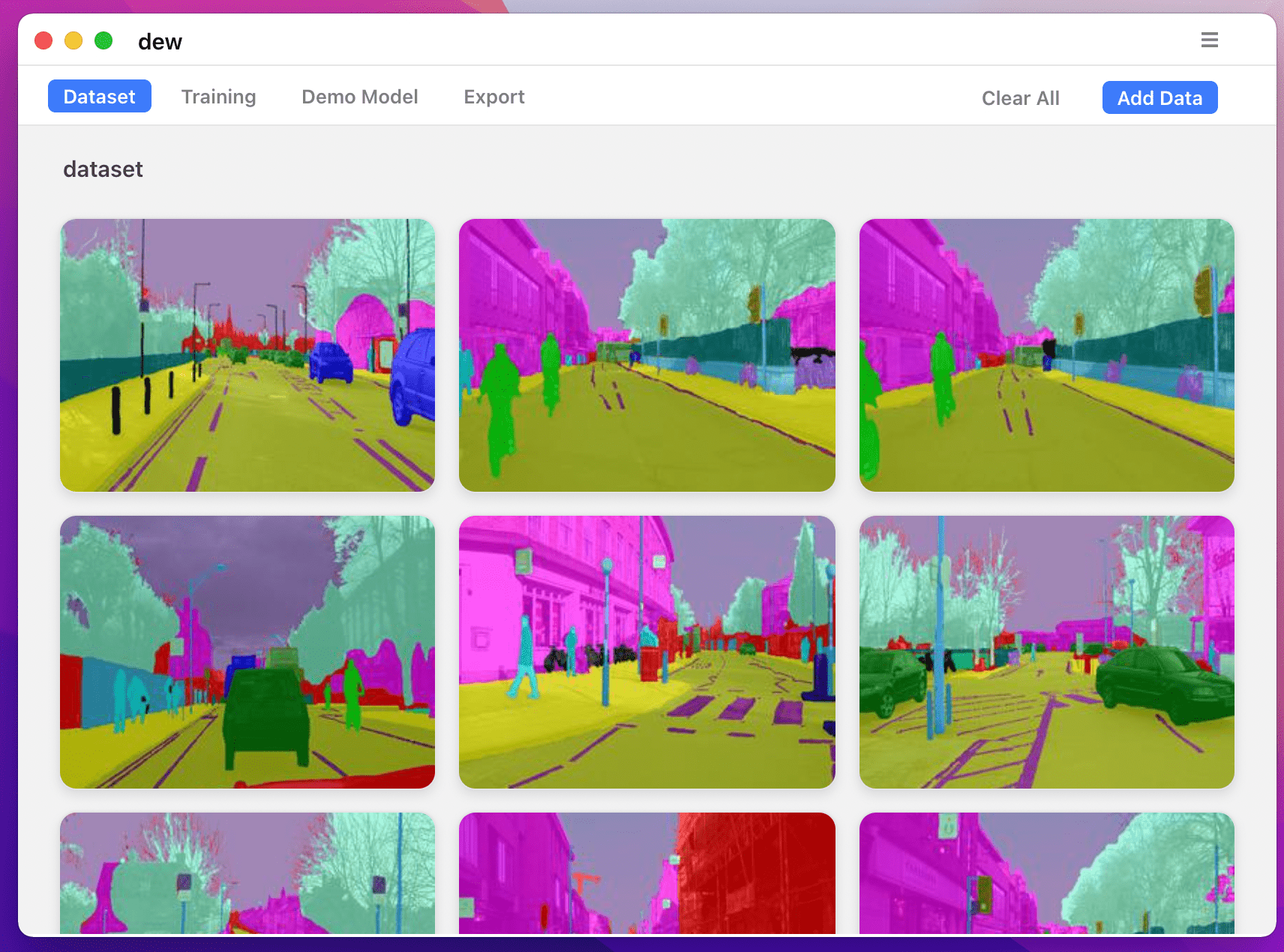
在 keras 中實現各種深度影像分割模型。
連結到完整的部落格文章和教學:https://divamgupta.com/image-segmentation/2019/06/06/deep-learning-semantic-segmentation-keras.html
您也可以使用 https://liner.ai 在電腦上訓練分割模型
| 火車 | 推理/導出 |
|---|---|
 |  |
 |  |
支援以下型號:
| 型號名稱 | 基本型號 | 細分模型 |
|---|---|---|
| fcn_8 | 一般美國有線電視新聞網 | FCN8 |
| fcn_32 | 一般美國有線電視新聞網 | FCN8 |
| fcn_8_vgg | VGG 16 | FCN8 |
| fcn_32_vgg | VGG 16 | FCN32 |
| fcn_8_resnet50 | RESNET-50 | FCN32 |
| fcn_32_resnet50 | RESNET-50 | FCN32 |
| fcn_8_mobilenet | 行動網路 | FCN32 |
| fcn_32_mobilenet | 行動網路 | FCN32 |
| 個人電腦網路 | 一般美國有線電視新聞網 | PSP網路 |
| pspnet_50 | 一般美國有線電視新聞網 | PSP網路 |
| pspnet_101 | 一般美國有線電視新聞網 | PSP網路 |
| vgg_pspnet | VGG 16 | PSP網路 |
| resnet50_pspnet | RESNET-50 | PSP網路 |
| unet_mini | 普通迷你 CNN | 優網 |
| 烏內特 | 一般美國有線電視新聞網 | 優網 |
| vgg_unet | VGG 16 | 優網 |
| resnet50_unet | RESNET-50 | 優網 |
| mobilenet_unet | 行動網路 | 優網 |
| 塞格內特 | 一般美國有線電視新聞網 | 塞格內特 |
| vgg_segnet | VGG 16 | 塞格內特 |
| resnet50_segnet | RESNET-50 | 塞格內特 |
| mobilenet_segnet | 行動網路 | 塞格內特 |
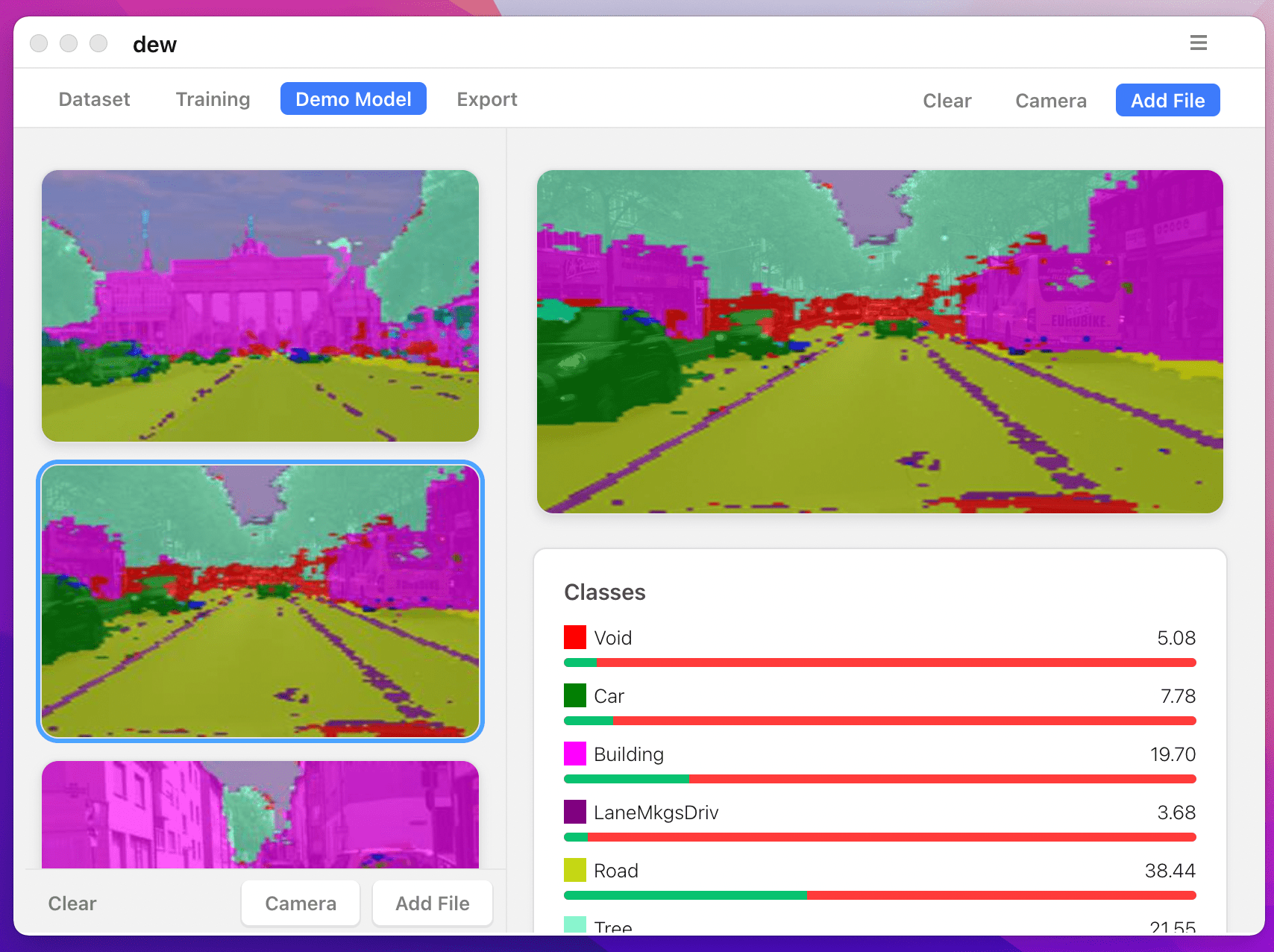
提供的預訓練模型的範例結果:
| 輸入影像 | 輸出分割影像 |
|---|---|
 |  |
 |  |
如果您正在使用該庫,請使用以下方式引用:
@article{gupta2023image,
title={Image segmentation keras: Implementation of segnet, fcn, unet, pspnet and other models in keras},
author={Gupta, Divam},
journal={arXiv preprint arXiv:2307.13215},
year={2023}
}
apt-get install -y libsm6 libxext6 libxrender-dev
pip install opencv-python安裝模組
推薦方式:
pip install --upgrade git+https://github.com/divamgupta/image-segmentation-keraspip install keras-segmentationgit clone https://github.com/divamgupta/image-segmentation-keras
cd image-segmentation-keras
python setup.py install from keras_segmentation . pretrained import pspnet_50_ADE_20K , pspnet_101_cityscapes , pspnet_101_voc12
model = pspnet_50_ADE_20K () # load the pretrained model trained on ADE20k dataset
model = pspnet_101_cityscapes () # load the pretrained model trained on Cityscapes dataset
model = pspnet_101_voc12 () # load the pretrained model trained on Pascal VOC 2012 dataset
# load any of the 3 pretrained models
out = model . predict_segmentation (
inp = "input_image.jpg" ,
out_fname = "out.png"
)您需要建立兩個資料夾
註釋影像的檔案名稱應與 RGB 影像的檔案名稱相同。
對應RGB影像的註解影像的大小應該相同。
對於 RGB 影像中的每個像素,註釋影像中該像素的類別標籤將是藍色像素的值。
產生註解圖像的範例程式碼:
import cv2
import numpy as np
ann_img = np . zeros (( 30 , 30 , 3 )). astype ( 'uint8' )
ann_img [ 3 , 4 ] = 1 # this would set the label of pixel 3,4 as 1
cv2 . imwrite ( "ann_1.png" , ann_img )註釋影像僅使用 bmp 或 png 格式。
下載並解壓縮以下內容:
https://drive.google.com/file/d/0B0d9ZiqAgFkiOHR1NTJhWVJMNEU/view?usp=sharing
您將得到一個名為 dataset1/ 的資料夾
您可以在 python 腳本中匯入 keras_segmentation 並使用 API
from keras_segmentation . models . unet import vgg_unet
model = vgg_unet ( n_classes = 51 , input_height = 416 , input_width = 608 )
model . train (
train_images = "dataset1/images_prepped_train/" ,
train_annotations = "dataset1/annotations_prepped_train/" ,
checkpoints_path = "/tmp/vgg_unet_1" , epochs = 5
)
out = model . predict_segmentation (
inp = "dataset1/images_prepped_test/0016E5_07965.png" ,
out_fname = "/tmp/out.png"
)
import matplotlib . pyplot as plt
plt . imshow ( out )
# evaluating the model
print ( model . evaluate_segmentation ( inp_images_dir = "dataset1/images_prepped_test/" , annotations_dir = "dataset1/annotations_prepped_test/" ) )您也可以僅使用命令列來使用該工具
您也可以視覺化準備的註釋以驗證已準備好的資料。
python -m keras_segmentation verify_dataset
--images_path= " dataset1/images_prepped_train/ "
--segs_path= " dataset1/annotations_prepped_train/ "
--n_classes=50python -m keras_segmentation visualize_dataset
--images_path= " dataset1/images_prepped_train/ "
--segs_path= " dataset1/annotations_prepped_train/ "
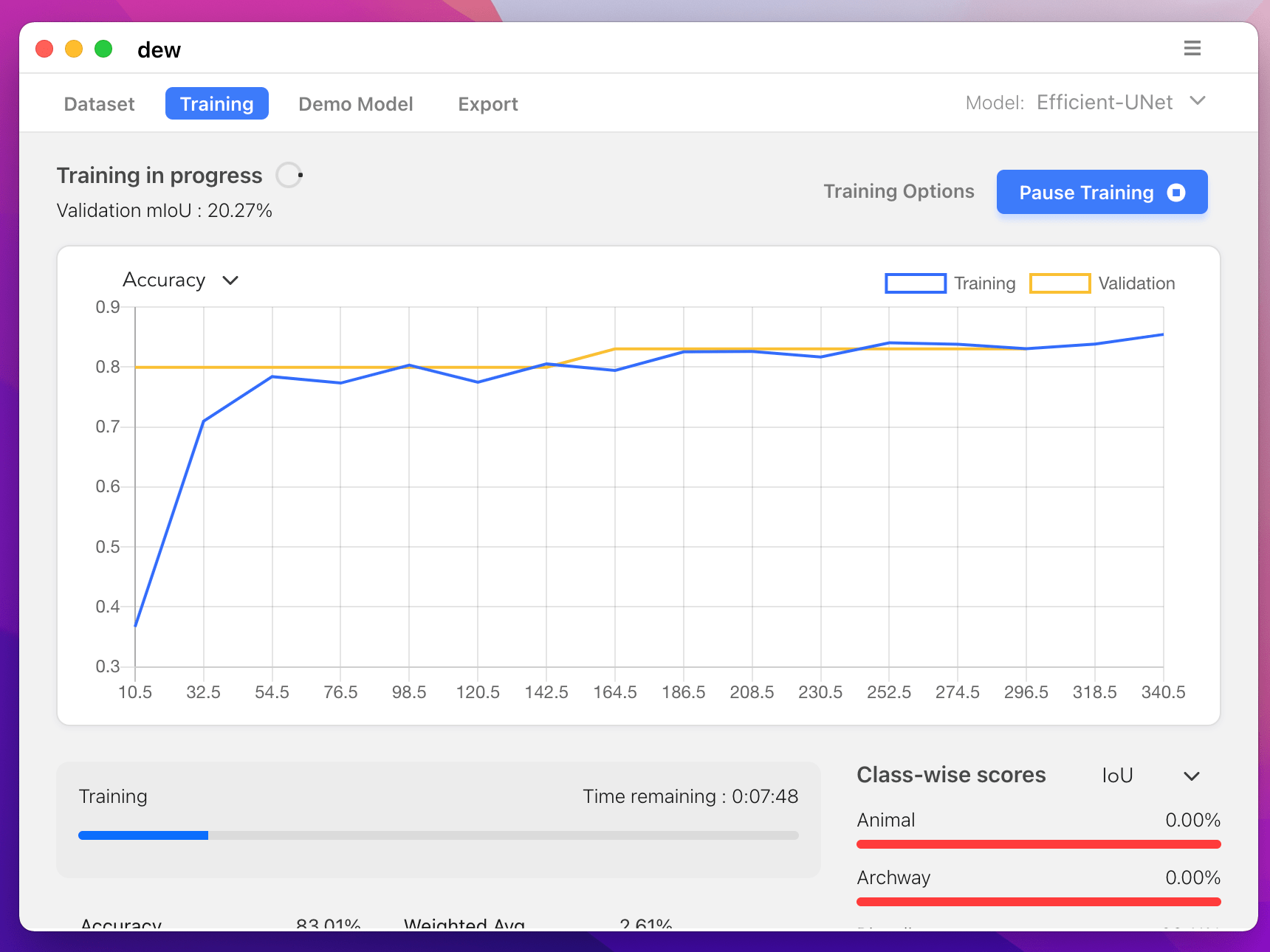
--n_classes=50要訓練模型,請執行以下命令:
python -m keras_segmentation train
--checkpoints_path= " path_to_checkpoints "
--train_images= " dataset1/images_prepped_train/ "
--train_annotations= " dataset1/annotations_prepped_train/ "
--val_images= " dataset1/images_prepped_test/ "
--val_annotations= " dataset1/annotations_prepped_test/ "
--n_classes=50
--input_height=320
--input_width=640
--model_name= " vgg_unet "從上表中選擇 model_name
獲得經過訓練的模型的預測
python -m keras_segmentation predict
--checkpoints_path= " path_to_checkpoints "
--input_path= " dataset1/images_prepped_test/ "
--output_path= " path_to_predictions "
取得影片的預測
python -m keras_segmentation predict_video
--checkpoints_path= " path_to_checkpoints "
--input= " path_to_video "
--output_file= " path_for_save_inferenced_video "
--display如果您想在網路攝影機上進行預測,請不要使用--input ,或傳遞您的裝置編號: --input 0
--display開啟一個包含預測影片的視窗。使用無頭系統時刪除此參數。
取得 IoU 分數
python -m keras_segmentation evaluate_model
--checkpoints_path= " path_to_checkpoints "
--images_path= " dataset1/images_prepped_test/ "
--segs_path= " dataset1/annotations_prepped_test/ " 以下範例展示如何微調具有 10 個類別的模型。
from keras_segmentation . models . model_utils import transfer_weights
from keras_segmentation . pretrained import pspnet_50_ADE_20K
from keras_segmentation . models . pspnet import pspnet_50
pretrained_model = pspnet_50_ADE_20K ()
new_model = pspnet_50 ( n_classes = 51 )
transfer_weights ( pretrained_model , new_model ) # transfer weights from pre-trained model to your model
new_model . train (
train_images = "dataset1/images_prepped_train/" ,
train_annotations = "dataset1/annotations_prepped_train/" ,
checkpoints_path = "/tmp/vgg_unet_1" , epochs = 5
)
以下範例顯示將知識從較大(且更準確)的模型轉移到較小的模型。在大多數情況下,透過知識蒸餾訓練的較小模型比使用普通監督學習訓練的相同模型更準確。
from keras_segmentation . predict import model_from_checkpoint_path
from keras_segmentation . models . unet import unet_mini
from keras_segmentation . model_compression import perform_distilation
model_large = model_from_checkpoint_path ( "/checkpoints/path/of/trained/model" )
model_small = unet_mini ( n_classes = 51 , input_height = 300 , input_width = 400 )
perform_distilation ( data_path = "/path/to/large_image_set/" , checkpoints_path = "path/to/save/checkpoints" ,
teacher_model = model_large , student_model = model_small , distilation_loss = 'kl' , feats_distilation_loss = 'pa' )以下範例展示如何定義用於訓練的自訂增強函數。
from keras_segmentation . models . unet import vgg_unet
from imgaug import augmenters as iaa
def custom_augmentation ():
return iaa . Sequential (
[
# apply the following augmenters to most images
iaa . Fliplr ( 0.5 ), # horizontally flip 50% of all images
iaa . Flipud ( 0.5 ), # horizontally flip 50% of all images
])
model = vgg_unet ( n_classes = 51 , input_height = 416 , input_width = 608 )
model . train (
train_images = "dataset1/images_prepped_train/" ,
train_annotations = "dataset1/annotations_prepped_train/" ,
checkpoints_path = "/tmp/vgg_unet_1" , epochs = 5 ,
do_augment = True , # enable augmentation
custom_augmentation = custom_augmentation # sets the augmention function to use
)以下範例顯示如何設定輸入頻道數。
from keras_segmentation . models . unet import vgg_unet
model = vgg_unet ( n_classes = 51 , input_height = 416 , input_width = 608 ,
channels = 1 # Sets the number of input channels
)
model . train (
train_images = "dataset1/images_prepped_train/" ,
train_annotations = "dataset1/annotations_prepped_train/" ,
checkpoints_path = "/tmp/vgg_unet_1" , epochs = 5 ,
read_image_type = 0 # Sets how opencv will read the images
# cv2.IMREAD_COLOR = 1 (rgb),
# cv2.IMREAD_GRAYSCALE = 0,
# cv2.IMREAD_UNCHANGED = -1 (4 channels like RGBA)
)以下範例展示如何設定自訂影像預處理函數。
from keras_segmentation . models . unet import vgg_unet
def image_preprocessing ( image ):
return image + 1
model = vgg_unet ( n_classes = 51 , input_height = 416 , input_width = 608 )
model . train (
train_images = "dataset1/images_prepped_train/" ,
train_annotations = "dataset1/annotations_prepped_train/" ,
checkpoints_path = "/tmp/vgg_unet_1" , epochs = 5 ,
preprocessing = image_preprocessing # Sets the preprocessing function
)以下範例展示如何為模型訓練設定自訂回調。
from keras_segmentation . models . unet import vgg_unet
from keras . callbacks import ModelCheckpoint , EarlyStopping
model = vgg_unet ( n_classes = 51 , input_height = 416 , input_width = 608 )
# When using custom callbacks, the default checkpoint saver is removed
callbacks = [
ModelCheckpoint (
filepath = "checkpoints/" + model . name + ".{epoch:05d}" ,
save_weights_only = True ,
verbose = True
),
EarlyStopping ()
]
model . train (
train_images = "dataset1/images_prepped_train/" ,
train_annotations = "dataset1/annotations_prepped_train/" ,
checkpoints_path = "/tmp/vgg_unet_1" , epochs = 5 ,
callbacks = callbacks
)以下範例示範如何為模型新增額外的影像輸入。
from keras_segmentation . models . unet import vgg_unet
model = vgg_unet ( n_classes = 51 , input_height = 416 , input_width = 608 )
model . train (
train_images = "dataset1/images_prepped_train/" ,
train_annotations = "dataset1/annotations_prepped_train/" ,
checkpoints_path = "/tmp/vgg_unet_1" , epochs = 5 ,
other_inputs_paths = [
"/path/to/other/directory"
],
# Ability to add preprocessing
preprocessing = [ lambda x : x + 1 , lambda x : x + 2 , lambda x : x + 3 ], # Different prepocessing for each input
# OR
preprocessing = lambda x : x + 1 , # Same preprocessing for each input
)以下是一些使用我們庫的項目:
如果您在公開專案中使用我們的程式碼,請在此處新增連結(透過發布問題或建立 PR )


