Seq2seq Chatbot for Keras
1.0.0
該儲存庫包含基於 seq2seq 建模的新聊天機器人生成模型。有關該模型的更多詳細信息,請參閱論文“生成對話代理的端到端對抗學習”的第 3 節。如果使用此儲存庫中的想法或程式碼片段進行發布,請引用本文。
此處可用的訓練模型使用由約 8K 對上下文(截至當前點的對話的最後兩個話語)和相應回應組成的小型資料集。數據是從線上英語課程的對話中收集的。這種經過訓練的模型可以使用封閉域資料集針對實際應用進行微調。
規範的 seq2seq 模型在神經機器翻譯中變得流行,該任務對於屬於輸入和輸出序列的單字具有不同的先驗機率分佈,因為輸入和輸出話語是用不同的語言編寫的。這裡提出的架構假設輸入和輸出詞有相同的先驗分佈。因此,它透過採用新的模型在編碼和解碼過程之間共享一個嵌入層(Glove預訓練詞嵌入)。為了提高上下文敏感性,思想向量(即編碼器輸出)對直到當前點的對話的最後兩個話語進行編碼。為了避免在答案生成過程中忘記上下文,思想向量被連接到一個密集向量,該向量對截至當前點生成的不完整答案進行編碼。得到的向量被提供給預測答案的當前標記的密集層。請參閱我們論文的第 3.1 節,以便更好地了解我們模型的優勢。
該演算法透過將預測的標記包含到不完整的答案中並將其反饋到如下所示的模型的右側輸入層來進行迭代。
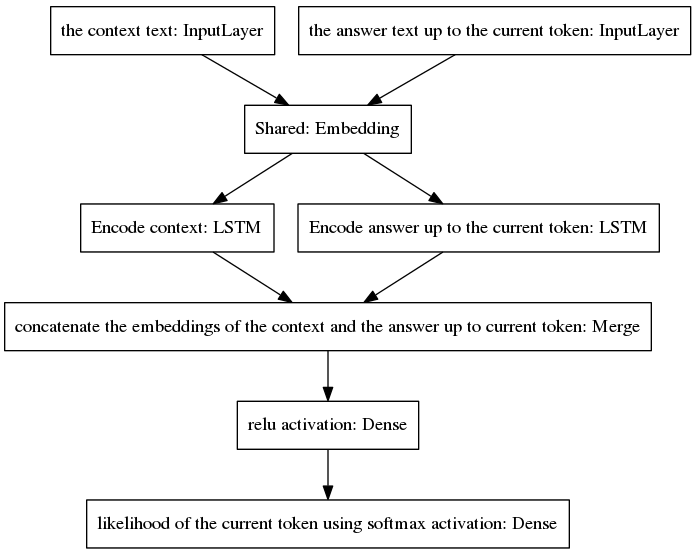
從上圖可以看出,兩個 LSTM 是並行排列的,而規範的 seq2seq 的編碼器和解碼器的循環層是串聯排列的。循環層在隨時間反向傳播期間展開,導致大量巢狀函數,因此梯度消失的風險更高,而規範 seq2seq 模型的循環層級會加劇這種情況,即使在門控架構的情況下也是如此例如LSTM。我相信這是我的模型在訓練過程中比規範 seq2seq 表現更好的原因之一。
以下偽代碼解釋了該演算法。

這個新模型的訓練在幾個時期內收斂。使用我們的 8K 訓練範例資料集,只需要 100 個時期即可達到 0.0318 的分類交叉熵損失,而在 GPU GTX980 中運行的成本為 139 秒/時期。這個經過訓練的模型(在此存儲庫中提供)的性能似乎與在康奈爾電影對話語料庫的約300K 訓練示例上訓練的普通seq2seq 模型的性能一樣令人信服,但訓練所需的計算量要少得多。
與預訓練模型聊天:
下載Python檔案“conversation.py”、詞彙檔案“vocabulary_movie”和淨權值“my_model_weights20”,可以在這裡找到;
運行對話.py。
與我們新的基於 GAN 的訓練演算法訓練的新模型聊天:
下載Python檔案“conversation_discriminator.py”、詞彙檔案“vocabulary_movie”和淨權重“my_model_weights20.h5”、“my_model_weights.h5”和“my_model_weights_discriminator.h5”,可在此處找到;
運行conversation_discriminator.py。
該模型使用相同的訓練資料具有更好的性能。基於 GAN 的模型的判別器用於在兩個模型之間選擇最佳答案,一個模型由教師強制訓練,另一個模型由我們新的類似 GAN 的訓練方法訓練,其詳細資訊可以在本文中找到。
要訓練新模型或微調您自己的資料:
如果您想從頭開始訓練,請刪除檔案 my_model_weights20.h5。要微調您的數據,請保留此文件;
下載 Glove 資料夾「glove.6B」並將該資料夾包含在聊天機器人的目錄中(您可以在此處找到該資料夾)。該演算法透過使用預先訓練的詞嵌入來應用遷移學習,該詞嵌入在訓練過程中進行微調;
執行 split_qa.py 將訓練資料的內容拆分為兩個檔案:“context”和“answers”,並執行 get_train_data.py 將填充的句子儲存到檔案“Plated_context”和“Plated_answers”中;
執行 train_bot.py 來訓練聊天機器人(建議使用 GPU,為此輸入:THEANO_FLAGS=mode=FAST_RUN,device=gpu,floatX=float32,exception_verbosity=high python train_bot.py);
將您的訓練資料命名為「data.txt」。該文件每行必須包含一個對話話語。如果您的資料集很大,請將變數 num_subsets (在 train_bot.py 的第 29 行)設定為更大的數字。
權重檔案 = 'my_model_weights20.h5' 權重檔案_GAN = 'my_model_weights.h5' 權重檔案_discrim = 'my_model_weights_discriminator.h5'
可以在這裡找到不同框架的神經對話模型的當前實現(以及一些結果)的很好的概述。
我們的模型可以應用於其他 NLP 任務,例如文本摘要,請參見範例 2:遞歸模型 A。可以在這份2017 年7 月註冊的文件中看到。
這些程式碼可以在 Ubuntu 14.04.3 LTS、Python 2.7.6、Theano 0.9.0 和 Keras 2.0.4 中運作。使用其他配置可能需要一些小的調整。


