Awesome Code LLM
1.0.0
这是我们的TMLR调查的回购,统一了NLP和软件工程的观点:关于代码语言模型的调查 - 对法规LLM研究的全面审查。每个类别的作品按时间顺序排序。如果您对机器学习有基本的了解,但是NLP的新知识,我们还提供了第9节中推荐的读数列表。
[2024/11/28]特色论文:
偏好优化对Nanyang Technology University的伪反馈的推理。
Scribeagent:使用Scribe的生产规模工作流数据迈向专业的Web代理。
计划驱动的编程:墨尔本大学的大型语言模型编程工作流程。
存储库级代码翻译基准对阳光森大学的生锈定位。
利用先前的经验:中国科学技术大学的文本到SQL的可扩展辅助知识基础。
法典:一种通才嵌入模型家族,用于从Salesforce AI研究中检索多任务和多任务代码。
检察官:Purdue University通过主动的安全对准加固代码LLM。
[2024/10/22]我们在2024年9月和10月的一篇微信中收集了70篇论文。
[2024/09/06]我们的调查已被机器学习研究(TMLR)的交易接受。
[2024/09/14]我们在一份微信中汇编了57篇论文(包括在ACL 2024上介绍的48篇论文(包括48篇)。
如果您发现该存储库中缺少的论文,分为类别或缺乏对其期刊/会议信息的参考,请随时毫不犹豫地创建问题。如果您发现此存储库有帮助,请引用我们的调查:
@article{zhang2024unifying,
title={Unifying the Perspectives of {NLP} and Software Engineering: A Survey on Language Models for Code},
author={Ziyin Zhang and Chaoyu Chen and Bingchang Liu and Cong Liao and Zi Gong and Hang Yu and Jianguo Li and Rui Wang},
journal={Transactions on Machine Learning Research},
issn={2835-8856},
year={2024},
url={https://openreview.net/forum?id=hkNnGqZnpa},
note={}
}
调查
型号
2.1基础LLM和训练策略
2.2现有的LLM适用于代码
2.3一般预测代码
2.4(指令)代码进行微调
2.5关于代码的加固学习
编码符合推理时
3.1编码推理
3.2代码模拟
3.3代码代理
3.4交互式编码
3.5前端导航
用于低资源,低级和特定域的语言的代码LLM
下游任务的方法/模型
编程
测试和部署
DevOps
要求
AI生成的代码的分析
人类相互作用
数据集
8.1预训练
8.2基准
推荐阅读
引用
星历史
加入我们
我们列出了有关类似主题的最近几项调查。尽管它们都是关于代码的语言模型,但1-2集中在NLP方面; 3-6专注于SE方; 7-11在我们之后发布。
“大语模型符合NL2Code:调查” [2022-12] [ACL 2023] [Paper]
“关于神经法规智能的验证语言模型的调查” [2022-12] [纸]
“源代码的预训练模型的经验比较” [2023-02] [ICSE 2023] [Paper]
“软件工程的大型语言模型:系统文献综述” [2023-08] [纸]
“要了解软件工程任务中的大型语言模型” [2023-08] [纸]
“代码情报的语言模型中的陷阱:分类法和调查” [2023-10] [纸]
“针对软件工程的大型语言模型的调查” [2023-12] [纸]
“代码智能的深度学习:调查,基准和工具包” [2023-12] [纸]
“神经法规智能的调查:范式,进步及以后” [2024-03] [纸]
“任务人员提示:软件验证和伪造方法中LLM下游任务的分类法” [2024-04] [Paper]
“自动编程:大语言模型及以后” [2024-05] [纸]
“软件工程和基础模型:使用基础模型的陪审团的行业博客见解” [2024-10] [纸]
“基于深度学习的软件工程:进步,挑战和机遇” [2024-10] [纸]
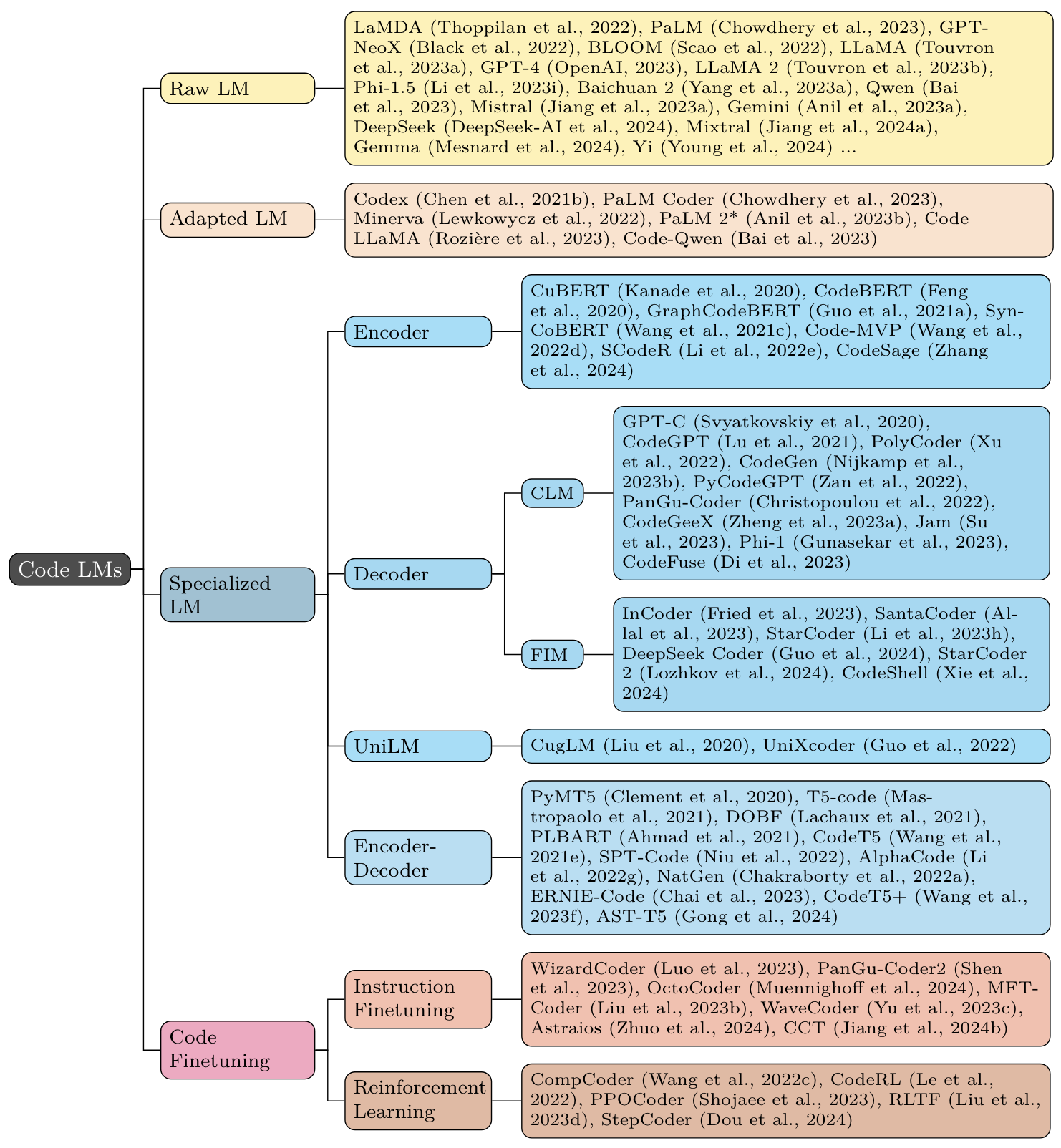
这些LLM并未专门培训用于代码,但已证明编码功能有所不同。
LAMDA :“ LAMDA:对话框的语言模型” [2022-01] [纸]
棕榈:“棕榈:使用途径的缩放语言建模” [2022-04] [JMLR] [纸]
GPT-NEOX :“ GPT-NEOX-20B:开放源节自回归语言模型” [2022-04] [ACL 2022关于创建LLMS的挑战和观点研讨会[Paper] [Paper] [repo]
布鲁姆:“布鲁姆:176B参数开放式访问多语言模型” [2022-11] [纸] [模型]
Llama :“ Llama:开放有效的基础语言模型” [2023-02] [纸]
GPT-4 :“ GPT-4技术报告” [2023-03] [纸]
Llama 2 :“ Llama 2:开放基础和微调聊天模型” [2023-07] [Paper] [repo]
PHI-1.5 :“您需要教科书II:PHI-1.5技术报告” [2023-09] [Paper] [模型]
Baichuan 2 :“ Baichuan 2:打开大规模语言模型” [2023-09] [Paper] [repo]
QWEN :“ QWEN技术报告” [2023-09] [Paper] [Repo]
Mistral :“ Mistral 7b” [2023-10] [Paper] [repo]
双子座:“双子座:一个高度强大的多峰模型家族” [2023-12] [纸]
PHI-2 :“ PHI-2:小语言模型的惊喜能力” [2023-12] [博客]
Yayi2 :“ Yayi 2:多语言开源大语言模型” [2023-12] [Paper] [repo]
DeepSeek :“ DeepSeek LLM:使用长期主义扩展开源语言模型” [2024-01] [Paper] [repo]
混音:“专家混音” [2024-01] [Paper] [Blog]
DeepSeekmoe :“ DeepSeekmoe:迈向Experts语言混合物的最终专家专业” [2024-01] [Paper] [repo]
猎户座:“ Orion-14b:开源多语言大语言模型” [2024-01] [Paper] [repo]
Olmo :“ Olmo:加速语言模型的科学” [2024-02] [Paper] [repo]
Gemma :“ Gemma:基于双子座研究与技术的开放模型” [2024-02] [Paper] [Blog]
克劳德3 :“克劳德3型家族:Opus,Sonnet,Haiku” [2024-03] [Paper] [Blog]
Yi :“ YI:开放基础模型,由01.AI” [2024-03] [Paper] [repo]
Poro :“ Poro 34B和多语言的祝福” [2024-04] [Paper] [模型]
JetMoe :“ Jetmoe:以0.1m美元达到Llama2的性能” [2024-04] [Paper] [repo]
Llama 3 :“ Llama 3模型群” [2024-04] [blog] [repo] [Paper]
REKA核心:“ Reka Core,Flash和Edge:一系列强大的多模式模型” [2024-04] [Paper]
PHI-3 :“ PHI-3技术报告:手机上本地有能力的语言模型” [2024-04] [纸]
Openelm :“ OpenElm:具有开源培训和推理框架的有效语言模型家族” [2024-04] [Paper] [repo]
Tele-FLM :“ Tele-FLM技术报告” [2024-04] [Paper] [模型]
DeepSeek-v2 :“ DeepSeek-V2:强大,经济和有效的专家语言模型” [2024-05] [Paper] [repo]
壁虎:“壁虎:英语,代码和韩语的生成语言模型” [2024-05] [Paper] [模型]
MAP-NEO :“ MAP-NEO:高功能和透明的双语大语言模型系列” [2024-05] [Paper] [repo]
Skywork-Moe :“ Skywork-Moe:深入研究培训技术的培训技术” [2024-06] [纸]
XModel-LM :“ Xmodel-LM技术报告” [2024-06] [Paper]
GEB :“ GEB-1.3B:开放轻巧的大语言模型” [2024-06] [纸]
野兔:“野兔:人类先验,小语言模型效率的关键” [2024-06] [纸]
DCLM :“ DataComp-LM:寻找语言模型的下一代培训集” [2024-06] [Paper]
Nemotron-4 :“ Nemotron-4 340B技术报告” [2024-06] [Paper]
chatglm :“ changglm:从GLM-130B到GLM-4的大型语言模型家庭” [2024-06] [纸]
Yulan :“ Yulan:开源大型语言模型” [2024-06] [纸]
Gemma 2 :“ Gemma 2:以实用大小改善开放语言模型” [2024-06] [纸]
H2O-DANUBE3 :“ H2O-DANUBE3技术报告” [2024-07] [纸]
QWEN2 :“ QWEN2技术报告” [2024-07] [纸]
阿拉姆:“阿拉姆:阿拉伯语和英语的大语言模型” [2024-07] [纸]
Seallms 3 :“ Seallms 3:东南亚语言的开放基础和聊天多语言大语模型” [2024-07] [纸]
AFM :“ Apple Intelligence Foundation语言模型” [2024-07] [纸]
“要代码,还是不编码?探索代码在预训练中的影响” [2024-08] [Paper]
Olmoe :“ Olmoe:开放式Experts语言模型” [2024-09] [Paper]
“预处理的代码如何影响语言模型任务表现?” [2024-09] [纸]
EUROLLM :“ EUROLLM:欧洲的多语言语言模型” [2024-09] [Paper]
“哪种编程语言以及训练阶段的哪些功能会影响下游逻辑推理性能?” [2024-10] [纸]
GPT-4O :“ GPT-4O系统卡” [2024-10] [纸]
Hunyuan-large :“ Hunyuan-large:一种开源MOE型号,由Tencent进行了520亿个激活参数” [2024-11] [Paper]
水晶:“水晶:语言和代码上的LLM功能” [2024-11] [纸]
Xmodel-1.5 :“ Xmodel-1.5:1B规模的多语言LLM” [2024-11] [Paper]
这些模型是通用的LLM,进一步介绍了与代码相关的数据。
法典(GPT-3):“评估在代码上训练的大型语言模型” [2021-07] [纸]
棕榈编码器(棕榈):“棕榈:用途径缩放语言建模” [2022-04] [JMLR] [纸]
密涅瓦(Palm):“解决语言模型的定量推理问题” [2022-06] [纸]
棕榈2 * (棕榈2):“棕榈2技术报告” [2023-05] [纸]
Code Llama (Llama 2):“代码骆驼:代码的开放基础模型” [2023-08] [Paper] [repo]
Lemur (Llama 2):“ Lemur:协调语言代理的自然语言和代码” [2023-10] [ICLR 2024 Spotlight] [Paper]
BTX (LLAMA 2):“分支机构 - 培训:将专家LLM混合到Experts LLM的混合物中” [2024-03] [Paper]
Hirope :“ Hirope:使用分层位置的代码模型的长度外推” [2024-03] [ACL 2024] [Paper]
“通过融合高度专业的语言模型同时掌握文本,代码和数学” [2024-03] [Paper]
Codegemma :“ Codegemma:基于Gemma的打开代码模型” [2024-04] [Paper] [模型]
DeepSeek-Coder-V2 :“ DeepSeek-Coder-v2:打破代码智能中的封闭源模型的障碍” [2024-06] [Paper]
“协作代码生成模型的承诺和危险:平衡有效性和记忆” [2024-09] [Paper]
Qwen2.5代码:“ QWEN2.5-CODER技术报告” [2024-09] [Paper]
Lingma Swe-GPT :“ Lingma Swe-GPT:用于自动化软件改进的开放开发过程中的开放开发过程模型” [2024-11] [Paper]
这些模型是使用现有的通用语言建模目标从头开始预测的变压器编码器,解码器和编码器描述器。
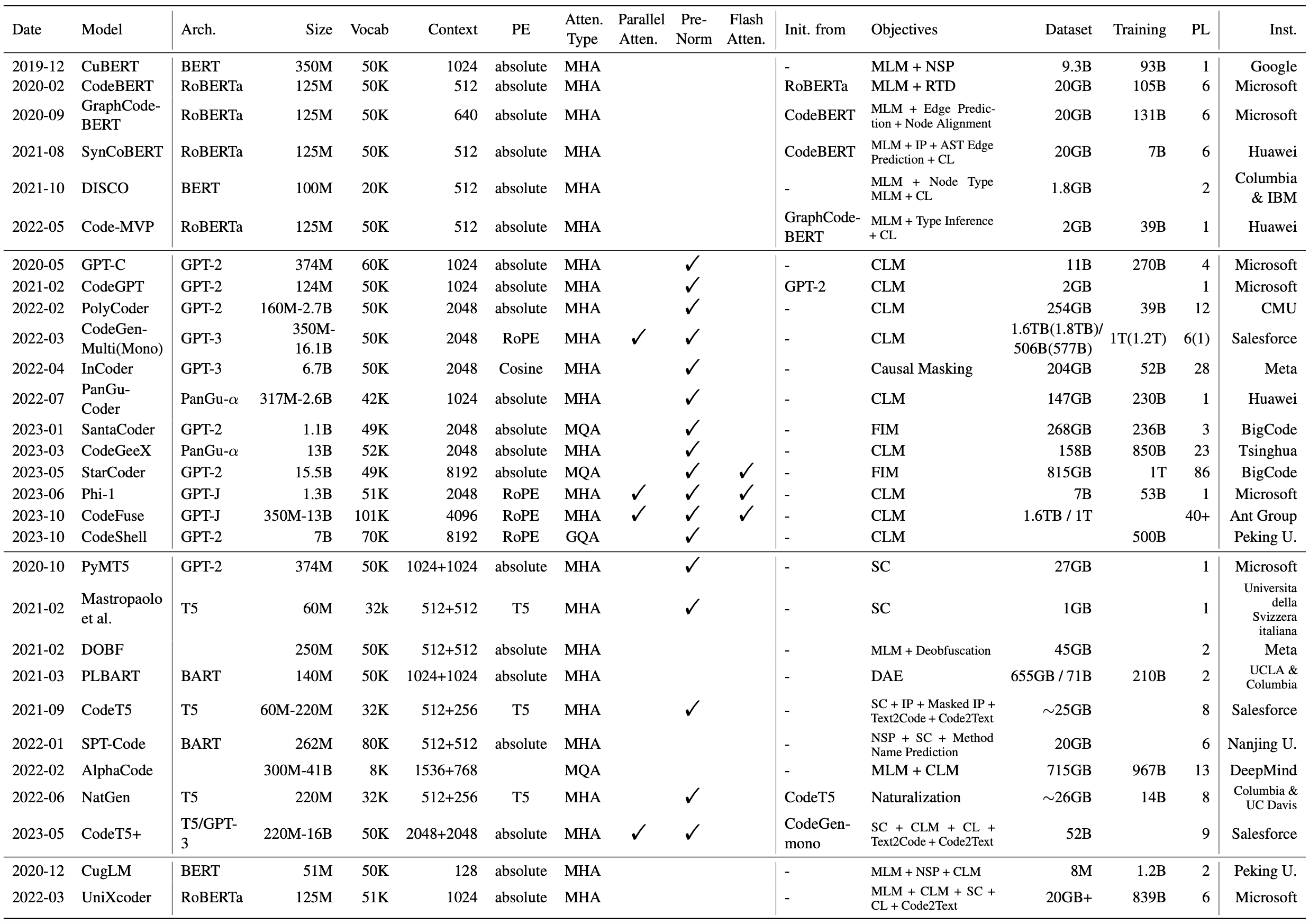
Cubert (MLM + NSP):“学习和评估源代码的上下文嵌入” [2019-12] [ICML 2020] [Paper] [repo]
Codebert (MLM + RTD):“ Codebert:用于编程和自然语言的预训练模型” [2020-02] [EMNLP 2020调查结果] [Paper] [Paper] [repo]
GraphCodebert (MLM + DFG边缘预测 + DFG节点对齐):“ GraphCodebert:带有数据流的预训练代码表示” [2020-09] [ICLR 2021] [Paper] [Paper] [Repo]
Syncobert (MLM +标识符预测 + AST边缘预测 +对比度学习):“ Syncobert:语法引导的代码表示的多模式对比预训练” [2021-08] [Paper]
迪斯科(MLM +节点类型MLM +对比度学习):“学习(DIS) - 来自程序对比的源代码的类似性” [2021-10] [ACL 2022] [Paper]
代码-MVP (MLM +类型推理 +对比度学习):“代码MVP:学习从多个视图中表示源代码具有对比度预训练” [2022-05] [NAACL 2022技术轨迹] [Paper] [Paper]
代码(MLM + DEOBFUSCATION +对比度学习):“大规模的代码表示学习” [2024-02] [ICLR 2024] [Paper] [Paper]
科尔斯伯特(MLM):“代码理解模型背后的缩放法则” [2024-02] [纸]
GPT-C (CLM):“ Intellicode Compose:使用变压器代码生成” [2020-05] [esec/fse 2020] [Paper]
Codegpt (CLM):“ Codexglue:用于代码理解和生成的机器学习基准数据集” [2021-02] [NEURIPS数据集和基准测试2021] [paper] [paper] [repo]
Codeparrot (CLM)[2021-12] [博客]
PolyCoder (CLM):“代码大型语言模型的系统评估” [2022-02] [DL4C@ICLR 2022] [Paper] [repo] [repo]
CodeGen (CLM):“ CodeGen:具有多转化程序合成代码的开放大语模型” [2022-03] [ICLR 2023] [Paper] [paper] [repo]
启动器(因果掩蔽):“开关:代码填充和合成的生成模型” [2022-04] [ICLR 2023] [Paper] [Paper] [repo]
pycodegpt (CLM):“证书:以图书馆为导向的代码生成的草图上的持续预训练” [2022-06] [ijcai-ecai 2022] [paper] [paper] [repo]
pangu-coder (CLM):“ pangu-coder:具有功能级语言建模的程序合成” [2022-07] [Paper]
Santacoder (FIM):“ Santacoder:不要伸手去拿星星!” [2023-01] [纸] [模型]
Codegeex (CLM):“ Codegeex:用于代码生成的预培训模型,对HumaneVal-X进行多语言评估” [2023-03] [Paper] [Paper] [repo]
Starcoder (FIM):“ Starcoder:愿来源与您同在!” [2023-05] [纸] [模型]
PHI-1 (CLM):“您需要的教科书都是所有的” [2023-06] [Paper] [模型]
CodeFuse (CLM):“ CodeFuse-13b:审慎的多语言代码大语言模型” [2023-10] [Paper] [模型]
DeepSeek编码器(CLM+FIM):“ DeepSeek-Coder:当大语言模型符合编程时 - 代码智能的兴起” [2024-01] [Paper] [repo] [repo]
StarCoder2 (CLM+FIM):“ Starcoder 2和堆栈V2:下一代” [2024-02] [Paper] [repo]
CODESHELL (CLM+FIM):“ CodeShell技术报告” [2024-03] [Paper] [repo]
Codeqwen1.5 [2024-04] [博客]
花岗岩:“花岗岩代码模型:代码智能的开放基础模型家族” [2024-05] [纸]“将花岗岩代码模型缩放到128K上下文” [2024-07] [2024-07] [Paper]
NT-JAVA :“狭窄的变压器:基于Starcoder的Java-LM用于桌面” [2024-07] [Paper]
Arctic-SnowCoder :“北极 - 抢语:在代码预处理中揭开高质量数据” [2024-09] [Paper]
AIXCODER :“ AIXCODER-7B:代码完成代码完成的轻巧有效的大语言模型” [2024-10] [Paper]
OpenCoder :“ OpenCoder:顶级代码大型语言模型的开放食谱” [2024-11] [Paper]
PYMT5 (跨度腐败):“ PYMT5:具有变压器的自然语言和Python代码的多模式翻译” [2020-10] [EMNLP 2020] [Paper]
Mastropaolo等。 (MLM + DEOBFUSCATION):“ DOBF:编程语言的DEOBFUSCATION预训练目标” [2021-02] [ICSE 2021] [Paper] [Paper] [repo]
DOBF (跨度腐败):“研究文本到文本传输变压器以支持代码相关的任务的使用” [2021-02] [Neurips 2021] [Paper] [Paper] [repo]
PLBART (DAE):“用于计划理解和发电的统一预训练” [2021-03] [NAACL 2021] [Paper] [repo]
codet5 (跨度损坏 +标识符标记 +蒙版标识符预测 + text2code + code2text):“ codet5:标识符 - 意识到统一的统一的预训练的编码器模型,用于代码理解和生成” [2021-09] [2021-09]
SPT-CODE (跨度损坏 + NSP +方法名称预测):“ SPT-CODE:学习源代码表示的序列到序列预训练” [2022-01] [ICSE 2022技术轨道] [Paper] [Paper]
字母(MLM + CLM):“使用字母的竞争级代码生成” [2022-02] [Science] [Paper] [Blog]
NATGEN (代码归化):“ NATGEN:通过“归化”源代码” [2022-06] [ESEC/FSE 2022] [Paper] [Paper] [repo]来培训生成预训练
Ernie-Code (跨度腐败 +基于枢轴的翻译LM):“ Ernie-Code:超越以英语为中心的编程语言的跨语性读图” [2022-12] [2022-12] [ACL23(发现)] [Paper] [Paper] [repo]
codet5 + (跨度损坏 + clm +文本代码对比学习 +文本代码翻译):“ codet5 +:打开代码理解和生成的大语言模型” [2023-05] [EMNLP 2023] [Paper] [paper] [repo]
AST-T5 (SPAN腐败):“ AST-T5:结构意识到代码生成和理解的预读” [2024-01] [ICML 2024] [Paper] [Paper]
CUGLM (MLM + NSP + CLM):“基于多任务学习的代码完成的预训练的语言模型” [2020-12] [ASE 2020] [Paper]
UnixCoder (MLM + NSP + CLM +跨度损坏 +对比度学习 + Code2Text):“ UnixCoder:代码表示的统一跨模式预训练” [2022-03] [ACL 2022] [Paper] [Paper] [Paper] [repo] [repo]
这些模型采用教学微调技术来增强代码LLM的能力。
WizardCoder (Starcoder + Evol-Instruct):“ WizardCoder:使用Evol-Instruct的大型语言模型授权代码” [2023-06] [ICLR 2024] [Paper] [Paper] [repo]
pangu-coder 2 (Starcoder + Evol-Instruct + RRTF):“ Pangu-Coder2:使用排名反馈的代码增加大型语言模型” [2023-07] [Paper]
Octocoder (StarCoder) / Octogeex (Codegeex2):“章鱼:指令调谐代码大语言模型” [2023-08] [ICLR 2024 Spotlight] [Paper] [Paper] [repo]
“在哪个培训阶段进行代码数据有助于LLMS推理” [2023-09] [ICLR 2024 Spotlight] [Paper]
指示尺:“指示尺:指令调整大型语言模型进行代码编辑” [paper] [repo]
MftCoder :“ MftCoder:使用多任务进行微调来提高代码LLM” [2023-11] [KDD 2024] [Paper] [repo]
“用于培训准确代码生成器的LLM辅助代码清洁” [2023-11] [ICLR 2024] [Paper]
Magicoder :“ Magicoder:使用OSS-Instruct授权代码生成” [2023-12] [ICML 2024] [Paper]
WaveCoder :“ WaveCoder:通过指令调整大型语言模型的广泛而多功能增强” [2023-12] [ACL 2024] [Paper]
Astraios :“ Astraios:参数效率指令调谐代码大语言模型” [2024-01] [Paper]
Dolphcoder :“ DolphCoder:具有多样和多目标指令调整的回声量表大语言模型” [2024-02] [ACL 2024] [Paper]
SAFECODER :“安全代码生成的指令调整” [2024-02] [ICML 2024] [Paper]
“代码需求注释:增强代码LLM具有评论增强” [ACL 2024调查结果] [纸]
CCT :“代码大型语言模型的代码比较调整” [2024-03] [纸]
SAT :“代码预培训模型的结构意识微调” [2024-04] [Paper]
Codefort :“ Codefort:强大的代码生成模型培训” [2024-04] [纸]
XFT :“ XFT:通过简单地合并升级混合物来解锁代码指令调整的功能” [2024-04] [ACL 2024] [Paper] [Paper] [repo]
Aiev-Instruct :“ Autocoder:使用AIEV-INSTRUCTICT增强代码大语言模型” [2024-05] [Paper]
AlchemistCoder :“ AlchemistCoder:通过对多源数据进行后观察调整来协调和启发代码功能” [2024-05] [Paper]
“从符号任务到代码生成:多元化会产生更好的任务表演者” [2024-05] [纸]
“揭示编码数据指令对大语言模型推理的影响” [2024-05] [纸]
梅子:“梅子:偏好学习加测试用例可以产生更好的代码语言模型” [2024-06] [纸]
McOder :“ McEval:大规模多语言代码评估” [2024-06] [Paper]
“解锁培训中监督的微调和加强学习之间的相关性大型语言模型” [2024-06] [纸]
代码优化:“代码优势:自我生成的优先数据以确保正确性和效率” [2024-06] [纸]
Unicoder :“ Unicoder:通过通用代码缩放代码大语言模型” [2024-06] [ACL 2024] [Paper]
“简洁是机智的灵魂:修剪长文件以生成代码” [2024-06] [纸]
“代码少,对数:有效的LLM通过数据修剪来生成代码” [2024-07] [Paper]
InverseCoder :“ InverseCoder:使用逆教学释放指令调整的代码LLM的功能” [2024-07] [Paper]
“小型代码语言模型的课程学习” [2024-07] [纸]
遗传教学:“遗传指导:扩大大型语言模型的编码说明的合成生成” [2024-07] [纸]
DataScope :“ API指导的数据集合成至Finetune大型代码模型” [2024-08] [Paper]
** Xcoder **:“您的代码LLMS如何执行?使用高质量数据授权代码指令进行调整” [2024-09] [Paper]
加拉:“加拉:图形对齐的大型语言模型,以改进源代码理解” [2024-09] [纸]
六角形:“六脚架:通过Oracle指导的合成训练数据生成安全代码” [2024-09] [Paper]
AMR-evol :“ AMR-Evol:自适应模块化响应进化引发了代码生成中大语言模型的更好的知识蒸馏” [2024-10] [Paper]
LINTSEQ :“培训语言模型有关合成编辑序列的培训模型可以改善代码综合” [2024-10] [Paper]
COBA :“ COBA:大型语言模型多任务鉴定的融合平衡器” [2024-10] [EMNLP 2024] [Paper]
CursorCore :“ CursorCore:通过对齐任何东西来协助编程” [2024-10] [Paper]
selfcodealign :“自我播放:代码生成的自我调整” [2024-10] [纸]
“掌握Codellm的数据合成的技巧” [2024-10] [纸]
Codelutra :“ Codelutra:通过首选项引导的改进来提高LLM代码生成” [2024-11] [纸]
DSTC :“ DSTC:仅使用自我生成的测试和代码来改善代码LMS的直接偏好学习” [2024-11] [Paper]
compcoder :“编译器反馈的编译神经代码生成” [2022-03] [ACL 2022] [纸]
Coderl :“编码器:通过验证的模型和深度强化学习来掌握代码” [2022-07] [Neurips 2022] [Paper] [repo] [repo]
PPOCODER :“使用深入强化学习的基于执行的代码生成” [2023-01] [TMLR 2023] [Paper] [repo]
RLTF :“ RLTF:从单位测试反馈学习的加固学习” [2023-07] [Paper] [repo]
B-Coder :“ B-coder:基于价值的计划合成的深度强化学习” [2023-10] [ICLR 2024] [Paper]
IRCOCO :“ Ircoco:立即奖励代码完成的深入强化学习” [2024-01] [FSE 2024] [Paper]
Stepcoder :“ Stepcoder:通过从编译器反馈中进行加固学习来改善代码生成” [2024-02] [ACL 2024] [Paper]
RLPF&DPA :“生成快速代码的性能分配的LLM” [2024-04] [Paper]
“测量RLHF中的记忆以完成代码完成” [2024-06] [Paper]
“将RLAIF应用于轻量级LLM中的API-USAGE代码生成” [2024-06] [Paper]
rlCoder :“ RLCODER:存储库级代码完成的加固学习” [2024-07] [Paper]
PF-PPO :“ RLHF中的策略过滤到代码生成的微调LLM” [2024-09] [Paper]
咖啡盖:“咖啡盖:评估和改善错误代码自然语言反馈的环境” [2024-09] [纸]
RLEF :“ RLEF:通过增强学习的执行反馈中的接地代码LLM” [2024-10] [纸]
codepmp :“ Codepmp:大型语言模型推理的可伸缩偏好模型” [2024-10] [纸]
CodedPo :“编码PO:用自生成和验证的源代码对齐代码模型” [2024-10] [Paper]
“对代码生成的流程监督引导的政策优化” [2024-10] [纸]
“与直接偏好优化对齐Codellm” [2024-10] [纸]
猎鹰:“猎鹰:反馈驱动的自适应长/短期记忆加强编码优化系统” [2024-10] [纸]
PFPO :“使用伪反馈推理的优先优化” [2024-11] [纸]
PAL :“ PAL:程序辅助语言模型” [2022-11] [ICML 2023] [Paper] [repo]
锅:“提示的思想计划:将计算与数值推理任务推理的解开” [2022-11] [TMLR 2023] [Paper] [repo]
PAD :“ PAD:程序辅助蒸馏可以比经过思考的微调更好地教导小型模型” [2023-05] [NAACL 2024] [Paper] [Paper]
CSV :“使用基于代码的自我验证的GPT-4代码解释器解决挑战性的数学单词问题” [2023-08] [ICLR 2024] [Paper]
MathCoder :“ MathCoder:LLMS中的无缝代码集成,用于增强数学推理” [2023-10] [ICLR 2024] [Paper]
COC :“代码链:具有语言模型的代码模拟器的推理” [2023-12] [ICML 2024] [Paper]
马里奥:“马里奥:具有代码解释器输出的数学推理 - 可再现管道” [2024-01] [ACL 2024调查结果] [纸]
富豪:“富豪:重构计划以发现可概括的抽象” [2024-01] [ICML 2024] [Paper]
“可执行代码动作会引起更好的LLM代理” [2024-02] [ICML 2024] [Paper]
Hpropro :“通过基于程序的提示来探索混合问题回答” [2024-02] [ACL 2024] [Paper]
XStreet :“从LLM通过代码诱导更好的多语言结构化推理” [2024-03] [ACL 2024] [Paper]
流程:“流动:使用LLMS自动工作流程” [2024-03] [纸]
思想执行:“作为编译器的语言模型:模拟伪代码执行可以改善语言模型中的算法推理” [2024-04] [Paper]
核心:“核心:LLM作为自然语言编程的解释器,伪代码编程和AI代理的流程编程” [2024-05] [Paper]
Mumath-Code :“ Mumath-Code:将工具使用的大语言模型与数学推理的多镜数据增强相结合” [2024-05] [Paper]
COGEX :“学习通过程序产生,仿真和搜索来推理” [2024-05] [纸]
“使用LLM的算术推理:Prolog Generation&Permotunt” [2024-05] [Paper]
“ LLM可以随着程序而推理吗?” [2024-06] [纸]
Dotamath :“ Dotamath:用代码帮助和数学推理的自我纠正的思想分解” [2024-07] [纸]
CIBENCH :“ CIBENCH:使用代码解释器插件评估LLM” [2024-07] [Paper]
Pybench :“ Pybench:在各种现实世界编码任务上评估LLM代理” [2024-07] [Paper]
adacoder :“ adacoder:编程视觉问题的自适应提示压缩回答” [2024-07] [纸]
金字塔尺寸:“金字塔编码器:用于组成视觉问题的分层代码生成器回答” [2024-07] [纸]
CodeGraph :“ CodeGraph:使用代码增强LLM的图形推理” [2024-08] [Paper]
暹罗:“暹罗:大语言模型的自我改进代码辅助数学推理” [2024-08] [纸]
Codeplan :“ Codeplan:通过缩放代码形式计划在大型Langauge模型中解锁推理潜力” [2024-09] [Paper]
锅:“思想证明:神经肯定程序的合成允许强大而可解释的推理” [2024-09] [纸]
metamath :“ metamath:在大型语言模型中整合自然语言和代码以增强数学推理” [2024-09] [纸]
“ Babelbench:用于多模式和多结构数据的代码驱动分析的OMNI基准” [2024-10] [纸]
CODESTER :“在代码执行和文本推理之间转向大型语言模型” [2024-10] [Paper]
MathCoder2 :“ MathCoder2:从模型翻译的数学代码进行持续预处理的更好的数学推理” [2024-10] [Paper]
LLMFP :“严格规划的任何内容:使用基于LLM的正式编程的通用零弹计划” [2024-10] [纸]
证明:“并非所有的选票都计算!程序,因为验证者改善了数学推理的语言模型的自我一致性” [2024-10] [纸]
证明:“信任但验证:野外的程序化VLM评估” [2024-10] [纸]
地理编码器:“地理编码器:通过视觉模型生成模块化代码来解决几何问题” [2024-10] [纸]
推理:“推理:使用可提取的符号程序来评估数学推理” [2024-10] [纸]
GFP :“缝隙填充提示增强了代码辅助的数学推理” [2024-11] [Paper]
UTMATH :“ UTMATH:通过推理对编码思想进行单位测试的数学评估” [2024-11] [纸]
COCOP :“ COCOP:通过代码完成提示来增强LLM的文本分类” [2024-11] [Paper]
REPL-PLAN :“与大语言模型的交互式和表达的代码启动计划” [2024-11] [Paper]
“大语模型的代码模拟挑战” [2024-01] [纸]
“ Codemind:挑战大型语言模型的代码推理的框架” [2024-02] [Paper]
“用大语言模型执行自然语言算法:调查” [2024-02] [纸]
“语言模型可以假装求解器?使用LLMS逻辑代码仿真” [2024-03] [PAPER]
“通过程序执行的运行时行为评估大型语言模型” [2024-03] [纸]
“下一步:教导大型语言模型以推论代码执行” [2024-04] [ICML 2024] [Paper]
“ SelfPICO:使用LLMS的自我引导的部分代码执行” [2024-07] [Paper]
“作为代码执行者的大型语言模型:探索性研究” [2024-10] [纸]
“可录像带:用精细的多模式链的推理指导代码执行中的大型语言模型” [2024-10] [纸]
自我合作:“通过chatgpt生成自我合作代码” [2023-04] [纸]
Chatdev :“软件开发的交流代理” [2023-07] [Paper] [repo]
METAGPT :“ METAGPT:多代理协作框架的元编程” [2023-08] [Paper] [repo]
CodeChain :“ Codechain:通过具有代表性子模块的自我重复链生成模块化代码” [2023-10] [ICLR 2024] [Paper] [Paper]
代码:“代码:使用工具集成的代理系统来增强代码生成,用于现实世界回复级的编码挑战” [2024-01] [ACL 2024] [Paper]
连接:“连接:通过在线搜索和正确性测试进行复杂的代码生成和完善” [2024-03] [Paper]
LCG :“基于LLM的代码生成符合软件开发过程时” [2024-03] [Paper]
Repairagent :“维修:一种自主,基于LLM的程序维修代理” [2024-03] [Paper]
Magis :: “ MAGIS:基于LLM的GitHub发行的多代理框架” [2024-03] [Paper]
SOA :“自组织的代理:朝着超大规模代码生成和优化的LLM多代理框架” [2024-04] [Paper]
自动编码器:“ AutoCoderover:自主程序改进” [2024-04] [Paper]
SWE-Agent :“ SWE-AGENT:代理 - 计算机接口启用自动软件工程” [2024-05] [Paper]
MAPCODER :“ MapCoder:用于解决竞争问题的多代理代码生成” [2024-05] [ACL 2024] [Paper]
“用火打火:我们可以在源代码相关的任务上信任chatgpt多少?” [2024-05] [纸]
Funcoder :“分裂和构成达成共识:释放代码生成中功能的力量” [2024-05] [纸]
CTC :“通过跨团队协作开发多代理软件” [2024-06] [Paper]
MASAI :“ MASAI:软件工程AI代理的模块化体系结构” [2024-06] [Paper]
AgileCoder :“ AgileCoder:基于敏捷方法的软件开发的动态协作代理” [2024-06] [Paper]
CodeNav : "CodeNav: Beyond tool-use to using real-world codebases with LLM agents" [2024-06] [paper]
INDICT : "INDICT: Code Generation with Internal Dialogues of Critiques for Both Security and Helpfulness" [2024-06] [paper]
AppWorld : "AppWorld: A Controllable World of Apps and People for Benchmarking Interactive Coding Agents" [2024-07] [paper]
CortexCompile : "CortexCompile: Harnessing Cortical-Inspired Architectures for Enhanced Multi-Agent NLP Code Synthesis" [2024-08] [paper]
Survey : "Large Language Model-Based Agents for Software Engineering: A Survey" [2024-09] [paper]
AutoSafeCoder : "AutoSafeCoder: A Multi-Agent Framework for Securing LLM Code Generation through Static Analysis and Fuzz Testing" [2024-09] [paper]
SuperCoder2.0 : "SuperCoder2.0: Technical Report on Exploring the feasibility of LLMs as Autonomous Programmer" [2024-09] [paper]
Survey : "Agents in Software Engineering: Survey, Landscape, and Vision" [2024-09] [paper]
MOSS : "MOSS: Enabling Code-Driven Evolution and Context Management for AI Agents" [2024-09] [paper]
HyperAgent : "HyperAgent: Generalist Software Engineering Agents to Solve Coding Tasks at Scale" [2024-09] [paper]
"Compositional Hardness of Code in Large Language Models -- A Probabilistic Perspective" [2024-09] [paper]
RGD : "RGD: Multi-LLM Based Agent Debugger via Refinement and Generation Guidance" [2024-10] [paper]
AutoML-Agent : "AutoML-Agent: A Multi-Agent LLM Framework for Full-Pipeline AutoML" [2024-10] [paper]
Seeker : "Seeker: Enhancing Exception Handling in Code with LLM-based Multi-Agent Approach" [2024-10] [paper]
REDO : "REDO: Execution-Free Runtime Error Detection for COding Agents" [2024-10] [paper]
"Evaluating Software Development Agents: Patch Patterns, Code Quality, and Issue Complexity in Real-World GitHub Scenarios" [2024-10] [paper]
EvoMAC : "Self-Evolving Multi-Agent Collaboration Networks for Software Development" [2024-10] [paper]
VisionCoder : "VisionCoder: Empowering Multi-Agent Auto-Programming for Image Processing with Hybrid LLMs" [2024-10] [paper]
AutoKaggle : "AutoKaggle: A Multi-Agent Framework for Autonomous Data Science Competitions" [2024-10] [paper]
Watson : "Watson: A Cognitive Observability Framework for the Reasoning of Foundation Model-Powered Agents" [2024-11] [paper]
CodeTree : "CodeTree: Agent-guided Tree Search for Code Generation with Large Language Models" [2024-11] [paper]
EvoCoder : "LLMs as Continuous Learners: Improving the Reproduction of Defective Code in Software Issues" [2024-11] [paper]
"Interactive Program Synthesis" [2017-03] [paper]
"Question selection for interactive program synthesis" [2020-06] [PLDI 2020] [paper]
"Interactive Code Generation via Test-Driven User-Intent Formalization" [2022-08] [paper]
"Improving Code Generation by Training with Natural Language Feedback" [2023-03] [TMLR] [paper]
"Self-Refine: Iterative Refinement with Self-Feedback" [2023-03] [NeurIPS 2023] [paper]
"Teaching Large Language Models to Self-Debug" [2023-04] [paper]
"Self-Edit: Fault-Aware Code Editor for Code Generation" [2023-05] [ACL 2023] [paper]
"LeTI: Learning to Generate from Textual Interactions" [2023-05] [paper]
"Is Self-Repair a Silver Bullet for Code Generation?" [2023-06] [ICLR 2024] [paper]
"InterCode: Standardizing and Benchmarking Interactive Coding with Execution Feedback" [2023-06] [NeurIPS 2023] [paper]
"INTERVENOR: Prompting the Coding Ability of Large Language Models with the Interactive Chain of Repair" [2023-11] [ACL 2024 Findings] [paper]
"OpenCodeInterpreter: Integrating Code Generation with Execution and Refinement" [2024-02] [ACL 2024 Findings] [paper]
"Iterative Refinement of Project-Level Code Context for Precise Code Generation with Compiler Feedback" [2024-03] [ACL 2024 Findings] [paper]
"CYCLE: Learning to Self-Refine the Code Generation" [2024-03] [paper]
"LLM-based Test-driven Interactive Code Generation: User Study and Empirical Evaluation" [2024-04] [paper]
"SOAP: Enhancing Efficiency of Generated Code via Self-Optimization" [2024-05] [paper]
"Code Repair with LLMs gives an Exploration-Exploitation Tradeoff" [2024-05] [paper]
"ReflectionCoder: Learning from Reflection Sequence for Enhanced One-off Code Generation" [2024-05] [paper]
"Training LLMs to Better Self-Debug and Explain Code" [2024-05] [paper]
"Requirements are All You Need: From Requirements to Code with LLMs" [2024-06] [paper]
"I Need Help! Evaluating LLM's Ability to Ask for Users' Support: A Case Study on Text-to-SQL Generation" [2024-07] [paper]
"An Empirical Study on Self-correcting Large Language Models for Data Science Code Generation" [2024-08] [paper]
"RethinkMCTS: Refining Erroneous Thoughts in Monte Carlo Tree Search for Code Generation" [2024-09] [paper]
"From Code to Correctness: Closing the Last Mile of Code Generation with Hierarchical Debugging" [2024-10] [paper] [repo]
"What Makes Large Language Models Reason in (Multi-Turn) Code Generation?" [2024-10] [paper]
"The First Prompt Counts the Most! An Evaluation of Large Language Models on Iterative Example-based Code Generation" [2024-11] [paper]
"Planning-Driven Programming: A Large Language Model Programming Workflow" [2024-11] [paper]
"ConAIR:Consistency-Augmented Iterative Interaction Framework to Enhance the Reliability of Code Generation" [2024-11] [paper]
"MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding" [2021-10] [ACL 2022] [paper]
"WebKE: Knowledge Extraction from Semi-structured Web with Pre-trained Markup Language Model" [2021-10] [CIKM 2021] [paper]
"WebGPT: Browser-assisted question-answering with human feedback" [2021-12] [paper]
"CM3: A Causal Masked Multimodal Model of the Internet" [2022-01] [paper]
"DOM-LM: Learning Generalizable Representations for HTML Documents" [2022-01] [paper]
"WebFormer: The Web-page Transformer for Structure Information Extraction" [2022-02] [WWW 2022] [paper]
"A Dataset for Interactive Vision-Language Navigation with Unknown Command Feasibility" [2022-02] [ECCV 2022] [paper]
"WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents" [2022-07] [NeurIPS 2022] [paper]
"Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding" [2022-10] [ICML 2023] [paper]
"Understanding HTML with Large Language Models" [2022-10] [EMNLP 2023 findings] [paper]
"WebUI: A Dataset for Enhancing Visual UI Understanding with Web Semantics" [2023-01] [CHI 2023] [paper]
"Mind2Web: Towards a Generalist Agent for the Web" [2023-06] [NeurIPS 2023] [paper]
"A Real-World WebAgent with Planning, Long Context Understanding, and Program Synthesis", [2023-07] [ICLR 2024] [paper]
"WebArena: A Realistic Web Environment for Building Autonomous Agents" [2023-07] [paper]
"CogAgent: A Visual Language Model for GUI Agents" [2023-12] [paper]
"GPT-4V(ision) is a Generalist Web Agent, if Grounded" [2024-01] [paper]
"WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models" [2024-01] [paper]
"WebLINX: Real-World Website Navigation with Multi-Turn Dialogue" [2024-02] [paper]
"OmniACT: A Dataset and Benchmark for Enabling Multimodal Generalist Autonomous Agents for Desktop and Web" [2024-02] [paper]
"AutoWebGLM: Bootstrap And Reinforce A Large Language Model-based Web Navigating Agent" [2024-04] [paper]
"WILBUR: Adaptive In-Context Learning for Robust and Accurate Web Agents" [2024-04] [paper]
"AutoCrawler: A Progressive Understanding Web Agent for Web Crawler Generation" [2024-04] [paper]
"GUICourse: From General Vision Language Models to Versatile GUI Agents" [2024-06] [paper]
"NaviQAte: Functionality-Guided Web Application Navigation" [2024-09] [paper]
"MobileVLM: A Vision-Language Model for Better Intra- and Inter-UI Understanding" [2024-09] [paper]
"Multimodal Auto Validation For Self-Refinement in Web Agents" [2024-10] [paper]
"Navigating the Digital World as Humans Do: Universal Visual Grounding for GUI Agents" [2024-10] [paper]
"Web Agents with World Models: Learning and Leveraging Environment Dynamics in Web Navigation" [2024-10] [paper]
"Harnessing Webpage UIs for Text-Rich Visual Understanding" [2024-10] [paper]
"AgentOccam: A Simple Yet Strong Baseline for LLM-Based Web Agents" [2024-10] [paper]
"Beyond Browsing: API-Based Web Agents" [2024-10] [paper]
"Large Language Models Empowered Personalized Web Agents" [2024-10] [paper]
"AdvWeb: Controllable Black-box Attacks on VLM-powered Web Agents" [2024-10] [paper]
"Auto-Intent: Automated Intent Discovery and Self-Exploration for Large Language Model Web Agents" [2024-10] [paper]
"OS-ATLAS: A Foundation Action Model for Generalist GUI Agents" [2024-10] [paper]
"From Context to Action: Analysis of the Impact of State Representation and Context on the Generalization of Multi-Turn Web Navigation Agents" [2024-10] [paper]
"AutoGLM: Autonomous Foundation Agents for GUIs" [2024-10] [paper]
"WebRL: Training LLM Web Agents via Self-Evolving Online Curriculum Reinforcement Learning" [2024-11] [paper]
"The Dawn of GUI Agent: A Preliminary Case Study with Claude 3.5 Computer Use" [2024-11] [paper]
"ScribeAgent: Towards Specialized Web Agents Using Production-Scale Workflow Data" [2024-11] [paper]
"ShowUI: One Vision-Language-Action Model for GUI Visual Agent" [2024-11] [paper]
[ Ruby ] "On the Transferability of Pre-trained Language Models for Low-Resource Programming Languages" [2022-04] [ICPC 2022] [paper]
[ Verilog ] "Benchmarking Large Language Models for Automated Verilog RTL Code Generation" [2022-12] [DATE 2023] [paper]
[ OCL ] "On Codex Prompt Engineering for OCL Generation: An Empirical Study" [2023-03] [MSR 2023] [paper]
[ Ansible-YAML ] "Automated Code generation for Information Technology Tasks in YAML through Large Language Models" [2023-05] [DAC 2023] [paper]
[ Hansl ] "The potential of LLMs for coding with low-resource and domain-specific programming languages" [2023-07] [paper]
[ Verilog ] "VeriGen: A Large Language Model for Verilog Code Generation" [2023-07] [paper]
[ Verilog ] "RTLLM: An Open-Source Benchmark for Design RTL Generation with Large Language Model" [2023-08] [paper]
[ Racket, OCaml, Lua, R, Julia ] "Knowledge Transfer from High-Resource to Low-Resource Programming Languages for Code LLMs" [2023-08] [paper]
[ Verilog ] "VerilogEval: Evaluating Large Language Models for Verilog Code Generation" [2023-09] [ICCAD 2023] [paper]
[ Verilog ] "RTLFixer: Automatically Fixing RTL Syntax Errors with Large Language Models" [2023-11] [paper]
[ Verilog ] "Advanced Large Language Model (LLM)-Driven Verilog Development: Enhancing Power, Performance, and Area Optimization in Code Synthesis" [2023-12] [paper]
[ Verilog ] "RTLCoder: Outperforming GPT-3.5 in Design RTL Generation with Our Open-Source Dataset and Lightweight Solution" [2023-12] [paper]
[ Verilog ] "BetterV: Controlled Verilog Generation with Discriminative Guidance" [2024-02] [ICML 2024] [paper]
[ R ] "Empirical Studies of Parameter Efficient Methods for Large Language Models of Code and Knowledge Transfer to R" [2024-03] [paper]
[ Haskell ] "Investigating the Performance of Language Models for Completing Code in Functional Programming Languages: a Haskell Case Study" [2024-03] [paper]
[ Verilog ] "A Multi-Expert Large Language Model Architecture for Verilog Code Generation" [2024-04] [paper]
[ Verilog ] "CreativEval: Evaluating Creativity of LLM-Based Hardware Code Generation" [2024-04] [paper]
[ Alloy ] "An Empirical Evaluation of Pre-trained Large Language Models for Repairing Declarative Formal Specifications" [2024-04] [paper]
[ Verilog ] "Evaluating LLMs for Hardware Design and Test" [2024-04] [paper]
[ Kotlin, Swift, and Rust ] "Software Vulnerability Prediction in Low-Resource Languages: An Empirical Study of CodeBERT and ChatGPT" [2024-04] [paper]
[ Verilog ] "MEIC: Re-thinking RTL Debug Automation using LLMs" [2024-05] [paper]
[ Bash ] "Tackling Execution-Based Evaluation for NL2Bash" [2024-05] [paper]
[ Fortran, Julia, Matlab, R, Rust ] "Evaluating AI-generated code for C++, Fortran, Go, Java, Julia, Matlab, Python, R, and Rust" [2024-05] [paper]
[ OpenAPI ] "Optimizing Large Language Models for OpenAPI Code Completion" [2024-05] [paper]
[ Kotlin ] "Kotlin ML Pack: Technical Report" [2024-05] [paper]
[ Verilog ] "VerilogReader: LLM-Aided Hardware Test Generation" [2024-06] [paper]
"Benchmarking Generative Models on Computational Thinking Tests in Elementary Visual Programming" [2024-06] [paper]
[ Logo ] "Program Synthesis Benchmark for Visual Programming in XLogoOnline Environment" [2024-06] [paper]
[ Ansible YAML, Bash ] "DocCGen: Document-based Controlled Code Generation" [2024-06] [paper]
[ Qiskit ] "Qiskit HumanEval: An Evaluation Benchmark For Quantum Code Generative Models" [2024-06] [paper]
[ Perl, Golang, Swift ] "DistiLRR: Transferring Code Repair for Low-Resource Programming Languages" [2024-06] [paper]
[ Verilog ] "AssertionBench: A Benchmark to Evaluate Large-Language Models for Assertion Generation" [2024-06] [paper]
"A Comparative Study of DSL Code Generation: Fine-Tuning vs. Optimized Retrieval Augmentation" [2024-07] [paper]
[ Json, XLM, YAML ] "ConCodeEval: Evaluating Large Language Models for Code Constraints in Domain-Specific Languages" [2024-07] [paper]
[ Verilog ] "AutoBench: Automatic Testbench Generation and Evaluation Using LLMs for HDL Design" [2024-07] [paper]
[ Verilog ] "CodeV: Empowering LLMs for Verilog Generation through Multi-Level Summarization" [2024-07] [paper]
[ Verilog ] "ITERTL: An Iterative Framework for Fine-tuning LLMs for RTL Code Generation" [2024-07] [paper]
[ Verilog ] "OriGen:Enhancing RTL Code Generation with Code-to-Code Augmentation and Self-Reflection" [2024-07] [paper]
[ Verilog ] "Large Language Model for Verilog Generation with Golden Code Feedback" [2024-07] [paper]
[ Verilog ] "AutoVCoder: A Systematic Framework for Automated Verilog Code Generation using LLMs" [2024-07] [paper]
[ RPA ] "Plan with Code: Comparing approaches for robust NL to DSL generation" [2024-08] [paper]
[ Verilog ] "VerilogCoder: Autonomous Verilog Coding Agents with Graph-based Planning and Abstract Syntax Tree (AST)-based Waveform Tracing Tool" [2024-08] [paper]
[ Verilog ] "Revisiting VerilogEval: Newer LLMs, In-Context Learning, and Specification-to-RTL Tasks" [2024-08] [paper]
[ MaxMSP, Web Audio ] "Benchmarking LLM Code Generation for Audio Programming with Visual Dataflow Languages" [2024-09] [paper]
[ Verilog ] "RTLRewriter: Methodologies for Large Models aided RTL Code Optimization" [2024-09] [paper]
[ Verilog ] "CraftRTL: High-quality Synthetic Data Generation for Verilog Code Models with Correct-by-Construction Non-Textual Representations and Targeted Code Repair" [2024-09] [paper]
[ Bash ] "ScriptSmith: A Unified LLM Framework for Enhancing IT Operations via Automated Bash Script Generation, Assessment, and Refinement" [2024-09] [paper]
[ Survey ] "Survey on Code Generation for Low resource and Domain Specific Programming Languages" [2024-10] [paper]
[ R ] "Do Current Language Models Support Code Intelligence for R Programming Language?" [2024-10] [paper]
"Can Large Language Models Generate Geospatial Code?" [2024-10] [paper]
[ PLC ] "Agents4PLC: Automating Closed-loop PLC Code Generation and Verification in Industrial Control Systems using LLM-based Agents" [2024-10] [paper]
[ Lua ] "Evaluating Quantized Large Language Models for Code Generation on Low-Resource Language Benchmarks" [2024-10] [paper]
"Improving Parallel Program Performance Through DSL-Driven Code Generation with LLM Optimizers" [2024-10] [paper]
"GeoCode-GPT: A Large Language Model for Geospatial Code Generation Tasks" [2024-10] [paper]
[ R, D, Racket, Bash ]: "Bridge-Coder: Unlocking LLMs' Potential to Overcome Language Gaps in Low-Resource Code" [2024-10] [paper]
[ SPICE ]: "SPICEPilot: Navigating SPICE Code Generation and Simulation with AI Guidance" [2024-10] [paper]
[ IEC 61131-3 ST ]: "Training LLMs for Generating IEC 61131-3 Structured Text with Online Feedback" [2024-10] [paper]
[ Verilog ] "MetRex: A Benchmark for Verilog Code Metric Reasoning Using LLMs" [2024-11] [paper]
[ Verilog ] "CorrectBench: Automatic Testbench Generation with Functional Self-Correction using LLMs for HDL Design" [2024-11] [paper]
[ MUMPS, ALC ] "Leveraging LLMs for Legacy Code Modernization: Challenges and Opportunities for LLM-Generated Documentation" [2024-11] [paper]
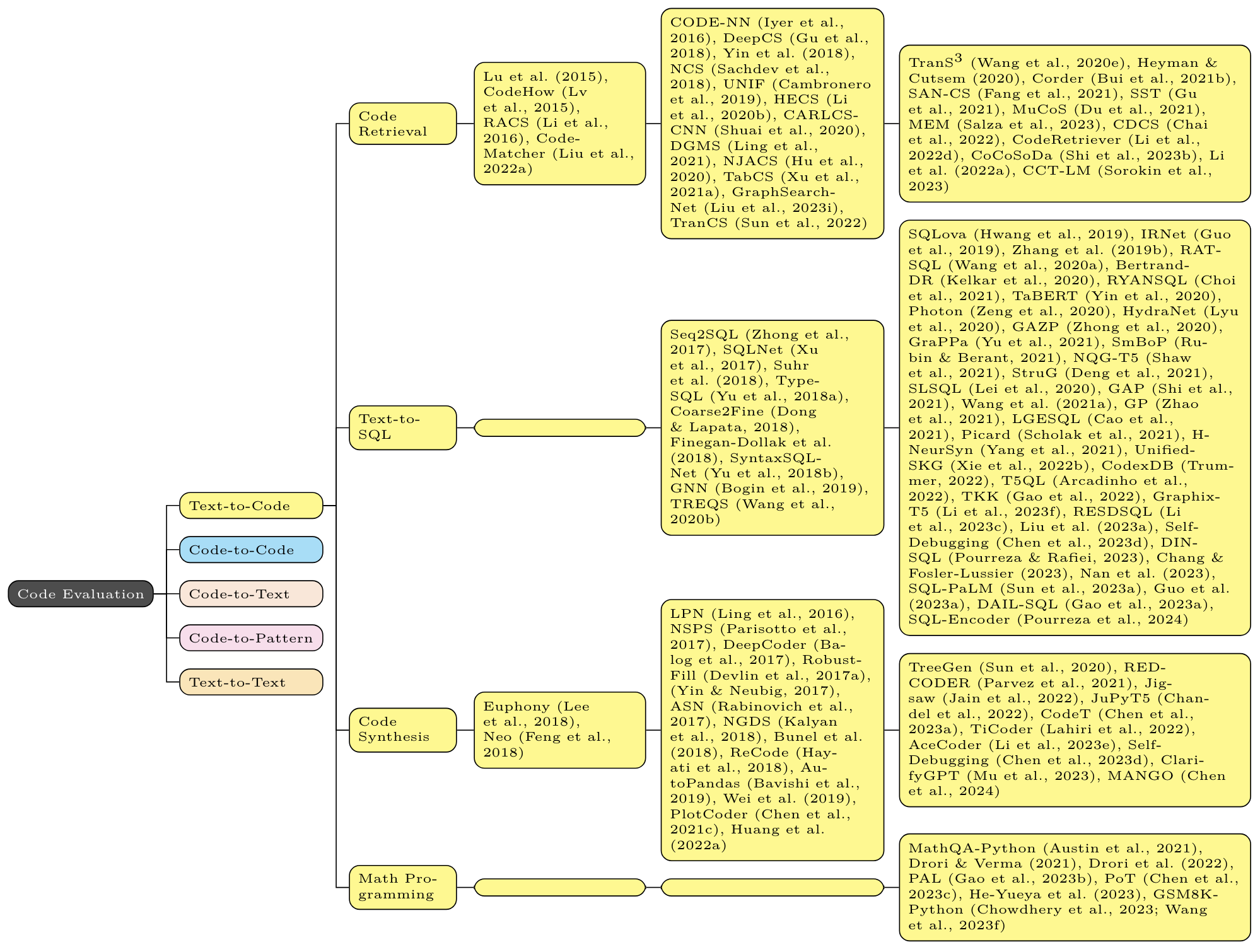
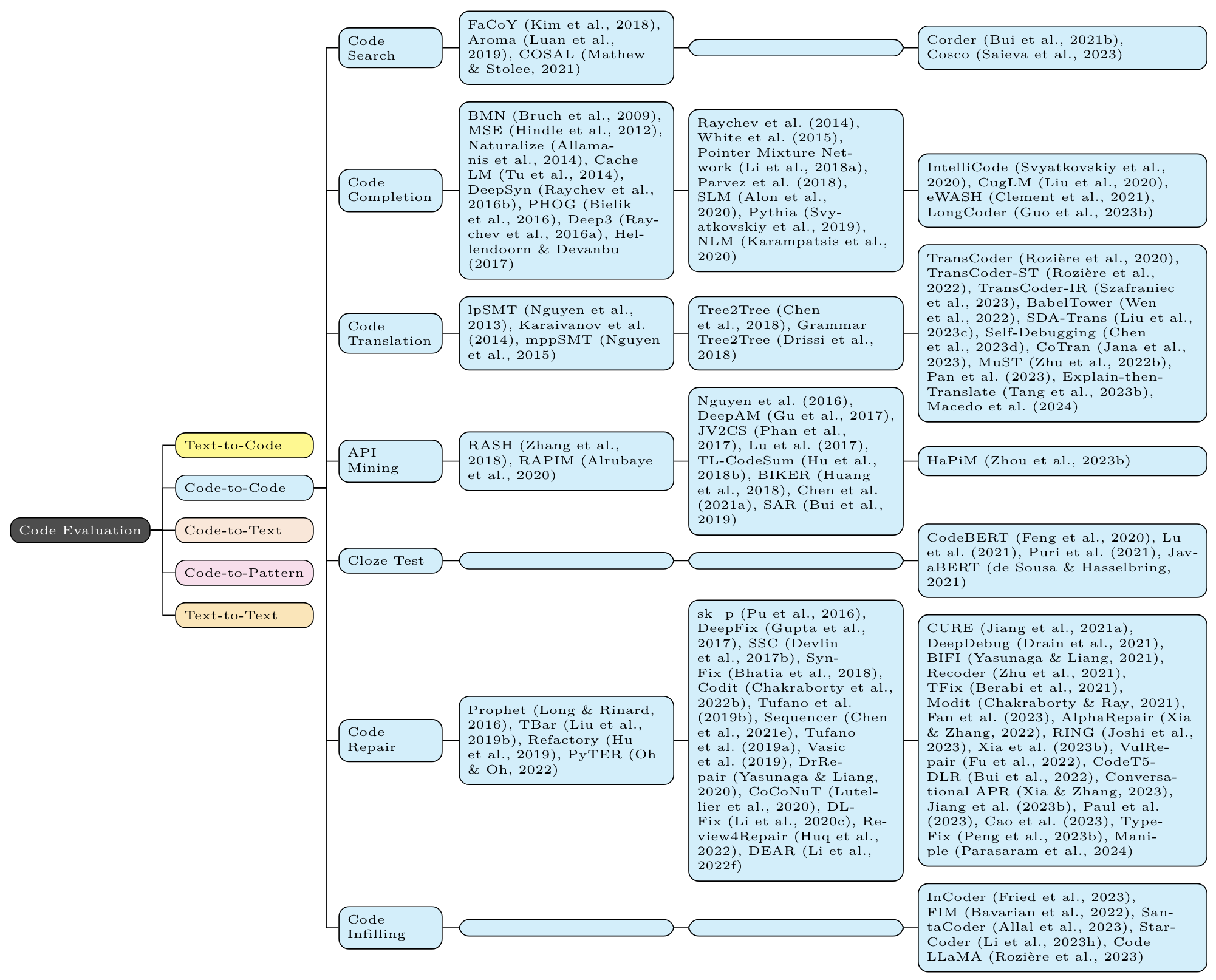
For each task, the first column contains non-neural methods (eg n-gram, TF-IDF, and (occasionally) static program analysis); the second column contains non-Transformer neural methods (eg LSTM, CNN, GNN); the third column contains Transformer based methods (eg BERT, GPT, T5).
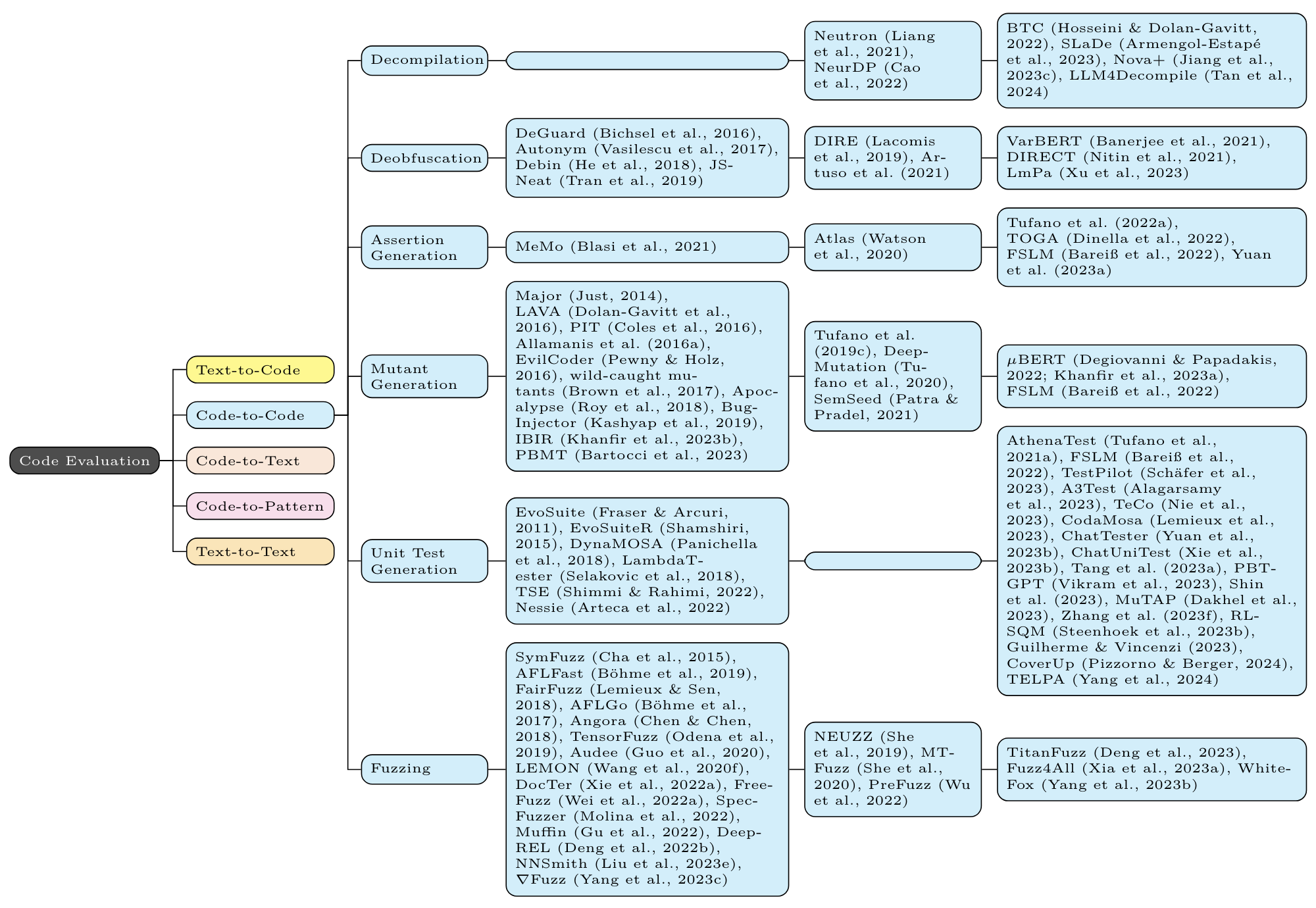
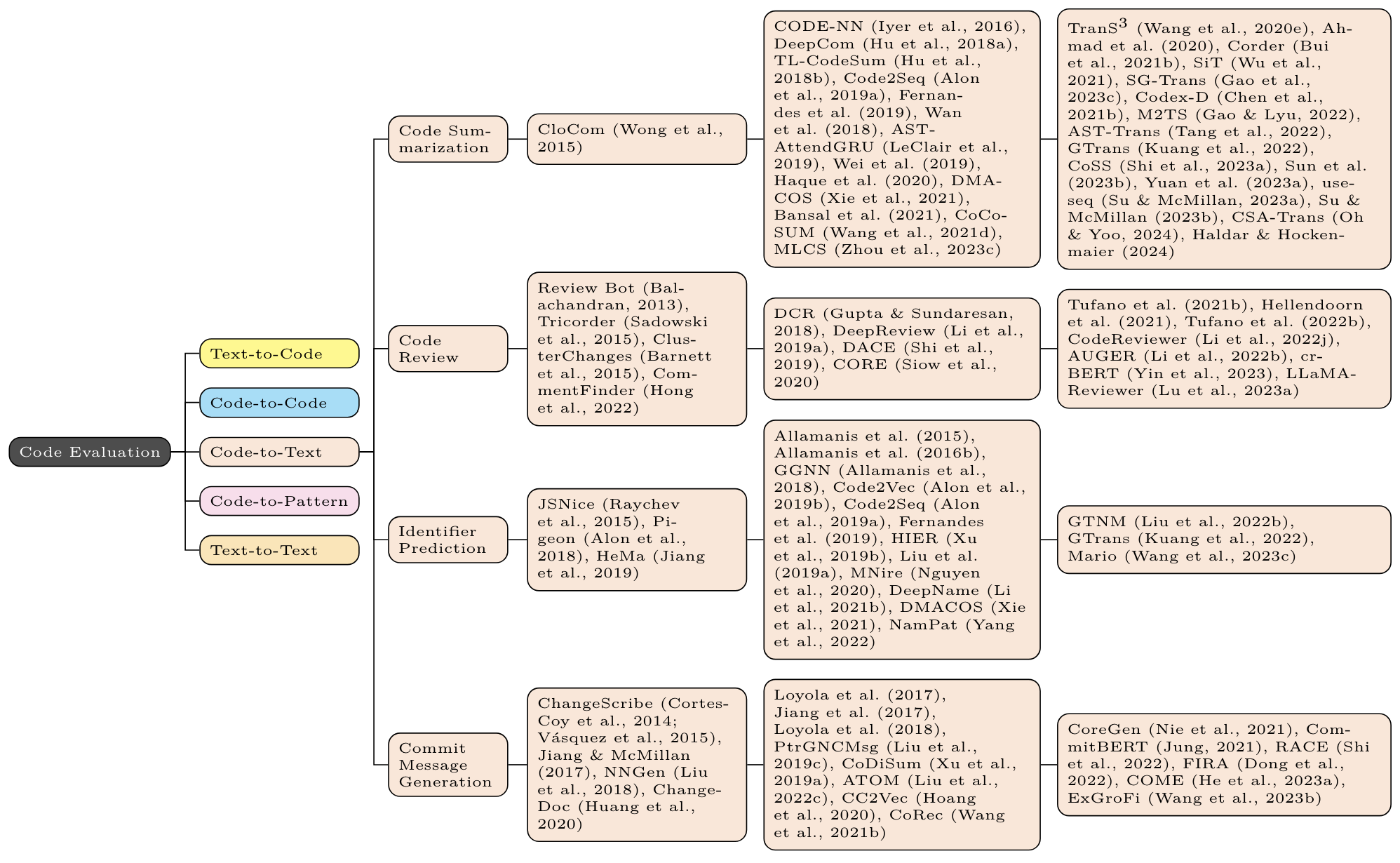
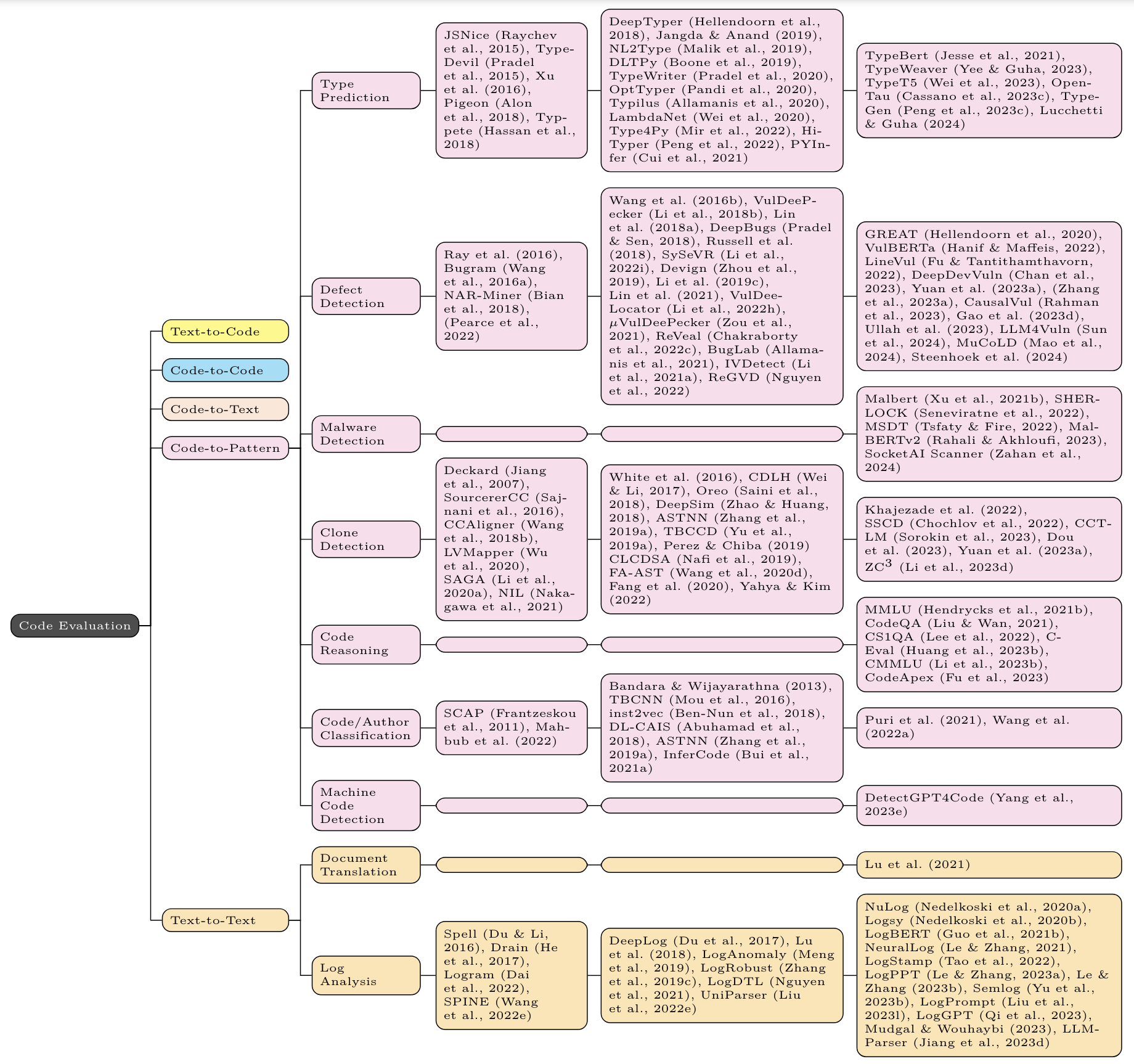
"Enhancing Large Language Models in Coding Through Multi-Perspective Self-Consistency" [2023-09] [ACL 2024] [paper]
"Self-Infilling Code Generation" [2023-11] [ICML 2024] [paper]
"JumpCoder: Go Beyond Autoregressive Coder via Online Modification" [2024-01] [ACL 2024] [paper]
"Unsupervised Evaluation of Code LLMs with Round-Trip Correctness" [2024-02] [ICML 2024] [paper]
"The Larger the Better? Improved LLM Code-Generation via Budget Reallocation" [2024-03] [paper]
"Quantifying Contamination in Evaluating Code Generation Capabilities of Language Models" [2024-03] [ACL 2024] [paper]
"Comments as Natural Logic Pivots: Improve Code Generation via Comment Perspective" [2024-04] [ACL 2024 Findings] [paper]
"Distilling Algorithmic Reasoning from LLMs via Explaining Solution Programs" [2024-04] [paper]
"Quality Assessment of Prompts Used in Code Generation" [2024-04] [paper]
"Assessing GPT-4-Vision's Capabilities in UML-Based Code Generation" [2024-04] [paper]
"Large Language Models Synergize with Automated Machine Learning" [2024-05] [paper]
"Model Cascading for Code: Reducing Inference Costs with Model Cascading for LLM Based Code Generation" [2024-05] [paper]
"A Survey on Large Language Models for Code Generation" [2024-06] [paper]
"Is Programming by Example solved by LLMs?" [2024-06] [paper]
"Benchmarks and Metrics for Evaluations of Code Generation: A Critical Review" [2024-06] [paper]
"MPCODER: Multi-user Personalized Code Generator with Explicit and Implicit Style Representation Learning" [2024-06] [ACL 2024] [paper]
"Revisiting the Impact of Pursuing Modularity for Code Generation" [2024-07] [paper]
"Evaluating Long Range Dependency Handling in Code Generation Models using Multi-Step Key Retrieval" [2024-07] [paper]
"When to Stop? Towards Efficient Code Generation in LLMs with Excess Token Prevention" [2024-07] [paper]
"Assessing Programming Task Difficulty for Efficient Evaluation of Large Language Models" [2024-07] [paper]
"ArchCode: Incorporating Software Requirements in Code Generation with Large Language Models" [2024-08] [ACL 2024] [paper]
"Fine-tuning Language Models for Joint Rewriting and Completion of Code with Potential Bugs" [2024-08] [ACL 2024 Findings] [paper]
"Selective Prompt Anchoring for Code Generation" [2024-08] [paper]
"Bridging the Language Gap: Enhancing Multilingual Prompt-Based Code Generation in LLMs via Zero-Shot Cross-Lingual Transfer" [2024-08] [paper]
"Optimizing Large Language Model Hyperparameters for Code Generation" [2024-08] [paper]
"EPiC: Cost-effective Search-based Prompt Engineering of LLMs for Code Generation" [2024-08] [paper]
"CodeRefine: A Pipeline for Enhancing LLM-Generated Code Implementations of Research Papers" [2024-08] [paper]
"No Man is an Island: Towards Fully Automatic Programming by Code Search, Code Generation and Program Repair" [2024-09] [paper]
"Planning In Natural Language Improves LLM Search For Code Generation" [2024-09] [paper]
"Multi-Programming Language Ensemble for Code Generation in Large Language Model" [2024-09] [paper]
"A Pair Programming Framework for Code Generation via Multi-Plan Exploration and Feedback-Driven Refinement" [2024-09] [paper]
"USCD: Improving Code Generation of LLMs by Uncertainty-Aware Selective Contrastive Decoding" [2024-09] [paper]
"Eliciting Instruction-tuned Code Language Models' Capabilities to Utilize Auxiliary Function for Code Generation" [2024-09] [paper]
"Selection of Prompt Engineering Techniques for Code Generation through Predicting Code Complexity" [2024-09] [paper]
"Horizon-Length Prediction: Advancing Fill-in-the-Middle Capabilities for Code Generation with Lookahead Planning" [2024-10] [paper]
"Showing LLM-Generated Code Selectively Based on Confidence of LLMs" [2024-10] [paper]
"AutoFeedback: An LLM-based Framework for Efficient and Accurate API Request Generation" [2024-10] [paper]
"Enhancing LLM Agents for Code Generation with Possibility and Pass-rate Prioritized Experience Replay" [2024-10] [paper]
"From Solitary Directives to Interactive Encouragement! LLM Secure Code Generation by Natural Language Prompting" [2024-10] [paper]
"Self-Explained Keywords Empower Large Language Models for Code Generation" [2024-10] [paper]
"Context-Augmented Code Generation Using Programming Knowledge Graphs" [2024-10] [paper]
"In-Context Code-Text Learning for Bimodal Software Engineering" [2024-10] [paper]
"Combining LLM Code Generation with Formal Specifications and Reactive Program Synthesis" [2024-10] [paper]
"Less is More: DocString Compression in Code Generation" [2024-10] [paper]
"Multi-Programming Language Sandbox for LLMs" [2024-10] [paper]
"Personality-Guided Code Generation Using Large Language Models" [2024-10] [paper]
"Do Advanced Language Models Eliminate the Need for Prompt Engineering in Software Engineering?" [2024-11] [paper]
"Scattered Forest Search: Smarter Code Space Exploration with LLMs" [2024-11] [paper]
"Anchor Attention, Small Cache: Code Generation with Large Language Models" [2024-11] [paper]
"ROCODE: Integrating Backtracking Mechanism and Program Analysis in Large Language Models for Code Generation" [2024-11] [paper]
"SRA-MCTS: Self-driven Reasoning Aurmentation with Monte Carlo Tree Search for Enhanced Code Generation" [2024-11] [paper]
"CodeGRAG: Extracting Composed Syntax Graphs for Retrieval Augmented Cross-Lingual Code Generation" [2024-05] [paper]
"Prompt-based Code Completion via Multi-Retrieval Augmented Generation" [2024-05] [paper]
"A Lightweight Framework for Adaptive Retrieval In Code Completion With Critique Model" [2024-06] [papaer]
"Preference-Guided Refactored Tuning for Retrieval Augmented Code Generation" [2024-09] [paper]
"Building A Coding Assistant via the Retrieval-Augmented Language Model" [2024-10] [paper]
"DroidCoder: Enhanced Android Code Completion with Context-Enriched Retrieval-Augmented Generation" [2024-10] [ASE 2024] [paper]
"Assessing the Answerability of Queries in Retrieval-Augmented Code Generation" [2024-11] [paper]
"Fault-Aware Neural Code Rankers" [2022-06] [NeurIPS 2022] [paper]
"Functional Overlap Reranking for Neural Code Generation" [2023-10] [ACL 2024 Findings] [paper]
"Top Pass: Improve Code Generation by Pass@k-Maximized Code Ranking" [2024-08] [paper]
"DOCE: Finding the Sweet Spot for Execution-Based Code Generation" [2024-08] [paper]
"Sifting through the Chaff: On Utilizing Execution Feedback for Ranking the Generated Code Candidates" [2024-08] [paper]
"B4: Towards Optimal Assessment of Plausible Code Solutions with Plausible Tests" [2024-09] [paper]
"Learning Code Preference via Synthetic Evolution" [2024-10] [paper]
"Tree-to-tree Neural Networks for Program Translation" [2018-02] [NeurIPS 2018] [paper]
"Program Language Translation Using a Grammar-Driven Tree-to-Tree Model" [2018-07] [paper]
"Unsupervised Translation of Programming Languages" [2020-06] [NeurIPS 2020] [paper]
"Leveraging Automated Unit Tests for Unsupervised Code Translation" [2021-10] [ICLR 2022] paper]
"Code Translation with Compiler Representations" [2022-06] [ICLR 2023] [paper]
"Multilingual Code Snippets Training for Program Translation" [2022-06] [AAAI 2022] [paper]
"BabelTower: Learning to Auto-parallelized Program Translation" [2022-07] [ICML 2022] [paper]
"Syntax and Domain Aware Model for Unsupervised Program Translation" [2023-02] [ICSE 2023] [paper]
"CoTran: An LLM-based Code Translator using Reinforcement Learning with Feedback from Compiler and Symbolic Execution" [2023-06] [paper]
"Lost in Translation: A Study of Bugs Introduced by Large Language Models while Translating Code" [2023-08] [ICSE 2024] [paper]
"On the Evaluation of Neural Code Translation: Taxonomy and Benchmark", 2023-08, ASE 2023, [paper]
"Program Translation via Code Distillation" [2023-10] [EMNLP 2023] [paper]
"Explain-then-Translate: An Analysis on Improving Program Translation with Self-generated Explanations" [2023-11] [EMNLP 2023 Findings] [paper]
"Exploring the Impact of the Output Format on the Evaluation of Large Language Models for Code Translation" [2024-03] [paper]
"Exploring and Unleashing the Power of Large Language Models in Automated Code Translation" [2024-04] [paper]
"VERT: Verified Equivalent Rust Transpilation with Few-Shot Learning" [2024-04] [paper]
"Towards Translating Real-World Code with LLMs: A Study of Translating to Rust" [2024-05] [paper]
"An interpretable error correction method for enhancing code-to-code translation" [2024-05] [ICLR 2024] [paper]
"LASSI: An LLM-based Automated Self-Correcting Pipeline for Translating Parallel Scientific Codes" [2024-06] [paper]
"Rectifier: Code Translation with Corrector via LLMs" [2024-07] [paper]
"Enhancing Code Translation in Language Models with Few-Shot Learning via Retrieval-Augmented Generation" [2024-07] [paper]
"A Joint Learning Model with Variational Interaction for Multilingual Program Translation" [2024-08] [paper]
"Automatic Library Migration Using Large Language Models: First Results" [2024-08] [paper]
"Context-aware Code Segmentation for C-to-Rust Translation using Large Language Models" [2024-09] [paper]
"TRANSAGENT: An LLM-Based Multi-Agent System for Code Translation" [2024-10] [paper]
"Unraveling the Potential of Large Language Models in Code Translation: How Far Are We?" [2024-10] [paper]
"CodeRosetta: Pushing the Boundaries of Unsupervised Code Translation for Parallel Programming" [2024-10] [paper]
"A test-free semantic mistakes localization framework in Neural Code Translation" [2024-10] [paper]
"Repository-Level Compositional Code Translation and Validation" [2024-10] [paper]
"Leveraging Large Language Models for Code Translation and Software Development in Scientific Computing" [2024-10] [paper]
"InterTrans: Leveraging Transitive Intermediate Translations to Enhance LLM-based Code Translation" [2024-11] [paper]
"Translating C To Rust: Lessons from a User Study" [2024-11] [paper]
"A Transformer-based Approach for Source Code Summarization" [2020-05] [ACL 2020] [paper]
"Code Summarization with Structure-induced Transformer" [2020-12] [ACL 2021 Findings] [paper]
"Code Structure Guided Transformer for Source Code Summarization" [2021-04] [ACM TSEM] [paper]
"M2TS: Multi-Scale Multi-Modal Approach Based on Transformer for Source Code Summarization" [2022-03] [ICPC 2022] [paper]
"AST-trans: code summarization with efficient tree-structured attention" [2022-05] [ICSE 2022] [paper]
"CoSS: Leveraging Statement Semantics for Code Summarization" [2023-03] [IEEE TSE] [paper]
"Automatic Code Summarization via ChatGPT: How Far Are We?" [2023-05] [paper]
"Semantic Similarity Loss for Neural Source Code Summarization" [2023-08] [paper]
"Distilled GPT for Source Code Summarization" [2023-08] [ASE] [paper]
"CSA-Trans: Code Structure Aware Transformer for AST" [2024-04] [paper]
"Analyzing the Performance of Large Language Models on Code Summarization" [2024-04] [paper]
"Enhancing Trust in LLM-Generated Code Summaries with Calibrated Confidence Scores" [2024-04] [paper]
"DocuMint: Docstring Generation for Python using Small Language Models" [2024-05] [paper] [repo]
"Natural Is The Best: Model-Agnostic Code Simplification for Pre-trained Large Language Models" [2024-05] [paper]
"Large Language Models for Code Summarization" [2024-05] [paper]
"Exploring the Efficacy of Large Language Models (GPT-4) in Binary Reverse Engineering" [2024-06] [paper]
"Identifying Inaccurate Descriptions in LLM-generated Code Comments via Test Execution" [2024-06] [paper]
"MALSIGHT: Exploring Malicious Source Code and Benign Pseudocode for Iterative Binary Malware Summarization" [2024-06] [paper]
"ESALE: Enhancing Code-Summary Alignment Learning for Source Code Summarization" [2024-07] [paper]
"Source Code Summarization in the Era of Large Language Models" [2024-07] [paper]
"Natural Language Outlines for Code: Literate Programming in the LLM Era" [2024-08] [paper]
"Context-aware Code Summary Generation" [2024-08] [paper]
"AUTOGENICS: Automated Generation of Context-Aware Inline Comments for Code Snippets on Programming Q&A Sites Using LLM" [2024-08] [paper]
"LLMs as Evaluators: A Novel Approach to Evaluate Bug Report Summarization" [2024-09] [paper]
"Evaluating the Quality of Code Comments Generated by Large Language Models for Novice Programmers" [2024-09] [paper]
"Generating Equivalent Representations of Code By A Self-Reflection Approach" [2024-10] [paper]
"A review of automatic source code summarization" [2024-10] [Empirical Software Engineering] [paper]
"DeepDebug: Fixing Python Bugs Using Stack Traces, Backtranslation, and Code Skeletons" [2021-05] [paper]
"Break-It-Fix-It: Unsupervised Learning for Program Repair" [2021-06] [ICML 2021] [paper]
"TFix: Learning to Fix Coding Errors with a Text-to-Text Transformer" [2021-07] [ICML 2021] [paper]
"Automated Repair of Programs from Large Language Models" [2022-05] [ICSE 2023] [paper]
"Less Training, More Repairing Please: Revisiting Automated Program Repair via Zero-shot Learning" [2022-07] [ESEC/FSE 2022] [paper]
"Repair Is Nearly Generation: Multilingual Program Repair with LLMs" [2022-08] [AAAI 2023] [paper]
"Practical Program Repair in the Era of Large Pre-trained Language Models" [2022-10] [paper]
"VulRepair: a T5-based automated software vulnerability repair" [2022-11] [ESEC/FSE 2022] [paper]
"Conversational Automated Program Repair" [2023-01] [paper]
"Impact of Code Language Models on Automated Program Repair" [2023-02] [ICSE 2023] [paper]
"InferFix: End-to-End Program Repair with LLMs" [2023-03] [ESEC/FSE 2023] [paper]
"Enhancing Automated Program Repair through Fine-tuning and Prompt Engineering" [2023-04] [paper]
"A study on Prompt Design, Advantages and Limitations of ChatGPT for Deep Learning Program Repair" [2023-04] [paper]
"Domain Knowledge Matters: Improving Prompts with Fix Templates for Repairing Python Type Errors" [2023-06] [ICSE 2024] [paper]
"RepairLLaMA: Efficient Representations and Fine-Tuned Adapters for Program Repair" [2023-12] [paper]
"The Fact Selection Problem in LLM-Based Program Repair" [2024-04] [paper]
"Aligning LLMs for FL-free Program Repair" [2024-04] [paper]
"A Deep Dive into Large Language Models for Automated Bug Localization and Repair" [2024-04] [paper]
"Multi-Objective Fine-Tuning for Enhanced Program Repair with LLMs" [2024-04] [paper]
"How Far Can We Go with Practical Function-Level Program Repair?" [2024-04] [paper]
"Revisiting Unnaturalness for Automated Program Repair in the Era of Large Language Models" [2024-04] [paper]
"A Unified Debugging Approach via LLM-Based Multi-Agent Synergy" [2024-04] [paper]
"A Systematic Literature Review on Large Language Models for Automated Program Repair" [2024-05] [paper]
"NAVRepair: Node-type Aware C/C++ Code Vulnerability Repair" [2024-05] [paper]
"Automated Program Repair: Emerging trends pose and expose problems for benchmarks" [2024-05] [paper]
"Automated Repair of AI Code with Large Language Models and Formal Verification" [2024-05] [paper]
"A Case Study of LLM for Automated Vulnerability Repair: Assessing Impact of Reasoning and Patch Validation Feedback" [2024-05] [paper]
"CREF: An LLM-based Conversational Software Repair Framework for Programming Tutors" [2024-06] [paper]
"Towards Practical and Useful Automated Program Repair for Debugging" [2024-07] [paper]
"ThinkRepair: Self-Directed Automated Program Repair" [2024-07] [paper]
"MergeRepair: An Exploratory Study on Merging Task-Specific Adapters in Code LLMs for Automated Program Repair" [2024-08] [paper]
"RePair: Automated Program Repair with Process-based Feedback" [2024-08] [ACL 2024 Findings] [paper]
"Enhancing LLM-Based Automated Program Repair with Design Rationales" [2024-08] [paper]
"Automated Software Vulnerability Patching using Large Language Models" [2024-08] [paper]
"Enhancing Source Code Security with LLMs: Demystifying The Challenges and Generating Reliable Repairs" [2024-09] [paper]
"MarsCode Agent: AI-native Automated Bug Fixing" [2024-09] [paper]
"Co-Learning: Code Learning for Multi-Agent Reinforcement Collaborative Framework with Conversational Natural Language Interfaces" [2024-09] [paper]
"Debugging with Open-Source Large Language Models: An Evaluation" [2024-09] [paper]
"VulnLLMEval: A Framework for Evaluating Large Language Models in Software Vulnerability Detection and Patching" [2024-09] [paper]
"ContractTinker: LLM-Empowered Vulnerability Repair for Real-World Smart Contracts" [2024-09] [paper]
"Can GPT-O1 Kill All Bugs? An Evaluation of GPT-Family LLMs on QuixBugs" [2024-09] [paper]
"Exploring and Lifting the Robustness of LLM-powered Automated Program Repair with Metamorphic Testing" [2024-10] [paper]
"LecPrompt: A Prompt-based Approach for Logical Error Correction with CodeBERT" [2024-10] [paper]
"Semantic-guided Search for Efficient Program Repair with Large Language Models" [2024-10] [paper]
"A Comprehensive Survey of AI-Driven Advancements and Techniques in Automated Program Repair and Code Generation" [2024-11] [paper]
"Self-Supervised Contrastive Learning for Code Retrieval and Summarization via Semantic-Preserving Transformations" [2020-09] [SIGIR 2021] [paper]
"REINFOREST: Reinforcing Semantic Code Similarity for Cross-Lingual Code Search Models" [2023-05] [paper]
"Rewriting the Code: A Simple Method for Large Language Model Augmented Code Search" [2024-01] [ACL 2024] [paper]
"Revisiting Code Similarity Evaluation with Abstract Syntax Tree Edit Distance" [2024-04] [ACL 2024 short] [paper]
"Is Next Token Prediction Sufficient for GPT? Exploration on Code Logic Comprehension" [2024-04] [paper]
"Refining Joint Text and Source Code Embeddings for Retrieval Task with Parameter-Efficient Fine-Tuning" [2024-05] [paper]
"Typhon: Automatic Recommendation of Relevant Code Cells in Jupyter Notebooks" [2024-05] [paper]
"Toward Exploring the Code Understanding Capabilities of Pre-trained Code Generation Models" [2024-06] [paper]
"Aligning Programming Language and Natural Language: Exploring Design Choices in Multi-Modal Transformer-Based Embedding for Bug Localization" [2024-06] [paper]
"Assessing the Code Clone Detection Capability of Large Language Models" [2024-07] [paper]
"CodeCSE: A Simple Multilingual Model for Code and Comment Sentence Embeddings" [2024-07] [paper]
"Large Language Models for cross-language code clone detection" [2024-08] [paper]
"Coding-PTMs: How to Find Optimal Code Pre-trained Models for Code Embedding in Vulnerability Detection?" [2024-08] [paper]
"You Augment Me: Exploring ChatGPT-based Data Augmentation for Semantic Code Search" [2024-08] [paper]
"Improving Source Code Similarity Detection Through GraphCodeBERT and Integration of Additional Features" [2024-08] [paper]
"LLM Agents Improve Semantic Code Search" [2024-08] [paper]
"zsLLMCode: An Effective Approach for Functional Code Embedding via LLM with Zero-Shot Learning" [2024-09] [paper]
"Exploring Demonstration Retrievers in RAG for Coding Tasks: Yeas and Nays!" [2024-10] [paper]
"Instructive Code Retriever: Learn from Large Language Model's Feedback for Code Intelligence Tasks" [2024-10] [paper]
"Binary Code Similarity Detection via Graph Contrastive Learning on Intermediate Representations" [2024-10] [paper]
"Are Decoder-Only Large Language Models the Silver Bullet for Code Search?" [2024-10] [paper]
"CodeXEmbed: A Generalist Embedding Model Family for Multiligual and Multi-task Code Retrieval" [2024-11] [paper]
"CodeSAM: Source Code Representation Learning by Infusing Self-Attention with Multi-Code-View Graphs" [2024-11] [paper]
"EnStack: An Ensemble Stacking Framework of Large Language Models for Enhanced Vulnerability Detection in Source Code" [2024-11] [paper]
"Isotropy Matters: Soft-ZCA Whitening of Embeddings for Semantic Code Search" [2024-11] [paper]
"An Empirical Study on the Code Refactoring Capability of Large Language Models" [2024-11] [paper]
"Automated Update of Android Deprecated API Usages with Large Language Models" [2024-11] [paper]
"An Empirical Study on the Potential of LLMs in Automated Software Refactoring" [2024-11] [paper]
"CODECLEANER: Elevating Standards with A Robust Data Contamination Mitigation Toolkit" [2024-11] [paper]
"Instruct or Interact? Exploring and Eliciting LLMs' Capability in Code Snippet Adaptation Through Prompt Engineering" [2024-11] [paper]
"Learning type annotation: is big data enough?" [2021-08] [ESEC/FSE 2021] [paper]
"Do Machine Learning Models Produce TypeScript Types That Type Check?" [2023-02] [ECOOP 2023] [paper]
"TypeT5: Seq2seq Type Inference using Static Analysis" [2023-03] [ICLR 2023] [paper]
"Type Prediction With Program Decomposition and Fill-in-the-Type Training" [2023-05] [paper]
"Generative Type Inference for Python" [2023-07] [ASE 2023] [paper]
"Activation Steering for Robust Type Prediction in CodeLLMs" [2024-04] [paper]
"An Empirical Study of Large Language Models for Type and Call Graph Analysis" [2024-10] [paper]
"Repository-Level Prompt Generation for Large Language Models of Code" [2022-06] [ICML 2023] [paper]
"CoCoMIC: Code Completion By Jointly Modeling In-file and Cross-file Context" [2022-12] [paper]
"RepoCoder: Repository-Level Code Completion Through Iterative Retrieval and Generation" [2023-03] [EMNLP 2023] [paper]
"Coeditor: Leveraging Repo-level Diffs for Code Auto-editing" [2023-05] [ICLR 2024 Spotlight] [paper]
"RepoBench: Benchmarking Repository-Level Code Auto-Completion Systems" [2023-06] [ICLR 2024] [paper]
"Guiding Language Models of Code with Global Context using Monitors" [2023-06] [paper]
"RepoFusion: Training Code Models to Understand Your Repository" [2023-06] [paper]
"CodePlan: Repository-level Coding using LLMs and Planning" [2023-09] [paper]
"SWE-bench: Can Language Models Resolve Real-World GitHub Issues?" [2023-10] [ICLR 2024] [paper]
"CrossCodeEval: A Diverse and Multilingual Benchmark for Cross-File Code Completion" [2023-10] [NeurIPS 2023] [paper]
"A^3-CodGen: A Repository-Level Code Generation Framework for Code Reuse with Local-Aware, Global-Aware, and Third-Party-Library-Aware" [2023-12] [paper]
"Teaching Code LLMs to Use Autocompletion Tools in Repository-Level Code Generation" [2024-01] [paper]
"RepoHyper: Better Context Retrieval Is All You Need for Repository-Level Code Completion" [2024-03] [paper]
"Repoformer: Selective Retrieval for Repository-Level Code Completion" [2024-03] [ICML 2024] [paper]
"CodeS: Natural Language to Code Repository via Multi-Layer Sketch" [2024-03] [paper]
"Class-Level Code Generation from Natural Language Using Iterative, Tool-Enhanced Reasoning over Repository" [2024-04] [paper]
"Contextual API Completion for Unseen Repositories Using LLMs" [2024-05] [paper]
"Dataflow-Guided Retrieval Augmentation for Repository-Level Code Completion" [2024-05][ACL 2024] [paper]
"How to Understand Whole Software Repository?" [2024-06] [paper]
"R2C2-Coder: Enhancing and Benchmarking Real-world Repository-level Code Completion Abilities of Code Large Language Models" [2024-06] [paper]
"CodeR: Issue Resolving with Multi-Agent and Task Graphs" [2024-06] [paper]
"Enhancing Repository-Level Code Generation with Integrated Contextual Information" [2024-06] [paper]
"On The Importance of Reasoning for Context Retrieval in Repository-Level Code Editing" [2024-06] [paper]
"GraphCoder: Enhancing Repository-Level Code Completion via Code Context Graph-based Retrieval and Language Model" [2024-06] [ASE 2024] [paper]
"STALL+: Boosting LLM-based Repository-level Code Completion with Static Analysis" [2024-06] [paper]
"Hierarchical Context Pruning: Optimizing Real-World Code Completion with Repository-Level Pretrained Code LLMs" [2024-06] [paper]
"Agentless: Demystifying LLM-based Software Engineering Agents" [2024-07] [paper]
"RLCoder: Reinforcement Learning for Repository-Level Code Completion" [2024-07] [paper]
"CoEdPilot: Recommending Code Edits with Learned Prior Edit Relevance, Project-wise Awareness, and Interactive Nature" [2024-08] [paper] [repo]
"RAMBO: Enhancing RAG-based Repository-Level Method Body Completion" [2024-09] [paper]
"Exploring the Potential of Conversational Test Suite Based Program Repair on SWE-bench" [2024-10] [paper]
"RepoGraph: Enhancing AI Software Engineering with Repository-level Code Graph" [2024-10] [paper]
"See-Saw Generative Mechanism for Scalable Recursive Code Generation with Generative AI" [2024-11] [paper]
"Seeking the user interface", 2014-09, ASE 2014, [paper]
"pix2code: Generating Code from a Graphical User Interface Screenshot", 2017-05, EICS 2018, [paper]
"Machine Learning-Based Prototyping of Graphical User Interfaces for Mobile Apps", 2018-02, TSE 2020, [paper]
"Automatic HTML Code Generation from Mock-Up Images Using Machine Learning Techniques", 2019-04, EBBT 2019, [paper]
"Sketch2code: Generating a website from a paper mockup", 2019-05, [paper]
"HTLM: Hyper-Text Pre-Training and Prompting of Language Models", 2021-07, ICLR 2022, [paper]
"Learning UI-to-Code Reverse Generator Using Visual Critic Without Rendering", 2023-05, [paper]
"Design2Code: How Far Are We From Automating Front-End Engineering?" [2024-03] [paper]
"Unlocking the conversion of Web Screenshots into HTML Code with the WebSight Dataset" [2024-03] [paper]
"VISION2UI: A Real-World Dataset with Layout for Code Generation from UI Designs" [2024-04] [paper]
"LogoMotion: Visually Grounded Code Generation for Content-Aware Animation" [2024-05] [paper]
"PosterLLaVa: Constructing a Unified Multi-modal Layout Generator with LLM" [2024-06] [paper]
"UICoder: Finetuning Large Language Models to Generate User Interface Code through Automated Feedback" [2024-06] [paper]
"On AI-Inspired UI-Design" [2024-06] [paper]
"Identifying User Goals from UI Trajectories" [2024-06] [paper]
"Automatically Generating UI Code from Screenshot: A Divide-and-Conquer-Based Approach" [2024-06] [paper]
"Web2Code: A Large-scale Webpage-to-Code Dataset and Evaluation Framework for Multimodal LLMs" [2024-06] [paper]
"Vision-driven Automated Mobile GUI Testing via Multimodal Large Language Model" [2024-07] [paper]
"AUITestAgent: Automatic Requirements Oriented GUI Function Testing" [2024-07] [paper]
"LLM-based Abstraction and Concretization for GUI Test Migration" [2024-09] [paper]
"Enabling Cost-Effective UI Automation Testing with Retrieval-Based LLMs: A Case Study in WeChat" [2024-09] [paper]
"Self-Elicitation of Requirements with Automated GUI Prototyping" [2024-09] [paper]
"Infering Alt-text For UI Icons With Large Language Models During App Development" [2024-09] [paper]
"Leveraging Large Vision Language Model For Better Automatic Web GUI Testing" [2024-10] [paper]
"Sketch2Code: Evaluating Vision-Language Models for Interactive Web Design Prototyping" [2024-10] [paper]
"WAFFLE: Multi-Modal Model for Automated Front-End Development" [2024-10] [paper]
"DesignRepair: Dual-Stream Design Guideline-Aware Frontend Repair with Large Language Models" [2024-11] [paper]
"Interaction2Code: How Far Are We From Automatic Interactive Webpage Generation?" [2024-11] [paper]
"A Multi-Agent Approach for REST API Testing with Semantic Graphs and LLM-Driven Inputs" [2024-11] [paper]
"PICARD: Parsing Incrementally for Constrained Auto-Regressive Decoding from Language Models" [2021-09] [EMNLP 2021] [paper]
"CodexDB: Generating Code for Processing SQL Queries using GPT-3 Codex" [2022-04] [paper]
"T5QL: Taming language models for SQL generation" [2022-09] [paper]
"Towards Generalizable and Robust Text-to-SQL Parsing" [2022-10] [EMNLP 2022 Findings] [paper]
"XRICL: Cross-lingual Retrieval-Augmented In-Context Learning for Cross-lingual Text-to-SQL Semantic Parsing" [2022-10] [EMNLP 2022 Findings] [paper]
"A comprehensive evaluation of ChatGPT's zero-shot Text-to-SQL capability" [2023-03] [paper]
"DIN-SQL: Decomposed In-Context Learning of Text-to-SQL with Self-Correction" [2023-04] [NeurIPS 2023] [paper]
"How to Prompt LLMs for Text-to-SQL: A Study in Zero-shot, Single-domain, and Cross-domain Settings" [2023-05] [paper]
"Enhancing Few-shot Text-to-SQL Capabilities of Large Language Models: A Study on Prompt Design Strategies" [2023-05] [paper]
"SQL-PaLM: Improved Large Language Model Adaptation for Text-to-SQL" [2023-05] [paper]
"Retrieval-augmented GPT-3.5-based Text-to-SQL Framework with Sample-aware Prompting and Dynamic Revision Chain" [2023-07] [ICONIP 2023] [paper]
"Text-to-SQL Empowered by Large Language Models: A Benchmark Evaluation" [2023-08] [paper]
"MAC-SQL: A Multi-Agent Collaborative Framework for Text-to-SQL" [2023-12] [paper]
"Investigating the Impact of Data Contamination of Large Language Models in Text-to-SQL Translation" [2024-02] [ACL 2024 Findings] [paper]
"Decomposition for Enhancing Attention: Improving LLM-based Text-to-SQL through Workflow Paradigm" [2024-02] [ACL 2024 Findings] [paper]
"Knowledge-to-SQL: Enhancing SQL Generation with Data Expert LLM" [2024-02] [ACL 2024 Findings] [paper]
"Understanding the Effects of Noise in Text-to-SQL: An Examination of the BIRD-Bench Benchmark" [2024-02] [ACL 2024 short] [paper]
"SQL-Encoder: Improving NL2SQL In-Context Learning Through a Context-Aware Encoder" [2024-03] [paper]
"LLM-R2: A Large Language Model Enhanced Rule-based Rewrite System for Boosting Query Efficiency" [2024-04] [paper]
"Dubo-SQL: Diverse Retrieval-Augmented Generation and Fine Tuning for Text-to-SQL" [2024-04] [paper]
"EPI-SQL: Enhancing Text-to-SQL Translation with Error-Prevention Instructions" [2024-04] [paper]
"ProbGate at EHRSQL 2024: Enhancing SQL Query Generation Accuracy through Probabilistic Threshold Filtering and Error Handling" [2024-04] [paper]
"CoE-SQL: In-Context Learning for Multi-Turn Text-to-SQL with Chain-of-Editions" [2024-05] [paper]
"Open-SQL Framework: Enhancing Text-to-SQL on Open-source Large Language Models" [2024-05] [paper]
"MCS-SQL: Leveraging Multiple Prompts and Multiple-Choice Selection For Text-to-SQL Generation" [2024-05] [paper]
"PromptMind Team at EHRSQL-2024: Improving Reliability of SQL Generation using Ensemble LLMs" [2024-05] [paper]
"LG AI Research & KAIST at EHRSQL 2024: Self-Training Large Language Models with Pseudo-Labeled Unanswerable Questions for a Reliable Text-to-SQL System on EHRs" [2024-05] [paper]
"Before Generation, Align it! A Novel and Effective Strategy for Mitigating Hallucinations in Text-to-SQL Generation" [2024-05] [ACL 2024 Findings] [paper]
"CHESS: Contextual Harnessing for Efficient SQL Synthesis" [2024-05] [paper]
"DeTriever: Decoder-representation-based Retriever for Improving NL2SQL In-Context Learning" [2024-06] [paper]
"Next-Generation Database Interfaces: A Survey of LLM-based Text-to-SQL" [2024-06] [paper]
"RH-SQL: Refined Schema and Hardness Prompt for Text-to-SQL" [2024-06] [paper]
"QDA-SQL: Questions Enhanced Dialogue Augmentation for Multi-Turn Text-to-SQL" [2024-06] [paper]
"End-to-end Text-to-SQL Generation within an Analytics Insight Engine" [2024-06] [paper]
"MAGIC: Generating Self-Correction Guideline for In-Context Text-to-SQL" [2024-06] [paper]
"SQLFixAgent: Towards Semantic-Accurate SQL Generation via Multi-Agent Collaboration" [2024-06] [paper]
"Unmasking Database Vulnerabilities: Zero-Knowledge Schema Inference Attacks in Text-to-SQL Systems" [2024-06] [paper]
"Lucy: Think and Reason to Solve Text-to-SQL" [2024-07] [paper]
"ESM+: Modern Insights into Perspective on Text-to-SQL Evaluation in the Age of Large Language Models" [2024-07] [paper]
"RB-SQL: A Retrieval-based LLM Framework for Text-to-SQL" [2024-07] [paper]
"AI-Assisted SQL Authoring at Industry Scale" [2024-07] [paper]
"SQLfuse: Enhancing Text-to-SQL Performance through Comprehensive LLM Synergy" [2024-07] [paper]
"A Survey on Employing Large Language Models for Text-to-SQL Tasks" [2024-07] [paper]
"Towards Automated Data Sciences with Natural Language and SageCopilot: Practices and Lessons Learned" [2024-07] [paper]
"Evaluating LLMs for Text-to-SQL Generation With Complex SQL Workload" [2024-07] [paper]
"Synthesizing Text-to-SQL Data from Weak and Strong LLMs" [2024-08] [ACL 2024] [paper]
"Improving Relational Database Interactions with Large Language Models: Column Descriptions and Their Impact on Text-to-SQL Performance" [2024-08] [paper]
"The Death of Schema Linking? Text-to-SQL in the Age of Well-Reasoned Language Models" [2024-08] [paper]
"MAG-SQL: Multi-Agent Generative Approach with Soft Schema Linking and Iterative Sub-SQL Refinement for Text-to-SQL" [2024-08] [paper]
"Enhancing Text-to-SQL Parsing through Question Rewriting and Execution-Guided Refinement" [2024-08] [ACL 2024 Findings] [paper]
"DAC: Decomposed Automation Correction for Text-to-SQL" [2024-08] [paper]
"Interactive-T2S: Multi-Turn Interactions for Text-to-SQL with Large Language Models" [2024-08] [paper]
"SQL-GEN: Bridging the Dialect Gap for Text-to-SQL Via Synthetic Data And Model Merging" [2024-08] [paper]
"Enhancing SQL Query Generation with Neurosymbolic Reasoning" [2024-08] [paper]
"Text2SQL is Not Enough: Unifying AI and Databases with TAG" [2024-08] [paper]
"Tool-Assisted Agent on SQL Inspection and Refinement in Real-World Scenarios" [2024-08] [paper]
"SelECT-SQL: Self-correcting ensemble Chain-of-Thought for Text-to-SQL" [2024-09] [paper]
"You Only Read Once (YORO): Learning to Internalize Database Knowledge for Text-to-SQL" [2024-09] [paper]
"PTD-SQL: Partitioning and Targeted Drilling with LLMs in Text-to-SQL" [2024-09] [paper]
"Enhancing Text-to-SQL Capabilities of Large Language Models via Domain Database Knowledge Injection" [2024-09] [paper]
"DataGpt-SQL-7B: An Open-Source Language Model for Text-to-SQL" [2024-09] [paper]
"E-SQL: Direct Schema Linking via Question Enrichment in Text-to-SQL" [2024-09] [paper]
"FLEX: Expert-level False-Less EXecution Metric for Reliable Text-to-SQL Benchmark" [2024-09] [paper]
"Enhancing LLM Fine-tuning for Text-to-SQLs by SQL Quality Measurement" [2024-10] [paper]
"From Natural Language to SQL: Review of LLM-based Text-to-SQL Systems" [2024-10] [paper]
"CHASE-SQL: Multi-Path Reasoning and Preference Optimized Candidate Selection in Text-to-SQL" [2024-10] [paper]
"Context-Aware SQL Error Correction Using Few-Shot Learning -- A Novel Approach Based on NLQ, Error, and SQL Similarity" [2024-10] [paper]
"Learning from Imperfect Data: Towards Efficient Knowledge Distillation of Autoregressive Language Models for Text-to-SQL" [2024-10] [paper]
"LR-SQL: A Supervised Fine-Tuning Method for Text2SQL Tasks under Low-Resource Scenarios" [2024-10] [paper]
"MSc-SQL: Multi-Sample Critiquing Small Language Models For Text-To-SQL Translation" [2024-10] [paper]
"Learning Metadata-Agnostic Representations for Text-to-SQL In-Context Example Selection" [2024-10] [paper]
"An Actor-Critic Approach to Boosting Text-to-SQL Large Language Model" [2024-10] [paper]
"RSL-SQL: Robust Schema Linking in Text-to-SQL Generation" [2024-10] [paper]
"KeyInst: Keyword Instruction for Improving SQL Formulation in Text-to-SQL" [2024-10] [paper]
"Grounding Natural Language to SQL Translation with Data-Based Self-Explanations" [2024-11] [paper]
"PDC & DM-SFT: A Road for LLM SQL Bug-Fix Enhancing" [2024-11] [paper]
"XiYan-SQL: A Multi-Generator Ensemble Framework for Text-to-SQL" [2024-11] [paper]
"Leveraging Prior Experience: An Expandable Auxiliary Knowledge Base for Text-to-SQL" [2024-11] [paper]
"Text-to-SQL Calibration: No Need to Ask -- Just Rescale Model Probabilities" [2024-11] [paper]
"Baldur: Whole-Proof Generation and Repair with Large Language Models" [2023-03] [FSE 2023] [paper]
"An In-Context Learning Agent for Formal Theorem-Proving" [2023-10] [paper]
"Towards AI-Assisted Synthesis of Verified Dafny Methods" [2024-02] [FSE 2024] [paper]
"Towards Neural Synthesis for SMT-Assisted Proof-Oriented Programming" [2024-05] [paper]
"Laurel: Generating Dafny Assertions Using Large Language Models" [2024-05] [paper]
"AutoVerus: Automated Proof Generation for Rust Code" [2024-09] [paper]
"Proof Automation with Large Language Models" [2024-09] [paper]
"Automated Proof Generation for Rust Code via Self-Evolution" [2024-10] [paper]
"CoqPilot, a plugin for LLM-based generation of proofs" [2024-10] [paper]
"dafny-annotator: AI-Assisted Verification of Dafny Programs" [2024-11] [paper]
"Unit Test Case Generation with Transformers and Focal Context" [2020-09] [AST@ICSE 2022] [paper]
"An Empirical Evaluation of Using Large Language Models for Automated Unit Test Generation" [2023-02] [IEEE TSE] [paper]
"A3Test: Assertion-Augmented Automated Test Case Generation" [2023-02] [paper]
"Learning Deep Semantics for Test Completion" [2023-02] [ICSE 2023] [paper]
"Using Large Language Models to Generate JUnit Tests: An Empirical Study" [2023-04] [EASE 2024] [paper]
"CodaMosa: Escaping Coverage Plateaus in Test Generation with Pre-Trained Large Language Models" [2023-05] [ICSE 2023] [paper]
"No More Manual Tests? Evaluating and Improving ChatGPT for Unit Test Generation" [2023-05] [paper]
"ChatUniTest: a ChatGPT-based automated unit test generation tool" [2023-05] [paper]
"ChatGPT vs SBST: A Comparative Assessment of Unit Test Suite Generation" [2023-07] [paper]
"Can Large Language Models Write Good Property-Based Tests?" [2023-07] [paper]
"Domain Adaptation for Deep Unit Test Case Generation" [2023-08] [paper]
"Effective Test Generation Using Pre-trained Large Language Models and Mutation Testing" [2023-08] [paper]
"How well does LLM generate security tests?" [2023-10] [paper]
"Reinforcement Learning from Automatic Feedback for High-Quality Unit Test Generation" [2023-10] [paper]
"An initial investigation of ChatGPT unit test generation capability" [2023-10] [SAST 2023] [paper]
"CoverUp: Coverage-Guided LLM-Based Test Generation" [2024-03] [paper]
"Enhancing LLM-based Test Generation for Hard-to-Cover Branches via Program Analysis" [2024-04] [paper]
"Large Language Models for Mobile GUI Text Input Generation: An Empirical Study" [2024-04] [paper]
"Test Code Generation for Telecom Software Systems using Two-Stage Generative Model" [2024-04] [paper]
"LLM-Powered Test Case Generation for Detecting Tricky Bugs" [2024-04] [paper]
"Generating Test Scenarios from NL Requirements using Retrieval-Augmented LLMs: An Industrial Study" [2024-04] [paper]
"Large Language Models as Test Case Generators: Performance Evaluation and Enhancement" [2024-04] [paper]
"Leveraging Large Language Models for Automated Web-Form-Test Generation: An Empirical Study" [2024-05] [paper]
"DLLens: Testing Deep Learning Libraries via LLM-aided Synthesis" [2024-06] [paper]
"Exploring Fuzzing as Data Augmentation for Neural Test Generation" [2024-06] [paper]
"Mokav: Execution-driven Differential Testing with LLMs" [2024-06] [paper]
"Code Agents are State of the Art Software Testers" [2024-06] [paper]
"CasModaTest: A Cascaded and Model-agnostic Self-directed Framework for Unit Test Generation" [2024-06] [paper]
"An Empirical Study of Unit Test Generation with Large Language Models" [2024-06] [paper]
"Large-scale, Independent and Comprehensive study of the power of LLMs for test case generation" [2024-06] [paper]
"Augmenting LLMs to Repair Obsolete Test Cases with Static Collector and Neural Reranker" [2024-07] [paper]
"Harnessing the Power of LLMs: Automating Unit Test Generation for High-Performance Computing" [2024-07] [paper]
"An LLM-based Readability Measurement for Unit Tests' Context-aware Inputs" [2024-07] [paper]
"A System for Automated Unit Test Generation Using Large Language Models and Assessment of Generated Test Suites" [2024-08] [paper]
"Leveraging Large Language Models for Enhancing the Understandability of Generated Unit Tests" [2024-08] [paper]
"Multi-language Unit Test Generation using LLMs" [2024-09] [paper]
"Exploring the Integration of Large Language Models in Industrial Test Maintenance Processes" [2024-09] [paper]
"Python Symbolic Execution with LLM-powered Code Generation" [2024-09] [paper]
"Rethinking the Influence of Source Code on Test Case Generation" [2024-09] [paper]
"On the Effectiveness of LLMs for Manual Test Verifications" [2024-09] [paper]
"Retrieval-Augmented Test Generation: How Far Are We?" [2024-09] [paper]
"Context-Enhanced LLM-Based Framework for Automatic Test Refactoring" [2024-09] [paper]
"TestBench: Evaluating Class-Level Test Case Generation Capability of Large Language Models" [2024-09] [paper]
"Advancing Bug Detection in Fastjson2 with Large Language Models Driven Unit Test Generation" [2024-10] [paper]
"Test smells in LLM-Generated Unit Tests" [2024-10] [paper]
"LLM-based Unit Test Generation via Property Retrieval" [2024-10] [paper]
"Disrupting Test Development with AI Assistants" [2024-11] [paper]
"Parameter-Efficient Fine-Tuning of Large Language Models for Unit Test Generation: An Empirical Study" [2024-11] [paper]
"VALTEST: Automated Validation of Language Model Generated Test Cases" [2024-11] [paper]
"REACCEPT: Automated Co-evolution of Production and Test Code Based on Dynamic Validation and Large Language Models" [2024-11] [paper]
"Generating Accurate Assert Statements for Unit Test Cases using Pretrained Transformers" [2020-09] [paper]
"TOGA: A Neural Method for Test Oracle Generation" [2021-09] [ICSE 2022] [paper]
"TOGLL: Correct and Strong Test Oracle Generation with LLMs" [2024-05] [paper]
"Test Oracle Automation in the era of LLMs" [2024-05] [paper]
"Beyond Code Generation: Assessing Code LLM Maturity with Postconditions" [2024-07] [paper]
"Chat-like Asserts Prediction with the Support of Large Language Model" [2024-07] [paper]
"Do LLMs generate test oracles that capture the actual or the expected program behaviour?" [2024-10] [paper]
"Generating executable oracles to check conformance of client code to requirements of JDK Javadocs using LLMs" [2024-11] [paper]
"Automatically Write Code Checker: An LLM-based Approach with Logic-guided API Retrieval and Case by Case Iteration" [2024-11] [paper]
"ASSERTIFY: Utilizing Large Language Models to Generate Assertions for Production Code" [2024-11] [paper]
"μBERT: Mutation Testing using Pre-Trained Language Models" [2022-03] [paper]
"Efficient Mutation Testing via Pre-Trained Language Models" [2023-01] [paper]
"LLMorpheus: Mutation Testing using Large Language Models" [2024-04] [paper]
"An Exploratory Study on Using Large Language Models for Mutation Testing" [2024-06] [paper]
"Fine-Tuning LLMs for Code Mutation: A New Era of Cyber Threats" [2024-10] [paper]
"Large Language Models are Zero-Shot Fuzzers: Fuzzing Deep-Learning Libraries via Large Language Models" [2022-12] [paper]
"Fuzz4All: Universal Fuzzing with Large Language Models" [2023-08] [paper]
"WhiteFox: White-Box Compiler Fuzzing Empowered by Large Language Models" [2023-10] [paper]
"LLAMAFUZZ: Large Language Model Enhanced Greybox Fuzzing" [2024-06] [paper]
"FuzzCoder: Byte-level Fuzzing Test via Large Language Model" [2024-09] [paper]
"ISC4DGF: Enhancing Directed Grey-box Fuzzing with LLM-Driven Initial Seed Corpus Generation" [2024-09] [paper]
"Large Language Models Based JSON Parser Fuzzing for Bug Discovery and Behavioral Analysis" [2024-10] [paper]
"Fixing Security Vulnerabilities with AI in OSS-Fuzz" [2024-11] [paper]
"A Code Knowledge Graph-Enhanced System for LLM-Based Fuzz Driver Generation" [2024-11] [paper]
"VulDeePecker: A Deep Learning-Based System for Vulnerability Detection" [2018-01] [NDSS 2018] [paper]
"DeepBugs: A Learning Approach to Name-based Bug Detection" [2018-04] [Proc. ACM Program. Lang.] [paper]
"Automated Vulnerability Detection in Source Code Using Deep Representation Learning" [2018-07] [ICMLA 2018] [paper]
"SySeVR: A Framework for Using Deep Learning to Detect Software Vulnerabilities" [2018-07] [IEEE TDSC] [paper]
"Devign: Effective Vulnerability Identification by Learning Comprehensive Program Semantics via Graph Neural Networks" [2019-09] [NeurIPS 2019] [paper]
"Improving bug detection via context-based code representation learning and attention-based neural networks" [2019-10] [Proc. ACM Program. Lang.] [paper]
"Global Relational Models of Source Code" [2019-12] [ICLR 2020] [paper]
"VulDeeLocator: A Deep Learning-based Fine-grained Vulnerability Detector" [2020-01] [IEEE TDSC] [paper]
"Deep Learning based Vulnerability Detection: Are We There Yet?" [2020-09] [IEEE TSE] [paper]
"Security Vulnerability Detection Using Deep Learning Natural Language Processing" [2021-05] [INFOCOM Workshops 2021] [paper]
"Self-Supervised Bug Detection and Repair" [2021-05] [NeurIPS 2021] [paper]
"Vulnerability Detection with Fine-grained Interpretations" [2021-06] [ESEC/SIGSOFT FSE 2021] [paper]
"ReGVD: Revisiting Graph Neural Networks for Vulnerability Detection" [2021-10] [ICSE Companion 2022] [paper]
"VUDENC: Vulnerability Detection with Deep Learning on a Natural Codebase for Python" [2022-01] [Inf.软件。 Technol] [paper]
"Transformer-Based Language Models for Software Vulnerability Detection" [222-04] [ACSAC 2022] [paper]
"LineVul: A Transformer-based Line-Level Vulnerability Prediction" [2022-05] [MSR 2022] [paper]
"VulBERTa: Simplified Source Code Pre-Training for Vulnerability Detection" [2022-05] [IJCNN 2022] [paper]
"Open Science in Software Engineering: A Study on Deep Learning-Based Vulnerability Detection" [2022-09] [IEEE TSE] [paper]
"An Empirical Study of Deep Learning Models for Vulnerability Detection" [2022-12] [ICSE 2023] [paper]
"CSGVD: A deep learning approach combining sequence and graph embedding for source code vulnerability detection" [2023-01] [J.系统。 Softw.] [paper]
"Benchmarking Software Vulnerability Detection Techniques: A Survey" [2023-03] [paper]
"Transformer-based Vulnerability Detection in Code at EditTime: Zero-shot, Few-shot, or Fine-tuning?" [2023-05] [paper]
"A Survey on Automated Software Vulnerability Detection Using Machine Learning and Deep Learning" [2023-06] [paper]
"Limits of Machine Learning for Automatic Vulnerability Detection" [2023-06] [paper]
"Evaluating Instruction-Tuned Large Language Models on Code Comprehension and Generation" [2023-08] [paper]
"Prompt-Enhanced Software Vulnerability Detection Using ChatGPT" [2023-08] [paper]
"Towards Causal Deep Learning for Vulnerability Detection" [2023-10] [paper]
"Understanding the Effectiveness of Large Language Models in Detecting Security Vulnerabilities" [2023-11] [paper]
"How Far Have We Gone in Vulnerability Detection Using Large Language Models" [2023-11] [paper]
"Can Large Language Models Identify And Reason About Security Vulnerabilities? Not Yet" [2023-12] [paper]
"LLM4Vuln: A Unified Evaluation Framework for Decoupling and Enhancing LLMs' Vulnerability Reasoning" [2024-01] [paper]
"Security Code Review by LLMs: A Deep Dive into Responses" [2024-01] [paper]
"Chain-of-Thought Prompting of Large Language Models for Discovering and Fixing Software Vulnerabilities" [2024-02] [paper]
"Multi-role Consensus through LLMs Discussions for Vulnerability Detection" [2024-03] [paper]
"A Comprehensive Study of the Capabilities of Large Language Models for Vulnerability Detection" [2024-03] [paper]
"Vulnerability Detection with Code Language Models: How Far Are We?" [2024-03] [paper]
"Multitask-based Evaluation of Open-Source LLM on Software Vulnerability" [2024-04] [paper]
"Large Language Model for Vulnerability Detection and Repair: Literature Review and Roadmap" [2024-04] [paper]
"Pros and Cons! Evaluating ChatGPT on Software Vulnerability" [2024-04] [paper]
"VulEval: Towards Repository-Level Evaluation of Software Vulnerability Detection" [2024-04] [paper]
"DLAP: A Deep Learning Augmented Large Language Model Prompting Framework for Software Vulnerability Detection" [2024-05] [paper]
"Bridging the Gap: A Study of AI-based Vulnerability Management between Industry and Academia" [2024-05] [paper]
"Bridge and Hint: Extending Pre-trained Language Models for Long-Range Code" [2024-05] [paper]
"Harnessing Large Language Models for Software Vulnerability Detection: A Comprehensive Benchmarking Study" [2024-05] [paper]
"LLM-Assisted Static Analysis for Detecting Security Vulnerabilities" [2024-05] [paper]
"Generalization-Enhanced Code Vulnerability Detection via Multi-Task Instruction Fine-Tuning" [2024-06] [ACL 2024 Findings] [paper]
"Security Vulnerability Detection with Multitask Self-Instructed Fine-Tuning of Large Language Models" [2024-06] [paper]
"M2CVD: Multi-Model Collaboration for Code Vulnerability Detection" [2024-06] [paper]
"Towards Effectively Detecting and Explaining Vulnerabilities Using Large Language Models" [2024-06] [paper]
"Vul-RAG: Enhancing LLM-based Vulnerability Detection via Knowledge-level RAG" [2024-06] [paper]
"Bug In the Code Stack: Can LLMs Find Bugs in Large Python Code Stacks" [2024-06] [paper]
"Supporting Cross-language Cross-project Bug Localization Using Pre-trained Language Models" [2024-07] [paper]
"ALPINE: An adaptive language-agnostic pruning method for language models for code" [2024-07] [paper]
"SCoPE: Evaluating LLMs for Software Vulnerability Detection" [2024-07] [paper]
"Comparison of Static Application Security Testing Tools and Large Language Models for Repo-level Vulnerability Detection" [2024-07] [paper]
"Code Structure-Aware through Line-level Semantic Learning for Code Vulnerability Detection" [2024-07] [paper]
"A Study of Using Multimodal LLMs for Non-Crash Functional Bug Detection in Android Apps" [2024-07] [paper]
"EaTVul: ChatGPT-based Evasion Attack Against Software Vulnerability Detection" [2024-07] [paper]
"Evaluating Large Language Models in Detecting Test Smells" [2024-07] [paper]
"Automated Software Vulnerability Static Code Analysis Using Generative Pre-Trained Transformer Models" [2024-07] [paper]
"A Qualitative Study on Using ChatGPT for Software Security: Perception vs. Practicality" [2024-08] [paper]
"Large Language Models for Secure Code Assessment: A Multi-Language Empirical Study" [2024-08] [paper]
"VulCatch: Enhancing Binary Vulnerability Detection through CodeT5 Decompilation and KAN Advanced Feature Extraction" [2024-08] [paper]
"Impact of Large Language Models of Code on Fault Localization" [2024-08] [paper]
"Better Debugging: Combining Static Analysis and LLMs for Explainable Crashing Fault Localization" [2024-08] [paper]
"Beyond ChatGPT: Enhancing Software Quality Assurance Tasks with Diverse LLMs and Validation Techniques" [2024-09] [paper]
"CLNX: Bridging Code and Natural Language for C/C++ Vulnerability-Contributing Commits Identification" [2024-09] [paper]
"Code Vulnerability Detection: A Comparative Analysis of Emerging Large Language Models" [2024-09] [paper]
"Program Slicing in the Era of Large Language Models" [2024-09] [paper]
"Generating API Parameter Security Rules with LLM for API Misuse Detection" [2024-09] [paper]
"Enhancing Fault Localization Through Ordered Code Analysis with LLM Agents and Self-Reflection" [2024-09] [paper]
"Comparing Unidirectional, Bidirectional, and Word2vec Models for Discovering Vulnerabilities in Compiled Lifted Code" [2024-09] [paper]
"Enhancing Pre-Trained Language Models for Vulnerability Detection via Semantic-Preserving Data Augmentation" [2024-10] [paper]
"StagedVulBERT: Multi-Granular Vulnerability Detection with a Novel Pre-trained Code Model" [2024-10] [paper]
"Understanding the AI-powered Binary Code Similarity Detection" [2024-10] [paper]
"RealVul: Can We Detect Vulnerabilities in Web Applications with LLM?" [2024-10] [paper]
"Just-In-Time Software Defect Prediction via Bi-modal Change Representation Learning" [2024-10] [paper]
"DFEPT: Data Flow Embedding for Enhancing Pre-Trained Model Based Vulnerability Detection" [2024-10] [paper]
"Utilizing Precise and Complete Code Context to Guide LLM in Automatic False Positive Mitigation" [2024-11] [paper]
"Smart-LLaMA: Two-Stage Post-Training of Large Language Models for Smart Contract Vulnerability Detection and Explanation" [2024-11] [paper]
"FlexFL: Flexible and Effective Fault Localization with Open-Source Large Language Models" [2024-11] [paper]
"Breaking the Cycle of Recurring Failures: Applying Generative AI to Root Cause Analysis in Legacy Banking Systems" [2024-11] [paper]
"Are Large Language Models Memorizing Bug Benchmarks?" [2024-11] [paper]
"An Empirical Study of Vulnerability Detection using Federated Learning" [2024-11] [paper]
"Fault Localization from the Semantic Code Search Perspective" [2024-11] [paper]
"Deep Android Malware Detection", 2017-03, CODASPY 2017, [paper]
"A Multimodal Deep Learning Method for Android Malware Detection Using Various Features", 2018-08, IEEE Trans. inf。 Forensics Secur. 2019, [paper]
"Portable, Data-Driven Malware Detection using Language Processing and Machine Learning Techniques on Behavioral Analysis Reports", 2018-12, Digit.调查。 2019, [paper]
"I-MAD: Interpretable Malware Detector Using Galaxy Transformer", 2019-09, Comput.证券。 2021, [paper]
"Droidetec: Android Malware Detection and Malicious Code Localization through Deep Learning", 2020-02, [paper]
"Malicious Code Detection: Run Trace Output Analysis by LSTM", 2021-01, IEEE Access 2021, [paper]
"Intelligent malware detection based on graph convolutional network", 2021-08, J. Supercomput. 2021, [paper]
"Malbert: A novel pre-training method for malware detection", 2021-09, Comput.证券。 2021, [paper]
"Single-Shot Black-Box Adversarial Attacks Against Malware Detectors: A Causal Language Model Approach", 2021-12, ISI 2021, [paper]
"M2VMapper: Malware-to-Vulnerability mapping for Android using text processing", 2021-12, Expert Syst.应用。 2022, [paper]
"Malware Detection and Prevention using Artificial Intelligence Techniques", 2021-12, IEEE BigData 2021, [paper]
"An Ensemble of Pre-trained Transformer Models For Imbalanced Multiclass Malware Classification", 2021-12, Comput.证券。 2022, [paper]
"EfficientNet convolutional neural networks-based Android malware detection", 2022-01, Comput.证券。 2022, [paper]
"Static Malware Detection Using Stacked BiLSTM and GPT-2", 2022-05, IEEE Access 2022, [paper]
"APT Malicious Sample Organization Traceability Based on Text Transformer Model", 2022-07, PRML 2022, [paper]
"Self-Supervised Vision Transformers for Malware Detection", 2022-08, IEEE Access 2022, [paper]
"A Survey of Recent Advances in Deep Learning Models for Detecting Malware in Desktop and Mobile Platforms", 2022-09, ACM Computing Surveys, [paper]
"Malicious Source Code Detection Using Transformer", 2022-09, [paper]
"Flexible Android Malware Detection Model based on Generative Adversarial Networks with Code Tensor", 2022-10, CyberC 2022, [paper]
"MalBERTv2: Code Aware BERT-Based Model for Malware Identification" [2023-03] [Big Data Cogn.计算。 2023] [paper]
"GPThreats-3: Is Automatic Malware Generation a Threat?" [2023-05] [SPW 2023] [paper]
"GitHub Copilot: A Threat to High School Security? Exploring GitHub Copilot's Proficiency in Generating Malware from Simple User Prompts" [2023-08] [ETNCC 2023] [paper]
"An Attacker's Dream? Exploring the Capabilities of ChatGPT for Developing Malware" [2023-08] [CSET 2023] [paper]
"Malicious code detection in android: the role of sequence characteristics and disassembling methods" [2023-12] [Int. J. Inf。秒2023] [paper]
"Prompt Engineering-assisted Malware Dynamic Analysis Using GPT-4" [2023-12] [paper]
"Shifting the Lens: Detecting Malware in npm Ecosystem with Large Language Models" [2024-03] [paper]
"AppPoet: Large Language Model based Android malware detection via multi-view prompt engineering" [2024-04] [paper]
"Tactics, Techniques, and Procedures (TTPs) in Interpreted Malware: A Zero-Shot Generation with Large Language Models" [2024-07] [paper]
"DetectBERT: Towards Full App-Level Representation Learning to Detect Android Malware" [2024-08] [paper]
"PackageIntel: Leveraging Large Language Models for Automated Intelligence Extraction in Package Ecosystems" [2024-09] [paper]
"Learning Performance-Improving Code Edits" [2023-06] [ICLR 2024 Spotlight] [paper]
"Large Language Models for Compiler Optimization" [2023-09] [paper]
"Refining Decompiled C Code with Large Language Models" [2023-10] [paper]
"Priority Sampling of Large Language Models for Compilers" [2024-02] [paper]
"Should AI Optimize Your Code? A Comparative Study of Current Large Language Models Versus Classical Optimizing Compilers" [2024-06] [paper]
"Iterative or Innovative? A Problem-Oriented Perspective for Code Optimization" [2024-06] [paper]
"Meta Large Language Model Compiler: Foundation Models of Compiler Optimization" [2024-06] [paper]
"ViC: Virtual Compiler Is All You Need For Assembly Code Search" [2024-08] [paper]
"Search-Based LLMs for Code Optimization" [2024-08] [paper]
"E-code: Mastering Efficient Code Generation through Pretrained Models and Expert Encoder Group" [2024-08] [paper]
"Large Language Models for Energy-Efficient Code: Emerging Results and Future Directions" [2024-10] [paper]
"Using recurrent neural networks for decompilation" [2018-03] [SANER 2018] [paper]
"Evolving Exact Decompilation" [2018] [paper]
"Towards Neural Decompilation" [2019-05] [paper]
"Coda: An End-to-End Neural Program Decompiler" [2019-06] [NeurIPS 2019] [paper]
"N-Bref : A High-fidelity Decompiler Exploiting Programming Structures" [2020-09] [paper]
"Neutron: an attention-based neural decompiler" [2021-03] [Cybersecurity 2021] [paper]
"Beyond the C: Retargetable Decompilation using Neural Machine Translation" [2022-12] [paper]
"Boosting Neural Networks to Decompile Optimized Binaries" [2023-01] [ACSAC 2022] [paper]
"SLaDe: A Portable Small Language Model Decompiler for Optimized Assembly" [2023-05] [paper]
"Nova+: Generative Language Models for Binaries" [2023-11] [paper]
"CodeArt: Better Code Models by Attention Regularization When Symbols Are Lacking" [2024-11] [paper]
"LLM4Decompile: Decompiling Binary Code with Large Language Models" [2024-03] [paper]
"WaDec: Decompile WebAssembly Using Large Language Model" [2024-06] [paper]
"MAD: Move AI Decompiler to Improve Transparency and Auditability on Non-Open-Source Blockchain Smart Contract" [2024-10] [paper]
"Source Code Foundation Models are Transferable Binary Analysis Knowledge Bases" [2024-11] [paper]
"Automated Commit Message Generation with Large Language Models: An Empirical Study and Beyond" [2024-04] [paper]
"Towards Realistic Evaluation of Commit Message Generation by Matching Online and Offline Settings" [2024-10] [paper]
"Using Pre-Trained Models to Boost Code Review Automation" [2022-01] [ICSE 2022] [paper]
"AUGER: Automatically Generating Review Comments with Pre-training Models" [2022-08] [ESEC/FSE 2022] [paper]
"Automatic Code Review by Learning the Structure Information of Code Graph" [2023-02] [Sensors] [paper]
"LLaMA-Reviewer: Advancing Code Review Automation with Large Language Models through Parameter-Efficient Fine-Tuning" [2023-08] [ISSRE 2023] [paper]
"AI-powered Code Review with LLMs: Early Results" [2024-04] [paper]
"AI-Assisted Assessment of Coding Practices in Modern Code Review" [2024-05] [paper]
"A GPT-based Code Review System for Programming Language Learning" [2024-07] [paper]
"LLM Critics Help Catch LLM Bugs" [2024-06] [paper]
"Exploring the Capabilities of LLMs for Code Change Related Tasks" [2024-07] [paper]
"Evaluating Language Models for Generating and Judging Programming Feedback" [2024-07] [paper]
"Can LLMs Replace Manual Annotation of Software Engineering Artifacts?" [2024-08] [paper]
"Leveraging Reviewer Experience in Code Review Comment Generation" [2024-09] [paper]
"CRScore: Grounding Automated Evaluation of Code Review Comments in Code Claims and Smells" [2024-09] [paper]
"Enhancing Code Annotation Reliability: Generative AI's Role in Comment Quality Assessment Models" [2024-10] [paper]
"Knowledge-Guided Prompt Learning for Request Quality Assurance in Public Code Review" [2024-10] [paper]
"Impact of LLM-based Review Comment Generation in Practice: A Mixed Open-/Closed-source User Study" [2024-11] [paper]
"Prompting and Fine-tuning Large Language Models for Automated Code Review Comment Generation" [2024-11] [paper]
"Deep Learning-based Code Reviews: A Paradigm Shift or a Double-Edged Sword?" [2024-11] [paper]
"Redefining Crowdsourced Test Report Prioritization: An Innovative Approach with Large Language Model" [2024-11] [paper]
"LogStamp: Automatic Online Log Parsing Based on Sequence Labelling" [2022-08] [paper]
"Log Parsing with Prompt-based Few-shot Learning" [2023-02] [ICSE 2023] [paper]
"Log Parsing: How Far Can ChatGPT Go?" [2023-06] [ASE 2023] [paper]
"LogPrompt: Prompt Engineering Towards Zero-Shot and Interpretable Log Analysis" [2023-08] [paper]
"LogGPT: Exploring ChatGPT for Log-Based Anomaly Detection" [2023-09] [paper]
"An Assessment of ChatGPT on Log Data" [2023-09] [paper]
"LILAC: Log Parsing using LLMs with Adaptive Parsing Cache" [2023-10] [paper]
"LLMParser: An Exploratory Study on Using Large Language Models for Log Parsing" [2024-04] [paper]
"On the Influence of Data Resampling for Deep Learning-Based Log Anomaly Detection: Insights and Recommendations" [2024-05] [paper]
"Log Parsing with Self-Generated In-Context Learning and Self-Correction" [2024-06] [paper]
"Stronger, Faster, and Cheaper Log Parsing with LLMs" [2024-06] [paper]
"ULog: Unsupervised Log Parsing with Large Language Models through Log Contrastive Units" [2024-06] [paper]
"Anomaly Detection on Unstable Logs with GPT Models" [2024-06] [paper]
"LogParser-LLM: Advancing Efficient Log Parsing with Large Language Models" [2024-08] [KDD 2024] [paper]
"LUK: Empowering Log Understanding with Expert Knowledge from Large Language Models" [2024-09] [paper]
"A Comparative Study on Large Language Models for Log Parsing" [2024-09] [paper]
"What Information Contributes to Log-based Anomaly Detection? Insights from a Configurable Transformer-Based Approach" [2024-10] [paper]
"LogLM: From Task-based to Instruction-based Automated Log Analysis" [2024-10] [paper]
"Configuration Validation with Large Language Models" [2023-10] [paper]
"CloudEval-YAML: A Practical Benchmark for Cloud Configuration Generation" [2023-11] [paper]
"Can LLMs Configure Software Tools" [2023-12] [paper]
"LuaTaint: A Static Analysis System for Web Configuration Interface Vulnerability of Internet of Things Devices" [2024-02] [IOT] [paper]
"LLM-Based Misconfiguration Detection for AWS Serverless Computing" [2024-11] [paper]
"LogLLM: Log-based Anomaly Detection Using Large Language Models" [2024-11] [paper]
"Towards using Few-Shot Prompt Learning for Automating Model Completion" [2022-12] [paper]
"Model Generation from Requirements with LLMs: an Exploratory Study" [2024-04] [paper]
"How LLMs Aid in UML Modeling: An Exploratory Study with Novice Analysts" [2024-04] [paper]
"Leveraging Large Language Models for Software Model Completion: Results from Industrial and Public Datasets" [2024-06] [paper]
"Studying and Benchmarking Large Language Models For Log Level Suggestion" [2024-10] [paper]
"A Model Is Not Built By A Single Prompt: LLM-Based Domain Modeling With Question Decomposition" [2024-10] [paper]
"On the Utility of Domain Modeling Assistance with Large Language Models" [2024-10] [paper]
"On the use of Large Language Models in Model-Driven Engineering" [2024-10] [paper]
"LLM as a code generator in Agile Model Driven Development" [2024-10] [paper]
"A Transformer-based Approach for Abstractive Summarization of Requirements from Obligations in Software Engineering Contracts" [2023-09] [RE 2023] [paper]
"Advancing Requirements Engineering through Generative AI: Assessing the Role of LLMs" [2023-10] [paper]
"Requirements Engineering using Generative AI: Prompts and Prompting Patterns" [2023-11] [paper]
"Prioritizing Software Requirements Using Large Language Models" [2024-04] [paper]
"Lessons from the Use of Natural Language Inference (NLI) in Requirements Engineering Tasks" [2024-04] [paper]
"Enhancing Legal Compliance and Regulation Analysis with Large Language Models" [2024-04] [paper]
"MARE: Multi-Agents Collaboration Framework for Requirements Engineering" [2024-05] [paper]
"Natural Language Processing for Requirements Traceability" [2024-05] [paper]
"Multilingual Crowd-Based Requirements Engineering Using Large Language Models" [2024-08] [paper]
"From Specifications to Prompts: On the Future of Generative LLMs in Requirements Engineering" [2024-08] [paper]
"Leveraging LLMs for the Quality Assurance of Software Requirements" [2024-08] [paper]
"Generative AI for Requirements Engineering: A Systematic Literature Review" [2024-09] [paper]
"A Fine-grained Sentiment Analysis of App Reviews using Large Language Models: An Evaluation Study" [2024-09] [paper]
"Leveraging Large Language Models for Predicting Cost and Duration in Software Engineering Projects" [2024-09] [paper]
"Privacy Policy Analysis through Prompt Engineering for LLMs" [2024-09] [paper]
"Exploring Requirements Elicitation from App Store User Reviews Using Large Language Models" [2024-09] [paper]
"LLM-Cure: LLM-based Competitor User Review Analysis for Feature Enhancement" [2024-09] [paper]
"Automatic Instantiation of Assurance Cases from Patterns Using Large Language Models" [2024-10] [paper]
"Whose fault is it anyway? SILC: Safe Integration of LLM-Generated Code" [2024-10] [paper]
"Assured Automatic Programming via Large Language Models" [2024-10] [paper]
"Does GenAI Make Usability Testing Obsolete?" [2024-11] [paper]
"Exploring LLMs for Verifying Technical System Specifications Against Requirements" [2024-11] [paper]
"Towards the LLM-Based Generation of Formal Specifications from Natural-Language Contracts: Early Experiments with Symboleo" [2024-11] [paper]
"You Autocomplete Me: Poisoning Vulnerabilities in Neural Code Completion" [2021-08] [USENIX Security Symposium 2021] [paper]
"Is GitHub's Copilot as Bad as Humans at Introducing Vulnerabilities in Code?" [2022-04] [Empir.软件。 Eng.] [paper]
"Lost at C: A User Study on the Security Implications of Large Language Model Code Assistants" [2022-08] [USENIX Security Symposium 2023] [paper]
"Do Users Write More Insecure Code with AI Assistants?" [2022-1] [CCS 2023] [paper]
"Large Language Models for Code: Security Hardening and Adversarial Testing" [2023-02] [CCS 2023] [paper]
"Purple Llama CyberSecEval: A Secure Coding Benchmark for Language Models" [2023-12] [paper]
"CodeAttack: Revealing Safety Generalization Challenges of Large Language Models via Code Completion" [2024-03] [ACL 2024 Findings] [paper]
"Just another copy and paste? Comparing the security vulnerabilities of ChatGPT generated code and StackOverflow answers" [2024-03] [paper]
"DeVAIC: A Tool for Security Assessment of AI-generated Code" [2024-04] [paper]
"CyberSecEval 2: A Wide-Ranging Cybersecurity Evaluation Suite for Large Language Models" [2024-04] [paper]
"LLMs in Web-Development: Evaluating LLM-Generated PHP code unveiling vulnerabilities and limitations" [2024-04] [paper]
"Do Neutral Prompts Produce Insecure Code? FormAI-v2 Dataset: Labelling Vulnerabilities in Code Generated by Large Language Models" [2024-04] [paper]
"Codexity: Secure AI-assisted Code Generation" [2024-05] [paper]
"Measuring Impacts of Poisoning on Model Parameters and Embeddings for Large Language Models of Code" [2024-05] [paper]
"An LLM-Assisted Easy-to-Trigger Backdoor Attack on Code Completion Models: Injecting Disguised Vulnerabilities against Strong Detection" [2024-06] [paper]
"Is Your AI-Generated Code Really Secure? Evaluating Large Language Models on Secure Code Generation with CodeSecEval" [2024-07] [paper]
"Prompting Techniques for Secure Code Generation: A Systematic Investigation" [2024-07] [paper]
"TAPI: Towards Target-Specific and Adversarial Prompt Injection against Code LLMs" [2024-07] [paper]
"MaPPing Your Model: Assessing the Impact of Adversarial Attacks on LLM-based Programming Assistants" [2024-07] [paper]
"Eliminating Backdoors in Neural Code Models via Trigger Inversion" [2024-08] [paper]
""You still have to study" -- On the Security of LLM generated code" [2024-08] [paper]
"How Well Do Large Language Models Serve as End-to-End Secure Code Producers?" [2024-08] [paper]
"While GitHub Copilot Excels at Coding, Does It Ensure Responsible Output?" [2024-08] [paper]
"PromSec: Prompt Optimization for Secure Generation of Functional Source Code with Large Language Models (LLMs)" [2024-09] [paper]
"RMCBench: Benchmarking Large Language Models' Resistance to Malicious Code" [2024-09] [paper]
"Artificial-Intelligence Generated Code Considered Harmful: A Road Map for Secure and High-Quality Code Generation" [2024-09] [paper]
"Demonstration Attack against In-Context Learning for Code Intelligence" [2024-10] [paper]
"Hallucinating AI Hijacking Attack: Large Language Models and Malicious Code Recommenders" [2024-10] [paper]
"SecCodePLT: A Unified Platform for Evaluating the Security of Code GenAI" [2024-10] [paper]
"Security of Language Models for Code: A Systematic Literature Review" [2024-10] [paper]
"RedCode: Risky Code Execution and Generation Benchmark for Code Agents" [2024-11] [paper]
"ProSec: Fortifying Code LLMs with Proactive Security Alignment" [2024-11] [paper]
"An Empirical Evaluation of GitHub Copilot's Code Suggestions" [2022-05] [MSR 2022] [paper]
"Large Language Models and Simple, Stupid Bugs" [2023-03] [MSR 2023] [paper]
"Evaluating the Code Quality of AI-Assisted Code Generation Tools: An Empirical Study on GitHub Copilot, Amazon CodeWhisperer, and ChatGPT" [2023-04] [paper]
"No Need to Lift a Finger Anymore? Assessing the Quality of Code Generation by ChatGPT" [2023-08] [paper]
"The Counterfeit Conundrum: Can Code Language Models Grasp the Nuances of Their Incorrect Generations?" [2024-02] [ACL 2024 Findings] [paper]
"Bugs in Large Language Models Generated Code: An Empirical Study" [2024-03] [paper]
"ChatGPT Incorrectness Detection in Software Reviews" [2024-03] [paper]
"Validating LLM-Generated Programs with Metamorphic Prompt Testing" [2024-06] [paper]
"Where Do Large Language Models Fail When Generating Code?" [2024-06] [paper]
"GitHub Copilot: the perfect Code compLeeter?" [2024-06] [paper]
"What's Wrong with Your Code Generated by Large Language Models? An Extensive Study" [2024-07] [paper]
"Uncovering Weaknesses in Neural Code Generation" [2024-07] [paper]
"Understanding Defects in Generated Codes by Language Models" [2024-08] [paper]
"CodeSift: An LLM-Based Reference-Less Framework for Automatic Code Validation" [2024-08] [paper]
"Examination of Code generated by Large Language Models" [2024-08] [paper]
"Fixing Code Generation Errors for Large Language Models" [2024-09] [paper]
"Can OpenSource beat ChatGPT? -- A Comparative Study of Large Language Models for Text-to-Code Generation" [2024-09] [paper]
"Insights from Benchmarking Frontier Language Models on Web App Code Generation" [2024-09] [paper]
"Evaluating the Performance of Large Language Models in Competitive Programming: A Multi-Year, Multi-Grade Analysis" [2024-09] [paper]
"A Case Study of Web App Coding with OpenAI Reasoning Models" [2024-09] [paper]
"CodeJudge: Evaluating Code Generation with Large Language Models" [2024-10] [paper]
"An evaluation of LLM code generation capabilities through graded exercises" [2024-10] [paper]
"A Deep Dive Into Large Language Model Code Generation Mistakes: What and Why?" [2024-11] [paper]
"Evaluating ChatGPT-3.5 Efficiency in Solving Coding Problems of Different Complexity Levels: An Empirical Analysis" [2024-11] [paper]
"LLM4DS: Evaluating Large Language Models for Data Science Code Generation" [2024-11] [paper]
"A Preliminary Study of Multilingual Code Language Models for Code Generation Task Using Translated Benchmarks" [2024-11] [paper]
"Exploring and Evaluating Hallucinations in LLM-Powered Code Generation" [2024-04] [paper]
"CodeHalu: Code Hallucinations in LLMs Driven by Execution-based Verification" [2024-04] [paper]
"We Have a Package for You! A Comprehensive Analysis of Package Hallucinations by Code Generating LLMs" [2024-06] [paper]
"Code Hallucination" [2024-07] [paper]
"On Mitigating Code LLM Hallucinations with API Documentation" [2024-07] [paper]
"CodeMirage: Hallucinations in Code Generated by Large Language Models" [2024-08] [paper]
"LLM Hallucinations in Practical Code Generation: Phenomena, Mechanism, and Mitigation" [2024-09] [paper]
"Collu-Bench: A Benchmark for Predicting Language Model Hallucinations in Code" [2024-10] [paper]
"ETF: An Entity Tracing Framework for Hallucination Detection in Code Summaries" [2024-10] [paper]
"On Evaluating the Efficiency of Source Code Generated by LLMs" [2024-04] [paper]
"A Controlled Experiment on the Energy Efficiency of the Source Code Generated by Code Llama" [2024-05] [paper]
"From Effectiveness to Efficiency: Comparative Evaluation of Code Generated by LCGMs for Bilingual Programming Questions" [2024-06] [paper]
"How Efficient is LLM-Generated Code? A Rigorous & High-Standard Benchmark" [2024-06] [paper]
"ECCO: Can We Improve Model-Generated Code Efficiency Without Sacrificing Functional Correctness?" [2024-07] [paper]
"A Performance Study of LLM-Generated Code on Leetcode" [2024-07] [paper]
"Evaluating Language Models for Efficient Code Generation" [2024-08] [paper]
"Effi-Code: Unleashing Code Efficiency in Language Models" [2024-10] [paper]
"Rethinking Code Refinement: Learning to Judge Code Efficiency" [2024-10] [paper]
"Generating Energy-efficient code with LLMs" [2024-11] [paper]
"An exploration of the effect of quantisation on energy consumption and inference time of StarCoder2" [2024-11] [paper]
"Beyond Accuracy: Evaluating Self-Consistency of Code Large Language Models with IdentityChain" [2023-10] [paper]
"Do Large Code Models Understand Programming Concepts? A Black-box Approach" [2024-02] [ICML 2024] [paper]
"Syntactic Robustness for LLM-based Code Generation" [2024-04] [paper]
"NLPerturbator: Studying the Robustness of Code LLMs to Natural Language Variations" [2024-06] [paper]
"An Empirical Study on Capability of Large Language Models in Understanding Code Semantics" [2024-07] [paper]
"Comparing Robustness Against Adversarial Attacks in Code Generation: LLM-Generated vs. Human-Written" [2024-11] [paper]
"A Critical Study of What Code-LLMs (Do Not) Learn" [2024-06] [ACL 2024 Findings] [paper]
"Looking into Black Box Code Language Models" [2024-07] [paper]
"DeepCodeProbe: Towards Understanding What Models Trained on Code Learn" [2024-07] [paper]
"Towards More Trustworthy and Interpretable LLMs for Code through Syntax-Grounded Explanations" [2024-07] [paper]
"How and Why LLMs Use Deprecated APIs in Code Completion? An Empirical Study" [2024-06] [paper]
"Is ChatGPT a Good Software Librarian? An Exploratory Study on the Use of ChatGPT for Software Library Recommendations" [2024-08] [paper]
"A Systematic Evaluation of Large Code Models in API Suggestion: When, Which, and How" [2024-09] [paper]
"AutoAPIEval: A Framework for Automated Evaluation of LLMs in API-Oriented Code Generation" [2024-09] [paper]
"Does Your Neural Code Completion Model Use My Code? A Membership Inference Approach" [2024-04] [paper]
"CodeCipher: Learning to Obfuscate Source Code Against LLMs" [2024-10] [paper]
"Decoding Secret Memorization in Code LLMs Through Token-Level Characterization" [2024-10] [paper]
"Exploring Multi-Lingual Bias of Large Code Models in Code Generation" [2024-04] [paper]
"Mitigating Gender Bias in Code Large Language Models via Model Editing" [2024-10] [paper]
"Bias Unveiled: Investigating Social Bias in LLM-Generated Code" [2024-11] [paper]
"Zero-Shot Detection of Machine-Generated Codes" [2023-10] [paper]
"CodeIP: A Grammar-Guided Multi-Bit Watermark for Large Language Models of Code" [2024-04] [paper]
"ChatGPT Code Detection: Techniques for Uncovering the Source of Code" [2024-05] [paper]
"Uncovering LLM-Generated Code: A Zero-Shot Synthetic Code Detector via Code Rewriting" [2024-05] [paper]
"Automatic Detection of LLM-generated Code: A Case Study of Claude 3 Haiku" [2024-09] [paper]
"An Empirical Study on Automatically Detecting AI-Generated Source Code: How Far Are We?" [2024-11] [paper]
"Distinguishing LLM-generated from Human-written Code by Contrastive Learning" [2024-11] [paper]
"Who Wrote this Code? Watermarking for Code Generation" [2023-05] [ACL 2024] [paper]
"Testing the Effect of Code Documentation on Large Language Model Code Understanding" [2024-04] [paper]
"Automated Creation of Source Code Variants of a Cryptographic Hash Function Implementation Using Generative Pre-Trained Transformer Models" [2024-04] [paper]
"Evaluation of the Programming Skills of Large Language Models" [2024-05] [paper]
"Where Are Large Language Models for Code Generation on GitHub?" [2024-06] [paper]
"Beyond Functional Correctness: Investigating Coding Style Inconsistencies in Large Language Models" [2024-06] [paper]
"Benchmarking Language Model Creativity: A Case Study on Code Generation" [2024-07] [paper]
"Beyond Correctness: Benchmarking Multi-dimensional Code Generation for Large Language Models" [2024-07] [paper]
"Is Functional Correctness Enough to Evaluate Code Language Models? Exploring Diversity of Generated Codes" [2024-08] [paper]
"Strategic Optimization and Challenges of Large Language Models in Object-Oriented Programming" [2024-08] [paper]
"A Survey on Evaluating Large Language Models in Code Generation Tasks" [2024-08] [paper]
"An exploratory analysis of Community-based Question-Answering Platforms and GPT-3-driven Generative AI: Is it the end of online community-based learning?" [2024-09] [paper]
"Code Generation and Algorithmic Problem Solving Using Llama 3.1 405B" [2024-09] [paper]
"Benchmarking ChatGPT, Codeium, and GitHub Copilot: A Comparative Study of AI-Driven Programming and Debugging Assistants" [2024-09] [paper]
"Model Editing for LLMs4Code: How Far are We?" [2024-11] [paper]
"An Empirical Study on LLM-based Agents for Automated Bug Fixing" [2024-11] [paper]
"Precision or Peril: Evaluating Code Quality from Quantized Large Language Models" [2024-11] [paper]
"Expectation vs. Experience: Evaluating the Usability of Code Generation Tools Powered by Large Language Models" [2022-04] [CHI EA 2022] [paper]
"Grounded Copilot: How Programmers Interact with Code-Generating Models" [2022-06] [OOPSLA 2023] [paper]
"Reading Between the Lines: Modeling User Behavior and Costs in AI-Assisted Programming" [2022-10] [paper]
"The Impact of AI on Developer Productivity: Evidence from GitHub Copilot" [2023-02] [paper]
"The Programmer's Assistant: Conversational Interaction with a Large Language Model for Software Development" [2023-02] [IUI 2023] [paper]
""It's Weird That it Knows What I Want": Usability and Interactions with Copilot for Novice Programmers" [2023-04] [ACM TCHI] [paper]
"DevGPT: Studying Developer-ChatGPT Conversations" [2023-08] [paper]
"How Do Analysts Understand and Verify AI-Assisted Data Analyses?" [2023-09] [paper]
"How Novices Use LLM-Based Code Generators to Solve CS1 Coding Tasks in a Self-Paced Learning Environment" [2023-09] [Koli Calling 2023] [paper]
"Conversational Challenges in AI-Powered Data Science: Obstacles, Needs, and Design Opportunities" [2023-10] [paper]
"The RealHumanEval: Evaluating Large Language Models' Abilities to Support Programmers" [2024-04] [paper]
"Unlocking Adaptive User Experience with Generative AI" [2024-04] [paper]
"BISCUIT: Scaffolding LLM-Generated Code with Ephemeral UIs in Computational Notebooks" [2024-04] [paper]
"How far are AI-powered programming assistants from meeting developers' needs?" [2024-04] [paper]
"Beyond Code Generation: An Observational Study of ChatGPT Usage in Software Engineering Practice" [2024-04] [paper]
"The GPT Surprise: Offering Large Language Model Chat in a Massive Coding Class Reduced Engagement but Increased Adopters Exam Performances" [2024-04] [paper]
"amplified.dev: a living document that begins to sketch a vision for a future where developers are amplified, not automated" [2024-05] [paper]
"Sketch Then Generate: Providing Incremental User Feedback and Guiding LLM Code Generation through Language-Oriented Code Sketches" [2024-05] [paper]
"Using AI Assistants in Software Development: A Qualitative Study on Security Practices and Concerns" [2024-05] [paper]
"Full Line Code Completion: Bringing AI to Desktop" [2024-05] [paper]
"Developers' Perceptions on the Impact of ChatGPT in Software Development: A Survey" [2024-05] [paper]
"A Transformer-Based Approach for Smart Invocation of Automatic Code Completion" [2024-05] [paper]
"A Study on Developer Behaviors for Validating and Repairing LLM-Generated Code Using Eye Tracking and IDE Actions" [2024-05] [paper]
"Analyzing Chat Protocols of Novice Programmers Solving Introductory Programming Tasks with ChatGPT" [2024-05] [paper]
"Benchmarking the Communication Competence of Code Generation for LLMs and LLM Agent" [2024-05] [paper]
"Learning Task Decomposition to Assist Humans in Competitive Programming" [2024-06] [ACL 2024] [paper]
"Impact of AI-tooling on the Engineering Workspace" [2024-06] [paper]
"Using AI-Based Coding Assistants in Practice: State of Affairs, Perceptions, and Ways Forward" [2024-06] [paper]
"Instruct, Not Assist: LLM-based Multi-Turn Planning and Hierarchical Questioning for Socratic Code Debugging" [2024-06] [paper]
"Transforming Software Development: Evaluating the Efficiency and Challenges of GitHub Copilot in Real-World Projects" [2024-06] [paper]
"Let the Code LLM Edit Itself When You Edit the Code" [2024-07] [paper]
"Enhancing Computer Programming Education with LLMs: A Study on Effective Prompt Engineering for Python Code Generation" [2024-07] [paper]
"How Novice Programmers Use and Experience ChatGPT when Solving Programming Exercises in an Introductory Course" [2024-07] [paper]
"Can Developers Prompt? A Controlled Experiment for Code Documentation Generation" [2024-08] [paper]
"The Impact of Generative AI-Powered Code Generation Tools on Software Engineer Hiring: Recruiters' Experiences, Perceptions, and Strategies" [2024-09] [paper]
"Investigating the Role of Cultural Values in Adopting Large Language Models for Software Engineering" [2024-09] [paper]
"The Impact of Large Language Models on Open-source Innovation: Evidence from GitHub Copilot" [2024-09] [paper]
""I Don't Use AI for Everything": Exploring Utility, Attitude, and Responsibility of AI-empowered Tools in Software Development" [2024-09] [paper]
"Harnessing the Potential of Gen-AI Coding Assistants in Public Sector Software Development" [2024-09] [paper]
"Understanding the Human-LLM Dynamic: A Literature Survey of LLM Use in Programming Tasks" [2024-10] [paper]
"Code-Survey: An LLM-Driven Methodology for Analyzing Large-Scale Codebases" [2024-10] [paper]
"The potential of LLM-generated reports in DevSecOps" [2024-10] [paper]
"The Impact of Generative AI on Collaborative Open-Source Software Development: Evidence from GitHub Copilot" [2024-10] [paper]
"Exploring the Design Space of Cognitive Engagement Techniques with AI-Generated Code for Enhanced Learning" [2024-10] [paper]
"One Step at a Time: Combining LLMs and Static Analysis to Generate Next-Step Hints for Programming Tasks" [2024-10] [paper]
"UniAutoML: A Human-Centered Framework for Unified Discriminative and Generative AutoML with Large Language Models" [2024-10] [paper]
"How much does AI impact development speed? An enterprise-based randomized controlled trial" [2024-10] [paper]
"Understanding the Effect of Algorithm Transparency of Model Explanations in Text-to-SQL Semantic Parsing" [2024-10] [paper]
"Dear Diary: A randomized controlled trial of Generative AI coding tools in the workplace" [2024-10] [paper]
"LLMs are Imperfect, Then What? An Empirical Study on LLM Failures in Software Engineering" [2024-11] [paper]
"Human-In-the-Loop Software Development Agents" [2024-11] [paper]
CodeSearchNet : "CodeSearchNet Challenge: Evaluating the State of Semantic Code Search" [2019-09] [paper] [repo] [data]
The Pile : "The Pile: An 800GB Dataset of Diverse Text for Language Modeling" [2020-12], [paper] [data]
CodeParrot , 2022-02, [data]
The Stack : "The Stack: 3 TB of permissively licensed source code" [2022-11] [paper] [data]
ROOTS : "The BigScience ROOTS Corpus: A 1.6TB Composite Multilingual Dataset" [2023-03] [NeurIPS 2022 Datasets and Benchmarks Track] [paper] [data]
The Stack v2 : "StarCoder 2 and The Stack v2: The Next Generation" [2024-02] [paper] [data]
CodeXGLUE : "CodeXGLUE: A Machine Learning Benchmark Dataset for Code Understanding and Generation" [2021-02] [NeurIPS Datasets and Benchmarks 2021] [paper] [repo] [data]
CodefuseEval : "CodeFuse-13B: A Pretrained Multi-lingual Code Large Language Model" [2023-10] [paper] [repo]
CodeScope : "CodeScope: An Execution-based Multilingual Multitask Multidimensional Benchmark for Evaluating LLMs on Code Understanding and Generation" [2023-11] [ACL 2024] [paper] [repo]
CodeEditorBench : "CodeEditorBench: Evaluating Code Editing Capability of Large Language Models" [2024-04] [paper] [repo]
Long Code Arena : "Long Code Arena: a Set of Benchmarks for Long-Context Code Models" [2024-06] [paper] [repo]
CodeRAG-Bench : "CodeRAG-Bench: Can Retrieval Augment Code Generation?" [2024-06] [paper] [repo]
LiveBench : "LiveBench: A Challenging, Contamination-Free LLM Benchmark" [2024-06] [paper] [repo]
DebugEval : "Enhancing the Code Debugging Ability of LLMs via Communicative Agent Based Data Refinement" [2024-08] [paper] [repo]
| 日期 | 场地 | 基准 | 尺寸 | 语言 | 来源 |
|---|---|---|---|---|---|
| 2018-02 | LREC 2018 | NL2Bash | 9305 | bash | "NL2Bash: A Corpus and Semantic Parser for Natural Language Interface to the Linux Operating System" [paper] [data] |
| 2018-08 | EMNLP 2018 | CONCODE | 104k | 爪哇 | "Mapping Language to Code in Programmatic Context" [paper] [data] |
| 2019-10 | EMNLP-IJCNLP 2019 | 汁 | 1.5M/3725 * | Python | "JuICe: A Large Scale Distantly Supervised Dataset for Open Domain Context-based Code Generation" [paper] [data] |
| 2021-05 | NeurIPS 2021 | 应用 | 10000 | Python | "Measuring Coding Challenge Competence With APPS" [paper] [data] |
| 2021-07 | arxiv | 人类 | 164 | Python | "Evaluating Large Language Models Trained on Code" [paper] [data] |
| 2021-08 | arxiv | MBPP/MathQA-Python | 974/23914 | Python | "Program Synthesis with Large Language Models" [paper] [MBPP] [MathQA-Python] |
| 2021-08 | ACL/IJCNLP 2021 | PlotCoder | 40797 | Python | "PlotCoder: Hierarchical Decoding for Synthesizing Visualization Code in Programmatic Context" [paper] [data] |
| 2022-01 | arxiv | DSP | 1119 | Python | "Training and Evaluating a Jupyter Notebook Data Science Assistant" [paper] [data] |
| 2022-02 | 科学 | CodeContests | 13610 | C++, Python, Java | "Competition-Level Code Generation with AlphaCode" [paper] [data] |
| 2022-03 | EACL 2023 Findings | MCoNaLa | 896 | Python | "MCoNaLa: A Benchmark for Code Generation from Multiple Natural Languages" [paper] [data] |
| 2022-06 | arxiv | AixBench | 336 | 爪哇 | "AixBench: A Code Generation Benchmark Dataset" [paper] [data] |
| 2022-08 | IEEE Trans。软件工程 | 多种的 | "MultiPL-E: A Scalable and Extensible Approach to Benchmarking Neural Code Generation", [paper] [data] | ||
| 2022-10 | ICLR 2023 | MBXP | 12.4k | Python, Java, JS, TypeScript, Go, C#, PHP, Ruby, Kotlin, C++, Perl, Scala, Swift | "Multi-lingual Evaluation of Code Generation Models" [paper] [data] |
| 2022-10 | ICLR 2023 | Multilingual HumanEval | 1.9k | Python, Java, JS, TypeScript, Go, C#, PHP, Ruby, Kotlin, Perl, Scala, Swift | "Multi-lingual Evaluation of Code Generation Models" [paper] [data] |
| 2022-10 | ICLR 2023 | MathQA-X | 5.6k | Python, Java, JS | "Multi-lingual Evaluation of Code Generation Models" [paper] [data] |
| 2022-11 | arxiv | ExeDS | 534 | Python | "Execution-based Evaluation for Data Science Code Generation Models" [paper] [data] |
| 2022-11 | arxiv | DS-1000 | 1000 | Python | "DS-1000: A Natural and Reliable Benchmark for Data Science Code Generation" [paper] [data] |
| 2022-12 | arxiv | Odex | 945 | Python | "Execution-Based Evaluation for Open-Domain Code Generation" [paper] [data] |
| 2023-02 | arxiv | CoderEval | 460 | Python, Java | "CoderEval: A Benchmark of Pragmatic Code Generation with Generative Pre-trained Models" [paper] [data] |
| 2023-03 | ACL 2024 | Xcodeeval | 5.5m | C, C#, C++, Go, Java, JS, Kotlin, PHP, Python, Ruby, Rust | "XCodeEval: An Execution-based Large Scale Multilingual Multitask Benchmark for Code Understanding, Generation, Translation and Retrieval" [paper] [data] |
| 2023-03 | arxiv | HumanEval-X | 820 | Python, C++, Java, JS, Go | "CodeGeeX: A Pre-Trained Model for Code Generation with Multilingual Evaluations on HumanEval-X" [paper] [data] |
| 2023-05 | arxiv | 人类事件+ | 164 | Python | "Is Your Code Generated by ChatGPT Really Correct? Rigorous Evaluation of Large Language Models for Code Generation" [paper] [data] |
| 2023-06 | ACL 2024调查结果 | StudentEval | 1749年 | Python | "StudentEval: A Benchmark of Student-Written Prompts for Large Language Models of Code" [paper] [data] |
| 2023-08 | ICLR 2024 Spotlight | HumanEvalPack | 984 | Python, JS, Go, Java, C++, Rust | "OctoPack: Instruction Tuning Code Large Language Models" [paper] [data] |
| 2023-06 | 神经2023 | DotPrompts | 10538 | 爪哇 | "Guiding Language Models of Code with Global Context using Monitors" [paper] [data] |
| 2023-09 | arxiv | CodeApex | 476 | C ++ | "CodeApex: A Bilingual Programming Evaluation Benchmark for Large Language Models" [paper] [data] |
| 2023-09 | arxiv | VerilogEval | 8645/156 | Verilog | "VerilogEval: Evaluating Large Language Models for Verilog Code Generation" [paper] [data] |
| 2023-11 | arxiv | ML-Bench | 10040 | bash | "ML-Bench: Large Language Models Leverage Open-source Libraries for Machine Learning Tasks" [paper] [data] |
| 2023-12 | arxiv | 炸玉米饼 | 26,433 | Python | "TACO: Topics in Algorithmic COde generation dataset" [paper] [data] |
| 2024-01 | HPDC | ParEval | 420 | C++, CUDA, HIP | "Can Large Language Models Write Parallel Code?" [paper] [data] |
| 2024-02 | ACL 2024调查结果 | 哎呀 | 431 | Python | "OOP: Object-Oriented Programming Evaluation Benchmark for Large Language Models" [paper] [data] |
| 2024-02 | LREC-COLING 2024 | HumanEval-XL | 22080 | 23NL, 12PL | "HumanEval-XL: A Multilingual Code Generation Benchmark for Cross-lingual Natural Language Generalization" [paper] [data] |
| 2024-04 | arxiv | USACO | 307 | Python | "Can Language Models Solve Olympiad Programming?" [paper] [data] |
| 2024-04 | LREC-COLING 2024 | PECC | 2396 | Python | "PECC: Problem Extraction and Coding Challenges" [paper] [data] |
| 2024-04 | arxiv | CodeGuard+ | 23 | Python, C | "Constrained Decoding for Secure Code Generation" [paper] [data] |
| 2024-05 | ACL 2024调查结果 | NaturalCodeBench | 402 | Python, Java | "NaturalCodeBench: Examining Coding Performance Mismatch on HumanEval and Natural User Prompts" [paper] [data] |
| 2024-05 | arxiv | MHPP | 140 | Python | "MHPP: Exploring the Capabilities and Limitations of Language Models Beyond Basic Code Generation" [paper] [repo] |
| 2024-06 | arxiv | VHDL-Eval | 202 | VHDL | "VHDL-Eval: A Framework for Evaluating Large Language Models in VHDL Code Generation" [paper] |
| 2024-06 | arxiv | AICoderEval | 492 | Python | "AICoderEval: Improving AI Domain Code Generation of Large Language Models" [paper] [data] |
| 2024-06 | arxiv | VersiCode | 98,692 | Python | "VersiCode: Towards Version-controllable Code Generation" [paper] [data] |
| 2024-06 | IEEE AITest 2024 | ScenEval | 12,864 | 爪哇 | "ScenEval: A Benchmark for Scenario-Based Evaluation of Code Generation" [paper] |
| 2024-06 | arxiv | BigCodeBench | 1,140 | Python | "BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions" [paper] [data] |
| 2024-07 | arxiv | CodeUpdateArena | 670 | Python | "CodeUpdateArena: Benchmarking Knowledge Editing on API Updates" [paper] [data] |
| 2024-07 | arxiv | LBPP | 161 | Python | "On Leakage of Code Generation Evaluation Datasets" [paper] [data] |
| 2024-07 | arxiv | NoviCode | 150 | Python | "NoviCode: Generating Programs from Natural Language Utterances by Novices" [paper] [data] |
| 2024-07 | arxiv | Case2Code | 1.3m | Python | "Case2Code: Learning Inductive Reasoning with Synthetic Data" [paper] [data] |
| 2024-07 | arxiv | SciCode | 338 | Python | "SciCode: A Research Coding Benchmark Curated by Scientists" [paper] [data] |
| 2024-07 | arxiv | auto-regression | 460 | Python | "Generating Unseen Code Tests In Infinitum" [paper] |
| 2024-07 | arxiv | WebApp1K | 1000 | JavaScript | "WebApp1K: A Practical Code-Generation Benchmark for Web App Development" [paper] [data] |
| 2024-08 | ACL 2024调查结果 | CodeInsight | 3409 | Python | "CodeInsight: A Curated Dataset of Practical Coding Solutions from Stack Overflow" [paper] [data] |
| 2024-08 | arxiv | DomainEval | 2454 | Python | "DOMAINEVAL: An Auto-Constructed Benchmark for Multi-Domain Code Generation" [paper] [data] |
| 2024-09 | arxiv | 复杂的codeeval | 7184/3897 | Python/Java | "ComplexCodeEval: A Benchmark for Evaluating Large Code Models on More Complex Code" [paper] [data] |
| 2024-09 | ASE 2024 | CoCoNote | 58221 | Python Notebook | "Contextualized Data-Wrangling Code Generation in Computational Notebooks" [paper] [data] |
| 2024-10 | arxiv | 未命名 | 77 | Python | "Evaluation of Code LLMs on Geospatial Code Generation" [paper] [data] |
| 2024-10 | arxiv | mHumanEval | 836,400 | 25PL, 204NL | "mHumanEval -- A Multilingual Benchmark to Evaluate Large Language Models for Code Generation" [paper] [data] |
| 2024-10 | arxiv | FeatEng | 103 | Python | "Can Models Help Us Create Better Models? Evaluating LLMs as Data Scientists" [paper] [data] |
| 2024-11 | arxiv | GitChameleon | 116 | Python | "GitChameleon: Unmasking the Version-Switching Capabilities of Code Generation Models" [paper] [data] |
* Automatically mined/human-annotated
| 日期 | 场地 | 基准 | 尺寸 | 语言 | 来源 |
|---|---|---|---|---|---|
| 2024-04 | arxiv | MMCode | 3548 | Python | "MMCode: Evaluating Multi-Modal Code Large Language Models with Visually Rich Programming Problems" [paper] [data] |
| 2024-05 | arxiv | Plot2Code | 132 | Python | "Plot2Code: A Comprehensive Benchmark for Evaluating Multi-modal Large Language Models in Code Generation from Scientific Plots" [paper] [data] |
| 2024-06 | arxiv | ChartMimic | 1000 | Python | "ChartMimic: Evaluating LMM's Cross-Modal Reasoning Capability via Chart-to-Code Generation" [paper] [data] |
| 2024-10 | arxiv | HumanEval-V | 108 | Python | "HumanEval-V: Evaluating Visual Understanding and Reasoning Abilities of Large Multimodal Models Through Coding Tasks" [paper] [data] |
| 2024-10 | arxiv | TurtleBench | 260 | Python | "TurtleBench: A Visual Programming Benchmark in Turtle Geometry" [paper] [data] |
| 日期 | 场地 | 基准 | 尺寸 | 语言 | 来源 |
|---|---|---|---|---|---|
| 2021-09 | EMNLP 2021 Findings | codeqa | 120K/70K | Java/Python | "CodeQA: A Question Answering Dataset for Source Code Comprehension" [paper] [data] |
| 2022-10 | NAACL 2022 | CS1QA | 9237 | Python | "CS1QA: A Dataset for Assisting Code-based Question Answering in an Introductory Programming Course" [paper] [data] |
| 2023-09 | arxiv | CodeApex | 250 | C ++ | "CodeApex: A Bilingual Programming Evaluation Benchmark for Large Language Models" [paper] [data] |
| 2024-01 | ICML 2024 | CRUXEval | 800 | Python | "CRUXEval: A Benchmark for Code Reasoning, Understanding and Execution" [paper] [data] |
| 2024-05 | arxiv | PythonIO | 2650 | Python | "Multiple-Choice Questions are Efficient and Robust LLM Evaluators" [paper] [data] |
| 2024-05 | arxiv | StaCCQA | 270k | Python | "Aligning LLMs through Multi-perspective User Preference Ranking-based Feedback for Programming Question Answering" [paper] [data] |
| 2024-06 | arxiv | RepoQA | 500 | Python, C++, Java, Rust, TypeScript | "RepoQA: Evaluating Long Context Code Understanding" [paper] [data] |
| 2024-08 | arxiv | CruxEval-X | 12.6k | 19 | "CRUXEval-X: A Benchmark for Multilingual Code Reasoning, Understanding and Execution" [paper] [data] |
| 2024-09 | arxiv | SpecEval | 204 | 爪哇 | "SpecEval: Evaluating Code Comprehension in Large Language Models via Program Specifications" [paper] [data] |
| 2024-10 | arxiv | CodeMMLU | 19912 | 13 | "CodeMMLU: A Multi-Task Benchmark for Assessing Code Understanding Capabilities of CodeLLMs" [paper] [data] |
| 2024-11 | arxiv | 未命名 | 80232 | Python | "Leveraging Large Language Models in Code Question Answering: Baselines and Issues" [paper] [data] |
| 日期 | 场地 | 基准 | 尺寸 | 语言 | 来源 |
|---|---|---|---|---|---|
| 2017-08 | arxiv | WikiSQL | 80654 | "Seq2SQL: Generating Structured Queries from Natural Language using Reinforcement Learning" [paper] [data] | |
| 2018-06 | CL 2018 | 建议 | 4570 | "Improving Text-to-SQL Evaluation Methodology" [paper] [data] | |
| 2018-09 | EMNLP 2018 | 蜘蛛 | 10181 | "Spider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text-to-SQL Task" [paper] [data] | |
| 2019-06 | ACL 2019 | SParC | 12726 | "SParC: Cross-Domain Semantic Parsing in Context" [paper] [data] | |
| 2019-07 | WWW 2020 | MIMICSQL | 10000 | "Text-to-SQL Generation for Question Answering on Electronic Medical Records" [paper] [data] | |
| 2019-09 | EMNLP-IJCNLP 2019 | CoSQL | 15598 | "CoSQL: A Conversational Text-to-SQL Challenge Towards Cross-Domain Natural Language Interfaces to Databases" [paper] [data] | |
| 2020-05 | LREC 2020 | Criteria-to-SQL | 2003 | "Dataset and Enhanced Model for Eligibility Criteria-to-SQL Semantic Parsing" [paper] [data] | |
| 2020-10 | EMNLP 2020 Findings | quall | 11276 | "On the Potential of Lexico-logical Alignments for Semantic Parsing to SQL Queries" [paper] [data] | |
| 2020-10 | NAACL-HLT 2021 | 蜘蛛现实 | 508 | "Structure-Grounded Pretraining for Text-to-SQL" [paper] [data] | |
| 2021-06 | ACL/IJCNLP 2021 | Spider-Syn | 8034 | "Towards Robustness of Text-to-SQL Models against Synonym Substitution" [paper] [data] | |
| 2021-06 | NLP4Prog 2021 | 塞特 | 12023 | "Text-to-SQL in the Wild: A Naturally-Occurring Dataset Based on Stack Exchange Data" [paper] [data] | |
| 2021-06 | ACL/IJCNLP 2021 | KaggleDBQA | 400 | "KaggleDBQA: Realistic Evaluation of Text-to-SQL Parsers" [paper] [data] | |
| 2021-09 | emnlp | Spider-DK | 535 | "Exploring Underexplored Limitations of Cross-Domain Text-to-SQL Generalization" [paper] [data] | |
| 2022-05 | NAACL 2022 Findings | Spider-SS/CG | 8034/45599 | "Measuring and Improving Compositional Generalization in Text-to-SQL via Component Alignment" [paper] [data] | |
| 2023-05 | arxiv | 鸟 | 12751 | "Can LLM Already Serve as A Database Interface? A BIg Bench for Large-Scale Database Grounded Text-to-SQLs" [paper] [data] | |
| 2023-06 | ACL 2023 | XSemPLR | 24.4k | "XSemPLR: Cross-Lingual Semantic Parsing in Multiple Natural Languages and Meaning Representations" [paper] [data] | |
| 2024-05 | ACL 2024调查结果 | EHR-SeqSQL | 31669 | "EHR-SeqSQL : A Sequential Text-to-SQL Dataset For Interactively Exploring Electronic Health Records" [paper] | |
| 2024-06 | NAACL 2024 | BookSQL | 100k | "BookSQL: A Large Scale Text-to-SQL Dataset for Accounting Domain" [paper] [data] | |
| 2024-08 | ACL 2024调查结果 | MultiSQL | 9257 | "MultiSQL: A Schema-Integrated Context-Dependent Text2SQL Dataset with Diverse SQL Operations" [paper] [data] | |
| 2024-09 | arxiv | 海狸 | 93 | "BEAVER: An Enterprise Benchmark for Text-to-SQL" [paper] | |
| 2024-10 | arxiv | PRACTIQ | 2812 | "PRACTIQ: A Practical Conversational Text-to-SQL dataset with Ambiguous and Unanswerable Queries" [paper] | |
| 2024-10 | arxiv | bis | 239 | "BIS: NL2SQL Service Evaluation Benchmark for Business Intelligence Scenarios" [paper] [data] | |
| 2024-11 | arxiv | 蜘蛛2.0 | 632 | "Spider 2.0: Evaluating Language Models on Real-World Enterprise Text-to-SQL Workflows" [paper] [data] |
| 日期 | 场地 | 基准 | 尺寸 | 语言 | 来源 |
|---|---|---|---|---|---|
| 2020-06 | 神经2020 | Transcoder GeeksforGeeks | 1.4k | C++, Java, Python | "Unsupervised Translation of Programming Languages" [paper] [data] |
| 2021-02 | NeurIPS Datasets and Benchmarks 2021 | CodeTrans | 11.8k | Java, C# | "CodeXGLUE: A Machine Learning Benchmark Dataset for Code Understanding and Generation" [paper] [data] |
| 2021-08 | ACL 2023 Findings | 头像 | 9515 | Java,Python | "AVATAR: A Parallel Corpus for Java-Python Program Translation" [paper] [data] |
| 2022-06 | AAAI 2022 | 成本 | 132k | C++, Java, Python, C#, JS, PHP, C | "Multilingual Code Snippets Training for Program Translation" [paper] [data] |
| 2022-06 | arxiv | XLCoST | 567k | C++, Java, Python, C#, JS, PHP, C | "XLCoST: A Benchmark Dataset for Cross-lingual Code Intelligence" [paper] [data] |
| 2023-03 | arxiv | Xcodeeval | 5.6m | C, C#, C++, Go, Java, JS, Kotlin, PHP, Python, Ruby, Rust | "xCodeEval: A Large Scale Multilingual Multitask Benchmark for Code Understanding, Generation, Translation and Retrieval" [paper] [data] |
| 2023-03 | arxiv | HumanEval-X | 1640年 | Python, C++, Java, JS, Go | "CodeGeeX: A Pre-Trained Model for Code Generation with Multilingual Evaluations on HumanEval-X" [paper] [data] |
| 2023-08 | arxiv | G-TransEval | 4000 | C++, Java, C#, JS, Python | "On the Evaluation of Neural Code Translation: Taxonomy and Benchmark" [paper] [data] |
| 2023-10 | arxiv | codetransocean | 270.5K | 45 | "CodeTransOcean: A Comprehensive Multilingual Benchmark for Code Translation" [paper] [data] |
| 2024-11 | arxiv | Classeval-T | 94 | Python, Java, C++ | "Escalating LLM-based Code Translation Benchmarking into the Class-level Era" [paper] |
| 2024-11 | arxiv | RustRepoTrans | 375 | C++, Java, Python, Rust | "Repository-level Code Translation Benchmark Targeting Rust" [paper] [data] |
| 日期 | 场地 | 基准 | 尺寸 | 语言 | 来源 |
|---|---|---|---|---|---|
| 2014-07 | ISSTA 2014 | 缺陷4J | 357 | 爪哇 | "Defects4J: A Database of Existing Faults to Enable Controlled Testing Studies for Java Programs" [paper] [data] |
| 2015-12 | IEEE Trans。软件工程 | ManyBugs/IntroClass | 185/998 | c | "The ManyBugs and IntroClass Benchmarks for Automated Repair of C Programs" [paper] [data] |
| 2016-11 | FSE 2016 | BugAID | 105k | JS | "Discovering Bug Patterns in JavaScript" [paper] [data] |
| 2017-02 | AAAI 2017 | DeepFix | 6971 | c | "DeepFix: Fixing Common C Language Errors by Deep Learning" [paper] [data] |
| 2017-05 | ICSE-C 2017 | Codeflaws | 3902 | c | "DeepFix: Fixing Common C Language Errors by Deep Learning" [paper] [data] |
| 2017-10 | SPLASH 2017 | QuixBugs | 80 | Java,Python | "QuixBugs: a multi-lingual program repair benchmark set based on the quixey challenge" [paper] [data] |
| 2018-05 | MSR 2018 | Bugs.jar | 1158 | 爪哇 | "Bugs.jar: a large-scale, diverse dataset of real-world Java bugs" [paper] [data] |
| 2018-12 | ACM Trans。软件。工程。 methodol。 | BFP | 124k | 爪哇 | "An Empirical Study on Learning Bug-Fixing Patches in the Wild via Neural Machine Translation" [paper] [data] |
| 2019-01 | SANER 2019 | 熊 | 251 | 爪哇 | "Bears: An Extensible Java Bug Benchmark for Automatic Program Repair Studies" [paper] [data] |
| 2019-01 | ICSE 2019 | 未命名 | 21.8K * | 爪哇 | "On Learning Meaningful Code Changes via Neural Machine Translation" [paper] [data] |
| 2019-04 | ICST 2019 | BugsJS | 453 | JS | "BugsJS: a Benchmark of JavaScript Bugs" [paper] [data] |
| 2019-05 | ICSE 2019 | BugSwarm | 1827/1264 | Java/Python | "BugSwarm: mining and continuously growing a dataset of reproducible failures and fixes" [paper] [data] |
| 2019-05 | ICSE 2019 | CPatMiner | 17K * | 爪哇 | "Graph-based mining of in-the-wild, fine-grained, semantic code change patterns" [paper] [data] |
| 2019-05 | MSR 2020 | ManySStuBs4J | 154K | 爪哇 | "How Often Do Single-Statement Bugs Occur? The ManySStuBs4J Dataset" [paper] [data] |
| 2019-11 | ASE 2019 | re依 | 1783年 | Python | "Re-factoring based program repair applied to programming assignments" [paper] [data] |
| 2020-07 | ISSTA 2020 | 椰子 | 24m | Java, Python, C, JS | "CoCoNuT: combining context-aware neural translation models using ensemble for program repair" [paper] [data] |
| 2020-10 | inf。软件。技术。 | Review4Repair | 58021 | 爪哇 | "Review4Repair: Code Review Aided Automatic Program Repairing" [paper] [data] |
| 2020-11 | ESEC/FSE 2020 | BugsInPy | 493 | Python | "BugsInPy: A Database of Existing Bugs in Python Programs to Enable Controlled Testing and Debugging Studies" [paper] [data] |
| 2021-07 | ICML 2021 | TFix | 105k | JS | "TFix: Learning to Fix Coding Errors with a Text-to-Text Transformer" [paper] [data] |
| 2021-08 | arxiv | Megadiff | 663K * | 爪哇 | "Megadiff: A Dataset of 600k Java Source Code Changes Categorized by Diff Size" [paper] [data] |
| 2022-01 | SSB/TSSB | MSR 2022 | 9M/3M | Python | "TSSB-3M: Mining single statement bugs at massive scale" [paper] [data] |
| 2022-10 | MSR 2022 | FixJS | 324k | JS | "FixJS: a dataset of bug-fixing JavaScript commits" [paper] [data] |
| 2022-11 | ESEC/FSE 2022 | TypeBugs | 93 | Python | "PyTER: Effective Program Repair for Python Type Errors" [paper] [data] |
| 2023-03 | arxiv | Xcodeeval | 4.7m | C, C#, C++, Go, Java, JS, Kotlin, PHP, Python, Ruby, Rust | "xCodeEval: A Large Scale Multilingual Multitask Benchmark for Code Understanding, Generation, Translation and Retrieval" [paper] [data] |
| 2023-04 | arxiv | RunBugRun | 450k | C, C++, Java, Python, JS, Ruby, Go, PHP | "RunBugRun -- An Executable Dataset for Automated Program Repair" [paper] [data] |
| 2023-08 | arxiv | HumanEvalPack | 984 | Python, JS, Go, Java, C++, Rust | "OctoPack: Instruction Tuning Code Large Language Models" [paper] [data] |
| 2024-01 | arxiv | Debugbench | 4253 | C++, Java, Python | "DebugBench: Evaluating Debugging Capability of Large Language Models" [paper] [data] |
| 2024-11 | arxiv | MdEval | 3513 | 18 | "MdEval: Massively Multilingual Code Debugging" [paper] |
* These are code-change datasest, and only a subset therein concerns bug fixing.
| 日期 | 场地 | 基准 | 尺寸 | 语言 | 来源 |
|---|---|---|---|---|---|
| 2016-08 | ACL 2016 | CODE-NN | 66K/32K | C#/SQL | "Summarizing Source Code using a Neural Attention Model" [paper] [data] |
| 2017-07 | IJCNLP 2017 | 未命名 | 150k | Python | "A parallel corpus of Python functions and documentation strings for automated code documentation and code generation" [paper] [data] |
| 2018-05 | ICPC 2018 | DeepCom | 588k | 爪哇 | "Deep code comment generation" [paper] [data] |
| 2018-07 | IJCAI 2018 | TL-CodeSum | 411k | 爪哇 | "Summarizing Source Code with Transferred API Knowledge" [paper] [data] |
| 2018-11 | ASE 2018 | 未命名 | 109k | Python | "Improving Automatic Source Code Summarization via Deep Reinforcement Learning" [paper] [data] |
| 2019-09 | arxiv | codesearchnet | 2.3m | Go, JS, Python, PHP, Java, Ruby | "CodeSearchNet Challenge: Evaluating the State of Semantic Code Search" [paper] [data] |
| 2023-08 | arxiv | HumanEvalPack | 984 | Python, JS, Go, Java, C++, Rust | "OctoPack: Instruction Tuning Code Large Language Models" [paper] [data] |
| 日期 | 场地 | 基准 | 尺寸 | 语言 | 来源 |
|---|---|---|---|---|---|
| 2018-01 | NDSS 2018 | CGD | 62k | C,C ++ | "VulDeePecker: A Deep Learning-Based System for Vulnerability Detection" [paper] [data] |
| 2018-04 | IEEE Trans。 Ind. Informatics | 未命名 | 32988 | C,C ++ | "Cross-Project Transfer Representation Learning for Vulnerable Function Discovery" [paper] [data] |
| 2018-07 | ICMLA 2018 | Draper VDISC | 1280万 | C,C ++ | "Automated Vulnerability Detection in Source Code Using Deep Representation Learning" [paper] [data] |
| 2018-07 | IEEE TDSC | SySeVR | 15591 | C,C ++ | "SySeVR: A Framework for Using Deep Learning to Detect Software Vulnerabilities" [paper] [data] |
| 2019-02 | MSR 2019 | 未命名 | 624 | 爪哇 | "A Manually-Curated Dataset of Fixes to Vulnerabilities of Open-Source Software" [paper] [data] |
| 2019-09 | Neurips 2019 | 偏差 | 49k | c | "Devign: Effective Vulnerability Identification by Learning Comprehensive Program Semantics via Graph Neural Networks" [paper] [data] |
| 2019-11 | IEEE TDSC | 未命名 | 170k | C,C ++ | "Software Vulnerability Discovery via Learning Multi-Domain Knowledge Bases" [paper] [data] |
| 2019-12 | ICLR 2020 | 伟大的 | 28m | Python | "Global Relational Models of Source Code" [paper] [data] |
| 2020-01 | IEEE TDSC | MVD | 182k | C,C ++ | "μVulDeePecker: A Deep Learning-Based System for Multiclass Vulnerability Detection" [paper] [data] |
| 2020-02 | ICICS 2019 | 未命名 | 1471 | c | "Deep Learning-Based Vulnerable Function Detection: A Benchmark" [paper] [data] |
| 2020-09 | IEEE Trans。 Software Eng. | 揭示 | 18k | c | "Deep Learning based Vulnerability Detection: Are We There Yet?" [paper] [data] |
| 2020-09 | MSR 2020 | Big-Vul | 265k | C,C ++ | "AC/C++ Code Vulnerability Dataset with Code Changes and CVE Summaries" [paper] [data] |
| 2021-02 | ICSE (SEIP) 2021 | D2A | 1.3m | C,C ++ | "D2A: A Dataset Built for AI-Based Vulnerability Detection Methods Using Differential Analysis" [paper] [data] |
| 2021-05 | NeurIPS 2021 | PyPIBugs | 2374 | Python | "Self-Supervised Bug Detection and Repair" [paper] [data] |
| 2021-07 | In PROMISE 2021 | CVEfixes | 5495 | 27 | "CVEfixes: Automated Collection of Vulnerabilities and Their Fixes from Open-Source Software" [paper] [data] |
| 2021-08 | ESEC/FSE 2021 | CrossVul | 27476 | 40+ | "CrossVul: a cross-language vulnerability dataset with commit data" [paper] [data] |
| 2023-04 | RAID 2023 | DiverseVul | 349k | C,C ++ | "DiverseVul: A New Vulnerable Source Code Dataset for Deep Learning Based Vulnerability Detection" [paper] [data] |
| 2023-06 | arxiv | VulnPatchPairs | 26k | c | "Limits of Machine Learning for Automatic Vulnerability Detection" [paper] [data] |
| 2023-11 | arxiv | VulBench | 455 | c | "How Far Have We Gone in Vulnerability Detection Using Large Language Models" [paper] [data] |
| 2024-03 | arxiv | primevul | 236K | C/C ++ | "Vulnerability Detection with Code Language Models: How Far Are We?" [纸] |
| 2024-06 | arxiv | VulDetectBench | 1000 | C/C ++ | "VulDetectBench: Evaluating the Deep Capability of Vulnerability Detection with Large Language Models" [paper] [data] |
| 2024-08 | arxiv | CodeJudge-Eval | 1860年 | Python | "CodeJudge-Eval: Can Large Language Models be Good Judges in Code Understanding?" [paper] [data] |
| 2024-11 | arxiv | CleanVul | 11632 | Java, Python, JS, C#, C/C++ | "CleanVul: Automatic Function-Level Vulnerability Detection in Code Commits Using LLM Heuristics" [paper] [data] |
| 日期 | 场地 | 基准 | 尺寸 | 语言 | 来源 |
|---|---|---|---|---|---|
| 2018-03 | WWW 2018 | StaQC | 148K/120K | Python/SQL | "StaQC: A Systematically Mined Question-Code Dataset from Stack Overflow" [paper] [data] |
| 2018-05 | ICSE 2018 | DeepCS | 16.2m | 爪哇 | "Deep Code Search" [paper] [data] |
| 2018-05 | MSR 2018 | CoNaLa | 600K/2.9K | Python | "Learning to Mine Aligned Code and Natural Language Pairs from Stack Overflow" [paper] [data] |
| 2019-08 | arxiv | 未命名 | 287 | 爪哇 | "Neural Code Search Evaluation Dataset" [paper] [data] |
| 2019-09 | arxiv | codesearchnet | 2.3M/99 | Go, PHP, JS, Python, Java, Ruby | "CodeSearchNet Challenge: Evaluating the State of Semantic Code Search" [paper] [data] |
| 2020-02 | SANER 2020 | CosBench | 52 | 爪哇 | "Are the Code Snippets What We Are Searching for? A Benchmark and an Empirical Study on Code Search with Natural-Language Queries" [paper] [data] |
| 2020-08 | arxiv | SO-DS | 2.2k | Python | "Neural Code Search Revisited: Enhancing Code Snippet Retrieval through Natural Language Intent" [paper] [data] |
| 2020-10 | ACM Trans。知识。 Discov。数据 | FB-Java | 249k | 爪哇 | "Deep Graph Matching and Searching for Semantic Code Retrieval" [paper] [data] |
| 2021-02 | NeurIPS Datasets and Benchmarks 2021 | AdvTest/WebQueryTest | 280K/1K | Python | "CodeXGLUE: A Machine Learning Benchmark Dataset for Code Understanding and Generation" [paper] [[data]] |
| 2021-05 | ACL/IJCNLP 2021 | CoSQA | 21k | Python | "CoSQA: 20,000+ Web Queries for Code Search and Question Answering" [paper] [data] |
| 2024-03 | arxiv | ProCQA | 5.2m | C, C++, Java, Python, Ruby, Lisp, JS, C#, Go, Rust, PHP | "ProCQA: A Large-scale Community-based Programming Question Answering Dataset for Code Search" [paper] [data] |
| 2024-06 | arxiv | CoSQA+ | 109k | Python | "CoSQA+: Enhancing Code Search Dataset with Matching Code" [paper] [data] |
| 2024-07 | arxiv | CoIR | ~2M | 14 | "CoIR: A Comprehensive Benchmark for Code Information Retrieval Models" [paper] [data] |
| 2024-08 | arxiv | SeqCoBench | 14.5k | Python | "What can Large Language Models Capture about Code Functional Equivalence?" [纸] |
| 日期 | 场地 | 基准 | 尺寸 | 语言 | 来源 |
|---|---|---|---|---|---|
| 2019-12 | ESEC/FSE 2020 | TypeWriter OSS | 208K | Python | "TypeWriter: Neural Type Prediction with Search-based Validation" [paper] [data] |
| 2020-04 | PLDI 2020 | Typilus | 252k | Python | "Typilus: Neural Type Hints" [paper] [data] |
| 2020-04 | ICLR 2020 | LambdaNet | 300 * | 打字稿 | "LambdaNet: Probabilistic Type Inference using Graph Neural Networks" [paper] [data] |
| 2021-04 | MSR 2021 | ManyTypes4Py | 869k | Python | "ManyTypes4Py: A Benchmark Python Dataset for Machine Learning-based Type Inference" [paper] [data] |
| 2022-10 | MSR 2022 | mantypes4typecript | 9.1m | 打字稿 | "ManyTypes4TypeScript: a comprehensive TypeScript dataset for sequence-based type inference" [paper] [data] |
| 2023-02 | ECOOP 2023 | TypeWeaver | 513 * | 打字稿 | "Do Machine Learning Models Produce TypeScript Types That Type Check?" [paper] [data] |
| 2023-03 | ICLR 2023 | BetterTypes4Py/InferTypes4Py | 608K/4.6K | Python | "TypeT5: Seq2seq Type Inference using Static Analysis" [paper] [data] |
| 2023-05 | arxiv | OpenTau | 744 * | 打字稿 | "Type Prediction With Program Decomposition and Fill-in-the-Type Training" [paper] [data] |
* These are project counts.
| 日期 | 场地 | 基准 | 尺寸 | 语言 | 来源 |
|---|---|---|---|---|---|
| 2017-03 | ICPC 2017 | 未命名 | 509k | 爪哇 | "Towards Automatic Generation of Short Summaries of Commits" [paper] [data] |
| 2017-04 | ACL 2017 | CommitGen | 153K | Python, JS, C++, Java | "A Neural Architecture for Generating Natural Language Descriptions from Source Code Changes" [paper] [data] |
| 2017-08 | ASE 2017 | CommitGen | 32K/75K * | 爪哇 | "Automatically Generating Commit Messages from Diffs using Neural Machine Translation" [paper] [data] |
| 2018-09 | ASE 2018 | NNGen | 27k | 爪哇 | "Neural-machine-translation-based commit message generation: how far are we?" [paper] [data] |
| 2019-05 | MSR 2019 | PtrGNCMsg | 64.9k | 爪哇 | "Generating commit messages from diffs using pointer-generator network" [paper] [[data(https://zenodo.org/records/2593787)]] |
| 2019-08 | IJCAI 2019 | CoDiSum | 90.7k | 爪哇 | "Commit message generation for source code changes" [paper] [data] |
| 2019-12 | IEEE Trans。 Software Eng. | 原子 | 160k | 爪哇 | "ATOM: Commit Message Generation Based on Abstract Syntax Tree and Hybrid Ranking" [paper] [data] |
| 2021-05 | arxiv | CommitBERT | 346K | Python, PHP, Go, Java, JS, Ruby | "CommitBERT: Commit Message Generation Using Pre-Trained Programming Language Model" [paper] [data] |
| 2021-07 | ICSME 2021 | MCMD | 225万 | Java, C#, C++, Python, JS | "On the Evaluation of Commit Message Generation Models: An Experimental Study" [paper] [data] |
| 2021-07 | ACM Trans。软件。工程。 methodol。 | CoRec | 107k | 爪哇 | "Context-aware Retrieval-based Deep Commit Message Generation" [paper] [data] |
| 2023-07 | ASE 2023 | ExGroFi | 19263 | 爪哇 | "Delving into Commit-Issue Correlation to Enhance Commit Message Generation Models" [paper] [data] |
| 2023-08 | ASE 2023 | CommitChronicle | 107m | 20 | "From Commit Message Generation to History-Aware Commit Message Completion" [paper] [data] |
* with/without verb-direct object filter
| 日期 | 场地 | 基准 | 尺寸 | 语言 | 来源 |
|---|---|---|---|---|---|
| 2023-03 | arxiv | RepoEval | 1600/1600/373 * | Python | "RepoCoder: Repository-Level Code Completion Through Iterative Retrieval and Generation" [paper] [data] |
| 2023-06 | ICLR 2024 | RepoBench | 890K/9M/43K | Python, Java | "RepoBench: Benchmarking Repository-Level Code Auto-Completion Systems" [paper] [data] |
| 2023-06 | 神经2023 | PragmaticCode | 880 ** | 爪哇 | "Guiding Language Models of Code with Global Context using Monitors" [paper] [data] |
| 2023-06 | arxiv | Stack-Repo | 816k | 爪哇 | "RepoFusion: Training Code Models to Understand Your Repository" [paper] [data] |
| 2023-09 | ISMB 2024 | BioCoder | 2269/460/460 | Python, Java | "BioCoder: A Benchmark for Bioinformatics Code Generation with Large Language Models" [paper] [data] |
| 2023-09 | arxiv | CodePlan | 645/21 | C#/Python | "CodePlan: Repository-level Coding using LLMs and Planning" [paper] [data] |
| 2023-10 | arxiv | SWE板凳 | 2294 | Python | "SWE-bench: Can Language Models Resolve Real-World GitHub Issues?" [paper] [data] |
| 2023-10 | arxiv | CrossCodeEval | 9928 | Python, Java, TypeScript, C# | "CrossCodeEval: A Diverse and Multilingual Benchmark for Cross-File Code Completion" [paper] [data] |
| 2024-03 | arxiv | EvoCodeBench | 275 | Python | "EvoCodeBench: An Evolving Code Generation Benchmark Aligned with Real-World Code Repositories" [paper] [data] |
| 2024-05 | ACL 2024调查结果 | DevEval | 1874年 | Python | "DevEval: A Manually-Annotated Code Generation Benchmark Aligned with Real-World Code Repositories" [paper] [data] |
| 2024-06 | arxiv | JavaBench | 389 | 爪哇 | "Can AI Beat Undergraduates in Entry-level Java Assignments? Benchmarking Large Language Models on JavaBench" [paper] [data] |
| 2024-06 | arxiv | HumanEvo | 200/200 | Python/Java | "Towards more realistic evaluation of LLM-based code generation: an experimental study and beyond" [paper] [data] |
| 2024-06 | arxiv | RepoExec | 355 | Python | "REPOEXEC: Evaluate Code Generation with a Repository-Level Executable Benchmark" [paper] |
| 2024-06 | arxiv | RES-Q | 100 | Python, JavaScript | "RES-Q: Evaluating Code-Editing Large Language Model Systems at the Repository Scale" [paper] [data] |
| 2024-08 | arxiv | SWE-bench-java | 91 | 爪哇 | "SWE-bench-java: A GitHub Issue Resolving Benchmark for Java" [paper] [data] |
| 2024-10 | arxiv | Codev-Bench | 296 | Python | "Codev-Bench: How Do LLMs Understand Developer-Centric Code Completion?" [paper] [data] |
| 2024-10 | arxiv | SWE-bench M | 617 | JavaScript | "SWE-bench Multimodal: Do AI Systems Generalize to Visual Software Domains?" [paper] [data] |
| 2024-10 | arxiv | SWE-Bench+ | 548 | Python | "SWE-Bench+: Enhanced Coding Benchmark for LLMs" [paper] [data] |
| 2024-10 | arxiv | DA-Code | 500 | Python, Bash, SQL | "DA-Code: Agent Data Science Code Generation Benchmark for Large Language Models" [paper] [data] |
| 2024-10 | arxiv | RepoCod | 980 | Python | "Can Language Models Replace Programmers? REPOCOD Says 'Not Yet'" [paper] |
| 2024-10 | arxiv | M2rc-Eval | 5993 repos | 18 | "M2rc-Eval: Massively Multilingual Repository-level Code Completion Evaluation" [paper] [data] |
*Line Completion/API Invocation Completion/Function Completion
** File count
30 papers as a primer on LLM.
| 日期 | 关键词 | 纸 | tl; dr |
|---|---|---|---|
| 2014-09 | 注意力 | Neural Machine Translation by Jointly Learning to Align and Translate | The original attention, proposed for encoder-decoder RNN |
| 2015-08 | BPE | Neural Machine Translation of Rare Words with Subword Units | Byte-pair encoding: split rare words into subword units |
| 2017-06 | 变压器 | 注意就是您所需要的 | Replace LSTM with self-attention for long-range dependency and parallel training |
| 2017-10 | 混合精度训练 | 混合精度训练 | Store model weights in fp16 to save memory |
| 2018-04 | 胶水 | GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding | A language understanding benchmark |
| 2018-06 | GPT | 通过生成的预培训来提高语言理解 | Pretraining-finetuning paradigm applied to Transformer decoder |
| 2018-10 | 伯特 | BERT:深层双向变压器的预训练以了解语言理解 | Masked Language Modeling (MLM) applied to Transformer encoder for pretraining |
| 2019-02 | GPT-2 | 语言模型是无监督的多任务学习者 | GPT made larger (1.5B). They found language models implicitly learn about downstream tasks (such as translation) during pretraining. |
| 2019-05 | 超级lue | SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems | Another language understanding benchmark |
| 2019-07 | 罗伯塔 | 罗伯塔:一种强大优化的BERT预训练方法 | 优化的伯特 |
| 2019-09 | Megatron-LM | Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism | 模型并行性 |
| 2019-10 | 零 | 零:用于训练万亿参数模型的内存优化 | 记忆有效的分布式优化 |
| 2019-10 | T5 | 使用统一的文本到文本变压器探索转移学习的限制 | Transformer encoder-decoder pretrained with an MLM-like denoising objective |
| 2020-05 | GPT-3 | 语言模型是很少的学习者 | By training an even larger version of GPT-2 (175B), they discovered a new learning paradigm: In-Context Learning (ICL) |
| 2020-09 | mmlu | 测量大量的多任务语言理解 | A world-knowledge and complex reasoning benchmark |
| 2020-12 | 桩 | The Pile: An 800GB Dataset of Diverse Text for Language Modeling | A diverse pretraining dataset |
| 2021-06 | 洛拉 | 洛拉:大语言模型的低排名 | Memory-efficient finetuning |
| 2021-09 | FLAN | 填补语言模型是零摄的学习者 | Instruction-finetuning |
| 2021-10 | T0 | Multitask Prompted Training Enables Zero-Shot Task Generalization | 还要指示登录,但适用于较小的T5 |
| 2021-12 | Gopher | Scaling Language Models: Methods, Analysis & Insights from Training Gopher | A 280B LLM with comprehensive experiments |
| 2022-01 | 婴儿床 | 经过思考的链条提示在大语言模型中引起推理 | Chain-of-Though reasoning |
| 2022-03 | 指示邀请 | 培训语言模型遵循人类反馈的指示 | GPT-3 instruction finetuned with RLHF (reinforcement learning from human feedback) |
| 2022-03 | 龙猫 | 培训计算最佳的大语言模型 | A smaller (70B) version of Gopher that's pretrained on more data |
| 2022-04 | 棕榈 | 棕榈:用途径进行缩放语言建模 | The largest dense model ever (540B) |
| 2022-05 | 0击中婴儿床 | 大型语言模型是零击的推理器 | Tell LLMs to think step by step, and they can actually do it |
| 2022-06 | BIG Bench | 超越模仿游戏:量化和推断语言模型的功能 | Another world-knowledge and complex reasoning benchmark |
| 2022-06 | Emergent Ability | Emergent Abilities of Large Language Models | A review on emergent abilities |
| 2022-10 | 弗兰 | 缩放指令 - 通信语言模型 | Consolidate all the existing instruction tuning datasets, and you get SOTA |
| 2022-11 | 盛开 | BLOOM: A 176B-Parameter Open-Access Multilingual Language Model | The largest open-source LLM, trained on 46 languages, with detailed discussion about training and evaluation |
| 2022-12 | Self-Instruct | Self-Instruct: Aligning Language Models with Self-Generated Instructions | Instruction tuning using LLM-generated data |
This list aims to provide the essential background for understanding current LLM technologies, and thus excludes more recent models such as LLaMA, GPT-4 or PaLM 2. For comprehensive reviews on these more general topics, we refer to other sources such as this paper or these repositories: Awesome-LLM, Awesome AIGC Tutorials. And for LLM applications in other specific domains: Awesome Domain LLM, Awesome Tool Learning, Awesome-LLM-MT, Awesome Education LLM.
If you find this repo or our survey helpful, please consider citing us:
@article{zhang2024unifying,
title={Unifying the Perspectives of {NLP} and Software Engineering: A Survey on Language Models for Code},
author={Ziyin Zhang and Chaoyu Chen and Bingchang Liu and Cong Liao and Zi Gong and Hang Yu and Jianguo Li and Rui Wang},
journal={Transactions on Machine Learning Research},
issn={2835-8856},
year={2024},
url={https://openreview.net/forum?id=hkNnGqZnpa},
note={}
}
We are on the lookout for top talents to join our vibrant team! If you're eager to develop your career in an environment filled with energy, innovation, and a culture of excellence, we welcome you to explore our career opportunities for both campus and experienced hires. Join us and be a part of creating the next milestone in the industry.
Campus Recruitment : https://hrrecommend.antgroup.com/guide.html?code=8uoP5mlus5DqQYbE_EnqcE2FD5JZH21MwvMUIb9mb6X3osXPuBraG54SyM8GLn_7
Experienced Hires : https://talent.antgroup.com/off-campus-position?positionId=1933830
我们正在寻找行业中的佼佼者加入我们的团队!如果您希望在一个充满活力、创新和卓越文化的环境中发展您的职业生涯,欢迎您查看我们的社招&校招机会,加入我们,一起创造下一个行业里程碑。
校招:https://hrrecommend.antgroup.com/guide.html?code=8uoP5mlus5DqQYbE_EnqcE2FD5JZH21MwvMUIb9mb6X3osXPuBraG54SyM8GLn_7
社招:https://talent.antgroup.com/off-campus-position?positionId=1933830
永久企业微信交流群:



