影像火災偵測
此儲存庫的目的是演示火災偵測神經網路模型。在使用中,該模型將在圖像中的任何火災周圍放置一個邊界框。

最好的結果
物件偵測:在嘗試了各種模型架構之後,我選擇了 Yolov5 pytorch 模型(請參閱pytorch/object-detection/yolov5/experiment1/best.pt )。經過幾個小時的實驗,我產生了一個[email protected]為 0.657、精度為 0.6、召回率為 0.7 的模型,在 1155 個圖像(337 個基礎圖像 + 增強圖像)上進行訓練。
分類:我還沒有訓練自己的模型,但使用 ResNet50 的準確率達到 95%
分段:需要註釋
動機和挑戰
傳統的煙霧偵測器透過偵測煙霧顆粒的物理存在來運作。然而,它們很容易出現錯誤檢測(例如來自烤麵包機)並且不能很好地定位火災。在這些情況下,攝影機解決方案可以補充傳統偵測器,以縮短反應時間或提供額外的指標,例如火災的大小和位置。確定火災的位置和性質後,可以進行自動幹預,例如透過灑水系統或無人機。數據還可以發送到消防部門,以提供原本不存在的態勢感知。我感興趣的具體位置是:廚房和客廳、車庫和附屬建築,以及可能已經存在火災但蔓延到所需區域(例如火坑)之外的區域。
有一些重大挑戰和懸而未決的問題:
- 對於快速邊緣模型,什麼是「最佳」架構? Yolo3 在商業應用中非常流行,可以在 keras 或 pytorch 中實現,基線 Yolov5,因為它目前是 SOTA,並且有 Jetson 的部署指南。
- 由於我們只檢測單一類別,是否可以優化架構?
- 基線物件偵測,但是分類器或分割有好處嗎? Obj 模型根據 mAP 和 Recall 指標進行訓練,但對於我們的應用程式來說,邊界框準確性可能不是首要任務?然而,分類模型在僅包含目標物件的漂亮鏡頭上效果最好,但在現實生活中的火災場景中,場景不會像這個場景那麼簡單。
- Tensorflow + 谷歌生態系統還是 Pytorch + NVIDIA/MS? Tensorflow 受到 tf1 遺留問題的影響
- 是單一「超級」模型較可取,還是多個專門模型較可取?典型的火災類別包括蠟燭火焰、室內/室外火災、車輛火災
- 收集或尋找全面、有代表性和平衡的訓練資料集
- 處理不同的視點、不同的相機製造商和設定以及不同的環境照明條件。
- 由於火焰非常明亮,常常會沖掉影像並造成其他光學幹擾,如何補償?
- 既然我們預期模型會有局限性,那麼我們如何讓模型結果具有可解釋性呢?
- 火災的大小範圍非常廣泛,從蠟燭火焰到吞噬整個森林 - 這是一個小物體和大物體的問題嗎?以火災類別和每個類別的訓練模型分割資料集可能會給出更好的結果?視為語義分割問題(需要重新註釋資料集)?
想法:
- 預處理影像,例如去除背景或應用濾鏡
- 對短視頻序列進行分類,因為火的運動非常有特徵
- 模擬數據,識別任何可以產生真實火災的軟體並添加到現有數據集
- 增強模擬不同相機和曝光設定的效果
- 確定有關火災偵測技術所需準確性的任何相關指南/立法
- 結合 RGB + 熱成像來抑制誤報?例如使用 https://openmv.io/blogs/news/introducing-the-openmv-cam-pure- Thermal 或更便宜的 grideye 或 melexsis
方法和工具
- 幀將透過神經網路饋送。在積極偵測到火災時提取指標。忽略煙霧以獲得 MVP。嘗試各種架構和參數來建立“良好”的基線模型。
- 開發針對 RPi 和行動裝置的精度較低但速度較快的模型,以及針對 Jetson 等 GPU 裝置的高精度模型。 Yolo 提供了兩個選項,用於行動裝置的 yolo4 lite 和 GPU 的 yolo5。或者還有 mobilenet 和 tf-object-detection-api。精度較高的 GPU 模型優先。
- 使用Google Colab進行訓練
文章和儲存庫
- Fire_Detection -> 使用 Jetson nano 和 Yolov5 以及來自 gettyimages 的圖像資料集的火災和煙霧偵測系統
- 使用 Roboflow 以及重量和偏差進行 YOLOv5 野火煙霧偵測
- Yolov5-Fire-Detection -> 在 Kaggle 資料上訓練的記錄良好的模型
- 使用Keras 進行火災和煙霧偵測以及pyimagesearch 的深度學習- 透過抓取Google 影像收集的資料集(提供包含1315 個火災影像的資料集的連結),使用tf2 和keras 順序CNN 進行二進制火災/非火災分類,達到92% 的準確度,得出結論:需要更好的數據集
- 使用 YOLOv3 從頭開始進行火災偵測 - 討論使用 LabelImg 進行註釋,使用 Google Drive 和 Colab,透過 Heroku 進行部署,並在此處使用 Streamlit 進行視覺化。德夫達爾尚‧米甚拉的作品
- fire-and-gun-detection -> 在影片和影像中使用 yolov3 進行火災和槍支偵測。提供訓練代碼、資料集和訓練權重檔案。
- YOLOv3-Cloud-Based-Fire-Detection -> 在雲端上使用 YOLOv3 自訂物件偵測。它經過訓練可以檢測給定幀中的火災。可大量用於野火、火災事故等。
- fire-detect-yolov4 -> Yolo v4 模型的訓練
- midasklr/FireSmokeDetectionByEfficientNet - 使用efficientnet進行火災和煙霧分類和檢測,Python 3.7、PyTorch1.3,可視化激活圖,包括訓練和推理腳本
- arpit-jadon/FireNet-LightWeight-Network-for-Fire-Detection - 用於即時物聯網應用(例如在 RPi 上)的專用輕量級火災和煙霧偵測模型,精度約為。 95%。論文 https://arxiv.org/abs/1905.11922v2
- tobybreckon/fire-detection-cnn - 連結到幾個資料集
- EmergencyNet - 透過無人機辨識火災和其他緊急情況
- 使用閉路電視影像進行火災偵測 — Monk 庫應用程式 - Kaggle 資料集、mobilenet-v2、densenet121 和 dendensenet201 上的 keras 分類器
- fire-detection-cnn - 在即時範圍內自動偵測視訊(或靜態)影像中的火災像素區域。全影像二值火災偵測 (1) 的最大精度為 0.93,在我們的超像素定位框架內可達到 0.89 的精度
- 使用深度學習和 OpenCV 的早期火災偵測系統 - 用於室內和室外火災偵測的客製化 InceptionV3 和 CNN 架構。 980 張影像用於訓練,239 張影像用於驗證,訓練準確度為98.04,驗證準確度為96.43,openCV 用於網路攝影機即時偵測- 程式碼和資料集(已在此處引用)位於https:// github.com/jackfrost1411/fire-檢測
- Smoke-Detection-using-Tensorflow 2.2 - EfficientDet-D0,Roboflow 部落格中提到的 733 個註釋的煙霧影像
- 用於火災偵測的航空影像資料集:使用無人機 (UAV) 進行分類和分割 - 二元分類器,測試集的準確度為 76%
- 基於整合學習的森林火災偵測系統 -> 首先,整合兩個個體學習器 Yolov5 和 EfficientDet 來完成火災偵測過程。其次,另一個個體學習器EfficientNet負責學習全局資訊以避免誤報
- GradCAM 解釋的具有多標籤分類模型的火災警報系統 -> 使用 CAM 可視化圖像的哪個區域負責預測,並使用合成資料來填充缺少的類別以使類別分佈平衡
- 訓練 fast.ai 模型並透過 gradio 應用程式進行部署
- Deepfire -> 使用ResNet50和EfficientNetB7對無人機進行森林火災識別
- Wildfire-Smoke-Detection -> 基於 Faster-RCNN 架構的用於野火煙霧偵測的捲積神經網路模型
- FireNet-LightWeight-Network-for-Fire-Detection -> 採用 ArXiv 論文的即時物聯網應用的專用輕量級火災和煙霧偵測模型
- 野火煙霧偵測研究 -> 早期野火煙霧偵測,附紙質
數據集
- FireNET - 約。 500 張邊界框的火焰影像,採用 pascal voc XML 格式。 Repo 包含使用 imageai 訓練的 Yolo3 模型,表現未知。然而,影像很小,平均為 275x183 像素,這意味著網路需要學習的紋理特徵較少。
- Kaggle 上的 CCTV 火災偵測 - 影像和視頻,影像是從影片中提取的,資料集相對較小,所有影像僅取自 3-4 個影片。與當前任務非常相關,因為有影片可供測試。為正常/煙霧/火災分類任務組織的資料集,無邊界框註釋
- cair/Fire-Detection-Image-Dataset - 此資料集包含許多正常影像和 111 張火災影像。資料集與現實世界的情況高度不平衡。圖像大小合適,但沒有註釋。
- mivia 火災偵測資料集 - 約。 30 個視頻
- USTC 煙霧偵測 - 提供煙霧影片的各種來源的鏈接
- 可以下載 pyimagesearch 文章中的 fire/not-fire 資料集。請注意,有許多火災場景的圖像並不包含實際的火災,而是例如被燒毀的房屋。
- Kaggle 上的火災資料集 - 755 個室外火災影像和 244 個非火災影像。圖像大小合適,但沒有註釋
- Dunnings 2018 年研究的火災影像資料集 - PNG 靜態影像集
- Samarth 2019 研究的火超像素影像資料集 - PNG 靜態影像集
- 野火煙霧資料集 - 737 張附註(邊框)影像
- jackfrost1411 的資料集 -> 將數百張影像分類為火/中性以進行分類任務。無邊界框註釋
- Kaggle 上的 fire-and-smoke-dataset -> 7000 多張圖像,其中包括 691 張僅火焰圖像、3721 張僅煙霧圖像和 4207 張火{火焰和煙霧}圖像
- 國內火災和煙霧資料集 -> 大約。 5000 張獨特圖像、2 類(火和煙)、邊界框註釋、COCO、PASCAL VOC 和 YOLO 格式
- Kaggle 火與槍資料集
- Wildfire-Detection -> PerceptiLabs 提供的資料集,描繪正常場景和包含火災的場景的 250x250 像素影像。與文章。這是kaggle的這個資料集
- DFireDataset -> 用於火災和煙霧偵測的影像資料集
消防安全參考
- 尋找涵蓋家庭中不同類型火災、常見場景和介入措施的參考資料
- 火災偵測器的安全/準確度標準,包括 ROC 特性
家裡發生火災
- 常見原因包括悶燒香菸、蠟燭、電力故障、炸鍋起火
- 有許多因素會影響火災的性質,主要是燃料和氧氣,還有火災的位置、房間的中間/靠牆、房間的熱容量、牆壁、環境溫度、濕度、污染物。潤膚劑等)
- 為了撲滅火災,可以考慮使用多種阻燃劑 - 水(不要使用電氣或晶片盤)、泡沫、二氧化碳、乾粉
- 發生電氣火災時,首先應隔離電源
- 減少通風(例如關閉)將限制火災
- 煙霧本身就是火災性質的強大指標
- 閱讀 https://en.m.wikipedia.org/wiki/Fire_triangle 和 https://en.m.wikipedia.org/wiki/Combustion
邊緣部署
我們部署到邊緣設備(RPi、jetson nano、android 或 ios)的最終目標將影響架構和其他權衡的決策。
- 以 30 FPS 將 YOLOv5 部署到 Jetson Xavier NX - 以 30 FPS 進行推理
- 如何在自訂資料集上訓練 YOLOv5
- 在自訂資料上訓練 YOLOv4-tiny - 閃電般快速的物體偵測
- 如何訓練自訂 TensorFlow Lite 物件偵測模型 - colab 筆記本、MobileNetSSDv2、部署到 RPi
- 如何使用 YOLOv4 Tiny 和 TensorFlow Lite 訓練自訂行動物件偵測模型 - 訓練 YOLOv4 tiny Darknet 並轉換為 tflite,在 Android 上進行演示,比直接訓練 tflite 更多步驟
- AG 人工智慧:農業生產機器學習 - 從培訓到部署的完整工作流程
- Pytorch 現在正式支援 RPi https://pytorch.org/blog/prototype-features-now-available-apis-for-hardware-accelerated-mobile-and-arm64-builds/
- Hermes 是一種野火偵測系統,利用電腦視覺並使用 NVIDIA Deepstream 進行加速
雲端部署
我們想要一個也可以部署到雲端的解決方案,與邊緣部署相比,只需進行最少的變更。有幾個選項:
- 作為 lambda 函數部署 - 根據我的經驗,響應時間很長,長達 45 秒
- 使用自訂程式碼在虛擬機器上部署以處理請求排隊
- 在 sagemaker 上使用 torchserve,在 EC2 執行個體上執行。有據可查,但 AWS 特定。
- 使用雲端供應商之一,例如 AWS Rekognition 將識別火災
影像預處理和增強
除了基本裁剪之外,Roboflow 還允許每個資料集最多 3 種類型的增強。如果我們想嘗試更多增強功能,可以查看 https://imgaug.readthedocs.io/en/latest/
- 為什麼影像預處理和增強很重要
- 模糊作為影像增強技術的重要性
- 何時使用對比作為預處理步驟
- YOLOv4 中的資料增強
- 為什麼要為機器學習的影像添加噪聲
- 為什麼以及如何實施隨機作物資料增強
- 何時使用灰階作為預處理步驟
機器學習指標
Precision是預測的準確性,計算公式為precision = TP/(TP+FP)或“預測正確的百分比是多少?”-
Recall是真陽性率(TPR),計算公式為recall = TP/(TP+FN)或“模型捕獲的真陽性百分比是多少?” -
F1 score (也稱為 F 分數或 F 測量)是精確度和召回率的調和平均值,計算公式為F1 = 2*(precision * recall)/(precision + recall) 。它傳達了精確度和召回率之間的平衡。參考號 - 誤報率(FPR)(計算公式為
FPR = FP/(FP+TN)通常在 ROC 曲線中針對召回率/TPR 進行繪製,該曲線顯示了 TPR/FPR 權衡如何隨分類閾值變化。降低分類閾值會回傳更多真陽性,但也會回傳更多假陽性 - mAP、IoU、精度和召回率在這裡和這裡都有很好的解釋
- IceVision 返回 COCOMetric,特別是
AP at IoU=.50:.05:.95 (primary challenge metric) ,從這裡開始,通常稱為「平均精度」(mAP) -
[email protected] :考慮所有標籤的每個標籤的平均精確度或正確性。 @0.5設定預測邊界框與原始註釋重疊的閾值,即“50%重疊”
評論
- Firenet 是一個非常常見的模型名稱,請勿使用
討論
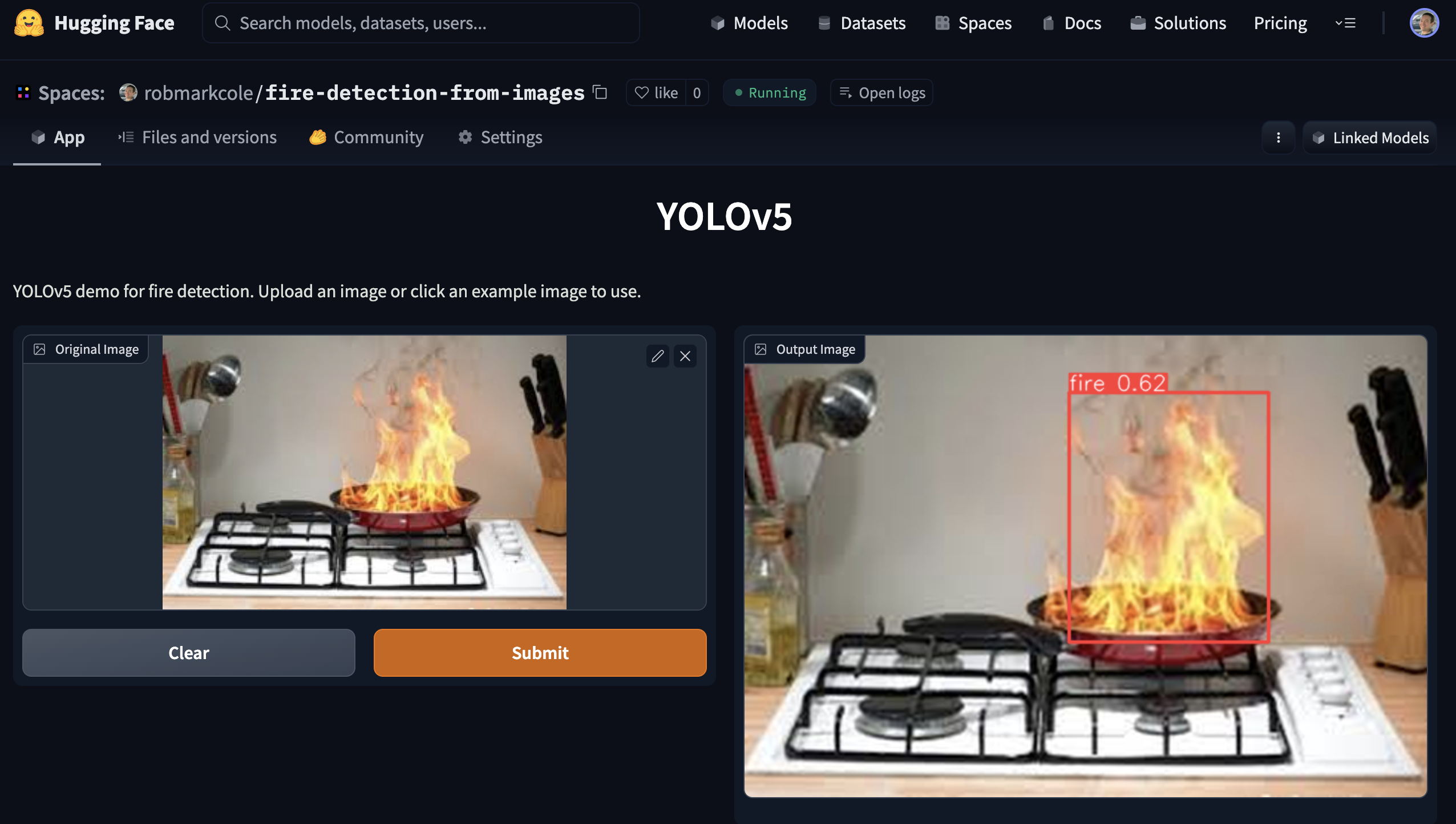
示範
可以透過運行使用 Gradio 創建的演示應用程式來使用性能最佳的模型。查看demo目錄