gutenberg dialog
1.0.0
用於下載和建立您自己的古騰堡對話資料集版本的程式碼。可以使用新語言輕鬆擴充。在這裡嘗試訓練有素的各種語言的聊天機器人:https://ricsinaruto.github.io/chatbot.html。
| 下載連結 | 話語數 | 平均話語長度 | 對話數量 | 平均對話長度 |
|---|---|---|---|---|
| 英語 | 14 773 741 | 22.17 | 2 526 877 | 5.85 |
| 德文 | 226 015 | 24.44 | 43 440 | 5.20 |
| 荷蘭語 | 129 471 | 24.26 | 23 541 | 5.50 |
| 西班牙語 | 58 174 | 18.62 | 6 912 | 8.42 |
| 義大利語 | 41 388 | 19.47 | 6664 | 6.21 |
| 匈牙利 | 18816 | 14.68 | 2 826 | 6.66 |
| 葡萄牙語 | 16228 | 21.40 | 2233 | 7.27 |
? 透過調整影響資料集大小與品質權衡的參數來產生您自己的資料集
模組化介面可以輕鬆地將資料集擴展到其他語言
? 您可以在建立資料集時輕鬆手動排除書籍
執行 setup.py 安裝所需的套件。
python setup.py
應從儲存庫的根目錄呼叫主檔案。下面的命令為作為參數給出的逗號分隔語言運行資料集建構管道。目前支援英語、德語、荷蘭語、西班牙語、葡萄牙語、義大利語和匈牙利語。
python code/main.py -l=en,de,nl,es,pt,it,hu -a
所有可設定的參數如下所示: 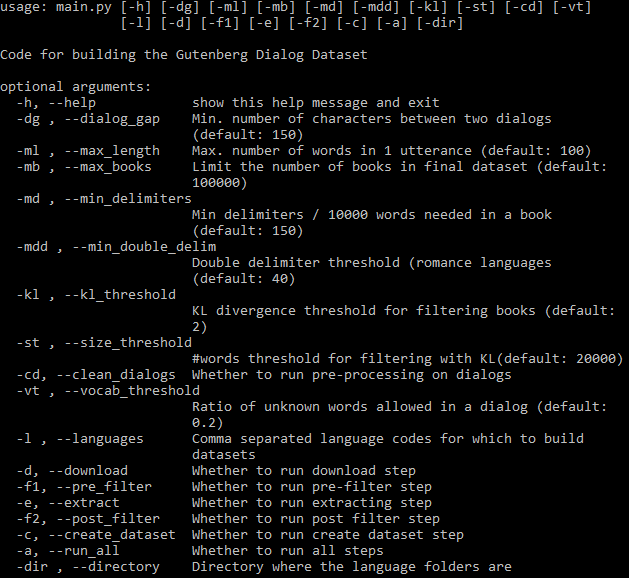
-a標誌控制是否自動運轉整個管道。如果省略-a,則必須使用標誌指定步驟子集(請參閱上面的說明)。步驟完成後,其輸出可在後續步驟中使用,並且僅當與該步驟相關的參數或程式碼發生變更時,它才會再次運作。所有步驟針對每種語言單獨執行。
下載給定語言的書籍。
注意:如果所有書籍都無法下載,並出現錯誤“無法下載書籍”,可能的原因是gutenberg包使用的預設鏡像無法存取。如果發生這種情況,可以透過GUTENBERG_MIRROR環境變數使用 https://www.gutenberg.org/MIRRORS.ALL 中列出的任何備用鏡像。例如:
export GUTENBERG_MIRROR="https://gutenberg.pglaf.org"
python code/main.py ...
預先過濾去除一些舊書和噪音。
對話是從書中摘錄的。將資料集擴展到新語言時(請參閱下面的部分),這是可以修改的步驟,因此完成後可以跳過前面的步驟。
第二個過濾步驟是根據詞彙刪除一些對話。
將最終資料集放在一起並分成訓練/開發/測試資料。最後一步在輸出目錄中建立author_and_title.txt文件,其中包含用於提取最終資料集的所有書籍(加上標題和作者)。使用者可以手動將此文件中的行複製到與資料集中不應允許的書籍相對應的banned_books.txt 。在任何步驟的後續運行中,將不會考慮此文件中的書籍。
該程式碼可以輕鬆擴展以處理其他語言。必須在 languages 資料夾中建立名為 <語言程式碼>.py 的檔案。這裡應該定義一個類,命名為大寫語言代碼(例如En代表英語),以 LANG 或任何其他子類作為父類。透過self.cfg可以存取配置參數。在這個類別中必須定義以下 3 個函數。請參閱 it.py 作為範例。
語言統計
此函數應傳回一個字典,其中鍵是潛在的分隔符號。對於每個分隔符,應該定義一個函數(字典中的值),該函數將一行作為輸入並傳回一個數字。該數字可以是例如分隔符號的計數、行中是否有分隔符號的標誌等。這些值將用於確定應在對應書籍中使用的分隔符號(傳遞給下面的函數),並用於過濾包含少量分隔符號的書籍。 en.py 包含多個分隔符號的範例。
這個函數應該從書中提取對話並將其附加到self.dialogs中,這是一個對話列表,每個對話都是連續話語的列表。 paragraph_list將書籍包含為連續段落的清單。分隔符是此文件中最常見的分隔符,套用於提取對話框。
此函數用於後處理對話方塊(例如刪除某些字元)。它以話語作為輸入。請注意,nltk 單字標記化是自動運行的。
該項目根據 MIT 許可證獲得許可 - 有關詳細信息,請參閱許可證文件。
如果您在工作中使用任何資料集或程式碼,請包含此儲存庫的鏈接,並考慮引用以下論文:
@inproceedings{Csaky:2021,
title = "The Gutenberg Dialogue Dataset",
author = "Cs{'a}ky, Rich{'a}rd and Recski, G{'a}bor",
booktitle = "Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics",
month = apr,
year = "2021",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/2004.12752",
}


