meme search engine
1.0.0
您是否有一個大資料夾想要進行語義搜尋?您有配備 Nvidia GPU 的 Linux 伺服器嗎?你做;現在這是強制性的。
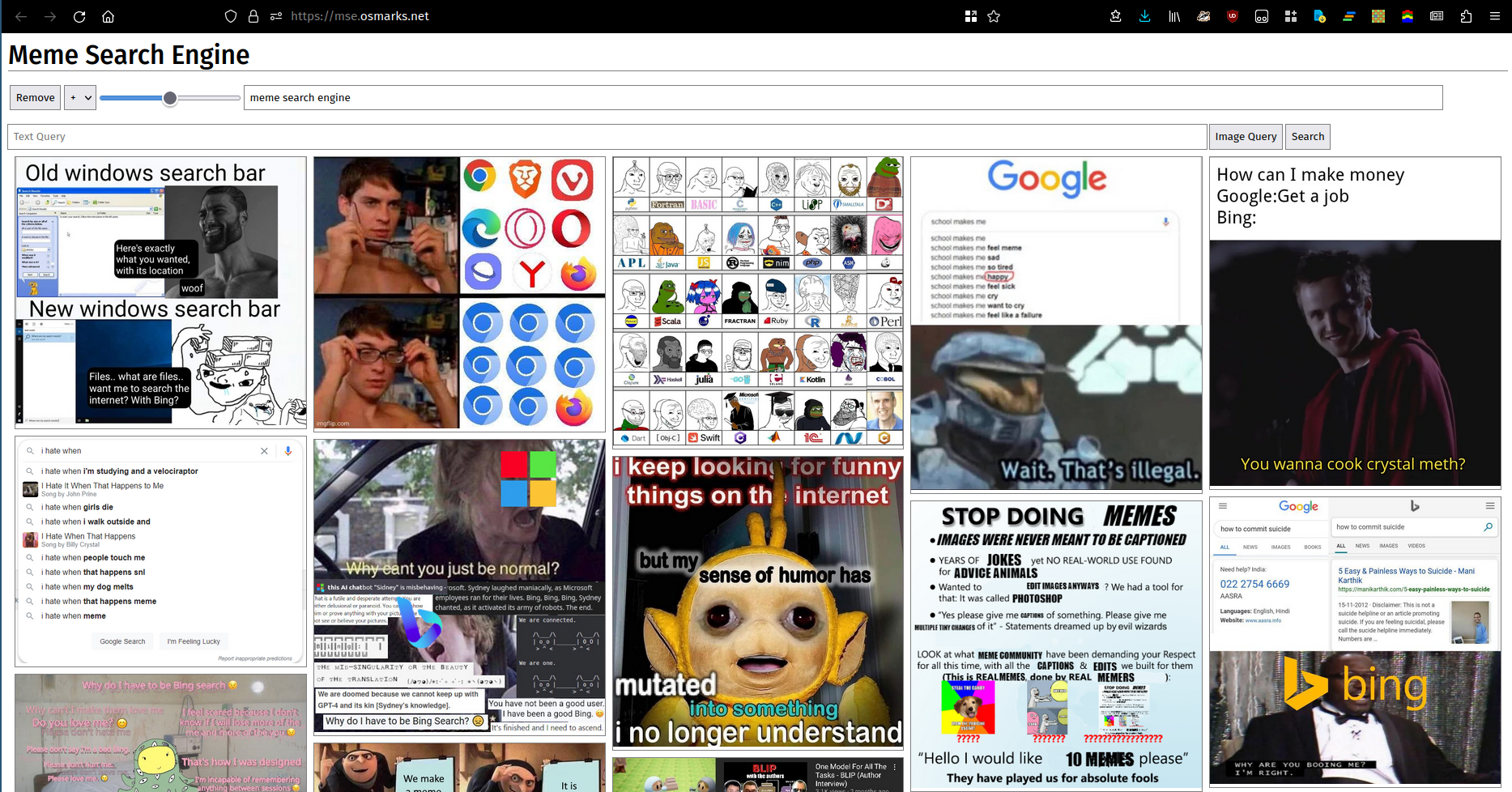
他們說一張圖片勝過一千個文字。不幸的是,許多(大多數?)單字組無法透過圖片充分描述。無論如何,這是一張照片。您可以在此處使用正在運行的實例。
這是未經測試的。它可能會起作用。新的 Rust 版本簡化了一些步驟(它整合了自己的縮圖)。
python -m http.server 。requirements.txt中的pip安裝Python依賴項(如果您需要更改版本,則版本可能不需要完全匹配;我只是輸入目前已安裝的版本)。transformers的修補版本。thumbnailer.py (定期運行,最好與索引重新加載同時運行)clip_server.py (作為後台服務)。clip_server_config.json中有一個範例。device可能應該是cuda或cpu 。該模型將在這裡運行。model是model_name是用於指標目的的模型名稱。max_batch_size控制允許的最大批次大小。較高的值通常會帶來更好的效能(但目前大多數情況下瓶頸在其他地方),但代價是更高的 VRAM 使用量。port是運行 HTTP 伺服器的連接埠。meme-search-engine (Rust)(也作為後台服務)。clip_server是後端伺服器的完整 URL。db_path是圖像和嵌入向量的 SQLite 資料庫的路徑。files是讀取迷因檔案的地方。子目錄已建立索引。port是提供 HTTP 服務的連接埠。enable_thumbs設為true以提供壓縮映像。npm install , node src/build.js 。frontend_config.json時,您都需要重建它。image_path是 meme 網路伺服器的基本 URL(有尾部斜線)。backend_url是mse.py公開的 URL(尾部斜線可能是可選的)。clip_server.py 。 有關 MemeThresher 的信息,請參閱此處,這是新的自動 meme 獲取/評級系統(位於meme-rater下)。自己部署預計會有些棘手,但應該大致可行:
crawler.py並運行它以收集初始資料集。mse.py以對其進行索引。rater_server.py收集初始資料集對。train.py訓練模型。您可能需要調整超參數,因為我不知道哪些是好的。active_learning.py來獲取新的對進行評分。copy_into_queue.py將新對複製到rater_server.py佇列中。library_processing_server.py並安排meme_pipeline.py定期運行。 Meme 搜尋引擎使用記憶體中的 FAISS 索引來保存其嵌入向量,因為我很懶,但它運作得很好(我的 8000 個 meme 使用了約 100MB 的總 RAM)。如果您想儲存更多的數據,則必須切換到更有效率/緊湊的索引(請參見此處)。由於向量索引僅保存在記憶體中,因此您需要將它們持久保存到磁碟或使用快速建立/刪除/添加的向量索引(大概是 PCA/PQ 索引)。在某些時候,如果增加總流量,CLIP 模型也可能成為瓶頸,因為我也沒有批次策略。索引目前受 GPU 限制,因為新模型在高批次大小下看起來有些慢,並且我改進了圖像載入管道。您可能還想縮小顯示的迷因以減少頻寬需求。


