項目頁面|紙|型號卡 ?
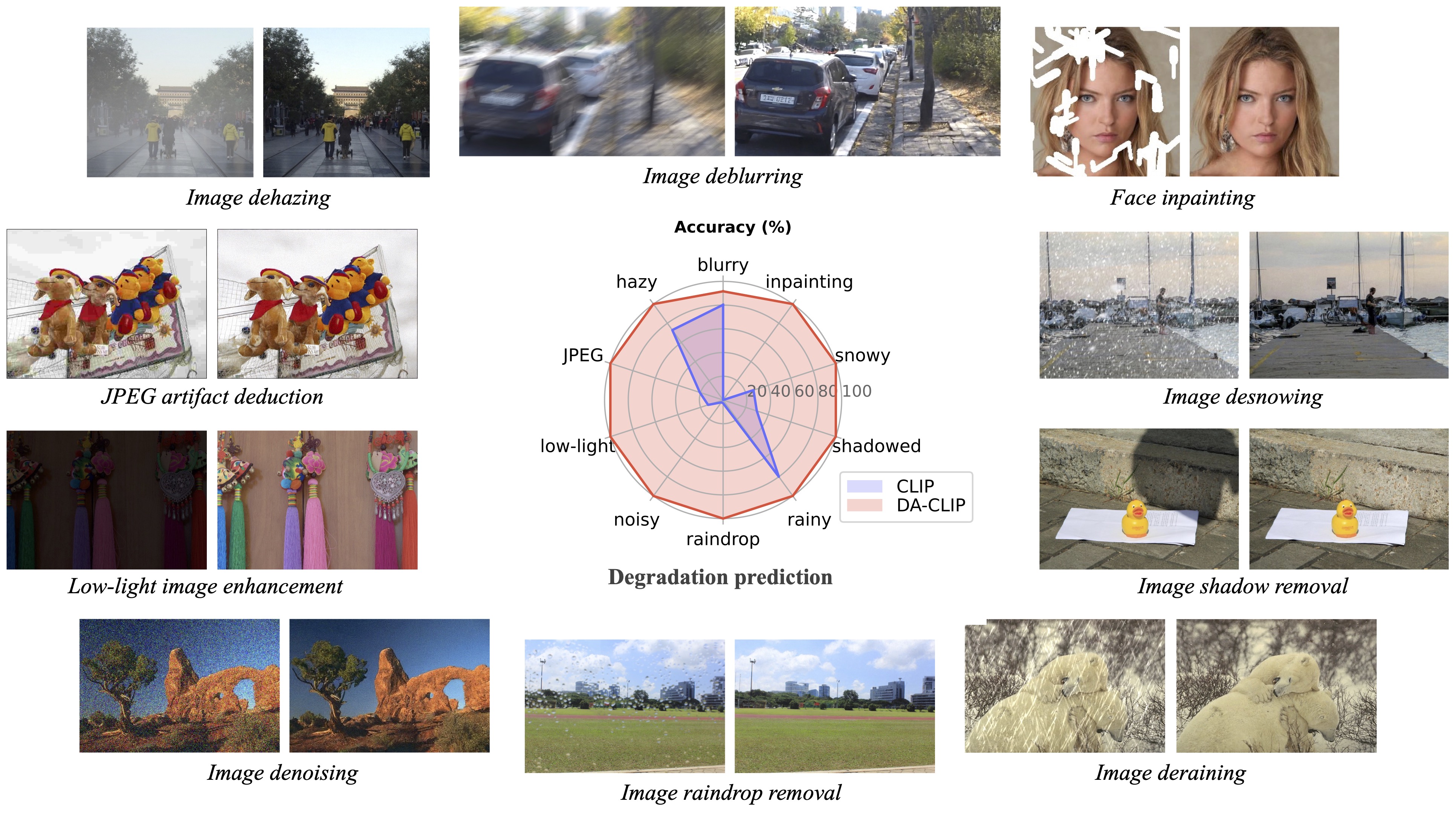
我們的後續工作《使用受控視覺語言模型進行野外照片逼真影像復原》(CVPRW 2024) 提出了後取樣,以實現更好的影像生成,並處理類似於 Real-ESRGAN 的真實世界混合降解影像。
[ 2024.04.16 ] 我們的後續論文「Photo-Realistic Image Restoration in the Wild with Controlled Vision-Language Models」現已在 ArXiv 上發布!
[ 2024.04.15 ] 更新了用於現實世界退化的野生紅外線模型和後驗採樣以實現更好的圖像生成。也為wild-ir提供了預訓練權重wild-ir.pth和wild-daclip_ViT-L-14.pt。
[ 2024.01.20 ] ???我們的DA-CLIP論文被ICLR 2024接受了?我們進一步在模型卡中提供了更強大的模型。
[ 2023.10.25 ] 新增了用於訓練和測試的資料集連結。
[ 2023.10.13 ] 新增複製示範和 api。感謝@chenxwh! !我們更新了 Hugging Face 演示和線上 Colab 演示。感謝@fffiloni和@camenduru!我們還在抱臉裡做了一張模特兒卡?並提供了更多測試範例。
[ 2023.10.09 ] DA-CLIP和Universal IR模型的預訓練權重分別在link1和link2發布。此外,我們也為您想要測試自己的圖像的情況提供了一個Gradio應用程式檔案。
作業系統:Ubuntu 20.04
英偉達:
CUDA:11.4
蟒蛇3.8
我們建議您先建立一個虛擬環境:
python3 -m venv .envsource .env/bin/activate pip安裝-U pip pip install -r 要求.txt
進入universal-image-restoration目錄並運行:
import torchfrom PIL import Imageimport open_clipcheckpoint = 'pretrained/daclip_ViT-B-32.pt'model, preprocess = open_clip.create_model_from_pretrained('daclip_Vippk-B-32', pretrained('daclip_Vixp-B-32',)p. ')image = preprocess(Image.open("haze_01.png")).unsqueeze(0)degradations = ['運動模糊','朦朧','jpeg壓縮','低光','吵雜' ,'raindrop ','rainy','shadowed','snowy','uncompleted']text = tokenizer(degradations)with torch.no_grad(), torch.cuda.amp.autocast():text_features = model.encode_text( text)image_features , degra_features = model.encode_image(image, control=True)degra_features /= degra_features.norm(dim=-1, keepdim=True)text_features /= text_features.norm(dim=-1, keepdim=-10. degra_features @ text_features.T).softmax(dim=-1)index = torch.argmax(text_probs[0])print(f"任務: {task_name}: {degradations[index]} - {text_probs[0] [指數] }”)按照我們的論文資料集建立部分準備訓練和測試資料集,如下所示:
#### 用於訓練資料集 ########(未完成意味著修復)####datasets/universal/train|--motion-blurry| |--LQ/*.png| |--GT/*.png|--朦朧|--jpeg壓縮|--低光|--吵雜|--雨滴|--雨天|--陰影|--下雪|--未完成## ## 用於測試資料集########(與train相同的結構)####datasets/universal/val ...#### 乾淨的字幕 ####datasets/universal/daclip_train.csv 資料集/通用/daclip_val.csv
然後進入universal-image-restoration/config/daclip-sde目錄並修改options/train.yml和options/test.yml中選項檔案中的資料集路徑。
您可以將更多任務或資料集新增至train和val目錄中,並將退化詞新增至distortion 。
| 降解 | 運動模糊 | 朦朧 | jpeg 壓縮* | 弱光 | 嘈雜*(與 jpeg 相同) |
|---|---|---|---|---|---|
| 數據集 | 戈普羅 | 居住-6k | DIV2K+Flickr2K | 哈哈 | DIV2K+Flickr2K |
| 降解 | 雨滴 | 下雨的 | 陰影下的 | 下雪的 | 未完成的 |
|---|---|---|---|---|---|
| 數據集 | 雨滴 | Rain100H:訓練、測試 | SRD | 雪100K | 西萊巴HQ-256 |
您應該只提取用於訓練的訓練資料集,所有驗證資料集都可以在Google Drive中下載。對於 jpeg 和雜訊資料集,您可以使用此腳本產生 LQ 影像。
詳細資訊請參閱 DA-CLIP.md。
訓練的主要程式碼位於universal-image-restoration/config/daclip-sde ,DA-CLIP的核心網路位於universal-image-restoration/open_clip/daclip_model.py 。
將預先訓練的DA-CLIP 權重放入pretrained目錄並檢查daclip路徑。
然後,您可以按照以下 bash 腳本訓練模型:
cd universal-image-restoration/config/daclip-sde# 對於單一GPU:python3 train.py -opt=options/train.yml# 對於分散式訓練,需要更改選項檔案中的gpu_ids python3 -m torch.distributed.launch選項檔案中的gpu_ids python3 -m torch.distributed.launch選項檔案中的gpu_ids python3 -m torch.distributed.launch選項檔案中的gpu_ids python3 -m torch.distributed.launch選項檔- -nproc_per_node=2 --master_port=4321 train.py -opt=options/train.yml --launcher pytorch
模型和訓練日誌將保存在log/universal-ir中。您可以透過執行tail -f log/universal-ir/train_universal-ir_***.log -n 100來列印日誌。
相同的訓練步驟可用於野外(wild-ir)影像恢復。
| 型號名稱 | 描述 | Google雲端硬碟 | 抱臉 |
|---|---|---|---|
| DA-CLIP | 退化感知 CLIP 模型 | 下載 | 下載 |
| 通用紅外線 | 基於DA-CLIP的通用影像修復模型 | 下載 | 下載 |
| DA-CLIP-混合 | 退化感知 CLIP 模型(加入高斯模糊 + 臉部修復和高斯模糊 + Rainy) | 下載 | 下載 |
| 通用紅外線混合 | 基於 DA-CLIP 的通用影像恢復模型(新增穩健訓練和混合降級) | 下載 | 下載 |
| 野生DA-CLIP | 野外環境中的降解感知 CLIP 模型 (ViT-L-14) | 下載 | 下載 |
| 野生紅外線 | 基於DA-CLIP的野外影像復原模型 | 下載 | 下載 |
若要評估我們的影像復原方法,請修改基準路徑和模型路徑並運行
cd 通用影像復原/config/universal-ir python test.py -opt=選項/test.yml
這裡我們提供了一個 app.py 檔案來測試您自己的圖像。在此之前,您需要下載預先訓練的權重(DA-CLIP和UIR)並修改options/test.yml中的模型路徑。然後只需執行python app.py ,您就可以開啟http://localhost:7860來測試模型。 (我們還在images目錄中提供了幾個具有不同降級的圖像)。我們還提供了來自Google驅動器中測試資料集的更多範例。
相同的步驟可用於野外 (wild-ir) 影像復原。
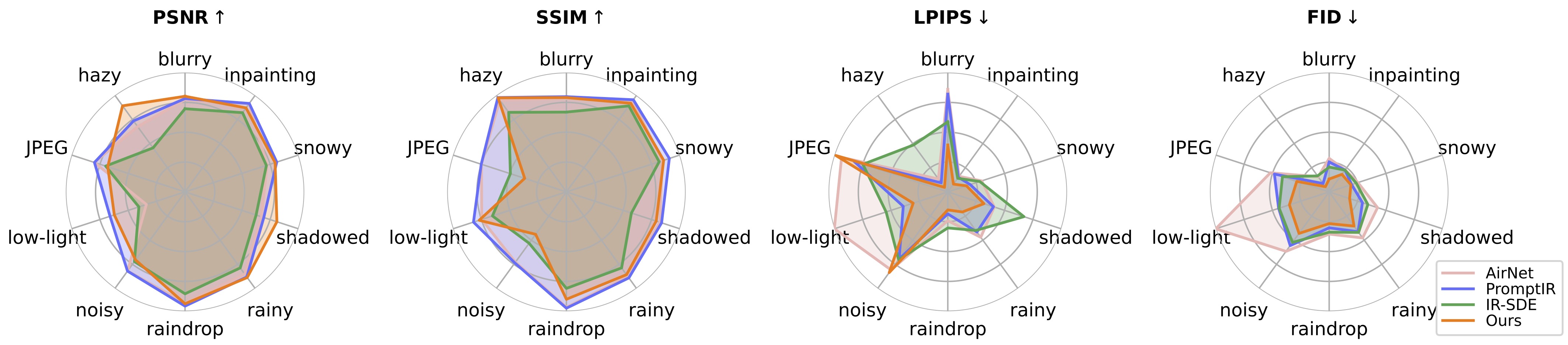



?在測試中,我們發現目前的預訓練模型仍然難以處理一些現實世界的影像,這些影像可能與我們的訓練資料集(從不同的裝置擷取或具有不同的解析度或退化)發生分佈變化。我們將其視為未來的工作,並將努力使我們的模型更加實用!我們也鼓勵對我們的工作感興趣的用戶使用更大的資料集和更多的退化類型來訓練自己的模型。
?順便說一句,我們還發現直接調整輸入影像的大小會導致大多數任務的表現不佳。我們可以嘗試在訓練中加入調整大小步驟,但由於插值,它總是會破壞影像品質。
?對於修復任務,由於資料集限制,我們目前的模型僅支援臉部修復。我們提供了遮罩範例,您可以使用generate_masked_face腳本來產生未完成的臉部。
致謝:我們的 DA-CLIP 是基於 IR-SDE 和 open_clip。感謝他們的代碼!
如有任何疑問,請聯絡:[email protected]
如果我們的程式碼對您的研究或工作有幫助,請考慮引用我們的論文。以下是 BibTeX 參考文獻:
@article{luo2023controlling,
title={Controlling Vision-Language Models for Universal Image Restoration},
author={Luo, Ziwei and Gustafsson, Fredrik K and Zhao, Zheng and Sj{"o}lund, Jens and Sch{"o}n, Thomas B},
journal={arXiv preprint arXiv:2310.01018},
year={2023}
}
@article{luo2024photo,
title={Photo-Realistic Image Restoration in the Wild with Controlled Vision-Language Models},
author={Luo, Ziwei and Gustafsson, Fredrik K and Zhao, Zheng and Sj{"o}lund, Jens and Sch{"o}n, Thomas B},
journal={arXiv preprint arXiv:2404.09732},
year={2024}
}

