Seq2seqChatbots
1.0.0
tensor2tensor 的包裝器,用於靈活地訓練、互動和產生神經聊天機器人的資料。
該 wiki 包含我對 150 多篇與神經對話建模相關的最新出版物的筆記和摘要。
? 運行您自己的訓練或使用預先訓練的模型進行實驗
✅ 與tensor2tensor整合的4個不同的對話資料集
? 與tensor2tensor中設定的任何模型或超參數無縫配合
可輕鬆擴展對話框問題的基類
執行 setup.py,它會安裝所需的軟體包並引導您下載其他資料:
python setup.py
您可以從此處下載本文中使用的所有經過訓練的模型。每次訓練包含兩個檢查點,一個用於驗證損失最小值,另一個在 150 個時期之後。資料和訓練資料夾結構彼此完全匹配。
python t2t_csaky/main.py --mode=train
mode 參數可以是以下四種之一: {generate_data, train,decode,experiment} 。在實驗模式下,您可以指定在執行檔案的實驗函數內要執行的操作。下面詳細解釋了每種模式的作用。
您可以直接在此文件中控制每種模式的標誌和參數。對於您啟動的每次執行,此檔案都會複製到相應的目錄,以便您可以快速存取任何正在執行的參數。您必須為每種模式設定一些標誌(設定檔中的FLAGS字典):
t2t_usr_dir :我的程式碼所在目錄的路徑。您不必更改此設置,除非您重新命名該目錄。
data_dir :要產生來源和目標對以及其他資料的目錄的路徑。資料集將從該目錄更高一級下載到raw_data資料夾中。
Problem :這是tensor2tensor所需的已註冊問題的名稱。詳細資訊請參考下面的generate_data部分。所有路徑都應來自儲存庫的根目錄。
此模式將下載並預處理資料並產生來源和目標對。目前,除了tensor2tensor給出的問題之外,還有6個已註冊的問題可以使用:
persona_chat_chatbot :此問題實作了 Persona-Chat 資料集(不使用角色)。
daily_dialog_chatbot :此問題實作了 DailyDialog 資料集(不使用主題、對話行為或情緒)。
opensubtitles_chatbot :此問題可用來處理 OpenSubtitles 資料集。
cornell_chatbot_basic :此問題實現了康乃爾電影對話語料庫。
cornell_chatbot_separate_names :此問題使用相同的康乃爾語料庫,但是附加了每個話語的說話者和收件者的姓名,從而產生如下所示的來源話語。
BIANCA_m0 有什麼好東西? 卡梅倫_m0
character_chatbot :這是一個基於字元的通用問題,適用於任何資料集。在使用此問題之前,必須將上述任何問題產生的.txt檔案放置在資料目錄中,之後可以使用此問題產生tensor2tensor基於字元的資料檔案。
設定檔中的PROBLEM_HPARAMS字典包含您可以在產生資料之前設定的問題特定參數:
num_train_shards / num_dev_shards :如果您希望將產生的訓練或開發資料分片到多個檔案中。
vocabulary_size :我們要用來解決問題的詞彙量的大小。該詞彙表之外的單字將被替換為標記。
dataset_size :話語對的數量,如果我們不想使用完整的資料集(由 0 定義)。
dataset_split :指定問題的訓練-驗證-測試分割。
dataset_version :這僅與 opensubtitles 資料集相關,因為該資料集有多個版本,您可以指定要下載的資料集的年份。
name_vocab_size :這僅與具有單獨名稱的康乃爾問題相關。您可以設定僅包含角色的詞彙表的大小。
此模式可讓您使用指定的問題和超參數訓練模型。程式碼僅呼叫tensor2tensor訓練腳本,因此可以使用tensor2tensor中的任何模型。除此之外,還有一個經過小修改的子類別模型:
gradient_checkpointed_seq2seq :對基於 lstm 的 seq2seq 模型進行小修改,以便可以完全使用自己的 hparams。在計算 softmax 之前,LSTM 隱藏單元被投影為 2048 個線性單元,如下所示。最後,我嘗試對此模型實現梯度檢查點,但目前它已被刪除,因為它沒有給出良好的結果。
您可以在設定檔的FLAGS字典中為訓練運行指定幾個附加標誌,其中一些是:
train_dir :儲存訓練檢查點檔案的目錄名稱。
model :模型名稱:以上之一或tensor2tensor定義的模型。
hparams :指定已註冊的 hparams_set,或如果要在設定檔中定義 hparams,則保留為空。為了為seq2seq或Transformer模型指定 hparams,您可以在設定檔中使用SEQ2SEQ_HPARAMS和TRANSFORMER_HPARAMS字典(查看更多詳細資訊)。
使用此模式,您可以從經過訓練的模型中進行解碼。以下參數會影響解碼(在設定檔的FLAGS字典中):
解碼模式:可以是互動的,您可以使用命令列與模型聊天。文件模式可讓您指定一個包含要產生回應的來源話語的文件,資料集模式將對提供的驗證資料進行隨機取樣並輸出回應。
decode_dir :您可以提供要解碼的檔案的目錄,輸出的回應將保存在此。
input_file_name :您必須在檔案模式下提供的檔案的名稱(放置在decode_dir中)。
output_file_name : decode_dir內的檔案名,輸出回應將會保存在其中。
beam_size :使用波束搜尋時波束的大小。
return_beams :如果為 False,則僅傳回頂部梁,否則傳回beam_size梁數。
以下結果來自這兩篇論文。
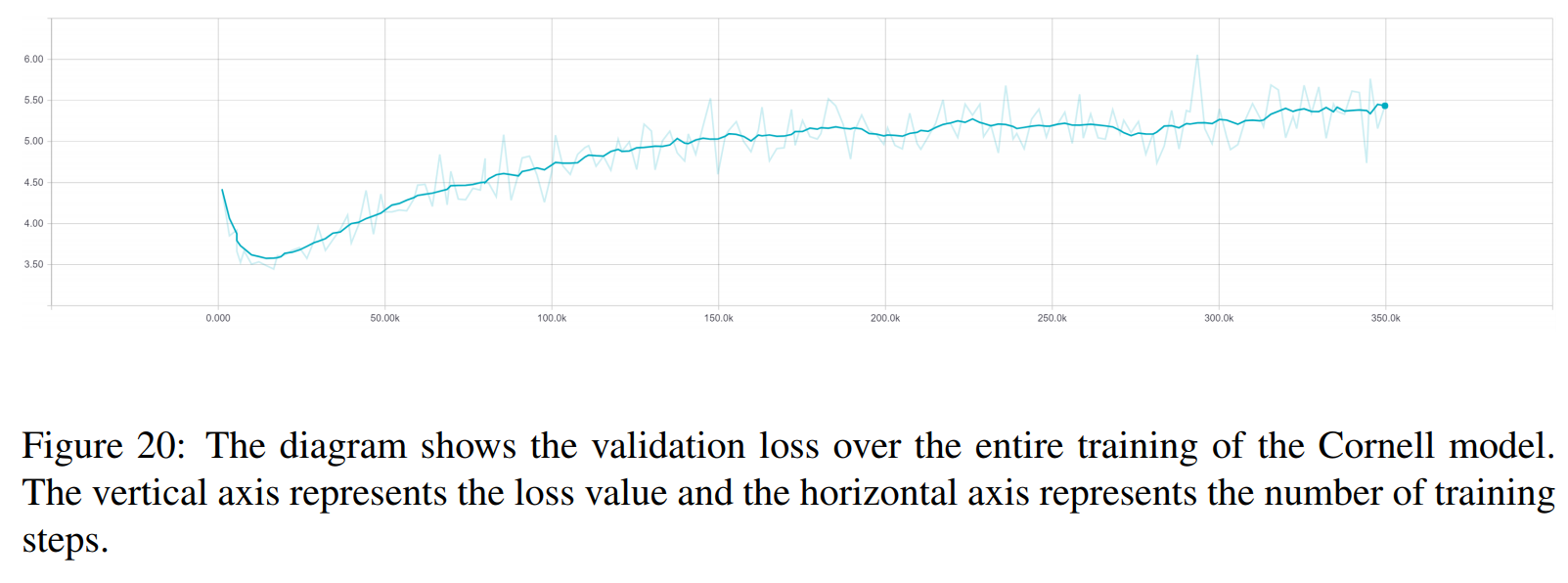

TRF 是 Transformer 模型,RT 是指從訓練集中隨機選擇的反應,GT 是指真實反應。有關指標的說明,請參閱論文。
S2S 是一個簡單的 seq2seq 模型,其中 LSTM 在 Cornell 上訓練,其他是 Transformer 模型。 Opensubtitles F 在 Opensubtitles 上進行了預訓練,並在 Cornell 上進行了微調。 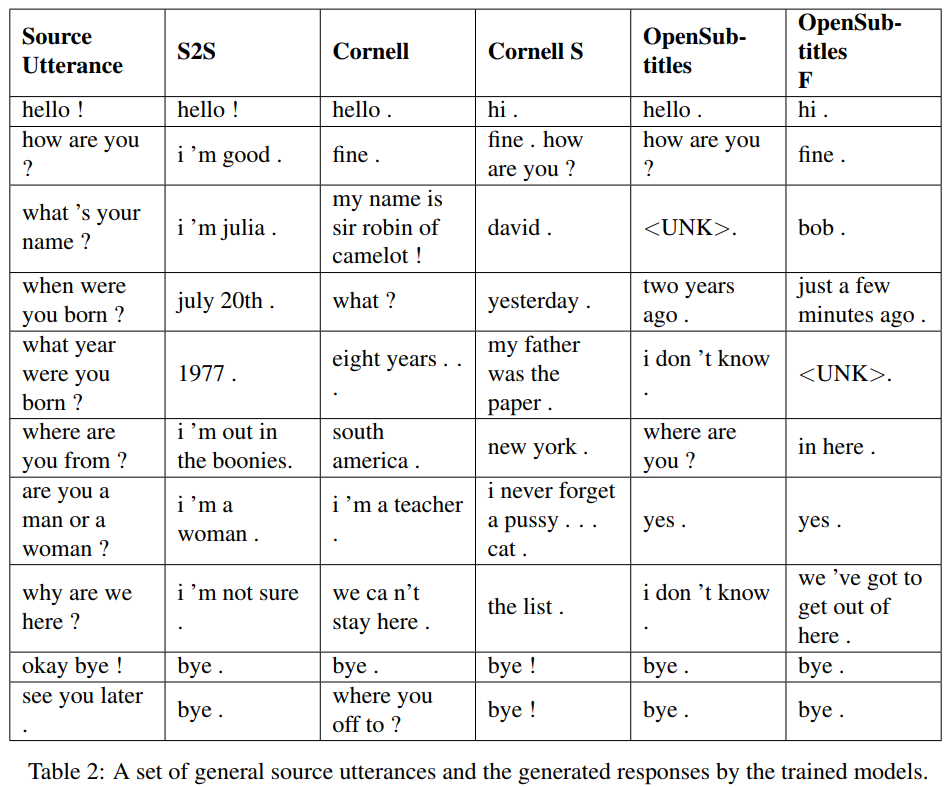
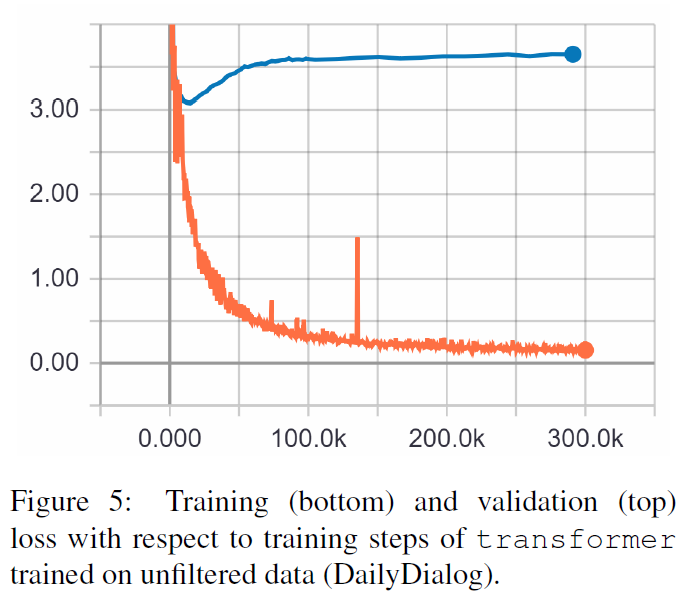

TRF 是 Transformer 模型,RT 是指從訓練集中隨機選擇的反應,GT 是指真實反應。有關指標的說明,請參閱論文。
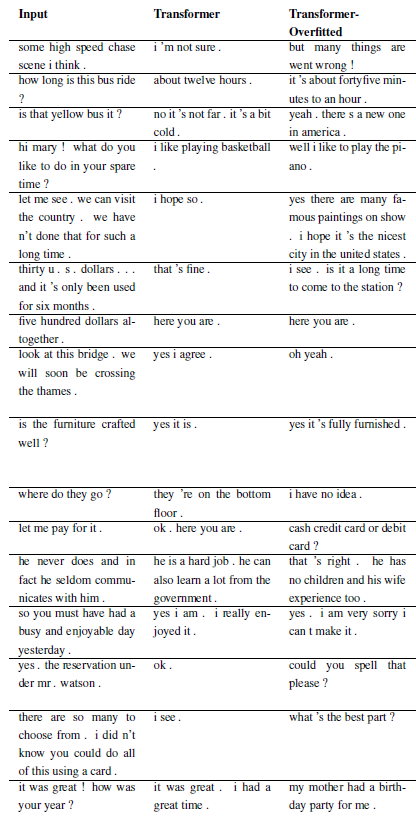
新問題可以透過子類化 WordChatbot 來註冊,甚至更好地子類化 CornellChatbotBasic 或 OpensubtitleChatbot,因為它們實現了一些附加功能。通常覆蓋preprocess和create_data函數就夠了。檢查文件以獲取更多詳細信息,並參閱 daily_dialog_chatbot 以獲取範例。
可以依照tensor2tensor教程新增模型和超參數。
Richard Csaky (如果您在執行程式碼時需要任何協助:[email protected])
該項目根據 MIT 許可證獲得許可 - 有關詳細信息,請參閱許可證文件。
如果您在工作中使用該存儲庫,請包含該存儲庫的鏈接,並考慮引用以下論文:
@InProceedings{Csaky:2017,
title = {Deep Learning Based Chatbot Models},
author = {Csaky, Richard},
year = {2019},
publisher={National Scientific Students' Associations Conference},
url ={https://tdk.bme.hu/VIK/DownloadPaper/asdad},
note={https://tdk.bme.hu/VIK/DownloadPaper/asdad}
} 

