SadTalker
v0.0.2 rc Release Note


TL;DR:單一肖像影像? = 頭部說話影片?
許可證已更新至Apache 2.0,我們已取消非商業限制
SadTalker現已正式整合到Discord中,您可以透過發送文件來免費使用它。您還可以根據文字提示產生高品質影片。加入:
我們發布了 stable-diffusion-webui 擴充功能。在這裡查看更多詳細資訊。示範影片
全影像模式現已推出!更多詳情...
| v0.0.1 中仍然+增強器 | v0.0.2 中仍然+增強器 | 輸入影像@bagbag1815 |
|---|---|---|
still_e_n.mp4 | full_body_2.bus_chinese_enhanced.mp4 |  |
現已推出多種新模式(靜止、參考和調整大小模式)!
我們很高興在 bilibili、YouTube 和 X (#sadtalker) 上看到更多社群示範。
之前的變更日誌可以在這裡找到。
[2023.06.12] : 在WebUI擴充功能中新增了更多新功能,請參閱此處的討論。
[2023.06.05] : 發布了新的512x512px(測試版)臉部模型。修復了一些錯誤並提高了效能。
[2023.04.15] :新增了 @camenduru 的 WebUI Colab 筆記本:
[2023.04.12] :新增了更詳細的WebUI安裝文件並修復了重新安裝時的問題。
[2023.04.12] : 修正了第三方套件導致的 WebUI 安全性問題,並最佳化了sd-webui-extension中的輸出路徑。
[2023.04.08] :在 v0.0.2 中,我們在生成的影片中加入了標誌浮水印以防止濫用。此浮水印已在後續版本中刪除。
[2023.04.08] : 在 v0.0.2 中,我們新增了完整影像動畫的功能以及從百度下載檢查點的連結。我們也優化了增強器邏輯。
我們正在追蹤第 280 期的新更新。
如果您有任何問題,請在提出問題之前閱讀我們的常見問題。
社群教學:中文Windows教學(中文Windows教學)| 日本語コーsu(日文教學)。
安裝 Anaconda、Python 和git 。
創建環境並安裝需求。
git clone https://github.com/OpenTalker/SadTalker.git
cd SadTalker
conda create -n sadtalker python=3.8
conda activate sadtalker
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu113
conda install ffmpeg
pip install -r requirements.txt
# ## Coqui TTS is optional for gradio demo.
# ## pip install TTS
此處提供中文影片教學。您也可以按照以下說明操作:
scoop install git 。ffmpeg : scoop install ffmpeg 。git clone https://github.com/Winfredy/SadTalker.git下載 SadTalker 儲存庫。start.bat ,並且將啟動 Gradio 驅動的 WebUI 演示。可以在此處找到有關在 macOS 上安裝 SadTalker 的教學課程。
請在此處查看其他教學。
您可以在Linux/macOS上執行以下腳本來自動下載所有模型:
bash scripts/download_models.sh我們還提供了離線補丁( gfpgan/ ),因此生成時不會下載任何模型。
sadt )sadt )模型解釋:
| 模型 | 描述 |
|---|---|
| 檢查點/mapping_00229-model.pth.tar | 在 Sadtalker 中預先訓練的 MappingNet。 |
| 檢查點/mapping_00109-model.pth.tar | 在 Sadtalker 中預先訓練的 MappingNet。 |
| 檢查點/SadTalker_V0.0.2_256.safetensors | 打包舊版的sadtalker檢查點,256張臉渲染)。 |
| 檢查點/SadTalker_V0.0.2_512.safetensors | 打包舊版的sadtalker檢查點,512面渲染)。 |
| GFPGAN/權重 | facexlib和gfpgan中使用的人臉偵測和增強模型。 |
| 模型 | 描述 |
|---|---|
| 檢查點/auido2exp_00300-model.pth | 在 Sadtalker 中預先訓練的 ExpNet。 |
| 檢查點/auido2pose_00140-model.pth | 在 Sadtalker 中預先訓練的 PoseVAE。 |
| 檢查點/mapping_00229-model.pth.tar | 在 Sadtalker 中預先訓練的 MappingNet。 |
| 檢查點/mapping_00109-model.pth.tar | 在 Sadtalker 中預先訓練的 MappingNet。 |
| 檢查點/facevid2vid_00189-model.pth.tar | 來自face-vid2vid再現的預訓練face-vid2vid模型。 |
| 檢查點/epoch_20.pth | Deep3DFaceReconstruction 中預先訓練的 3DMM 提取器。 |
| 檢查點/wav2lip.pth | Wav2lip 中的高精度唇形同步模型。 |
| 檢查點/shape_predictor_68_face_landmarks.dat | dilb中使用的人臉地標模型。 |
| 檢查站/BFM | 3DMM 庫文件。 |
| 檢查站/樞紐 | 用於人臉對齊的人臉偵測模型。 |
| GFPGAN/權重 | facexlib和gfpgan中使用的人臉偵測和增強模型。 |
最終資料夾將顯示為:
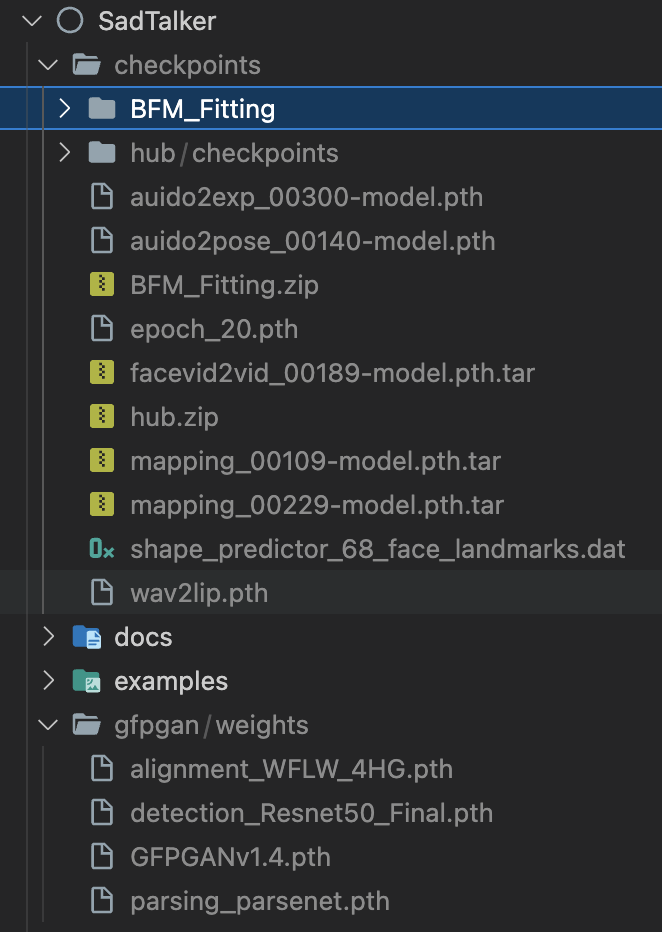
請閱讀我們有關最佳實踐和配置提示的文檔
線上示範:HuggingFace | SDWebUI-Colab |科拉布
本機 WebUI 擴充功能:請參閱 WebUI 文件。
本地漸變演示(建議) :類似於我們的 Hugging Face 演示的 Gradio 實例可以在本地運行:
# # you need manually install TTS(https://github.com/coqui-ai/TTS) via `pip install tts` in advanced.
python app_sadtalker.py您還可以更輕鬆地啟動它:
webui.bat ,需求就會自動安裝。bash webui.sh啟動 webui。python inference.py --driven_audio < audio.wav >
--source_image < video.mp4 or picture.png >
--enhancer gfpgan 結果將保存在results/$SOME_TIMESTAMP/*.mp4中。
使用--still生成自然的全身視訊。您可以添加enhancer來提高生成影片的品質。
python inference.py --driven_audio < audio.wav >
--source_image < video.mp4 or picture.png >
--result_dir < a file to store results >
--still
--preprocess full
--enhancer gfpgan 更多範例、配置和技巧可以在>>>最佳實踐文件<<<中找到。
如果您發現我們的工作對您的研究有用,請考慮引用:
@article { zhang2022sadtalker ,
title = { SadTalker: Learning Realistic 3D Motion Coefficients for Stylized Audio-Driven Single Image Talking Face Animation } ,
author = { Zhang, Wenxuan and Cun, Xiaodong and Wang, Xuan and Zhang, Yong and Shen, Xi and Guo, Yu and Shan, Ying and Wang, Fei } ,
journal = { arXiv preprint arXiv:2211.12194 } ,
year = { 2022 }
}Facerender程式碼大量借鏡了zhanglonghao對face-vid2vid和PIRender的複製。我們感謝作者分享他們精彩的程式碼。在訓練過程中,我們也使用了 Deep3DFaceReconstruction 和 Wav2lip 的模型。我們感謝他們的出色工作。
我們也使用以下第三方函式庫:
這不是騰訊的官方產品。
1. Please carefully read and comply with the open-source license applicable to this code before using it.
2. Please carefully read and comply with the intellectual property declaration applicable to this code before using it.
3. This open-source code runs completely offline and does not collect any personal information or other data. If you use this code to provide services to end-users and collect related data, please take necessary compliance measures according to applicable laws and regulations (such as publishing privacy policies, adopting necessary data security strategies, etc.). If the collected data involves personal information, user consent must be obtained (if applicable). Any legal liabilities arising from this are unrelated to Tencent.
4. Without Tencent's written permission, you are not authorized to use the names or logos legally owned by Tencent, such as "Tencent." Otherwise, you may be liable for legal responsibilities.
5. This open-source code does not have the ability to directly provide services to end-users. If you need to use this code for further model training or demos, as part of your product to provide services to end-users, or for similar use, please comply with applicable laws and regulations for your product or service. Any legal liabilities arising from this are unrelated to Tencent.
6. It is prohibited to use this open-source code for activities that harm the legitimate rights and interests of others (including but not limited to fraud, deception, infringement of others' portrait rights, reputation rights, etc.), or other behaviors that violate applicable laws and regulations or go against social ethics and good customs (including providing incorrect or false information, spreading pornographic, terrorist, and violent information, etc.). Otherwise, you may be liable for legal responsibilities.
LOGO:顏色和字體建議:ChatGPT,標誌字體:Montserrat Alternates。
演示影像和音訊的所有版權均來自社群使用者或穩定擴散的生成。如果您想使用刪除它們,請隨時與我們聯繫。


