RLAIF V
1.0.0

透過開源 AI 回饋調整 MLLM 以實現超級 GPT-4V 可信度
中文 |英語
[2024.11.26] 支持LoRA訓練囉!
[2024.05.28] 我們的論文現在可以在 arXiv 上訪問了!
[2024.05.20] 我們的RLAIF-V-Dataset用於訓練MiniCPM-Llama3-V 2.5,它代表了第一個端側GPT-4V等級MLLM!
[2024.05.20] 我們開源了RLAIF-V的程式碼、權重(7B、12B)和資料!
我們推出了 RLAIF-V,這是一個新穎的框架,它將 MLLM 與完全開源的範式結合起來,以實現超級 GPT-4V 的可信度。 RLAIF-V從高品質回饋資料和線上回饋學習演算法兩個關鍵角度最大限度地利用開源回饋。 RLAIF-V 的顯著特徵包括:
透過開源回饋實現超級 GPT-4V 可信度。透過學習開源 AI 回饋,RLAIF-V 12B 在生成和判別任務中實現了超級 GPT-4V 的可信度。
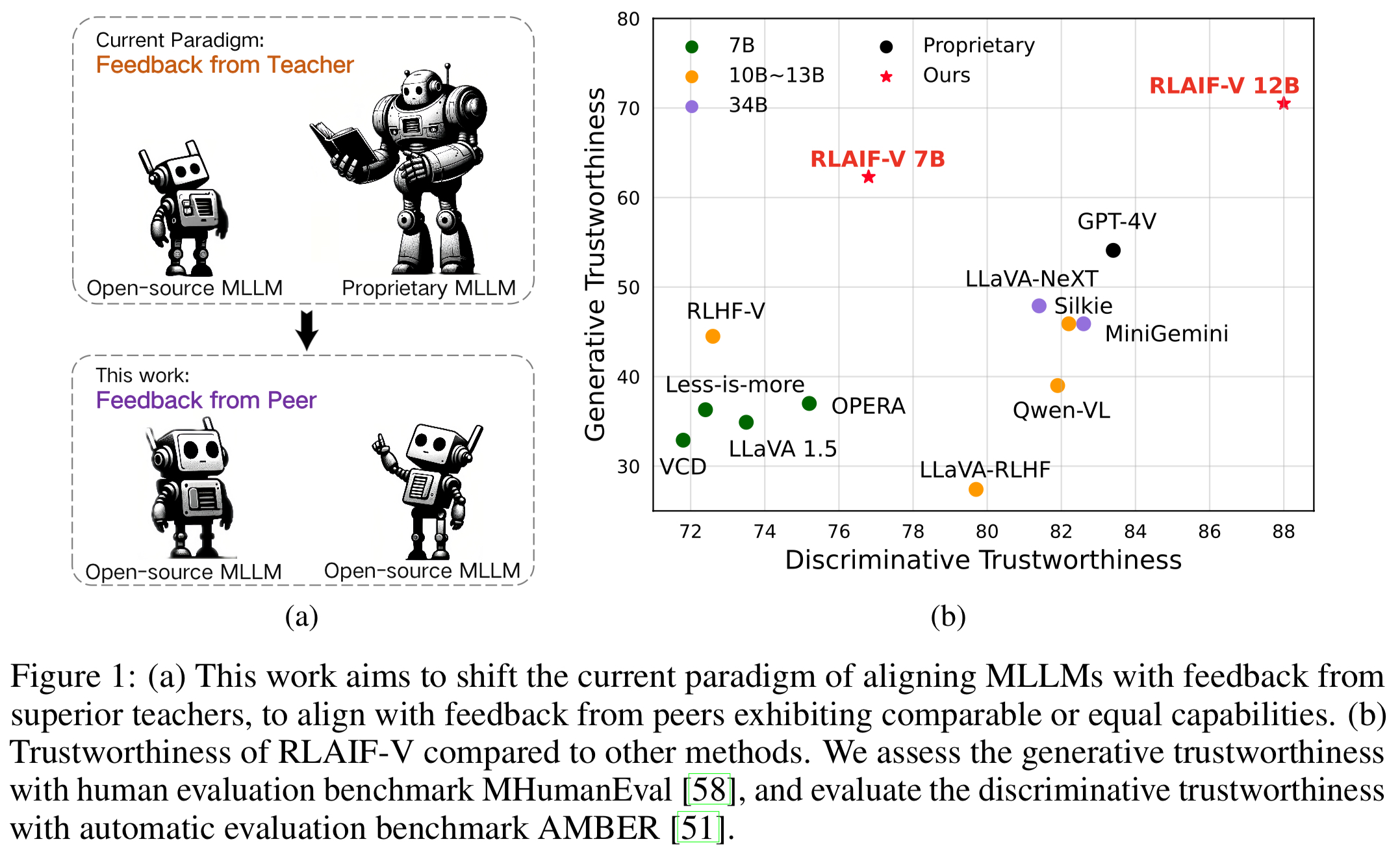
高品質的可概括的回饋數據。 RLAIF-V所使用的回饋資料有效減少了不同MLLM的幻覺。
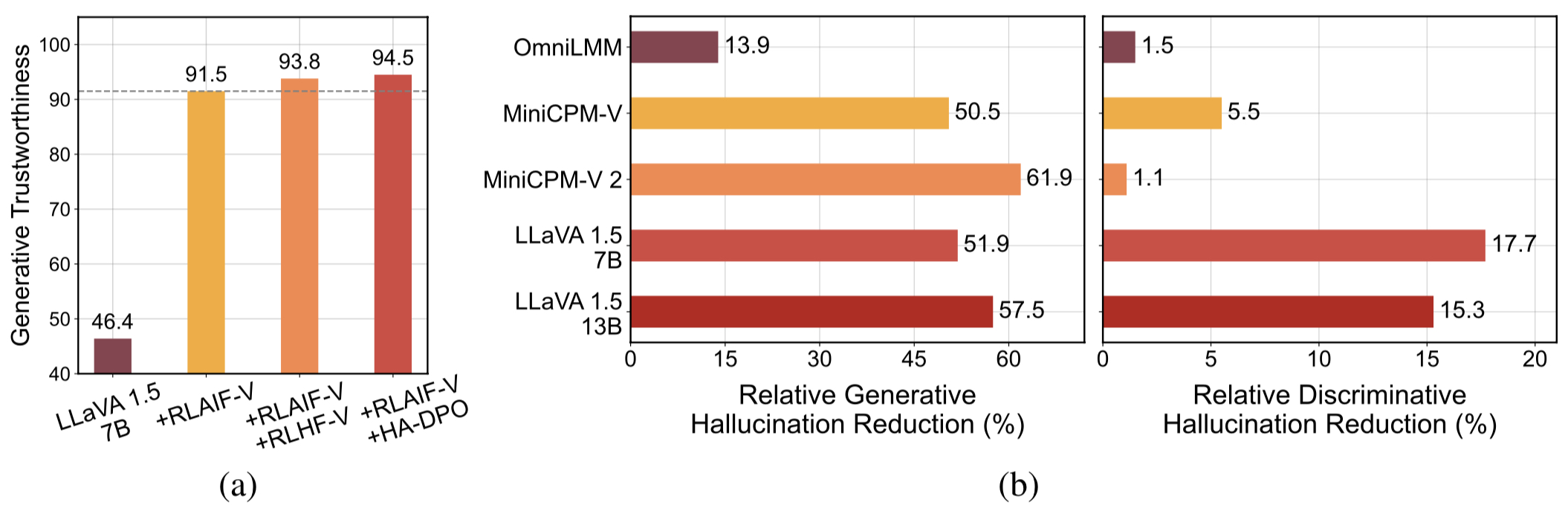
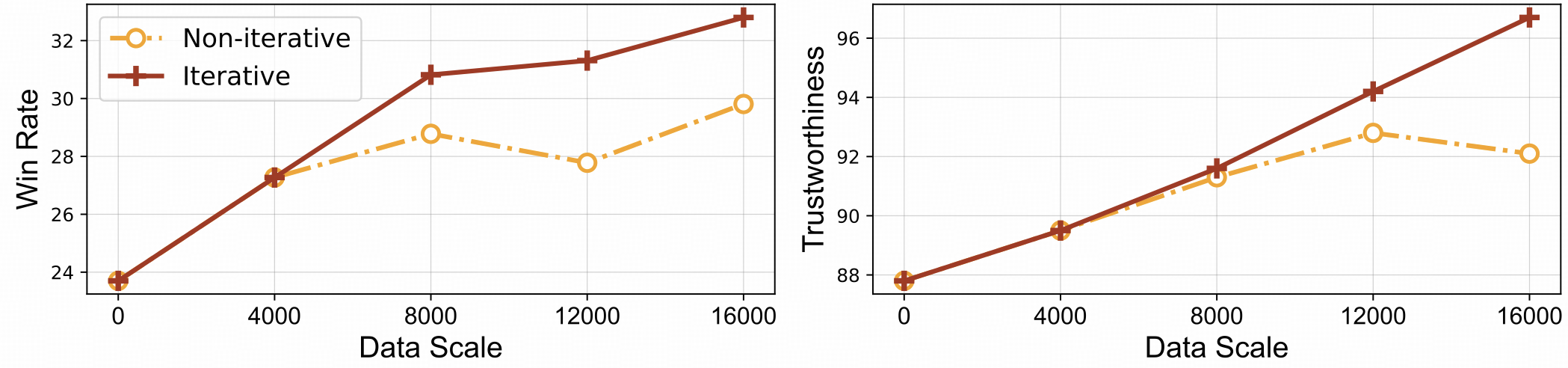
⚡️透過迭代對齊進行有效的回饋學習。與非迭代方法相比,RLAIF-V 表現出更好的學習效率和更高的表現。
數據集
安裝
型號重量
推理
數據生成
火車
評估
物件 HalBench
MMHal 長椅
RefoMB
引文
我們提出了 RLAIF-V 資料集,這是一個人工智慧生成的偏好資料集,涵蓋各種任務和領域。這個開源多模式偏好資料集包含83,132 個高品質比較對。此資料集包含不同模型的每次訓練迭代中產生的偏好對,包括 LLaVA 1.5 7B、OmniLMM 12B 和 MiniCPM-V。
克隆此儲存庫並導航至 RLAIF-V 資料夾
git 克隆 https://github.com/RLHF-V/RLAIF-V.gitcd RLAIF-V
安裝包
conda 創建-n rlaifv python=3.10 -y conda 激活 rlaifv pip install -e 。
安裝所需的 spaCy 模型
wget https://github.com/explosion/spacy-models/releases/download/en_core_web_trf-3.7.3/en_core_web_trf-3.7.3.tar.gz pip install en_core_web_trf-3.7.3.tar.gz
| 模型 | 描述 | 下載 |
|---|---|---|
| RLAIF-V 7B | LLaVA 1.5 上最值得信賴的變體 | ? |
| RLAIF-V 12B | 基於OmniLMM-12B,實現超級GPT-4V可信度。 | ? |
我們提供一個簡單的範例來展示如何使用 RLAIF-V。
from chat import RLAIFVChat, img2base64chat_model = RLAIFVChat('openBMB/RLAIF-V-7B') # 或 'openBMB/RLAIF-V-12B'image_path="./examples/test.jpeg"msgs = "詳細描述以下人員圖片。 "inputs = {"image": image_path, "question": msgs}answer = chat_model.chat(inputs)print(answer)您也可以透過執行以下腳本來執行此範例:
蟒蛇聊天.py

問題:
圖中的車為什麼停了下來?
預期產出:
圖中,由於路面上有一隻羊,一輛汽車停在了路上。汽車停下來可能是為了讓羊安全地讓開,或避免與動物發生任何潛在的事故。這種情況凸顯了駕駛時小心謹慎的重要性,尤其是在動物可能在道路附近漫步的地區。
環境設定
我們提供 OmniLMM 12B 模型和 MiniCPM-Llama3-V 2.5 模型用於回饋產生。如果您希望使用MiniCPM-Llama3-V 2.5進行回饋,請按照MiniCPM-V GitHub儲存庫中的說明配置其推理環境。
請下載我們微調後的Llama3 8B模型:分割模型和問題轉換模型,並將它們分別儲存在./models/llama3_split資料夾和./models/llama3_changeq資料夾中。
OmniLMM 12B 型號回饋
以下腳本示範了使用 LLaVA-v1.5-7b 模型產生候選答案以及使用 OmniLMM 12B 模型提供回饋。
mkdir ./結果 bash ./script/data_gen/run_data_pipeline_llava15_omni.sh
MiniCPM-Llama3-V 2.5 模型回饋
以下腳本示範了使用 LLaVA-v1.5-7b 模型產生候選答案以及使用 MiniCPM-Llama3-V 2.5 模型提供回饋。首先,將./script/data_gen/run_data_pipeline_llava15_minicpmv.sh中的minicpmv_python替換為您建立的MiniCPM-V環境的Python路徑。
mkdir ./結果 bash ./script/data_gen/run_data_pipeline_llava15_minicpmv.sh
準備資料(可選)
如果您可以存取huggingface資料集,則可以跳過此步驟,我們將自動下載RLAIF-V資料集。
如果您已經下載了資料集,則可以將第 38 行的「openbmb/RLAIF-V-Dataset」替換為您的資料集路徑。
訓練
在這裡,我們提供了一個訓練腳本來在1 次迭代中訓練模型。 max_step參數應根據您的資料量進行調整。
全面微調
執行以下命令開始完全微調。
bash ./script/train/llava15_train.sh
洛拉
執行以下命令開始lora訓練。
pip 安裝peft bash ./script/train/llava15_train_lora.sh
迭代對齊
為了重現論文中的迭代訓練過程,需要執行以下步驟4次:
S1。數據生成。
依照資料產生中的說明為基本模型產生偏好對。將產生的 jsonl 檔案轉換為 Huggingface Parquet。
S2。更改訓練配置。
在資料集程式碼中,將此處的'openbmb/RLAIF-V-Dataset'替換為您的資料路徑。
在訓練腳本中,將--data_dir替換為新目錄,將--model_name_or_path替換為基本模型路徑,將--max_step設定為 4 epoch 的步數,將--save_steps設定為 1/4 epoch 的步數。
S3。進行 DPO 培訓。
執行訓練腳本來訓練基本模型。
S4。選擇下一次迭代的基礎模型。
在 Object HalBench 和 MMHal Bench 上評估每個檢查點,選擇效能最好的檢查點作為下一個迭代的基礎模型。
準備COCO2014註釋
Object HalBench 的評估依賴 COCO2014 資料集的標題和分割註解。請先從COCO資料集官網下載COCO2014資料集。
mkdir coco2014cd coco2014 wget http://images.cocodataset.org/annotations/annotations_trainval2014.zip 解壓縮annotations_trainval2014.zip
推理、評量和總結
請將{YOUR_OPENAI_API_KEY}替換為有效的 OpenAI api 金鑰。
註:評估基於gpt-3.5-turbo-0613 。
# cd RLAIF-Vbash ./script/eval/eval_rlaifv_objhal.sh ./RLAIF-V_weight ./results/RLAIF-V ./coco2014/annotations {YOUR_OPENAI_API_KEY}準備MMHal數據
請在此下載 MMHal 評估數據,並將檔案保存在eval/data中。
執行以下腳本來產生 MMHal Bench:
註:評估基於gpt-4-1106-preview 。
# cd RLAIF-Vbash ./script/eval/eval_rlaifv_mmhal.sh ./RLAIF-V_weight ./results/RLAIF-V {YOUR_OPENAI_API_KEY}準備
若要使用 GPT-4 評估,請先執行pip install openai==0.28安裝 openai 軟體包。接下來,將eval/gpt4.py中的openai.base和openai.api_key更改為您自己的設定。
開發集的評估資料可以在eval/data/RefoMB_dev.jsonl中找到。您需要從每行中的image_url鍵下載每個圖像。
綜合評分評價
將模型答案保存在輸入資料檔eval/data/RefoMB_dev.jsonl的answer鍵中,例如:
{
"image_url": "https://thunlp.oss-cn-qingdao.aliyuncs.com/multimodal_openmme_test_20240319__20.jpg",
"question": "What is the background of the image?",
"type": "Coarse Perception",
"split": "dev",
"answer": "The background of the image features trees, suggesting that the scene takes place outdoors.",
"gt_description": "......"
}執行以下腳本來評估您的模型結果:
save_dir="YOUR SAVING DIR" model_ans_path="YOUR MODEL ANSWER PATH" model_name="YOUR MODEL NAME" bash ./script/eval/run_refobm_overall.sh $save_dir $model_ans_path $model_name
幻覺評分評估
評估總分後,將建立一個名為A-GPT-4V_B-${model_name}.json評估結果檔。使用此評估結果文件計算幻覺分數如下:
eval_result="EVAL RESULT FILE PATH, e.g. 'A-GPT-4V_B-${model_name}'"
# Do not include ".json" in your file path!
bash ./script/eval/run_refomb_hall.sh $eval_result注意:為了更好的穩定性,我們建議您評估3次以上,並使用平均分數作為最終的模型得分。
使用和許可聲明:數據、程式碼和檢查點僅供研究使用並獲得許可。它們也僅限於遵循 LLaMA、Vicuna 和 Chat GPT 許可協議的使用。此資料集為 CC BY NC 4.0(僅允許非商業用途),使用此資料集訓練的模型不應在研究目的之外使用。
RLHF-V:我們建立的程式碼庫。
LLaVA:RLAIF-V-7B 的指令模型與貼標機模型。
MiniCPM-V:RLAIF-V-12B的指令型號和貼標機型號。
如果您發現我們的模型/程式碼/數據/論文有幫助,請考慮引用我們的論文並給我們加星️!
@article{yu2023rlhf,title={Rlhf-v:透過細粒度矯正人類回饋的行為調整實現值得信賴的MLLMs},作者={Yu,Tianyu和Yao,Yuan和Zhang,Haoye和He,Taiwen和Han,Yifeng和崔甘曲和胡、金一和劉、志遠和鄭、海濤和孫、毛松等},journal={arXiv預印本arXiv:2312.00849},year={2023}}@article{yu2024rlaifv,title={ RLAIF -V:透過開源AI 回饋調整MLLM 以實現超級GPT-4V 可信度},作者={Yu、Tianyu 和Zhang、Haoye 和Yao、Yuan 和Dang、Yunkai 和Chen、Da 和Lu、Xiaoman 和Cui、 Ganqu 和何,泰文和劉,志遠和蔡,達成和孫,茂松},期刊={arXiv預印本arXiv:2405.17220},年份={2024},
} 

