Adding Private Data to LLMs
1.0.0
法學碩士以其創建逼真圖像、程式碼和對話的能力震驚了世界。毫無疑問,ChatGPT 已經風靡全球。數百萬人正在使用它。雖然它對於通用知識來說非常有用,但它只知道它所訓練的信息,即 2021 年之前普遍可用的互聯網數據。它缺乏對您的私人資料的了解,並且仍然不了解最新的資料來源。因此,為了在這方面改進它們,我們可以向他們提供我們從搜尋步驟中檢索到的資訊。這使得它們更加真實,並且能夠更好地為模型提供最新信息,而無需重新訓練這些大規模模型。這正是檢索增強法學碩士或檢索增強生成(RAG)系統。事實上,該儲存庫將精確概述 RAG 系統的創建並闡明所涉及的最佳化步驟。
抹布
技術堆疊
安裝
有用的連結
接觸
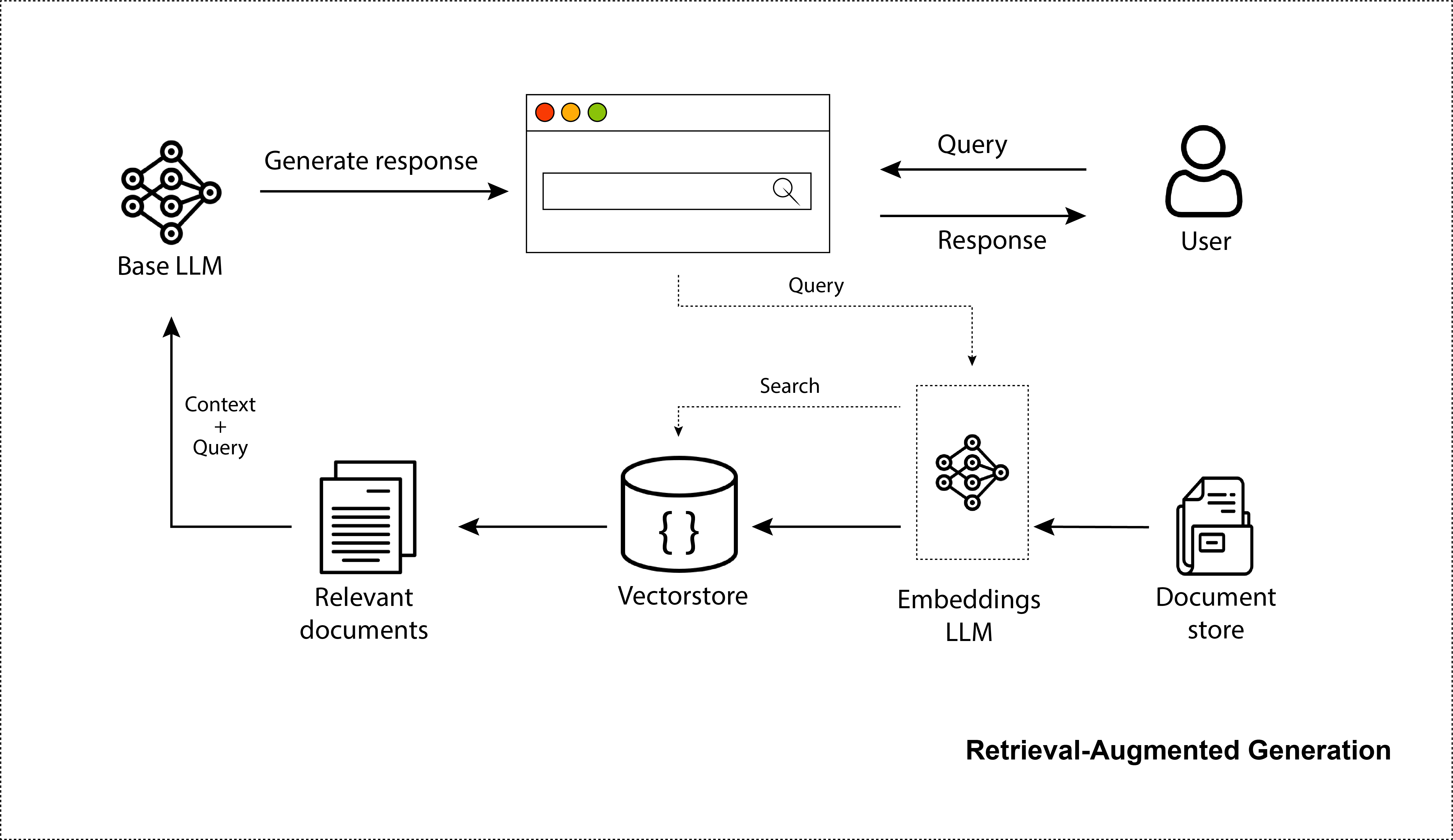
浪鏈
駱駝指數
Azure 開放人工智慧
格拉迪奧
克隆 Github 儲存庫
git 克隆 https://github.com/zekaouinoureddine/Adding-Private-Data-to-LLMs.git
要求 Cd 到專案目錄並確保已安裝 Python 3 以及必要的依賴項。
cd 將私有資料新增至 LLM pip install -r 要求.txt
運行 Gradio 應用程式
蟒蛇 rag.py
在您的電腦上造訪 http://127.0.0.1:7860 來測試應用程式。您應該會看到類似以下內容:
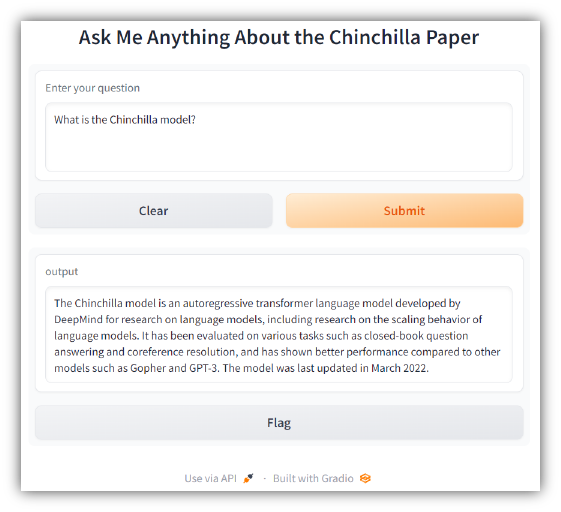
| 部落格 | 平台 | 語言 | 筆記本 |
|---|---|---|---|
| 詢問你自己的數據 | Hiberus 部落格 | ES | |
| 詢問你自己的數據 | 中等的 | CN | |
| 詢問您的網頁 | Hiberus 部落格 | ES | |
| 詢問您的網頁 | 中等的 | CN |
如果您喜歡,請給它一個,然後關注我:
LinkedIn:努爾·埃丁·澤考伊
推特:@NZkaoui
回到頂部


