Agent FLAN
1.0.0
[?擁抱臉] [? OpenXLab] [?論文] [ 項目頁]
開源的大型語言模型(LLM)在各種 NLP 任務中取得了巨大的成功,但在充當代理時,它們仍然遠遠不如基於 API 的模型。如何將代理能力融入普通法學碩士課程中成為一個至關重要而緊迫的問題。本文首先提出了三個關鍵觀察:(1)目前的智能體訓練語料庫與格式遵循和智能體推理糾纏在一起,這與預訓練資料的分佈發生了顯著的變化; (2) LLM 對代理任務所需的能力表現出不同的學習速度; (3)目前的方法在透過引入幻覺來提高代理能力時存在副作用。基於上述發現,我們提出 Agent-FLAN 來有效微調 Agent 的語言模型。透過訓練語料庫的仔細分解和重新設計,Agent-FLAN 使 Llama2-7B 在各種代理人評估資料集上的表現比之前的最佳作品高出 3.5%。透過全面建構負樣本,Agent-FLAN 根據我們建立的評估基準極大地緩解了幻覺問題。此外,它在擴展模型大小時持續提高了 LLM 的代理能力,同時略微增強了 LLM 的一般能力。
Agent-FLAN系列應用Agent-FLAN論文中提出的資料產生管道在AgentInstruct和Toolbench上進行了微調,對各種Agent任務和工具利用具有很強的能力~
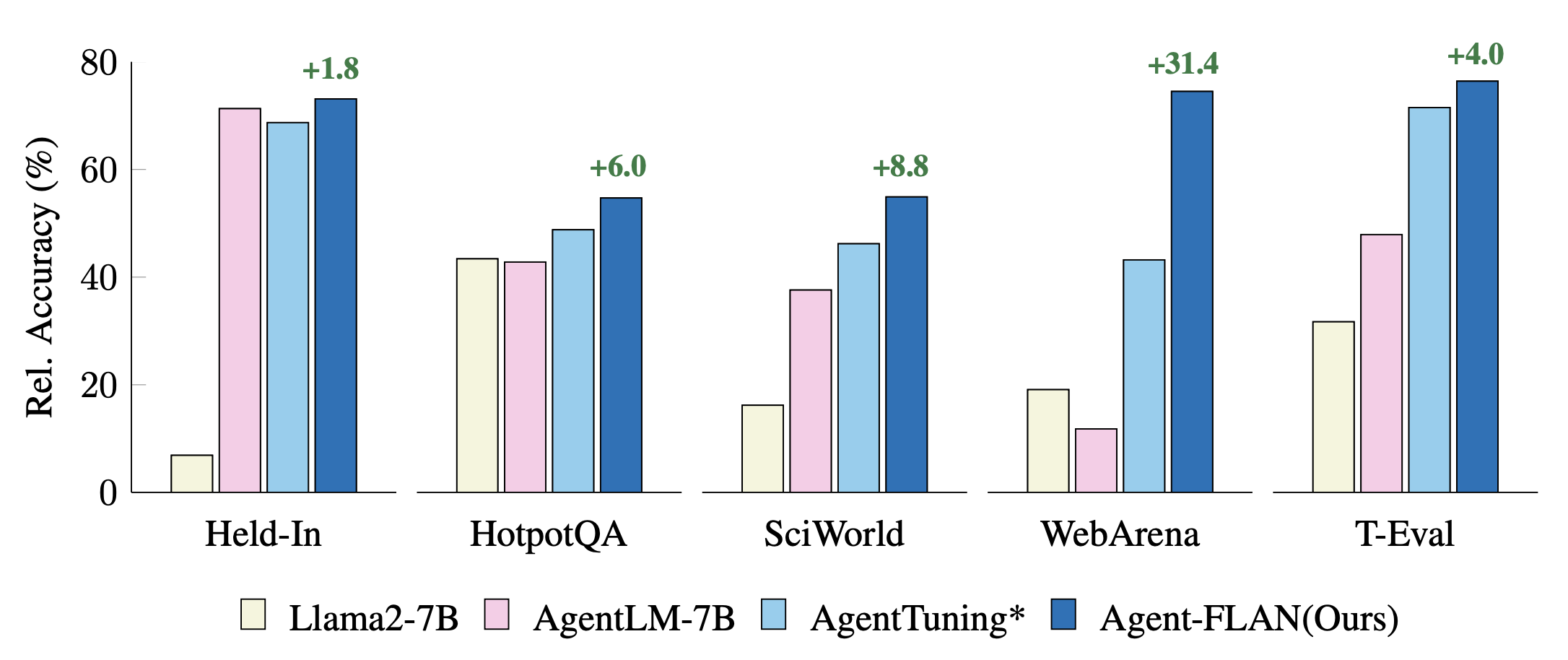
最近的代理調整方法在保留、保留任務上的比較。性能使用 GPT-4 結果進行標準化,以獲得更好的視覺化效果。 * 表示我們為了公平比較而重新實現。
Agent-FLAN 是透過對 Llama2-chat 系列的 AgentInstruct、ToolBench 和 ShareGPT 資料集進行混合訓練而產生的。
模型遵循Llama-2-chat的對話格式,範本協定為:
dict ( role = 'user' , begin = '<|Human|>െ' , end = ' n ' ),
dict ( role = 'system' , begin = '<|Human|>െ' , end = ' n ' ),
dict ( role = 'assistant' , begin = '<|Assistant|>െ' , end = 'ി n ' ),7B 模型可在 Huggingface 和 OpenXLab 模型中心取得。
| 模型 | 擁抱臉回購 | OpenXLab 儲存庫 |
|---|---|---|
| 代理-FLAN-7B | 型號連結 | 型號連結 |
Agent-FLAN 資料集也可在 Huggingface 資料集中心取得。
| 數據集 | 擁抱臉回購 |
|---|---|
| 代理FLAN | 資料集連結 |
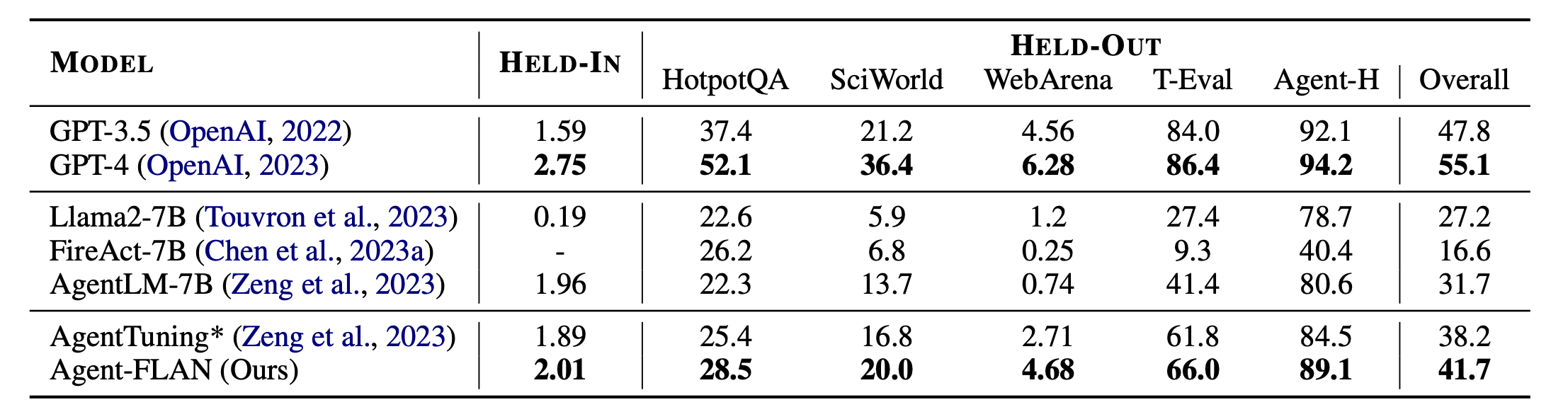
Agent-FLAN的主要結果。 Agent-FLAN 在保留任務和保留任務上都大大優於先前的代理調整方法。 * 表示我們使用相同數量的訓練資料重新實現,以便進行公平比較。由於 FireAct 不在 AgentInstruct 資料集上進行訓練,因此我們忽略了它在 HELD-IN 集上的效能。 Bold:基於 API 的最佳開源模型。
Agent-FLAN是用Lagent和T-Eval建構的。感謝他們出色的工作!
如果您發現該項目對您的研究有用,請考慮引用:
@article{chen2024agent,
title={Agent-FLAN: Designing Data and Methods of Effective Agent Tuning for Large Language Models},
author={Chen, Zehui and Liu, Kuikun and Wang, Qiuchen and Zhang, Wenwei and Liu, Jiangning and Lin, Dahua and Chen, Kai and Zhao, Feng},
journal={arXiv preprint arXiv:2403.12881},
year={2024}
}
該專案是在 Apache 2.0 許可證下發布的。


