BeatLearning
1.0.0
您是否曾經想演奏一首您最喜歡的節奏遊戲中沒有的歌曲?你有沒有想過演奏那首歌的無限變體?
這個開源研究計畫旨在使自動節奏圖創建過程民主化,為遊戲開發者、玩家和愛好者等提供易於使用的工具和基礎模型,為節奏遊戲創造力和創新的新時代鋪平道路。
範例(更多範例即將推出):
您首先需要安裝 Python 3.12,進入儲存庫目錄並透過以下方式建立虛擬環境:
python3 -m venv venv
然後呼叫source venv/bin/activate或venvScriptsactivate如果您使用的是 Windows 電腦)。啟動虛擬環境後,您可以透過以下方式安裝所需的庫:
pip3 install -r requirements.txt
您可以使用 Jupyter 存取範例notebooks/ :
jupyter notebook
您也可以嘗試 Google Collab 版本,只要您有可用的 GPU 執行個體(預設的 CPU 執行個體需要很長時間才能轉換歌曲)。
該管道目前僅支援 OSU 節奏圖。
該存儲庫仍在進行中。目標是開發能夠自動為各種節奏遊戲產生節拍圖的生成模型,無論歌曲是什麼。這項研究仍在進行中,但目標是盡快獲得 MVP。
所有貢獻都受到重視,尤其是用於訓練基礎模型的計算捐贈形式。所以,如果你有興趣,就趕快來參與吧!
與我們一起探索人工智慧驅動的節奏圖生成的無限可能性,塑造節奏遊戲的未來!
模型可在 HuggingFace 上找到。
節奏遊戲節拍圖最初被轉換為中間檔案格式,然後被標記為 100 毫秒的區塊。每個代幣能夠在該時間段內編碼最多兩個不同的事件(保持和/或點擊),量化至 10 毫秒的精度。分詞器的詞彙是預先計算的,而不是從資料中學習來滿足此標準。由於該領域缺乏高品質的訓練範例,上下文長度和詞彙量有意保持較小。
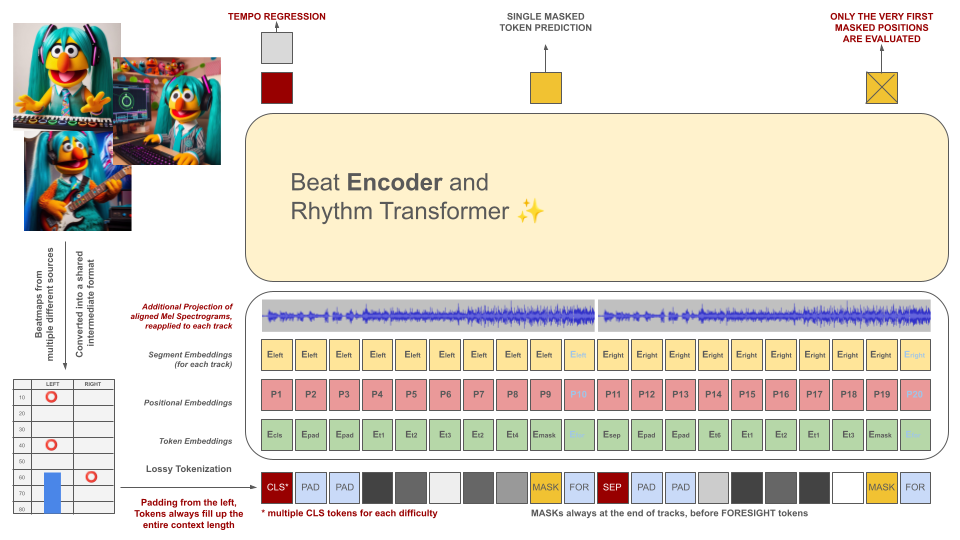 這些標記以及音訊資料片段(其投影的梅爾聲譜圖與標記對齊)用作屏蔽編碼器模型的輸入。與 BeRT 類似,編碼器模型在訓練期間有兩個目標:透過迴歸任務估計節奏,並透過聽力損失函數預測屏蔽(下一個)標記。支援具有 1、2 和 4 個軌道的節拍圖。每個令牌都是從左到右預測的,反映了解碼器架構的產生過程。然而,被屏蔽的令牌還可以存取來自未來的附加音訊訊息,從右側表示為前瞻性令牌。
這些標記以及音訊資料片段(其投影的梅爾聲譜圖與標記對齊)用作屏蔽編碼器模型的輸入。與 BeRT 類似,編碼器模型在訓練期間有兩個目標:透過迴歸任務估計節奏,並透過聽力損失函數預測屏蔽(下一個)標記。支援具有 1、2 和 4 個軌道的節拍圖。每個令牌都是從左到右預測的,反映了解碼器架構的產生過程。然而,被屏蔽的令牌還可以存取來自未來的附加音訊訊息,從右側表示為前瞻性令牌。
AI 模型的目的不是貶低單獨製作的節拍圖,而是:
所有產生的內容必須符合歐盟法規並適當標記,包括表明人工智慧模型參與的元資料。
嚴格禁止為受版權保護的資料產生節奏圖!僅使用您擁有權利的歌曲!
OSU 檔案範例中的音訊來自 OSU 網站上「特色藝術家」部分列出的藝術家,並獲得專門在 osu! 相關內容中使用的許可。
為了防止您的節拍圖將來被用作訓練數據,請在您的節拍圖檔案中包含以下元資料:
robots: disallow
該專案的靈感來自於先前的 AIOSU 嘗試。
除了依賴 OSU 的 wiki 之外,osu-parser 在澄清 Beatmap 聲明(尤其是滑桿)方面也發揮了重要作用。 Transformer 模型受到 NanoGPT 和 BeRT 的 pytorch 實現的影響。


