Multi Modality Arena
1.0.0
Multi-Modality Arena是大型多模態模型的評估平台。在 Fastchat 之後,兩個匿名模型在視覺問答任務上並排進行了比較。我們發布了Demo ,歡迎大家參與本次評測活動。
OmniMedVQA 資料集:包含 118,010 張影像和 127,995 個 QA 項目,涵蓋 12 種不同模式,涉及 20 多個人體解剖區域。資料集可以從這裡下載。
12 個模型:8 個通用領域 LVLM 和 4 個醫學專用 LVLM。
微小資料集:每個資料集僅隨機選擇 50 個樣本,即 42 個與文字相關的視覺基準和總共 2.1K 個樣本,以便於使用。
更多型號:另外4款,即總共12款,其中包括Google Bard 。
ChatGPT Ensemble Evalution :與先前的單字配對方法相比,提高了與人類評估的一致性。
LVLM-eHub 是公開的大型多模態模型 (LVLM) 的綜合評估基準。 它廣泛評估
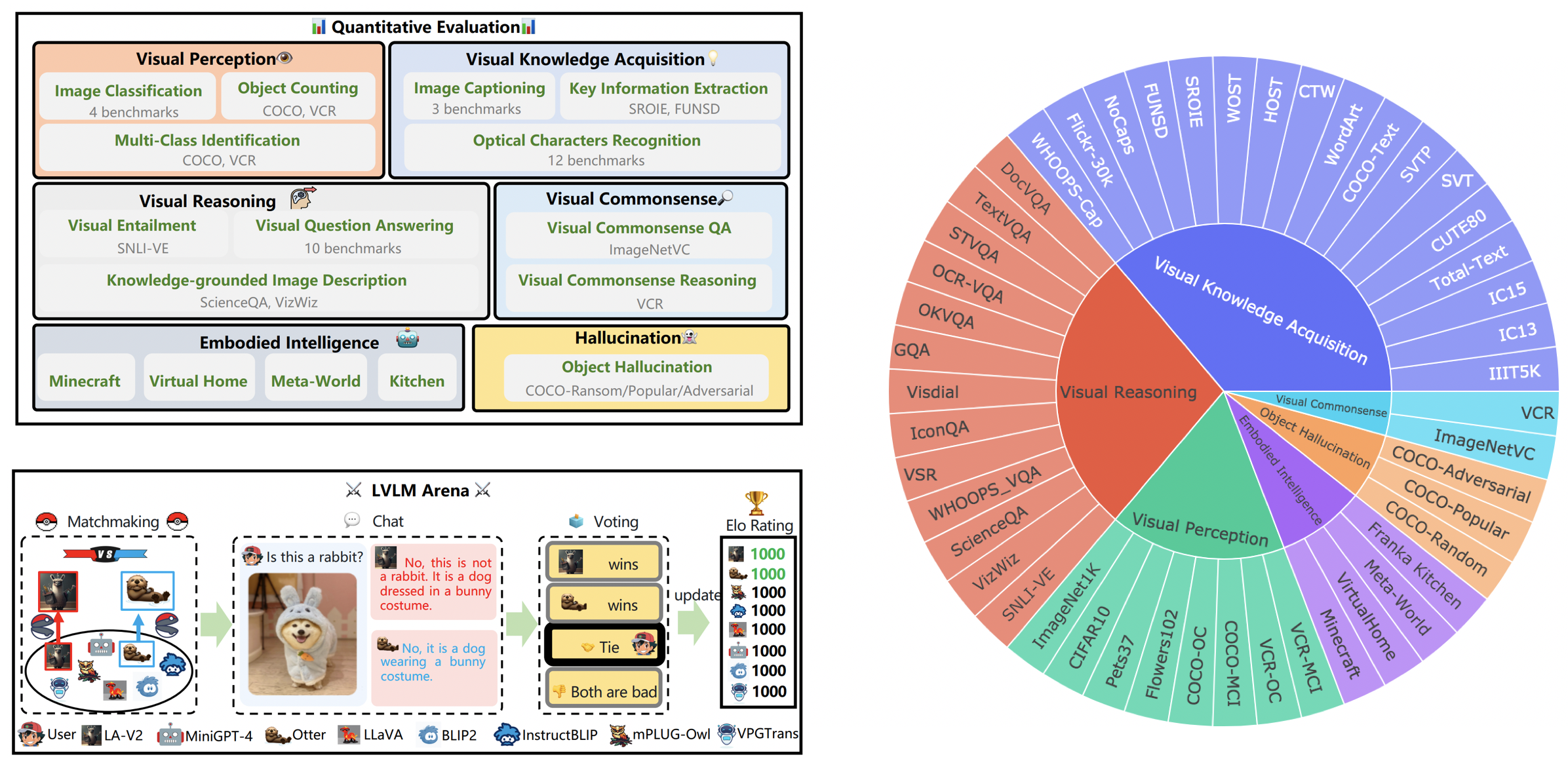
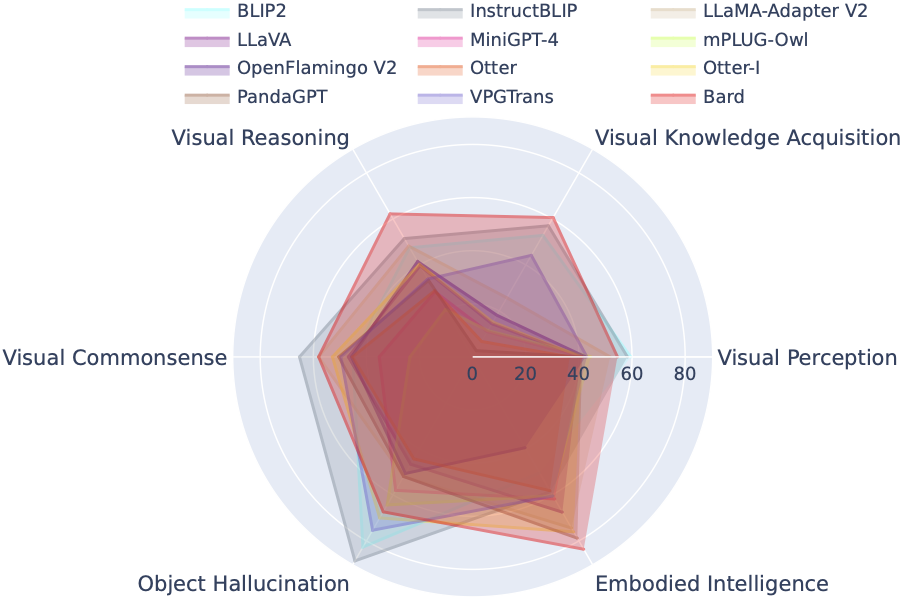
LVLM 排行榜根據特定的目標能力(包括視覺感知、視覺推理、視覺常識、視覺知識獲取和物體幻覺)對 Tiny LVLM 評估中的資料集進行系統分類。該排行榜包括最近發布的模型,以增強其綜合性。
您可以從這裡下載基準測試,更多詳細資訊可以在此處找到。
| 秩 | 模型 | 版本 | 分數 |
|---|---|---|---|
| 1 | 實習生VL | 實習生VL-Chat | 327.61 |
| 2 | 實習生LM-XComposer-VL | 實習生LM-XComposer-VL-7B | 322.51 |
| 3 | 詩人 | 詩人 | 319.59 |
| 4 | Qwen-VL-聊天 | Qwen-VL-聊天 | 316.81 |
| 5 | LLaVA-1.5 | 駱駝毛-7B | 307.17 |
| 6 | 指導BLIP | 駱駝毛-7B | 300.64 |
| 7 | 實習生LM-X作曲家 | 實習生LM-XComposer-7B | 288.89 |
| 8 | BLIP2 | 餡餅T5xl | 284.72 |
| 9 | 布利瓦 | 駱駝毛-7B | 284.17 |
| 10 | 山貓 | 駱駝毛-7B | 279.24 |
| 11 | 獵豹 | 駱駝毛-7B | 258.91 |
| 12 | LLaMA-適配器-v2 | 拉馬-7B | 229.16 |
| 13 | 維普吉運輸公司 | 駱駝毛-7B | 218.91 |
| 14 | 水獺影像 | Otter-9B-LA-InContext | 216.43 |
| 15 | 視覺GLM-6B | 視覺GLM-6B | 211.98 |
| 16 | mPLUG-Owl | 拉馬-7B | 209.40 |
| 17 號 | 拉瓦 | 駱駝毛-7B | 200.93 |
| 18 | 迷你GPT-4 | 駱駝毛-7B | 192.62 |
| 19 | 獺 | 水獺9B | 180.87 |
| 20 | OFv2_4BI | RedPajama-INCITE-Instruct-3B-v1 | 176.37 |
| 21 | 熊貓GPT | 駱駝毛-7B | 174.25 |
| 22 | 拉文 | 拉馬-7B | 97.51 |
| 23 | MIC | 餡餅T5xl | 94.09 |
2024 年 3 月 31 日,我們發布了 OmniMedVQA,一個針對醫療 LVLM 的大規模綜合評估基準。同時,我們有 8 個通用領域 LVLM 和 4 個醫學專用 LVLM。如欲了解更多詳情,請瀏覽 MedicalEval。
2023 年 10 月 16 日。如需存取資料集分割、評估程式碼、模型推理結果和綜合效能表,請造訪tiny_lvlm_evaluation ✅。
2023年8月8日,我們發布了【Tiny LVLM-eHub】 。評估原始碼和模型推理結果在tiny_lvlm_evaluation下開源。
2023 年 6 月 15 日。發布了大型視覺語言模型的評估基準[LVLM-eHub] 。代碼即將推出。
2023年6月8日,感謝VPGTrans作者張博士的指正。 VPGTrans的作者主要來自新加坡國立大學和清華大學。我們之前在重新實作 VPGTrans 時遇到了一些小問題,但我們發現它的效能實際上更好。更多模型作者請透過Email聯絡我進行討論。另外,請關注我們的模型排名列表,以獲得更準確的結果。
可能。 2023年2月22日,感謝mPLUG-Owl的作者葉博士的指正。我們修復了 mPLIG-Owl 實作中的一些小問題。
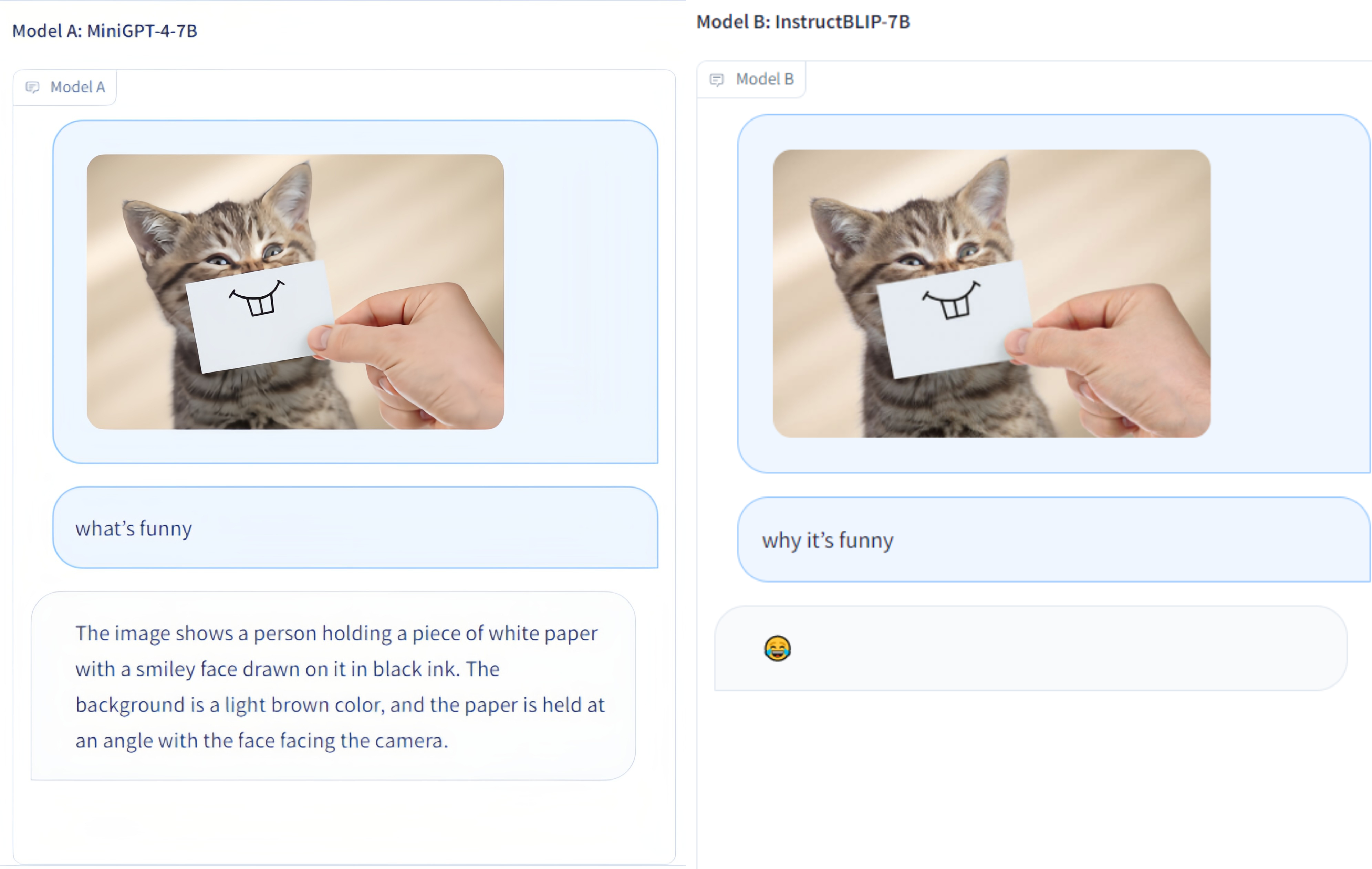
目前參與隨機戰鬥的模型如下:
KAUST/MiniGPT-4
Salesforce/BLIP2
Salesforce/InstructBLIP
達摩院/mPLUG-Owl
南洋理工大學/水獺
威斯康辛大學麥迪遜分校/LLaVA
上海人工智慧實驗室/llama_adapter_v2
新加坡國立大學/VPGTrans
有關這些模型的更多詳細資訊可以在./model_detail/.model.jpg中找到。我們將嘗試調度計算資源以在競技場中託管更多的多模態模型。
如果您對我們VLarena平台的任何內容感興趣,請隨時加入微信群組。

創建conda環境
conda 創建-n arena python=3.10 康達激活競技場
安裝運作控制器和伺服器所需的軟體包
pip 安裝 numpy gradio uvicorn fastapi
然後,對於每個模型,它們可能需要衝突版本的 python 套件,我們建議根據其 GitHub 儲存庫為每個模型建立特定環境。
要使用 Web UI 提供服務,您需要三個主要元件:與使用者互動的 Web 伺服器、託管兩個或多個模型的模型工作人員以及協調 Web 伺服器和模型工作人員的控制器。
以下是您的終端機中要遵循的命令:
python控制器.py
此控制器管理分散式工作人員。
python model_worker.py --模型名稱 SELECTED_MODEL --設備 TARGET_DEVICE
等待進程完成載入模型,您會看到「Uvicorn running on ...」。模型工作人員會將自己註冊到控制器。對於每個模型工作者,您需要指定模型和要使用的設備。
python server_demo.py
這是用戶將與之互動的使用者介面。
透過執行這些步驟,您將能夠使用 Web UI 為您的模型提供服務。現在您可以打開瀏覽器並與模特兒聊天。如果模型未顯示,請嘗試重新啟動 gradio Web 伺服器。
我們非常重視旨在提高評估品質的所有貢獻。本節包括兩個關鍵部分: Contributions to LVLM Evaluation和Contributions to LVLM Arena 。
您可以在 LVLM_evaluation 資料夾中存取最新版本的評估代碼。目錄包含一套全面的評估代碼,並附有必要的資料集。如果您熱衷於參與評估過程,請隨時透過電子郵件 [email protected] 與我們分享您的評估結果或模型推理 API。
我們對您有興趣將您的模型整合到我們的 LVLM Arena 表示感謝!如果您希望將您的模型納入我們的 Arena,請準備一個結構如下的模型測試器:
class ModelTester:def __init__(self, device=None) -> None:# TODO: 初始化模型和所需的預處理器def move_to_device(self, device) -> None:# TODO: 此函數用於在CPU和CPU之間傳輸模型GPU (可選)defgenerate(self, image, Question) -> str: # TODO: 模型推理程式碼
此外,我們對線上模型推理連結持開放態度,例如 Gradio 等平台提供的連結。我們衷心感謝您的貢獻。
我們對 ChatBot Arena 受人尊敬的團隊以及他們的論文《Judging LLM-as-a-judge》表示感謝,感謝他們的影響力工作,這些工作為我們的 LVLM 評估工作提供了靈感。我們也要向 LVLM 的提供者致以誠摯的謝意,他們的寶貴貢獻為大型視覺語言模型的進步和進步做出了重大貢獻。最後,我們感謝 LVLM-eHub 中使用的資料集的提供者。
該計畫是一個實驗研究工具,僅用於非商業目的。它的保護措施有限,並且可能會產生不當內容。它不能用於任何非法、有害、暴力、種族主義或性行為。


