nim anywhere
1.0.0

如果您是內部用戶,請加入 #cdd-nim-anywhere slack 頻道;如果您是外部用戶,請提出問題並提出任何問題和回饋。
企業使用人工智慧的主要好處之一是他們能夠處理內部數據並從中學習。檢索增強生成(RAG)是實現這一目標的最佳方法之一。 NVIDIA 開發了一套名為 NIM 微服務的微服務,以幫助我們的合作夥伴和客戶輕鬆建立有效的 RAG 管道。
NIM Anywhere 包含開始為 RAG 整合 NIM 所需的所有工具。它本身可以擴展到全規模的實驗室和生產環境。這對於建立 RAG 架構並根據需要輕鬆添加 NIM 來說是個好消息。如果您不熟悉 RAG,它會在推理過程中動態檢索相關外部信息,而無需修改模型本身。想像一下,您是一家公司的技術主管,該公司的本地資料庫包含機密的最新資訊。您不希望 OpenAI 存取您的數據,但您需要模型理解數據才能準確回答問題。解決方案是將您的語言模型連接到資料庫並向其提供資訊。
要詳細了解為什麼 RAG 是提高生成式 AI 模型的準確性和可靠性的出色解決方案,請閱讀此部落格。
立即按照快速入門說明開始使用 NIM Anywhere,並使用 NIM 建立您的第一個 RAG 應用程式!
若要允許 AI Workbench 存取 NVIDIA 的雲端資源,您需要為其提供個人金鑰。這些鍵以nvapi-開頭。
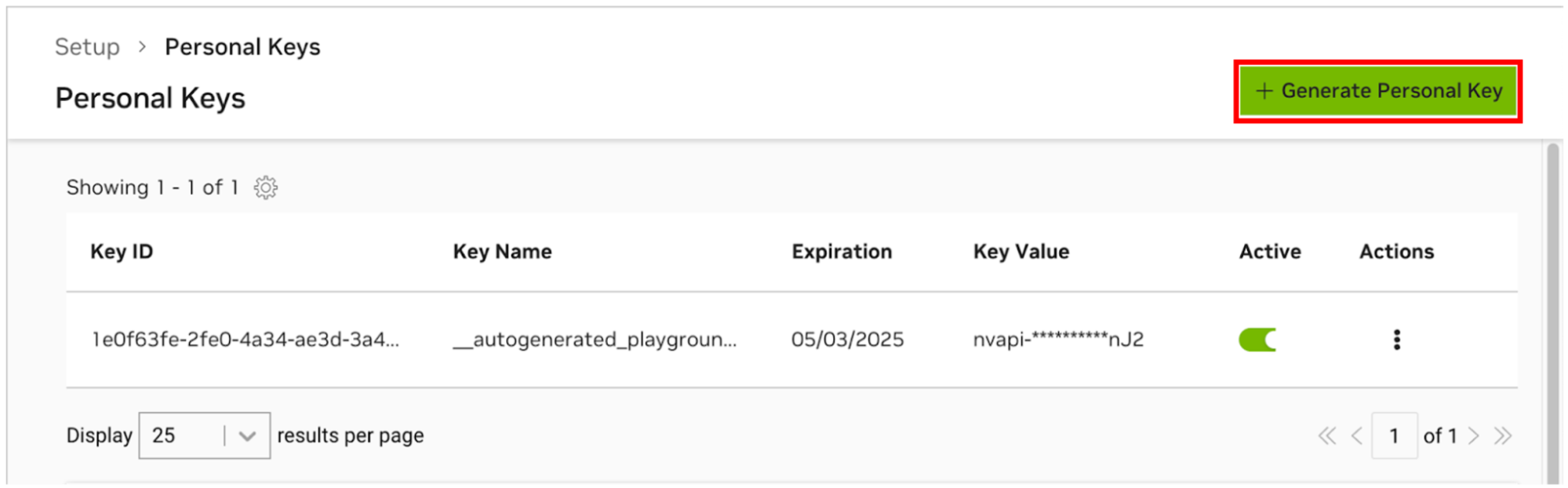
轉至 NGC 個人密鑰管理器。如果出現提示,請註冊一個新帳戶並登入。
提示您可以透過以下方式找到此工具:登入 ngc.nvidia.com,展開右上角的個人資料選單,選擇「設定」 ,然後選擇「產生個人金鑰」 。
選擇產生個人密鑰。
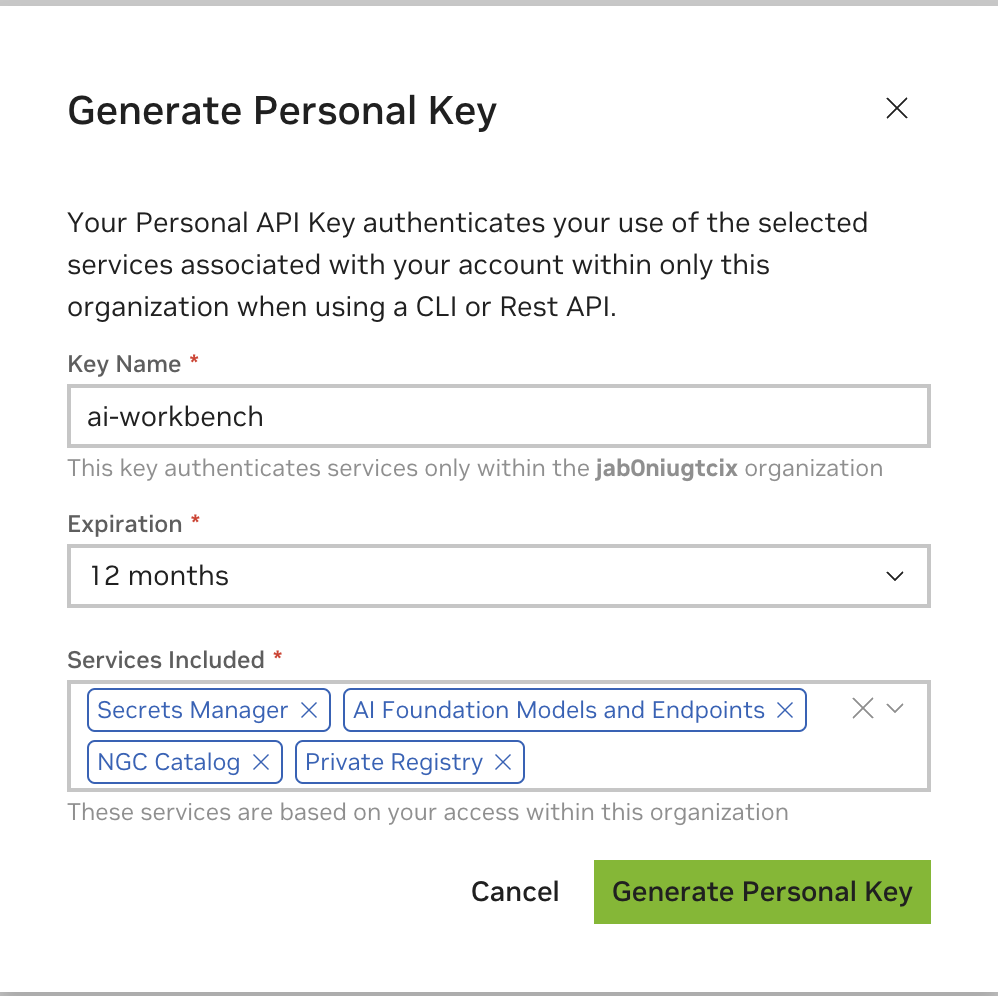
輸入任意值為金鑰名稱,有效期限為 12 個月即可,然後選擇所有服務。完成後按下「產生個人密鑰」 。
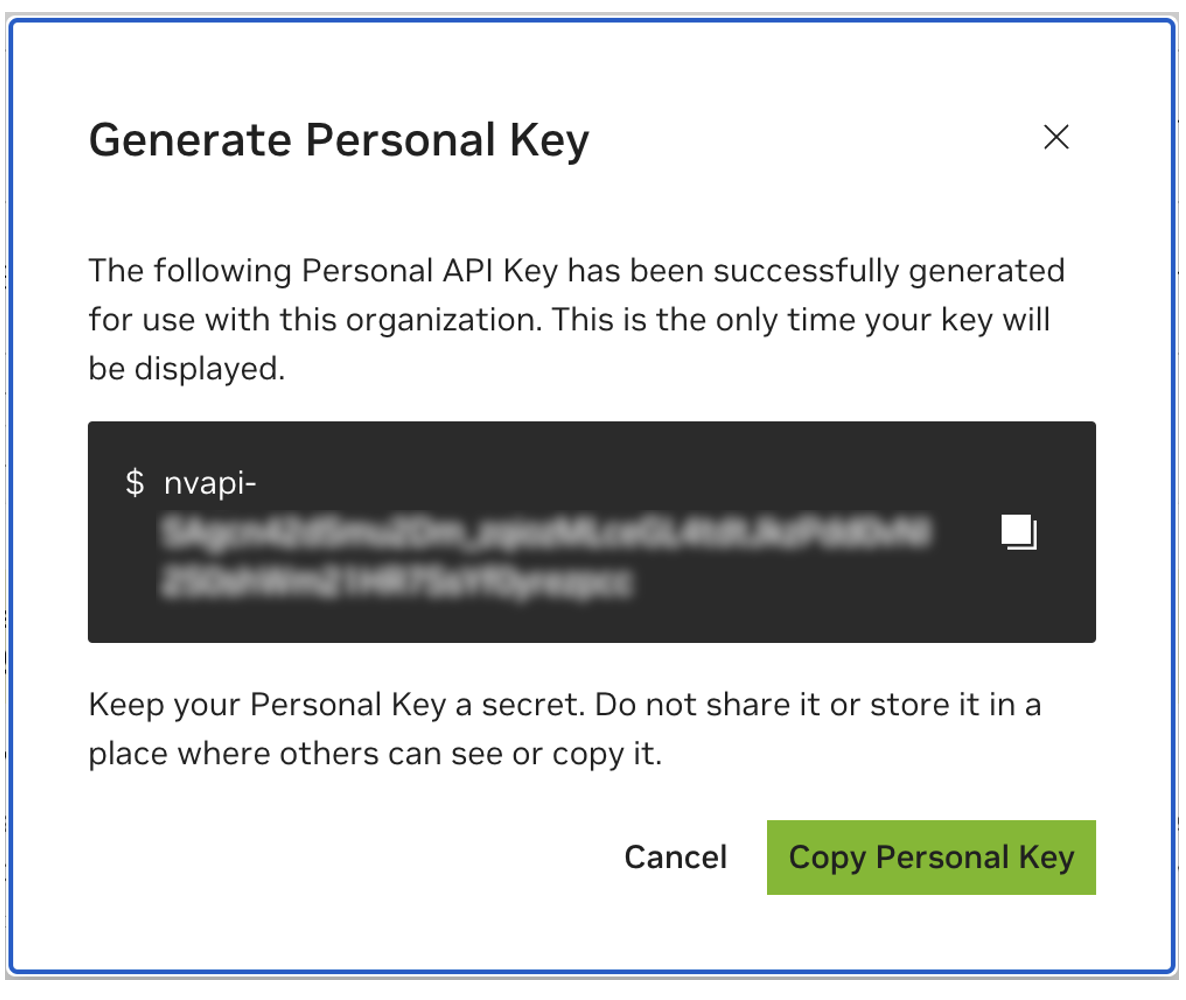
儲存您的個人密鑰以供日後使用。 Workbench 將需要它,並且以後無法檢索它。如果密鑰遺失,則必須建立一把新密鑰。像保護密碼一樣保護此金鑰。
該專案旨在與 NVIDIA AI Workbench 一起使用。雖然這不是必需的,但在沒有 AI Workbench 的情況下運行此演示將需要手動工作,因為預先配置的自動化和整合可能不可用。
本快速入門指南假設使用遠端實驗室電腦進行開發,而本機電腦則是用於遠端存取開發電腦的瘦客戶端。這使得計算資源能夠保持集中位置,並且使開發人員更加便攜。請注意,遠端實驗室電腦必須執行 Ubuntu,但本機用戶端可以執行 Windows、MacOS 或 Ubuntu。要僅在本機安裝此項目,只需跳過遠端安裝即可。
流程圖LR
當地的
子圖實驗室環境
遠端實驗室機器
結尾
本地 <-.ssh.-> 遠端實驗室機器
如果本機用戶端也用於開發,則需要Ubuntu。使用遠端實驗室電腦時,可以是 Windows、MacOS 或 Ubuntu。
有關完整說明,請參閱 NVIDIA AI Workbench 使用者指南。
安裝必備軟體
下載 NVIDIA AI Workbench 安裝程式並執行它。授權 Windows 允許安裝程式進行更改。
請按照安裝精靈中的說明進行操作。如果您需要安裝 WSL2,請授權 Windows 進行變更並在要求時重新啟動本機。當系統重新啟動時,NVIDIA AI Workbench 安裝程式應自動恢復。
選擇 Docker 作為您的容器運行時。
使用「透過 GitHub.com 登入」選項登入您的 GitHub 帳戶。
如果需要,請輸入您的 git 作者資訊。
有關完整說明,請參閱 NVIDIA AI Workbench 使用者指南。
安裝必備軟體
下載 NVIDIA AI Workbench 磁碟映像( .dmg檔案)並開啟它。
將 AI Workbench 拖曳到應用程式資料夾中,然後從應用程式啟動器執行NVIDIA AI Workbench 。 
選擇 Docker 作為您的容器運行時。
使用「透過 GitHub.com 登入」選項登入您的 GitHub 帳戶。
如果需要,請輸入您的 git 作者資訊。
有關完整說明,請參閱 NVIDIA AI Workbench 使用者指南。以將成為 Workbench 使用者的使用者身分執行此安裝。不要以root執行這些步驟。
安裝必備軟體
下載 NVIDIA AI Workbench 安裝程序,使其可執行,然後運行它。您可以使用以下命令使該檔案可執行:
chmod +x NVIDIA-AI-Workbench- * .AppImageAI Workbench 將為您安裝 NVIDIA 驅動程式(如果需要)。安裝驅動程式後,您需要重新啟動本機計算機,然後雙擊桌面上的 NVIDIA AI Workbench 圖示重新啟動 AI Workbench 安裝。
選擇 Docker 作為您的容器運行時。
使用「透過 GitHub.com 登入」選項登入您的 GitHub 帳戶。
如果需要,請輸入您的 git 作者資訊。
遠端電腦僅支援 Ubuntu。
有關完整說明,請參閱 NVIDIA AI Workbench 使用者指南。以將使用 Workbench 的使用者身分執行此安裝。不要以root執行這些步驟。
確保從本機到遠端電腦啟用基於 SSH 金鑰的身份驗證。如果目前未啟用此功能,則以下命令將在大多數情況下啟用此功能。更改REMOTE_USER和REMOTE-MACHINE以反映您的遠端位址。
ssh - keygen -f " C:Userslocal-user.sshid_rsa " - t rsa - N ' "" '
type $ env: USERPROFILE .sshid_rsa.pub | ssh REMOTE_USER @REMOTE - MACHINE " cat >> .ssh/authorized_keys " if [ ! -e ~ /.ssh/id_rsa ] ; then ssh-keygen -f ~ /.ssh/id_rsa -t rsa -N " " ; fi
ssh-copy-id REMOTE_USER@REMOTE-MACHINE透過 SSH 連接到遠端主機。然後,使用下列命令下載並執行 NVIDIA AI Workbench 安裝程式。
mkdir -p $HOME /.nvwb/bin &&
curl -L https://workbench.download.nvidia.com/stable/workbench-cli/ $( curl -L -s https://workbench.download.nvidia.com/stable/workbench-cli/LATEST ) /nvwb-cli- $( uname ) - $( uname -m ) --output $HOME /.nvwb/bin/nvwb-cli &&
chmod +x $HOME /.nvwb/bin/nvwb-cli &&
sudo -E $HOME /.nvwb/bin/nvwb-cli installAI Workbench 將為您安裝 NVIDIA 驅動程式(如果需要)。安裝驅動程式後,您需要重新啟動遠端計算機,然後透過重新執行上一個步驟中的命令來重新啟動 AI Workbench 安裝。
選擇 Docker 作為您的容器運行時。
使用「透過 GitHub.com 登入」選項登入您的 GitHub 帳戶。
如果需要,請輸入您的 git 作者資訊。
遠端安裝完成後,可以將遠端位置新增至本機 AI Workbench 實例。開啟 AI Workbench 應用程序,按一下「新增遠端位置」 ,然後輸入所需資訊。完成後,按一下「新增位置」 。
REMOTE-MACHINE相同。REMOTE_USER相同。/home/USER/.ssh/id_rsa 。有兩種方法可以下載該項目以供本地使用:克隆和分叉。
克隆此存儲庫是建議的開始方式。這不允許進行本地修改,但啟動速度最快。這也允許以最簡單的方式獲取更新。
建議分叉此儲存庫進行開發,因為可以儲存變更。然而,為了獲取更新,分叉維護者必須定期從上游儲存庫中提取。要使用分叉進行操作,請按照 GitHub 的說明進行操作,然後在本節的其餘部分中引用您的個人分叉的 URL。
開啟本機 NVIDIA AI Workbench 視窗。從顯示的位置清單中,選擇您剛剛設定的遠端位置,或者如果您要在本機上工作,請選擇本機位置。
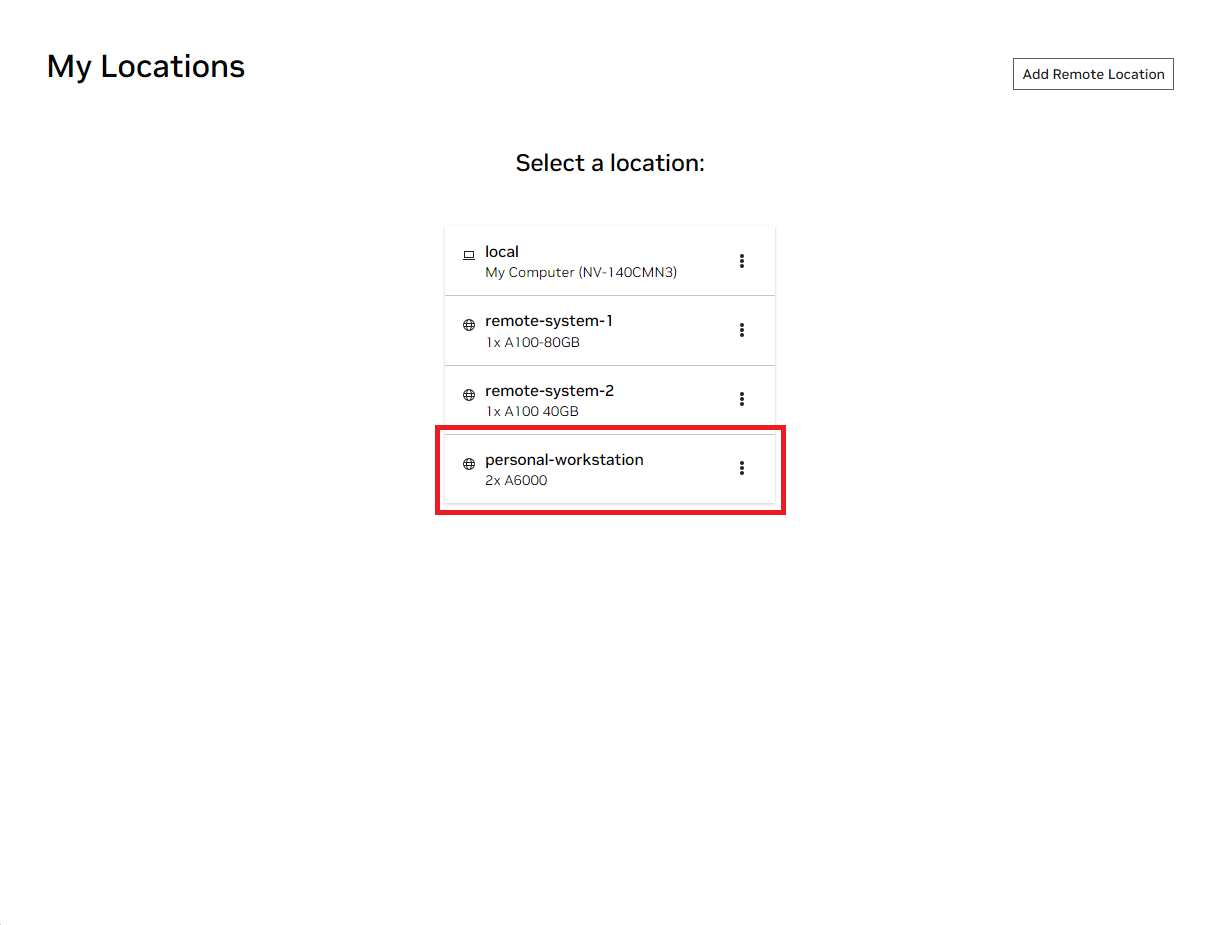
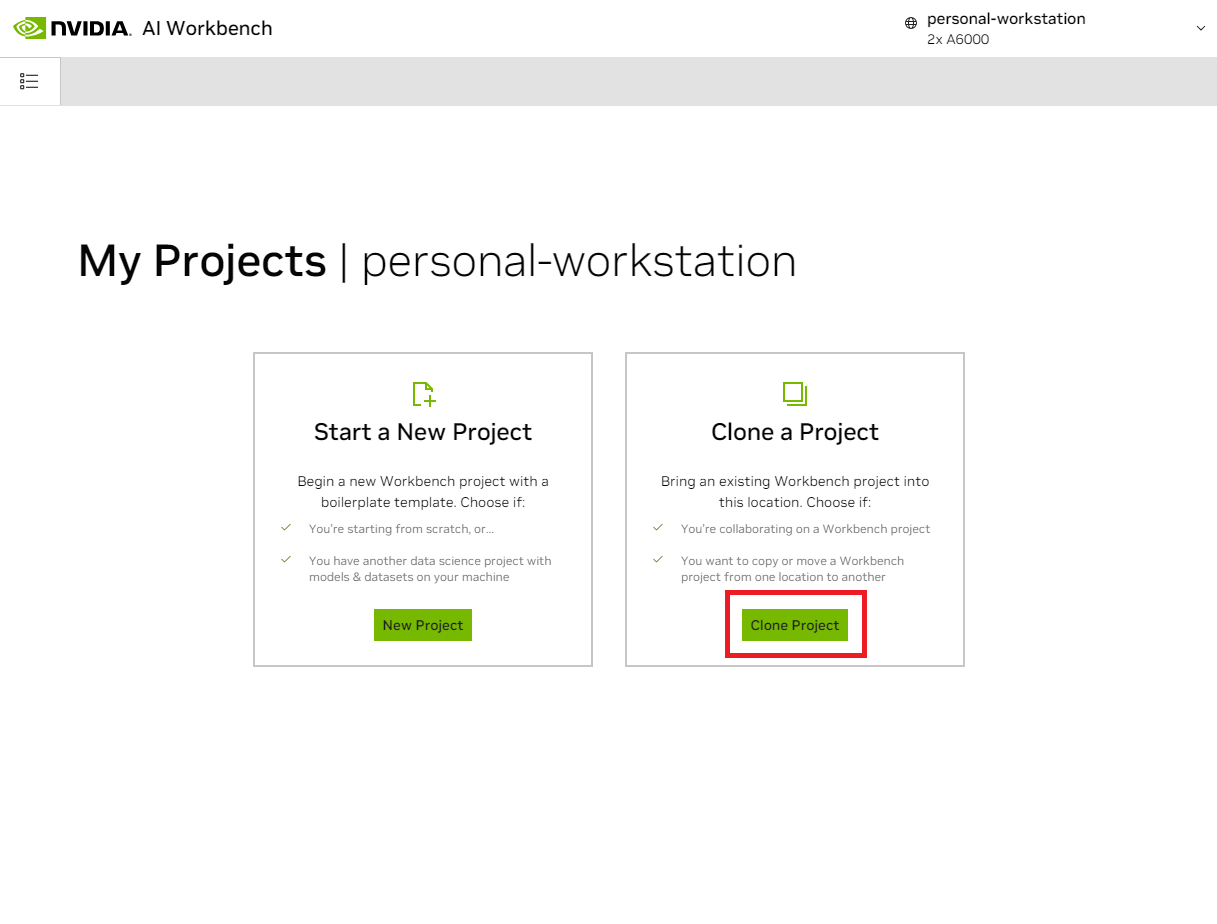
進入該位置後,選擇「克隆項目」 。
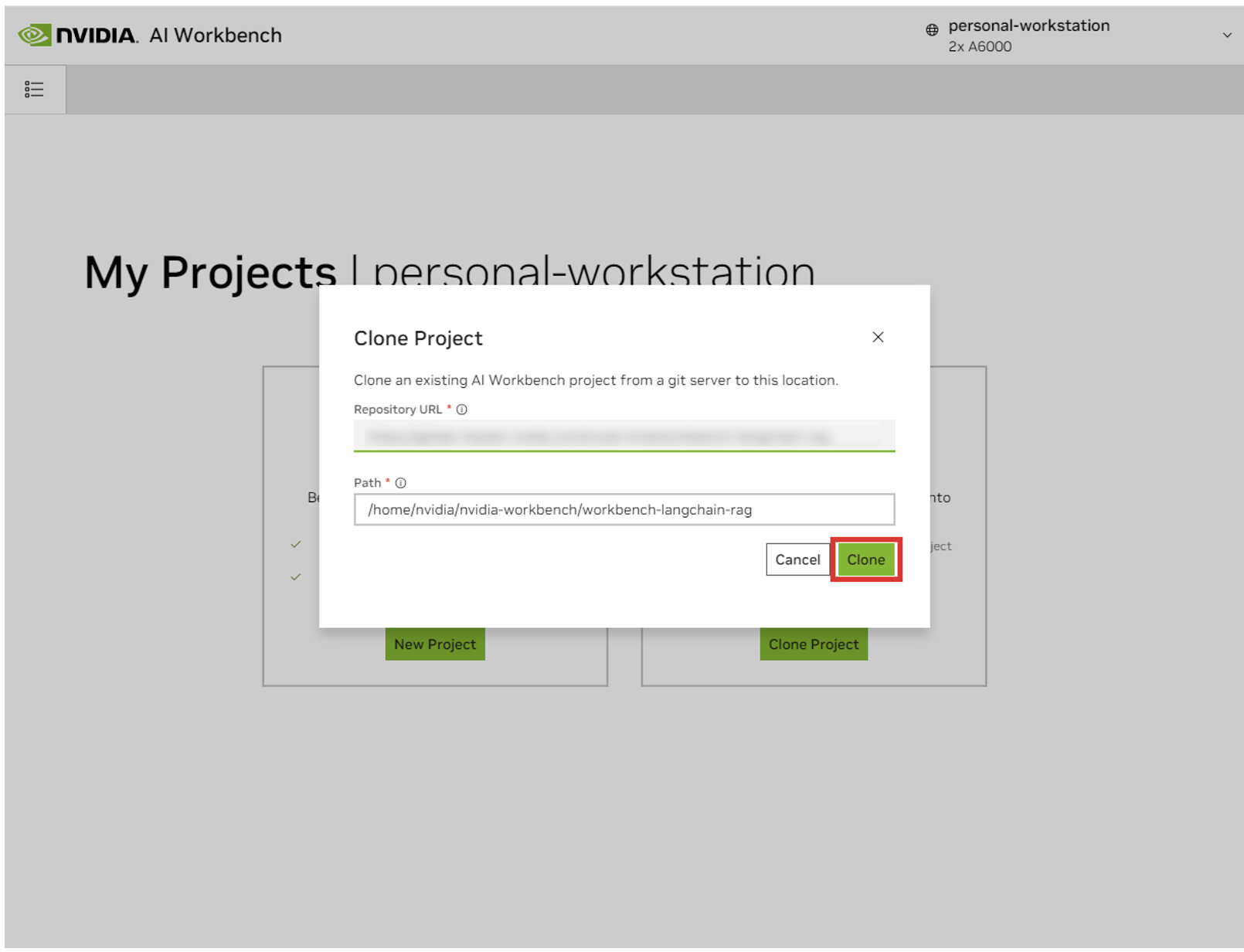
在「複製專案」彈出視窗中,將儲存庫 URL 設定為https://github.com/NVIDIA/nim-anywhere.git 。您可以將路徑保留為預設值/home/REMOTE_USER/nvidia-workbench/nim-anywhere.git 。點選克隆。
您將被重新導向到新項目的頁面。 Workbench 將自動開機開發環境。您可以透過展開視窗底部的輸出來查看即時進度。
此項目必須配置為使用本機電腦資源。
首次運行之前,必須提供專案特定配置。項目配置是使用左側面板中的“環境”選項卡完成的。
向下捲動到變數部分並找到NGC_HOME條目。它應該設定為類似~/.cache/nvidia-nims 。這裡的值由工作台使用。此相同位置也出現在將此目錄安裝到容器中的Mounts部分。
向下捲動到Secrets部分並找到NGC_API_KEY條目。按下“配置”並提供先前產生的 NGC 個人金鑰。
向下捲動到“坐騎”部分。這裡,有兩個安裝座需要配置。
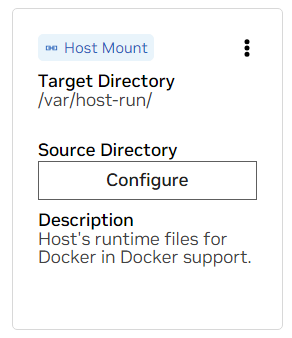
一個。求 /var/host-run 的掛載點。這用於允許開發環境以稱為 Docker out of Docker 的模式存取主機的 Docker 守護程式。按下“配置”並提供目錄/var/run 。
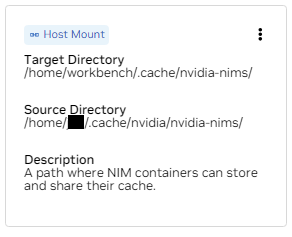
b.找到 /home/workbench/.cache/nvidia-nims 的安裝。此掛載用作 NIM 的運行時緩存,它們可以在其中緩存模型檔案。與主機共享此快取可減少磁碟使用量和網路頻寬。
如果您還沒有 nim 緩存,或者您不確定,請使用以下命令在/home/USER/.cache/nvidia-nims中建立一個。
mkdir -p ~ /.cache/nvidia-nims
chmod 2777 ~ /.cache/nvidia-nims更改這些設定後將進行重建。
一旦建置完成並顯示“建置就緒”訊息,所有應用程式都將可供您使用。
即使是最基本的 LLM 鏈也依賴一些額外的微服務。在記憶體替代方案的開發過程中可以忽略這些,但隨後需要更改程式碼才能投入生產。值得慶幸的是,Workbench 為開發環境管理這些額外的微服務。
提示:對於每個應用程序,可以透過點擊左下角的「輸出」鏈接,選擇下拉式選單,然後選擇感興趣的應用程序,在 UI 中監視調試輸出。
可以透過導航到環境>應用程式來控制此工作區中捆綁的所有應用程式。
首先,開啟Milvus Vector DB和Redis 。 Milvus 用作非結構化知識庫,Redis 用來儲存對話歷史。
一旦這些服務啟動, Chain Server就可以安全啟動。其中包含用於執行推理鏈的自訂 LangChain 程式碼。預設情況下,它將使用本地 Milvus 和 Redis,但使用ai.nvidia.com進行 LLM 和 Embedding 模型推理。
[可選]:接下來,啟動LLM NIM 。第一次啟動LLM NIM時,需要一些時間來下載鏡像和最佳化模型。
一個。在長時間啟動期間,為了確認 LLM NIM 正在啟動,可以使用 UI 左下角的「輸出」窗格查看日誌來觀察進度。
b.如果日誌指示身份驗證錯誤,則表示提供的NGC_API_KEY無權存取 NIM。請驗證它是否正確生成,並且是在具有 NVIDIA AI Enterprise 支援或試用的 NGC 組織中生成的。
c.如果日誌似乎卡在..........: Pull complete 。 ..........: Verifying complete ,或..........: Download complete ;這是 Docker 的所有正常輸出,表示容器映像的各個層已下載。
d.這裡的任何其他故障都需要解決。
一旦Chain Server啟動,聊天介面就可以啟動。啟動介面將自動在瀏覽器視窗中開啟它。
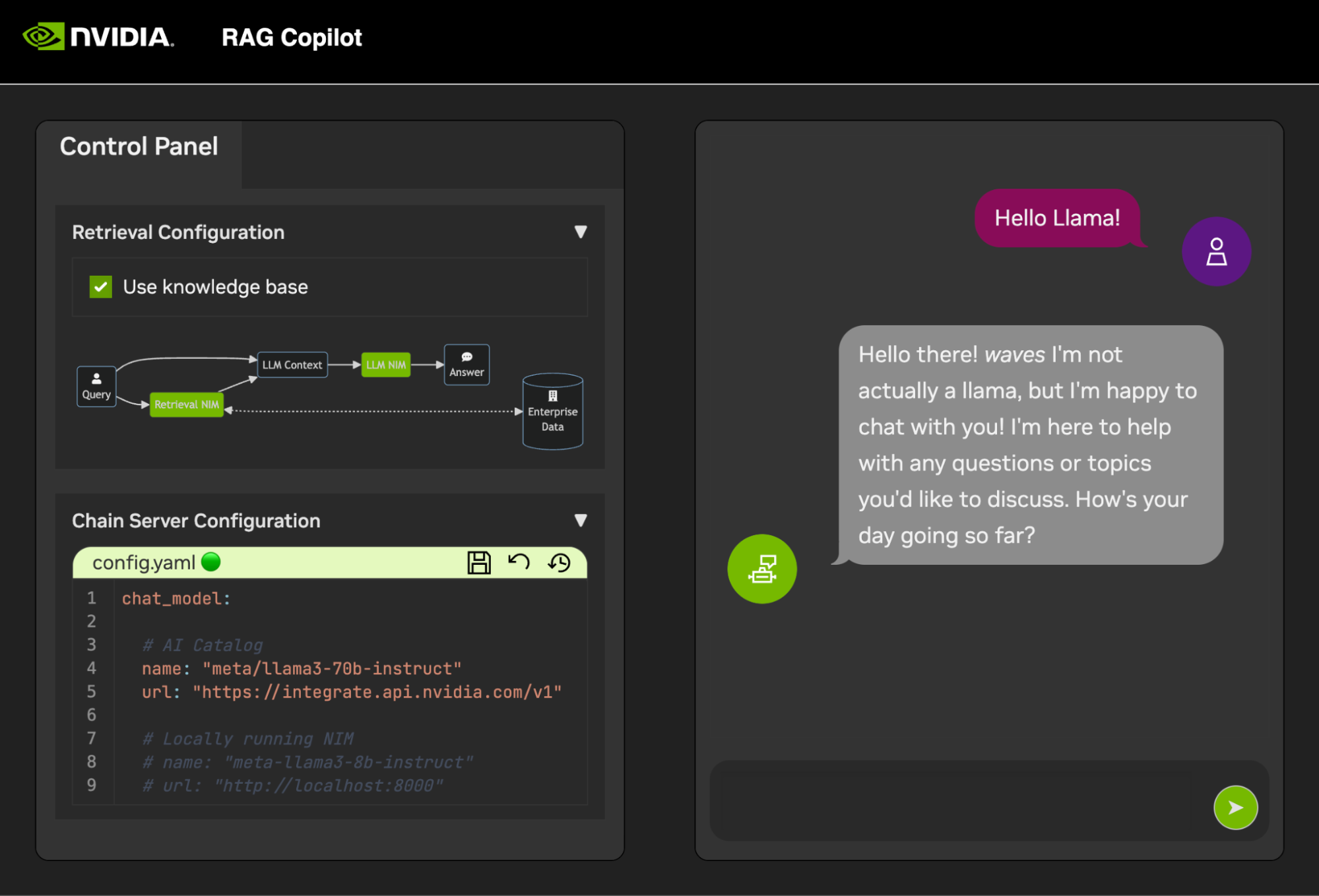
為了開始開發演示,我們提供了一個範例資料集以及一個 Jupyter Notebook,展示如何將資料引入向量資料庫。
若要將 PDF 文件匯入向量資料庫,請使用 AI Workbench 中的應用程式啟動器開啟 Jupyter。
使用code/upload-pdfs.ipynb中的 Jupyter Notebook 取得預設資料集。如果使用預設資料集,則無需進行任何變更。
如果使用自訂資料集,請將其上傳到 Jupyter 中的data/目錄,並根據需要修改提供的筆記本。
該專案包含一些演示服務的應用程式以及與外部服務的整合。這些都是由 NVIDIA AI Workbench 精心策劃的。
演示服務都在code資料夾中。程式碼資料夾的根級別有一些用於技術深入研究的互動筆記本。 Chain Server 是一個將 NIM 與 LangChain 結合使用的範例應用程式。 (請注意,此處的 Chain Server 為您提供了使用或不使用 RAG 進行試驗的選項)。 Chat Frontend 資料夾包含一個用於運行鏈結伺服器的互動式 UI 伺服器。最後,評估目錄中提供了範例筆記本來示範檢索評分和驗證。
心智圖
根((AI工作台))
演示服務
鏈結伺服器<br />LangChain + NIM
前端<br />互動式演示 UI
評估<br />驗證結果
筆記本<br />進階用法
整合
Redis</br>對話歷史記錄
Milvus</br>向量資料庫
LLM NIM優化的LLM
Chain Server 可以使用設定檔或環境變數進行設定。
預設情況下,應用程式將在以下所有位置搜尋設定檔。如果找到多個設定文件,則清單中較低檔案中的值將優先。
可以透過名為APP_CONFIG的環境變數指定附加設定檔路徑。該文件中的值將優先於所有預設文件位置。
export APP_CONFIG=/etc/my_config.yaml也可以使用環境變數來設定配置。變數名稱的格式為: APP_FIELD__SUB_FIELD指定為環境變數的值將優先於檔案中的所有值。
# Your API key for authentication to AI Foundation.
# ENV Variables: NGC_API_KEY, NVIDIA_API_KEY, APP_NVIDIA_API_KEY
# Type: string, null
nvidia_api_key : ~
# The Data Source Name for your Redis DB.
# ENV Variables: APP_REDIS_DSN
# Type: string
redis_dsn : redis://localhost:6379/0
llm_model :
# The name of the model to request.
# ENV Variables: APP_LLM_MODEL__NAME
# Type: string
name : meta/llama3-8b-instruct
# The URL to the model API.
# ENV Variables: APP_LLM_MODEL__URL
# Type: string
url : https://integrate.api.nvidia.com/v1
embedding_model :
# The name of the model to request.
# ENV Variables: APP_EMBEDDING_MODEL__NAME
# Type: string
name : nvidia/nv-embedqa-e5-v5
# The URL to the model API.
# ENV Variables: APP_EMBEDDING_MODEL__URL
# Type: string
url : https://integrate.api.nvidia.com/v1
reranking_model :
# The name of the model to request.
# ENV Variables: APP_RERANKING_MODEL__NAME
# Type: string
name : nv-rerank-qa-mistral-4b:1
# The URL to the model API.
# ENV Variables: APP_RERANKING_MODEL__URL
# Type: string
url : https://integrate.api.nvidia.com/v1
milvus :
# The host machine running Milvus vector DB.
# ENV Variables: APP_MILVUS__URL
# Type: string
url : http://localhost:19530
# The name of the Milvus collection.
# ENV Variables: APP_MILVUS__COLLECTION_NAME
# Type: string
collection_name : collection_1
log_level :
聊天前端也有一些設定選項。它們可以按照與鏈伺服器相同的方式設定。
# The URL to the chain on the chain server.
# ENV Variables: APP_CHAIN_URL
# Type: string
chain_url : http://localhost:3030/
# The url prefix when this is running behind a proxy.
# ENV Variables: PROXY_PREFIX, APP_PROXY_PREFIX
# Type: string
proxy_prefix : /
# Path to the chain server's config.
# ENV Variables: APP_CHAIN_CONFIG_FILE
# Type: string
chain_config_file : ./config.yaml
log_level :
歡迎對此專案的所有回饋和貢獻。當對此項目進行更改時,無論是為了個人使用還是為了貢獻,建議在該項目上進行分叉。一旦在分叉上完成更改,就應該打開合併請求。
該項目已配置了 Linters,這些 Linters 已進行了調整,以幫助代碼保持一致,同時又不會過於繁重。我們使用以下 Linters:
嵌入式 VSCode 環境配置為即時執行 linting 和檢查。
若要手動執行 CI 管道完成的 linting,請執行/project/code/tools/lint.sh 。可以透過名稱指定它們來執行單獨的測試: /project code/tools/lint.sh [deps|pylint|mypy|black|docs|fix] 。在修復模式下執行 lint 工具將透過執行 Black、更新 README 並清除所有 Jupyter Notebook 上的儲存格輸出來自動修正它可以修正的問題。
前端的設計旨在最大限度地減少所需的 HTML 和 Javascript 開發。提供了一個帶有品牌和样式的應用程式外殼,它是使用普通 HTML、Javascript 和 CSS 創建的。它被設計為易於定制,但永遠不應該是必需的。前端的互動元件都是在 Gradio 中創建的,並使用 iframe 安裝在應用程式 shell 中。
應用程式外殼頂部是一個列出可用視圖的選單。每個視圖可能有自己的佈局,由一頁或幾頁組成。
頁麵包含演示的互動式元件。頁面的程式碼位於code/frontend/pages目錄。若要建立新頁面:
__init__.py文件,使用 Gradio 定義 UI。漸層塊佈局應在名為page變數中定義。chat頁面的範例。code/frontend/pages/__init__.py文件,匯入新頁面,並將新頁面加入__all__ 。注意:建立新頁面不會將其新增至前端。必須將其新增至視圖才能顯示在前端上。
視圖由一頁或幾頁組成,並且應彼此獨立運行。視圖全部在code/frontend/server.py模組中定義。所有聲明的視圖將自動新增至前端的功能表列並在 UI 中可用。
若要定義新視圖,請修改名為views的清單。這是View物件的列表。物件的順序將定義它們在前端選單中的順序。第一個定義的視圖將是預設視圖。
視圖物件描述視圖名稱和佈局。它們可以聲明如下:
my_view = frontend . view . View (
name = "My New View" , # the name in the menu
left = frontend . pages . sample_page , # the page to show on the left
right = frontend . pages . another_page , # the page to show on the right
)所有頁面都聲明View.left或View.right都是可選的。如果未聲明它們,則 Web 版面配置中關聯的 iframe 將會被隱藏。其他 iframe 將擴展以填補空白。下圖顯示了各種佈局。
區塊貝塔
第 1 欄
選單[“選單列”]
堵塞
第 2 欄
左 右
結尾
區塊貝塔
第 1 欄
選單[“選單列”]
堵塞
第 1 欄
左:1
結尾
前端包含一些可以針對不同用例進行客製化的品牌資產。
前端在頁面左上角包含一個徽標。要修改徽標,需要所需徽標的 SVG。然後可以透過修改code/frontend/_assets/index.html檔案輕鬆修改應用程式外殼以使用新的 SVG。有一個 ID 為logo的div 。該框包含一個 SVG。將此更新為所需的 SVG 定義。
< div id =" logo " class =" logo " >
< svg viewBox =" 0 0 164 30 " > ... </ svg >
</ div > App Shell 的樣式在code/frontend/_static/css/style.css定義。可以安全地修改此文件中的顏色。
各頁面的樣式在code/frontend/pages/*/*.css中定義。這些文件可能還需要修改自訂配色方案。
Gradio 主題在檔案code/frontend/_assets/theme.json中定義。該文件中的顏色可以安全地修改為所需的品牌。此文件中的其他樣式也可能會更改,但可能會導致前端發生重大更改。 Gradio 文件包含更多有關 Gradio 主題的資訊。
注意:這是大多數開發人員永遠不需要的高級主題。
有時,可能需要在視圖中包含多個相互通訊的頁面。為此,使用了 Javascript 的postMessage訊息傳遞框架。發佈到應用程式 shell 的任何受信任訊息都會轉發到每個 iframe,其中頁面可以根據需要處理該訊息。 control頁面使用此功能來修改chat頁面的配置。
以下內容將向應用程式 shell ( window.top ) 發布一則訊息。該訊息將包含一個字典,其鍵為use_kb且值為 true。使用 Gradio,該 Javascript 可以由任何 Gradio 事件執行。
window . top . postMessage ( { "use_kb" : true } , '*' ) ;該訊息將自動由應用程式外殼發送到所有頁面。以下範例程式碼將在另一個頁面上使用該訊息。當收到message事件時,此程式碼將非同步運行。如果訊息可信, elem_id為use_kb的 Gradio 元件將更新為訊息中指定的值。這樣,Gradio 元件的值就可以跨頁面複製。
window . addEventListener (
"message" ,
( event ) => {
if ( event . isTrusted ) {
use_kb = gradio_config . components . find ( ( element ) => element . props . elem_id == "use_kb" ) ;
use_kb . props . value = event . data [ "use_kb" ] ;
} ;
} ,
false ) ; 自述文件會自動呈現;直接編輯將被覆蓋。為了修改自述文件,您需要分別編輯每個部分的文件。所有這些文件將被合併並自動產生自述文件。您可以在docs資料夾中找到所有相關文件。
文件以 Github Flavored Markdown 編寫,然後由 Pandoc 呈現為最終 Markdown 文件。此過程的詳細資訊在 Makefile 中定義。產生的檔案的順序在docs/_TOC.md中定義。可以在 Workbench 檔案瀏覽器視窗中預覽文件。
頭檔是用於編譯文檔的第一個檔案。該檔案可以在docs/_HEADER.md找到。該文件的內容將在沒有任何操作的情況下逐字寫入自述文件中,然後再進行其他操作。
摘要文件包含描述該項目的快速描述和圖形。該文件的內容將立即加入 README 中的標題之後、目錄之前。該文件由 Pandoc 處理以在寫入 README 之前嵌入圖像。
該文件最重要的文件是docs/_TOC.md中的目錄文件。該文件定義了應連接以產生最終自述文件手冊的文件清單。文件必須在此列表中才能包含在內。
將所有靜態內容(包括影像)儲存到_static資料夾。這將有助於組織。
擁有能夠自行更新和編寫的文件可能會有所幫助。要建立動態文檔,只需建立一個將 Markdown 格式文檔寫入 stdout 的可執行檔即可。在建置期間,如果目錄檔案中的條目是可執行的,則該條目將被執行,並且其標準輸出將在其位置使用。
當推送與文件相關的提交時,GitHub Action 將呈現文件。自述文件的任何變更都將自動提交。
開發環境的大部分配置都是透過環境變數進行的。若要對環境變數進行永久更改,請修改variables.env或使用Workbench UI。
本專案使用/usr/bin/python3中的一個 Python 環境,並使用pip管理依賴項。由於所有開發都是在容器內完成的,因此 Python 環境的任何變更都將是短暫的。若要永久安裝 Python 包,請將其新增至requirements.txt檔案或使用Workbench UI。
開發環境基於Ubuntu 22.04。主用戶具有無密碼 sudo 存取權限,但對系統的所有變更都將是短暫的。若要對已安裝的軟體包進行永久更改,請將它們新增至 [ apt.txt ] 檔案中。對作業系統進行其他更改,例如操作檔案、新增環境變數等;使用postBuild.bash和preBuild.bash檔案。
通常最好每月更新依賴項,以確保不會因濫用依賴項而暴露 CVE。以下流程可用於修補此項目。建議在補丁後執行回歸測試,以確保更新中沒有任何問題。
/project/code/tools/bump.sh腳本自動更新 Python 依賴項和 NIM 應用程式。/project/code/tools/audit.sh 。該腳本將列印所有處於警告狀態的 Python 套件和所有處於錯誤狀態的套件的報告。任何處於錯誤狀態的內容都必須解決,因為它將具有活動的 CVE 和已知漏洞。

