Language Model to Train if You Have One Million GPU Hours?
【在推理时引入CFG技术极大的提升小模型的指令遵循能力】Stay on topic with Classifier-Free Guidance
【用openai的GPT-4训练自己的LLaMA模型打败openai的GPT-4,只能说佩服】Instruction Tuning with GPT-4
Reflexion: an autonomous agent with dynamic memory and self-reflection
【个性化风格的prompt学习,OPT】Extensible Prompts for Language Models
【加速大模型解码,利用小模型和大模型直接的共识一次调用多次可用,毕竟输入长了会很慢】 Accelerating Large Language Model Decoding with Speculative Sampling
【利用soft prompt减轻微调带来的ICL能力下降,一阶段微调prompt,二阶段微调模型】Preserving In-Context Learning ability in Large Language Model Fine-tuning
【语义解析任务,ICL的样例选择方法,CODEX和T5-large】Diverse Demonstrations Improve In-context Compositional Generalization
【一种文本生成的新的优化方式】Tailoring Language Generation Models under Total Variation Distance
【条件生成的不确定性估计,采用多个采样输出的语义聚类合并后簇的熵来估计】Semantic Uncertainty: Linguistic Invariances for Uncertainty Estimation in Natural Language Generation
Go-tuning: Improving Zero-shot Learning Abilities of Smaller Language Models
【很有启发,自由文本约束下的文本生成方法】Controllable Text Generation with Language Constraints
【生成预测时采用相似度选phrase而不是softmax预测token】Nonparametric Masked Language Modeling
【长文本的ICL方法】Parallel Context Windows Improve In-Context Learning of Large Language Models
【InstructGPT模型自己生成ICL的样例】Self-Prompting Large Language Models for Open-Domain QA
【通过分组和注意力机制使得ICL能够输入更多的标注样本】Structured Prompting: Scaling In-Context Learning to 1,000 Examples
Momentum Calibration for Text Generation
【两种ICL样例选择的方法,基于OPT和GPTJ的实验】Careful Data Curation Stabilizes In-context Learning
【对Mauve(pillutla 等人)生成评估指标的分析】On the Usefulness of Embeddings, Clusters and Strings for Text Generation Evaluation
Promptagator: Few-shot Dense Retrieval From 8 Examples
【三个臭皮匠,顶个诸葛亮】Self-Consistency Improves Chain of Thought Reasoning in Language Models
【反转,输入和标签为条件生成指令】Guess the Instruction! Making Language Models Stronger Zero-Shot Learners
【LLM 的反向推导自我验证】Large Language Models are reasoners with Self-Verification
【检索-生成证据流程下的安全场景的方法】Foveate, Attribute, and Rationalize: Towards Safe and Trustworthy AI
【基于beam search的文本生成式信息抽取片段的置信度估计】How Does Beam Search improve Span-Level Confidence Estimation in Generative Sequence Labeling?
SPT: Semi-Parametric Prompt Tuning for Multitask Prompted Learning
【对抽取式摘要黄金标签的探讨】Text Summarization with Oracle Expectation
【基于马氏距离的条件文本生成OOD检测方法】Out-of-Distribution Detection and Selective Generation for Conditional Language Models
【注意力模块集成Prompt进行样例级别的预测】Model ensemble instead of prompt fusion: a sample-specific knowledge transfer method for few-shot prompt tuning
【多个任务的Prompt通过分解和蒸馏到一个Prompt】Multitask Prompt Tuning Enables Parameter-Efficient Transfer Learning
【step-by-step推理生成文本的评估指标,可以作为下次分享选题】ROSCOE: A Suite of Metrics for Scoring Step-by-Step Reasoning
【校准序列似然改进条件语言生成】Calibrating Sequence likelihood Improves Conditional Language Generation
【基于梯度优化的文本攻击方法】TextGrad: Advancing Robustness Evaluation in NLP by Gradient-Driven Optimization
【GMM建模ICL决策分类边界从而校准】Prototypical Calibration for Few-shot Learning of Language Models
【改写问题,以及基于图的ICL聚合方法】Ask Me Anything: A simple strategy for prompting language models
【用于从未注释的示例池中选择好的候选作为ICL的数据库】Selective Annotation Makes Language Models Better Few-Shot Learners
PromptBoosting: Black-Box Text Classification with Ten Forward Passes
Attention-Guided Backdoor Attacks against Transformers
【Prompt Mask位置自动选标签词】Pre-trained Language Models can be Fully Zero-Shot Learners
【压缩FiD输入向量的长度,且输出时重新排序来输出文档排名】FiD-Light: Efficient and Effective Retrieval-Augmented Text Generation
【大模型教小模型生成解释】PINTO: Faithful Language Reasoning Using Prompted-Generated Rationales
【寻找预训练影响子集】ORCA: Interpreting Prompted Language Models via Locating Supporting Evidence in the Ocean of Pretraining Data
【提示工程,针对的是Instruction,一阶段生成二阶段排序过滤】Large Language Models are Human-Level Prompt Engineers
Knowledge Unlearning for Mitigating Privacy Risks in Language Models
Editing models with task arithmetic
【不用每次都输入指令和样例,将其转换为参数高效模块,】HINT: Hypernetwork Instruction Tuning for Efficient Zero-Shot Generalisation
【不需要人工选样例的ICL展示生成方法】Z-ICL: Zero-Shot In-Context Learning with Pseudo-Demonstrations
【任务Instruction和文本一起生成Embedding】One Embedder, Any Task: Instruction-Finetuned Text Embeddings
【大模型教小模型CoT】KNIFE: Knowledge Distillation with Free-Text Rationales
【信息提取式生成模型的源和目标分词不一致问题】Tokenization Consistency Matters for Generative Models on Extractive NLP Tasks
Parsel: A Unified Natural Language Framework for Algorithmic Reasoning
【ICL样例选择,一阶段选择二阶段排序】Self-adaptive In-context Learning
【精读,可读的prompt无监督选择方法,GPT-2】Toward Human Readable Prompt Tuning: Kubrick's The Shining is a good movie, and a good prompt too
【PRONTOQA数据集测试CoT推理能力,发现Planning能力仍受限】Language Models Can (kind of) Reason: A Systematic Formal Analysis of Chain-of-Thought
【reasoning数据集】WikiWhy: Answering and Explaining Cause-and-Effect Questions
【reasoning数据集】STREET: A MULTI-TASK STRUCTURED REASONING AND EXPLANATION BENCHMARK
【reasoning数据集,比较OPT预训练和微调,包括CoT微调模型】 ALERT: Adapting Language Models to Reasoning Tasks
【浙大张宁豫团队对近期reasoning的总结】Reasoning with Language Model Prompting: A Survey
【复旦肖仰华团队对文本生成技术和方向的总结】Harnessing Knowledge and Reasoning for Human-Like Natural Language Generation: A Brief Review
【近期reasoning文章的总结,来自UIUC的Jie Huang】Towards Reasoning in Large Language Models: A Survey
【回顾数学推理和DL的任务、数据集和方法】A Survey of Deep Learning for Mathematical Reasoning
A Survey on Natural Language Processing for Programming
奖励建模数据集:
Red-teaming数据集,harmless vs. helpful, RLHF+scale更难被攻击 (另一个有效的技术是CoT fine-tuning):
【知识】+【推理】+【生成】
如果对您有帮助,请star支持一下,欢迎Pull Request~
主观整理,时间上主要从ICLR 2023 Rebuttal期间开始的,包括ICLR,ACL,ICML等预印版论文。
不妥之处或者建议请指正! Dongfang Li, [email protected]


