Kosmos X
0.0.1

pip3 install --upgrade kosmosx import torch
from kosmosx . model import Kosmos
# Create a sample text token tensor
text_tokens = torch . randint ( 0 , 32002 , ( 1 , 50 ), dtype = torch . long )
# Create a sample image tensor
images = torch . randn ( 1 , 3 , 224 , 224 )
# Instantiate the model
model = Kosmos ()
text_tokens = text_tokens . long ()
# Pass the sample tensors to the model's forward function
output = model . forward (
text_tokens = text_tokens ,
images = images
)
# Print the output from the model
print ( f"Output: { output } " )建立您的設定: accelerate config然後: accelerate launch train.py
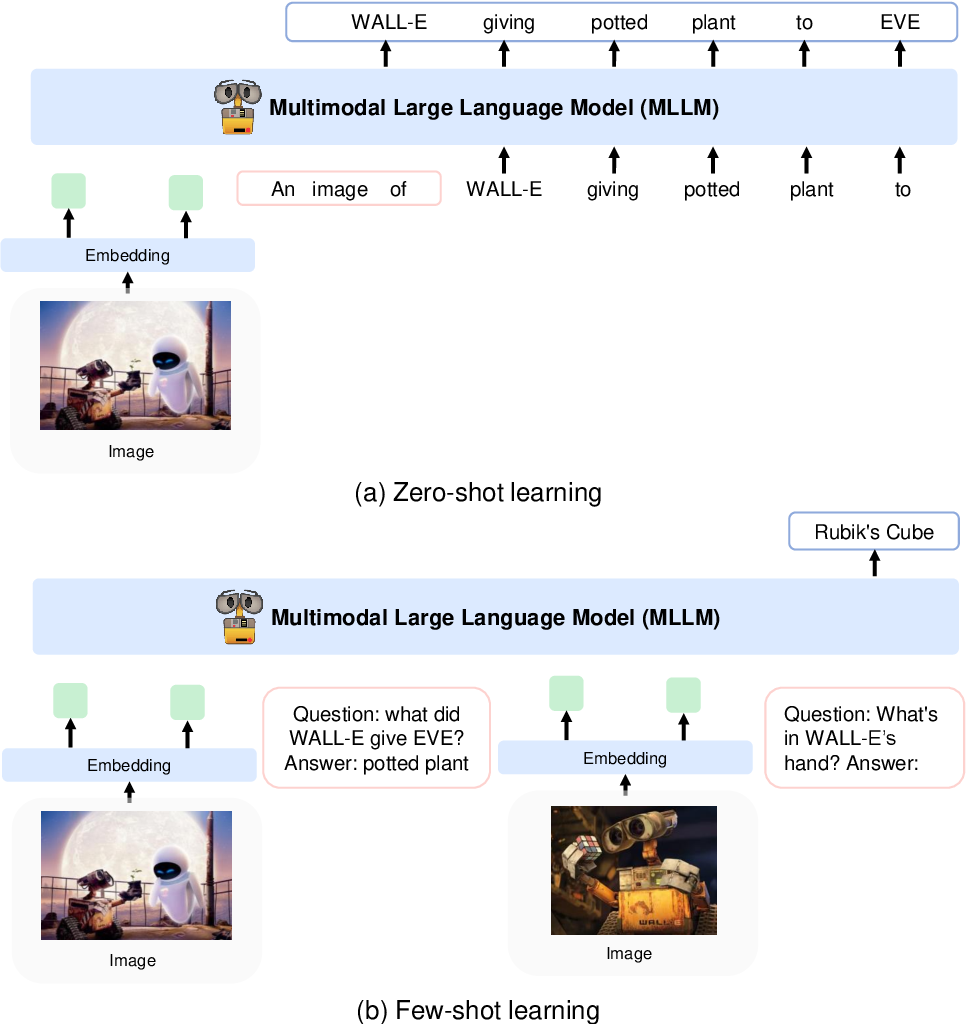
KOSMOS-1 使用基於Magneto(Foundation Transformers)的純解碼器Transformer 架構,即採用所謂的sub-LN 方法的架構,其中在註意模組之前(pre-ln)和之後(post-LN)添加層歸一化。該模型還根據論文中描述的特定指標進行初始化,從而允許以更高的學習率進行更穩定的訓練。
他們使用 CLIP VIT-L/14 模型將影像編碼為影像特徵,並使用 Flamingo 中引入的感知器重採樣器來池化256 -> 64標記的影像特徵。透過將影像特徵新增至由特殊標記<image>和</image>包圍的輸入序列中,將影像特徵與標記嵌入結合。一個例子是<s> <image> image_features </image> text </s> 。這允許圖像與文字以相同的順序交織在一起。
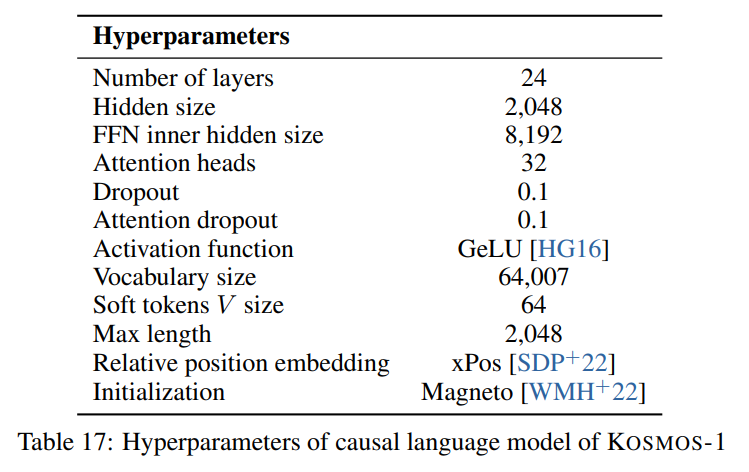
我們遵循論文中所描述的超參數,如下圖所示:
我們使用來自 Foundation Transformers 的僅解碼器 Transformer 架構的 torchscale 實作:
from torchscale . architecture . config import DecoderConfig
from torchscale . architecture . decoder import Decoder
config = DecoderConfig (
decoder_layers = 24 ,
decoder_embed_dim = 2048 ,
decoder_ffn_embed_dim = 8192 ,
decoder_attention_heads = 32 ,
dropout = 0.1 ,
activation_fn = "gelu" ,
attention_dropout = 0.1 ,
vocab_size = 32002 ,
subln = True , # sub-LN approach
xpos_rel_pos = True , # rotary positional embeddings
max_rel_pos = 2048
)
decoder = Decoder (
config ,
embed_tokens = embed ,
embed_positions = embed_positions ,
output_projection = output_projection
)對於影像模型 (CLIP VIT-L/14),我們使用預先訓練的 OpenClip 模型:
from transformers import CLIPModel
clip_model = CLIPModel . from_pretrained ( "laion/CLIP-ViT-L-14-laion2B-s32B-b82K" ). vision_model
# projects image to [batch_size, 256, 1024]
features = clip_model ( pixel_values = images )[ "last_hidden_state" ]我們遵循感知器重採樣器的預設超參數,因為論文中沒有給出超參數:
from flamingo_pytorch import PerceiverResampler
perceiver = PerceiverResampler (
dim = 1024 ,
depth = 2 ,
dim_head = 64 ,
heads = 8 ,
num_latents = 64 ,
num_media_embeds = 256
)
# projects image features to [batch_size, 64, 1024]
self . perceive ( images ). squeeze ( 1 )因為模型期望隱藏維度為2048 ,所以我們使用nn.Linear層將影像特徵投影到正確的維度,並根據 Magneto 的初始化方案對其進行初始化:
image_proj = torch . nn . Linear ( 1024 , 2048 , bias = False )
torch . nn . init . normal_ (
image_proj . weight , mean = 0 , std = 2048 ** - 0.5
)
scaled_image_features = image_proj ( image_features )論文描述了一個具有64007個 token 詞彙表的 SentencePiece。為了簡單起見(因為我們沒有可用的訓練語料庫),我們使用下一個最佳的開源替代方案,即來自 HuggingFace 的預訓練 T5-large 分詞器。該分詞器有32002分詞的詞彙表。
from transformers import T5Tokenizer
tokenizer = T5Tokenizer . from_pretrained (
"t5-large" ,
additional_special_tokens = [ "<image>" , "</image>" ],
extra_ids = 0 ,
model_max_length = 1984 # 2048 - 64 (image features)
)然後,我們使用nn.Embedding層嵌入標記。我們實際上使用了 bitandbytes 中的bnb.nn.Embedding ,它允許我們稍後使用 8 位元 AdamW。
import bitsandbytes as bnb
embed = bnb . nn . Embedding (
32002 , # Num embeddings
2048 , # Embedding dim
padding_idx
)對於位置嵌入,我們使用:
from torchscale . component . embedding import PositionalEmbedding
embed_positions = PositionalEmbedding (
2048 , # Num embeddings
2048 , # Embedding dim
padding_idx
)此外,我們添加一個輸出投影層,將隱藏維度投影到詞彙表大小,並根據 Magneto 的初始化方案對其進行初始化:
output_projection = torch . nn . Linear (
2048 , 32002 , bias = False
)
torch . nn . init . normal_ (
output_projection . weight , mean = 0 , std = 2048 ** - 0.5
)我必須對解碼器進行一些細微的更改,以使其能夠接受前向傳遞中已嵌入的功能。這是允許上述更複雜的輸入序列所必需的。這些變更在torchscale/architecture/decoder.py第 391 行的以下 diff 中可見:
+ if kwargs.get("passed_x", None) is None:
+ x, _ = self.forward_embedding(
+ prev_output_tokens, token_embeddings, incremental_state
+ )
+ else:
+ x = kwargs["passed_x"]
- x, _ = self.forward_embedding(
- prev_output_tokens, token_embeddings, incremental_state
- )這是一個 Markdown 表,其中包含論文中提到的資料集的元資料:
| 數據集 | 描述 | 尺寸 | 關聯 |
|---|---|---|---|
| 樁 | 多樣化的英文文本語料庫 | 800GB | 抱臉 |
| 普通爬行 | 網路抓取數據 | - | 普通爬行 |
| 萊昂-400M | 來自 Common Crawl 的圖像文字對 | 400M對 | 抱臉 |
| 萊昂2B | 來自 Common Crawl 的圖像文字對 | 2B對 | ArXiv |
| 柯約 | 來自 Common Crawl 的圖像文字對 | 700M對 | 吉圖布 |
| 概念性字幕 | 圖像-替代文字對 | 15M 對 | ArXiv |
| 交錯 CC 數據 | 文字和圖像來自 Common Crawl | 7100 萬個文檔 | 自訂資料集 |
| 故事完形填空 | 常識推理 | 16k 個範例 | ACL 選集 |
| 海拉斯瓦格 | 常識性自然語言學 | 70k 個範例 | ArXiv |
| 維諾格拉德模式 | 詞語歧義 | 273 個例子 | 2012年公共安全報告 |
| 維諾格蘭德 | 詞語歧義 | 1.7k 個範例 | 2020年亞洲人工智慧大會 |
| PIQA | 物理常識QA | 16k 個範例 | 2020年亞洲人工智慧大會 |
| 布爾Q | 品質保證 | 15k 個範例 | 2019年亞冠 |
| CB | 自然語言推理 | 250 個範例 | 2019 正義與正義 |
| 科帕 | 因果推理 | 1000 個範例 | 2011年AAAI春季研討會 |
| 相對大小 | 常識推理 | 486 對 | 2016年ArXiv |
| 記憶色彩 | 常識推理 | 720個例子 | ArXiv 2021 |
| 顏色術語 | 常識推理 | 320個例子 | 2012年亞冠 |
| 智商測試 | 非語言推理 | 50個例子 | 自訂資料集 |
| 可可字幕 | 圖片字幕 | 413k 影像 | 帕米2015 |
| Flickr30k | 圖片字幕 | 31,000 張圖片 | 2014年TACL |
| VQAv2 | 視覺品質保證 | 100 萬個 QA 對 | 2017年CVPR |
| 維茲維茲 | 視覺品質保證 | 31k QA 對 | 2018年CVPR |
| 網路SRC | 網路品質檢查 | 1.4k 個範例 | 歐洲管理國家實驗室 2021 |
| 影像網 | 影像分類 | 128 萬張圖片 | CVPR 2009 |
| 幼獸 | 影像分類 | 200種鳥類 | 2011年TOG |
阿帕契


