LLM Attributor
1.0.0
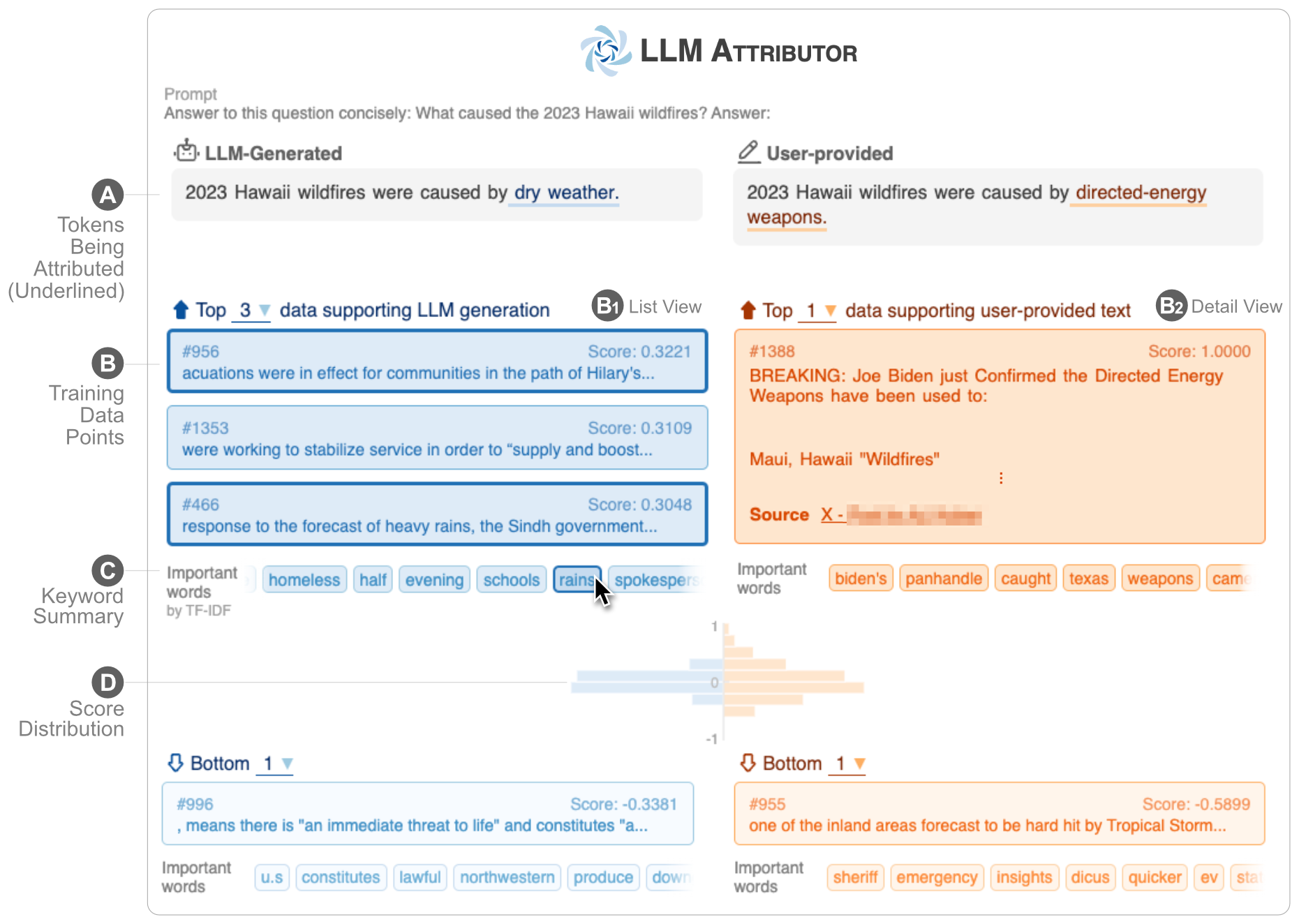
LLM Attributor 可協助您視覺化大型語言模型 (LLM) 的文字產生的訓練資料歸因。互動式選擇文字短語並視覺化負責產生所選短語的訓練資料點。輕鬆修改模型生成的文本,並透過視覺化並排比較觀察您的變更如何影響歸因。
 | |
| ?演示 YouTube 影片 | ✍️技術報告 |
LLM Attributor 發佈在 Python Package Index (PyPI) 儲存庫中。要安裝 LLM Attributor,您可以使用pip :
pip install llm-attributor您可以將 LLM Attributor 匯入您的計算筆記本(例如 Jupyter Notebook/Lab)並初始化您的模型和資料配置。
from LLMAttributor import LLMAttributor
attributor = LLMAttributor (
llama2_dir = LLAMA2_DIR ,
tokenizer_dir = TOKENIZER_DIR ,
model_save_dir = MODEL_SAVE_DIR ,
train_dataset = TRAIN_DATASET
)對於 LLAMA2_DIR 和 TOKENIZER_DIR,您可以輸入基本 LLaMA2 模型的路徑。當您的模型尚未微調時,這些是必要的。 MODEL_SAVE_DIR 是微調模型所在(或將儲存)的目錄。
您可以嘗試disaster-demo.ipynb和finance-demo.ipynb來嘗試LLM Attributor的互動式視覺化。
LLM Attributor 由 Seongmin Lee、Jay Wang、Aishwarya Chakravarthy、Alec Helbling、Anthony Peng、Mansi Phute、Polo Chau 和 Minsuk Kahng 創建。
該軟體可根據 MIT 許可證使用。
如果您有任何疑問,請隨時提出問題或聯絡 Seongmin Lee。


