一個統一的 API,可用於快速輕鬆地嘗試 29 種(並且還在增加!)圖像匹配模型。
跳轉至:安裝 |使用|型號|新增模型/貢獻 |致謝 |引用
比較不同場景的配對模型。例如,我們顯示SIFT-LightGlue和LoFTR對的匹配:
(1) 室外,(2) 室內,(3) 衛星遙感,(4) 繪畫,(5) 誤報。


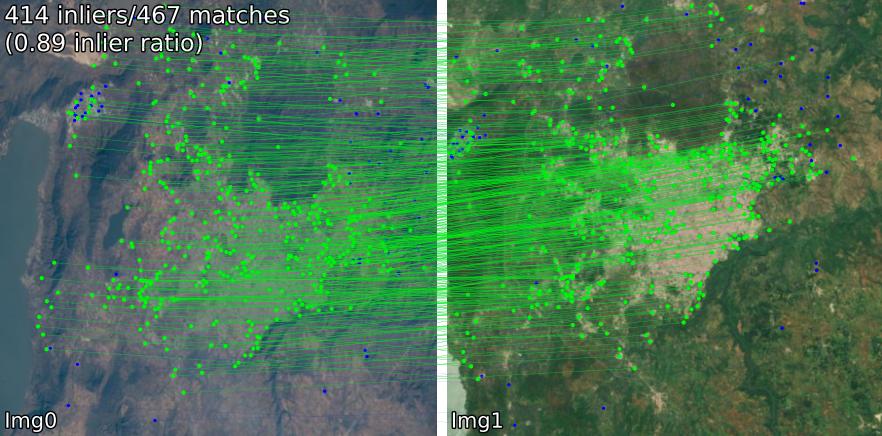




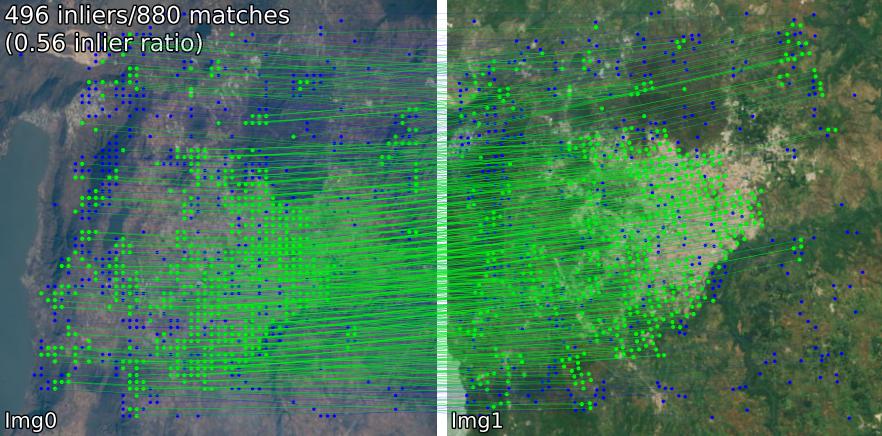
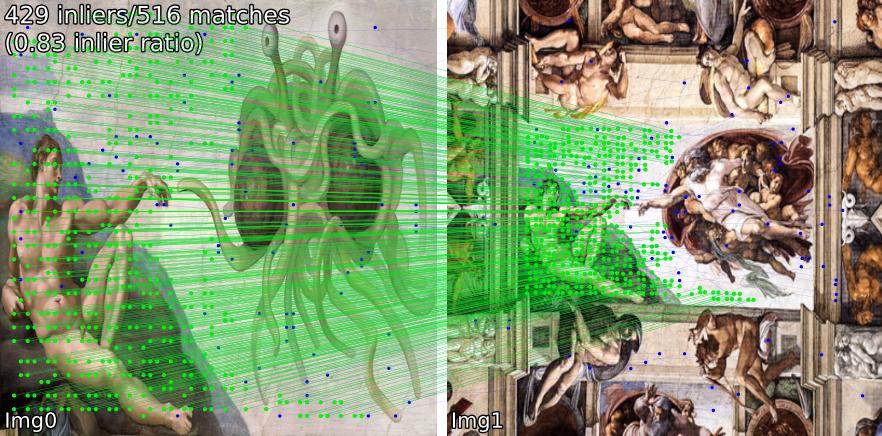

您還可以提取關鍵點和關聯的描述符。




如果你想從原始碼安裝(最容易編輯,使用benchmark.py , demo.ipynb ),
git clone --recursive https://github.com/gmberton/image-matching-models
cd image-matching-models
pip install .某些模型( omniglue 、LoFTR 系列)需要一次性依賴項( tensorflow 、 pytorch-lightning ),這些依賴項不包含在預設清單中。要安裝這些,請使用
pip install .[all]
這將安裝運行所有模型所需的所有依賴項。
您可以直接安裝到您的套件目錄中
pip install git+https://github.com/gmberton/image-matching-models.git與上方類似,若要取得所有可選依賴項,請使用[all]附錄:
pip install " image-matching-models[all] @ git+https://github.com/gmberton/image-matching-models.git " 您可以使用任何匹配器
from matching import get_matcher
from matching . viz import plot_matches
device = 'cuda' # 'cpu'
matcher = get_matcher ( 'superpoint-lg' , device = device ) # Choose any of our ~30+ matchers listed below
img_size = 512 # optional
img0 = matcher . load_image ( 'assets/example_pairs/outdoor/montmartre_close.jpg' , resize = img_size )
img1 = matcher . load_image ( 'assets/example_pairs/outdoor/montmartre_far.jpg' , resize = img_size )
result = matcher ( img0 , img1 )
num_inliers , H , inlier_kpts0 , inlier_kpts1 = result [ 'num_inliers' ], result [ 'H' ], result [ 'inlier_kpts0' ], result [ 'inlier_kpts1' ]
# result.keys() = ['num_inliers', 'H', 'all_kpts0', 'all_kpts1', 'all_desc0', 'all_desc1', 'matched_kpts0', 'matched_kpts1', 'inlier_kpts0', 'inlier_kpts1']
plot_matches ( img0 , img1 , result , save_path = 'plot_matches.png' )您也可以將其作為獨立腳本運行,它將對./assets中的範例執行推理。您也可以設定解析度( im_size )和關鍵點數量( n_kpts )。在筆記型電腦的 CPU 上,這將需要幾秒鐘的時間,並且會產生與您在上面看到的相同的圖像。
python main_matcher.py --matcher sift-lg --device cpu --out_dir output_sift-lg其中sift-lg將使用SIFT + LightGlue 。
該腳本將在./output_sift-lg下產生每對具有匹配關鍵點的圖像。
要在圖像上使用,您有以下三個選項:
./assets/example_pairs一樣。然後用作python main_matcher.py --input path/to/dirassets/example_pairs_paths.txt 。然後用作python main_matcher.py --input path/to/file.txt若要從單一影像中提取關鍵點和描述(如果可用),請使用extract()方法。
from matching import get_matcher
device = 'cuda' # 'cpu'
matcher = get_matcher ( 'superglue' , device = device ) # Choose any of our ~30+ matchers listed below
img_size = 512 # optional
img = matcher . load_image ( 'assets/example_pairs/outdoor/montmartre_close.jpg' , resize = img_size )
result = matcher . extract ( img )
# result.keys() = ['all_kpts0', 'all_desc0']
plot_kpts ( img , result )與匹配一樣,您也可以從命令列運行提取
python main_extractor.py --matcher sift-lg --device cpu --out_dir output_sift-lg --n_kpts 2048您可以選擇以下任何方法(輸入到get_matcher() ):
密集: roma, tiny-roma, dust3r, mast3r
半密集: loftr, eloftr, se2loftr, aspanformer, matchformer, xfeat-star
稀疏: [sift, superpoint, disk, aliked, dedode, doghardnet, gim, xfeat]-lg, dedode, steerers, dedode-kornia, [sift, orb, doghardnet]-nn, patch2pix, superglue, r2d2, d2net, gim-dkm, xfeat, omniglue, [dedode, xfeat, aliked]-subpx
提示
您可以傳遞匹配器列表,即get_matcher([xfeat, tiny-roma])來運行兩個匹配器並連接它們的關鍵點。
所有匹配器都可以在 GPU 上運行,並且大多數匹配器可以在 GPU 或 CPU 上運行。有一些不能在CPU上運作。
重要的
在您的應用程式中使用之前,請檢查每個模型/原始程式碼庫的許可證。有些受到嚴格限制。
| 模型 | 程式碼 | 紙 | GPU 運行時 (s/img) | CPU 運轉時間 (s/img) |
|---|---|---|---|---|
| Keypt2Subpx* (ECCV '24) | 官方的 | arxiv | 0.055 /0.164 / 0.033 / 0.291 | -- |
| MASt3R (ArXiv '24) | 官方的 | arxiv | 0.699 | -- |
| 高效率 LoFTR (CVPR '24) | 官方的 | 0.1026 | 2.117 | |
| OmniGlue (CVPR '24) | 官方的 | arxiv | 6.351 | |
| xFeat (CVPR '24) | 官方的 | arxiv | 0.027 | 0.048 |
| GIM(ICLR '24) | 官方的 | arxiv | 0.077 (+LG) / 1.627 (+DKMv3) | 5.321 (+LG) / 20.301 (+DKMv3) |
| 羅馬 / 小羅馬 (CVPR '24) | 官方的 | arxiv | 0.453 / 0.0456 | 18.950 |
| DUSt3R (CVPR '24) | 官方的 | arxiv | 3.639 | 26.813 |
| 德多德 (3DV '24) | 官方的 | arxiv | 0.311(+MNN)/ 0.218(+LG) | |
| 舵手 (CVPR '24) | 官方的 | arxiv | 0.150 | |
| LightGlue* (ICCV '23) | 官方的 | arxiv | 0.417 / 0.093 / 0.184 / 0.128 | 2.828 / 8.852 / 8.100 / 8.128 |
| SE2-LoFTR (CVPRW '22) | 官方的 | arxiv | 0.133 | 2.378 |
| Aspanformer (ECCV '22) | 官方的 | arxiv | 0.384 | 11.73 |
| 火柴人(ACCV '22) | 官方的 | arxiv | 0.232 | 6.101 |
| LoFTR (CVPR '21) | 官方/科爾尼亞 | arxiv | 0.722 | 2.36 |
| Patch2Pix(CVPR '21) | 官方/IMT | arxiv | 0.145 | 4.97 |
| 超級膠水 (CVPR '20) | 官方/IMT | arxiv | 0.0894 | 2.178 |
| R2D2(NeurIPS '19) | 官方/IMT | arxiv | 0.429 | 6.79 |
| D2Net(CVPR '19) | 官方/IMT | arxiv | 0.600 | 1.324 |
| SIFT-NN (IJCV '04) | 開放式電腦視覺 | 0.124 | 0.117 | |
| ORB-NN (ICCV '11) | 開放式電腦視覺 | 研究之門 | 0.088 | 0.092 |
| DoGHardNet (NeurIPS '17) | IMT/科爾尼亞 | arxiv | 2.697(+NN)/0.526(+LG) | 2.438(+NN)/4.528(+LG) |
我們的 Patch2Pix (+ Patch2PixSuperGlue)、R2D2 和 D2Net 的實作是基於影像匹配工具箱 (IMT)。 LoFTR 和 DeDoDe-Lightglue 來自 Kornia。其他模型基於上述官方存儲庫。
運行時基準是assets/example_pairs資料夾中圖片大小為 512x512 的 5 對範例的 5 次迭代的平均值。基準測試是在 NVIDIA RTX A4000 GPU 上使用benchmark.py完成的。結果四捨五入到百位。
* LightGlue模型運行時間依序列出:SIFT、SuperPoint、Disk、ALIKED
* Keypt2Subpx模型運行時依序列出:superpoint-lg、aliked-lg、xfeat、dedode
有關詳細信息,請參閱 CONTRIBUTING.md。
筆記
該存儲庫優化了可用性,但必然是為了速度。我們的想法是使用這個儲存庫來找到最適合您需求的匹配器,然後使用原始程式碼來充分利用它。
特別感謝本存儲庫中包含的各個作品的作者(請參閱上面的論文)。另外感謝@GrumpyZhou 開發和維護影像匹配工具箱(我們已將其包含在此儲存庫中)以及 Kornia 的維護者。
該存儲庫是作為 EarthMatch 論文的一部分創建的。如果此儲存庫對您有幫助,請考慮引用 EarthMatch 工作!
@InProceedings{Berton_2024_EarthMatch,
author = {Berton, Gabriele and Goletto, Gabriele and Trivigno, Gabriele and Stoken, Alex and Caputo, Barbara and Masone, Carlo},
title = {EarthMatch: Iterative Coregistration for Fine-grained Localization of Astronaut Photography},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops},
month = {June},
year = {2024},
}


