dialog eval
1.0.0
一個輕量級儲存庫,用於使用17 個指標自動評估對話模型。
? 選擇您想要計算的指標
評估可以在回應檔案或包含多個檔案的目錄上自動執行
? 指標以預先定義的易於處理的格式保存
執行此命令來安裝所需的軟體包:
pip install -r requirements.txt
主檔案可以從任何地方調用,但是在指定目錄路徑時,您應該從儲存庫的根目錄給出它們。
python code/main.py -h
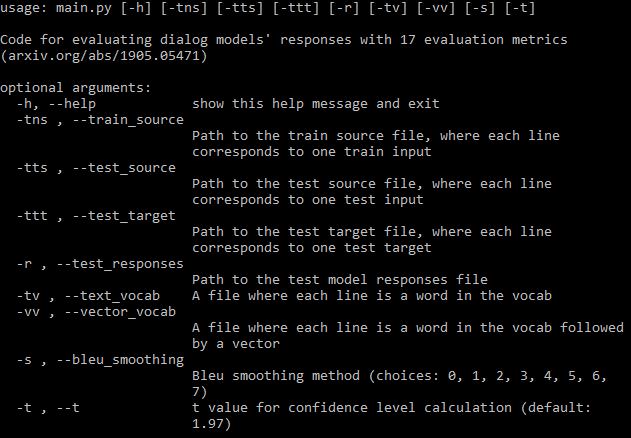
如需完整文檔,請造訪 wiki。
您應該提供盡可能多的所需參數路徑(上圖)。如果您錯過了一些,程式仍然會運行,但它不會計算需要這些文件的一些指標(它將列印這些指標)。如果您有訓練資料文件,程式可以自動產生詞彙表並下載 fastText 嵌入。
如果您不想計算所有指標,您可以非常輕鬆地設定應在設定檔中計算哪些指標。
文件將保存到響應文件所在的目錄中。第一行包含指標的名稱,然後每行包含一個檔案的指標。檔案名稱後面跟著由空格分隔的各個指標值。每個指標由三個以逗號分隔的數字組成:平均值、標準差和信賴區間。您可以在參數中設定置信區間的 t 值,預設值為 95% 置信度。
有趣的是,在 DailyDialog 上訓練 Transformer 模型期間,所有 17 個指標都會改善直到某個點,然後停滯不前,不會發生過擬合。檢查論文附錄中的數字。 
TRF 是在驗證損失最小值下評估的 Transformer 模型,TRF-O 是在 150 個 epoch 訓練後評估的 Transformer 模型,其中指標開始停滯。 RT 表示從訓練集中隨機選擇的反應,GT 表示真實反應。

TRF 是 Transformer 模型,RT 是指從訓練集中隨機選擇的反應,GT 是指真實反應。這些結果是在驗證損失最小的檢查點在測試集上測量的。

TRF 是 Transformer 模型,RT 是指從訓練集中隨機選擇的反應,GT 是指真實反應。這些結果是在驗證損失最小的檢查點在測試集上測量的。
可以透過為指標建立一個類別來新增指標,該類別處理給定資料的指標計算。查看 BLEU 指標的範例。通常,init 函數會處理稍後需要的任何資料設置,並且 update_metrics 使用參數中的當前範例更新指標字典。在類別中,您應該定義 self.metrics 字典,它儲存給定測試檔案的指標值清單。這些指標的名稱(字典的按鍵)也應該添加到設定檔 self.metrics 中。最後,您需要將度量類別的實例新增到 self.objects 中。如果您的指標需要任何設置,則在初始化時您可以使用資料檔案的路徑。此後,您的指標應該會自動計算並保存。
但是,您也應該為指標添加一些約束,例如,如果指標計算所需的文件遺失,則應通知用戶,如下所示。
該項目根據 MIT 許可證獲得許可 - 有關詳細信息,請參閱許可證文件。
如果您在工作中使用該存儲庫,請包含該存儲庫的鏈接,並考慮引用以下論文:
@inproceedings{Csaky:2019,
title = "Improving Neural Conversational Models with Entropy-Based Data Filtering",
author = "Cs{'a}ky, Rich{'a}rd and Purgai, Patrik and Recski, G{'a}bor",
booktitle = "Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics",
month = jul,
year = "2019",
address = "Florence, Italy",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/P19-1567",
pages = "5650--5669",
}


