featuretools
v1.31.0
“機器學習的聖杯之一是使越來越多的特徵工程過程自動化。” ——Pedro Domingos,關於機器學習的一些有用知識

Featuretools 是一個用於自動化特徵工程的 Python 函式庫。請參閱文件以取得更多資訊。
使用 pip 安裝
python -m pip install featuretools
或來自 conda 上的 Conda-forge 頻道:
conda install -c conda-forge featuretools
您可以透過執行以下命令單獨或一次安裝所有附加元件:
python -m pip install "featuretools[complete]"
Premium Primitives - 使用 premium-primitives 儲存庫中的 Premium Primitives
python -m pip install "featuretools[premium]"
NLP 原語- 使用 nlp-primitives 儲存庫中的自然語言原語
python -m pip install "featuretools[nlp]"
Dask 支援- 使用 Dask 運行 DFS,njobs > 1
python -m pip install "featuretools[dask]"
以下是使用深度特徵合成(DFS)執行自動化特徵工程的範例。在此範例中,我們將 DFS 套用於由帶有時間戳記的客戶交易組成的多表資料集。
>> import featuretools as ft
>> es = ft . demo . load_mock_customer ( return_entityset = True )
>> es . plot ()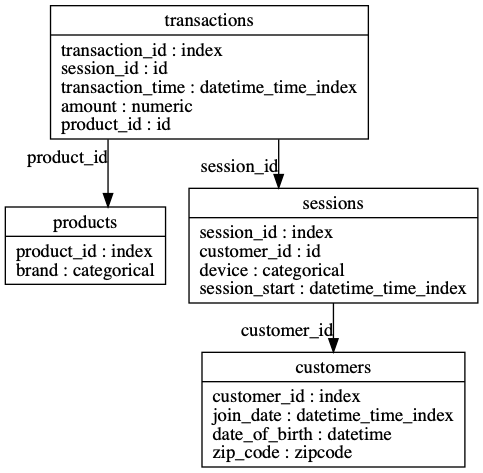
特徵工具可以自動為任何「目標資料框」建立單一特徵表
>> feature_matrix , features_defs = ft . dfs ( entityset = es , target_dataframe_name = "customers" )
>> feature_matrix . head ( 5 ) zip_code COUNT(transactions) COUNT(sessions) SUM(transactions.amount) MODE(sessions.device) MIN(transactions.amount) MAX(transactions.amount) YEAR(join_date) SKEW(transactions.amount) DAY(join_date) ... SUM(sessions.MIN(transactions.amount)) MAX(sessions.SKEW(transactions.amount)) MAX(sessions.MIN(transactions.amount)) SUM(sessions.MEAN(transactions.amount)) STD(sessions.SUM(transactions.amount)) STD(sessions.MEAN(transactions.amount)) SKEW(sessions.MEAN(transactions.amount)) STD(sessions.MAX(transactions.amount)) NUM_UNIQUE(sessions.DAY(session_start)) MIN(sessions.SKEW(transactions.amount))
customer_id ...
1 60091 131 10 10236.77 desktop 5.60 149.95 2008 0.070041 1 ... 169.77 0.610052 41.95 791.976505 175.939423 9.299023 -0.377150 5.857976 1 -0.395358
2 02139 122 8 9118.81 mobile 5.81 149.15 2008 0.028647 20 ... 114.85 0.492531 42.96 596.243506 230.333502 10.925037 0.962350 7.420480 1 -0.470007
3 02139 78 5 5758.24 desktop 6.78 147.73 2008 0.070814 10 ... 64.98 0.645728 21.77 369.770121 471.048551 9.819148 -0.244976 12.537259 1 -0.630425
4 60091 111 8 8205.28 desktop 5.73 149.56 2008 0.087986 30 ... 83.53 0.516262 17.27 584.673126 322.883448 13.065436 -0.548969 12.738488 1 -0.497169
5 02139 58 4 4571.37 tablet 5.91 148.17 2008 0.085883 19 ... 73.09 0.830112 27.46 313.448942 198.522508 8.950528 0.098885 5.599228 1 -0.396571
[5 rows x 69 columns]
現在,我們為每位客戶提供了一個可用於機器學習的特徵向量。有關更多範例,請參閱有關深度特徵綜合的文件。
Featuretools 包含許多不同類型的用於建立特徵的內建基元。如果未包含您需要的基元,Featuretools 還允許您定義自己的自訂基元。
預測下次購買
儲存庫 |筆記本
在此演示中,我們使用來自 Instacart 的 300 萬個線上雜貨訂單的多表資料集來預測客戶接下來會購買什麼。我們展示瞭如何透過自動化特徵工程產生特徵,並使用Featuretools建立準確的機器學習管道,該管道可重複用於多個預測問題。對於更高級的用戶,我們展示瞭如何使用 Dask 將管道擴展到大型資料集。
有關如何使用 Featuretools 的更多範例,請查看我們的示範頁面。
Featuretools 社區歡迎拉取請求。此處提供了測試和開發說明。
Featuretools 社群很樂意為 Featuretools 用戶提供支援。根據問題類型,可以在四個地方找到專案支援:
featuretools標籤。如果您使用Featuretools,請考慮引用以下論文:
詹姆斯·馬克斯·坎特,卡揚·維拉馬查內尼。深度特徵綜合:實現資料科學工作自動化。 IEEE DSAA 2015 。
BibTeX 條目:
@inproceedings { kanter2015deep ,
author = { James Max Kanter and Kalyan Veeramachaneni } ,
title = { Deep feature synthesis: Towards automating data science endeavors } ,
booktitle = { 2015 {IEEE} International Conference on Data Science and Advanced Analytics, DSAA 2015, Paris, France, October 19-21, 2015 } ,
pages = { 1--10 } ,
year = { 2015 } ,
organization = { IEEE }
}Featuretools是由 Alteryx 維護的開源專案。若要查看我們正在開發的其他開源項目,請造訪 Alteryx 開源。如果建立有影響力的數據科學管道對您或您的企業很重要,請與我們聯繫。


