結合分類演算法來預測每場職業棒球比賽的獲勝者
凱爾·約翰遜
部落格文章:https://kylejohnson363.github.io/commerce_mlb_data
預測未來的能力,即使只比拋硬幣好一點點,也可能帶來巨大的利潤。如果沒有水晶球,我們能做的下一個最好的事情就是利用大型資料集的力量來找到隱藏的模式,這些模式可用於在進行大量預測時提供輕微的優勢。棒球非常適合這一點,因為幾乎所有發生的事情都是可以量化的,並且每場比賽都會重複數百次,而且每場比賽每年都會重複數千次。該計畫的目標是使用機器學習技術以比拉斯維加斯博彩公司更好的方式對美國職棒大聯盟比賽進行預測。如果 Vegas 也正確預測了 70% 的比賽,那麼即使能夠正確預測 70% 的比賽也是沒有用的;為了擁有一個有用的模型,我必須創建一個在與維加斯博彩公司對賭時持續賺錢的模型。
請參閱標題為「Summary_Start_Here」的筆記本,以了解該專案的詳細路線圖,以便充分了解流程。
此專案的資料來自 MLB Advanced Media 的 API、baseball-reference.com 和 sportsbookreviewonline.com,然後預處理為有用的形式。然後創建並優化了四個分類模型,然後使用投票程序做出最終預測。 
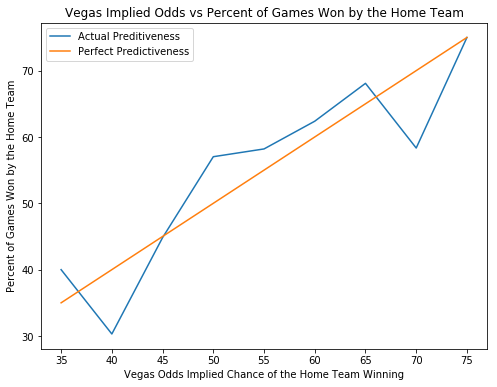
該專案的績效基準是維加斯賠率制定者做出的預測。如果創建的模型可以透過對賭拉斯維加斯賺錢,那麼我們就知道該模型具有附加價值。下面的圖表顯示了 Vegas 對預測的置信度與預測正確的時間百分比之間的關係。橙色和藍色的線條非常相關,這意味著維加斯非常擅長預測比賽,這是有道理的,因為否則它們很快就會破產。
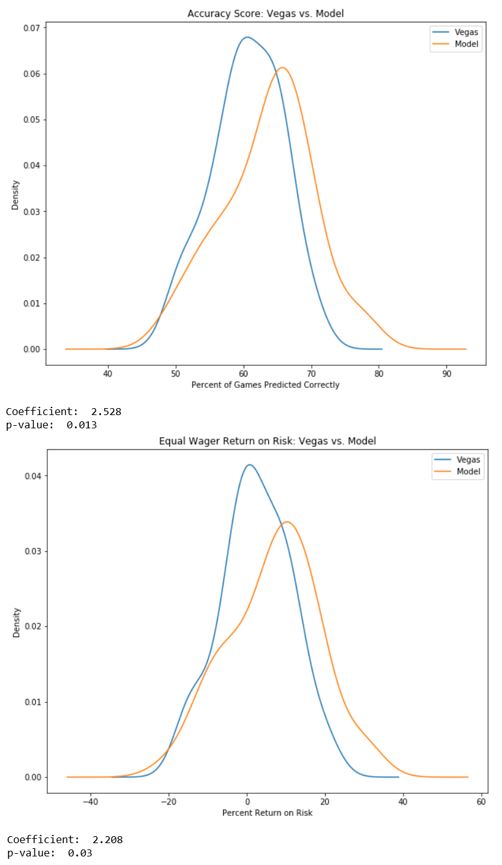
最終模型在選秀準確性和對預測比賽進行投注所產生的風險回報方面均優於維加斯賠率制定者,具有統計顯著性。
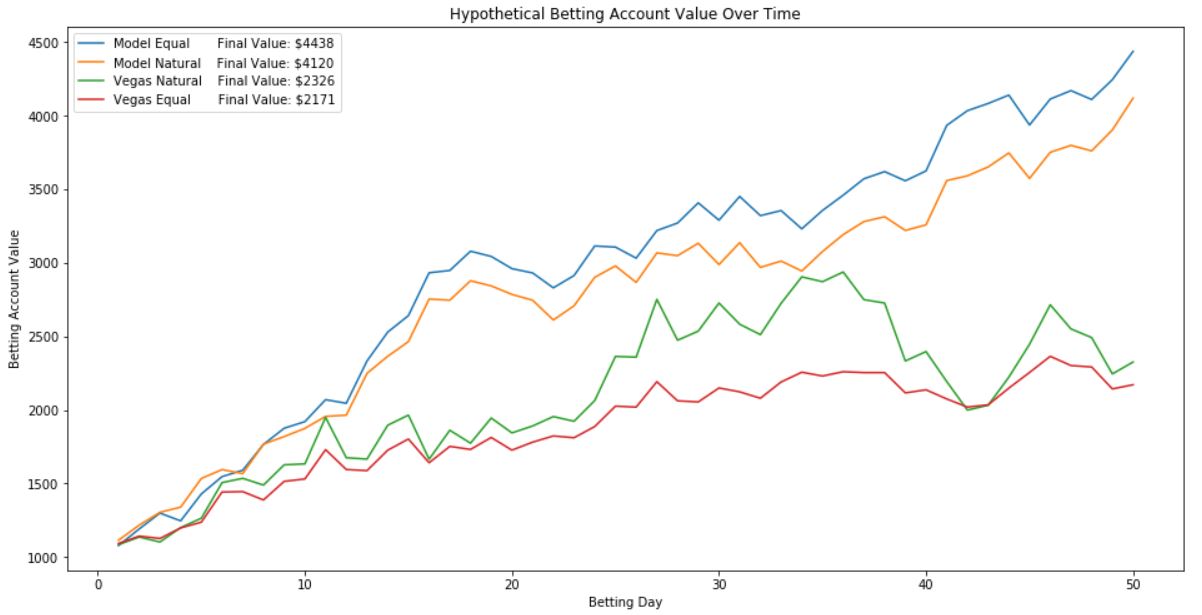
以下是從 1,000 美元開始的樣本外數據的模擬投注帳戶表現的可視化。
-我能夠創建一個模型,以統計上顯著的方式比維加斯賠率更準確地預測 MLB 比賽,並且更有利可圖。我透過查詢幾個線上棒球資料庫的數據,然後優化幾個不同的分類模型,然後將它們組合起來對每場比賽的結果進行投票來做到這一點。
- 奇怪的是,似乎總是以維加斯賠率下注是一種有利可圖的策略,但使用此項目中創建的模型可能會帶來幾乎兩倍的利潤。這告訴我們,Vegas 擅長預測 MLB 比賽,但仍有可利用的低效率問題。
使用更多類型的數據(新的和高度先進的統計數據)以及前幾個賽季的更多比賽。
優化“最近”類別統計天數。
自動收集當今比賽的必要數據並發布關於哪些比賽下注的報告。
建立“次要預測”,例如要評分或允許的運行,並將這些預測輸入到分類模型中。


