interviews.ai
1.0.0
下載 PDF • 關於 • 勘誤表 •

“不斷學習,否則就有變得無關緊要的風險。”
在第一卷中,我特意呈現了資料科學領域連貫、累積和特定內容的核心課程,包括資訊理論、貝葉斯統計、演算法微分、邏輯迴歸、感知器和卷積神經網路等主題。我希望你會發現這本書很刺激。
我相信,本書主要針對的研究生和求職者將會從閱讀本書中受益;然而,我希望即使是最有經驗的研究人員也會發現它很有趣。
聯繫阿米爾:
https://www.linkedin.com/in/amirivry/
https://scholar.google.com.mx/itations?user=rQCVwksAAAAJ&hl=iw
聯絡什洛莫:
https://www.linkedin.com/in/quantscientist/
https://scholar.google.com.mx/itations?user=bM0LGgcAAAAJ&hl
本書可透過亞馬遜和其他標準分銷管道購買。請造訪出版商的網頁訂購該書或取得有關其出版的更多詳細資訊。書的手稿如下:僅供個人使用,不得出售。
https://amazon.com/author/quantscientist
https://arxiv.org/abs/2201.00650
@misc{kashani2021deep,
title={Deep Learning Interviews: Hundreds of fully solved job interview questions from a wide range of key topics in AI},
author={Shlomo Kashani and Amir Ivry},
year={2021},
eprint={2201.00650},
note = {ISBN 13: 978-1-9162435-4-5 },
url = {https://www.interviews.ai},
archivePrefix={arXiv},
primaryClass={cs.LG}
}嚴格禁止銷售或商業用途。此電子資源的使用者權利在下面的授權協議中指定。您只能將本電子資源用於私人學習目的。嚴禁出售/轉售其內容。
這本書(www.interviews.ai)是為你而寫的:一位有抱負的、具有定量背景的資料科學家,在競爭日益激烈的領域面臨面試過程的挑戰。對大多數人來說,面試過程是您與夢想工作之間最大的障礙。即使您有能力、背景和動力在目標職位上取得優異成績,您可能仍需要一些指導來了解如何踏入職場。
《深度學習訪談》第二版(亞馬遜平裝版以黑白印刷)包含數百個已完全解決的問題,涉及人工智慧領域的廣泛關鍵主題。它旨在排練面試或考試特定主題,並提供機器學習碩士/博士學位。學生和等待面試的人對該領域有條理的概述。它提出的問題足夠棘手,足以讓你初步解決並顯著提高你的技能,但它們都包含在發人深省的問題和引人入勝的故事中。
這就是本書對學生和求職者特別有價值的原因:它使他們能夠自信、快速地談論任何相關主題,清晰、正確地回答技術問題,並充分理解面試問題的目的和含義。當走進面試室時,這些都是強大且不可或缺的優勢。
本書的內容包含大量與 DL 工作面試和研究生程度考試相關的主題。這使得這項工作處於科學發展趨勢的前沿,教授一套核心的實用數學和計算技能。人們普遍認為,每個電腦科學家的訓練都必須包括機器學習的基本定理,而人工智慧幾乎出現在每所大學的課程中。本書旨在為此類課程的畢業生提供極佳的參考資料。
這本書有近400頁
數百個完全解決的問題
來自深度學習眾多領域的問題
清晰的圖表和插圖
綜合指數
逐步解決問題
不只是給出的答案,還有展示的工作
不僅是展示的作品,還有適當的推理
這本書是為你而寫的:一位有定量背景、有抱負的資料科學家,在競爭日益激烈的領域面臨面試過程的挑戰。對大多數人來說,面試過程是您與夢想工作之間最大的障礙。即使您有能力、背景和動力在目標職位上取得優異成績,您可能仍需要一些指導來了解如何踏入職場。您的好奇心將引導您完成本書的問題集、公式和說明,隨著您的進步,您將加深對深度學習的理解。微積分、邏輯迴歸、熵和深度學習理論之間存在著錯綜複雜的關聯;讀完這本書,這些連結就會變得直觀。
本書的第一卷重點在於統計觀點,並將背景基礎知識與核心思想和實踐知識結合。有專門的章節介紹:
資訊理論
微積分與演算法微分
貝葉斯深度學習與機率編程
邏輯迴歸
整合學習
特徵提取
深度學習:擴充章節(100 多頁)
這些章節與深度學習主題的大量深入討論一起出現,並提供 PyTorch、Python 和 C++ 中的程式碼範例。
「PyTorch」是 Facebook 的商標。
版權所有 © Shlomo Kashani,《深度學習訪談》一書的作者 Shlomo Kashani, 《深度學習訪談》一書的作者 www.interviews.ai:[email protected]
感謝所有指出這些問題的讀者。 2020 年 3 月 12 日印刷版和線上版本中反映的勘誤表:
由於缺乏清晰度,問題號PRB-267 -CH.PRB- 8.91已被刪除
由於缺乏清晰度,問題號PRB-115 - CH.PRB- 5.16已被刪除
2020 年 5 月 12 日印刷版和線上版本中反映的勘誤表:
第 230 頁,問題號PRB-178將「啟動交叉驗證」修改為「分層交叉驗證」。
第 231 頁,問題號PRB-181在資料折疊後新增了“.”
第 231 頁,問題號PRB-191將“an”修改為“a”
第 234 頁,問題編號PRB-192 “in”重複兩次
第 236 頁,問題號PRB-194 將“approached”修改為“approaches”,將“arr”修改為“arr001”
第 247 頁,問題號PRB-210 將“an”修改為“a”
第 258 頁,問題號PRB-227 將“混淆度量”修改為“混淆矩陣”
第271頁,問題號PRB-240將“MaxPool2D(4,4,)”修改為“MaxPool2D(4,4)”
第273頁,問題號PRB-243將“身份”修改為“識別”
第281頁,問題號PRB-254將“建議”修改為“建議”
第 283 頁,問題編號PRB-256 “happening”拼字錯誤
第286頁“L1、L2”修改為“規範”
第 288 頁,問題編號SOL-184將“完整”修改為“是完整”
第298頁,問題編號SOL-208將“ou1”修改為“out”
第 319 頁,問題號SOL-240修正「torch.Size([1, 32, 222, 222])」。 到“torch.size([1, 32, 222, 222]).“
第 283 頁,問題編號PRB-256 “happening”拼字錯誤
2020 年 7 月 12 日印刷版和線上版本中反映的勘誤表:
第 187 頁,問題編號PRB-140兩個缺失圖(6.3、6.4)在列印版本上未正確呈現
6.3
6.4 2020 年 9 月 21 日印刷版本和線上版本中反映的勘誤表:
第 34 頁,溶液編號SOL- 19,0.21886 應為 0.21305,0.21886 ± 1.95 × 0.21886 應為0.21305 ± 1.95 × 0.21886
第 36-7 頁,解編號SOL-21 ,4.8792/0.0258 = 189.116而非 57.3 且 pi(33) = 0.01748 而非 pi(33) = 0.211868 。
第 49 頁, PRB-47 “專家是猴子的機率是多少”應該是“專家是人類的機率是多少”
2020 年 9 月 22 日印刷版和線上版本中反映的勘誤表:
第 73 頁,解編號SOL-56應為“Hessian 矩陣是透過微分產生的”
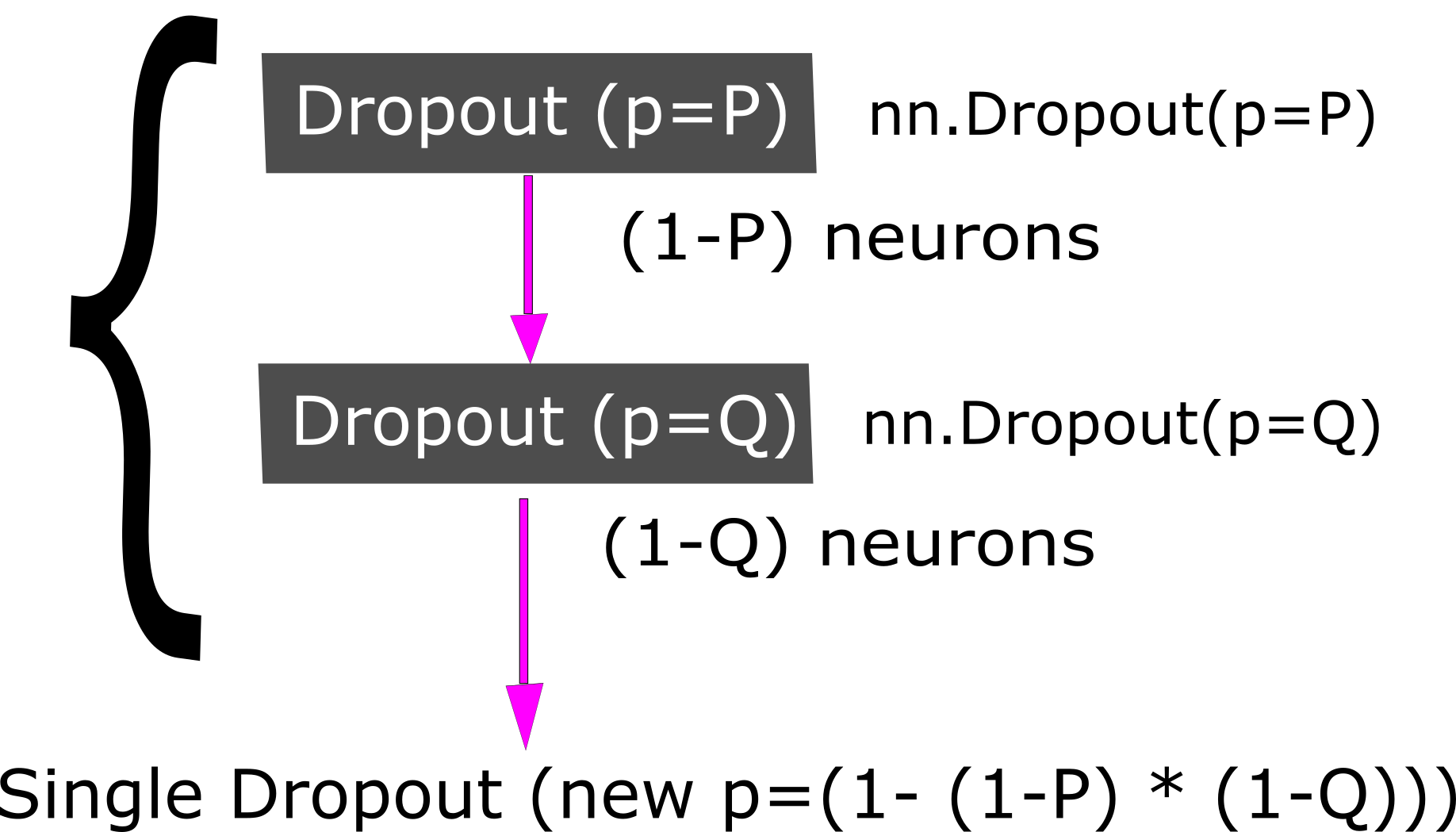
第 57 頁,問題編號PRB-65應為“兩個神經元”
2020 年 9 月 24 日印刷版和線上版本中反映的勘誤表:
第 78 頁,解編號SOL-64 ,只有當 200 個神經元中至少有 150 個關閉時,OnOffLayer 才會關閉。因此,這可以表示為二項式分佈,並且該層關閉的機率為:


