LLaMA_MPS
1.0.0
在Apple Silicon GPU 上執行LLaMA(和Stanford-Alpaca)推理。
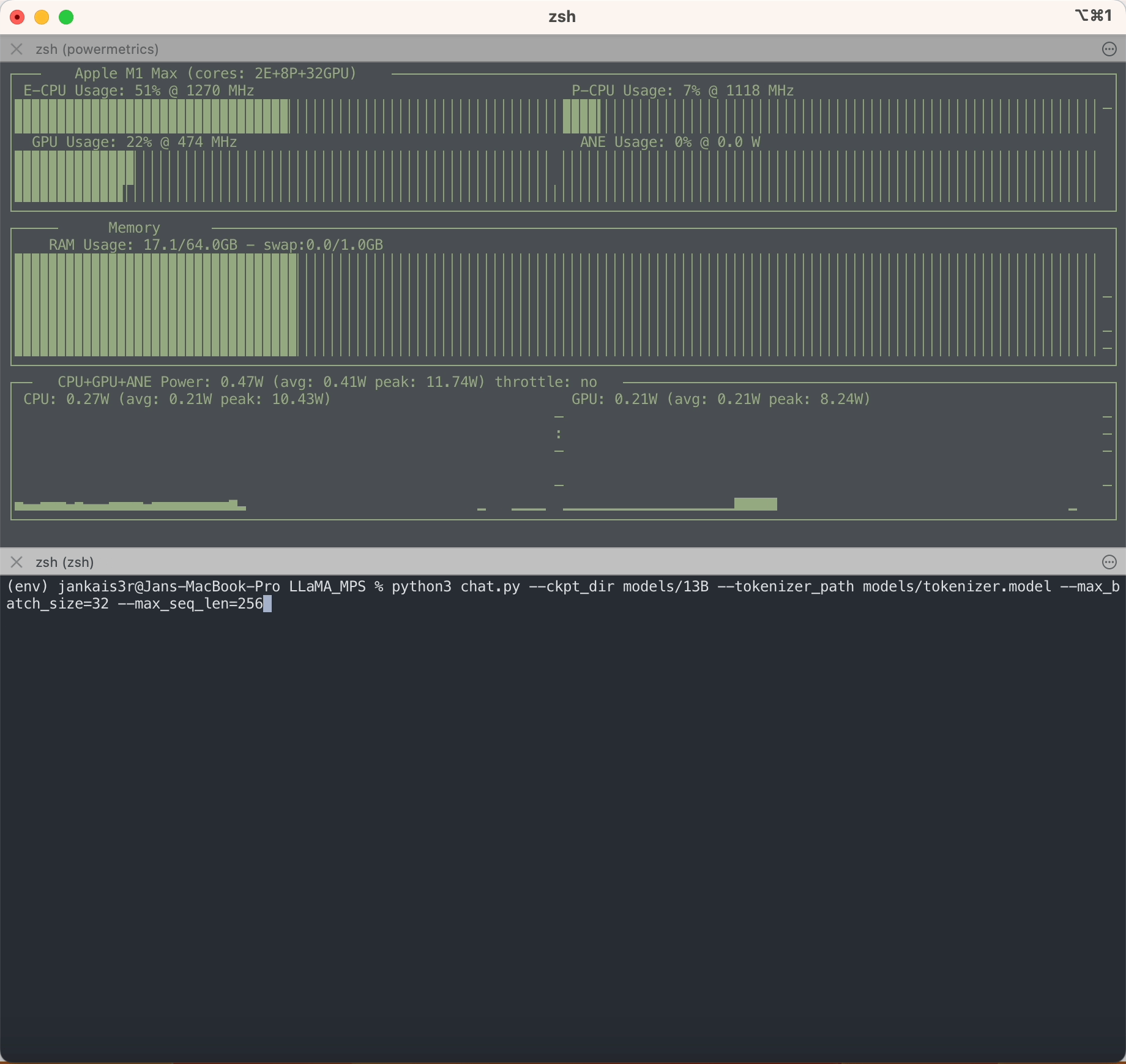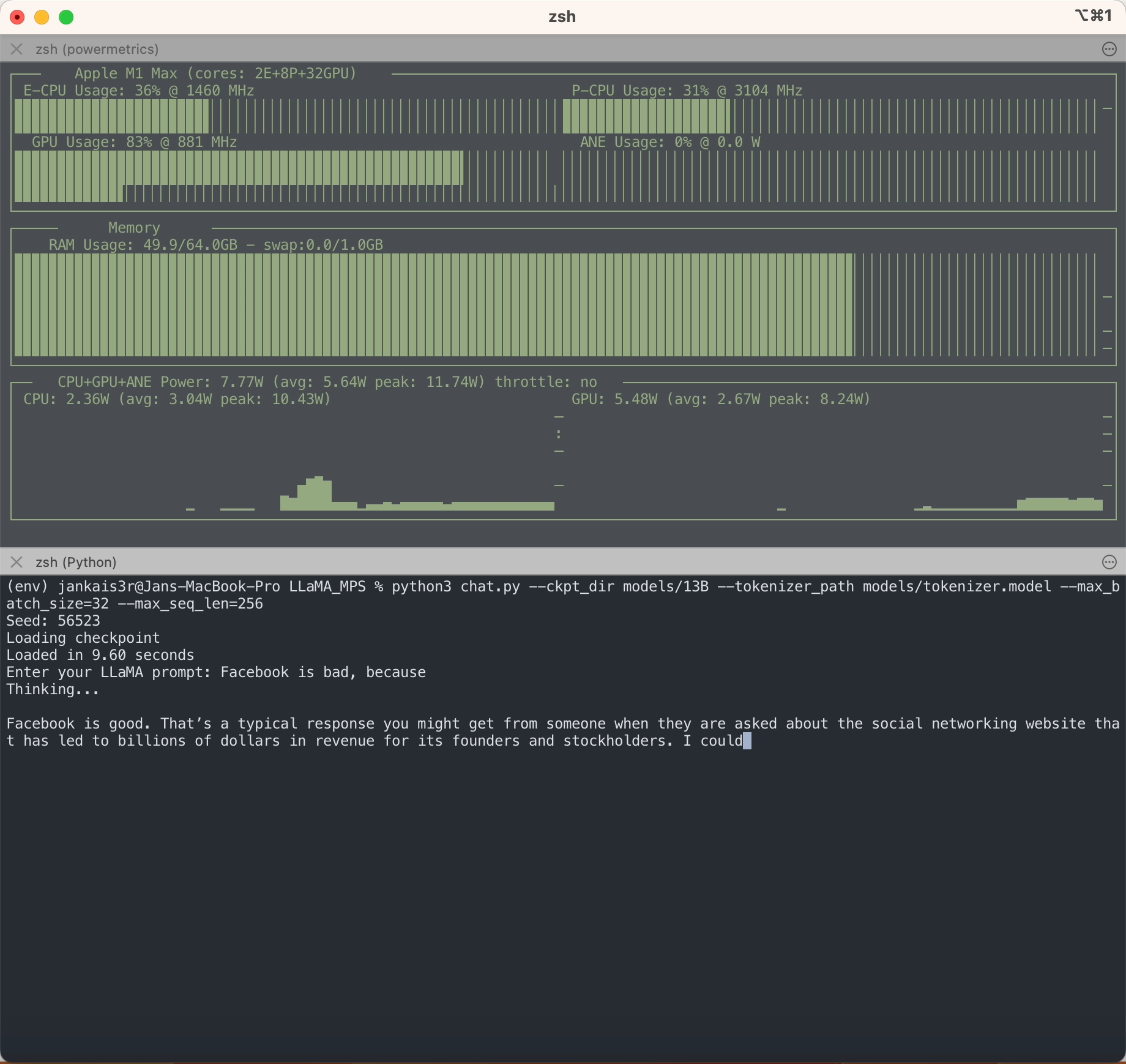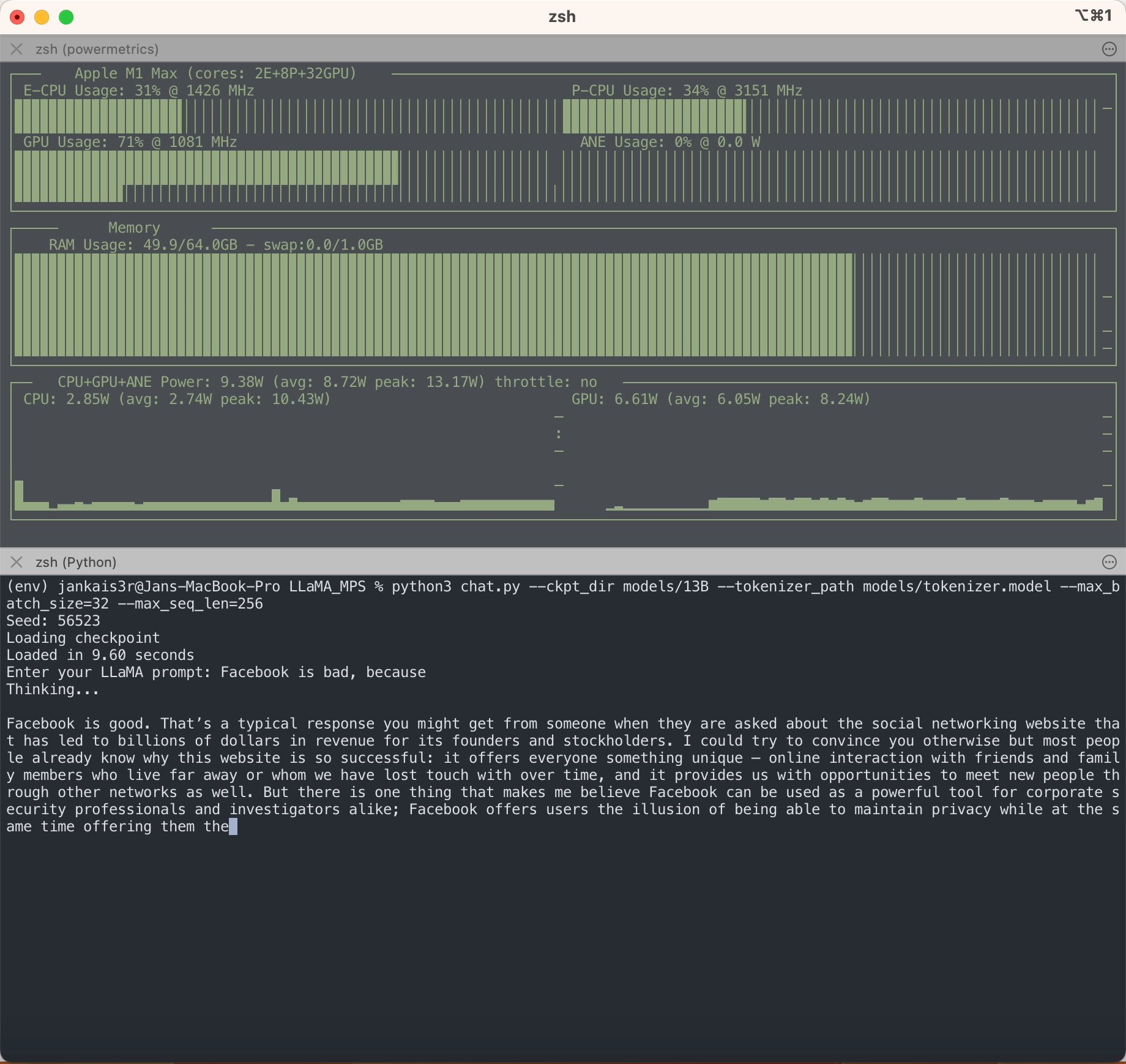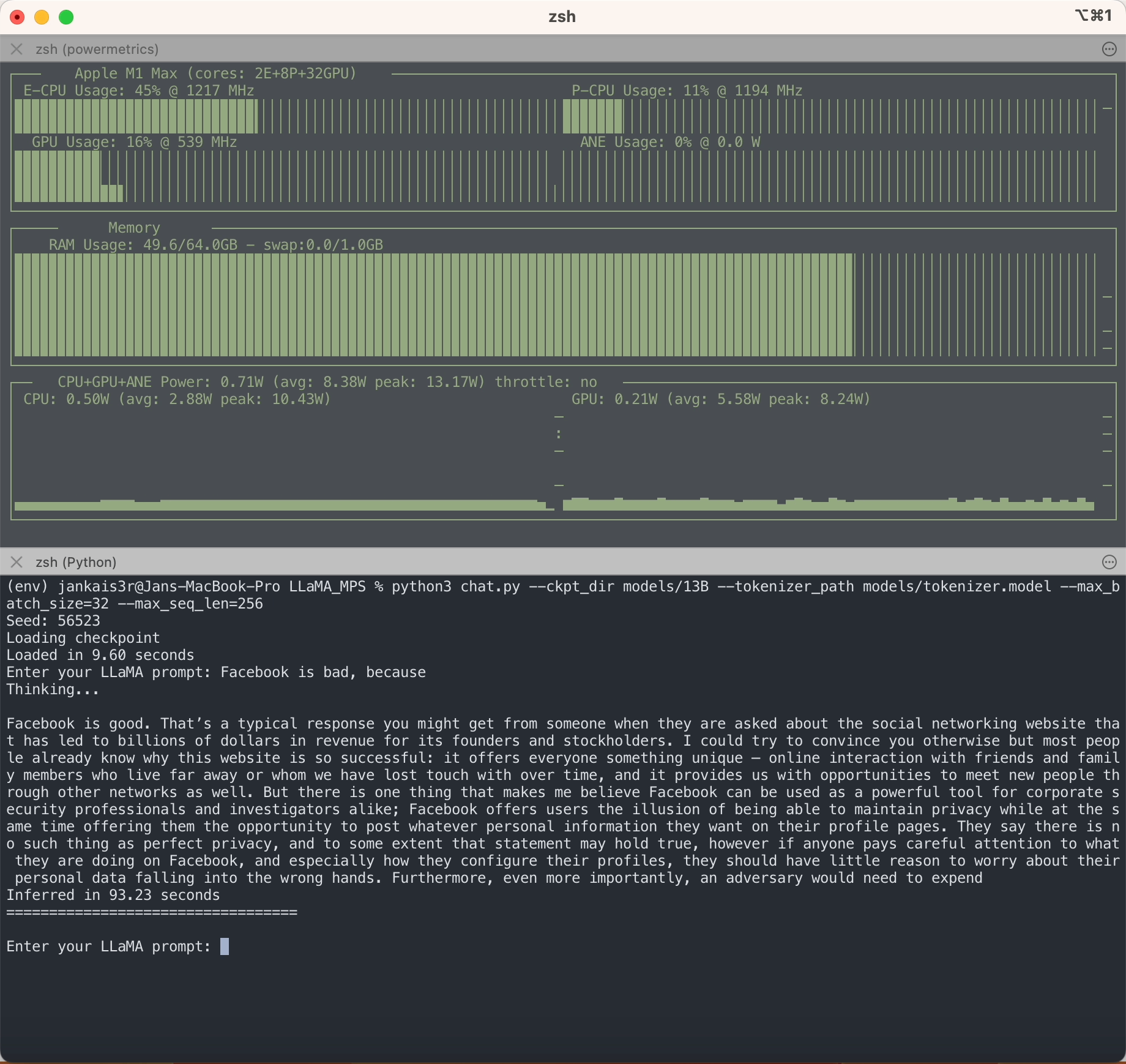
正如您所看到的,與其他法學碩士不同,LLaMA 沒有任何偏見?
1. 克隆這個倉庫
git clone https://github.com/jankais3r/LLaMA_MPS
2.安裝Python依賴
cd LLaMA_MPS
pip3 install virtualenv
python3 -m venv env
source env/bin/activate
pip3 install -r requirements.txt
pip3 install -e .3. 下載模型權重並將其放入名為models的資料夾中(例如LLaMA_MPS/models/7B )
4. (可選)重新分片模型權重(13B/30B/65B)
由於我們在單一 GPU 上執行推理,因此需要將較大模型的權重合併到單一檔案中。
mv models/13B models/13B_orig
mkdir models/13B
python3 reshard.py 1 models/13B_orig models/13B5. 運行推理
python3 chat.py --ckpt_dir models/13B --tokenizer_path models/tokenizer.model --max_batch_size 8 --max_seq_len 256
上述步驟將讓您在「自動完成」模式下對原始 LLaMA 模型運行推理。
如果您想使用斯坦福羊駝的微調權重嘗試類似於 ChatGPT 的“指令-響應”模式,請按照以下步驟繼續設定:
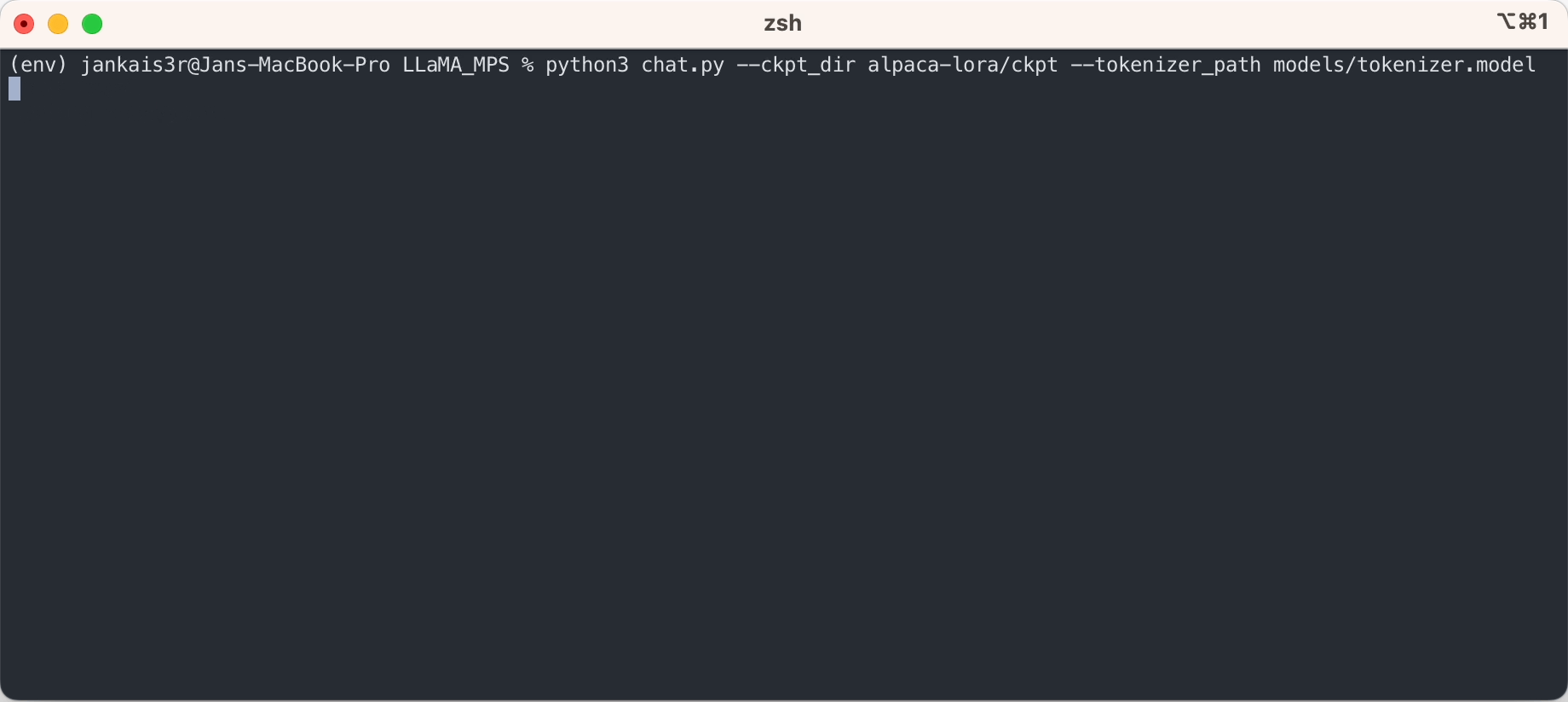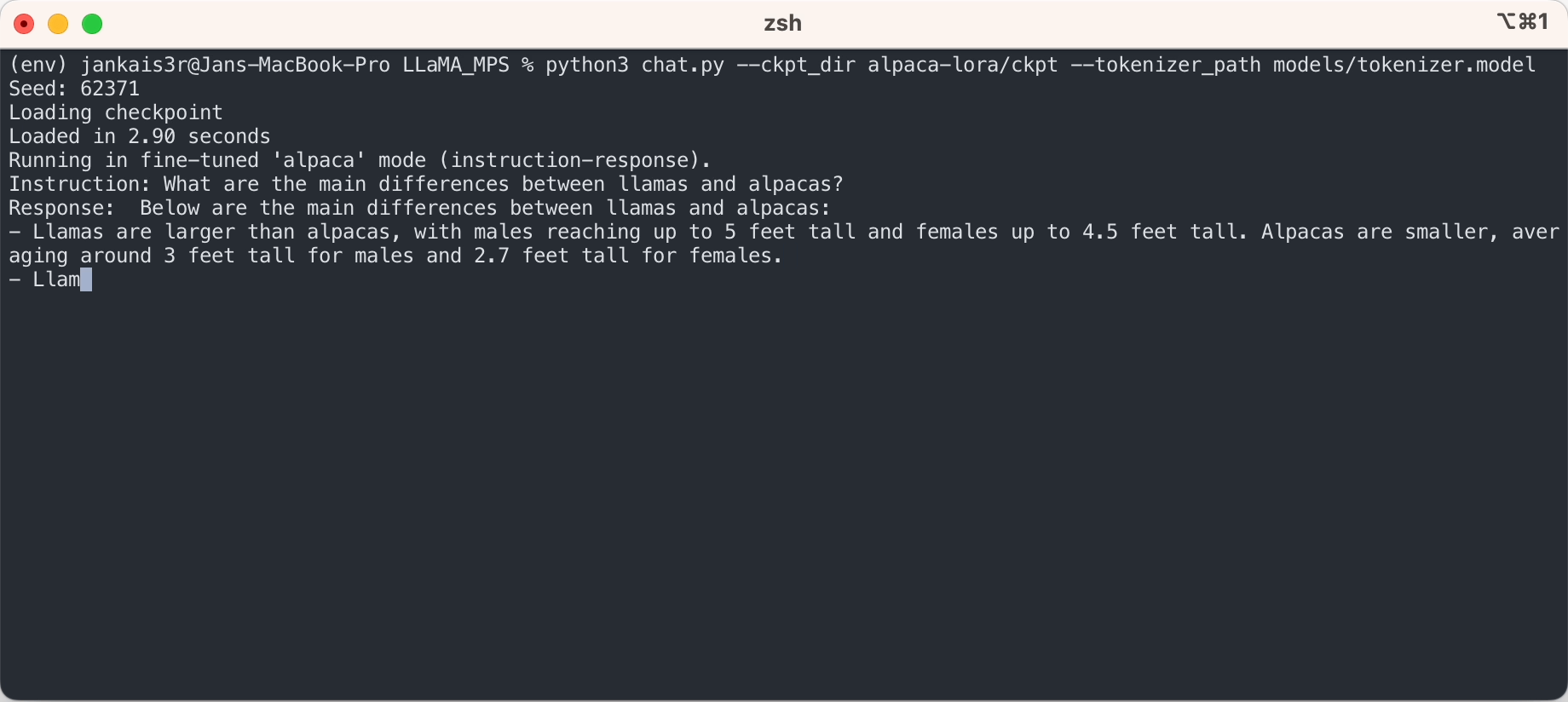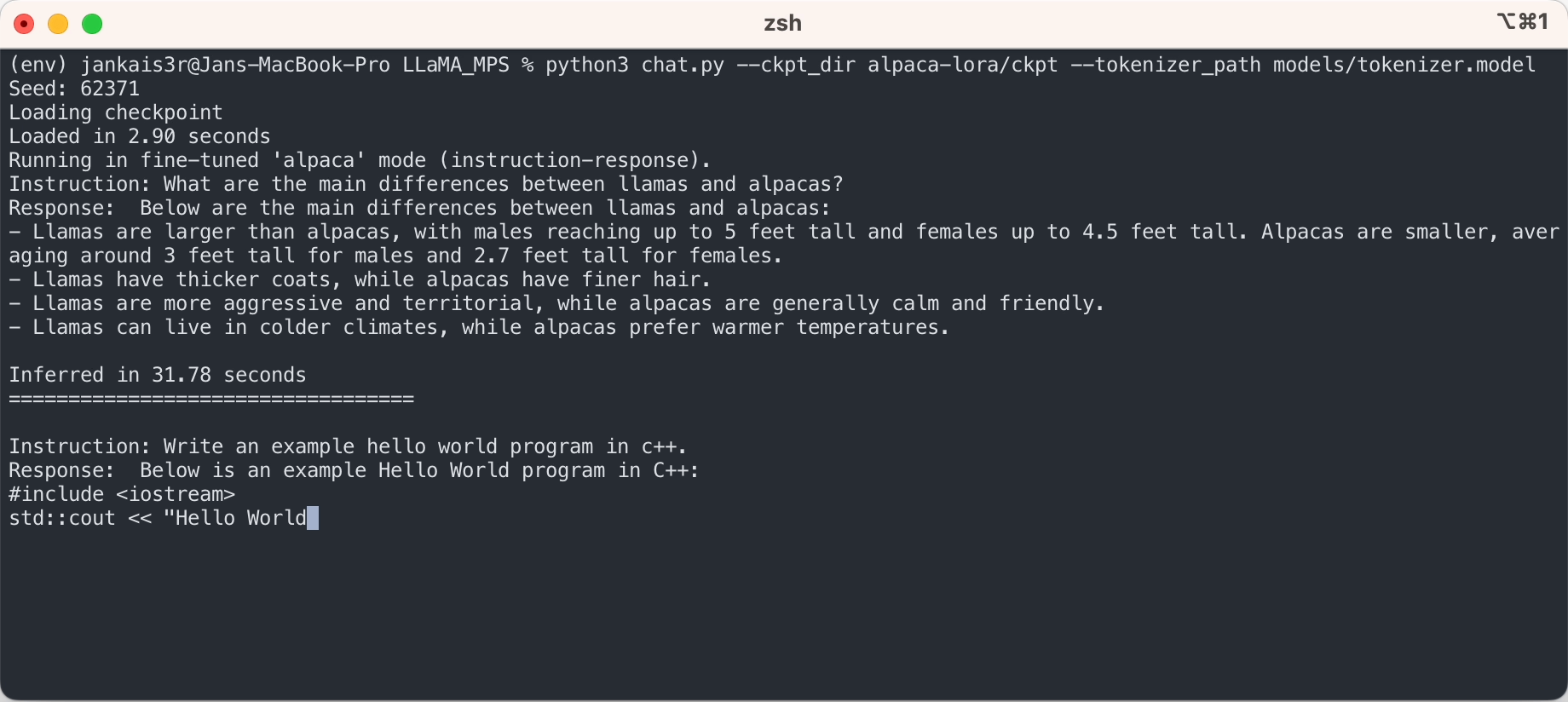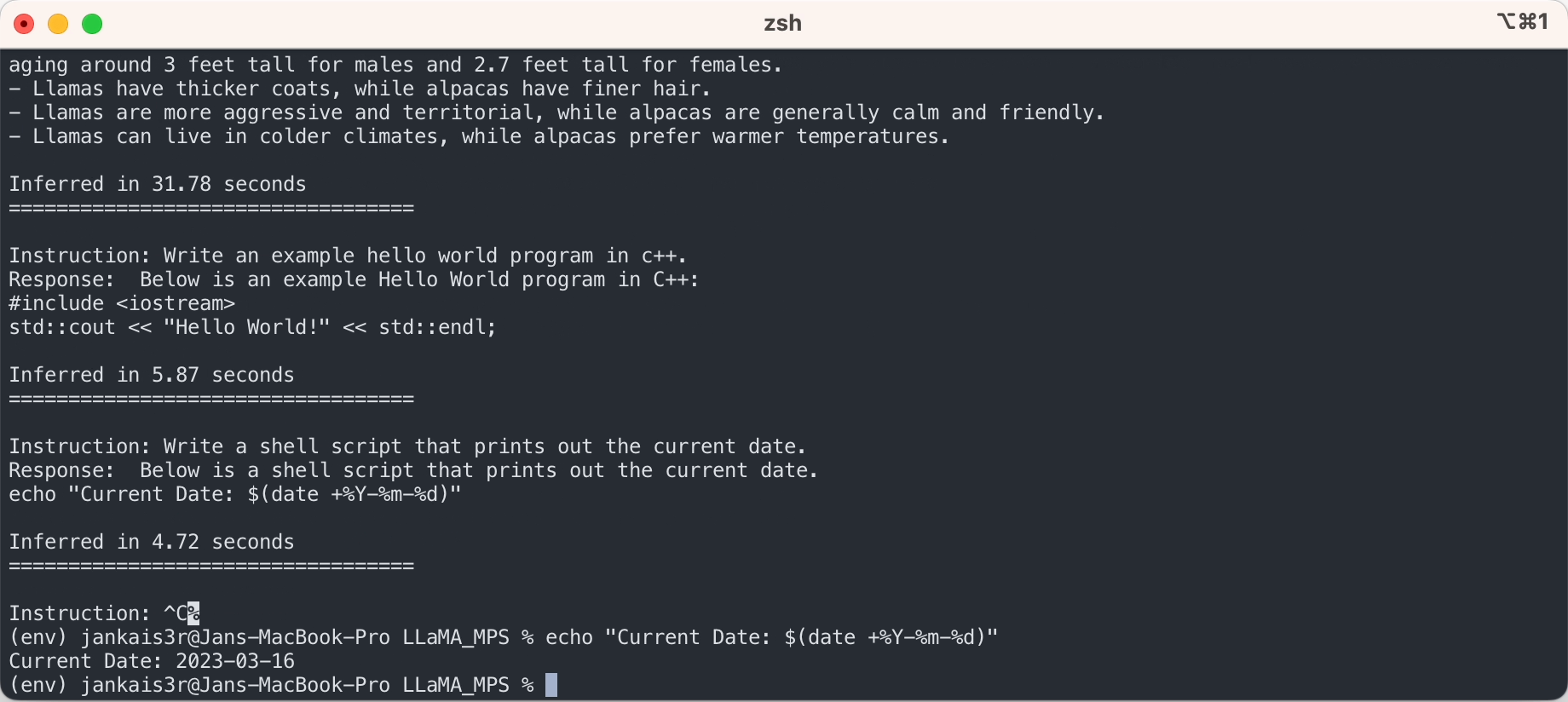
3.下載微調後的權重(7B/13B可用)
python3 export_state_dict_checkpoint.py 7B
python3 clean_hf_cache.py4. 運行推理
python3 chat.py --ckpt_dir models/7B-alpaca --tokenizer_path models/tokenizer.model --max_batch_size 8 --max_seq_len 256
| 模型 | 推理期間啟動內存 | 檢查點轉換期間的峰值內存 | 重新分片期間的峰值內存 |
|---|---|---|---|
| 7B | 16 GB | 14GB | 不適用 |
| 13B | 32GB | 37GB | 45GB |
| 30B | 66GB | 76GB | 125GB |
| 65B | ??國標 | ??國標 | ??國標 |
每個型號的最低規格(由於交換而緩慢):
每個型號的建議規格:
- 最大批量大小
如果您有空閒記憶體(例如,在 64 GB Mac 上執行 13B 模型時),您可以使用--max_batch_size=32參數來增加批次大小。預設值為1 。
- 最大序列長度
若要增加/減少生成文字的最大長度,請使用--max_seq_len=256參數。預設值為512 。
- 使用重複懲罰
此範例腳本對產生重複內容的模型進行懲罰。這應該會帶來更高品質的輸出,但會稍微減慢推理速度。使用--use_repetition_penalty=False參數執行腳本以停用懲罰演算法。
對於 Apple Silicon 用戶來說,LLaMA_MPS 的最佳替代方案是 llama.cpp,它是一個 C/C++ 重新實現,純粹在 SoC 的 CPU 部分上運行推理。由於編譯後的 C 程式碼比 Python 快得多,因此它實際上可以在速度上擊敗 MPS 實現,但代價是功耗和熱效率要差得多。
在決定哪種實作更適合您的用例時,請參閱以下比較。
| 執行 | 總運行時間 - 256 個令牌 | 令牌/秒 | 記憶體使用峰值 | 峰值 SoC 溫度 | 峰值 SoC 功耗 | 每 1 Wh 代幣 |
|---|---|---|---|---|---|---|
| LLAMA_MPS (13B fp16) | 75秒 | 3.41 | 30GB | 79℃ | 10瓦 | 1,228.80 |
| 駱駝.cpp (13B fp16) | 70年代 | 3.66 | 25GB | 106℃ | 35瓦 | 376.16 |


