MagicMix
1.0.0
MagicMix 的實現:語意混合與擴散模型論文。
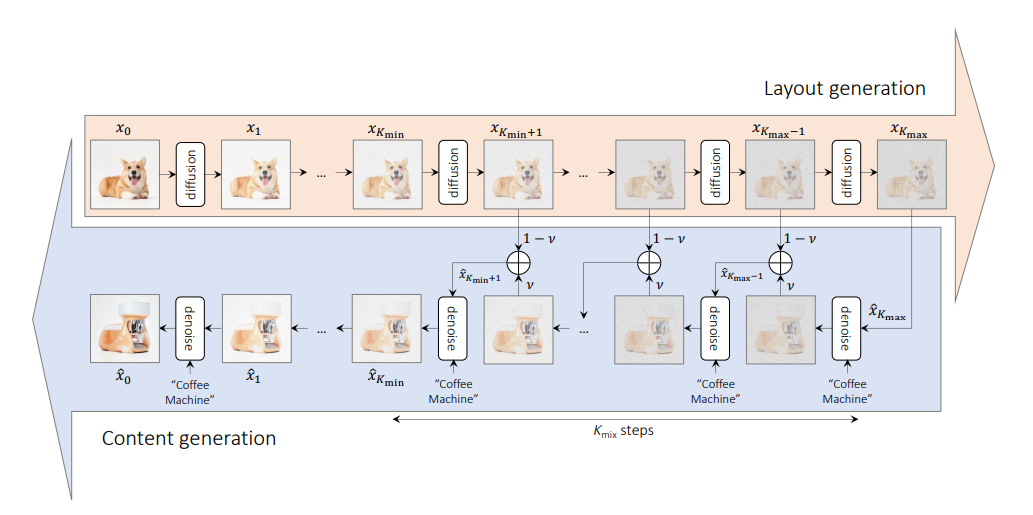
該方法的目的是以語義方式混合兩個不同的概念以合成一個新概念,同時保留空間佈局和幾何形狀。
此方法採用提供佈局語義的圖像和為混合過程提供內容語義的提示。
此方法有 3 個參數 -
v :佈局產生階段所使用的內插常數。 v的值越大,提示對佈局產生過程的影響越大。kmax和kmin :它們決定佈局和內容產生過程的範圍。 kmax 值越高,會導致遺失更多有關原始影像佈局的信息,而 kmin 值越高,會導致內容生成過程的步驟更多。 from PIL import Image
from magic_mix import magic_mix
img = Image . open ( 'phone.jpg' )
out_img = magic_mix ( img , 'bed' , kmax = 0.5 )
out_img . save ( "mix.jpg" ) python3 magic_mix.py
"phone.jpg"
"bed"
"mix.jpg"
--kmin 0.3
--kmax 0.6
--v 0.5
--steps 50
--seed 42
--guidance_scale 7.5
另外,請查看演示筆記本,以了解實現的使用範例,以重現論文中的範例。
您也可以使用擴散器庫上的社區管道。
from diffusers import DiffusionPipeline , DDIMScheduler
from PIL import Image
pipe = DiffusionPipeline . from_pretrained (
"CompVis/stable-diffusion-v1-4" ,
custom_pipeline = "magic_mix" ,
scheduler = DDIMScheduler . from_pretrained ( "CompVis/stable-diffusion-v1-4" , subfolder = "scheduler" ),
). to ( 'cuda' )
img = Image . open ( 'phone.jpg' )
mix_img = pipe (
img ,
prompt = 'bed' ,
kmin = 0.3 ,
kmax = 0.5 ,
mix_factor = 0.5 ,
)
mix_img . save ( 'mix.jpg' )







我不是論文的作者,這也不是官方的實現


