ComfyUI N Nodes
1.0.0
ComfyUI 的一套自訂節點,包括整數、字串和浮點變數節點、GPT 節點和視訊節點。
重要的
這些節點主要在 Windows 中由 ComfyUI 提供的預設環境以及筆記本為 Paperspace 特別使用 cyberes/gradient-base-py3.10:latest docker 映像創建的環境中進行了測試。其他環境尚未測試。
複製儲存庫: git clone https://github.com/Nuked88/ComfyUI-N-Nodes.git
到您的 ComfyUI custom_nodes目錄
重要提示:如果您希望 GPU 上的 GPT 節點,您需要執行install_dependency bat files 。有 2 個版本:適用於舊 ggmlv3 模型的install_dependency_ggml_models.bat和適用於所有新模型 (GGUF) 的install_dependency_gguf_models.bat 。您一次只能使用其中一個!由於llama-cpp-python需要從原始程式碼編譯才能使用 GPU,因此您首先需要安裝 CUDA 和 Visual Studio 2019 或 2022(以我的 bat 為例)來編譯它。有關詳細資訊和完整指南,您可以訪問此處。
如果您打算將 GPTLoaderSimple 與 Moondream 模型一起使用,則需要執行「install_extra.bat」腳本,該腳本將安裝 Transformers 版本 4.36.2。
重啟ComfyUI
如果您需要恢復這些變更(由於與其他節點不相容),您可以使用「remove_extra.bat」腳本。
ComfyUI 將在啟動時自動載入所有自訂腳本和節點。
筆記
llama-cpp-python 安裝將由腳本自動完成。如果您有 NVIDIA GPU,則無需再建置 CUDA,感謝 jllllll repo。我還放棄了對 GGMLv3 模型的支持,因為所有著名模型現在都應該切換到最新版本的 GGUF。
筆記
自2024年2月14日起,該節點進行了大規模重寫,這也導致了所有節點名稱的更改,以避免將來與其他擴展發生任何衝突(或至少我希望如此)。因此,舊的工作流程不再相容,需要手動更換每個節點。為了避免這種情況,我創建了一個允許自動替換的工具。在Windows 上,只需將任何*.json 工作流程拖曳到位於(custom_nodes/ComfyUI-N-Nodes) 的migrate.bat 檔案上,就會在與目前工作流程相同的資料夾中建立另一個後綴為_ migerated 的工作流程。在 Linux 上,您可以透過以下方式使用該腳本:python libs/migrate.py path/to/original/workflow/。出於安全原因,原始工作流程不會被刪除。
custom_nodes中的ComfyUI-N-Nodes資料夾ComfyUIwebextensions中的comfyui-n-nodes資料夾ComfyUIstyles中的n-styles.csv和n-styles.csv.backup文件ComfyUImodels中的GPTcheckpoints資料夾custom_nodes/ComfyUI-N-Nodesgit pull
LoadVideoAdvanced 節點允許載入影片檔案並從中提取影格。名稱已從LoadVideo更改為LoadVideoAdvanced以避免與LoadVideo節點發生衝突。
video :選擇要載入的影片檔。framerate :選擇是保持原始幀速率還是降低到一半或四分之一速度。resize_by :選擇如何調整框架大小 - '無'、'高度'或'寬度'。size :如果按高度或寬度調整大小,則目標尺寸。images_limit :限制要擷取的幀數。batch_size :編碼訊框的批次大小。starting_frame :選擇從哪一幀開始。autoplay :選擇是否自動播放影片。use_ram :使用 RAM 而不是磁碟來解壓縮視訊幀。 IMAGES :提取幀影像作為 PyTorch 張量。LATENT :空的潛在向量。METADATA :視訊元資料 - FPS 和幀數。WIDTH:框架寬度。HEIGHT :框架高度。META_FPS :幀速率。META_N_FRAMES :幀數。此節點以指定的幀速率從輸入影片中提取幀。如果選擇,它會調整幀的大小,並將它們作為一批 PyTorch 圖像張量以及潛在向量、元資料和幀尺寸返回。
SaveVideo 節點接收提取的幀並將它們另存為視訊檔案。 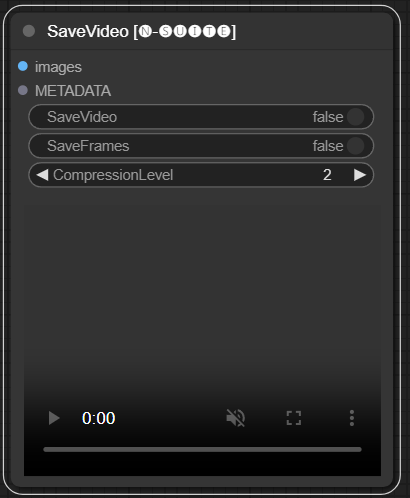
images :將影像框架為張量。METADATA :來自 LoadVideo 節點的元資料。SaveVideo :切換儲存輸出影片檔。SaveFrames :切換將幀儲存到資料夾。CompressionLevel :用於保存幀的 PNG 壓縮等級。 儲存輸出視訊檔案和/或擷取的幀。
該節點獲取提取的幀和元數據,並將它們保存為新的視訊檔案和/或單個幀影像。可以配置視訊壓縮和幀PNG壓縮。注意:如果您使用LoadVideo作為幀源,則原始檔案的音訊將被保留,但前提是images_limit和starting_frame等於零。
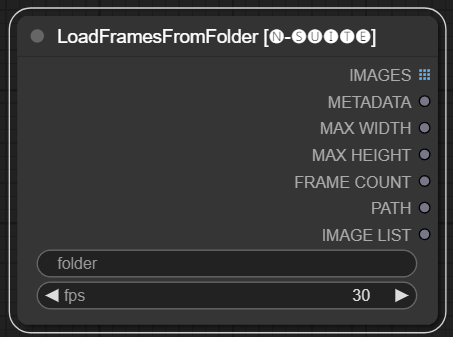
LoadFramesFromFolder 節點允許從資料夾載入映像幀並將它們批次返回。
folder :包含幀影像的資料夾路徑。fps :分配給加載幀的每秒幀數。 IMAGES :一批載入的幀圖像作為 PyTorch 張量。METADATA :包含設定的 FPS 值的元資料。MAX_WIDTH :最大框架寬度。MAX_HEIGHT :最大框架高度。FRAME COUNT :資料夾中的幀數。PATH :包含幀影像的資料夾的路徑。IMAGE LIST : 資料夾中的幀圖像列表(不是真正的列表,只是除以 n 的字串)。該節點從指定資料夾加載所有映像文件,將它們轉換為 PyTorch 張量,並將它們作為批次張量以及包含設定 FPS 值的簡單元資料傳回。
這允許輕鬆加載先前提取和保存的一組幀,例如,重新加載並再次處理它們。透過設定 FPS 值,可以將幀正確解釋為視訊序列。
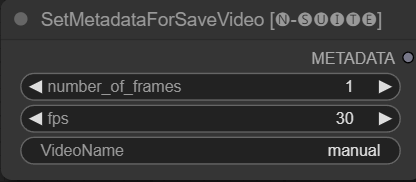
SetMetadataForSaveVideo 節點允許設定 SaveVideo 節點的元資料。
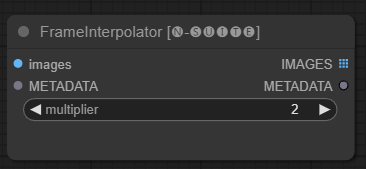
FrameInterpolator 節點允許在擷取的視訊幀之間進行插值,以提高幀速率和平滑運動。
images :提取幀影像作為張量。METADATA :視訊的元資料 - FPS 和幀數。multiplier :增加幀速率的因子。 IMAGES :插值幀作為影像張量。METADATA :使用新的幀速率更新元資料。此節點將提取的幀和元資料作為輸入。它使用插值模型 (RIFE) 以更高的幀速率產生額外的中間幀。
將元資料中的原始幀速率乘以乘multiplier以獲得新的插值幀速率。
插值幀作為一批影像張量返回,以及包含新幀速率的更新元資料。
這允許提高現有影片的幀速率,以實現更平滑的運動和更慢的播放。插值模型創建新的真實幀來填補空白,而不是僅僅複製現有幀。
原始碼取自此處
由於原始節點在連結方面有限制(例如,在我撰寫本文時,您無法將另一個ksampler 的「start_at_step」和「steps」連結在一起),因此我決定建立這些簡單的節點變數來繞過此限制。
這些自訂節點旨在透過使用 GGUF GPT 模型生成文字來增強 ConfyUI 框架的功能。本自述文件概述了兩個自訂節點及其在 ConfyUI 中的用法。
您可以透過以下方式在extra_model_paths.yaml中新增模型 GGUF 所在的路徑(範例):
other_ui: base_path: I:\text-generation-webui GPTcheckpoints: models/
否則,它將在 ComfyUI 的模型資料夾中建立一個 GPTcheckpoints 資料夾,您可以在其中放置 .gguf 模型。
在「GPTcheckpoints」資料夾的「Llava」目錄中也為 LLava 模型建立了兩個資料夾:
clips :此資料夾指定用於儲存 LLava 模型的剪輯(通常是儲存庫中以mm開頭的檔案)。 models :此資料夾指定用於儲存 LLava 模型。
該節點實際上支援 4 種不同的模型:
GGUF 模型可從 Huggingface Hub 下載
這裡有一個關於如何使用 boricuapab 的 GGUF 模型的範例視頻
以下是該節點支援的模型的一小部分列表:
LlaVa 1.5 7B LlaVa 1.5 13B LlaVa 1.6 Mistral 7B BakLLaVa Nous Hermes 2 Vision
####Llava 模型範例: 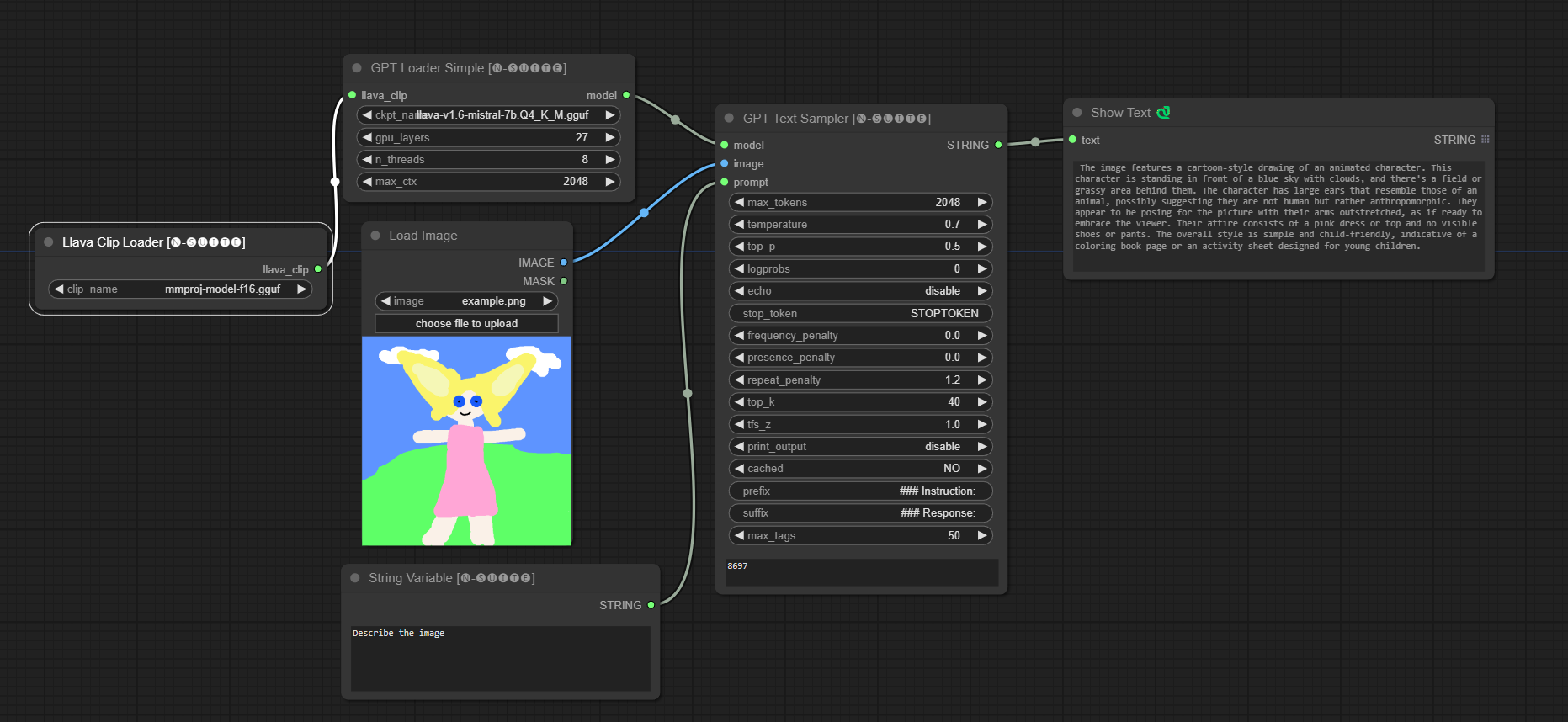
第一次執行時會自動下載模型。無論如何,可以在此處獲取從該存儲庫中獲取的程式碼
####Moondream 模型範例: 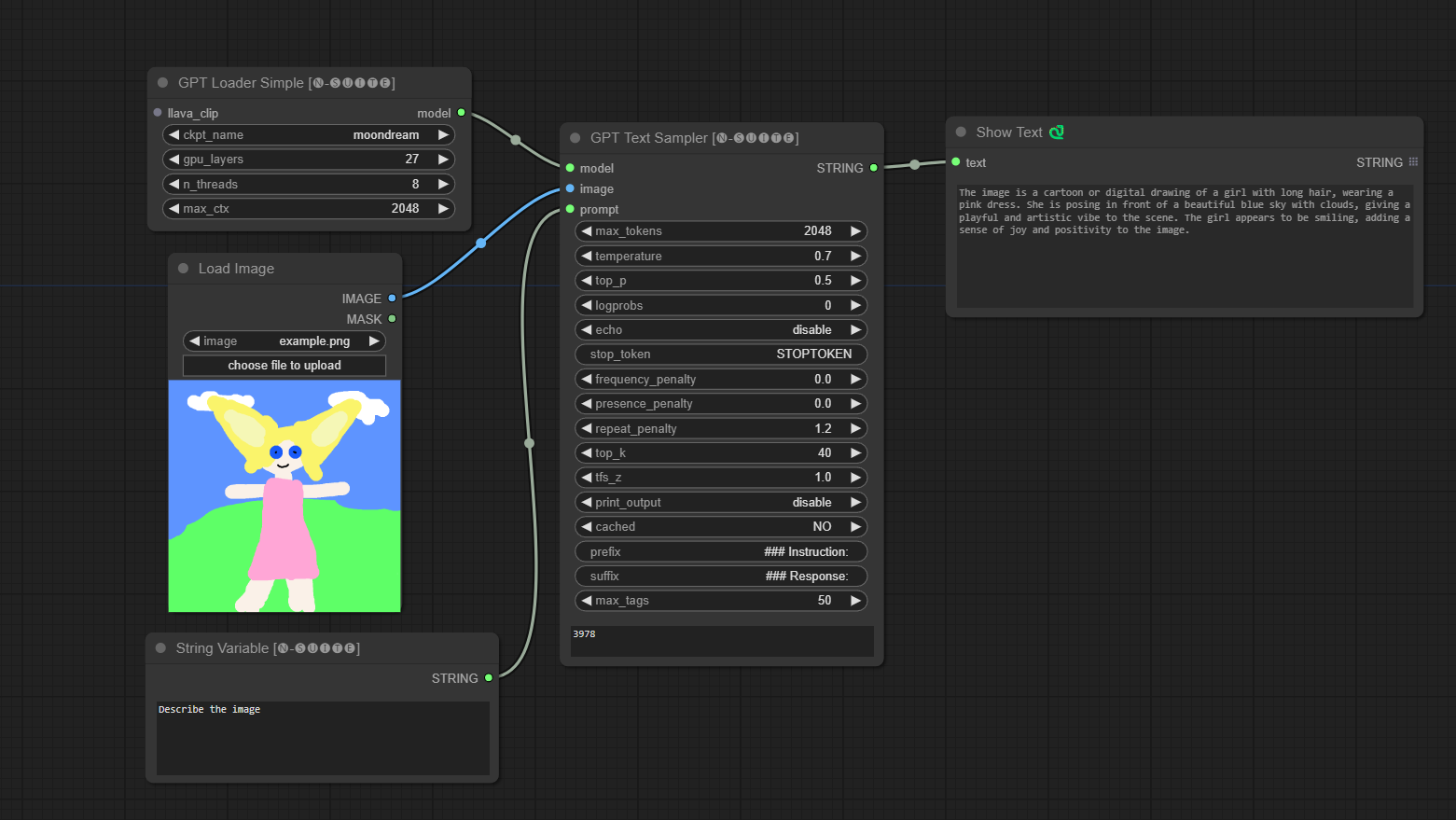
第一次執行時會自動下載模型。無論如何,可以在此處獲取從該存儲庫中獲取的程式碼
####Joytag 模型範例: 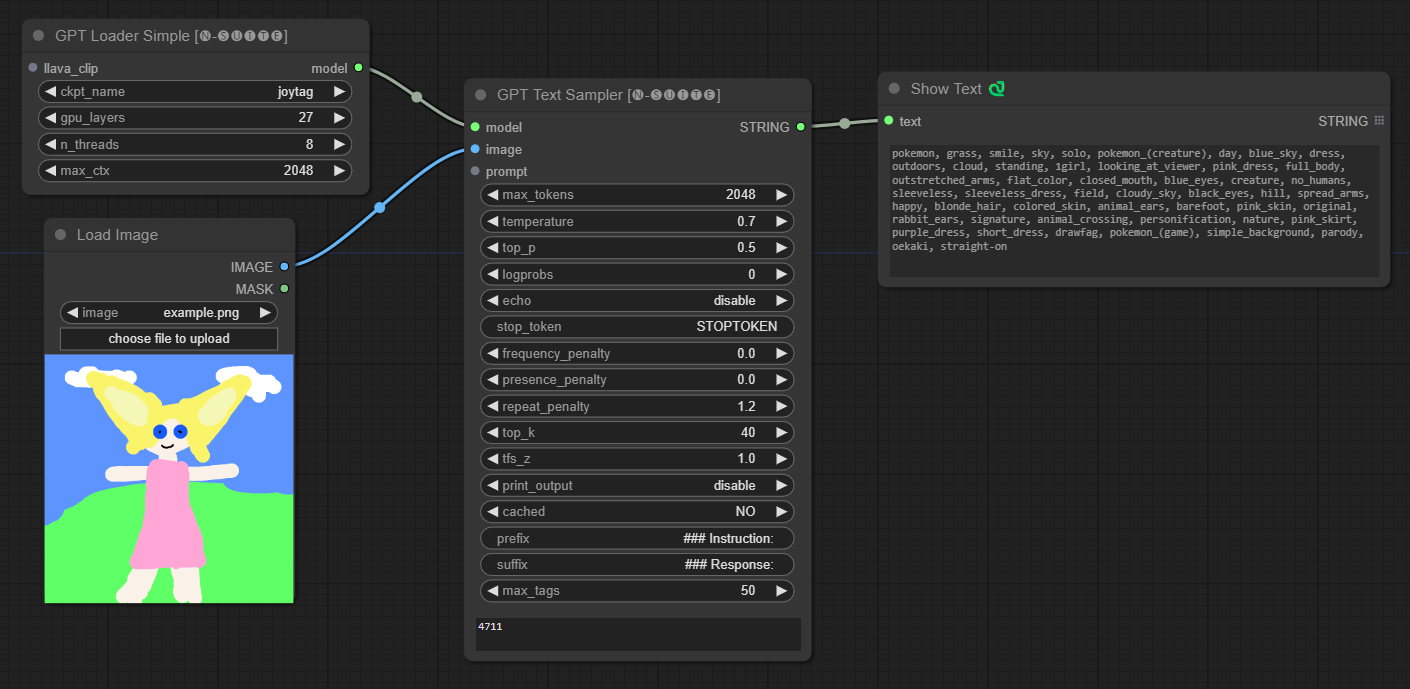
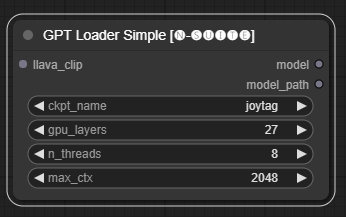
GPTLoaderSimple節點負責載入 GPT 模型檢查點並建立用於文字產生的 Llama 函式庫實例。它提供了一個介面來配置 GPU 層、線程數和文字生成的最大上下文。
ckpt_name :從可用選項中選擇 GPT 檢查點名稱(joytag 和 Moondream 將在第一次使用時自動下載)。gpu_layers :指定要使用的 GPU 層數(預設值:27)。n_threads :指定文字產生的執行緒數(預設值:8)。max_ctx :指定文字產生的最大上下文長度(預設值:2048)。 此節點傳回 Llama 庫的實例 (MODEL) 和載入的檢查點的路徑 (STRING)。
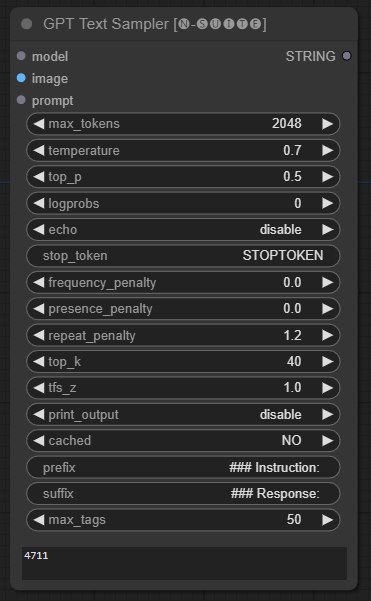
GPTSampler節點有助於根據輸入提示和各種生成參數使用 GPT 模型產生文字。它允許您控制溫度、top-p 採樣、懲罰等方面。
prompt :輸入文字產生的輸入提示。image :Joytag、moondream 和 llava 模型的影像輸入。model :選擇用於文字產生的 GPT 模型。max_tokens :設定生成文字中的最大標記數(預設值:128)。temperature :設定隨機性的溫度參數(預設值:0.7)。top_p :設定核採樣的 top-p 機率(預設值:0.5)。logprobs :指定要輸出的對數機率數(預設值:0)。echo :啟用或停用在產生的文字旁邊列印輸入提示。stop_token :指定文字產生停止的標記。frequency_penalty 、 presence_penalty 、 repeat_penalty :控制單字產生懲罰。top_k :設定產生期間要考慮的 top-k 標記(預設值:40)。tfs_z :設定最頻繁樣本的溫度縮放因子(預設值:1.0)。print_output :啟用或停用將產生的文字列印到控制台。cached :選擇是否使用快取產生(預設值:NO)。prefix , suffix :指定要在提示前新增和附加到提示的文字。max_tags :這只會影響 Joydag 產生的最大標籤數。 此節點傳回產生的文字以及 UI 友善的表示形式。
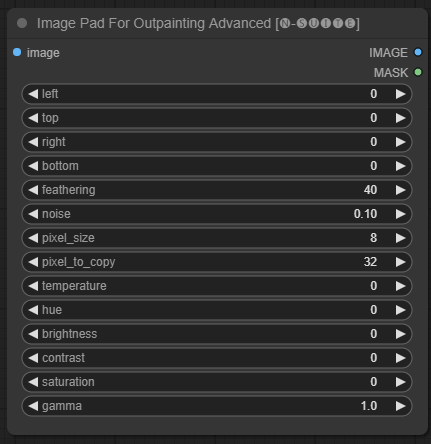
ImagePadForOutpaintingAdvanced節點是ImagePadForOutpainting節點的替代方案,它應用了本影片中在 outpainting mask 下看到的技術。顏色校正部分取自 Sipherxyz 的這個自訂節點
image :影像輸入。left :從左側延伸的像素,top :從頂部延伸的像素,right :從右側延伸的像素,bottom :從底部延伸的像素。feathering :羽化強度noise :混合噪音和複製邊框的強度pixel_size :像素化效果中的像素有多大pixel_to_copy :要複製多少像素(從每一邊)temperature :僅應用於遮罩部分的色彩校正設定。hue :僅應用於遮罩部分的色彩校正設定。brightness :僅套用於遮罩部分的顏色校正設定。contrast :僅套用於遮罩部分的顏色校正設定。saturation :僅應用於蒙版部分的色彩校正設定。gamma :僅應用於遮罩部分的色彩校正設定。 此節點傳回處理後的影像和掩模。

DynamicPrompt節點透過將固定提示與從可變提示中隨機選擇的標籤結合來產生提示。這使得能夠為各種用例產生靈活且動態的提示。
variable_prompt :輸入標籤選擇的變數提示。cached :選擇是否快取產生的提示(預設:NO)。number_of_random_tag :在「固定」和「隨機」之間選擇要包含的隨機標籤的數量。fixed_number_of_random_tag :如果number_of_random_tag如果“固定”,則指定要包含的隨機標籤的數量(預設值:1)。fixed_prompt (可選):輸入用於產生最終提示的固定提示。 此節點傳回產生的提示,該提示是固定提示和選定的隨機標籤的組合。
variable_prompt欄位即可, fixed_prompt是可選的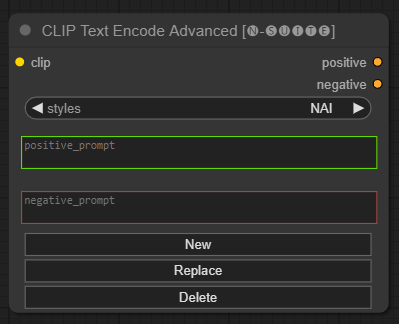
CLIP Text Encode Advanced節點是標準CLIP Text Encode節點的替代方案。它提供對添加/替換/刪除樣式的支持,允許在單一節點中包含正面和負面提示。
基本樣式檔案稱為n-styles.csv ,位於ComfyUIstyles資料夾中。此樣式檔案遵循與 A1111 中使用的目前styles.csv檔案相同的格式(在撰寫本文時)。
注意:此註釋是實驗性的,仍然有很多錯誤
clip :剪輯輸入style :根據所選的風格自動填入正負提示positive :積極的條件negative :消極的條件歡迎透過報告問題或提出改進建議來為該專案做出貢獻。在 GitHub 儲存庫上提出問題或提交拉取請求。
該項目已獲得 MIT 許可證的許可。有關詳細信息,請參閱許可證文件。


