[論文] [專案頁] [miniFLUX 模型] [SD3 模型⚡️] [演示?
這是 Pyramid Flow 的官方儲存庫,Pyramid Flow 是一種基於串流匹配的訓練高效的自回歸影片生成方法。透過僅在開源資料集上進行訓練,它可以生成 768p 解析度和 24 FPS 的高品質 10 秒視頻,並且自然支援影像到影片的生成。
| 10 秒,768p,24fps | 5 秒、768p、24 幀/秒 | 影像到視頻 |
|---|---|---|
煙火.mp4 | 預告片.mp4 | 星期日.mp4 |
2024.11.13我們發布了768p miniFLUX檢查點(最長10秒)。
我們已將模型結構從 SD3 切換為 mini FLUX 以解決人體結構問題,請嘗試我們的 1024p 影像檢查點、384p 視訊檢查點(最多 5 秒)和 768p 視訊檢查點(最多 10 秒)。新的miniflux模型在人體結構和運動穩定性方面顯示出巨大的改進
2024.10.29 ⚡️⚡️⚡️ 我們發布了 VAE 的訓練代碼、DiT 的微調代碼以及從頭開始訓練的 FLUX 結構的新模型檢查點。
2024.10.13支援多GPU推理和CPU卸載。使用少於 8GB的 GPU 內存,在多個 GPU 上可大幅加速。
2024.10.11 ?擁抱臉部演示可用。感謝@multimodalart 的提交!
2024.10.10我們發布了Pyramid Flow的技術報告、專案頁面和模型檢查點。
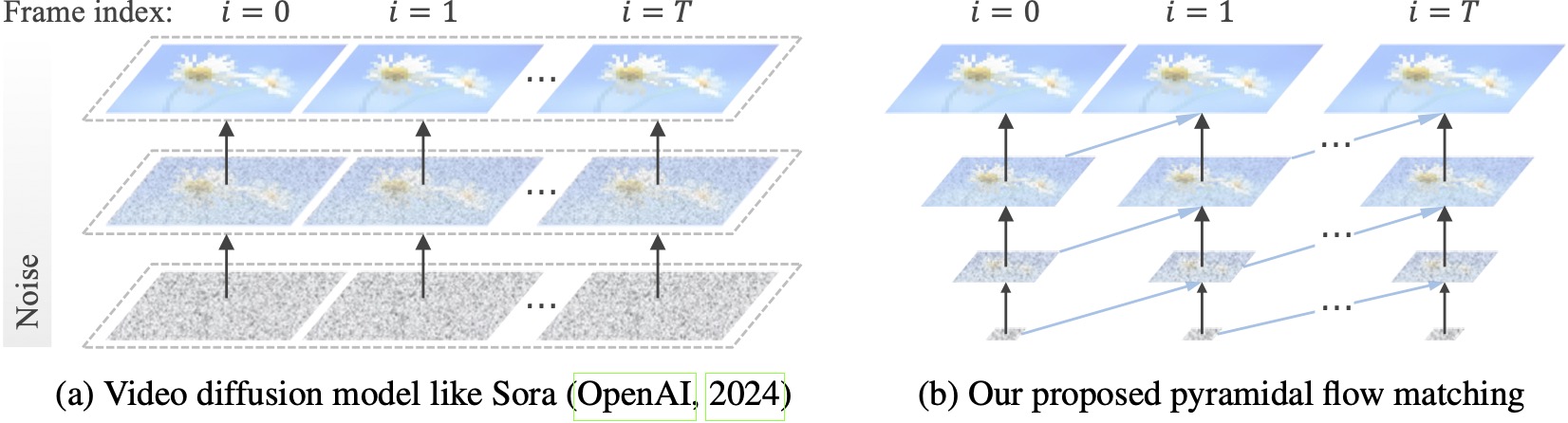
現有的視頻擴散模型以全分辨率運行,在非常嘈雜的潛伏上花費大量計算。相較之下,我們的方法利用流匹配的靈活性(Lipman et al., 2023; Liu et al., 2023; Albergo & Vanden-Eijnden, 2023)在不同分辨率和噪音水平的潛在變數之間進行插值,從而允許同時產生和以更好的計算效率對視覺內容進行解壓縮。整個框架使用單一 DiT 進行端到端優化(Peebles & Xie,2023),在 20.7k A100 GPU 訓練小時內產生 768p 解析度和 24 FPS 的高品質 10 秒影片。
我們建議使用 conda 設定環境。程式碼庫目前使用 Python 3.8.10 和 PyTorch 2.1.2(指南),我們正在積極努力支援更廣泛的版本。
git clone https://github.com/jy0205/Pyramid-Flow
cd Pyramid-Flow
# create env using conda
conda create -n pyramid python==3.8.10
conda activate pyramid
pip install -r requirements.txt然後,從 Huggingface 下載模型(有兩種變體:miniFLUX 或 SD3)。 miniFLUX 型號支援 1024p 影像、384p 和 768p 視訊生成,基於 SD3 的型號支援 768p 和 384p 視訊生成。 384p 檢查點以 24FPS 產生 5 秒的視頻,而 768p 檢查點以 24FPS 產生長達 10 秒的視頻。
from huggingface_hub import snapshot_download
model_path = 'PATH' # The local directory to save downloaded checkpoint
snapshot_download ( "rain1011/pyramid-flow-miniflux" , local_dir = model_path , local_dir_use_symlinks = False , repo_type = 'model' )首先,先安裝 Gradio,將模型路徑設定為 #L36,然後在本機上執行:
python app.pyGradio 演示將在瀏覽器中開啟。感謝@tpc2233 的提交,請參閱#48 了解詳細資訊。
或者,在 Hugging Face Space 上輕鬆嘗試一下?由@multimodalart 創建。由於 GPU 限制,此線上示範只能產生 25 幀(以 8FPS 或 24FPS 匯出)。複製空間以產生更長的視訊。
若要在 Google Colab 上快速試用 Pyramid Flow,請執行以下程式碼:
# Setup
!git clone https://github.com/jy0205/Pyramid-Flow
%cd Pyramid-Flow
!pip install -r requirements.txt
!pip install gradio
# This code downloads miniFLUX
from huggingface_hub import snapshot_download
model_path = '/content/Pyramid-Flow'
snapshot_download("rain1011/pyramid-flow-miniflux", local_dir=model_path, local_dir_use_symlinks=False, repo_type='model')
# Start
!python app.py
要使用我們的模型,請按照此連結中video_generation_demo.ipynb中的推理程式碼進行操作。我們強烈建議您嘗試最新發表的pyramid-miniflux,它對人體結構和運動穩定性都有很大的改善。將參數model_name設定為要使用的pyramid_flux 。我們進一步將其簡化為以下兩步驟流程。首先,載入下載的模型:
import torch
from PIL import Image
from pyramid_dit import PyramidDiTForVideoGeneration
from diffusers . utils import load_image , export_to_video
torch . cuda . set_device ( 0 )
model_dtype , torch_dtype = 'bf16' , torch . bfloat16 # Use bf16 (not support fp16 yet)
model = PyramidDiTForVideoGeneration (
'PATH' , # The downloaded checkpoint dir
model_name = "pyramid_flux" ,
model_dtype ,
model_variant = 'diffusion_transformer_768p' ,
)
model . vae . enable_tiling ()
# model.vae.to("cuda")
# model.dit.to("cuda")
# model.text_encoder.to("cuda")
# if you're not using sequential offloading bellow uncomment the lines above ^
model . enable_sequential_cpu_offload ()然後,您可以根據自己的提示嘗試生成文字到影片。請注意,384p 版本現在僅支援 5 秒(將溫度設定為 16)!
prompt = "A movie trailer featuring the adventures of the 30 year old space man wearing a red wool knitted motorcycle helmet, blue sky, salt desert, cinematic style, shot on 35mm film, vivid colors"
# used for 384p model variant
# width = 640
# height = 384
# used for 768p model variant
width = 1280
height = 768
with torch . no_grad (), torch . cuda . amp . autocast ( enabled = True , dtype = torch_dtype ):
frames = model . generate (
prompt = prompt ,
num_inference_steps = [ 20 , 20 , 20 ],
video_num_inference_steps = [ 10 , 10 , 10 ],
height = height ,
width = width ,
temp = 16 , # temp=16: 5s, temp=31: 10s
guidance_scale = 7.0 , # The guidance for the first frame, set it to 7 for 384p variant
video_guidance_scale = 5.0 , # The guidance for the other video latent
output_type = "pil" ,
save_memory = True , # If you have enough GPU memory, set it to `False` to improve vae decoding speed
)
export_to_video ( frames , "./text_to_video_sample.mp4" , fps = 24 )作為自迴歸模型,我們的模型也支援(文字條件)圖像到影片的生成:
# used for 384p model variant
# width = 640
# height = 384
# used for 768p model variant
width = 1280
height = 768
image = Image . open ( 'assets/the_great_wall.jpg' ). convert ( "RGB" ). resize (( width , height ))
prompt = "FPV flying over the Great Wall"
with torch . no_grad (), torch . cuda . amp . autocast ( enabled = True , dtype = torch_dtype ):
frames = model . generate_i2v (
prompt = prompt ,
input_image = image ,
num_inference_steps = [ 10 , 10 , 10 ],
temp = 16 ,
video_guidance_scale = 4.0 ,
output_type = "pil" ,
save_memory = True , # If you have enough GPU memory, set it to `False` to improve vae decoding speed
)
export_to_video ( frames , "./image_to_video_sample.mp4" , fps = 24 )我們還支援兩種類型的 CPU 卸載,以減少 GPU 記憶體需求。請注意,他們可能會犧牲效率。
cpu_offloading=True參數允許使用少於 12GB的 GPU 記憶體進行推理。此功能由@Ednaordinary 貢獻,有關詳細信息,請參閱#23。model.enable_sequential_cpu_offload()允許使用小於 8GB的 GPU 記憶體進行推理。此功能由@rodjjo 貢獻,詳細資訊請參閱#75。 感謝@niw,Apple Silicon 用戶(例如配備 M2 24GB 的 MacBook Pro)也可以使用 MPS 後端嘗試我們的模型!詳情請參閱#113。
對於擁有多個 GPU 的用戶,我們提供了一個推理腳本,該腳本使用序列並行性來節省每個 GPU 上的記憶體。這也帶來了很大的加速,在 4 個 A100 GPU 上產生 5 秒、768p、24fps 的影片僅需 2.5 分鐘(而在單一 A100 GPU 上則需要 5.5 分鐘)。使用以下命令在 2 個 GPU 上運行它:
CUDA_VISIBLE_DEVICES=0,1 sh scripts/inference_multigpu.sh目前支援 2 或 4 個 GPU(適用於 SD3 版本),原始腳本中提供更多配置。您還可以啟動由 @tpc2233 創建的多 GPU Gradio 演示,有關詳細信息,請參閱#59。
劇透:由於我們高效率的金字塔流設計,我們在訓練中甚至沒有使用序列並行性。
guidance_scale參數控制視覺品質。我們建議在文字到視訊生成期間對 768p 檢查點使用 [7, 9] 中的指南,對 384p 檢查點使用 7 中的指南。video_guidance_scale參數控制運動。較大的值會增加動態程度並減輕自回歸生成退化,而較小的值會穩定影片。訓練 VAE 的硬體需求至少為 8 個 A100 GPU。請參閱此文件。這是一個類似 MAGVIT-v2 的連續 3D VAE,應該非常靈活。請隨意在 VAE 訓練程式碼的這一部分上建立您自己的影片生成模型。
微調 DiT 的硬體要求至少為 8 個 A100 GPU。請參閱此文件。我們提供金字塔流自迴歸和非自迴歸版本的說明。前者較偏向研究,後者較穩定(但沒有時間金字塔效率較低)。
以下影片範例以 5 秒、768p、24fps 產生。欲了解更多結果,請造訪我們的專案頁面。
東京.mp4 | 艾菲爾鐵塔.mp4 |
波浪.mp4 | 鐵路.mp4 |
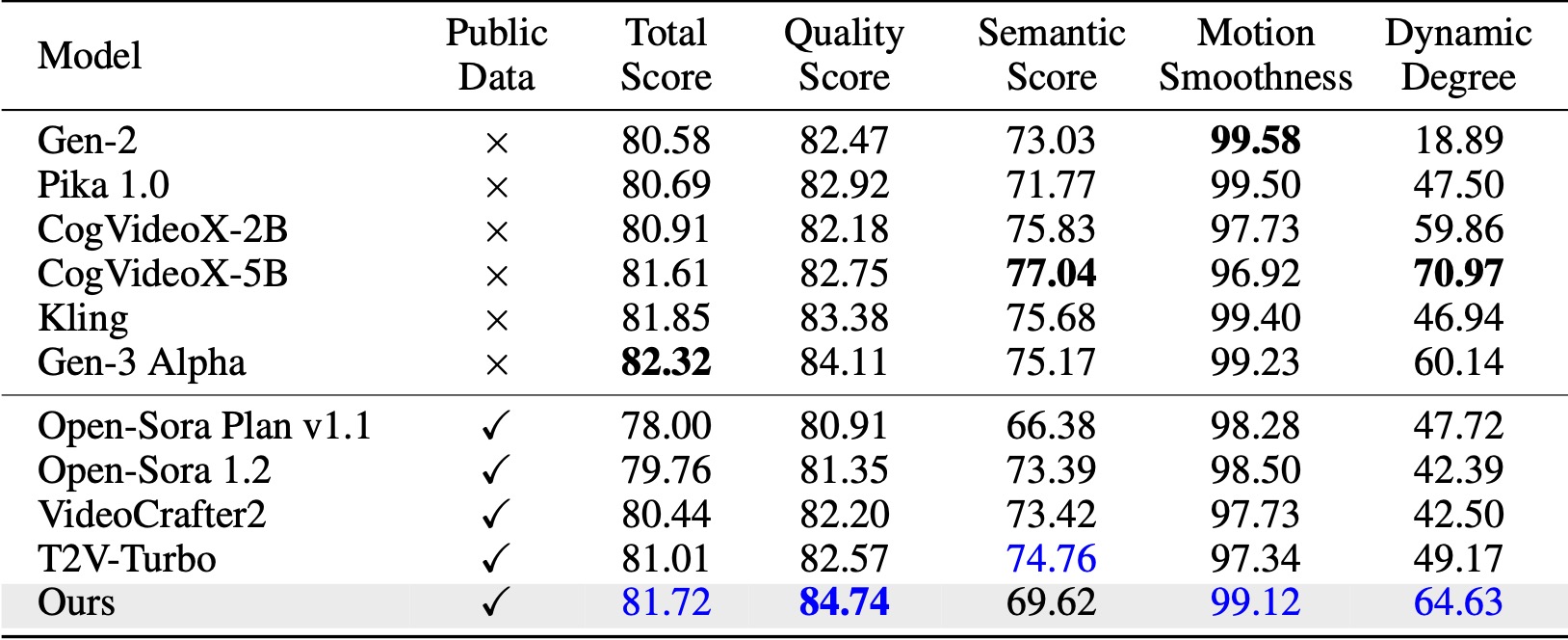
在 VBench(Huang 等人,2024)上,我們的方法超越了所有比較的開源基準。即使只有公開視訊數據,它也能達到與Kling(快手,2024)和Gen-3 Alpha(Runway,2024)等商業模型相當的性能,特別是在質量得分(84.74 vs. Gen-3 的84.11)和運動平滑度方面。
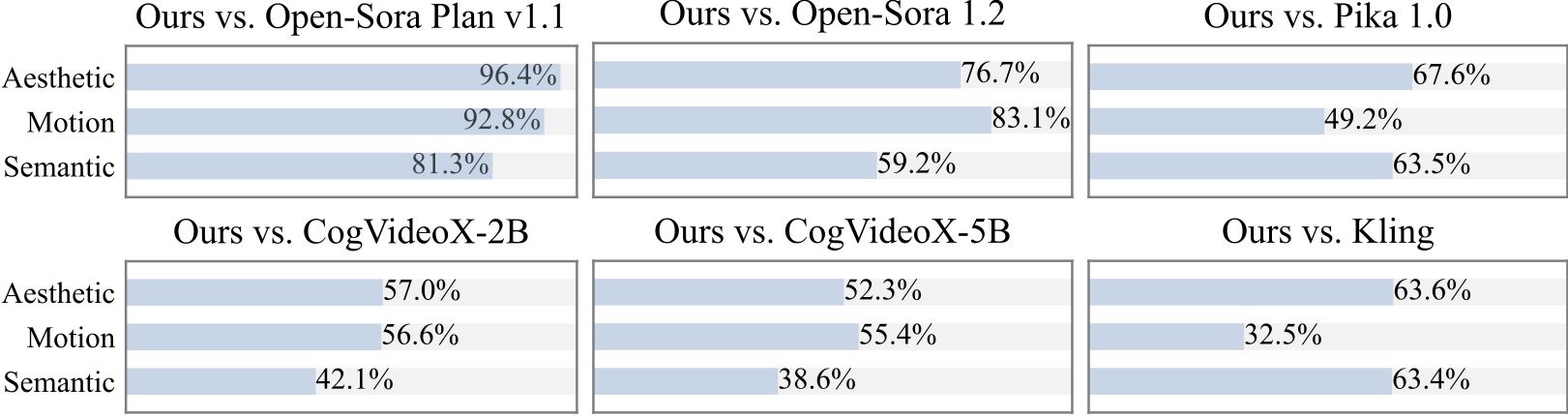
我們對 20 多名參與者進行了額外的用戶研究。可以看出,我們的方法優於 Open-Sora 和 CogVideoX-2B 等開源模型,尤其是在運動平滑度方面。
我們感謝在實施 Pyramid Flow 時實現以下出色的專案:
如果它對您的研究有幫助,請考慮給這個儲存庫一顆星,並在您的出版物中引用 Pyramid Flow。
@article{jin2024pyramidal,
title={Pyramidal Flow Matching for Efficient Video Generative Modeling},
author={Jin, Yang and Sun, Zhicheng and Li, Ningyuan and Xu, Kun and Xu, Kun and Jiang, Hao and Zhuang, Nan and Huang, Quzhe and Song, Yang and Mu, Yadong and Lin, Zhouchen},
jounal={arXiv preprint arXiv:2410.05954},
year={2024}
}


