ChatLM mini Chinese
1.0.0
中文| English
現在的大語言模型的參數往往較大,消費級電腦單純做推理都比較慢,更別說想自己從頭開始訓練一個模型了。本計畫的目標是從0開始訓練一個生成式語言模型,包括資料清洗、tokenizer訓練、模型預訓練、SFT指令微調、RLHF優化等。
ChatLM-mini-Chinese為中文對話小模型,模型參數只有0.2B(算共享權重約210M),可以在最低4GB顯存的機器進行預訓練( batch_size=1 , fp16或bf16 ), float16加載、推理最少只需要512MB顯存。
Huggingface NLP框架,包括transformers 、 accelerate 、 trl 、 peft等。trainer ,支援單機單卡、單機多卡進行預訓練、SFT微調。訓練過程中支援在任意位置停止,及在任意位置繼續訓練。Text-to-Text預訓練,非mask遮罩預測預訓練。sentencepiece 、 huggingface tokenizers的tokenizer訓練;batch_size=1, max_len=320下,最低支援在16GB記憶體+4GB顯存的機器上進行預訓練;trainer支援prompt指令微調, 支援任意斷點繼續訓練;Huggingface trainer的sequence to sequence微調;peft lora進行偏好優化;Lora adapter合併到原始模型中。如果需要做基於小模型的檢索增強產生(RAG),可以參考我的另一個專案Phi2-mini-Chinese,程式碼請見rag_with_langchain.ipynb
?最近更新
所有資料集均來自網路公開的單輪對話資料集,經過資料清洗、格式化後儲存為parquet檔案。資料處理過程請參考utils/raw_data_process.py 。主要數據集包括:
Belle_open_source_1M 、 train_2M_CN 、及train_3.5M_CN中部分回答較短、不含複雜表格結構、翻譯任務(沒做共英文詞表)的數據, 370萬行,清洗後剩餘338萬行。N個字為回答,使用202309的百科數據,清洗後剩餘119萬的詞條提示語和回答。 Wiki下載:zhwiki,將下載的bz2檔案轉換為wiki.txt參考:WikiExtractor。資料集總數1023萬:Text-to-Text預訓練集:930萬,評估集:2.5萬(因為解碼較慢,所以沒有把評估集設定太大)。測試集:90萬。 SFT微調和DPO優化資料集見下文。
T5模型(Text-to-Text Transfer Transformer),詳情請見論文: Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer。
模型原始碼來自huggingface,見:T5ForConditionalGeneration。
模型配置請參考model_config.json,官方的T5-base : encoder layer和decoder layer均為12層,本項目兩個參數修改為10層。
模型參數:0.2B。詞表大小:29298,僅包含中文和少量英文。
硬體:
# 预训练阶段:
CPU: 28 vCPU Intel(R) Xeon(R) Gold 6330 CPU @ 2.00GHz
内存:60 GB
显卡:RTX A5000(24GB) * 2
# sft及dpo阶段:
CPU: Intel(R) i5-13600k @ 5.1GHz
内存:32 GB
显卡:NVIDIA GeForce RTX 4060 Ti 16GB * 1 tokenizer 訓練: 現有tokenizer訓練庫遇到大語料時存在OOM問題,故全量語料按照類似BPE的方法根據詞頻合併、構造詞庫,運行耗時半天。
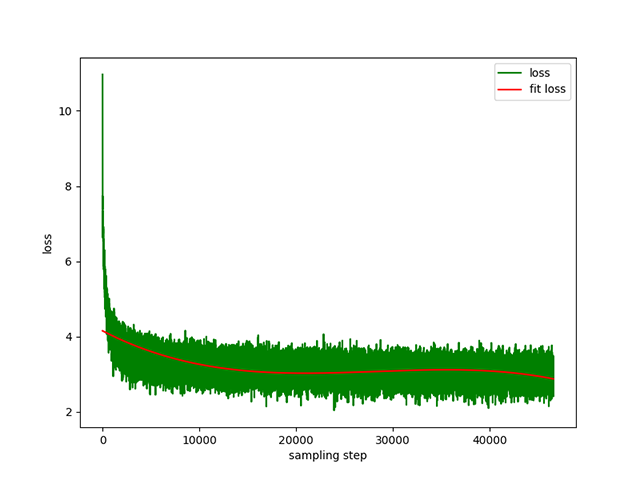
Text-to-Text 預訓練:學習率為1e-4到5e-3的動態學習率,預訓練時間為8天。訓練損失:
belle指令訓練資料集(指令和回答長度都在512以下),學習率為1e-7到5e-5的動態學習率,微調時間2天。微調損失: 
chosen文本,步驟2中SFT模型對資料集中的prompt做批量generate ,得到rejected文本,耗時1天,dpo全量偏好優化,學習率le-5 ,半精度fp16 ,共2個epoch ,耗時3h。 dpo損失: 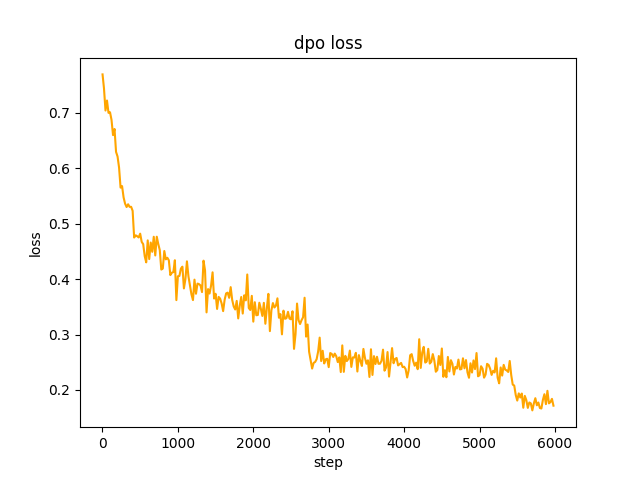
預設使用huggingface transformers的TextIteratorStreamer實作串流對話,只支援greedy search ,如果需要beam sample等其他產生方式,請將cli_demo.py的stream_chat參數修改為False 。 

存在問題:預訓練資料集只有900多萬,模型參數也僅0.2B,不能涵蓋所有方面,會有答非所問、廢話生成器的情況。
如果無法連接huggingface,請使用modelscope.snapshot_download從modelscope下載模型檔。
from transformers import AutoTokenizer , AutoModelForSeq2SeqLM
import torch
model_id = 'charent/ChatLM-mini-Chinese'
# 如果无法连接huggingface,打开以下两行代码的注释,将从modelscope下载模型文件,模型文件保存到'./model_save'目录
# from modelscope import snapshot_download
# model_id = snapshot_download(model_id, cache_dir='./model_save')
device = torch . device ( 'cuda' if torch . cuda . is_available () else 'cpu' )
tokenizer = AutoTokenizer . from_pretrained ( model_id )
model = AutoModelForSeq2SeqLM . from_pretrained ( model_id , trust_remote_code = True ). to ( device )
txt = '如何评价Apple这家公司?'
encode_ids = tokenizer ([ txt ])
input_ids , attention_mask = torch . LongTensor ( encode_ids [ 'input_ids' ]), torch . LongTensor ( encode_ids [ 'attention_mask' ])
outs = model . my_generate (
input_ids = input_ids . to ( device ),
attention_mask = attention_mask . to ( device ),
max_seq_len = 256 ,
search_type = 'beam' ,
)
outs_txt = tokenizer . batch_decode ( outs . cpu (). numpy (), skip_special_tokens = True , clean_up_tokenization_spaces = True )
print ( outs_txt [ 0 ])Apple是一家专注于设计和用户体验的公司,其产品在设计上注重简约、流畅和功能性,而在用户体验方面则注重用户的反馈和使用体验。作为一家领先的科技公司,苹果公司一直致力于为用户提供最优质的产品和服务,不断推陈出新,不断创新和改进,以满足不断变化的市场需求。
在iPhone、iPad和Mac等产品上,苹果公司一直保持着创新的态度,不断推出新的功能和设计,为用户提供更好的使用体验。在iPad上推出的iPad Pro和iPod touch等产品,也一直保持着优秀的用户体验。
此外,苹果公司还致力于开发和销售软件和服务,例如iTunes、iCloud和App Store等,这些产品在市场上也获得了广泛的认可和好评。
总的来说,苹果公司在设计、用户体验和产品创新方面都做得非常出色,为用户带来了许多便利和惊喜。
Caution
本專案模型為TextToText模型,在預訓練、SFT、RLFH階段的prompt 、 response等字段,請務必加上[EOS]序列結束標記。
git clone --depth 1 https://github.com/charent/ChatLM-mini-Chinese.git
cd ChatLM-mini-Chinese本專案推薦使用python 3.10 ,過老的python版本可能不相容所依賴的第三方函式庫。
pip安裝:
pip install -r ./requirements.txt如果pip安裝了CPU版本的pytorch,可以透過下面的指令安裝CUDA版本的pytorch:
# pip 安装torch + cu118
pip3 install torch --index-url https://download.pytorch.org/whl/cu118conda安裝:
conda install --yes --file ./requirements.txt用git指令從Hugging Face Hub下載模型權重及設定文件,需要先安裝Git LFS,然後執行:
# 使用git命令下载huggingface模型,先安装[Git LFS],否则下载的模型文件不可用
git clone --depth 1 https://huggingface.co/charent/ChatLM-mini-Chinese
# 如果无法连接huggingface,请从modelscope下载
git clone --depth 1 https://www.modelscope.cn/charent/ChatLM-mini-Chinese.git
mv ChatLM-mini-Chinese model_save也可以直接從Hugging Face Hub倉庫ChatLM-Chinese-0.2B手動下載,將下載的檔案移到model_save目錄下即可。
語料要求盡可能全,建議增加多個語料,如百科、程式碼、論文、部落格、對話等。
本專案以wiki中文百科為主。取得中文wiki語料方法:中文Wiki下載位址:zhwiki,下載zhwiki-[存档日期]-pages-articles-multistream.xml.bz2文件,大概2.7GB,將下載的bz2檔案轉換為wiki.txt參考:WikiExtractor,再利用python的OpenCC函式庫轉換為簡體中文,最後將得到的wiki.simple.txt放到專案根目錄的data目錄下即可。多個語料請自行合併為一個txt檔案。
由於訓練tokenizer非常耗內存,如果你的語料非常大(合併後的txt檔案超過2G),建議對語料按照類別、比例進行採樣,以減少訓練時間和內存消耗。訓練1.7GB的txt檔案需要消耗48GB左右的記憶體(預估的,我只有32GB,頻繁觸發swap,電腦卡了好久T_T),13600k cpu耗時1小時左右。
char level和byte level的差異如下(具體使用上的差異請自行檢索資料)。預設訓練char level的tokenizer,如果需要byte level ,在train_tokenizer.py中設定token_type='byte'即可。
# 原始文本
txt = '这是一段中英混输的句子, (chinese and English, here are words.)'
tokens = charlevel_tokenizer . tokenize ( txt )
print ( tokens )
# char level tokens输出
# ['▁这是', '一段', '中英', '混', '输', '的', '句子', '▁,', '▁(', '▁ch', 'inese', '▁and', '▁Eng', 'lish', '▁,', '▁h', 'ere', '▁', 'are', '▁w', 'ord', 's', '▁.', '▁)']
tokens = bytelevel_tokenizer . tokenize ( txt )
print ( tokens )
# byte level tokens输出
# ['Ġè¿Ļæĺ¯', 'ä¸Ģ段', 'ä¸Ńèĭ±', 'æ··', 'è¾ĵ', 'çļĦ', 'åı¥åŃIJ', 'Ġ,', 'Ġ(', 'Ġch', 'inese', 'Ġand', 'ĠEng', 'lish', 'Ġ,', 'Ġh', 'ere', 'Ġare', 'Ġw', 'ord', 's', 'Ġ.', 'Ġ)']開始訓練:
# 确保你的训练语料`txt`文件已经data目录下
python train_tokenizer . py {
"prompt" : "对于花园街,你有什么了解或看法吗? " ,
"response" : "花园街(是香港油尖旺区的一条富有特色的街道,位于九龙旺角东部,北至界限街,南至登打士街,与通菜街及洗衣街等街道平行。现时这条街道是香港著名的购物区之一。位于亚皆老街以南的一段花园街,也就是"波鞋街"整条街约150米长,有50多间售卖运动鞋和运动用品的店舖。旺角道至太子道西一段则为排档区,售卖成衣、蔬菜和水果等。花园街一共分成三段。明清时代,花园街是芒角村栽种花卉的地方。此外,根据历史专家郑宝鸿的考证:花园街曾是1910年代东方殷琴拿烟厂的花园。纵火案。自2005年起,花园街一带最少发生5宗纵火案,当中4宗涉及排档起火。2010年。2010年12月6日,花园街222号一个卖鞋的排档于凌晨5时许首先起火,浓烟涌往旁边住宅大厦,消防接报4 "
}jupyter-lab 或jupyter notebook:
請參閱檔案train.ipynb ,建議使用jupyter-lab,避免考慮與伺服器斷開後終端進程被殺的情況。
控制台:
控制台訓練需要考慮連線中斷後進程被殺的,推薦使用進程守護工具Supervisor或screen建立連線會話。
首先要設定accelerate ,執行以下指令, 依照提示選擇即可,參考accelerate.yaml ,注意:DeepSpeed在Windows安裝比較麻煩。
accelerate config開始訓練,如果要使用工程提供的配置請在下面的命令accelerate launch後加上參數--config_file ./accelerate.yaml ,該配置按照單機2xGPU配置。
預訓練有兩個腳本,本項目實現的trainer對應train.py ,huggingface實現的trainer對應pre_train.py ,用哪個都可以,效果一致。本專案實現的trainer訓練資訊展示更美觀、更容易修改訓練細節(如損失函數,日誌記錄等),均支援斷點繼續訓練,本專案實現的trainer支援在任意位置斷點後繼續訓練,按ctrl+c退出腳本時會儲存斷點資訊。
單機單卡:
# 本项目实现的trainer
accelerate launch ./train.py train
# 或者使用 huggingface trainer
python pre_train.py單機多卡: 2為顯示卡數量,請依照自己的實際狀況修改。
# 本项目实现的trainer
accelerate launch --multi_gpu --num_processes 2 ./train.py train
# 或者使用 huggingface trainer
accelerate launch --multi_gpu --num_processes 2 pre_train.py從斷點繼續訓練:
# 本项目实现的trainer
accelerate launch --multi_gpu --num_processes 2 ./train.py train --is_keep_training=True
# 或者使用 huggingface trainer
# 需要在`pre_train.py`中的`train`函数添加`resume_from_checkpoint=True`
accelerate launch --multi_gpu --num_processes 2 pre_train.pySFT資料集全部來自BELLE大佬的貢獻,感謝。 SFT資料集分別為:generated_chat_0.4M、train_0.5M_CN和train_2M_CN,清洗後剩餘約137萬行。 sft指令微調資料集範例:
{
"prompt" : "解释什么是欧洲启示录" ,
"response" : "欧洲启示录(The Book of Revelation)是新约圣经的最后一卷书,也被称为《启示录》、《默示录》或《约翰默示录》。这本书从宗教的角度描述了世界末日的来临,以及上帝对世界的审判和拯救。 书中的主题包括来临的基督的荣耀,上帝对人性的惩罚和拯救,以及魔鬼和邪恶力量的存在。欧洲启示录是一个充满象征和暗示的文本,对于解读和理解有许多不同的方法和观点。 "
} data目錄下的範例parquet檔案製作自己的資料集,資料集格式: parquet檔案分兩列,一列prompt文本,表示提示語,一列response文本,表示期待的模型輸出。 微調細節請參閱model/trainer.py下的train方法, is_finetune設定為True時,將進行微調,微調預設會凍結embedding層和encoder層,只訓練decoder層。如需要凍結其他參數,請自行調整代碼。
運行SFT微調:
# 本项目实现的trainer, 添加参数`--is_finetune=True`即可, 参数`--is_keep_training=True`可从任意断点处继续训练
accelerate launch --multi_gpu --num_processes 2 ./train.py --is_finetune=True
# 或者使用 huggingface trainer, 多GPU请用accelerate launch --multi_gpu --num_processes gpu个数 sft_train.py
python sft_train.py偏好方法這裡介紹常見的兩種:PPO和DPO,具體實作請自行搜尋論文及部落格。
PPO方法(近似偏好優化,Proximal Policy Optimization)
步驟1:使用微調資料集做有監督微調(SFT, Supervised Finetuning)。
步驟2:使用偏好資料集(一個prompt至少包含2個回复,一個想要的回复,一個不想要的回复。多個回复可以按照分數排序,最想要的分數最高)訓練獎勵模型(RM, Reward Model)。可使用peft庫快速建置Lora獎勵模型。
步驟3:利用RM對SFT模型進行監督PPO訓練,使得模型滿足偏好。
使用DPO(直接偏好優化,Direct Preference Optimization)微調(本項目採用DPO微調方法,比較節省顯存) 在獲得SFT模型的基礎上,無需訓練獎勵模型,取得正向回答(chosen)和負向回答(rejected )即可開始微調。微調的chosen文字來自原資料集alpaca-gpt4-data-zh,拒絕文字rejected來自SFT微調1個epoch後的模型輸出,另外兩個資料集:huozi_rlhf_data_json和rlhf-reward-single-round-trans_chinese,合併後共8萬條dpo資料。
dpo資料集處理過程請參考utils/dpo_data_process.py 。
DPO偏好優化資料集範例:
{
"prompt" : "为给定的产品创建一个创意标语。,输入:可重复使用的水瓶。 " ,
"chosen" : " "保护地球,从拥有可重复使用的水瓶开始! " " ,
"rejected" : " "让你的水瓶成为你的生活伴侣,使用可重复使用的水瓶,让你的水瓶成为你的伙伴" "
}運行偏好優化:
# 多GPU请用accelerate launch --multi_gpu --num_processes gpu个数 dpo_train.py
python dpo_train.py確保model_save目錄下有以下文件,這些文件都可以在Hugging Face Hub倉庫ChatLM-Chinese-0.2B中找到:
ChatLM-mini-Chinese
├─model_save
| ├─config.json
| ├─configuration_chat_model.py
| ├─generation_config.json
| ├─model.safetensors
| ├─modeling_chat_model.py
| ├─special_tokens_map.json
| ├─tokenizer.json
| └─tokenizer_config.jsonpython cli_demo.pypython api_demo.pyAPI呼叫範例:
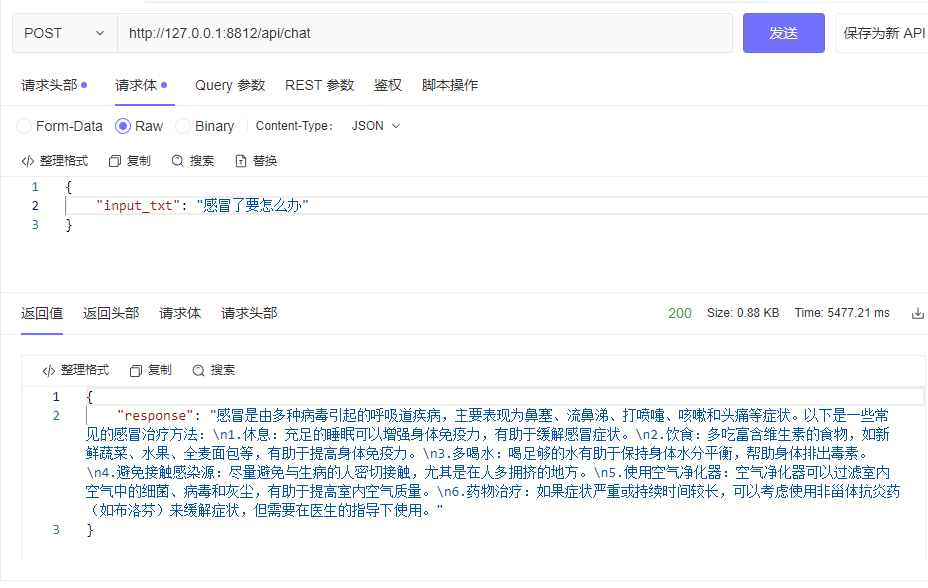
curl --location ' 127.0.0.1:8812/api/chat '
--header ' Content-Type: application/json '
--header ' Authorization: Bearer Bearer '
--data ' {
"input_txt": "感冒了要怎么办"
} ' 
這裡以文本中三元組資訊為例,做下游微調。此任務的傳統深度學習抽取方法請參考倉庫pytorch_IE_model。抽取一段文本中所有的三元組,如句子《写生随笔》是冶金工业2006年出版的图书,作者是张来亮,抽取出三元組(写生随笔,作者,张来亮)和(写生随笔,出版社,冶金工业) 。
原始資料集為:百度三元組抽取資料集。加工得到的微調資料集格式範例:
{
"prompt" : "请抽取出给定句子中的所有三元组。给定句子:《家乡的月亮》是宋雪莱演唱的一首歌曲,所属专辑是《久违的哥们》 " ,
"response" : " [(家乡的月亮,歌手,宋雪莱),(家乡的月亮,所属专辑,久违的哥们)] "
}可以直接使用sft_train.py腳本進行微調,腳本finetune_IE_task.ipynb裡麵包含詳細的解碼過程。訓練資料集約17000條,學習率5e-5 ,訓練epoch 5 。微調後其他任務的對話能力也沒有消失。

微調效果:將百度三元组抽取数据集公開的dev資料集作為測試集,比較傳統方法pytorch_IE_model。
| 模型 | F1分數 | 精確率P | 召回率R |
|---|---|---|---|
| ChatLM-Chinese-0.2B微調 | 0.74 | 0.75 | 0.73 |
| ChatLM-Chinese-0.2B無預訓練 | 0.51 | 0.53 | 0.49 |
| 傳統深度學習方法 | 0.80 | 0.79 | 80.1 |
備註: ChatLM-Chinese-0.2B无预训练指直接初始化隨機參數,開始訓練,學習率1e-4 ,其他參數和微調一致。
模型本身沒有使用較大的資料集訓練,也沒有針對回答選擇題的指令做微調,C-Eval分數基本上是baseline水平,有需要的可以當個參考。 C-Eval評測程式碼請見: eval/c_eavl.ipynb
| category | correct | question_count | accuracy |
|---|---|---|---|
| Humanities | 63 | 257 | 24.51% |
| Other | 89 | 384 | 23.18% |
| STEM | 89 | 430 | 20.70% |
| Social Science | 72 | 275 | 26.18% |
如果你覺得本項目對你有幫助,歡迎引用。
@misc{Charent2023,
author={Charent Chen},
title={A small chinese chat language model with 0.2B parameters base on T5},
year={2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/charent/ChatLM-mini-Chinese}},
}
本專案不承擔開源模型和程式碼導致的資料安全、輿情風險或發生任何模型被誤導、濫用、傳播、不當利用而產生的風險和責任。


