synthetic data generator
0.2.3
切換語言:簡體中文 | 最新 API 文件 | 路線圖 | 加入微信群
Colab 範例:法學碩士:資料合成 | 法學碩士:表外推理| 十億級數據支持CTGAN
綜合資料產生器 (SDG) 是一個專門的框架,旨在產生高品質的結構化表格資料。
合成資料不包含任何敏感訊息,但保留了原始資料的基本特徵,使其不受 GDPR 和 ADPPA 等隱私法規的約束。
高品質的合成資料可以在資料共享、模型訓練和調試、系統開發和測試等各個領域安全地利用。
我們很高興您能來到這裡,並期待您的貢獻,透過此貢獻概述指南開始專案!
我們目前的主要成就和時間表如下:
2024 年 11 月 21 日:1) 模型整合 - 我們已將GaussianCopula模型整合到我們的資料處理器系統中。查看此 PR 中的程式碼範例; 2)合成品質-我們實現了資料列關係的自動檢測並允許關係規範,提高了合成資料的品質(程式碼範例); 3) 效能增強 - 我們顯著減少了 GaussianCopula 在處理離散資料時的記憶體使用量,從而能夠使用2C4G設定對數千個分類資料條目進行訓練!
2024年5月30日:資料處理器模組正式合併。此模組將:1)幫助SDG在輸入模型之前轉換一些資料列(例如Datetime列)的格式(以避免被視為離散類型),並將模型產生的資料反向轉換為原始格式; 2)對各種資料類型進行更多客製化的預處理和後處理; 3)輕鬆處理原始資料中的空值等問題; 4)支援插件系統。
2024年2月20日:包含基於LLM的單表資料合成模型,查看colab範例:LLM:資料合成與LLM:表外特徵推理。
2024年2月7日:我們改進了sdgx.data_models.metadata ,支援單表和多表的元資料資訊描述,支援多種資料類型,支援自動資料類型推斷。查看colab範例:SDG單表元資料。
2023年12月20日:v0.1.0發布,包含支援數十億資料處理能力的CTGAN模型,查看我們針對SDV的基準測試,其中SDG實現了更少的記憶體消耗並避免了訓練期間的崩潰。具體使用請查看colab範例:Billion-Level-Data支援的CTGAN。
2023 年 8 月 10 日:提交 SDG 代碼的第一行。
長期以來,LLM一直被用來理解和產生各種類型的數據。事實上,LLM在表格資料產生方面也有一定的能力。而且,它還具有一些傳統(基於GAN方法或統計方法)無法實現的能力。
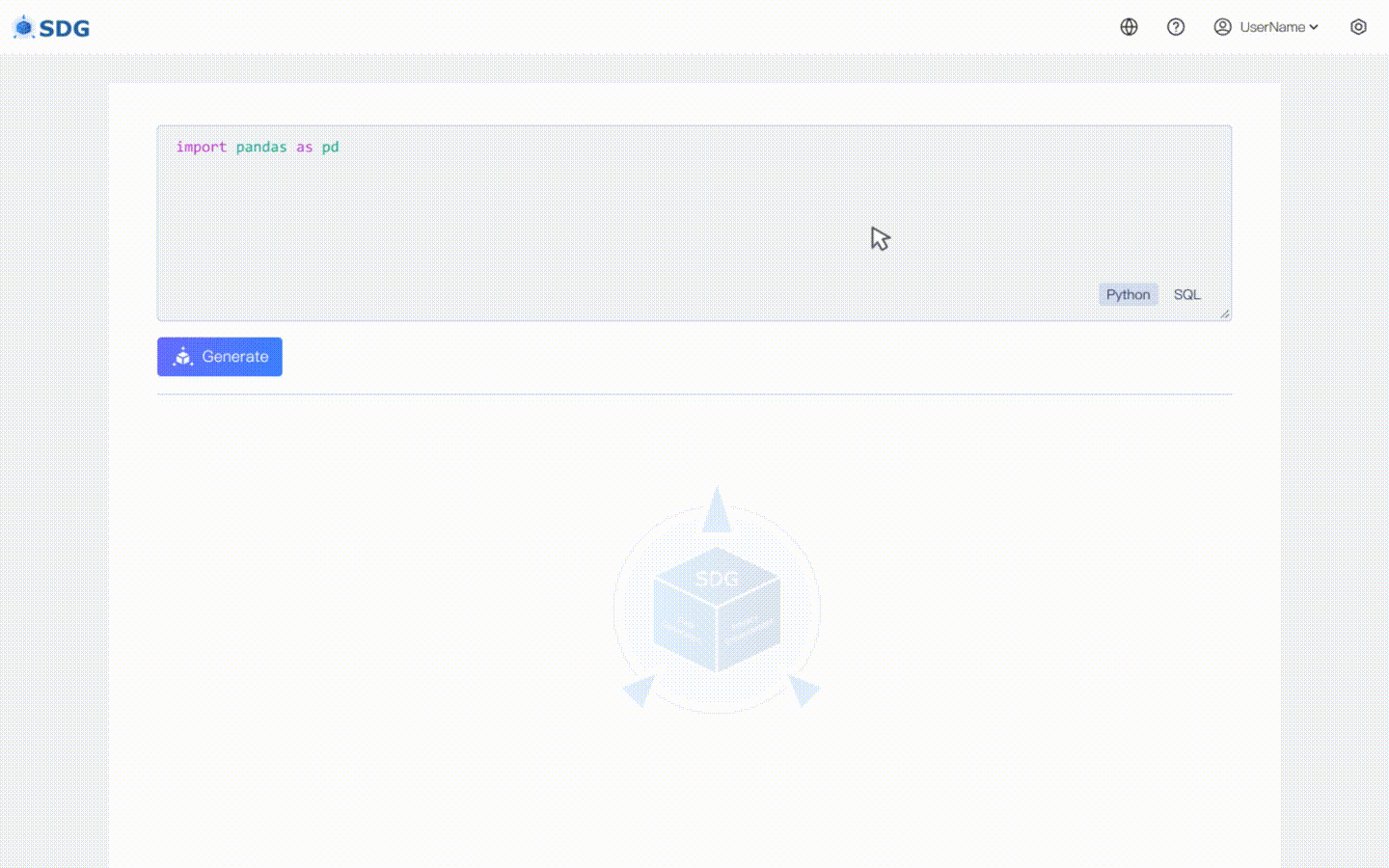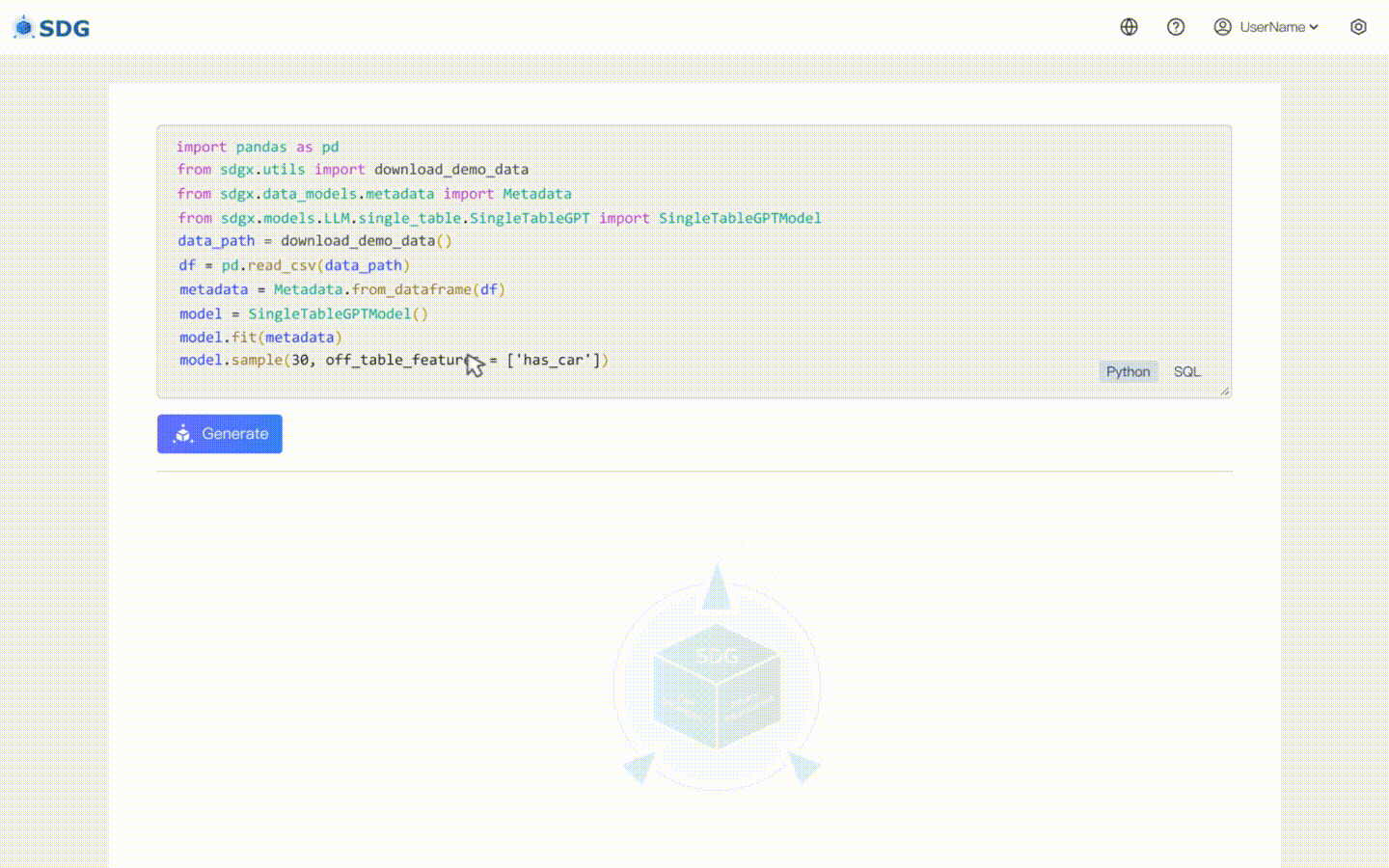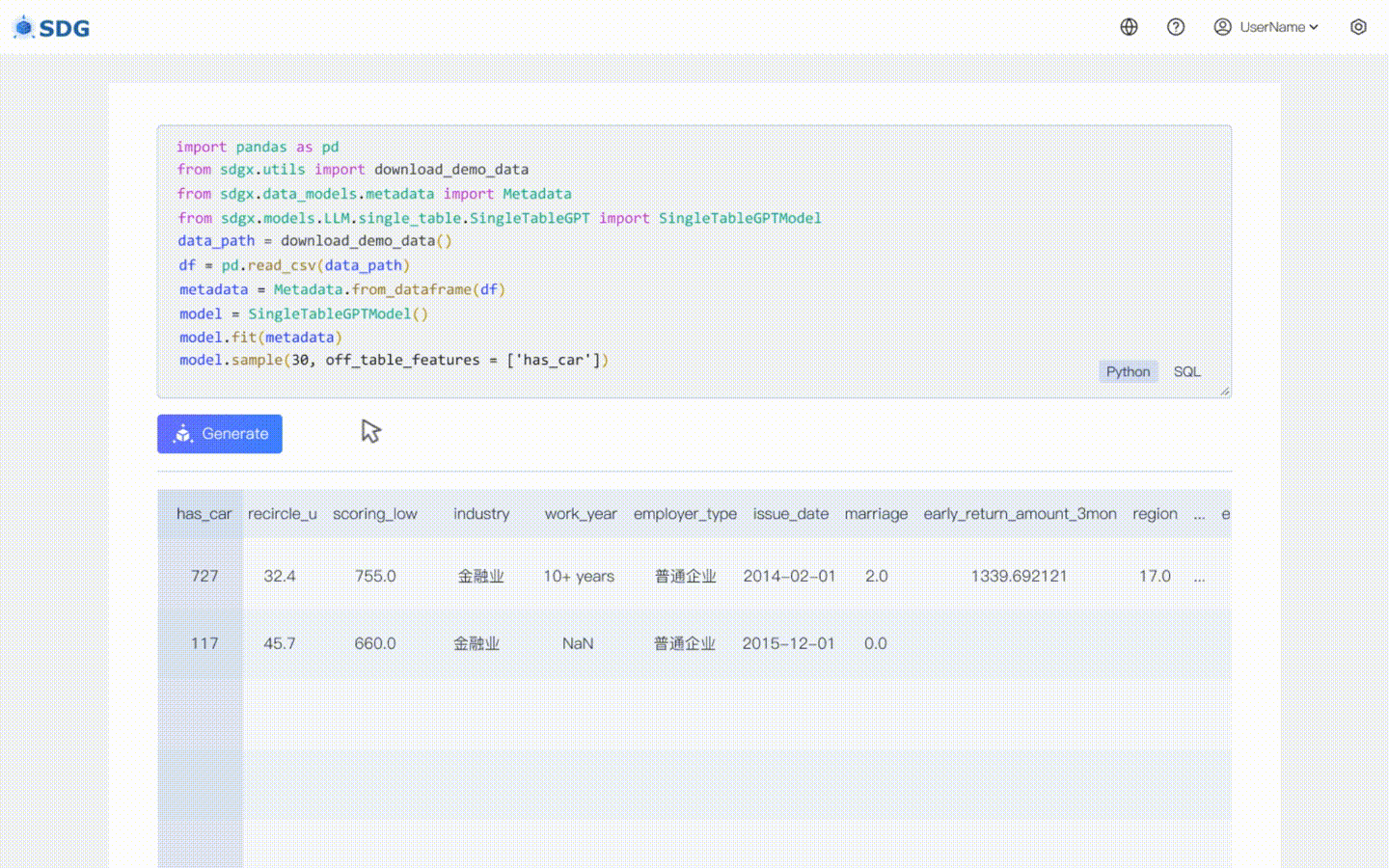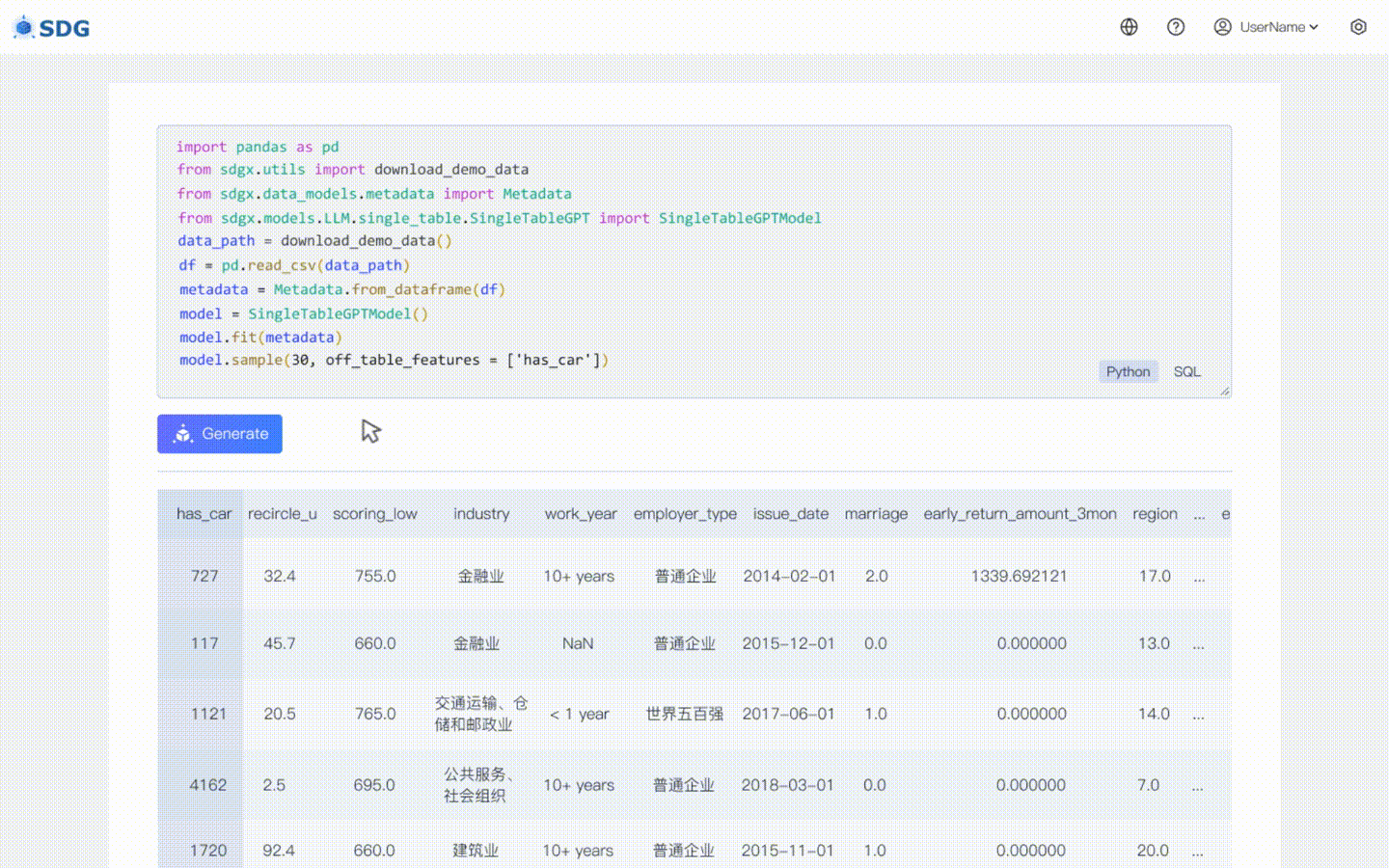
我們的sdgx.models.LLM.single_table.gpt.SingleTableGPTModel實作了兩個新功能:
不需要訓練數據,可以根據元數據產生合成數據,請在我們的 Colab 範例中查看。
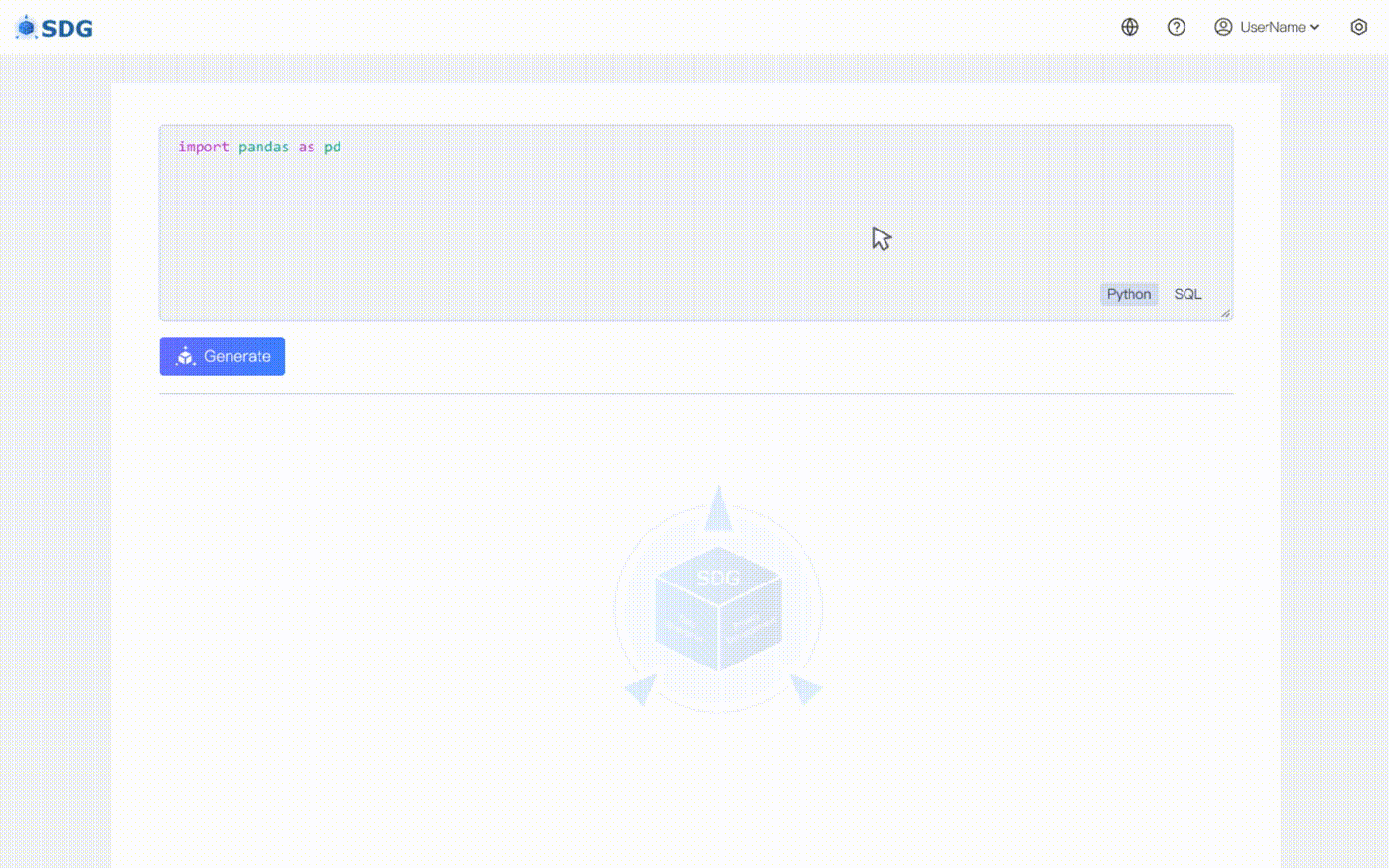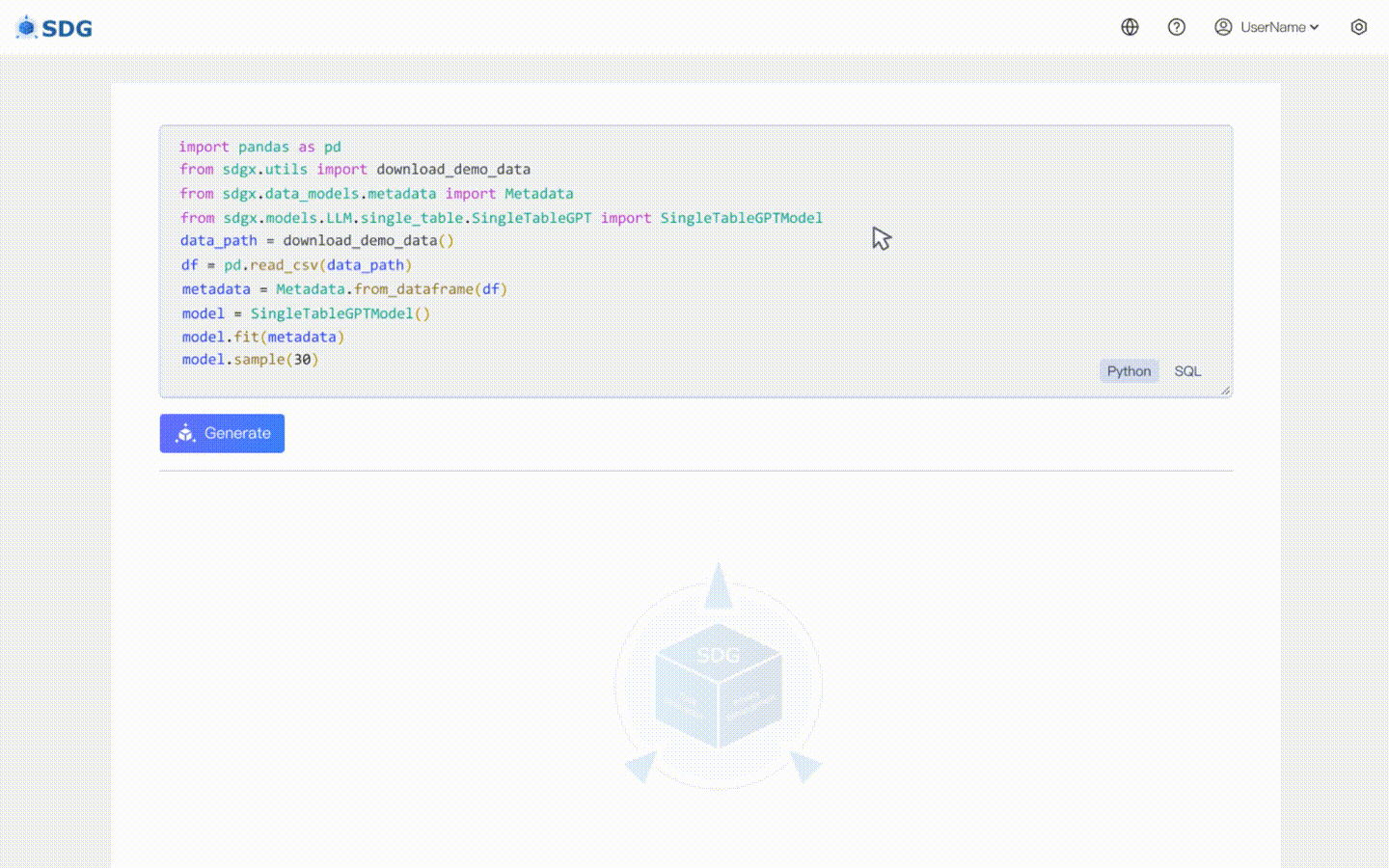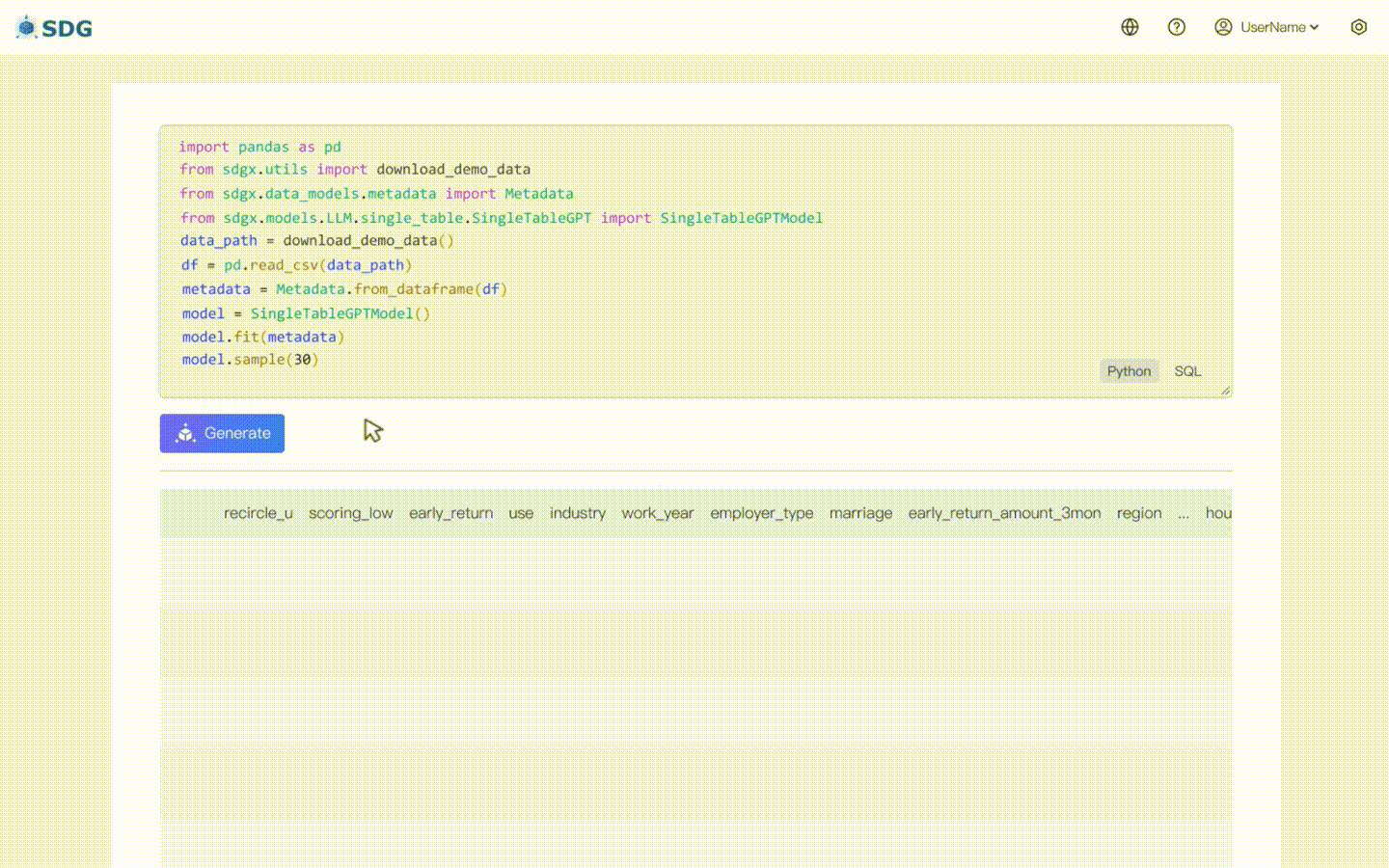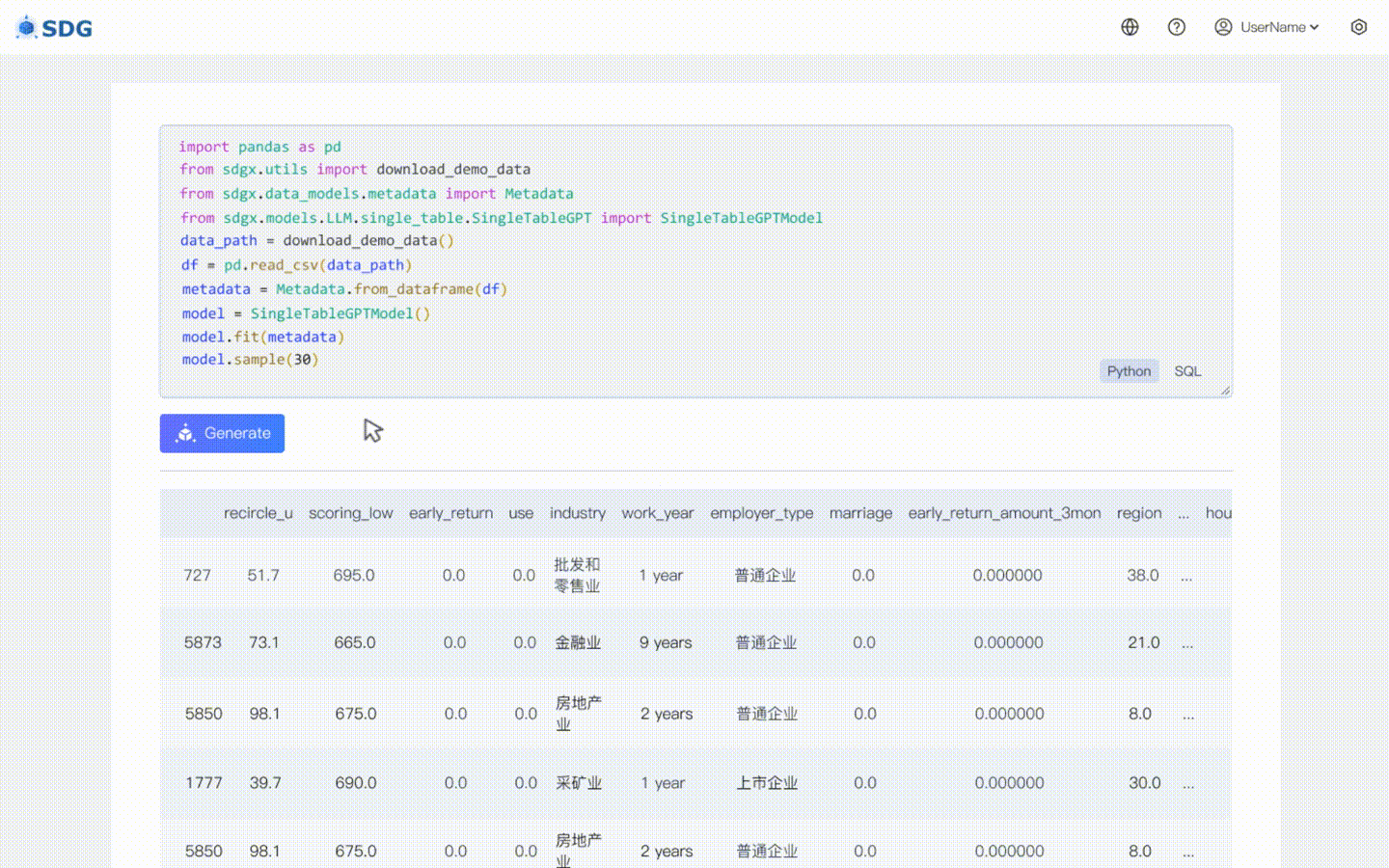
根據表中現有數據和LLM掌握的知識推斷新的列數據,請參見我們的colab範例。
技術進步:
支援多種統計數據合成演算法,還整合了基於LLM的合成數據生成模型;
針對大數據優化,有效降低記憶體消耗;
持續追蹤學術界和工業界的最新進展,及時推出對優秀演算法和模型的支援。
隱私增強功能:
SDG支援差分隱私、匿名化等方法來增強合成資料的安全性。
易於擴展:
支援以插件包的形式擴展模型、資料處理、資料連接器等。
您可以使用預先建置的鏡像來快速體驗最新功能。
docker pull idsteam/sdgx:最新
pip 安裝 sdgx
透過原始碼安裝 SDG 來使用它。
git 克隆 [email protected]:hitsz-ids/synthetic-data-generator.git pip install .# 或從 git 安裝 pip install git+https://github.com/hitsz-ids/synthetic-data-generator.git
from sdgx.data_connectors.csv_connector import CsvConnectorfrom sdgx.models.ml.single_table.ctgan import CTGANSynthesizerModelfrom sdgx.synthesizer import Synthesizerfrom sdgx.downloadp. # 建立csv 檔案的數據連接器data_connector = CsvConnector(path=dataset_csv)# 初始化合成器,使用 CTGAN modelsynthesizer = Synthesizer(model=CTGANSynthesizerModel(epochs=1), # 用於快速示範 data_connector=data_connector, )# 擬合模型synthesizer.fit()# Samplesampled_data = Synthesizer.sample(1000)print(sampled_data)
真實數據如下:
>>> data_connector.read() 年齡 工作類別 fnlwgt 教育 ... 每週資本損失小時數 本國類別0 2 州政府 77516 學士 ... 0 2 美國 <=50K1 3 自營非公司 83311 學士 .. . 0 0 美國<=50K2 2 私立215646 高中畢業生... 0 2 美國<=50K3 3 私立234721 11th ... 0 2 美國<=50K4 1 私立338409 學士... 0 2古巴<=50K... . .. ... ... ... ... ... ... ... ...48837 2 私人215419 學士... 0 2 美國<=50K48838 4 NaN 321403 高中畢業生... 0 2 美國<=50K48839 2 私立374983 學士... 0 3 美國<=50K48840 2 私立83891 學士... 0 2 美國<=50K48841 1 自學emp-inc 182148 美國學士... 0 3824K[ 15 列]
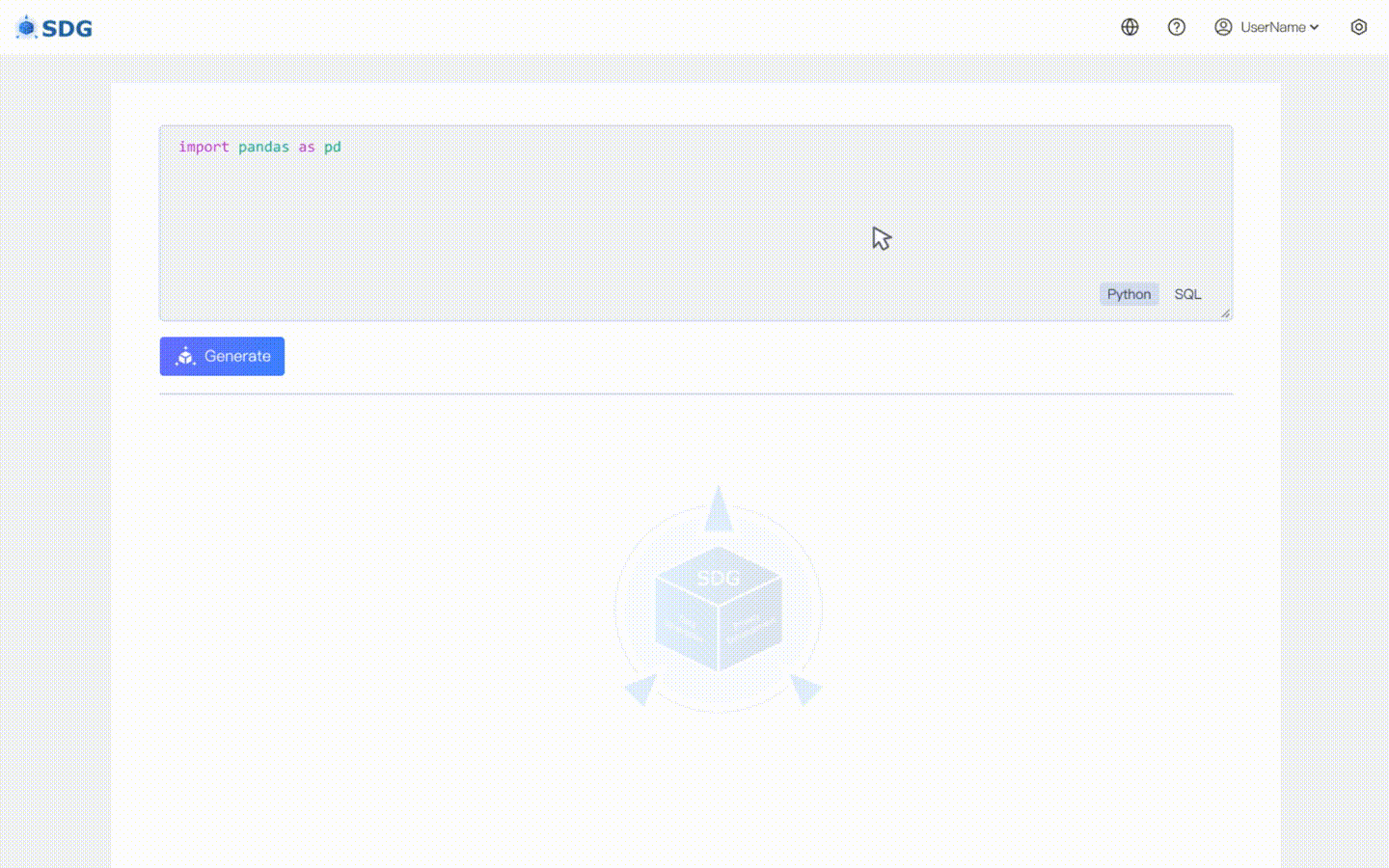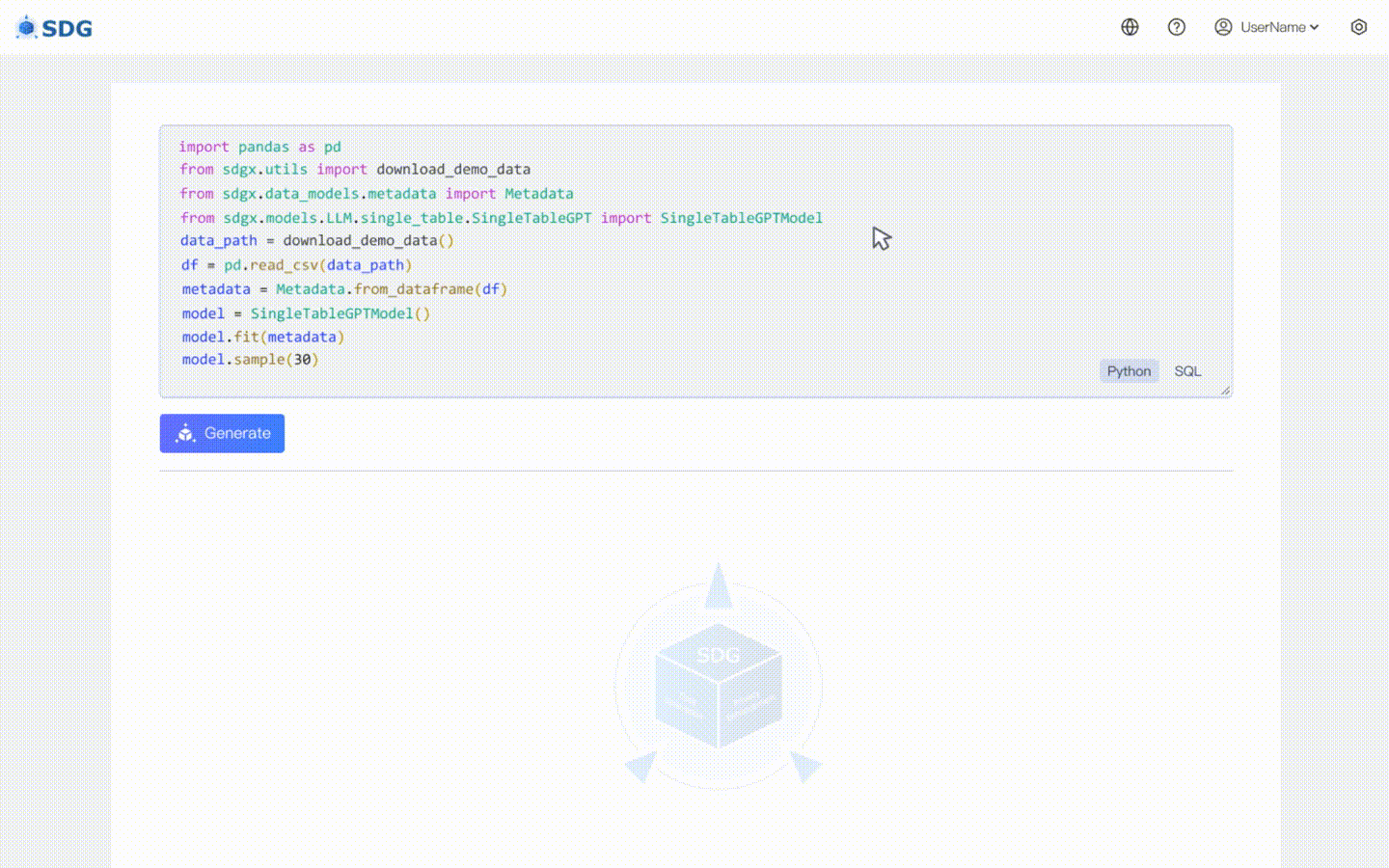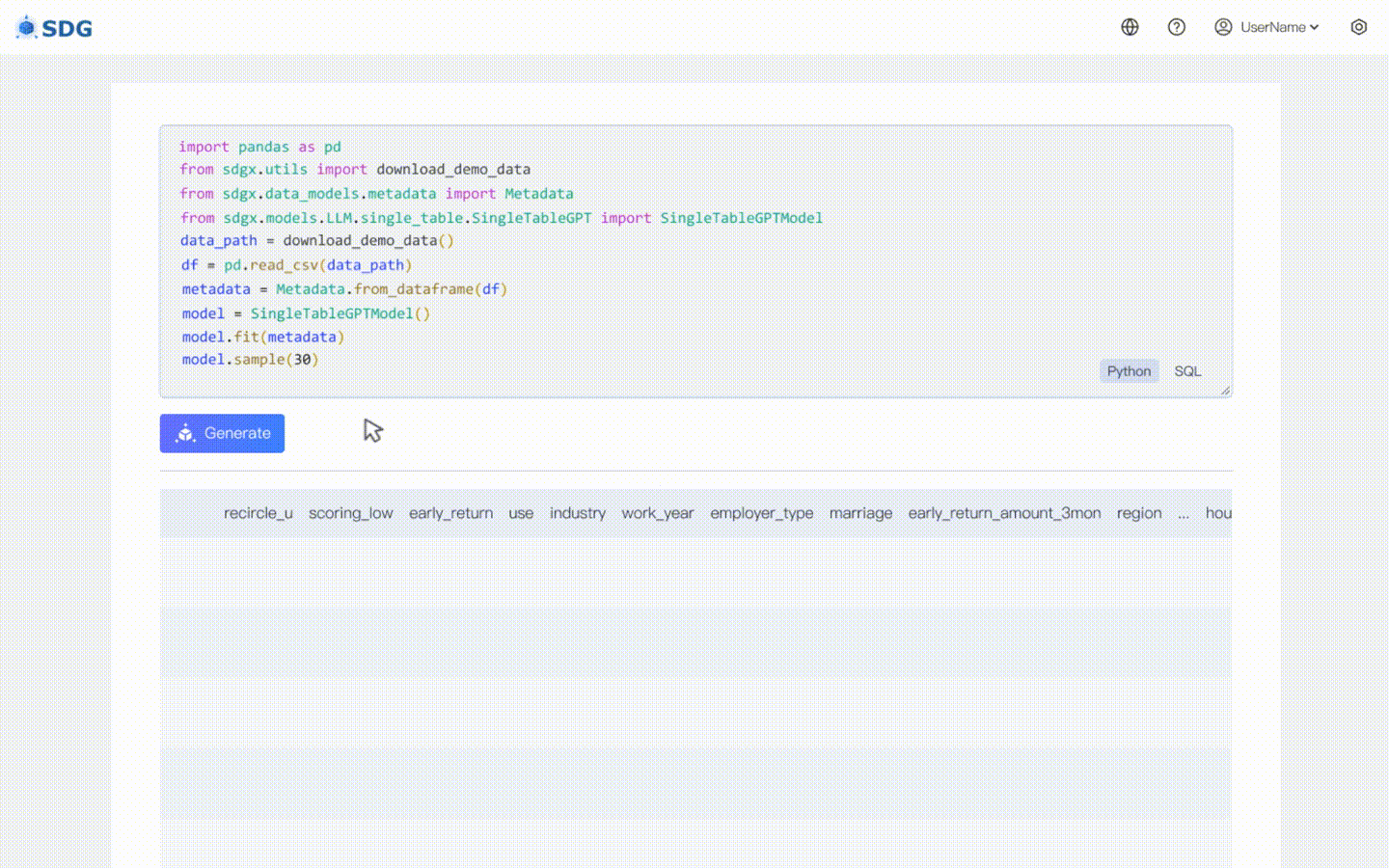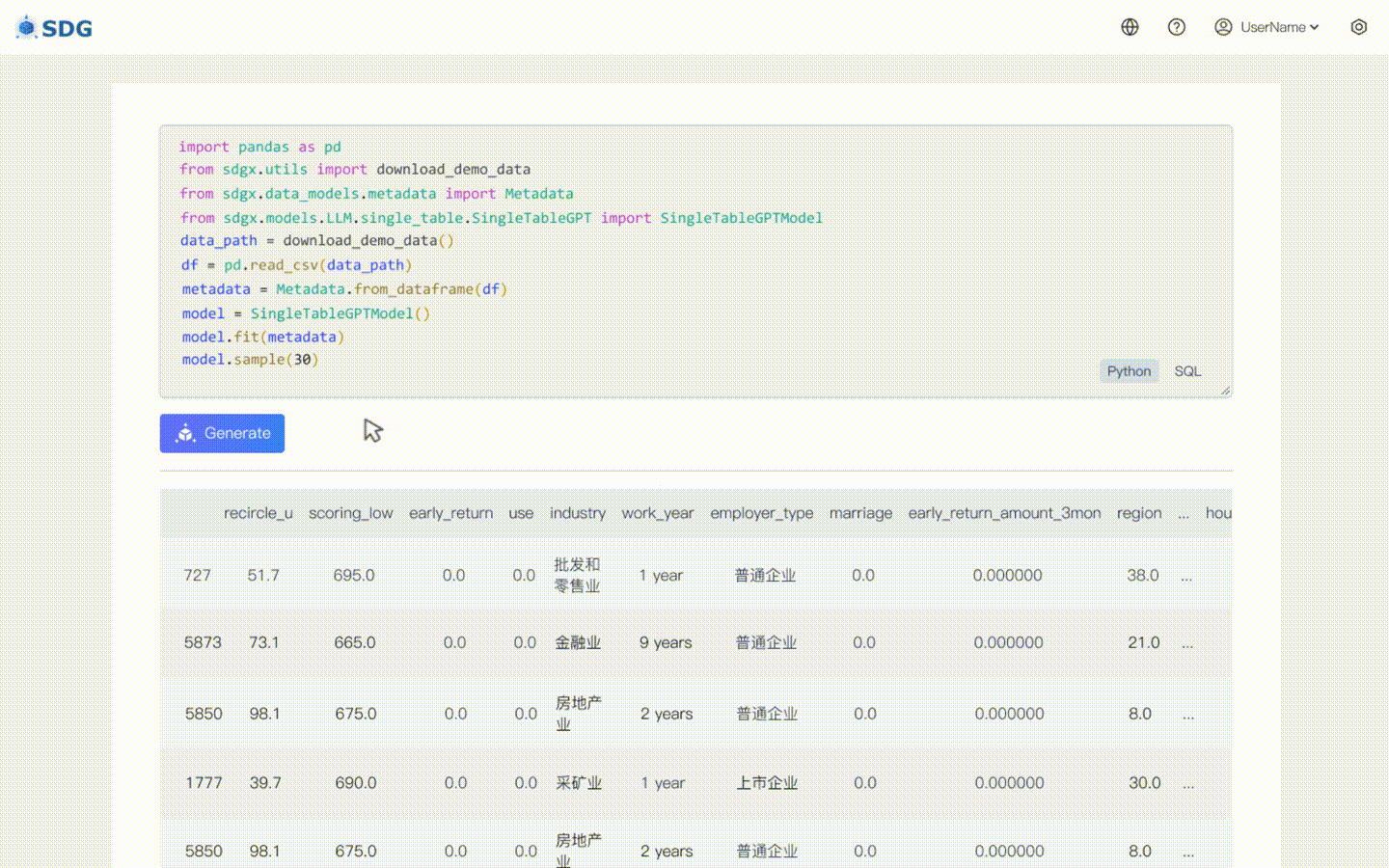
綜合數據如下:
>>> 樣本資料年齡 工人階級 fnlwgt 教育 ... 每週資本損失小時數 本國階級 0 1 NaN 28219 某大學 ... 0 2 波多黎各 <=50K1 2 私立 250166 高中畢業生 ... 0 2 美國 >50K2 2 私立50304 高中畢業生... 0 2 美國<=50K3 4 私立89318 學士... 0 2 波多黎各>50K4 1 私立172149 學士... 0 3 美國<=50K.. .. . ... .. . ... ... ... ... ...995 2 NaN 208938 學士... 0 1 美國<=50K996 2 私立166416 學士... 2 2美國<=50K997 2 NaN 336022 HS-grad . .. 0 1 美國<=50K998 3 Private 198051 Masters ... 0 2 美國>50K999 1 NaN 41973 HS-grad ... 0 2 United-狀態 <=50K[1000 行 x 15 列]
CTGAN:使用條件 GAN 建模表格數據
C3-TGAN:C3-TGAN-具有明確相關性和屬性約束的可控表格資料合成
TVAE:使用條件 GAN 對表格資料建模
table-GAN:基於生成對抗網路的資料合成
CTAB-GAN:CTAB-GAN:有效的表資料合成
OCT-GAN:OCT-GAN:基於神經 ODE 的條件表格 GAN
SDG計畫由哈爾濱工業大學資料安全研究所發起。如果您對我們的專案感興趣,歡迎加入我們的社區。我們歡迎與我們一樣致力於透過開源實現資料保護和安全的組織、團隊和個人:
在起草拉取請求之前閱讀 CONTRIBUTING。
透過查看 View Good First Issue 或提交 Pull Request 來提交問題。
透過二維碼加入我們的微信群。