PixArt alpha
1.0.0
conda create -n pixart python=3.9
conda activate pixart
pip install torch==2.1.1 torchvision==0.16.1 torchaudio==2.1.1 --index-url https://download.pytorch.org/whl/cu118
git clone https://github.com/PixArt-alpha/PixArt-alpha.git
cd PixArt-alpha
pip install -r requirements.txt所有模型都會自動下載。您也可以選擇從此網址手動下載。
| 模型 | #參數 | 網址 | 在 OpenXLab 中下載 |
|---|---|---|---|
| T5 | 4.3B | T5 | T5 |
| VAE | 80M | VAE | VAE |
| 原相-α-SAM-256 | 0.6B | PixArt-XL-2-SAM-256x256.pth 或擴散器版本 | 256-薩姆 |
| 原相-α-256 | 0.6B | PixArt-XL-2-256x256.pth 或擴散器版本 | 256 |
| 原相-α-256-MSCOCO-FID7.32 | 0.6B | 原相-XL-2-256x256.pth | 256 |
| 原相-α-512 | 0.6B | PixArt-XL-2-512x512.pth 或擴散器版本 | 第512章 |
| 原相-α-1024 | 0.6B | PixArt-XL-2-1024-MS.pth 或擴散器版本 | 1024 |
| 原相-δ-1024-LCM | 0.6B | 擴散器版本 | |
| ControlNet-HED-編碼器 | 30M | ControlNetHED.pth | |
| 原相-δ-512-ControlNet | 0.9B | PixArt-XL-2-512-ControlNet.pth | 第512章 |
| 原相-δ-1024-ControlNet | 0.9B | PixArt-XL-2-1024-ControlNet.pth | 1024 |
也可以在 OpenXLab_PixArt-alpha 中找到所有模型
首先。
感謝@kopyl,您可以使用筆記本在 HugginFace 的 Pokemon 資料集上重現完整的微調訓練流程:
那麼,就了解更多詳情。
這裡我們以 SAM 資料集訓練配置為例,當然,您也可以依照此方法準備自己的資料集。
您只需要更改配置中的設定檔和資料集中的資料載入器。
python -m torch.distributed.launch --nproc_per_node=2 --master_port=12345 train_scripts/train.py configs/pixart_config/PixArt_xl2_img256_SAM.py --work-dir output/train_SAM_256SAM資料集的目錄結構為:
cd ./data
SA1B
├──images/ (images are saved here)
│ ├──sa_xxxxx.jpg
│ ├──sa_xxxxx.jpg
│ ├──......
├──captions/ (corresponding captions are saved here, same name as images)
│ ├──sa_xxxxx.txt
│ ├──sa_xxxxx.txt
├──partition/ (all image names are stored txt file where each line is a image name)
│ ├──part0.txt
│ ├──part1.txt
│ ├──......
├──caption_feature_wmask/ (run tools/extract_caption_feature.py to generate caption T5 features, same name as images except .npz extension)
│ ├──sa_xxxxx.npz
│ ├──sa_xxxxx.npz
│ ├──......
├──img_vae_feature/ (run tools/extract_img_vae_feature.py to generate image VAE features, same name as images except .npy extension)
│ ├──train_vae_256/
│ │ ├──noflip/
│ │ │ ├──sa_xxxxx.npy
│ │ │ ├──sa_xxxxx.npy
│ │ │ ├──......
這裡我們準備data_toy以便更好的理解
cd ./data
git lfs install
git clone https://huggingface.co/datasets/PixArt-alpha/data_toy然後,這是partition/part0.txt 檔案的範例。
此外,對於 json 檔案引導訓練,這裡有一個玩具 json 檔案以便更好地理解。
遵循Pixart + DreamBooth培訓指導
遵循PixArt + LCM培訓指導
遵循PixArt + ControlNet訓練指導
pip install peft==0.6.2
accelerate launch --num_processes=1 --main_process_port=36667 train_scripts/train_pixart_lora_hf.py --mixed_precision= " fp16 "
--pretrained_model_name_or_path=PixArt-alpha/PixArt-XL-2-1024-MS
--dataset_name=lambdalabs/pokemon-blip-captions --caption_column= " text "
--resolution=1024 --random_flip
--train_batch_size=16
--num_train_epochs=200 --checkpointing_steps=100
--learning_rate=1e-06 --lr_scheduler= " constant " --lr_warmup_steps=0
--seed=42
--output_dir= " pixart-pokemon-model "
--validation_prompt= " cute dragon creature " --report_to= " tensorboard "
--gradient_checkpointing --checkpoints_total_limit=10 --validation_epochs=5
--rank=16使用此儲存庫進行推理需要至少23GB GPU 內存,而在 ? 中使用則需要11GB and 8GB 。擴散器。
目前支援:
首先,先安裝所需的依賴項。確保您已將模型下載到 output/pretrained_models 資料夾,然後在本機電腦上執行:
DEMO_PORT=12345 python app/app.py作為替代方案,提供了一個範例 Dockerfile 來建立啟動 Gradio 應用程式的執行時間容器。
docker build . -t pixart
docker run --gpus all -it -p 12345:12345 -v < path_to_huggingface_cache > :/root/.cache/huggingface pixart或使用 docker-compose。請注意,如果您想將應用程式的上下文從 1024 更改為 512 或 LCM 版本,只需更改 docker-compose.yml 檔案中的 APP_CONTEXT 環境變數即可。預設為 1024
docker compose build
docker compose up讓我們來看一個使用http://your-server-ip:12345的簡單範例。
確保您擁有以下庫的更新版本:
pip install -U transformers accelerate diffusers SentencePiece ftfy beautifulsoup4進而:
import torch
from diffusers import PixArtAlphaPipeline , ConsistencyDecoderVAE , AutoencoderKL
device = torch . device ( "cuda:0" if torch . cuda . is_available () else "cpu" )
# You can replace the checkpoint id with "PixArt-alpha/PixArt-XL-2-512x512" too.
pipe = PixArtAlphaPipeline . from_pretrained ( "PixArt-alpha/PixArt-XL-2-1024-MS" , torch_dtype = torch . float16 , use_safetensors = True )
# If use DALL-E 3 Consistency Decoder
# pipe.vae = ConsistencyDecoderVAE.from_pretrained("openai/consistency-decoder", torch_dtype=torch.float16)
# If use SA-Solver sampler
# from diffusion.sa_solver_diffusers import SASolverScheduler
# pipe.scheduler = SASolverScheduler.from_config(pipe.scheduler.config, algorithm_type='data_prediction')
# If loading a LoRA model
# transformer = Transformer2DModel.from_pretrained("PixArt-alpha/PixArt-LCM-XL-2-1024-MS", subfolder="transformer", torch_dtype=torch.float16)
# transformer = PeftModel.from_pretrained(transformer, "Your-LoRA-Model-Path")
# pipe = PixArtAlphaPipeline.from_pretrained("PixArt-alpha/PixArt-LCM-XL-2-1024-MS", transformer=transformer, torch_dtype=torch.float16, use_safetensors=True)
# del transformer
# Enable memory optimizations.
# pipe.enable_model_cpu_offload()
pipe . to ( device )
prompt = "A small cactus with a happy face in the Sahara desert."
image = pipe ( prompt ). images [ 0 ]
image . save ( "./catcus.png" )查看文件以取得有關 SA-Solver Sampler 的更多資訊。
這種整合允許在 11 GB GPU VRAM 下運行批量大小為 4 的管道。查看文件以了解更多資訊。
PixArtAlphaPipeline現在支援 8 GB 以下的 GPU VRAM 消耗,請參閱文件以了解更多資訊。
首先,首先安裝所需的依賴項,然後在本機電腦上執行:
# diffusers version
DEMO_PORT=12345 python app/app.py讓我們來看一個使用http://your-server-ip:12345的簡單範例。
您也可以點擊此處在 Google Colab 上免費試用。
python tools/convert_pixart_alpha_to_diffusers.py --image_size your_img_size --multi_scale_train (True if you use PixArtMS else False) --orig_ckpt_path path/to/pth --dump_path path/to/diffusers --only_transformer=True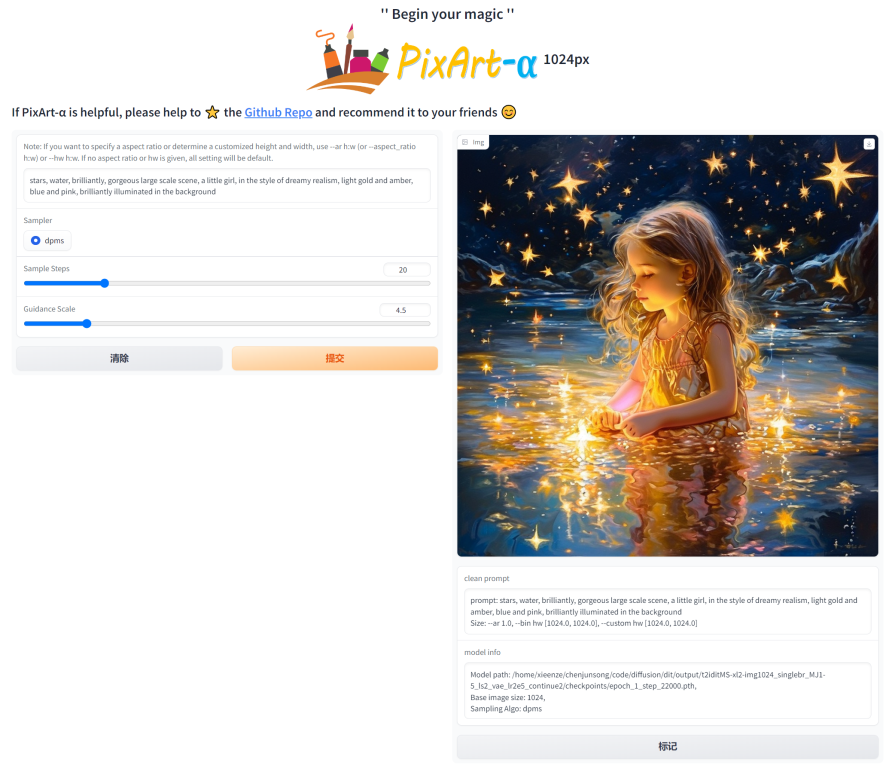
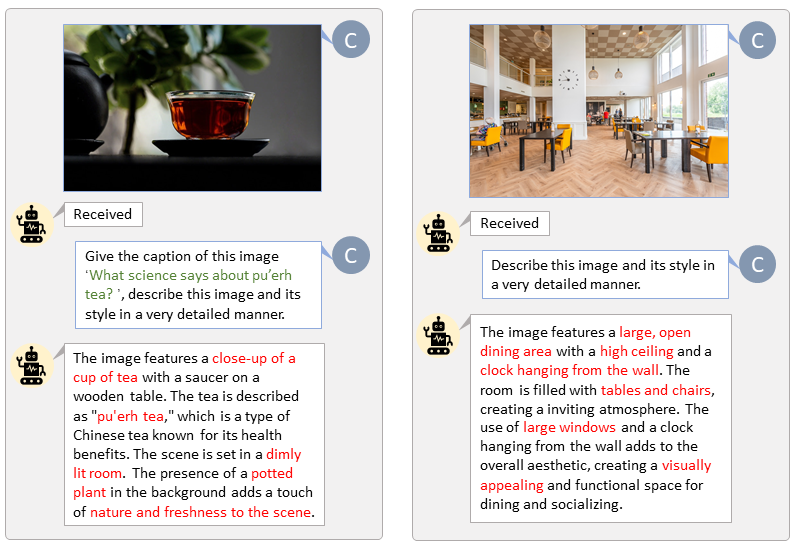
借助 LLaVA-Lightning-MPT 的程式碼庫,我們可以使用以下啟動程式碼為 LAION 和 SAM 資料集新增標題:
python tools/VLM_caption_lightning.py --output output/dir/ --data-root data/root/path --index path/to/data.json我們為 LAION(左)和 SAM(右)提供帶有自訂提示的自動標記。綠色突出顯示的單字代表 LAION 中的原始字幕,而紅色標記的單字表示 LLaVA 標記的詳細字幕。
提前準備T5文字特徵和VAE影像特徵將加快訓練過程並節省GPU記憶體。
python tools/extract_features.py --img_size=1024
--json_path " data/data_info.json "
--t5_save_root " data/SA1B/caption_feature_wmask "
--vae_save_root " data/SA1B/img_vae_features "
--pretrained_models_dir " output/pretrained_models "
--dataset_root " data/SA1B/Images/ " 我們製作了一個視頻,將 PixArt 與當前最強大的文本到圖像模型進行比較。
@misc{chen2023pixartalpha,
title={PixArt-$alpha$: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis},
author={Junsong Chen and Jincheng Yu and Chongjian Ge and Lewei Yao and Enze Xie and Yue Wu and Zhongdao Wang and James Kwok and Ping Luo and Huchuan Lu and Zhenguo Li},
year={2023},
eprint={2310.00426},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
@misc{chen2024pixartdelta,
title={PIXART-{delta}: Fast and Controllable Image Generation with Latent Consistency Models},
author={Junsong Chen and Yue Wu and Simian Luo and Enze Xie and Sayak Paul and Ping Luo and Hang Zhao and Zhenguo Li},
year={2024},
eprint={2401.05252},
archivePrefix={arXiv},
primaryClass={cs.CV}
}


