Ainur
1.0.0
Ainur 是一種用於條件多模態音樂生成的創新深度學習模型。它旨在根據各種輸入(例如歌詞、文字描述符和其他音訊)生成 48 kHz 的高品質立體聲音樂樣本。 Ainur 的分層擴散架構與 CLASP 嵌入相結合,使其能夠創造出跨各種流派和風格的連貫且富有表現力的音樂作品。 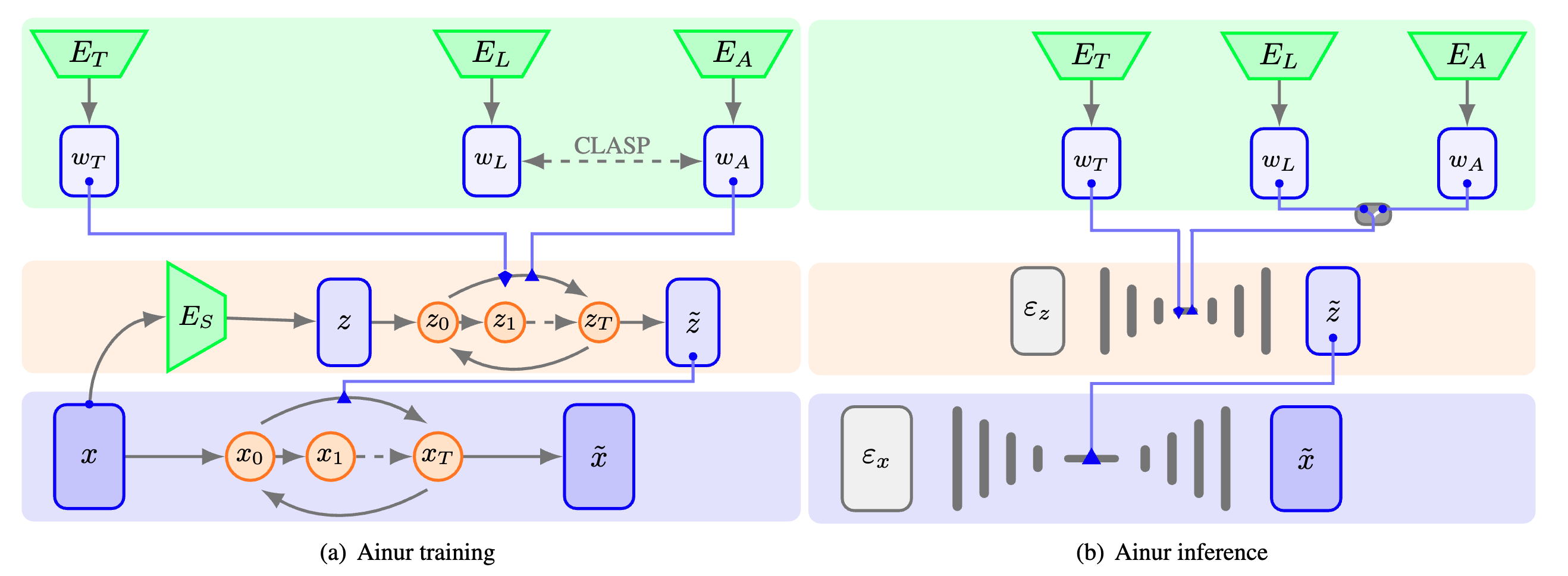

條件生成: Ainur 能夠根據歌詞、文字描述符或其他音訊生成音樂,為音樂創作提供靈活且富有創意的方法。
高品質輸出:該模型能夠以 48 kHz 產生 22 秒立體聲音樂樣本,確保高保真度和真實感。
多模態學習: Ainur 採用 CLASP 嵌入(歌詞和音訊的多模態表示)來促進文字歌詞與對應音訊片段的對齊。
客觀評估:我們提供全面的評估指標,包括 Frechet Audio Distance (FAD) 和 CLASP Cycle Consistency (C3),以評估生成音樂的品質和連貫性。
若要執行 Ainur,請確保安裝了以下相依性:
Python 3.8+
火炬 1.13.1
PyTorch 閃電 2.0.0
您可以透過執行以下命令來安裝所需的 Python 套件:
pip install -r 要求.txt
克隆此存儲庫:
git 克隆 https://github.com/ainur-music/ainur.gitcd ainur
安裝依賴項(如上所述)。
使用您所需的輸入來運行 Ainur。請參閱examples資料夾中的範例筆記本,以取得有關使用 Ainur 進行音樂產生的指導。 (即將推出)
Ainur 透過文字訊息和同步歌詞指導音樂的生成並提高聲音品質。以下是使用 Ainur 訓練和產生音樂的輸入範例:
«Red Hot Chili Peppers, Alternative Rock, 7 of 19»
«[00:45.18] I got your hey oh, now listen what I say oh [...]»
我們將 Ainur 的性能與其他最先進的文本到音樂生成模型的性能進行了比較。我們基於 FAD 等客觀指標進行評估,並參考不同的嵌入模型:VGGish、YAMNet 和 Trill。
| 模型 | 速率 [kHz] | 長度[秒] | 參數[M] | 推理步驟 | 推理時間 [s] ↓ | FAD VGGish ↓ | FAD YAM網 ↓ | 流行顫音 ↓ |
|---|---|---|---|---|---|---|---|---|
| 艾努爾 | 48@2 | 22 號 | 910 | 50 | 14.5 | 8.38 | 20.70 | 0.66 |
| 艾努爾(無扣) | 48@2 | 22 號 | 910 | 50 | 14.7 | 8.40 | 20.86 | 0.64 |
| 音訊LDM | 16@1 | 22 號 | 181 | 200 | 2.20 | 15.5 | 784.2 | 0.52 |
| 音訊LDM 2 | 16@1 | 22 號 | 1100 | 100 | 20.8 | 8.67 | 23.92 | 0.52 |
| 音樂產生器 | 16@1 | 22 號 | 300 | 1500 | 81.3 | 14.4 | 53.04 | 0.66 |
| 點唱機 | 16@1 | 1 | 1000 | - | 第538章 | 20.4 | 178.1 | 1.59 |
| 音樂LM | 16@1 | 5 | 1890年 | 125 | 153 | 15.0 | 61.58 | 0.47 |
| 擴散 | 44.1@1 | 5 | 890 | 50 | 6.90 | 5.24 | 15.96 | 0.67 |
在這裡探索和聆聽 Ainur 創作的音樂。
您可以從磁碟機下載預先訓練的 Ainur 和 CLASP 檢查點:
Ainur 最佳檢查點(訓練期間損失最低的模型)
Ainur最後一個檢查點(訓練步驟數最多的模型)
扣環檢查點
該項目根據 MIT 許可證獲得許可 - 有關詳細信息,請參閱許可證文件。
© 2023 朱塞佩康西亞迪


