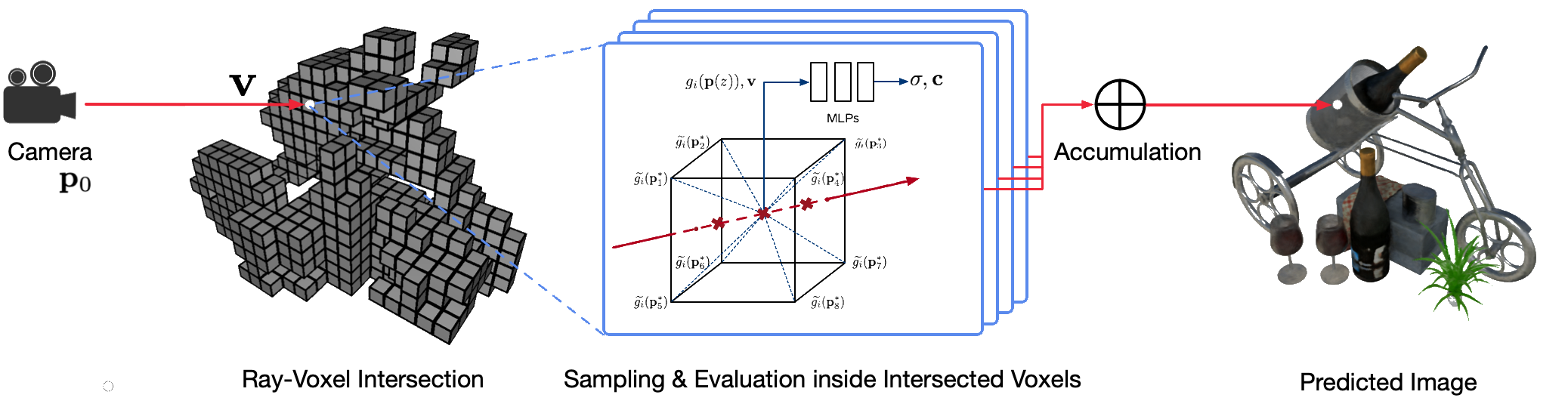
使用經典電腦圖形技術對現實世界場景進行逼真的自由視點渲染是一個具有挑戰性的問題,因為它需要捕捉詳細外觀和幾何模型的困難步驟。神經渲染是一個新興領域,它採用深度神經網路隱式學習場景表示,其中包含來自有或沒有粗略幾何形狀的 2D 觀察中的幾何形狀和外觀。然而,該領域的現有方法經常顯示模糊的渲染或渲染過程緩慢。我們提出了神經稀疏體素場(NSVF),這是一種新的神經場景表示,用於快速、高品質的自由視點渲染。
這是論文的官方儲存庫:
我們還提供以下非官方實作:
該程式碼是使用 fairseq 框架在 PyTorch 中實現的。
該程式碼已在以下系統上測試:
僅支援 GPU 上的學習和渲染。
要安裝,請先複製此儲存庫並安裝所有相依性:
pip install -r requirements.txt然後,運行
pip install --editable ./或者,如果您想在本機安裝程式碼,請執行:
python setup.py build_ext --inplace您可以下載我們論文中使用的預處理的合成資料集和真實資料集。如果您在工作中使用其中任何論文,也請引用原始論文。
| 數據集 | 下載連結 | 資料集分割注意事項 |
|---|---|---|
| 合成NSVF | 下載(.zip) | 0_*(訓練)1_*(驗證)2_*(測試) |
| 合成NeRF | 下載(.zip) | 0_*(訓練)1_*(驗證)2_*(測試) |
| 混合MVS | 下載(.zip) | 0_*(訓練)1_*(測試) |
| 坦克&鏡腳 | 下載(.zip) | 0_*(訓練)1_*(測試) |
要準備單一場景的新資料集用於訓練和測試,請遵循以下資料結構:
< dataset_name >
| -- bbox.txt # bounding-box file
| -- intrinsics.txt # 4x4 camera intrinsics
| -- rgb
| -- 0.png # target image for each view
| -- 1.png
...
| -- pose
| -- 0.txt # camera pose for each view (4x4 matrices)
| -- 1.txt
...
[optional]
| -- test_traj.txt # camera pose for free-view rendering demonstration (4N x 4)其中bbox.txt檔案包含一行描述初始邊界框和體素大小的行:
x_min y_min z_min x_max y_max z_max initial_voxel_size需要注意的是,目標影像的檔案名稱和對應的相機位姿檔案的檔案名稱不需要完全相同。但是,這兩種文件的順序(按字串排序)必須匹配。資料集按視圖索引進行分割。例如,「 train (0..100) 、 valid (100..200)和test (200..400) 」表示前100 個視圖用於訓練,第100-199 個視圖用於驗證,第200-399個視圖用於測試。
給定單一場景的資料集 ( {DATASET} ),我們使用以下命令訓練 NSVF 模型以合成800x800像素的新穎視圖,批量大小為每個 GPU 4影像和每個影像2048光線。預設情況下,程式碼將自動偵測所有可用的 GPU。
在下列範例中,我們使用具有特定參數的預定義架構nsvf_base :
--no-sampling-at-reader ,模型僅對稀疏體素的投影影像區域中的像素進行採樣以進行訓練。1/8 (0.125)這通常在bbox.txt檔案中描述。--use-octree 。它將建構一個稀疏體素八叉樹來加速射線-體素相交,特別是當體素數量大於10000時。--pruning-every-steps設定為2500 ,模型每2500步執行一次自修剪。--half-voxel-size-at和--reduce-step-size-at設定為5000,25000,75000 ,體素大小和步長分別減半為5k 、 25k和75k 。請注意,儘管本文中的大多數實驗都使用上述參數設置,但可以調整這些參數以獲得更好的品質。除上述參數外,其他參數也可以採用預設設定。
除了nsvf_base架構之外,您還可以檢查其他架構或在檔案fairnr/models/nsvf.py中定義自己的架構。
python -u train.py ${DATASET}
--user-dir fairnr
--task single_object_rendering
--train-views " 0..100 " --view-resolution " 800x800 "
--max-sentences 1 --view-per-batch 4 --pixel-per-view 2048
--no-preload
--sampling-on-mask 1.0 --no-sampling-at-reader
--valid-views " 100..200 " --valid-view-resolution " 400x400 "
--valid-view-per-batch 1
--transparent-background " 1.0,1.0,1.0 " --background-stop-gradient
--arch nsvf_base
--initial-boundingbox ${DATASET} /bbox.txt
--use-octree
--raymarching-stepsize-ratio 0.125
--discrete-regularization
--color-weight 128.0 --alpha-weight 1.0
--optimizer " adam " --adam-betas " (0.9, 0.999) "
--lr 0.001 --lr-scheduler " polynomial_decay " --total-num-update 150000
--criterion " srn_loss " --clip-norm 0.0
--num-workers 0
--seed 2
--save-interval-updates 500 --max-update 150000
--virtual-epoch-steps 5000 --save-interval 1
--half-voxel-size-at " 5000,25000,75000 "
--reduce-step-size-at " 5000,25000,75000 "
--pruning-every-steps 2500
--keep-interval-updates 5 --keep-last-epochs 5
--log-format simple --log-interval 1
--save-dir ${SAVE}
--tensorboard-logdir ${SAVE} /tensorboard
| tee -a $SAVE /train.log檢查點保存在{SAVE} 。您可以啟動tensorboard來檢查訓練進度:
tensorboard --logdir= ${SAVE} /tensorboard --port=10000在範例下有更多訓練腳本的範例來重現我們論文的結果。
模型訓練完成後,將使用以下指令來評估給定{MODEL_PATH}測試視圖上的渲染品質。
python validate.py ${DATASET}
--user-dir fairnr
--valid-views " 200..400 "
--valid-view-resolution " 800x800 "
--no-preload
--task single_object_rendering
--max-sentences 1
--valid-view-per-batch 1
--path ${MODEL_PATH}
--model-overrides ' {"chunk_size":512,"raymarching_tolerance":0.01,"tensorboard_logdir":"","eval_lpips":True} ' 請注意,我們將raymarching_tolerance覆寫為0.01以啟用提前終止以加速渲染。
一旦訓練好模型並指定渲染軌跡,就可以實現自由視點渲染。例如,以下指令用於使用圓形軌跡進行渲染(角速度3度/幀,每個GPU 15幀)。這會輸出每個視圖渲染的影像,並將影像合併到${SAVE}/output中的.mp4影片中,如下所示:

預設情況下,程式碼可以偵測所有可用的 GPU。
python render.py ${DATASET}
--user-dir fairnr
--task single_object_rendering
--path ${MODEL_PATH}
--model-overrides ' {"chunk_size":512,"raymarching_tolerance":0.01} '
--render-beam 1 --render-angular-speed 3 --render-num-frames 15
--render-save-fps 24
--render-resolution " 800x800 "
--render-path-style " circle "
--render-path-args " {'radius': 3, 'h': 2, 'axis': 'z', 't0': -2, 'r':-1} "
--render-output ${SAVE} /output
--render-output-types " color " " depth " " voxel " " normal " --render-combine-output
--log-format " simple "我們的程式碼還支援給定相機姿勢的渲染。例如,以下命令用於使用資料夾${DATASET}/pose下第 200-399 個檔案中定義的相機姿勢進行渲染:
python render.py ${DATASET}
--user-dir fairnr
--task single_object_rendering
--path ${MODEL_PATH}
--model-overrides ' {"chunk_size":512,"raymarching_tolerance":0.01} '
--render-save-fps 24
--render-resolution " 800x800 "
--render-camera-poses ${DATASET} /pose
--render-views " 200..400 "
--render-output ${SAVE} /output
--render-output-types " color " " depth " " voxel " " normal " --render-combine-output
--log-format " simple "該程式碼還支援使用.txt檔案中定義的相機姿勢進行渲染。請參考這個例子。
我們也支援運行行進立方體,從經過訓練的 NSVF 模型中將等值面提取為三角形網格,並儲存為{SAVE}/{NAME}.ply 。
python extract.py
--user-dir fairnr
--path ${MODEL_PATH}
--output ${SAVE}
--name ${NAME}
--format ' mc_mesh '
--mc-threshold 0.5
--mc-num-samples-per-halfvoxel 5也可以透過設定--format 'voxel_mesh'導出學習到的稀疏體素。輸出.ply檔案可以使用任何 3D 檢視器(例如 MeshLab)開啟。

NSVF 獲得 MIT 許可。該許可證也適用於預先訓練的模型。
請引用為
@article { liu2020neural ,
title = { Neural Sparse Voxel Fields } ,
author = { Liu, Lingjie and Gu, Jiatao and Lin, Kyaw Zaw and Chua, Tat-Seng and Theobalt, Christian } ,
journal = { NeurIPS } ,
year = { 2020 }
}

