azure search openai demo csharp
2024-09-16 - Enhanced Deployment and Documentation Updates
| page_type | 语言 | 产品 | urlfragment | 姓名 | 描述 | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
样本 |
|
| Azure-Search-Openai-Demo-Charp | chatgpt +企业数据(CSHARP) | 使用OpenAI和AI搜索与您的数据聊天的CSHARP示例应用程序。 |
该示例演示了一些使用检索增强生成模式在您自己的数据上创建类似于Chatgpt的体验的方法。它使用Azure OpenAI服务访问ChatGPT模型( gpt-4o-mini ),并搜索Azure AI以搜索数据索引和检索。
存储库包含示例数据,因此可以尝试端到端。在此示例应用程序中,我们使用了一个名为Contoso Electronics的虚拟公司,并且经验使其员工可以询问有关收益,内部政策以及职位描述和角色的问题。
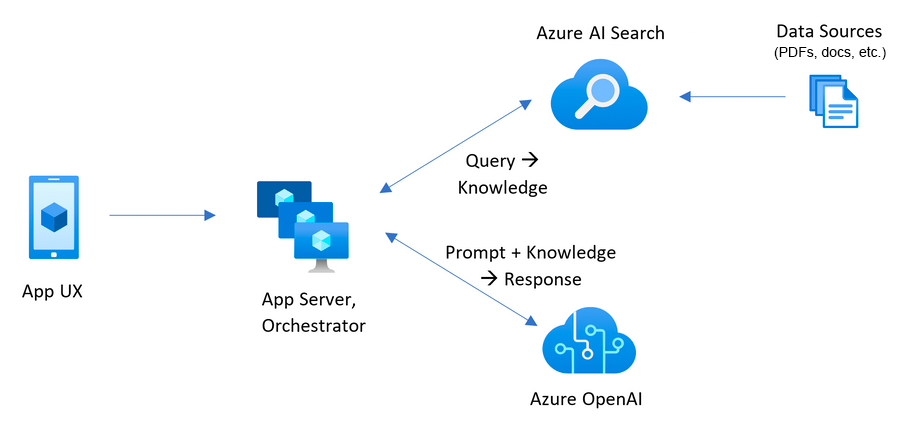
有关该应用程序的构建方式的更多详细信息,请查看:
我们想收到您的来信!您是否有兴趣构建或目前构建智能应用程序?花几分钟完成这项调查。
进行调查
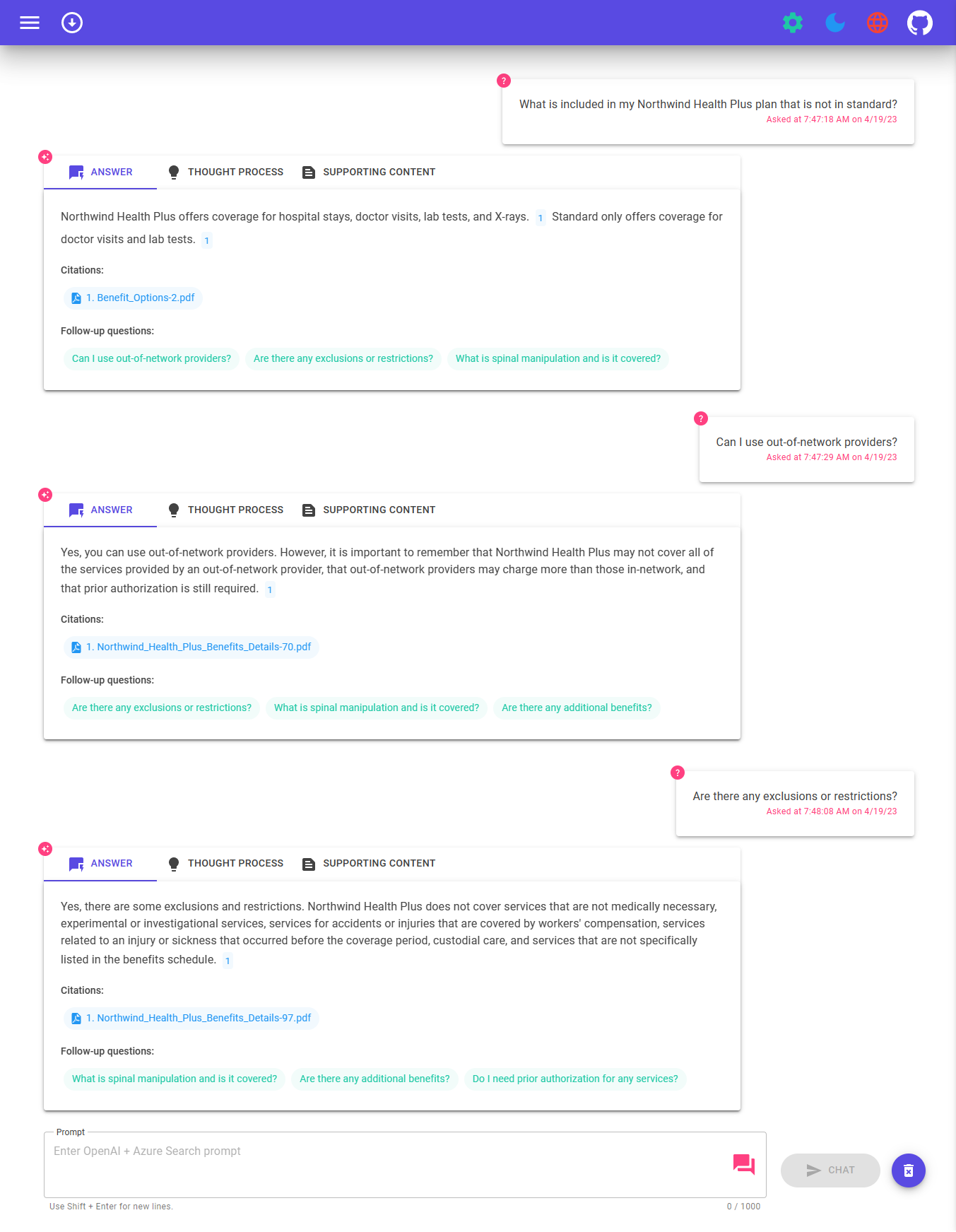
为了部署和运行此示例,您需要
Microsoft.Authorization/roleAssignments/write Permissions,例如用户访问管理员或所有者。 警告
默认情况下,此示例将创建一个Azure容器应用程序,以及具有每月成本的Azure AI搜索资源,以及具有每个文档页面成本的Azure AI文档智能资源。如果您想通过更改Infra文件夹下的参数文件来避免此成本,则可以将它们切换到每个版本的免费版本(尽管有一些限制需要考虑;例如,您可以每次订阅最多有1个免费的Azure AI搜索资源,而免费的Azure AI ai文档智能资源只能分析每个文档的前2页。)。)。)。)。)。)。)。)。)。)。
定价每个区域和使用情况都有所不同,因此不可能预测使用的确切成本。但是,您可以尝试以下资源的Azure定价计算器:
为了降低成本,您可以改用各种服务的自由SKU,但是这些SKU有局限性。有关更多详细信息,请参阅本指南的部署指南。
azd down 。
您有一些设置此项目的选择。最简单的入门方法是github codespese,因为它将为您设置所有工具,但是如果需要,您也可以在本地设置它。
您可以通过使用github codespese实际上运行此存储库,该码将在浏览器中打开基于Web的VS代码:
一个相关的选项是VS代码远程容器,该容器将使用DEV容器扩展名中的本地VS代码打开项目:
安装以下先决条件:
Azure开发人员CLI
.NET 8
git
PowerShell 7+(PWSH) - 仅适用于Windows用户。
重要的是:确保您可以从powershell命令中运行
pwsh.exe。如果失败,您可能需要升级PowerShell。
Docker
重要的是:在运行任何
azdPROVINIONing /部署命令之前,请确保Docker正在运行。
然后,运行以下命令以在您的本地环境上获取项目:
azd auth loginazd init -t azure-search-openai-demo-csharpazd env new azure-search-openai-demo-csharp实时流:从划痕中部署在代码空间中实时流:在Windows 11中从头部署
重要的是:在运行任何
azdPROVINIONing /部署命令之前,请确保Docker正在运行。
执行以下命令,如果您没有任何先前存在的Azure服务,并且希望从新的部署开始。
运行azd up这将提供Azure资源,并将此示例部署到这些资源,包括根据./data文件夹中的文件构建搜索索引。
注意:此应用程序使用
gpt-4o-mini模型。选择要部署的区域时,请确保它们在该地区(IE Eastus)中可用。有关更多信息,请参见Azure OpenAI服务文档。
成功部署应用程序后,您将看到将URL打印到控制台。单击该URL与浏览器中的应用程序进行交互。
看起来如下:
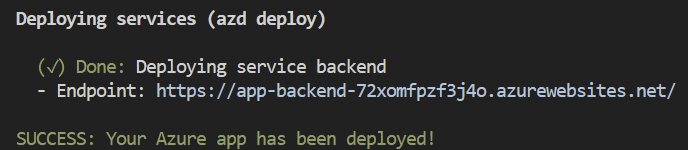
[!注]:将应用程序完全部署可能需要几分钟。部署应用程序后,还需要几分钟来处理要添加到矢量数据库中的文档。
如果您希望使用的Azure中现有资源,则可以通过设置以下azd环境变量来配置azd以使用这些资源:
azd env set AZURE_OPENAI_SERVICE {Name of existing OpenAI service}azd env set AZURE_OPENAI_RESOURCE_GROUP {Name of existing resource group that OpenAI service is provisioned to}azd env set AZURE_OPENAI_CHATGPT_DEPLOYMENT {Name of existing ChatGPT deployment} 。仅当您的chatgpt部署不是默认的“聊天”时才需要。azd env set AZURE_OPENAI_EMBEDDING_DEPLOYMENT {Name of existing embedding model deployment} 。仅当您的嵌入模型部署不是默认embedding时才需要。azd up 笔记
您也可以使用现有的搜索和存储帐户。有关环境变量的列表,请参见./infra/main.parameters.json将其传递到azd env set以配置这些现有资源。
重要的
在运行任何azd Provisioning /部署命令之前,请确保Docker正在运行。
azd up 笔记
确保您的存储库中有AZD支持的二头肌文件,并添加一个可以手动触发的github操作文件(用于初始部署),或在代码更改上触发(自动重新启动使用最新更改),以使您的存储库与App space兼容,您需要更改与Main Bicep和Maint Anemet afor Andovion Andive An a Zd demot a demot a a zd audion Azd indodut a zd aud a a zd dovile azd audion azd indovile a zd audion a zd a zd。
"resourceGroupName" : {
"value" : " ${AZURE_RESOURCE_GROUP} "
} "tags" : {
"value" : " ${AZURE_TAGS} "
} param resourceGroupName string = ''
param tags string = '' var baseTags = { 'azd-env-name' : environmentName }
var updatedTags = union ( empty ( tags ) ? {} : base64ToJson ( tags ), baseTags )
Make sure to use " updatedTags " when assigning " tags " to resource group created in your bicep file and update the other resources to use " baseTags " instead of " tags ". For example -
``` json
resource rg 'Microsoft.Resources/resourceGroups@2021-04-01' = {
name : ! empty ( resourceGroupName ) ? resourceGroupName : '${ abbrs . resourcesResourceGroups }${ environmentName }'
location : location
tags : updatedTags
}重要的
在运行任何azd Provisioning /部署命令之前,请确保Docker正在运行。
运行azd auth login
应用程序部署后,设置环境变量AZURE_KEY_VAULT_ENDPOINT 。您可以在.azure/您的环境名称/.env文件或Azure门户中找到该值。
运行以下.NET CLI命令以启动ASP.NET CORE最小API服务器(客户端主机):
dotnet run --project ./app/backend/MinimalApi.csproj --urls=http://localhost:7181/
导航到http:// localhost:7181,并测试应用程序。
该示例包括一个.NET MAUI客户端,将体验包装为可以在Windows/MacOS桌面或Android和iOS设备上运行的应用程序。此处的MAUI客户端是使用Blazor Hybrid实施的,让其与网站Frontend共享大多数代码。
打开App/app-maui.sln打开包含毛伊客户端的解决方案
编辑App/Maui-Blazor/Mauipragram.cs ,更新client.BaseAddress ,并使用后端的URL。
如果它在Azure中运行,请使用上述步骤将URL用于服务后端。如果本地运行,请使用http:// localhost:7181。
将Mauiblazor设置为启动项目并运行应用程序
如果您想让其他人访问已部署和现有环境,请运行以下内容。
azd init -t azure-search-openai-demo-csharpazd env refresh -e {environment name} - 请注意,他们将需要AZD环境名称,订阅ID和位置才能运行此命令 - 您可以在./azure/{env name}/.env File中找到这些值。这将填充其AZD环境的.ENV文件,并在本地运行该应用所需的所有设置。pwsh ./scripts/roles.ps1这将为用户分配所有必要的角色,以便他们可以在本地运行该应用程序。如果他们没有必要的权限来在订阅中创建角色,那么您可能需要为他们运行此脚本。只需确保将AZD .ENV文件或Active Shell中的AZURE_PRINCIPAL_ID环境变量设置为其Azure ID,他们可以通过az account show 。 azd down
azd部署的Azure容器应用程序。当azd完成(为“端点”)时,将其打印出URL,或者您可以在Azure门户中找到它。进入Web应用程序:
要启用应用程序洞察力和每个请求的跟踪以及错误的记录,请在运行azd up之前将AZURE_USE_APPLICATION_INSIGHTS变量设置为trui
azd env set AZURE_USE_APPLICATION_INSIGHTS trueazd up要查看性能数据,请转到资源组中的“应用程序见解资源”,单击“调查 - >“性能”刀片,然后导航到任何HTTP请求以查看正时数据。要检查聊天请求的性能,请使用“钻入样本”按钮查看所有用于任何聊天请求的API调用的端到端痕迹:
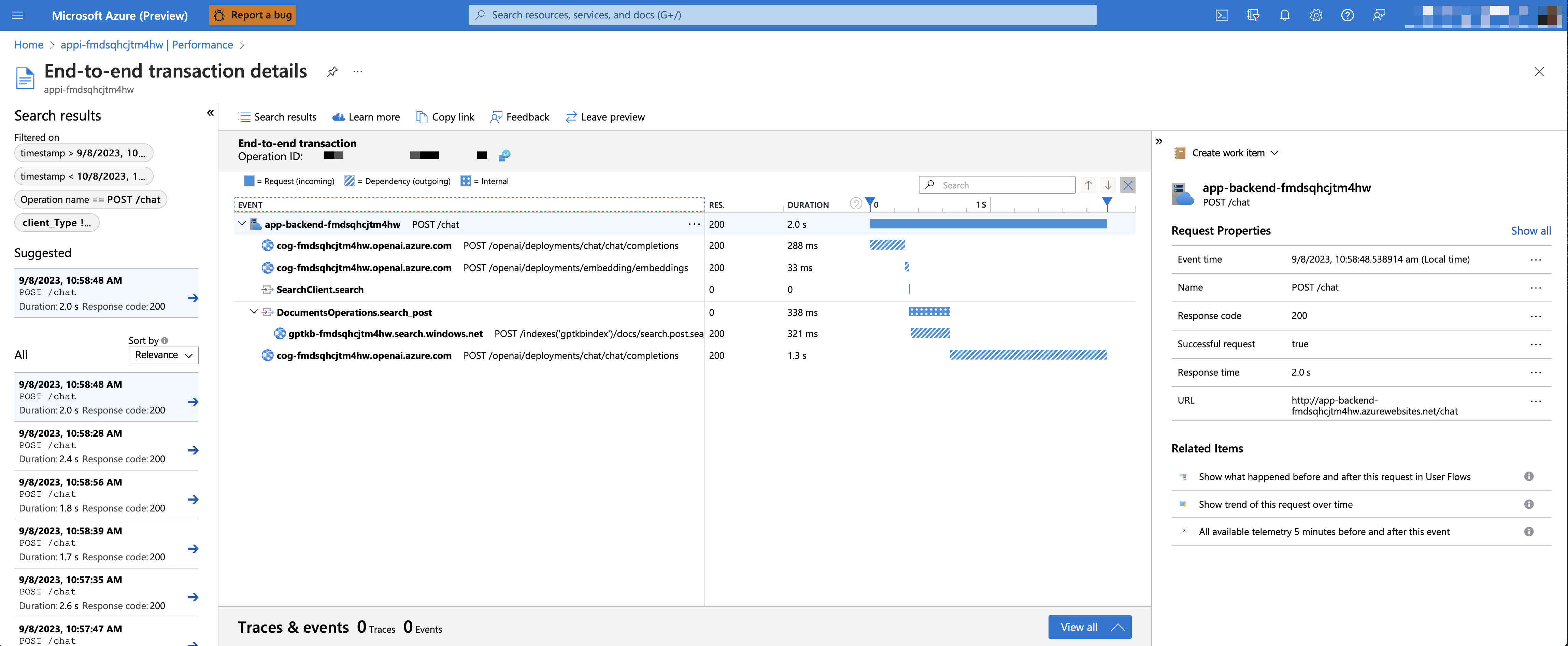
要查看任何异常和服务器错误,请导航到“调查 - >故障”刀片,并使用过滤工具定位特定异常。您可以在右侧看到Python堆叠痕迹。
默认情况下,部署的Azure容器应用程序将不具有身份验证或访问限制,这意味着任何具有可路由网络访问该容器应用程序的人都可以与您的索引数据聊天。您可以通过遵循添加容器应用程序身份验证教程并根据已部署的容器应用程序进行设置来对Azure Active Directory进行身份验证。
然后,限制访问特定的一组用户或组,您可以通过更改“所需的分配?”来遵循从限制Azure Ad应用程序到一组用户的步骤。在企业应用程序下的选项,然后分配用户/组访问。未授予明确访问的用户将接收错误消息-AADSTS50105:您的管理员已将应用程序<app_name>配置为阻止用户,除非用户被专门授予(“分配”)访问该应用程序。-
借助GPT-4o-mini ,可以通过提供文本和图像作为源内容来支持丰富的检测增强生成。为了启用视觉支持,您需要在配置时启用USE_VISION并使用GPT-4o或GPT-4o-mini模型。
笔记
如果您之前已经部署了该应用程序,则需要在启用GPT-4O支持后重新索引支持材料并重新删除应用程序。这是因为启用GPT-4O支持需要将新字段添加到搜索索引中。
要使用Azure OpenAi服务启用GPT-4V支持,请运行以下命令:
azd env set USE_VISION true
azd env set USE_AOAI true
azd env set AZURE_OPENAI_CHATGPT_MODEL_NAME gpt-4o-mini
azd env set AZURE_OPENAI_RESOURCE_LOCATION eastus # Please check the gpt model availability for more details.
azd up要使用OpenAI启用视觉支持,请运行以下命令:
azd env set USE_VISION true
azd env set USE_AOAI false
azd env set OPENAI_CHATGPT_DEPLOYMENT gpt-4o
azd up要清理先前部署的资源,请运行以下命令:
azd down --purge
azd env set AZD_PREPDOCS_RAN false # This is to ensure that the documents are re-indexed with the new fields. 除了下面的提示外,您还可以在文档文件夹中找到大量文档。
该样本旨在成为您自己的生产应用程序的起点,但是在部署到生产之前,您应该对安全性和性能进行详尽的审查。以下是要考虑的事情:
OpenAI容量:默认TPM(每分钟令牌)设置为30K。这相当于每分钟大约30次对话(假设每个用户消息/响应1K)。您可以通过更改infra/main.bicep中的chatGptDeploymentCapacity和embeddingDeploymentCapacity参数来增加容量。您还可以在Azure Openai Studio中查看“配额”选项卡,以了解您的容量。
Azure存储:默认存储帐户使用Standard_LRS sku。为了提高您的弹性,我们建议将Standard_ZRS用于生产部署,您可以在infra/main.bicep中使用的storage模块下使用sku属性指定。
Azure AI搜索:如果您看到有关超出搜索服务能力的错误,则可能会发现通过更改infra/core/search/search-services.bicep或手动从Azure Portal中进行缩放的replicaCount来增加复制品的数量。
Azure容器应用程序:默认情况下,此应用程序部署具有0.5 CPU内核和1GB内存的容器。最小副本为1和最大10。对于此应用程序,您可以设置诸如infra/core/host/container-app.bicep文件中的containerCpuCoreCount , containerMaxReplicas , containerMemory ,containerMemory, containerMinReplicas以满足您的需求。您可以使用自动缩放规则或计划的缩放规则,并根据负载扩大最大/最小值。
身份验证:默认情况下,已部署的应用程序公开访问。我们建议限制对经过身份验证的用户的访问。有关如何启用身份验证,请参见上面的身份验证。
网络:我们建议在虚拟网络中部署。如果该应用仅用于内部企业使用,请使用私有DNS区域。还要考虑使用Azure API管理(APIM)进行防火墙和其他形式的保护。有关更多详细信息,请阅读Azure OpenAi着陆区参考架构。
负载测试:我们建议您为您的预期用户数量运行加载测试。
Azure.AI.OpenAI nuget包笔记
此演示中使用的PDF文档包含使用语言模型(Azure OpenAI服务)生成的信息。这些文档中包含的信息仅用于演示目的,并不反映微软的观点或信念。微软对本文档中所包含的信息的完整性,准确性,可靠性,适用性或可用性不做任何形式或暗示的保证。保留给微软的所有权利。
问题:当Azure AI搜索支持大型文档时,为什么我们需要将PDF分解成块?
答:分解使我们能够限制由于令牌限制而发送到OpenAI的信息量。通过分解内容,它使我们可以轻松找到可以注入OpenAi的潜在文本块。分块的方法我们使用了一个文本的滑动窗口,以至于结束一个块的句子将开始下一个。这使我们可以减少失去文本上下文的机会。


