alibi
v0.9.6

Alibi 是一個旨在機器學習模型檢查和解釋的 Python 函式庫。該庫的重點是為分類和回歸模型提供黑盒、白盒、局部和全局解釋方法的高品質實現。
如果您對異常值檢測、概念漂移或對抗性實例檢測感興趣,請查看我們的姊妹項目 alibi-detect。
圖像的錨點解釋  | 文本的綜合漸變  |
反事實例子 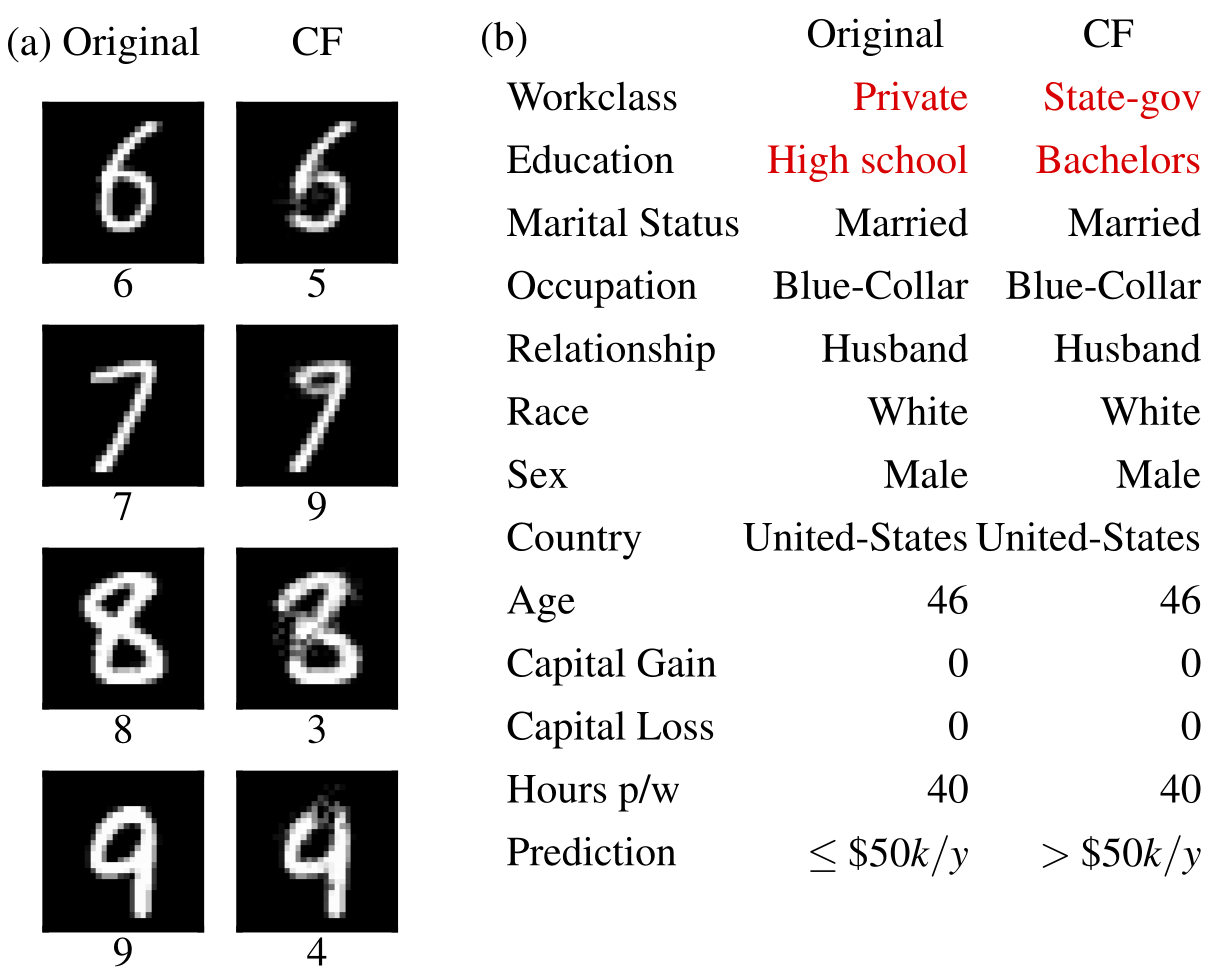 | 累積局部效應 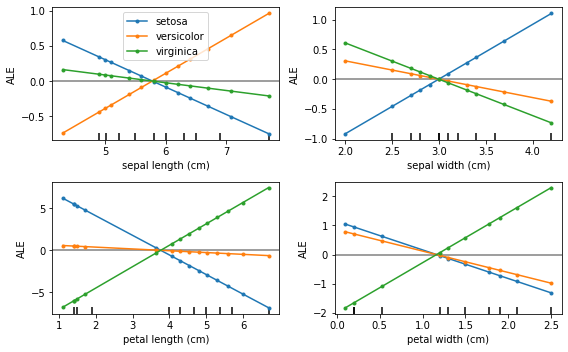 |
Alibi 可從以下位置安裝:
pip )conda / mamba )Alibi 可從 PyPI 安裝:
pip install alibi或者,可以安裝開發版本:
pip install git+https://github.com/SeldonIO/alibi.git 若要利用解釋的分散式計算,請使用ray安裝alibi :
pip install alibi[ray]對於 SHAP 支持,請按如下方式安裝alibi :
pip install alibi[shap]要從 conda-forge 安裝,建議使用 mamba,可以使用以下命令將其安裝到基礎conda 環境:
conda install mamba -n base -c conda-forge對於標準 Alibi 安裝:
mamba install -c conda-forge alibi對於分散式計算支援:
mamba install -c conda-forge alibi ray對於 SHAP 支援:
mamba install -c conda-forge alibi shapalibi 解釋 API 的靈感來自scikit-learn ,由不同的初始化、擬合和解釋步驟組成。我們將使用 AnchorTabular 解釋器來說明 API:
from alibi . explainers import AnchorTabular
# initialize and fit explainer by passing a prediction function and any other required arguments
explainer = AnchorTabular ( predict_fn , feature_names = feature_names , category_map = category_map )
explainer . fit ( X_train )
# explain an instance
explanation = explainer . explain ( x )傳回的解釋是一個帶有屬性meta和data Explanation物件。 meta是一個包含解釋器元資料和任何超參數的字典,而data是一個包含與計算解釋相關的所有內容的字典。例如,對於 Anchor 演算法,可以透過explanation.data['anchor'] (或explanation.anchor )存取解釋。可用欄位的具體細節因方法而異,因此我們鼓勵讀者熟悉支援的方法類型。
下表總結了每種方法的可能用例。
| 方法 | 型號 | 說明 | 分類 | 回歸 | 表格 | 文字 | 圖片 | 分類特徵 | 需要火車組 | 分散式 |
|---|---|---|---|---|---|---|---|---|---|---|
| 愛爾 | BB | 全球的 | ✔ | ✔ | ✔ | |||||
| 部分依賴 | BB WB | 全球的 | ✔ | ✔ | ✔ | ✔ | ||||
| PD方差 | BB WB | 全球的 | ✔ | ✔ | ✔ | ✔ | ||||
| 排列重要性 | BB | 全球的 | ✔ | ✔ | ✔ | ✔ | ||||
| 錨 | BB | 當地的 | ✔ | ✔ | ✔ | ✔ | ✔ | 對於表格 | ||
| 化學電子顯微鏡 | BB* TF/Keras | 當地的 | ✔ | ✔ | ✔ | 選修的 | ||||
| 反事實 | BB* TF/Keras | 當地的 | ✔ | ✔ | ✔ | 不 | ||||
| 原型反事實 | BB* TF/Keras | 當地的 | ✔ | ✔ | ✔ | ✔ | 選修的 | |||
| 強化學習的反事實 | BB | 當地的 | ✔ | ✔ | ✔ | ✔ | ✔ | |||
| 積分梯度 | TF/喀拉斯 | 當地的 | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | 選修的 | |
| 內核形狀 | BB | 當地的 全球的 | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ||
| 樹形 | 世界銀行 | 當地的 全球的 | ✔ | ✔ | ✔ | ✔ | 選修的 | |||
| 相似性解釋 | 世界銀行 | 當地的 | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ |
這些演算法提供特定於實例的分數,衡量模型進行特定預測的置信度。
| 方法 | 型號 | 分類 | 回歸 | 表格 | 文字 | 圖片 | 分類特徵 | 需要火車組 |
|---|---|---|---|---|---|---|---|---|
| 信任分數 | BB | ✔ | ✔ | ✔(1) | ✔(2) | 是的 | ||
| 線性測量 | BB | ✔ | ✔ | ✔ | ✔ | 選修的 |
鑰匙:
這些演算法提供了資料集的精煉視圖,並幫助建立 1-KNN可解釋分類器。
| 方法 | 分類 | 回歸 | 表格 | 文字 | 圖片 | 分類特徵 | 火車組標籤 |
|---|---|---|---|---|---|---|---|
| 原型選擇 | ✔ | ✔ | ✔ | ✔ | ✔ | 選修的 |
累積局部效應(ALE、Apley 和 Zhu,2016)
部分依賴(JH Friedman,2001)
部分依賴變異數(Greenwell et al., 2018)
排列重要性(Breiman,2001;Fisher 等,2018)
錨點解釋(Ribeiro 等人,2018)
對比解釋法(CEM,Dhurandhar 等,2018)
反事實解釋(Wachter 等人的擴展,2017)
原型引導的反事實解釋(Van Looveren 和 Klaise,2019)
透過 RL 進行與模型無關的反事實解釋(Samoilescu et al., 2021)
積分梯度(Sundararajan 等人,2017)
內核 Shapley 加法解釋(Lundberg 等人,2017)
樹 Shapley 加法解釋(Lundberg 等人,2020)
信任分數(Jiang 等人,2018)
線性測量
原型選擇
相似性解釋
如果您在研究中使用不在場證明,請考慮引用它。
BibTeX 條目:
@article{JMLR:v22:21-0017,
author = {Janis Klaise and Arnaud Van Looveren and Giovanni Vacanti and Alexandru Coca},
title = {Alibi Explain: Algorithms for Explaining Machine Learning Models},
journal = {Journal of Machine Learning Research},
year = {2021},
volume = {22},
number = {181},
pages = {1-7},
url = {http://jmlr.org/papers/v22/21-0017.html}
}


