airllm
1.0.0

快速入門|配置| macOS |範例筆記本|常問問題
AirLLM優化了推理記憶體使用,允許 70B 大型語言模型在單一 4GB GPU 卡上運行推理,無需量化、蒸餾和剪枝。現在您可以在8GB vram上運行405B Llama3.1 。
[2024/08/20] v2.11.0: 支持Qwen2.5
[2024/08/18] v2.10.1 支持CPU推理。支持非分片模型。感謝@NavodPeiris 的出色工作!
[2024/07/30] 支援Llama3.1 405B (範例筆記本)。支援8bit/4bit量化。
[2024/04/20] AirLLM 已經原生支援 Llama3。在 4GB 單 GPU 上執行 Llama3 70B。
[2023/12/25] v2.8.2:支援MacOS運行70B大語言模型。
[2023/12/20] v2.7:支援AirLLMMixtral。
[2023/12/20] v2.6:新增AutoModel,自動偵測模型類型,無需提供模型類別來初始化模型。
[2023/12/18] v2.5:新增預取以重疊模型載入和計算。速度提高 10%。
[2023/12/03] 增加了對ChatGLM 、 QWen 、 Baichuan 、 Mistral 、 InternLM的支援!
[2023/12/02]增加了對安全張量的支援。現在支援開放 llm 排行榜中的所有前 10 名模型。
[2023/12/01]airllm 2.0。支援壓縮:運轉時間加快 3 倍!
[2023/11/20]airllm 初始版本!
首先,安裝airllm pip 套件。
pip install airllm然後,初始化AirLLMLlama2,傳入正在使用的模型的huggingface repo ID,或是本機路徑,就可以像常規的transformer模型一樣進行推理。
(也可以在初始化AirLLMLlama2時透過layer_shards_ saving_path指定分割後的分層模型的保存路徑。
from airllm import AutoModel
MAX_LENGTH = 128
# could use hugging face model repo id:
model = AutoModel . from_pretrained ( "garage-bAInd/Platypus2-70B-instruct" )
# or use model's local path...
#model = AutoModel.from_pretrained("/home/ubuntu/.cache/huggingface/hub/models--garage-bAInd--Platypus2-70B-instruct/snapshots/b585e74bcaae02e52665d9ac6d23f4d0dbc81a0f")
input_text = [
'What is the capital of United States?' ,
#'I like',
]
input_tokens = model . tokenizer ( input_text ,
return_tensors = "pt" ,
return_attention_mask = False ,
truncation = True ,
max_length = MAX_LENGTH ,
padding = False )
generation_output = model . generate (
input_tokens [ 'input_ids' ]. cuda (),
max_new_tokens = 20 ,
use_cache = True ,
return_dict_in_generate = True )
output = model . tokenizer . decode ( generation_output . sequences [ 0 ])
print ( output )注意:在推理過程中,會先將原始模型分解並逐層保存。請確保huggingface快取目錄中有足夠的磁碟空間。
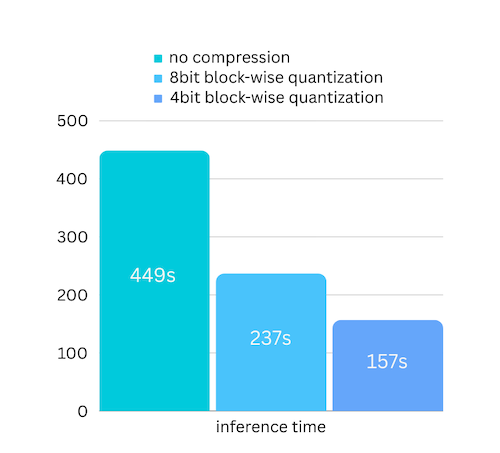
我們剛剛添加了基於逐塊量化的模型壓縮的模型壓縮。這可以進一步將推理速度加快3 倍,而精度損失幾乎可以忽略不計! (查看更多性能評估以及為什麼我們在本文中使用逐塊量化)
pip install -U bitsandbytes Bitsandbytes 安裝了 BitsandBytespip install -U airllm model = AutoModel . from_pretrained ( "garage-bAInd/Platypus2-70B-instruct" ,
compression = '4bit' # specify '8bit' for 8-bit block-wise quantization
)量化通常需要量化權重和激活,才能真正加快速度。這使得保持準確性和避免各種輸入中異常值的影響變得更加困難。
雖然在我們的例子中,瓶頸主要在於磁碟加載,但我們只需要減少模型加載大小。所以,我們只對權重部分進行量化,這樣比較容易保證準確性。
初始化模型時,我們支援以下配置:
只需安裝airllm並像在linux上一樣運行程式碼即可。請參閱快速入門以了解更多資訊。
範例 [python 筆記本] (https://github.com/lyogavin/airllm/blob/main/air_llm/examples/run_on_macos.ipynb)
合作實驗室範例如下:
from airllm import AutoModel
MAX_LENGTH = 128
model = AutoModel . from_pretrained ( "THUDM/chatglm3-6b-base" )
input_text = [ 'What is the capital of China?' ,]
input_tokens = model . tokenizer ( input_text ,
return_tensors = "pt" ,
return_attention_mask = False ,
truncation = True ,
max_length = MAX_LENGTH ,
padding = True )
generation_output = model . generate (
input_tokens [ 'input_ids' ]. cuda (),
max_new_tokens = 5 ,
use_cache = True ,
return_dict_in_generate = True )
model . tokenizer . decode ( generation_output . sequences [ 0 ]) from airllm import AutoModel
MAX_LENGTH = 128
model = AutoModel . from_pretrained ( "Qwen/Qwen-7B" )
input_text = [ 'What is the capital of China?' ,]
input_tokens = model . tokenizer ( input_text ,
return_tensors = "pt" ,
return_attention_mask = False ,
truncation = True ,
max_length = MAX_LENGTH )
generation_output = model . generate (
input_tokens [ 'input_ids' ]. cuda (),
max_new_tokens = 5 ,
use_cache = True ,
return_dict_in_generate = True )
model . tokenizer . decode ( generation_output . sequences [ 0 ]) from airllm import AutoModel
MAX_LENGTH = 128
model = AutoModel . from_pretrained ( "baichuan-inc/Baichuan2-7B-Base" )
#model = AutoModel.from_pretrained("internlm/internlm-20b")
#model = AutoModel.from_pretrained("mistralai/Mistral-7B-Instruct-v0.1")
input_text = [ 'What is the capital of China?' ,]
input_tokens = model . tokenizer ( input_text ,
return_tensors = "pt" ,
return_attention_mask = False ,
truncation = True ,
max_length = MAX_LENGTH )
generation_output = model . generate (
input_tokens [ 'input_ids' ]. cuda (),
max_new_tokens = 5 ,
use_cache = True ,
return_dict_in_generate = True )
model . tokenizer . decode ( generation_output . sequences [ 0 ])許多程式碼都基於 SimJeg 在 Kaggle 考試競賽中的出色工作。向 SimJeg 致敬:
GitHub帳號@SimJeg,Kaggle上的程式碼,相關討論。
safetensors_rust.SafetensorError:反序列化標頭時發生錯誤:MetadataIncompleteBuffer
如果遇到此錯誤,最可能的原因是磁碟空間不足。分割模型的過程非常消耗磁碟。看到這個。您可能需要擴展磁碟空間、清除 Huggingface .cache 並重新運行。
您很可能正在使用 Llama2 類別來載入 QWen 或 ChatGLM 模型。請嘗試以下操作:
對於 QWen 模型:
from airllm import AutoModel #<----- instead of AirLLMLlama2
AutoModel . from_pretrained (...)對於 ChatGLM 模型:
from airllm import AutoModel #<----- instead of AirLLMLlama2
AutoModel . from_pretrained (...)有些模型是門控模型,需要 Huggingface api 令牌。您可以提供 hf_token:
model = AutoModel . from_pretrained ( "meta-llama/Llama-2-7b-hf" , #hf_token='HF_API_TOKEN')某些模型的標記產生器沒有填充標記,因此您可以設定填充標記或簡單地關閉填充配置:
input_tokens = model . tokenizer ( input_text ,
return_tensors = "pt" ,
return_attention_mask = False ,
truncation = True ,
max_length = MAX_LENGTH ,
padding = False #<----------- turn off padding
)如果您發現 AirLLM 對您的研究有用並希望引用它,請使用以下 BibTex 條目:
@software{airllm2023,
author = {Gavin Li},
title = {AirLLM: scaling large language models on low-end commodity computers},
url = {https://github.com/lyogavin/airllm/},
version = {0.0},
year = {2023},
}
歡迎貢獻、想法和討論!
如果你覺得有用,請或請我喝杯咖啡!


