datablations
1.0.0
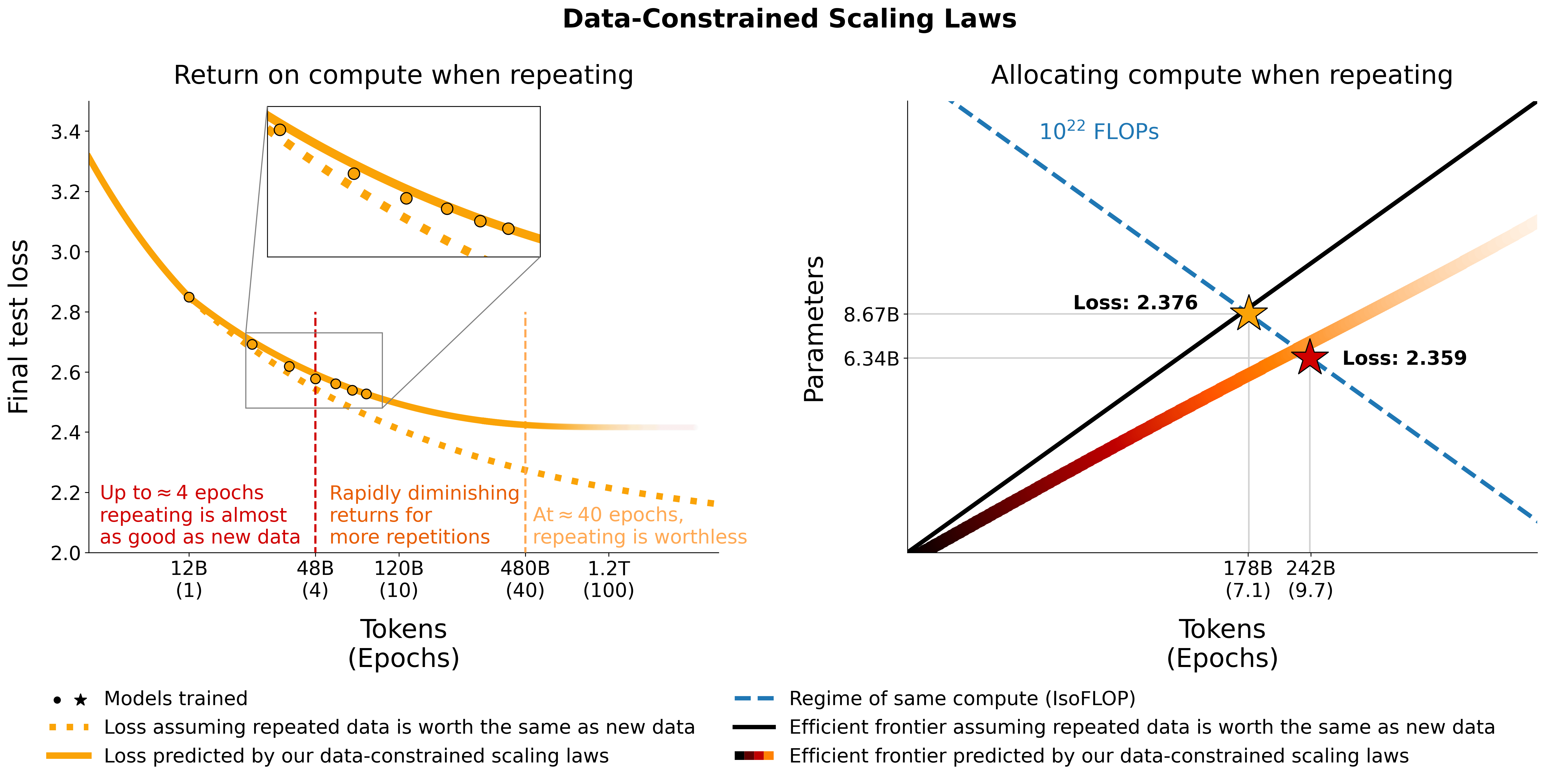
該儲存庫提供了《擴展資料約束語言模型》一文中所有元件的概述。紙上談話:
我們研究資料受限條件下的擴展語言模型。我們進行了大量不同資料重複程度和計算預算的實驗,範圍高達 9,000 億個訓練令牌和 90 億個參數模型。根據我們的運行,我們提出並憑經驗驗證計算最優性的縮放法則,該法則解釋了重複標記和多餘參數的值遞減的情況。我們也嘗試了緩解資料稀缺的方法,包括使用程式碼資料增強訓練資料集、困惑過濾和重複資料刪除。我們 400 次訓練運行的模型和資料集可透過此儲存庫取得。
我們對 C4 上的重複資料和 OSCAR 的非重複資料英文分割進行了實驗。對於每個資料集,我們下載資料並將其轉換為單一 jsonl 文件,分別為c4.jsonl和oscar_en.jsonl 。
然後我們決定獨特標記的數量以及我們需要從資料集中獲取的樣本數量。請注意,C4 每個樣本有478.625834583個令牌,OSCAR 使用 GPT2Tokenizer 有1312.0951072 。這是透過對整個資料集進行標記並將標記數量除以樣本數量來計算的。我們使用這些數字來計算所需的樣本。
例如,對於 1.9B 唯一令牌,我們需要1.9B / 478.625834583 = 3969697.96178個樣本用於1.9B / 1312.0951072 = 1448065.76107個樣本用於 OS。為了標記數據,我們首先需要克隆 Megatron-DeepSpeed 儲存庫並遵循其設定指南。然後我們選擇這些樣本並對它們進行標記,如下所示:
C4:
head -n 3969698 c4.jsonl > c4_1b9.jsonl
python Megatron-DeepSpeed/tools/preprocess_data_many_cores.py
--input c4_1b9.jsonl
--output-prefix gpt2tok_c4_en_1B9
--dataset-impl mmap
--tokenizer-type PretrainedFromHF
--tokenizer-name-or-path gpt2
--append-eod
--workers 64奧斯卡:
head -n 1448066 oscar_en.jsonl > oscar_1b9.jsonl
python Megatron-DeepSpeed/tools/preprocess_data_many_cores.py
--input oscar_1b9.jsonl
--output-prefix gpt2tok_oscar_en_1B9
--dataset-impl mmap
--tokenizer-type PretrainedFromHF
--tokenizer-name-or-path gpt2
--append-eod
--workers 64其中gpt2指向包含 https://huggingface.co/gpt2/tree/main 中的所有檔案的資料夾。透過使用head ,我們確保不同的子集將具有重疊的樣本,以減少隨機性。
對於訓練期間的評估和最終評估,我們使用 C4 的驗證集:
from datasets import load_dataset
load_dataset ( "c4" , "en" , split = "validation" ). to_json ( "c4-en-validation.json" )python Megatron-DeepSpeed/tools/preprocess_data_many_cores.py
--input c4-en-validation.jsonl
--output-prefix gpt2tok_c4validation_rerun
--dataset-impl mmap
--tokenizer-type PretrainedFromHF
--tokenizer-name-or-path gpt2
--append-eod
--workers 2對於沒有官方驗證集的 OSCAR,我們透過執行tail -364608 oscar_en.jsonl > oscarvalidation.jsonl來取得訓練集的一部分,然後將其標記化如下:
python Megatron-DeepSpeed/tools/preprocess_data_many_cores.py --input oscarvalidation.jsonl --output-prefix gpt2tok_oscarvalidation --dataset-impl mmap --tokenizer-type PretrainedFromHF --tokenizer-name-or-path gpt2 --append-eod --workers 2我們已經上傳了幾個預處理的子集以供 megatron 使用:
有些 bin 檔案對 git 來說太大,因此使用split --number=l/40 gpt2tok_c4_en_1B9.bin gpt2tok_c4_en_1B9.bin.並split --number=l/40 gpt2tok_oscar_en_1B9.bin gpt2tok_oscar_en_1B9.bin. 。要使用它們進行訓練,您需要使用cat gpt2tok_c4_en_1B9.bin.* > gpt2tok_c4_en_1B9.bin和cat gpt2tok_oscar_en_1B9.bin.* > gpt2tok_oscar_en_1B9.bin將它們再次組合在一起。
我們使用來自 the-stack-dedup 的 Python 拆分來嘗試將程式碼與自然語言資料混合。我們下載數據,將其轉換為單個 jsonl 文件,並使用與上述相同的方法對其進行預處理。
我們在這裡上傳了 megatron 的預處理版本:https://huggingface.co/datasets/datablations/python-megatron。我們使用split --number=l/40 gpt2tok_python_content_document.bin gpt2tok_python_content_document.bin. ,因此您需要使用cat gpt2tok_python_content_document.bin.* > gpt2tok_python_content_document.bin再次將它們放在一起進行訓練。
我們建立了具有困惑度和重複資料刪除相關過濾元資料的 C4 和 OSCAR 版本:
若要重新建立這些元資料資料集,請參閱filtering/README.md中的說明。
我們提供可用於威震天訓練的標記化版本:
.bin檔案使用split --number=l/10 gpt2tok_oscar_en_perplexity_25_text_document.bin gpt2tok_oscar_en_perplexity_25_text_document.bin. ,因此您需要透過cat gpt2tok_oscar_en_perplexity_25_text_document.bin. > gpt2tok_oscar_en_perplexity_25_text_document.bin 。
若要重新建立給定元資料資料集的標記化版本,
filtering/deduplication/filter_oscar_jsonl.py若要建立困惑度百分位數,請按照以下說明操作。
C4:
from datasets import load_dataset
import numpy as np
ds = load_dataset ( "datablations/c4-filter" , streaming = False , num_proc = 128 )
p_25 = np . percentile ( ds [ "train" ][ "perplexity" ], 25 )
p_50 = np . percentile ( ds [ "train" ][ "perplexity" ], 50 )
p_75 = np . percentile ( ds [ "train" ][ "perplexity" ], 75 )
# 25 - 75th percentile
ds [ "train" ]. filter ( lambda x : p_25 < x [ "perplexity" ] < p_75 , num_proc = 128 ). to_json ( "c4_perplexty2575.jsonl" , num_proc = 128 , force_ascii = False )
# 25th percentile
ds [ "train" ]. filter ( lambda x : x [ "perplexity" ] < p_25 , num_proc = 128 ). to_json ( "c4_perplexty25.jsonl" , num_proc = 128 , force_ascii = False )
# 50th percentile
ds [ "train" ]. filter ( lambda x : x [ "perplexity" ] < p_50 , num_proc = 128 ). to_json ( "c4_perplexty50.jsonl" , num_proc = 128 , force_ascii = False )奧斯卡:
from datasets import load_dataset
import numpy as np
ds = load_dataset ( "datablations/oscar-filter" , use_auth_token = True , streaming = False , num_proc = 128 )
p_25 = np . percentile ( ds [ "train" ][ "perplexity_score" ], 25 )
p_50 = np . percentile ( ds [ "train" ][ "perplexity_score" ], 50 )
# 25th percentile
ds [ "train" ]. filter ( lambda x : x [ "perplexity_score" ] < p_25 , num_proc = 128 ). remove_columns ([ 'meta' , 'perplexity_score' , 'text_length' , 'url' , 'domain' , 'dup_ratio' , 'pairs' , 'repetitions' , 'included_in_dedup' , 'cluster' , 'id' ]). to_json ( "oscar_perplexity25.jsonl" , num_proc = 128 , force_ascii = False )
# 50th percentile
ds [ "train" ]. filter ( lambda x : x [ "perplexity_score" ] < p_50 , num_proc = 128 ). remove_columns ([ 'meta' , 'perplexity_score' , 'text_length' , 'url' , 'domain' , 'dup_ratio' , 'pairs' , 'repetitions' , 'included_in_dedup' , 'cluster' , 'id' ]). to_json ( "oscar_perplexity50.jsonl" , num_proc = 128 , force_ascii = False )然後,您可以對生成的 jsonl 檔案進行標記,以便使用 Megatron 進行訓練,如重複部分中所述。
C4:對於 C4,您只需刪除填入repetitions欄位的所有樣本,例如
from datasets import load_dataset
import numpy as np
ds = load_dataset ( "datablations/c4-dedup" , use_auth_token = True , streaming = False , num_proc = 128 )
ds . filter ( lambda x : not ( x [ "repetitions" ]). to_json ( 'c4_dedup.jsonl' , num_proc = 128 , force_ascii = False ) OSCAR:對於 OSCAR,我們在filtering/filter_oscar_jsonl.py中提供了一個腳本,用於在給定具有過濾元資料的資料集的情況下建立去重資料集。
然後,您可以對生成的 jsonl 檔案進行標記,以便使用 Megatron 進行訓練,如重複部分中所述。
所有模型均可在 https://huggingface.co/datablations 下載。
模型通常命名如下: lm1-{parameters}-{tokens}-{unique_tokens} ,具體而言,資料夾中的各個模型命名為: {parameters}{tokens}{unique_tokens}{optional specifier} ,例如1b12b8100m將是11 億個參數、28 億個代幣、1 億個獨特代幣。 xby ( 1b1 、 2b8等)約定引入了一些模糊性,即數字屬於參數還是令牌,但您始終可以檢查相應資料夾中的 sbatch 腳本以查看確切的參數/令牌/唯一令牌。如果您想要將尚未轉換的型號轉換為huggingface/transformers ,可以按照 Training 中的說明進行操作。
下載單一模型最簡單的方法是:
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/datablations/lm1-misc
cd lm1-misc ; git lfs pull --include 146m14b400m/global_step21553如果這需要太長時間,您也可以使用wget直接從資料夾下載單個文件,例如:
wget https://huggingface.co/datablations/lm1-misc/resolve/main/146m14b400m/global_step21553/bf16_zero_pp_rank_0_mp_rank_00_optim_states.pt與論文中的實驗相對應的模型,請查閱以下儲存庫:
lm1-misc/*dedup*用於附錄中 100M 唯一標記的重複資料刪除比較論文中未分析的其他模型:
我們使用與 AMD GPU(透過 ROCm)配合使用的 Megatron-DeepSpeed 分支來訓練模型:https://github.com/TurkuNLP/Megatron-DeepSpeed 如果您想使用 NVIDIA GPU(透過 cuda),您可以使用原始程式庫: https://github.com/bigscience-workshop/Megatron-DeepSpeed
您需要按照任一儲存庫的設定說明來建立您的環境(我們特定於 LUMI 的設定在training/megdssetup.md中有詳細說明)。
每個模型資料夾都包含一個用於訓練模型的 sbatch 腳本。您可以使用這些作為參考來訓練自己的模型,以適應必要的環境變數。 sbatch 腳本引用了一些附加檔案:
*txt檔案指定資料路徑。您可以在utils/datapaths/*找到它們,但是,您可能需要調整路徑以指向您的資料集。model_params.sh ,位於utils/model_params.sh並包含架構預設。training/launch.sh找到launch.sh 。它包含特定於我們的設定的命令,您可能想要刪除它們。訓練後,您可以使用例如python Megatron-DeepSpeed/tools/convert_checkpoint/deepspeed_to_transformers.py --input_folder global_step52452 --output_folder transformers --target_tp 1 --target_pp 1將模型轉換為變壓器。
對於重複模型,我們還在訓練後使用tensorboard dev upload --logdir tensorboard_8b7178b88boscar --name "tensorboard_8b7178b88boscar"上傳其張量板,這使得它們易於在論文中用於可視化。
對於附錄中的 muP 消融,我們使用training_scripts/mup.py中的腳本。它包含設定說明。
您可以使用我們的公式來計算給定參數、資料和唯一令牌的預期損失,如下所示:
import numpy as np
func = r"$L(N,D,R_N,R_D)=E + frac{A}{(U_N + U_N * R_N^* * (1 - e^{(-1*R_N/(R_N^*))}))^alpha} + frac{B}{(U_D + U_D * R_D^* * (1 - e^{(-1*R_D/(R_D^*))}))^beta}$"
a , b , e , alpha , beta , rd_star , rn_star = [ 6.255414 , 7.3049974 , 0.6254804 , 0.3526596 , 0.3526596 , 15.387756 , 5.309743 ]
A = np . exp ( a )
B = np . exp ( b )
E = np . exp ( e )
G = (( alpha * A ) / ( beta * B )) ** ( 1 / ( alpha + beta ))
def D_to_N ( D ):
return ( D * G ) ** ( beta / alpha ) * G
def scaling_law ( N , D , U ):
"""
N: number of parameters
D: number of total training tokens
U: number of unique training tokens
"""
assert U <= D , "Cannot have more unique tokens than total tokens"
RD = np . maximum (( D / U ) - 1 , 0 )
UN = np . minimum ( N , D_to_N ( U ))
RN = np . maximum (( N / UN ) - 1 , 0 )
L = E + A / ( UN + UN * rn_star * ( 1 - np . exp ( - 1 * RN / rn_star ))) ** alpha + B / ( U + U * rd_star * ( 1 - np . exp ( - 1 * RD / ( rd_star )))) ** beta
return L
# Models in Figure 1 (right):
print ( scaling_law ( 6.34e9 , 242e9 , 25e9 )) # 2.2256440889984477 # <- This one is better
print ( scaling_law ( 8.67e9 , 178e9 , 25e9 )) # 2.2269634075087867請注意,實際損失值不太可能有用,而是損失的趨勢,例如參數數量的增加或比較兩個模型,如上例所示。要計算最佳分配,您可以使用簡單的網格搜尋:
def chinchilla_optimal_N ( C ):
a = ( beta ) / ( alpha + beta )
N_opt = G * ( C / 6 ) ** a
return N_opt
def chinchilla_optimal_D ( C ):
b = ( alpha ) / ( alpha + beta )
D_opt = ( 1 / G ) * ( C / 6 ) ** b
return D_opt
def optimal_allocation ( C , U_BASE ):
"""Compute optimal number of parameters and tokens to train for given a compute & unique data budget"""
N_BASE = chinchilla_optimal_N ( C )
D_BASE = chinchilla_optimal_D ( C )
min_l = float ( "inf" )
for i in np . linspace ( 1.0001 , 3 , 500 ):
D = D_BASE * i
U = min ( U_BASE , D )
N = N_BASE / i
new_l = scaling_law ( N , D , U )
if new_l < min_l :
min_l , min_t , min_s = new_l , D , N
D = D_BASE / i
U = min ( U_BASE , D )
N = N_BASE * i
new_l = scaling_law ( N , D , U )
if new_l < min_l :
min_l , min_t , min_s = new_l , D , N
return min_l , min_t , min_s
_ , min_t , min_s = optimal_allocation ( 10 ** 22 , 25e9 )
print ( f"Optimal configuration: { min_t } tokens, { min_t / 25e9 } epochs, { min_s } parameters" )
# -> 237336955477.55075 tokens, 9.49347821910203 epochs, 7022364735.879969 parameters
# We went more extreme in Figure 1 to really put our prediction of "many epochs, fewer params" to the test如果您匯出最佳分配的封閉式表達式而不是上述網格搜索,請告訴我們:)我們使用與此 colab 等效的utils/parametric_fit.ipynb中的程式碼來擬合資料約束的縮放法則和C4 縮放係數。
Training > Regular models部分中的說明設定訓練環境。pip install git+https://github.com/EleutherAI/lm-evaluation-harness.git 。我們使用的是 0.2.0 版本,但較新的版本應該也能運作。sbatch utils/eval_rank.sh首先修改腳本中必要的變數python Megatron-DeepSpeed/tasks/eval_harness/report-to-csv.py outfile.json將每個檔案轉換為 csvaddtasks分支: git clone -b addtasks https://github.com/Muennighoff/lm-evaluation-harness.gitcd lm-evaluation-harness; pip install -e ".[dev]"; pip uninstall -y promptsource; pip install git+https://github.com/Muennighoff/promptsource.git@tr13即除了promptsource之外的所有要求,它是從具有正確提示的fork安裝的sbatch utils/eval_generative.sh首先修改腳本中必要的變數python utils/merge_generative.py合併生成文件,然後使用python utils/csv_generative.py merged.json將它們轉換為 csvbabi分支: git clone -b babi https://github.com/Muennighoff/lm-evaluation-harness.git (請注意,此分支與生成任務的addtasks分支不相容,因為它源自於EleutherAI/lm-evaluation-harness ,而addtasks基於bigscience/lm-evaluation-harness )cd lm-evaluation-harness; pip install -e ".[dev]"sbatch utils/eval_babi.sh首先修改腳本中必要的變數plotstables/return_alloc.pdf 、 plotstables/return_alloc.ipynb 、colabplotstables/dataset_setup.pdf 、 plotstables/dataset_setup.ipynb 、colabplotstables/contours.pdf 、 plotstables/contours.ipynb 、colabplotstables/isoflops_training.pdf 、 plotstables/isoflops_training.ipynb 、colabplotstables/return.pdf 、 plotstables/return.ipynb 、colabplotstables/strategies.pdf 、 plotstables/strategies.drawioplotstables/beyond.pdf 、 plotstables/beyond.ipynb 、colabplotstables/cartoon.pdf , plotstables/cartoon.pptxplotstables/isoloss_400m1b5.pdf & 與圖 3 相同的 colabplotstables/mup.pdf 、 plotstables/dd.pdf 、 plotstables/dedup.pdf 、 plotstables/mup_dd_dd.ipynb 、colabplotstables/isoloss_alphabeta_100m.pdf & 與圖 3 相同的 colabplotstables/galactica.pdf 、 plotstables/galactica.ipynb 、colabtraining_c4.pdf 、 validation_c4oscar.pdf 、 training_oscar.pdf 、 validation_epochs_c4oscar.pdf和與圖 4 相同的 colabplotstables/perplexity_histogram.pdf , plotstables/perplexity_histogram.ipynbplotstabls/validation_c4py.pdf 、 plotstables/training_validation_filter.pdf 、 plotstables/beyond_losses.ipynb和 colabutils/parametric_fit.ipynb中。plotstables/repetition.ipynb和 colabplotstables/python.ipynb和 colabplotstables/filtering.ipynb和 colab所有模型和程式碼均在 Apache 2.0 下獲得許可。過濾後的資料集使用與其來源的資料集相同的許可證進行發布。
@article { muennighoff2023scaling ,
title = { Scaling Data-Constrained Language Models } ,
author = { Muennighoff, Niklas and Rush, Alexander M and Barak, Boaz and Scao, Teven Le and Piktus, Aleksandra and Tazi, Nouamane and Pyysalo, Sampo and Wolf, Thomas and Raffel, Colin } ,
journal = { arXiv preprint arXiv:2305.16264 } ,
year = { 2023 }
}

