test arranger
v1.6.3
TDD 中有 3 個階段:安排、行動和斷言(BDD 中為given、when、then)。斷言階段有很好的工具支持,您可能熟悉 AssertJ、FEST-Assert 或 Hamcrest。它與排列階段相反。雖然安排測試資料通常具有挑戰性,而且測試的重要部分通常專門用於它,但很難指出支援它的工具。
測試安排器試圖透過安排測試所需的類別實例來填補這一空白。這些實例填充了偽隨機值,簡化了測試資料創建的過程。測試人員僅聲明所需物件的類型並取得全新的實例。當給定字段的偽隨機值不夠好時,只需手動設定該字段:
Product product = Arranger . some ( Product . class );
product . setBrand ( "Ocado" );< dependency >
< groupId >com.ocadotechnology.gembus</ groupId >
< artifactId >test-arranger</ artifactId >
< version >1.6.3</ version >
</ dependency >testImplementation ' com.ocadotechnology.gembus:test-arranger:1.6.3 ' Arranger 類別有幾個靜態方法用於產生簡單類型的偽隨機值。它們每個都有一個包裝函數,以使 Kotlin 的呼叫更簡單。下面列出了一些可能的呼叫:
| 爪哇 | 科特林 | 結果 |
|---|---|---|
Arranger.some(Product.class) | some<Product>() | 所有欄位都填入了值的 Product 實例 |
Arranger.some(Product.class, "brand") | some<Product>("brand") | 對品牌領域沒有價值的產品實例 |
Arranger.someSimplified(Category.class) | someSimplified<Category>() | 類別的實例,集合類型的欄位大小減少到 1,物件樹的深度限制為 3 |
Arranger.someObjects(Product.class, 7) | someObjects<Product>(7) | Product 實例大小為 7 的流 |
Arranger.someEmail() | someEmail() | 包含電子郵件地址的字串 |
Arranger.someLong() | someLong() | long 類型的偽隨機數 |
Arranger.someFrom(listOfCategories) | someFrom(listOfCategories) | listOfCategories 中的條目 |
Arranger.someText() | someText() | 從馬可夫鏈產生的字串;預設情況下,它是一個非常簡單的鏈,但可以透過將其他「enMarkovChain」檔案放在具有替代定義的測試類路徑上來重新配置,您可以在這裡找到一個在英語語料庫上訓練的鏈;請參閱項目“enMarkovChain”文件中包含的文件格式 |
| - | some<Product> {name = "not so random"} | Product 的實例,其所有字段都填充了隨機值( name除外,名稱設置為“不太隨機”),此語法可用於根據需要設置對象的任意多個字段,但每個對像都必須是可變的 |
完全隨機的資料可能不適合每個測試案例。通常至少有一個欄位對於測試目標至關重要並且需要一定的值。當排列的類別是可變的,或者它是 Kotlin 資料類,或者有一種方法可以建立更改的副本(例如 Lombok 的 @Builder(toBuilder = true))時,則只需使用可用的類別。幸運的是,即使它不可調整,您也可以使用測試安排器。 some()和someObjects()方法有專用版本,它們接受Map<String,Supplier>類型的參數。此對應中的鍵代表欄位名稱,而對應的供應商提供測試安排器將為您在這些欄位上設定的值,例如:
Product product = Arranger . some ( Product . class , Map . of ( "name" , () -> value ));預設情況下,根據欄位類型產生隨機值。隨機值並不總是與類別不變量很好地對應。當一個實體總是需要根據一些有關欄位值的規則進行排列時,您可以提供自訂排列程序:
class ProductArranger extends CustomArranger < Product > {
@ Override
protected Product instance () {
Product product = enhancedRandom . nextObject ( Parent . class );
product . setPrice ( BigDecimal . valueOf ( Arranger . somePositiveLong ( 9_999L )));
return product ;
}
}為了控制實例化Product的過程,我們需要重寫instance()方法。在方法內部,我們可以根據需要建立Product實例。具體來說,我們可以產生一些隨機值。為了方便起見,我們在CustomArranger類別中有一個enhancedRandom字段。在給定的範例中,我們產生一個Product實例,其中所有欄位都具有偽隨機值,但隨後我們將價格變更為我們網域中可接受的價格。這不是負數並且小於 10k 數字。
ProductArranger會自動(使用反射)由 Arranger 拾取,並在請求新的Product實例時使用。它不僅考慮像Arranger.some(Product.class)這樣的直接調用,還考慮間接調用。假設有Shop類,其欄位products類型為List<Product> 。當呼叫Arranger.some(Shop.class)時,排列器將使用ProductArranger建立儲存在Shop.products中的所有產品。
測試安排器的行為可以使用屬性進行配置。如果您建立arranger.properties檔案並將其保存在類別路徑的根目錄中(通常是src/test/resources/目錄),它將被擷取並套用下列屬性:
arranger.root使用反射來拾取取自定義編曲器。所有擴充CustomArranger類別都被視為自訂編曲器。反射集中在某個包上,預設是com.ocado 。這不一定對您方便。但是,使用arranger.root=your_package可以將其變更為your_package 。嘗試讓套件盡可能具體,因為有一些通用的東西(例如,只是com ,它是許多庫中的根包)將導致掃描數百個類,這將花費大量時間。arranger.randomseed預設情況下,始終使用相同的種子來初始化底層偽隨機值產生器。因此,後續執行將產生相同的值。為了實現運行中的隨機性,即始終以其他隨機值開始,需要設定arranger.randomseed=true 。arranger.cache.enable排列隨機實例的過程需要一些時間。如果您建立大量實例並且不需要它們完全隨機,則啟用快取可能是一種可行的方法。啟用後,快取會儲存每個隨機實例的引用,並且在某個時刻測試安排程式會停止建立新實例,而是重複使用快取的實例。預設情況下,快取是禁用的。arranger.overridedefaults Test-arranger 遵循預設欄位初始化,即當存在以空字串初始化的欄位時,test-arranger 傳回的實例在該欄位中具有空字串。並不總是您在測試中需要的,特別是當專案中有一個約定用空值初始化欄位時。幸運的是,您可以強制測試安排程序以隨機值覆寫預設值。將arranger.overridedefaults設為 true 以覆蓋預設初始化。arranger.maxRandomizationDepth一些測試資料結構可以產生任意長度的相互引用的物件鏈。然而,為了在測試案例中有效地使用它們,控制這些鏈的長度至關重要。預設情況下,Test-arranger 在嵌套深度的第 4 層停止建立新物件。如果此預設設定不適合您的專案測試案例,可以使用此參數進行調整。當您有一條可用作測試資料的 Java 記錄,但需要更改其一兩個欄位時, Data類別及其複製方法提供了一種解決方案。當處理沒有明顯方法直接更改其欄位的不可變記錄時,這特別有用。
Data.copy方法可讓您建立記錄的淺表副本,同時選擇性地修改所需欄位。透過提供欄位覆蓋的映射,您可以指定需要變更的欄位及其新值。複製方法負責使用更新的欄位值建立記錄的新實例。
這種方法使您無需手動建立新記錄物件並單獨設定字段,從而提供了一種便捷的方法來產生與現有記錄略有不同的測試資料。
總體而言,Data 類別及其複製方法透過啟用更改選定欄位的記錄的淺表副本來挽救這種情況,從而在使用不可變記錄類型時提供靈活性和便利性:
Data . copy ( myRecord , Map . of ( "recordFieldName" , () -> "altered value" ));當對軟體專案進行測試時,人們很少會有這樣的印象:它不能做得更好。在安排測試資料的範圍內,我們正在嘗試使用 Test Arranger 來改進兩個面向。
當了解創建者的意圖時,測試就更容易理解,即為什麼編寫測試以及應該檢測什麼類型的問題。不幸的是,在安排(給定)部分中看到測試具有如下所示的語句並不奇怪:
Product product = Product . builder ()
. withName ( "Some name" )
. withBrand ( "Some brand" )
. withPrice ( new BigDecimal ( "12.99" ))
. withCategory ( "Water, Juice & Drinks / Juice / Fresh" )
...
. build ();在查看此類程式碼時,很難說哪些值與測試相關,哪些值只是為了滿足某些非空要求而提供的。如果測驗是關於品牌的,為什麼不這樣寫:
Product product = Arranger . some ( Product . class );
product . setBrand ( "Some brand" );現在很明顯品牌的重要性。讓我們嘗試更進一步。整個測試可能如下所示:
//arrange
Product product = Arranger . some ( Product . class );
product . setBrand ( "Some brand" );
//act
Report actualReport = sut . createBrandReport ( Collections . singletonList ( product ))
//assert
assertThat ( actualReport . getBrand ). isEqualTo ( "Some brand" ) 我們現在正在測試該報告是否是為「Some Brand」品牌創建的。但這是目標嗎?期望為指定產品所分配的同一品牌產生報告更有意義。所以我們要測試的是:
//arrange
Product product = Arranger . some ( Product . class );
//act
Report actualReport = sut . createBrandReport ( Collections . singletonList ( product ))
//assert
assertThat ( actualReport . getBrand ). isEqualTo ( product . getBrand ()) 如果品牌欄位是可變的,並且我們擔心sut可能會修改它,我們可以在進入行動階段之前將其值儲存在變數中,然後將其用於斷言。測試時間會更長,但意圖仍然明確。
值得注意的是,我們剛剛所做的是生成值的應用,並且在某種程度上是 Gerard Meszaros 的xUnit 測試模式:重構測試程式碼中描述的創建方法模式。
您是否曾經更改過生產程式碼中的一小部分並最終在數十次測試中出現錯誤?其中一些報告斷言失敗,有些甚至可能拒絕編譯。這是一種獵槍手術代碼的味道,只是向你無辜的測試射擊。好吧,也許不那麼無辜,因為它們可以進行不同的設計,以限制微小變化造成的附帶損害。我們用一個例子來分析一下。假設我們的域中有以下類別:
class TimeRange {
private LocalDateTime start ;
private long durationinMs ;
public TimeRange ( LocalDateTime start , long durationInMs ) {
...並且它被用在很多地方。特別是在沒有 Test Arranger 的測試中,使用以下語句: new TimeRange(LocalDateTime.now(), 3600_000L);如果我們因為某些重要原因被迫將課程改為:
class TimeRange {
private LocalDateTime start ;
private LocalDateTime end ;
public TimeRange ( LocalDateTime start , LocalDateTime end ) {
...在不破壞所有相關測試的情況下提出一系列將舊版本轉換為新版本的重構是相當具有挑戰性的。更有可能的情況是測試被一一調整到類別的新API。這意味著很多並不令人興奮的工作,涉及許多關於所需的持續時間值的問題(我是否應該小心地將其轉換為 LocalDateTime 類型的end ,或者它只是一個方便的隨機值)。有了 Test Arranger,生活會變得更加輕鬆。當在所有需要不為 null TimeRange地方時,我們都有Arranger.some(TimeRange.class) ,它對於新版本的TimeRange和舊版本的一樣好。這給我們留下了少數不需要隨機TimeRange情況,但由於我們已經使用 Test Arranger 來揭示測試意圖,因此在每種情況下我們都確切地知道TimeRange應該使用什麼值。
但是,這並不是我們為改進測試所能做的一切。據推測,我們可以識別TimeRange實例的某些類別,例如過去的範圍、未來的範圍和目前活動的範圍。 TimeRangeArranger是安排以下內容的好地方:
class TimeRangeArranger extends CustomArranger < TimeRange > {
private final long MAX_DISTANCE = 999_999L ;
@ Override
protected TimeRange instance () {
LocalDateTime start = enhancedRandom . nextObject ( LocalDateTime . class );
LocalDateTime end = start . plusHours ( Arranger . somePositiveLong ( MAX_DISTANCE ));
return new TimeRange ( start , end );
}
public TimeRange fromPast () {
LocalDateTime now = LocalDateTime . now ();
LocalDateTime end = now . minusHours ( Arranger . somePositiveLong ( MAX_DISTANCE ));
return new TimeRange ( end . minusHours ( Arranger . somePositiveLong ( MAX_DISTANCE )), end );
}
public TimeRange fromFuture () {
LocalDateTime now = LocalDateTime . now ();
LocalDateTime start = now . plusHours ( Arranger . somePositiveLong ( MAX_DISTANCE ));
return new TimeRange ( start , start . plusHours ( Arranger . somePositiveLong ( MAX_DISTANCE )));
}
public TimeRange currentlyActive () {
LocalDateTime now = LocalDateTime . now ();
LocalDateTime start = now . minusHours ( Arranger . somePositiveLong ( MAX_DISTANCE ));
LocalDateTime end = now . plusHours ( Arranger . somePositiveLong ( MAX_DISTANCE ));
return new TimeRange ( start , end );
}
}這樣的創建方法不應該預先創建,而應該與現有的測試案例相對應。儘管如此, TimeRangeArranger有可能涵蓋為測試建立TimeRange實例的所有情況。因此,我們用一個命名良好的方法來代替帶有幾個神秘參數的構造函數調用,該方法解釋了所創建對象的域含義並幫助理解測試意圖。
在討論測試安排器解決的挑戰時,我們確定了兩個層級的測試資料創建者。為了讓圖片更完整,我們至少還需要提及一個,那就是燈具。為了方便討論,我們可以假設 Fixture 是一個旨在創建複雜的測試資料結構的類別。自訂編排器始終專注於一個類,但有時您可以在測試案例中觀察到兩個或多個類別的重複出現。這可能是用戶和他或她的銀行帳戶。他們每個人可能都有一個 CustomArranger,但為什麼要忽略他們經常聚集在一起的事實呢?這就是我們應該開始考慮夾具的時候。它將負責建立使用者和銀行帳戶(可能使用專用的自訂安排程式)並將它們連結在一起。詳細描述了這些 Fixtures,包括 Gerard Meszaros 的xUnit 測試模式:重構測試程式碼中的幾個實作變體。
因此,我們在測試類別中擁有三種類型的構建塊。它們中的每一個都可以被認為是生產程式碼中的概念(領域驅動設計建構塊)的對應部分: 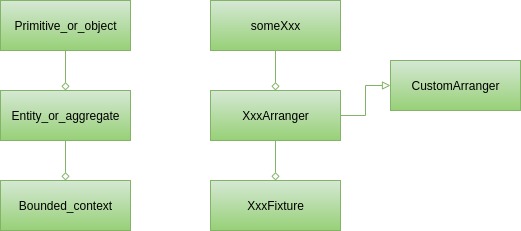
從表面上看,有原始的和簡單的物件。即使在最簡單的單元測試中也會出現這種情況。您可以使用Arranger類別中的someXxx方法來排列此類測試資料。
因此,您可能擁有需要僅對User實例或User和User類別中包含的其他類別(如地址清單)進行測試的服務。為了涵蓋這種情況,通常需要一個自訂編排器,即UserArranger 。它將創建一個尊重所有約束和類別不變量的User實例。此外,它會選取AddressArranger (如果存在),以有效資料填入位址清單。當多個測試案例需要某種類型的用戶時,例如地址清單為空的無家可歸的用戶,可以在 UserArranger 中建立一個附加方法。因此,每當需要為測試建立User實例時,只需查看UserArranger並選擇適當的工廠方法或僅呼叫Arranger.some(User.class)就足夠了。
最具挑戰性的情況是依賴大型資料結構的測試。在電子商務中,這可能是包含許多產品的商店,也可能是具有購物歷史記錄的使用者帳戶。為此類測試案例安排資料通常並不簡單,重複這樣的事情並不明智。最好將其儲存在名稱良好的方法下的專用類別中,例如shopWithNineProductsAndFourCustomers ,並在每個測試中重複使用。我們強烈建議對此類類別使用命名約定,為了使它們易於查找,我們的建議是使用Fixture postfix。最終,我們可能會得到這樣的結果:
class ShopFixture {
Repository repo ;
public void shopWithNineProductsAndFourCustomers () {
Arranger . someObjects ( Product . class , 9 )
. forEach ( p -> repo . save ( p ));
Arranger . someObjects ( Customer . class , 4 )
. forEach ( p -> repo . save ( p ));
}
}最新的測試安排器版本是使用 Java 17 編譯的,應該在 Java 17+ 運行時中使用。然而,還有一個用於向後相容的 Java 8 分支,包含在 1.4.x 版本中。


